



FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas

 , ,
, ,  , ,
, ,  , ,
, ,  and
and
Abstract
:1. Introduction
- We designed a novel FMDNet model based on deep learning for the detection of face masks.
- We designed and developed a face mask recognition system based on computer vision for real-time deployment.
- Our system achieved the best accuracy compared to existing techniques.
- Our system easily found those people who were not wearing a mask in a gathering place.
2. Materials and Methods
2.1. Datasets
2.1.1. Pins Face Recognition Dataset
2.1.2. Omkargurav Face-Mask Dataset
2.1.3. Labelled Faces in the Wild Dataset
2.1.4. Real-World-Masked-Face-Dataset
2.1.5. YOLO-Medical-Mask-Dataset
2.2. Data Augmentation
2.3. Proposed Model
- A kernel size of 3 × 3 was used for the spatial convolutions.
- The total number of parameters was 2,619,074, out of which 2,584,962 were trainable parameters and 34,112 were non-trainable parameters.
- The network was trained on an NVIDIA-SMI 455.32.00, with 32 as the batch size.
3. Results and Discussion
3.1. Experimental Environment
3.2. Confidence and Frames Per Second
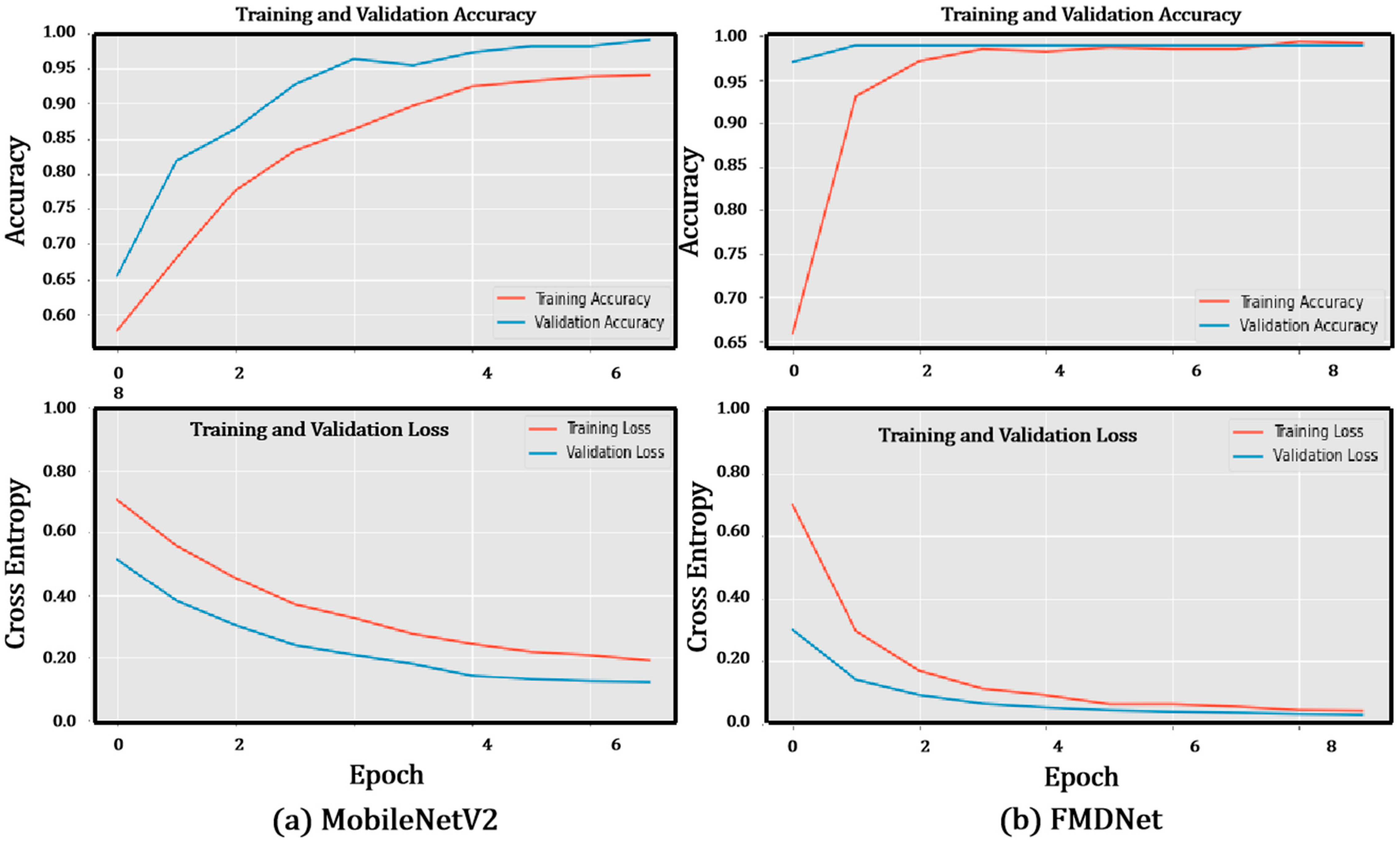
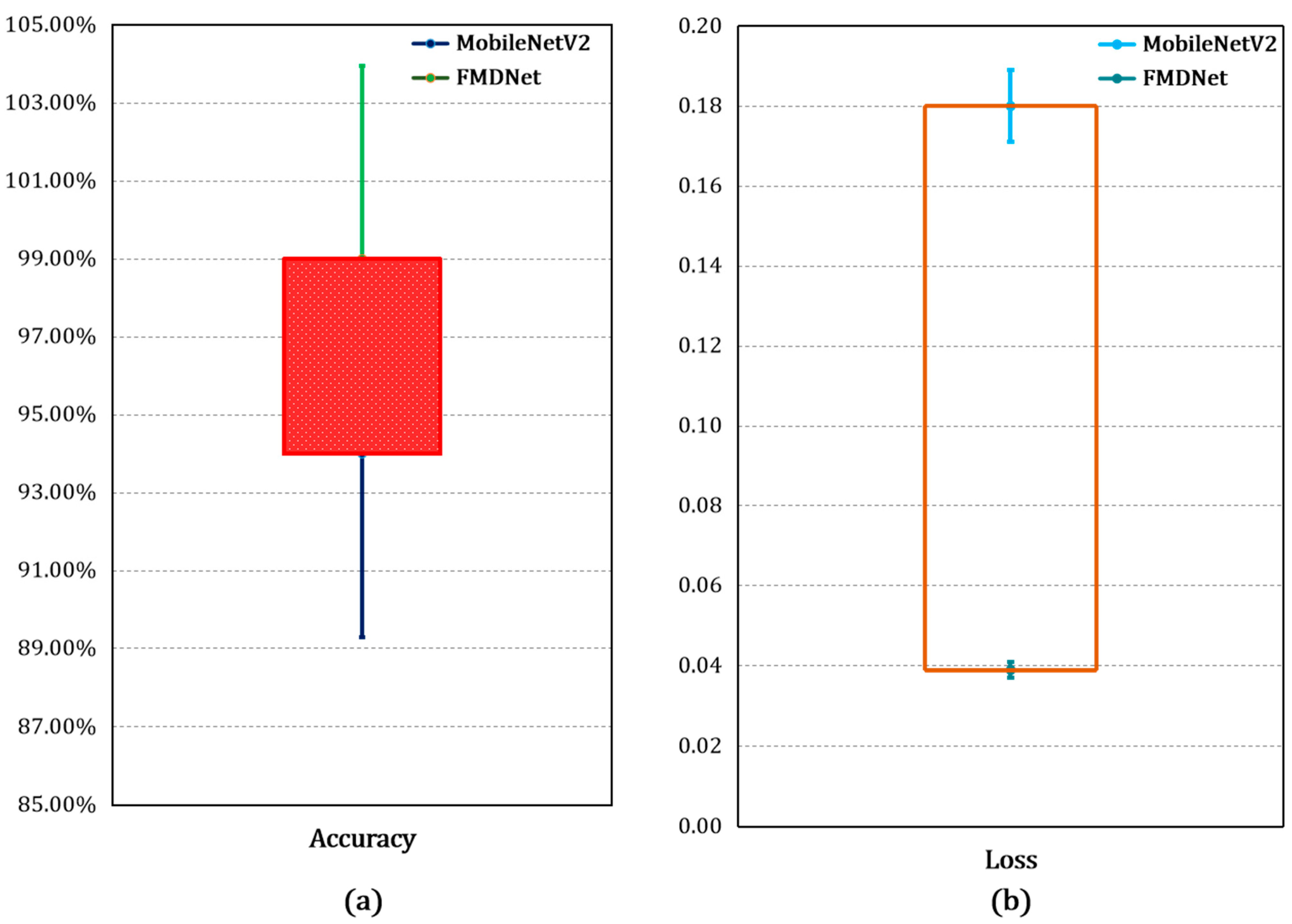
3.3. Comparison between MobileNetV2 and FMDNet Models
3.4. Comparison of Proposed and Existing Models
3.5. Limitations and Future Recommendations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fauci, A.S.; Lane, H.C.; Redfield, R.R. COVID-19—Navigating the Uncharted. N. Engl. J. Med. 2020, 382, 1268–1269. [Google Scholar] [CrossRef] [PubMed]
- Kuitunen, I.; Artama, M.; Mäkelä, L.; Backman, K.; Heiskanen-Kosma, T.; Renko, M. Effect of Social Distancing Due to the COVID-19 Pandemic on the Incidence of Viral Respiratory Tract Infections in Children in Finland during Early 2020. Pediatr. Infect. Dis. J. 2020, 39, E423–E427. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Shen, C.; Xia, N.; Song, W.; Fan, M.; Cowling, B.J. Rational Use of Face Masks in the COVID-19 Pandemic. Lancet Respir. Med. 2020, 8, 434–436. [Google Scholar] [CrossRef] [PubMed]
- Leung, N.H.L.; Chu, D.K.W.; Shiu, E.Y.C.; Chan, K.H.; McDevitt, J.J.; Hau, B.J.P.; Yen, H.L.; Li, Y.; Ip, D.K.M.; Peiris, J.S.M.; et al. Respiratory Virus Shedding in Exhaled Breath and Efficacy of Face Masks. Nat. Med. 2020, 26, 676–680. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Liu, Y.; Li, M.; Qian, X.; Dai, S.Y. Mask or No Mask for COVID-19: A Public Health and Market Study. PLoS ONE 2020, 15, e0237691. [Google Scholar] [CrossRef]
- Mamalet, F.; Farrugia, N.; Roux, S.; Yang, F.; Paindavoine, M. Design of a Real-Time Face Detection Parallel Architecture Using High-Level Synthesis. EURASIP J. Embed. Syst. 2008, 2008, 938256. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Zhang, S. COVID-19: Face Masks and Human-to-Human Transmission. Influenza Other Respi. Viruses 2020, 14, 472–473. [Google Scholar] [CrossRef]
- World Health Organization (WHO). WHO Coronavirus Disease (COVID-19) Dashboard|WHO Coronavirus Disease (COVID-19) Dashboard; Who.int 202AD; WHO: Geneva, Switzerland, 2020. [Google Scholar]
- Loey, M.; Smarandache, F.; Khalifa, N.E.M. Within the Lack of Chest COVID-19 X-ray Dataset: A Novel Detection Model Based on GAN and Deep Transfer Learning. Symmetry 2020, 12, 651. [Google Scholar] [CrossRef] [Green Version]
- Ting, D.S.W.; Carin, L.; Dzau, V.; Wong, T.Y. Digital Technology and COVID-19. Nat. Med. 2020, 26, 459–461. [Google Scholar] [CrossRef] [Green Version]
- Altmann, D.M.; Douek, D.C.; Boyton, R.J. What Policy Makers Need to Know about COVID-19 Protective Immunity. Lancet 2020, 395, 1527–1529. [Google Scholar] [CrossRef]
- Fouquet, H. Paris Tests Face-Mask Recognition Software on Metro Riders. Available online: https://www.bloomberg.com/news/articles/2020-05-07/paris-tests-face-mask-recognition-software-on-metro-riders%0Ahttps://www.bloomberg.com/news/articles/2020-05-07/paris-tests-face-mask-recognition-software-on-metro-riders?sref=C3P1bRLC (accessed on 20 December 2022).
- Xu, J.; Dou, Y.; Pang, Z. A Reconfigurable Architecture for Rotation Invariant Multi-View Face Detection Based on a Novel Two-Stage Boosting Method. EURASIP J. Adv. Signal Process. 2009, 2009, 917354. [Google Scholar] [CrossRef] [Green Version]
- Zuo, F.; de With, P.H.N. Cascaded Face Detection Using Neural Network Ensembles. EURASIP J. Adv. Signal Process. 2007, 2008, 736508. [Google Scholar] [CrossRef] [Green Version]
- Hong, S.H.; Lee, J.W.; Lama, R.K.; Kwon, G.R. Real-Time Face Detection and Phone-to-Face Distance Measuring for Speech Recognition for Multi-Modal Interface in Mobile Device. Multimed. Tools Appl. 2016, 75, 6717–6735. [Google Scholar] [CrossRef]
- Sun, X.; Wu, P.; Hoi, S.C.H. Face Detection Using Deep Learning: An Improved Faster RCNN Approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.; Cao, D.; Gao, L. Face Detection Based on Occlusion Area Detection and Recovery. Multimed. Tools Appl. 2020, 79, 16531–16546. [Google Scholar] [CrossRef]
- Soundararajan, R.; Biswas, S. Machine Vision Quality Assessment for Robust Face Detection. Signal Process. Image Commun. 2019, 72, 92–104. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, X.; Hoi, S.C.H.; Zhu, J. Feature Agglomeration Networks for Single Stage Face Detection. Neurocomputing 2020, 380, 180–189. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Yan, Y.; Zheng, J.; Li, B. A Fast Face Detection Method via Convolutional Neural Network. Neurocomputing 2020, 395, 128–137. [Google Scholar] [CrossRef] [Green Version]
- Sen, S.; Sawant, K. Face Mask Detection for Covid_19 Pandemic Using Pytorch in Deep Learning. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1070, 012061. [Google Scholar] [CrossRef]
- Rahman, M.M.; Manik, M.M.H.; Islam, M.M.; Mahmud, S.; Kim, J.H. An Automated System to Limit COVID-19 Using Facial Mask Detection in Smart City Network. In Proceedings of the IEMTRONICS 2020—International IOT, Electronics and Mechatronics Conference, Vancouver, BC, Canada, 9–12 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Khandelwal, P.; Khandelwal, A.; Agarwal, S.; Thomas, D.; Xavier, N.; Raghuraman, A. Using Computer Vision to Enhance Safety of Workforce in Manufacturing in a Post COVID World. arXiv 2020, arXiv:2005.05287. [Google Scholar]
- Qin, B.; Li, D. Identifying Facemask-Wearing Condition Using Image Super-Resolution with Classification Network to Prevent COVID-19. Sensors 2020, 20, 5236. [Google Scholar] [CrossRef] [PubMed]
- Fan, X.; Jiang, M. RetinaFaceMask: A Single Stage Face Mask Detector for Assisting Control of the COVID-19 Pandemic. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Man, Melbourne, Australia, 17–20 October 2021; pp. 832–837. [Google Scholar] [CrossRef]
- Li, S.; Ning, X.; Yu, L.; Zhang, L.; Dong, X.; Shi, Y.; He, W. Multi-Angle Head Pose Classification When Wearing the Mask for Face Recognition under the COVID-19 Coronavirus Epidemic. In Proceedings of the 2020 International Conference on High Performance Big Data and Intelligent Systems, HPBD and IS 2020, Shenzhen, China, 23 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Matthias, D.; Managwu, C.; Olumide, O. Face Mask Detection Application and Dataset. J. Comput. Sci. Its Appl. 2021, 27. [Google Scholar] [CrossRef]
- Yang, T.Y.; Chen, Y.T.; Lin, Y.Y.; Chuang, Y.Y. Fsa-Net: Learning Fine-Grained Structure Aggregation for Head Pose Estimation from a Single Image. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1087–1096. [Google Scholar]
- Inamdar, M.; Mehendale, N. Real-Time Face Mask Identification Using Facemasknet Deep Learning Network. SSRN Electron. J. 2020, 3663305. [Google Scholar] [CrossRef]
- Ristea, N.C.; Ionescu, R.T. Are You Wearing a Mask? Improving Mask Detection from Speech Using Augmentation by Cycle-Consistent GANs. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2020, Shanghai, China, 25–29 October 2020; pp. 2102–2106. [Google Scholar]
- Sethi, S.; Kathuria, M.; Kaushik, T. Face Mask Detection Using Deep Learning: An Approach to Reduce Risk of Coronavirus Spread. J. Biomed. Inform. 2021, 120, 103848. [Google Scholar] [CrossRef]
- Gupta, P.; Sharma, V.; Varma, S. A Novel Algorithm for Mask Detection and Recognizing Actions of Human. Expert Syst. Appl. 2022, 198, 116823. [Google Scholar] [CrossRef]
- Ullah, N.; Javed, A.; Ali Ghazanfar, M.; Alsufyani, A.; Bourouis, S. A Novel DeepMaskNet Model for Face Mask Detection and Masked Facial Recognition. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 9905–9914. [Google Scholar] [CrossRef]
- Teboulbi, S.; Messaoud, S.; Hajjaji, M.A.; Mtibaa, A. Real-Time Implementation of AI-Based Face Mask Detection and Social Distancing Measuring System for COVID-19 Prevention. Sci. Program. 2022, 2022, 8340779. [Google Scholar] [CrossRef]
- Goyal, H.; Sidana, K.; Singh, C.; Jain, A.; Jindal, S. A Real Time Face Mask Detection System Using Convolutional Neural Network. Multimed. Tools Appl. 2022, 81, 14999–15015. [Google Scholar] [CrossRef]
- Mestetskiy, L.M.; Guru, D.S.; Benifa, J.V.B.; Nagendraswamy, H.S.; Chola, C. Gender Identification of Drosophila Melanogaster Based on Morphological Analysis of Microscopic Images. Vis. Comput. 2022, 39, 1815–1827. [Google Scholar] [CrossRef]
- Chola, C.; Benifa, J.V.B.; Guru, D.S.; Muaad, A.Y.; Hanumanthappa, J.; Al-Antari, M.A.; AlSalman, H.; Gumaei, A.H. Gender Identification and Classification of Drosophila Melanogaster Flies Using Machine Learning Techniques. Comput. Math. Methods Med. 2022, 2022, 4593330. [Google Scholar] [CrossRef]
- Burak Pins Face Recognition. Available online: https://www.kaggle.com/datasets/hereisburak/pins-face-recognition/metadata%0Ahttps://www.kaggle.com/hereisburak/pins-face-recog (accessed on 1 October 2022).
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Pal, R.; Adhikari, D.; Bin Heyat, B.; Ullah, I.; You, Z. Yoga Meets Intelligent Internet of Things: Recent Challenges and Future Directions. Bioengineering 2023, 10, 459. [Google Scholar] [CrossRef]
- Bin Heyat, B.; Akhtar, F.; Abbas, S.J.; Al-Sarem, M.; Alqarafi, A.; Stalin, A.; Abbasi, R.; Muaad, A.Y.; Lai, D.; Wu, K. Wearable Flexible Electronics Based Cardiac Electrode for Researcher Mental Stress Detection System Using Machine Learning Models on Single Lead Electrocardiogram Signal. Biosensors 2022, 12, 427. [Google Scholar] [CrossRef]
- Bin Heyat, B.; Akhtar, F.; Khan, A.; Noor, A.; Benjdira, B.; Qamar, Y.; Abbas, S.J.; Lai, D. A Novel Hybrid Machine Learning Classification for the Detection of Bruxism Patients Using Physiological Signals. Appl. Sci. 2020, 10, 7410. [Google Scholar] [CrossRef]
- Qadri, S.F.; Lin, H.; Shen, L.; Ahmad, M.; Qadri, S.; Khan, S.; Khan, M.; Zareen, S.S.; Akbar, M.A.; Bin Heyat, M.B.; et al. CT-Based Automatic Spine Segmentation Using Patch-Based Deep Learning. Int. J. Intell. Syst. 2023, 2023, 2345835. [Google Scholar] [CrossRef]
- Alphonse, A.S.; Benifa, J.V.B.; Muaad, A.Y.; Chola, C.; Bin Heyat, B.; Murshed, B.A.H.; Samee, N.A.; Alabdulhafith, M.; Al-Antari, M.A. A Hybrid Stacked Restricted Boltzmann Machine with Sobel Directional Patterns for Melanoma Prediction in Colored Skin Images. Diagnostics 2023, 13, 1104. [Google Scholar] [CrossRef] [PubMed]
- Lai, D.; Bin Heyat, B.; Khan, F.I.; Zhang, Y. Prognosis of Sleep Bruxism Using Power Spectral Density Approach Applied on EEG Signal of Both EMG1-EMG2 and ECG1-ECG2 Channels. IEEE Access 2019, 7, 82553–82562. [Google Scholar] [CrossRef]
- Bin Heyat, B.; Lai, D.; Khan, F.I.; Zhang, Y. Sleep Bruxism Detection Using Decision Tree Method by the Combination of C4-P4 and C4-A1 Channels of Scalp EEG. IEEE Access 2019, 7, 102542–102553. [Google Scholar] [CrossRef]
- Bin Heyat, B.; Lai, D.; Wu, K.; Akhtar, F.; Sultana, A.; Tumrani, S.; Teelhawod, B.N.; Abbasi, R.; Kamal, M.A.; Muaad, A.Y. Role of Oxidative Stress and Inflammation in Insomnia Sleep Disorder and Cardiovascular Diseases: Herbal Antioxidants and Anti-Inflammatory Coupled with Insomnia Detection Using Machine Learning. Curr. Pharm. Des. 2022, 28, 3618–3636. [Google Scholar] [CrossRef]
- Sultana, A.; Rahman, K.; Bin Heyat, B.; Sumbul, U.; Akhtar, F.; Muaad, A.Y. Role of Inflammation, Oxidative Stress, and Mitochondrial Changes in Premenstrual Psychosomatic Behavioral Symptoms with Anti-Inflammatory, Antioxidant Herbs, and Nutritional Supplements. Oxid. Med. Cell. Longev. 2022, 2022, 3599246. [Google Scholar] [CrossRef]
- Qayyum, S.; Sultana, A.; Bin Heyat, B.; Rahman, K.; Akhtar, F.; Haq, A.U.; Alkhamis, B.A.; Alqahtani, M.A.; Gahtani, R.M. Therapeutic Efficacy of a Formulation Prepared with Linum usitatissimum L., Plantago ovata Forssk., and Honey on Uncomplicated Pelvic Inflammatory Disease Analyzed with Machine Learning Techniques. Pharmaceutics 2023, 15, 643. [Google Scholar] [CrossRef]
- Teelhawod, B.N.; Akhtar, F.; Heyat, M.B.B.; Tripathi, P.; Mehrotra, R.; Asfaw, A.B.; Al Shorman, O.; Masadeh, M. Machine Learning in E-Health: A Comprehensive Survey of Anxiety. In Proceedings of the 2021 International Conference on Data Analytics for Business and Industry, ICDABI 2021, Virtually, 25–26 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 167–172. [Google Scholar]
- Akhtar, F.; Bin Heyat, M.B.; Li, J.P.; Patel, P.K.; Rishipal; Guragai, B. Role of Machine Learning in Human Stress: A Review. In Proceedings of the 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing, ICCWAMTIP 2020, Chengdu, China, 18–20 December 2020; 20 December 2020. [Google Scholar]
- Tripathi, P.; Ansari, M.A.; Gandhi, T.K.; Mehrotra, R.; Bin Heyat, B.; Akhtar, F.; Ukwuoma, C.C.; Muaad, A.Y.; Kadah, Y.M.; Al-Antari, M.A.; et al. Ensemble Computational Intelligent for Insomnia Sleep Stage Detection via the Sleep ECG Signal. IEEE Access 2022, 10, 108710–108721. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class Type | No. of Images | Train | Test |
|---|---|---|---|---|
| 1 | With mask | 600 | 300 | 300 |
| 2 | Without mask | 600 | 300 | 300 |
| Total | 1200 | 600 | 600 | |
| Input | Operator | Expansion Factor | No. of Output Channels | Repeating No. | Stride Size |
|---|---|---|---|---|---|
| 224 × 224 × 3 | Conv2d | - | 32 | 1 | 2 |
| 112 ×112 × 32 | Bn | 1 | 16 | 1 | 1 |
| 1122 × 16 | Bn | 6 | 24 | 2 | 2 |
| 562 × 24 | Bn | 6 | 32 | 3 | 2 |
| 282 × 32 | Bn | 6 | 64 | 4 | 2 |
| 142 × 64 | Bn | 6 | 96 | 3 | 1 |
| 142 × 96 | Bn | 6 | 160 | 3 | 2 |
| 72 × 160 | Bn | 6 | 320 | 1 | 2 |
| 72 × 320 | Conv2d 1 × 1 | - | 1280 | 1 | 1 |
| 72 × 1280 | Avgpool 7 × 7 | - | - | 1 | 1 |
| 1 × 1 × 1280 | Conv2d 1 × 1 | - | K | - | - |
| Layer | Input Dimensions | Output Channels |
|---|---|---|
| Conv2d | 224 × 224 × 3 | 32 |
| Bn | 112 × 112 × 32 | 16 |
| Bn | 112 × 112 × 16 | 24 |
| Bn | 56 × 56 × 24 | 32 |
| Bn | 28 × 28 × 32 | 64 |
| Bn | 14 × 14 × 64 | 96 |
| Bn | 14 × 14 × 96 | 160 |
| Bn | 7 × 7 × 160 | 320 |
| Conv2d | 7 × 7 × 320 | 1280 |
| Avgpool | 7 × 7 × 1280 | 1280 |
| Flatten | 1 × 1 × 1280 | - |
| Dense 1 | 1280 | 256 |
| Dense 2 | 256 | 128 |
| Dense 3 | 128 | 2 |
| Dataset | Dataset No. | Mask/No Mask | Confidence | FPS |
|---|---|---|---|---|
| Pins Face Recognition Dataset | Dataset-1 | No Mask | 99.99 | 41.7268 |
| Mask | 98.59 | 41.9384 | ||
| Omkargurav Face-Mask Dataset | Dataset-2 | No Mask | 99.98 | 41.8548 |
| Mask | 98.91 | 41.6729 | ||
| Labelled Faces in the Wild (LFW) Dataset | Dataset-3 | No Mask | 99.95 | 41.9521 |
| Mask | 98.96 | 41.7603 | ||
| Real-World-Masked-Face-Dataset | Dataset-4 | No Mask | 99.92 | 41.8171 |
| Mask | 98.94 | 41.9513 | ||
| YOLO-Medical-mask-Dataset | Dataset-5 | No Mask | 99.99 | 41.8607 |
| Mask | 98.91 | 41.6713 |
| No. | Model | Information | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|---|
| 1 | MobileNetV2 | With mask | 1.00 | 0.87 | 0.93 | 0.94 |
| Without mask | 0.89 | 1.00 | 0.94 | 0.93 | ||
| 2 | FMDNet | With mask | 0.99 | 0.98 | 0.99 | 0.99 |
| Without mask | 0.98 | 0.99 | 0.99 | 0.99 |
| Author | Year | Model | Performance |
|---|---|---|---|
| [21] | 2020 | Deep learning framework | Accuracy: 79.24% |
| [22] | 2020 | Deep learning framework | Accuracy: 98.70% |
| [23] | 2020 | Deep learning and classic projective geometry techniques | AUC: 97.6%, precision: 97.00%, recall: 97.00% |
| [24] | 2020 | Deep-Learning-based SRCNet | Accuracy: 98.70% |
| [26] | 2020 | HGL to deal with the head pose classification with CNN | Front accuracy: 93.64%, side accuracy: 87.17% |
| [29] | 2020 | Deep learning method called FaceMaskNet | Accuracy: 98.6% |
| [30] | 2020 | Generative adversarial networks (GANs) and support vector machines (SVMs) classifier | Mask sub-challenge: 74.6% |
| [31] | 2021 | ResNet50, AlexNet, and MobileNet | Accuracy: 98.2% |
| [32] | 2022 | Expanded mask R-CNN | mAP: 80.25 |
| [34] | 2022 | Deep MaskNet framework-MDMFR | Accuracy: 93.33 |
| [35] | 2022 | CNN architecture | Accuracy: 98% |
| Proposed Model | FMDNet | Accuracy: 99% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benifa, J.V.B.; Chola, C.; Muaad, A.Y.; Hayat, M.A.B.; Bin Heyat, M.B.; Mehrotra, R.; Akhtar, F.; Hussein, H.S.; Vargas, D.L.R.; Castilla, Á.K.; et al. FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas. Sensors 2023, 23, 6090. https://doi.org/10.3390/s23136090
Benifa JVB, Chola C, Muaad AY, Hayat MAB, Bin Heyat MB, Mehrotra R, Akhtar F, Hussein HS, Vargas DLR, Castilla ÁK, et al. FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas. Sensors. 2023; 23(13):6090. https://doi.org/10.3390/s23136090
Chicago/Turabian StyleBenifa, J. V. Bibal, Channabasava Chola, Abdullah Y. Muaad, Mohd Ammar Bin Hayat, Md Belal Bin Heyat, Rajat Mehrotra, Faijan Akhtar, Hany S. Hussein, Debora Libertad Ramírez Vargas, Ángel Kuc Castilla, and et al. 2023. "FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas" Sensors 23, no. 13: 6090. https://doi.org/10.3390/s23136090
APA StyleBenifa, J. V. B., Chola, C., Muaad, A. Y., Hayat, M. A. B., Bin Heyat, M. B., Mehrotra, R., Akhtar, F., Hussein, H. S., Vargas, D. L. R., Castilla, Á. K., Díez, I. d. l. T., & Khan, S. (2023). FMDNet: An Efficient System for Face Mask Detection Based on Lightweight Model during COVID-19 Pandemic in Public Areas. Sensors, 23(13), 6090. https://doi.org/10.3390/s23136090