1. Introduction
Audio transducers are devices that convert electrical signals into acoustic waves or vice versa [
1]. In the first case, they are called
audio actuators (e.g., loudspeakers), while in the second case
audio sensors (e.g., microphones). The transduction process that characterizes such devices involves different physical domains (such as mechanical, acoustic, electrical, magnetic, etc.), which not only are affected by different nonlinear behaviors but they do interact in a nonlinear fashion. For instance, piezoelectric loudspeakers are impaired by hysteretic phenomena which do increase the Total Harmonic Distortion (THD) [
2,
3,
4], electrodynamic loudspeakers are characterized by a nonlinear force factor and compliance [
5], while clipping is the major source of distortion in microphones [
6]. Audio transducers are pervasive devices that have become, over the years, of fundamental importance all over the markets. It is thus desirable to come up with solutions that enable a control on the nonlinear behavior of acoustic transducers, and thus on the amount of distortion that they introduce, such that better acoustic performance can be obtained.
Since the rise of the audio industry, different techniques have been proposed for improving the sonic response of audio transducers. Apart from solutions based on a more refined analog design, many techniques do exploit digital audio signal processing for accomplishing such a task. For the case of audio actuators, the simplest solutions make use of filters to equalize the acoustic response over the frequency spectrum [
7]. Other solutions, instead, pre-distort the electrical signal with the aim of reducing the impact of nonlinearities [
8]; others involve feedback loops for accomplishing linearization and compensation [
9,
10], while more recent virtual bass enhancement techniques exploit psychoacoustic effects for deceiving the human perception of sound [
11,
12,
13]. On the other side, similar approaches have been proposed for digitally enhancing the performance of audio sensors [
14,
15].
In this work, we introduce and analyze a novel class of digital signal processing algorithms which we refer to as
virtualization algorithms. We define virtualization as the task of digitally altering and conditioning the acoustic behavior of an audio transducer with the aim of mimicking the sound of a (virtual) target transducer. Such algorithms are based on general signal processing chains which can be exploited to perform all the traditional tasks envisaged by the algorithms mentioned in the previous paragraph, e.g., linearization and equalization. Recently, loudspeaker virtualization has been tackled by using a digital signal processing approach based on physical modeling [
16,
17], which exploits the inverse model of the loudspeaker equivalent circuit. The design of the inverse system relies on Leuciuc’s theorem [
18], reworded in [
16,
19], and it is derived by duly adding to the direct circuital system a theoretical two-port element, known in circuit theory as
nullor. The digital inverse system can then be used to compensate for the behavior of the physical loudspeaker and, hence, impose the behavior of a digital target system. This is achieved by implementing the so called Direct–Inverse–Direct Chain [
17] composed of a target direct system, which is a digital filter characterized by the desired transduction behavior to be imposed; the inverse loudspeaker system, which is a digital filter whose response is the inverse of that of the physical transducer; and the (direct) phyisical loudspeaker. While in the approach of [
16,
17] inversion is digitally attained, other methods to design inverse circuital systems, which rely on analog filters or integrated circuits, such as operational transconductance amplifiers, current conveyors, current differencing buffered amplifiers, etc. [
20], have been proposed. However, for the sake of simplicity, in this manuscript, we will only consider inverse design approaches based on digital filters. In this regard, nullors can be efficiently implemented in the discrete-time domain making use of the Wave Digital Filter (WDF) paradigm.
WDF theory was originally introduced by A. Fettweis in the late 1970s for designing stable digital filters through the discretization of linear passive analog filters [
21], and was later extended to also efficiently implement active and nonlinear circuits in the discrete-time domain [
22,
23,
24]. In the WDF framework, port voltages and port currents are substituted with linear combinations of
incident and
reflected waves introducing a free parameter per port called
port resistance. In the Wave Digital (WD) domain, circuit elements are modeled in a modular fashion as input–output blocks characterized by scattering relations, while topological interconnections or, more generally, connection networks are described by multi-port junctions characterized by scattering matrices [
21,
24]. The introduced free parameters can be properly set to eliminate some delay-free-loops (i.e., implicit relations between circuit variables) appearing in the digital structure composed of input–output elements and junctions. Circuits with up to one nonlinear element (described by an explicit mapping) can be digitally implemented in the WD domain in a fully explicit fashion, i.e., without making use of any iterative solver [
24], while using stable discretization methods (e.g., Backward Euler, trapezoidal rule, etc.) to approximate time-derivatives. As far as the implementation of nullors is concerned, different techniques have been proposed in the literature of WDFs. In [
22], stamps are provided for encompassing nullors into scattering junctions by means of the Modified Nodal Analysis (MNA) formalism. The same result is reached in a more efficient fashion considering a double digraph decomposition of the connection network, as pointed out in [
23]. In [
25], vector waves are used to derive a vectorial scattering relation that allows to implement a nullor as a two-port input–output element in the WD domain. Moreover, in [
16,
17], it has already been shown that WDFs are suitable to efficiently emulate direct and inverse models of nonlinear loudspeakers in the discrete-time domain with no need of iterative solvers.
In this paper, we discuss the task of audio transducer virtualization from a general theoretical perspective, by analyzing different scenarios and combinations of input/output signals. Our aim is to provide a
compendium for the design of inverse circuital models of audio transducers in different vitualization scenarios. In fact, we describe both the case of actuator virtualization and of sensor virtualization, making appropriate adjustments to the employed Direct–Inverse–Direct Chain [
17,
26]. In doing so, we will consider electrical equivalent models of audio transducers which are derived by exploiting the electro-mechano-acoustical analogy [
1,
27]. Finally, we present two case studies showing how the proposed methodology can be exploited to alter the acoustic response of different audio devices.
The manuscript is organized as follows.
Section 2 provides, first, background knowledge on nullor-based inversion of circuital systems, and, then, introduces ready-to-use schemes and block diagrams for the inversion of electrical equivalent models of audio systems taking into account all possible combinations of input and output variables. Virtualization algorithms that exploit nullor-based inversion of circuits are, instead, presented in
Section 3. Examples of application of such algorithms are provided in
Section 4 and
Section 5, where the virtualization of a capacitive microphone and a nonlinear compression driver are presented. Conclusions are drawn in
Section 6.
3. Direct–Inverse–Direct Chains
We now present a general block chain to perform virtualization of transducers. Such a chain, shown in
Figure 7, is called
Direct–Inverse–Direct Chain (DIDC) and was proposed in [
17] for addressing the virtualization of loudspeakers. It is composed of three main blocks: two
Direct Systems, and one
Inverse System. The
Inverse System is always implemented in the digital domain, whereas, according to the considered actuator or sensor application, only the first or the last
Direct System is implemented in the digital domain since the other is the actual physical transducer. Moreover, in real scenarios, amplifiers could be present in-between blocks. Hence, gains should be considered at different stages of the processing chain for the algorithm to properly work.
The DIDC working principle is based on the assumption that the cascade of the Inverse System and the Physical Direct System is equivalent to the identity. This means that the digital processing chain allows us to somehow cancel out the behavior of the transducer such that the target behavior, i.e., the behavior of the digital Direct System, can be imposed. Hence, the proposed processing chain can be employed to accomplish the task of transducer virtualization (i.e., digitally altering the acoustic behavior of an audio transducer with the aim of mimicking the sound of a target transducer).
In the following two subsections, we will present application-specific DIDCs targeting both the cases of actuator and sensor virtualization.
3.1. Target-Inverse-Physical Chain (TIPC)
Let us consider the particular DIDC shown in
Figure 8. Such a DIDC is specifically tailored for the task of actuator virtualization, and has been first proposed in [
16] for deriving the loudspeaker virtualization algorithm. The green blocks are to be implemented in the digital domain, while the red block represents the actual physical transducer. In particular, the
Target Direct System is the digital implementation of the actuator circuital model which we would like to obtain, whereas the
Inverse System is the inverse circuital model of the
Physical Direct System, which is the transducer itself. Hence, given that we are considering actuation, we may call this chain
Target-Inverse-Physical Chain (TIPC), since the target behavior must be imposed in a pre-processing phase and thus before driving the actuator, i.e., the
Physical Direct System.
For the case of loudspeaker virtualization, the input
is the electrical signal driving the loudspeaker, while the output signal
may be the output pressure or the velocity of the speaker diaphragm (usually represented in electrical equivalent models as a voltage signal and a current signal, respectively [
1,
16,
17,
27]). Then, in principle, the TIPC allows us to make a speaker A sound as a speaker B, where such a speaker B (i.e., the
Target Direct System) can be a linearized or equalized version of A, or a different speaker. It follows that the more accurate the considered electrical models, the higher the performance of the algorithm. Nonetheless, in [
17], it is shown that the algorithm is robust to parameter uncertainty, increasing the number of real scenarios in which it can be applied. In
Section 5, we will show how to apply TIPC for the virtualization of a nonlinear compression driver, and how this can be accomplished in a simple and efficient fashion making use of Wave Digital Filters (WDFs).
It is worth adding that other variables aside currents and voltages could be taken into account to obtain the inverse of a given circuit. For example, for the case of loudspeakers, it might be convenient to consider the displacement of the diaphragm (i.e., the integral of the velocity of the diaphragm) as the output variable. In this case, another stage should be inserted into the processing chain for performing the integral of the velocity (which is a current variable in the electrical equivalent circuit) in the Direct System, and the derivative of the displacement in the Inverse System.
Finally, note that according to the type of virtualization, the blocks could be either linear or nonlinear. For example, all the three blocks could be nonlinear if the chain is exploited for imposing the nonlinear sonic behavior of a target transducer. Instead, if linearization is envisaged, one out of the three blocks will be linear (i.e., the Target Direct System). In this case, the purpose of virtualization is to improve the performance of the transducers by reducing the Total Harmonic Distortion (THD) imposing somehow the acoustic behavior of an ideal version of the transducer under consideration. Such a discussion is also valid for the specific DIDC that we introduce in the next subsection.
3.2. Physical-Inverse-Target Chain (PITC)
Let us now consider the DIDC shown in
Figure 9, which is specifically designed to address the task of sensor virtualization. Such a DIDC can be considered as a flipped version of the TIPC, since the target behavior is imposed in a post-processing phase instead of a pre-processing phase. Once again, the green blocks are implemented in the digital domain, whereas the red block represents the actual physical transducer. The
Target Direct System is the digital implementation of the sensor circuital model whose behavior we would like to impose, while the
Inverse System is the inverse circuital model of the
Physical Direct System, i.e., the sensor itself. Given that we are considering sensing, we call this version of the chain
Physical-Inverse-Target Chain (PITC), since first the audio signal is acquired by means of the sensor, and then, after compensating for the physical behavior by means of the
Inverse System, the signal is processed to impose the target acoustic response. For the case of microphone virtualization, the input signal
might be the acoustic pressure (i.e., a voltage) acquired by the sensor while the output signal is an electrical signal (e.g., a voltage) that is usually fed to an audio interface. In this scenario, therefore, the aim of the PITC is to modify the electrical signal as if it was acquired by another sensor, which can be a linearized or equalized version of the sensor under consideration or a different sensor. In
Section 4, we will apply such a virtualization algorithm for altering the acoustic response of a condenser microphone.
Once again, input and output variable different from voltages and currents (e.g., displacement signals) can be considered by introducing integrators and derivators into the green blocks of the processing chain.
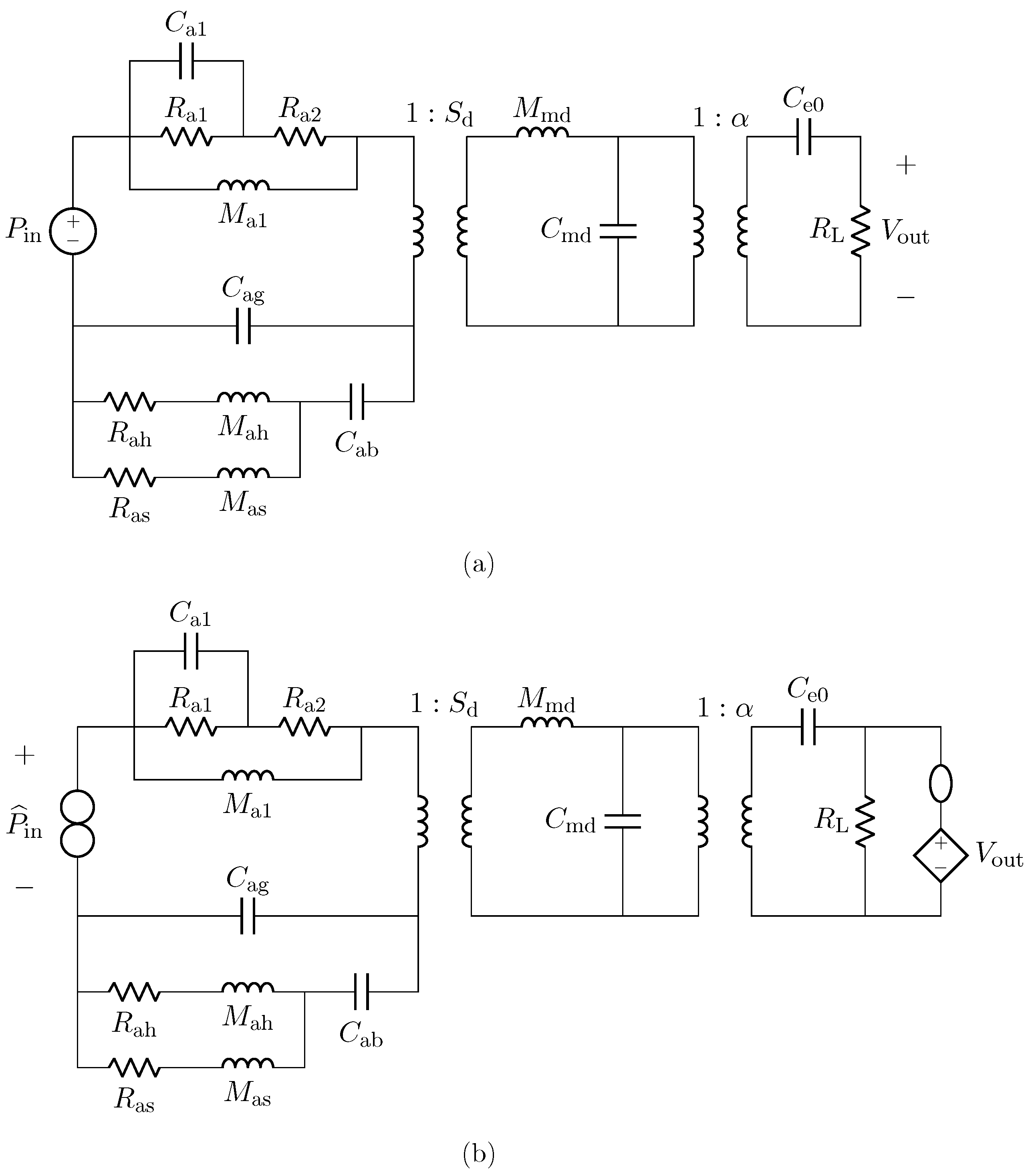
4. Sensor Virtualization: Application to Capacitive Microphones
In this section, we provide an example of sensor virtualization by taking into account a capacitive microphone as a case study. For this application, we employ a linear model, while an example of transducer virtualization based on nonlinear models will be provided in the next section. The microphone is described by means of the circuit shown in
Figure 10a. The circuit is similar to the one presented in [
1] and, it is composed of three subcircuits which represent, from left to right, the acoustic, mechanical, and electrical domains. In particular,
is the acoustic compliance of the air gap,
and
model the acoustic resistance and mass of the back plate slots,
and
model the acoustic resistance and mass of the back plate holes, while the acoustic compliance of the back chamber is represented by
. Moreover,
,
,
, and
model the free-field acoustic impedance. As far as the mechanical domain is concerned,
represents the mass of the diaphragm, whereas
is the mechanical compliance. Regarding the electrical domain,
is the electrical capacitance of the microphone, and
models the input resistance of the Junction gate Field-Effect Transistor (JFET) to which the microphone capsule is usually connected.
The two transformers model the transduction between the physical domains, where
is the diaphragm area and
is the electromechanical transduction factor. Finally, the input signal
is the acoustic pressure acquired by the microphone, while the output signal is the electrical voltage across resistor
.
Table 2 reports the values of all the parameters for modeling both the Brüel & Kjær 4134 (hereafter referred to as BK4134) and the Brüel & Kjær 4146 (hereafter referred to as BK4146) electrostatic microphones [
1,
34,
35].
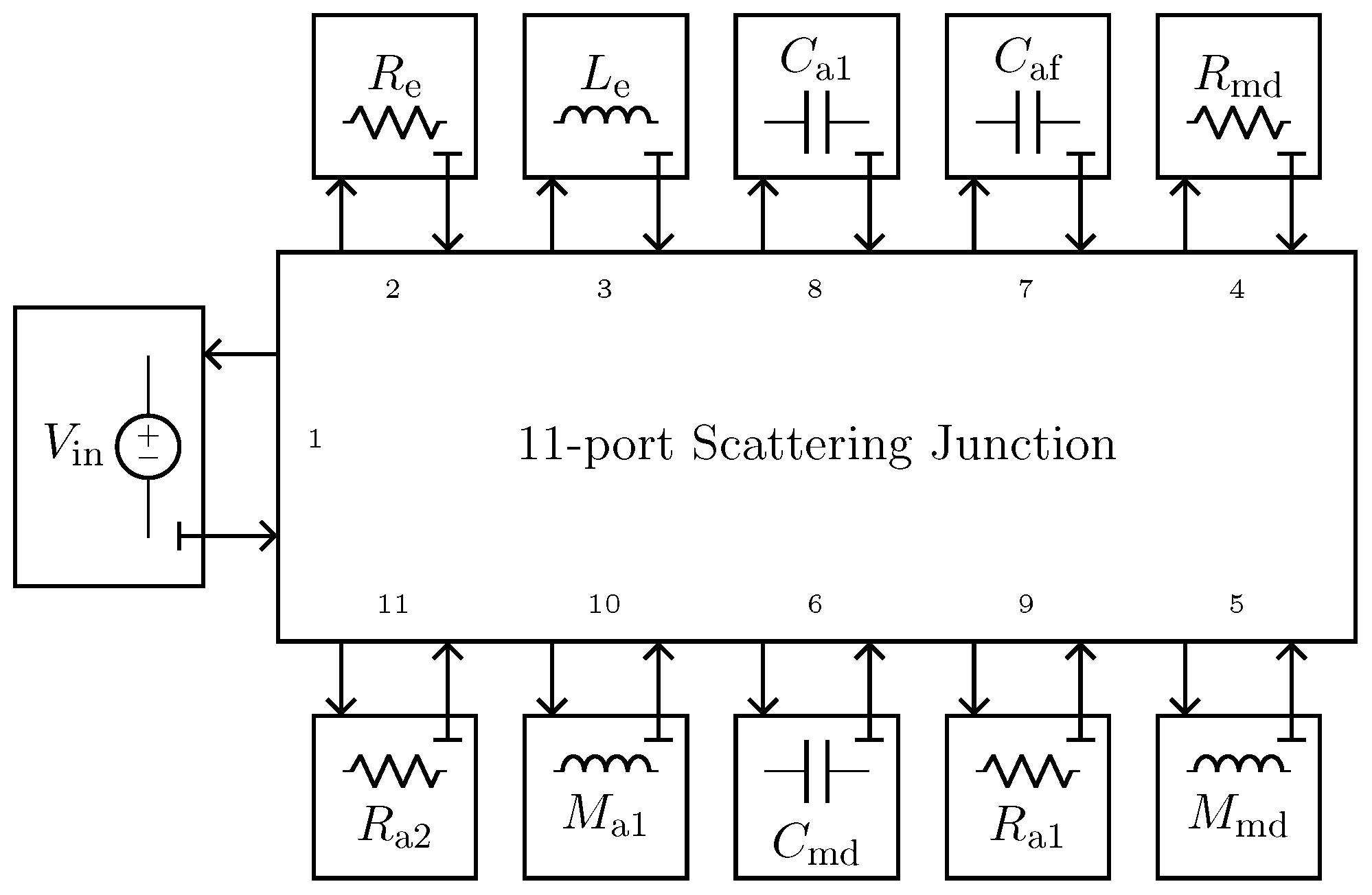
The implementation of the microphone circuital model in the digital domain can be carried out by employing different techniques [
21,
36,
37]. In this work, we use Wave Digital Filters (WDFs) [
21] since they proved to be suitable for an efficient implementation of both direct and inverse models of loudspeakers [
16,
17]. In particular, elements and topological interconnections can be realized as explained in [
24], whereas nullors are encompassed into the scattering junction exploiting the double digraph decomposition of connection networks presented in [
23]. Then, being the circuit linear, the Wave Digital (WD) structure can be solved with no iterative solvers by means of traditional techniques [
21]. A possible WD realization of the circuit in
Figure 10a is shown in
Figure 11.
In order to test the accuracy of the WD implementation, we compare the Discrete Fourier Transform (DFT) of the impulse response obtained by simulating the reference circuit in the WD domain with the DFT of the impulse response obtained by simulating the same circuit in Mathworks Simscape (SSC), for both BK4134 and BK4146 microphones. The curves are then normalized with respect tot the pressure at 1 kHz as it is typically done to describe the microphone sensitivity. The results are shown in
Figure 12 where the overlap between the continuous blue (WD) and the dashed red (SSC) curves confirms the accuracy of the representation. Looking at
Figure 12b, we can appreciate that microphone BK4146 is characterized by a lower resonance frequency with respect to BK4134’s (see
Figure 12b), which is due to a larger diaphragm mounted in the mic capsule.
4.1. Inverse Model Validation
In this subsection, we refer to the digital implementation of the microphone BK4134 equivalent circuit as
Direct System. By applying the theorem presented in
Section 2, it is possible to derive the
Inverse System circuit shown in
Figure 10b. In particular, since we are in a VIVO scenario, in order to design the
Inverse System, once augmented the
Direct System with a parallel connection of a nullator and a norator as explained in
Section 2.2.1, we substitute the norator with a VCVS driven by
and the input source with the norator. The
Inverse System can be implemented in the WD domain in a fully explicit fashion. In order to validate the
Inverse System implementation, we consider the processing chain in
Figure 13 which is composed of the cascade of the
Direct System and the
Inverse System, and we verify that the output of the cascade is equal to the input of the same cascade, i.e.,
.
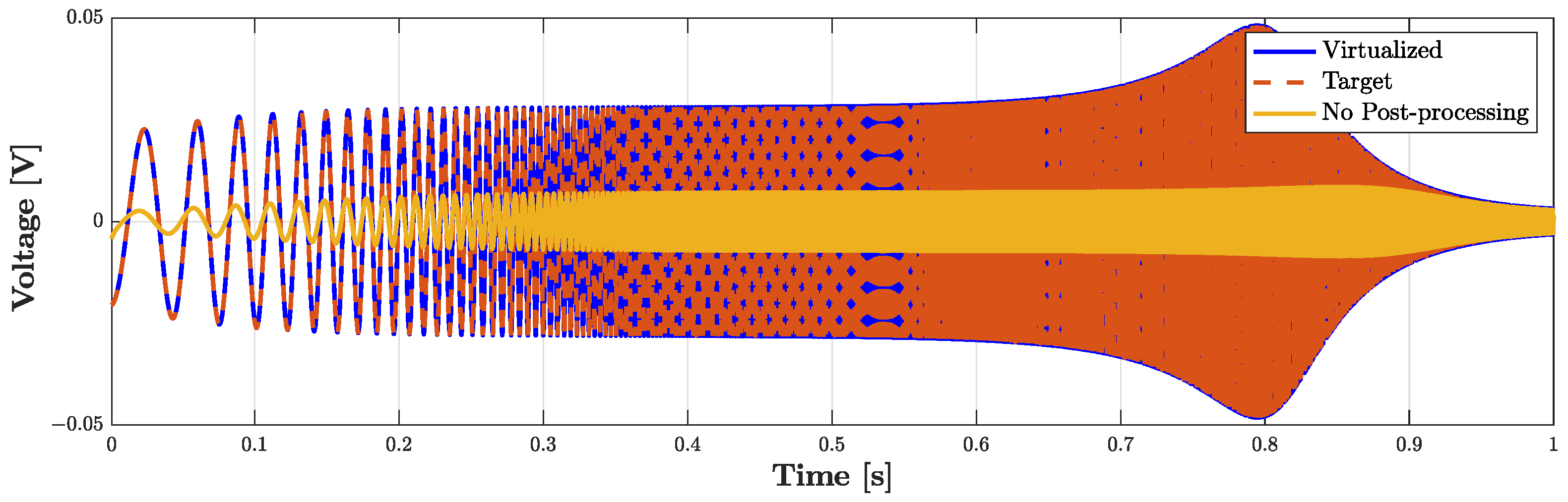
Figure 14 shows the results of such a test. We consider the input signal
of the
Direct System to be an impulse and we compute the response of the microphone, which is shown in
Figure 14a. Then, we feed the BK4134
Inverse System with the obtained voltage signal and we compare the output
with the input
. Looking at
Figure 14b, we can notice that
and
match perfectly since the output of the
Inverse System is indeed an impulse. In order to further remark the accuracy of the
Inverse System implementation, we compute the Root Mean Square Error (RMSE) between the input and output of the processing chain, obtaining a result below the machine precision. Finally, a similar test is carried considering the circuit equivalent parameters of microphone BK4146; even in this case, the RMSE is numerically zero.
4.2. Sensor Virtualization Test
In this subsection, we provide an example of sensor virtualization. In particular, we employ the PITC-based algorithm presented in
Section 3.2 for imposing the acoustic behavior of a target microphone. Let us suppose that the
Physical Direct System is microphone BK4134 and that we would like to obtain a voltage signal
as if it was acquired by the microphone BK4146, i.e., the
Target Direct System. It follows that the
Inverse System is the circuital inverse model of microphone BK4134. The circuit parameters of both BK4134 and BK4146 are, once again, those listed in
Table 2. Direct, inverse, and target systems are implemented in the WD domain as explained in the previous subsections. As input signal, we consider an exponential sine sweep defined as follows
where
kHz is the sampling frequency,
k the sample index, and
, with
Hz as the starting frequency,
kHz as the final frequency, and
s as the total duration of the sweep.
Figure 15 shows the result of such a test. The continuous yellow curve represents the output of the
Physical Direct System when the PITC-based algorithm is not active, the dashed red curve represents the target behavior that we would like to obtain, while the continuous blue curve represents the output of the PITC, i.e., the output of the system when the algorithm is active. The overlap between blue and red curve is perfect given that the RMSE is below machine precision. The algorithm is thus able to impose the response of microphone BK4146 even if the pressure signal is acquired by means of BK4143, being characterized at the same time by real time capabilities. In fact, the algorithm implemented in a MATLAB script is able to process, on average, one sample in
µs, which is lower than
µs. Note that, for these tests, the
Physical Direct System is simulated by means of the WDF shown in
Figure 11, but, in applications of interest, it represents the actual physical transducer. Moreover, the considered WDF is composed of just one topological junction to which all the elements are connected, but other solutions can be obtained. For example, 3-port topological adaptors can be employed when possible in order to create a WDF composed of multiple junctions and reduce the size of scattering matrices.
Finally, we would like to stress the fact that the circuital model shown in
Figure 10a does not take into account the nonlinear behavior introduced by the JFET, which is typically connected to the microphone capsule, since it is not directly involved in the transduction process. It follows that, depending on the application, the electrical subcircuit might be modified by introducing the circuital elements downstream in order to accomplish a proper virtualization.
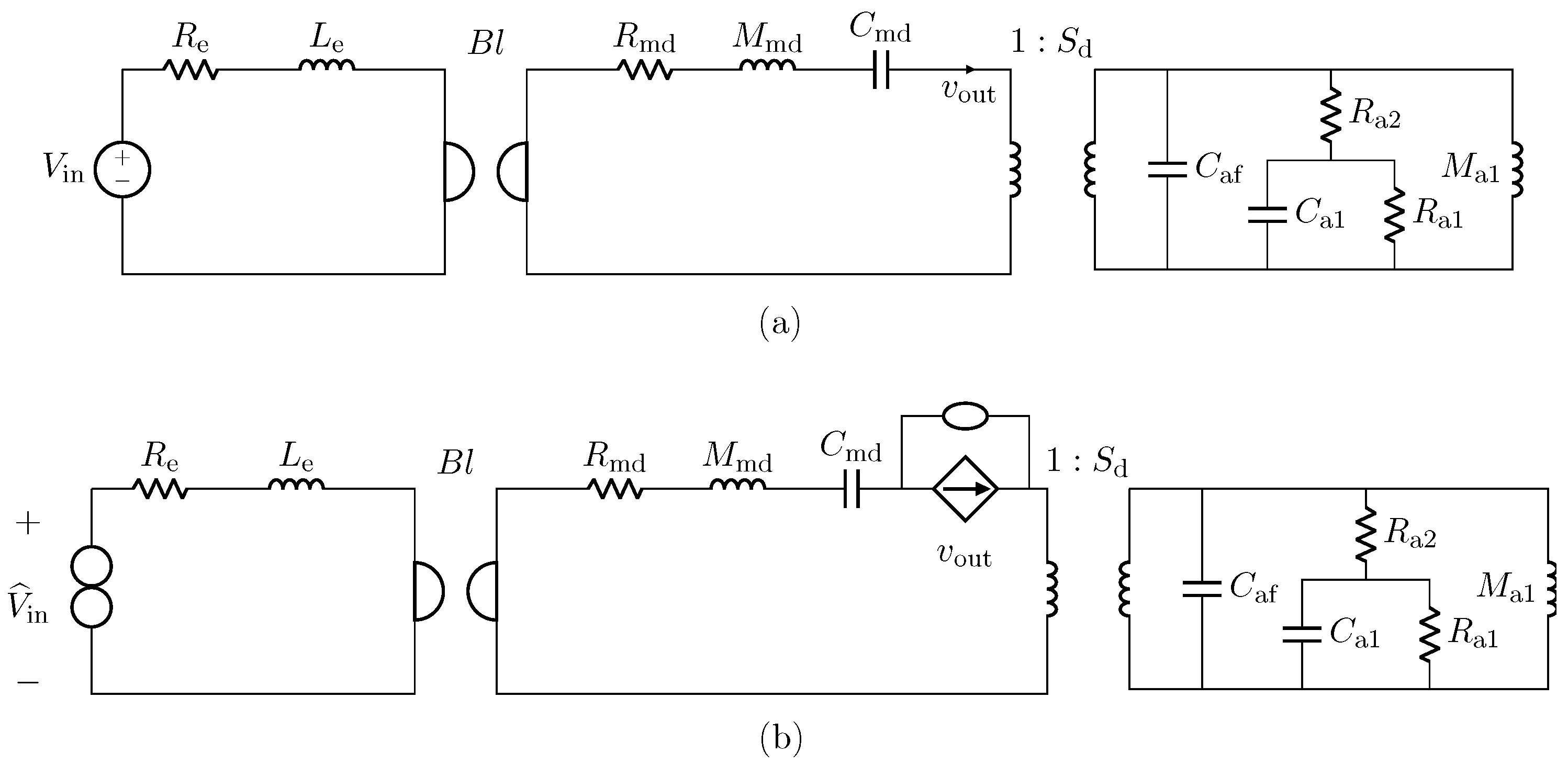
5. Actuator Virtualization: Application to Compression Drivers
We now consider a compression driver as an example of audio actuator. Such a transducer can be described by means of the circuit shown in
Figure 16a adapted from [
1], where we can anew distinguish three subsystems: the leftmost subcircuit modeling the electrical domain, the subcircuit in the middle modeling the mechanical domain, and the rightmost subcircuit modeling the acoustic domain. In particular,
and
are the electrical inductance and resistance of the voice coil, while
,
, and
are mechanical parameters:
models both the mechanical resistance and the resistance of the enclosure;
models the mass, also taking into account the voice coil, and
models both the compliance of the diaphragm and the compliance of the air in the enclosure. Moreover,
is the acoustic compliance of the front cavity. In addition,
,
,
, and
model the free-field acoustic impedance at the driver throat. The gyrator represents the electromechanical transduction and is characterized by a nonlinear force factor
that can be modeled as follows [
38]
where
x is the displacement of the diaphragm in millimeters obtained integrating velocity
, and
are real polynomial coefficients. The ideal transformer, instead, models acoustic transduction as a function of the area of the diaphragm
. The input signal
is the electrical signal driving the loudspeaker, whereas as output signal we select the velocity
, even though other signals can be chosen, e.g., the output pressure.
Table 3 shows the values of the circuital parameters of the SEAS type 27TFF (H0831) compression driver model [
1] (hereafter referred to as SEAS). Notably, the force factor coefficients are determined considering the typical
curve shown in
Figure 17.
We implement the circuital model of the nonlinear compression driver using WDF principles. In particular, we encompass the gyrator into the scattering matrix by considering the method presented in [
22], whereas the nonlinear force factor is modeled in the digital domain as explained in [
16], leading to a fully explicit WDF structure that does not need iterative solvers to be implemented. The used WDF realization of the circuit in
Figure 16a is shown in
Figure 18.
The accuracy of the WDF modeling the Direct System has been validated by means of a comparison with Mathwork Simscape.
5.1. Inverse Model Validation
In this subsection, we validate the designed inverse of the loudspeaker circuital model shown in
Figure 16a. We derive the
Inverse System by applying the theorem presented in
Section 2 and considering the VICO case. We do this by first augmenting the
Direct System with a connection of a nullator and a norator in series to the same branch through which the output current flows as explained in
Section 2.2.2; then, we substitute the norator with a CCCS driven by
and the input source with the norator. We finally implement the
Inverse System in the WD domain in a fully explicit fashion, similarly to what done with the
Direct System. In order to encompass both the nullor and the gyrator into the WD multi-port scattering junction, we employ again the method presented in [
22].
With the purpose of validating the WD implementation, we consider a processing chain similar to that shown in
Figure 13, where now the
Direct System is driven by voltage
and the
Inverse System by the velocity signal
, which, in turn, is the output current of the
Direct System. If the implementation of the
Inverse System is exact, we obtain
.
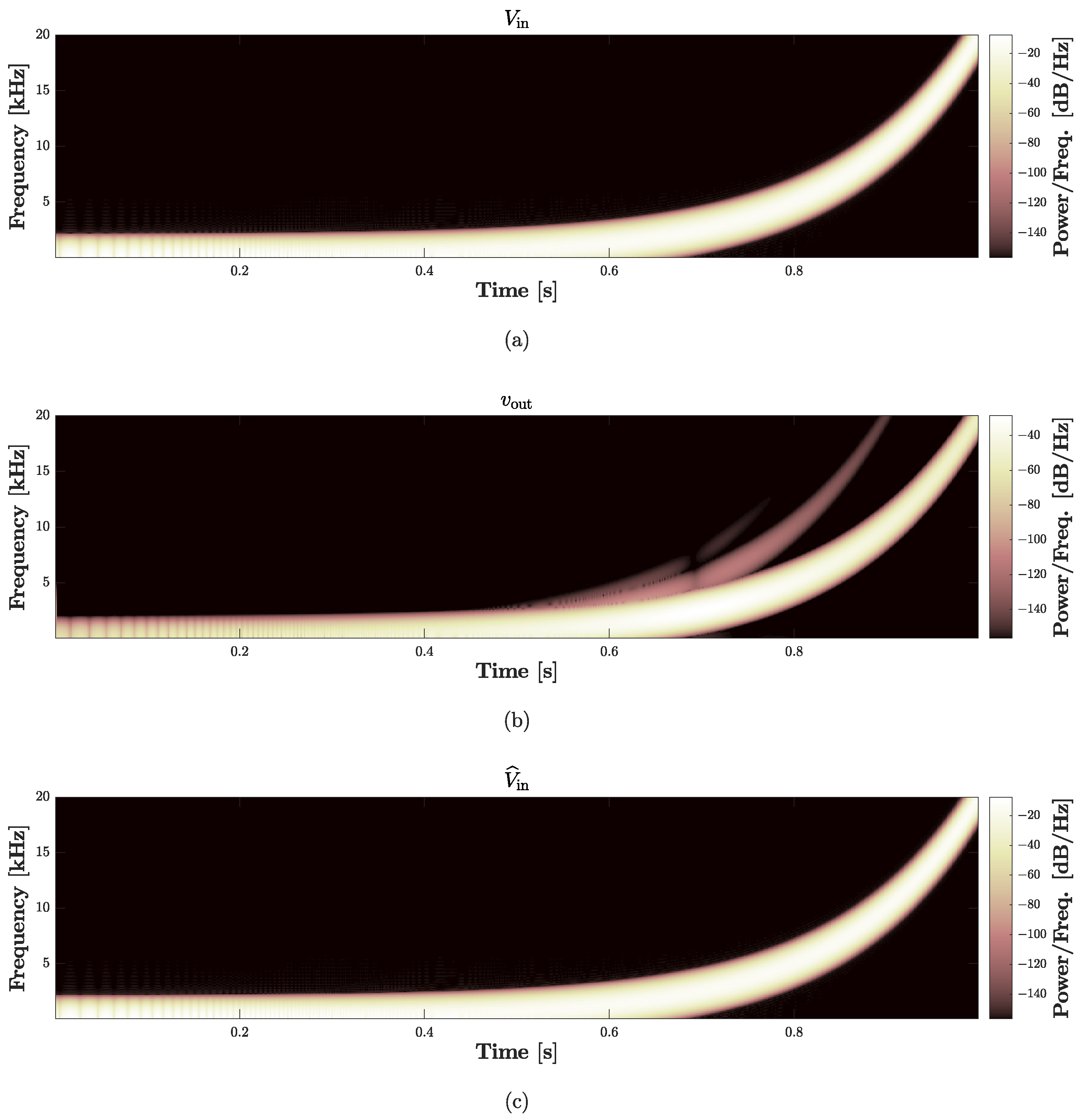
Figure 19 and
Figure 20 show the results of such a test, the first in the time domain, while the second in the frequency domain. In particular, we consider as input signal of the cascade of
Direct System and
Inverse System the following exponential sine sweep
where
V is the amplitude, while all the other parameters are set as in
Section 4.2.
Figure 19 shows the signals obtained in the first
s of simulation: the dashed red curve represents the input of the
Direct System, i.e.,
, and is perfectly overlapped with the continuous blue curve which represents the output of the
Inverse System, i.e.,
. To further analyze the performance of the
Inverse System, in
Figure 20 we also provide the spectrograms of the three signals involved in the validation chain. In particular,
Figure 20a shows the spectrogram of
,
Figure 20b the spectrogram of
, while
Figure 20c the spectrogram of
. In the second plot, we can appreciate the nonlinear behavior of the loudspeaker circuital model since different harmonics appear over the frequency spectrum. Looking at the third plot, instead, we can further verify the action of the
Inverse System since the harmonics characterizing
(i.e., the input of the
Inverse System) nicely disappear, leading to a perfect match between
and
. Finally, both for time- and frequency-domain studies, we compute the RMSE between
and
obtaining, once again, values below machine precision.
5.2. Actuator Linearization Test
In a last application scenario, we show how the transducer linearization task can be accomplished as a particular case of the proposed virtualization algorithms. We aim, in fact, at eliminating the distortion effect introduced by the nonlinear behavior of the loudspeaker SEAS. In order to reach this goal, we employ the TIPC-based algorithm presented in
Section 3.1 to impose the acoustic response of a target loudspeaker. In this application scenario, the
Target Direct System is the linear version of the circuit shown in
Figure 16a, which can be obtained by simply setting
[
16]. The parameters listed in
Table 3 are again used for the WD implementations of the
Target Direct System, the
Inverse System, and the
Physical Direct System. Contrary to what done in the microphone case, the desired behavior is imposed at the beginning of the processing chain since the physical transducer is an actuator. In order to test the chain, we set the input
, where
A is the amplitude,
k is the sample index,
Hz is the fundamental frequency, and
kHz is the sampling frequency. Moreover, in order to test the nonlinear system in different operating conditions, we consider two different amplitudes.
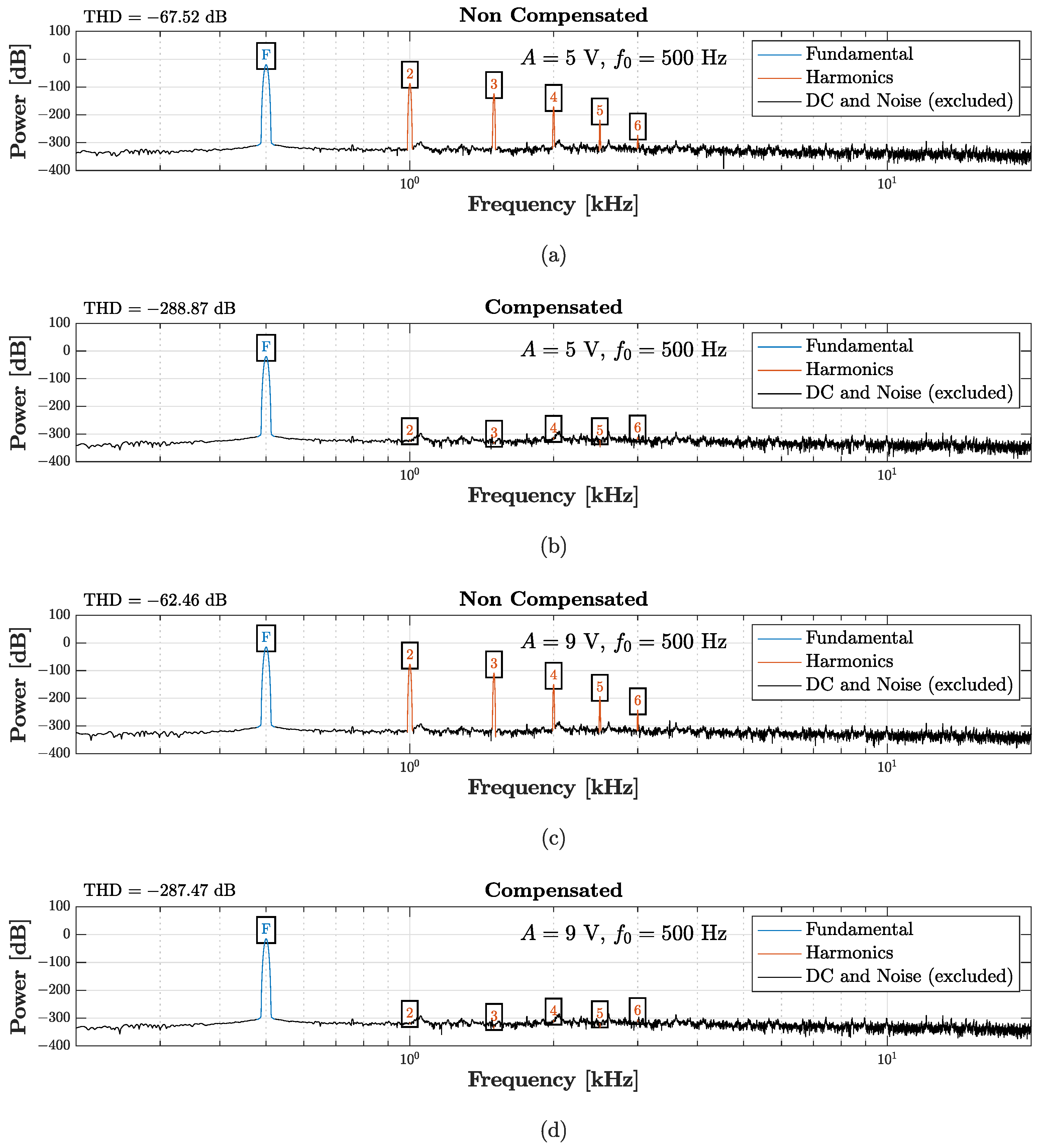
Figure 21 shows the results of such a test. In particular, the figure shows the power spectra of the
Direct System output (“Non Compensated”) and of the TIPC output (“Compensated”), together with the values of THD.
Figure 21a,b are obtained by setting
V, whereas
Figure 21c,d are obtained by setting
V. In both cases, the TIPC-based algorithm is able to suppress the harmonics introduced by the nonlinearity affecting the compression driver, while maintaining the content at the fundamental frequency
. This can be quantified looking at the THD reduction, which for both the tests is over 220 dB. As far as efficiency is concerned, instead, the algorithm, implemented in a MATLAB script, is able to run in real-time, processing on average one sample in
µs. Note that, even in this case, the
Physical Target System is simulated but, in real scenarios, it represents the actual physical transducer.
The TIPC-based algorithm can be thus promising for improving the acoustic response of the loudspeaker on the fly by pre-processing the electrical signal driving the loudspeaker itself. Finally, it is worth stressing that the tested virtualization algorithm can be exploited not only to accomplish linearization but also to impose a desired nonlinear behavior, similarly to what already shown in [
17].
6. Conclusions
In this paper, we described a general approach for the virtualization of audio transducers applicable to both sensors, like microphones, and actuators, like loudspeakers. We defined virtualization as the task of altering the acquired/reproduced signal by making it sound as if acquired/reproduced by another ideal or real audio sensor/actuator. In order to accomplish such a task, we started by reformulating Leuciuc’s theorem and proof for circuit inversion, providing case-specific guidelines on how to derive the inverse circuital model for all combinations of input and output variables. In particular, circuital inversion is achieved by augmenting the
Direct System with a theoretical two-port called nullor, exploiting nullor equivalent models of short and open circuits [
30]. We then presented two versions of the Direct–Inverse–Direct Chain which allow us to address virtualization for both sensors (Physical-Inverse-Target Chain) and actuators (Target-Inverse-Physical Chain). The chains are composed of three blocks: a
Physical Direct System, which is the responsible for the actual transduction process, an
Inverse System, which is the circuital inverse of the
Physical Direct System, and a
Target Direct System, which is the transducer characterized by the behavior that we would like to obtain. We exploited WDF principles to implement the digital blocks of such processing chains in a fully explicit fashion, i.e., without resorting to iterative solvers. Finally, we tested both the PITC-based and the TIPC-based algorithms for addressing microphone virtualization and linearization of a loudspeaker system with nonlinear compression driver.
Future work may concern first the extension of circuital inversion theory to the Multiple Input Multiple Output (MIMO) case, and then, by exploiting this new theory, the development of refined DIDC-based algorithms for addressing the case of array virtualization, both in sensing and actuation scenarios.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







