1. Introduction
The Bayesian estimation of the state of high dimensional systems is a relevant topic in diverse research and application areas. When a Gaussian estimator is applied in an optimal way, the full covariance matrix needs to be maintained during the estimation process; for that, the numerical format commonly used for representing the elements of the covariance matrix is the double precision floating point (e.g., the 64 bits IEEE-754) or, in some cases, in which the covariance matrix characteristic allows it, the single precision floating point (32 bits IEEE-754). However, in certain cases, single precision can result in numerical problems. Numerical formats of even lower precision, e.g., 16 bits, are usually more difficult to be applied, due to usual numerical instability, lack of consistency or, in the best cases where the approximation is properly applied (by performing matrix inflation), highly conservative results. However, when properly treated, a full Gaussian filter can operate in low precision without incurring relevant errors or excessive conservativeness. In particular, for systems that can be processed through a Generalized Compressed Kalman Filter (GCKF) [
1], it is possible to operate under a lower precision numerical format. The advantage of maintaining and storing the huge covariance matrix using low precision is relevant because the required memory can be reduced to a fraction of the nominal required amount. In addition to reducing the amount of required data memory, the fact that a program operates using lower amount of memory, improves its performance by lowering the number of RAM cache misses, a limitation which is still present in the current computer technology. The frequent RAM cache misses lead to additional problems such as high memory traffic, energy consumption, and additional issues that decrease the efficiency of CPU utilization.
This effect is even more relevant when those operations do occur massively and at high frequency. That is the case of a standard Gaussian estimator performing update steps, because those require updating the full covariance matrix, which means the full covariance matrix is read and written at each KF update, i.e., all the elements of the covariance matrix are R/W acceded. If, in addition to the high dimensionality and high frequency operation, the estimator also includes the capability of performing smoothing, then the requirements of memory can be dramatically increased, further exacerbating the problem.
The approach presented in this paper exploits the low-frequency nature of the global updates of the GCKF in combination with a simple matrix bounding technique, for treating truncation errors associated with low precision numerical representation. In the GCKF framework, only during the low-frequency global updates the full covariance matrix is modified. That particularity of the GCKF allows performing additional processing on the full covariance matrix, if required for diverse purposes. As the global updates are performed at a low execution rate, the cost of the treatment of the full covariance matrix is amortized over the overall operation, in many cases making the overhead result in very low extra cost. One of the purposes of treating the full covariance matrix, , can be for approximating it by a low precision version of it; e.g., for representing the covariance matrix in single precision format or even by lower precision representations such as scaled 16-bit integers. Just truncating precision (truncating bits) is not adequate for replacing a covariance matrix; consequently, proper relaxation of the matrix needs to be performed. One way of doing it is by generating a bounding matrix, , which satisfies two conditions:
The approximating matrix, , must be more conservative than the original one (the one being approximated), i.e., must be positive semidefinite; this fact is usually expressed as or as .
is represented through a lower precision numerical format.
In addition, it is desirable that the discrepancy should be as small as possible to avoid over-conservative estimates, particularly if the approximation needs to be applied repeatedly. This technique would allow a GCKF engine to operate servicing a number of clients, that when a request to perform a global update is received, the required memory for temporary storing and processing the full covariance matrix is partially or fully provided by the engine, while the memory for storing the low precision version of the full covariance matrixes is maintained by the clients, which means that the actual required memory for double precision is only one and it is shared by many client processes. Furthermore, by proper manipulation of the required operations in the prediction and update steps, many of those do not need to be performed in full double precision, but just requiring high precision temporary accumulators of low memory footprint.
In addition, the required precision can be dynamically decided according to the availability of memory resources, observability of the estimation process, and required accuracy of the estimates. The technique would also allow maintaining copies of the full covariance matrix at different times (regressors of matrixes), e.g., for cases of smoothing.
3. Other Well-Known Approaches
Other approaches exist in the literature for reducing the computational cost of the KF-based methods which is a necessity in high dimensional problems especially when real-time estimates are a requirement or when computational resources are limited such as on embedded systems. These can be broadly classified into three categories: (i) error subspace KFs, (ii) distributed/decentralization methods, and (iii) methods rooted in optimizations that exploit the characteristics of the estimation problems [
7].
The error subspace KFs reduce the computational cost by using a lower rank approximation of the covariance matrix. The methods under this category include the reduced rank square root algorithm [
8], the singular evolutive extended Kalman (SEEK) filter [
9], and the Ensemble KF (EnKF) [
10] which instead use an ensemble of states to represent the error statistics instead of the mean vector and the covariance matrix in EKF. Although the EnKF is the preferred method when dealing with high dimensional estimation problems, it often requires a large number of observations for convergence in estimating strongly non-linear problems [
11]. Furthermore, the ensemble representation is ideal for dealing with cases of strong correlation but that is not a general characteristic of all the estimation problems [
2]. The optimizations employed in the EnKF are also based on conservative assumptions. The local analysis method, for example, assumes that the statistical dependency is localized [
12] to reduce the computational cost when processing a large number of observations in the update/analysis step. This assumption is valid for the systems modeled by certain PDEs but again it is not a general characteristic of all the estimation problems [
2].
The distributed or decentralization methods reduce the computational cost by dividing the estimation problem into a set of sub-problems. The examples of the methods under this classification include: (i) the distributed KF for sensor networks using consensus algorithms in [
13,
14] where the estimates have been shown to converge to those of the centralized KF with the cost of temporarily sacrificing optimality [
15]; (ii) the fully decentralized KF suitable for systems that are sparse and localized such as those resulting from spatio-temporal discretization of PDEs [
16]; (iii) the aforementioned GCKF [
1], which is not fully decentralized requiring low-frequency global updates, shown to optimally treat problems that allow the estimation process to be divided, during certain periods of time, into a set of lower dimensional sub-problems; and, (iv) GCKF with switching technique and architecture for information exchange between sub-processes [
2,
7] targeting previously intractable cases, i.e., problems that can’t be decoupled into lower dimensional sub-problems.
There is a large literature that has exploited various characteristics and structures of the estimation problem to reduce the computational cost of KF and its variants. Some notable examples include: [
17,
18] when the process or the observation model is partly linear, [
17,
19,
20] when the measurements are conditionally linear, [
21] when only part of the state is observed through the measurement model, [
4,
6] when the system’s structure contains unobserved and static states consistently for a period of time, [
1] when the system’s process and observation models can be decoupled into a set of sub-processes, [
17] when the number of measurements is large and the measurement noise covariance matrix is diagonal or block-diagonal, and [
17] when the number of observations is greater than the dimensionality of the states.
The use of a lower precision numerical format in high dimensional problems such as that employed in this paper is previously observed in EnKF [
22,
23]. However, no matrix inflation or matrix bounding techniques were applied as they relied on the assumption that the numerical errors were within the tolerance of the system. They instead redistributed the saved computational resources from lower precision arithmetic and lower memory usage to employing a larger ensemble size which provided a better estimate of the underlying distribution.
4. Low-Precision Approximating Covariance Matrix
In general, for any covariance matrix,
, its non-diagonal elements can be expressed as follows:
This fact can be expressed in matrix terms (for the purpose of explaining it, but not for implementation reasons),
where the full covariance matrix is expressed by a scaling matrix
(which is diagonal) and a full dense symmetric matrix
whose elements are bounded in the range
. The matrix
is in fact a normalized covariance matrix. The low precision representation, introduced in this work, keeps the diagonal matrix
(i.e., its diagonal elements) in its standard precision representation (e.g., single, double, or long double precision), and it approximates the usually dense matrix
by a low precision integer numerical format. For instance, if a precision of
N bits is required, then
is fully represented by the integer matrix
whose elements are signed integers of
N bits. For obtaining the elements of
, the relation is as follows,
The operator
means that the argument is approximated to the nearest integer (i.e., “rounded”). The inverse operation produces a discrete set of elements in the range of real numbers
, and it is defined as follows,
The discrepancy between
and its low precision version,
, is simply the matrix residual
. This discrepancy matrix can be bounded by a diagonal matrix,
, that must satisfy the condition
. A “conservative” bounding diagonal matrix, is as it was introduced in [
5,
21], or adapted for this case, as follows,
This type of approximation is deterministic, i.e., always valid, and it may be too conservative for cases such as in this application, for dealing with limited numerical precision. The resulting diagonal elements are deterministically calculated; however, they can be simply estimated by considering that the added values do follow a uniform distribution, as usually is the case of the rounding errors. For the case of adding a high number of independently and identically distributed random variables, whose PDF is uniform, the resulting PDF is almost Gaussian. As the rounding errors follow a uniform distribution, a less conservative and “highly probable” bounding matrix for the error matrix can be simply defined as follows,
In which
n is the size of the matrix (more exactly
is a square matrix of size
n by
n), and
N is the number of bits of the integer format being used. The bound
is usually much lower than the conservative bound
. This less conservative bound is valid for the cases where the residuals
follow a uniform distribution in the range
, as it is the case of the truncation error in this approximation. Because of that, an approximating covariance matrix
is obtained as follows,
This means that the slightly conservative bound for
is given by the matrix
in which
is the reduced precision version of
, and the rest of the (implicit) matrixes are high precision (e.g., double) but diagonal. Consequently, the approximating covariance matrix can be stored by using
n double precision elements and
integers. When implemented, the matrix relation is simply evaluated by relaxing the diagonal elements of the nominal covariance matrix, as follows:
In which
are simply the standard deviations of the individual state estimates. The apparently expensive conversion defined in Equation (
8), is implemented in a straightforward way, due to the fact that the elements
are always bounded in the range
; not even needing any expensive CPU operation, but just reading the mantissas from memory. Only
n square roots and only
n divisions need to be evaluated. The rest of the massive operations are additions and products. Alternative integer approximations are also possible. Similarly, the integer approximation could also be implemented via the CEIL truncation operation. Depending on the CPU type and its settings, some of them may be more appropriate than others. The CEIL case is expressed as follows,
In this case, the approximation error
follows a uniform distribution in the range
. It could be shown that the discrepancy is always bounded as expressed in Equation (
7). The resulting required inflation of the diagonal elements, for all the cases (round and CEIL), is marginal provided that the relation
is satisfied. For instance, if 16 bits are used for the integer approximation, for a
covariance matrix, the required inflation of the diagonal elements results to be
This means that if the bounding were applied 100 times, the cumulated error would be
, which for such a small value of
c would result in a variation of about
, i.e.,
. If 12 bits are used, then the required inflation will be higher; however, it would still be small,
An aggressive discretization, e.g.,
bits, would require a more evident inflation,
The required low inflation, for the case of
and
, may create the impression that it could be even applied at high frequency rates, e.g., in a standard Gaussian filter. This impression is usually wrong, in particular if the prediction and update steps are applied at very high rates, which would result in a highly inflated covariance matrix. The advantage of using this decorrelation approach, in combination with the GCKF, is that while the estimator operates in a compressed way, the low dimensional individual estimators can permanently operate in high precision (e.g., in double precision) and only at the global updates the precision reduction is applied; this results in marginal inflation of the diagonal elements of the covariance matrix. If more bits can be dedicated for storing
(via the integer matrix), highly tight bounds can be achieved. For instance, in the case of
if the integer length is
bits,
For the case of using the GCKF, between 10 and 16 bits seems an appropriate precision, due to the usually low frequency nature of the global updates. If the approximations were to be applied at high frequencies (e.g., not being part of a GCKF process), higher precision formats may be necessary, e.g.,
. From the previous analysis, it can be inferred that the cumulative approximation error is linear with respect to the rate of application (this is concluded without considering the compensating effect of the information provided by the updates). This is an intuitive estimation because bounding approximations are immersed and interleaved between the prediction and the update steps of the Gaussian estimation process. A more natural way of expressing the same equations would be based in “kilo-states”,
where
K is the number of kilo-states, for expressing the dimension of the state vector in thousands of states; and where the constant 40 is simply an easy bound for
. The bounding factor of
, which was obtained heuristically, is a conservative value. In the
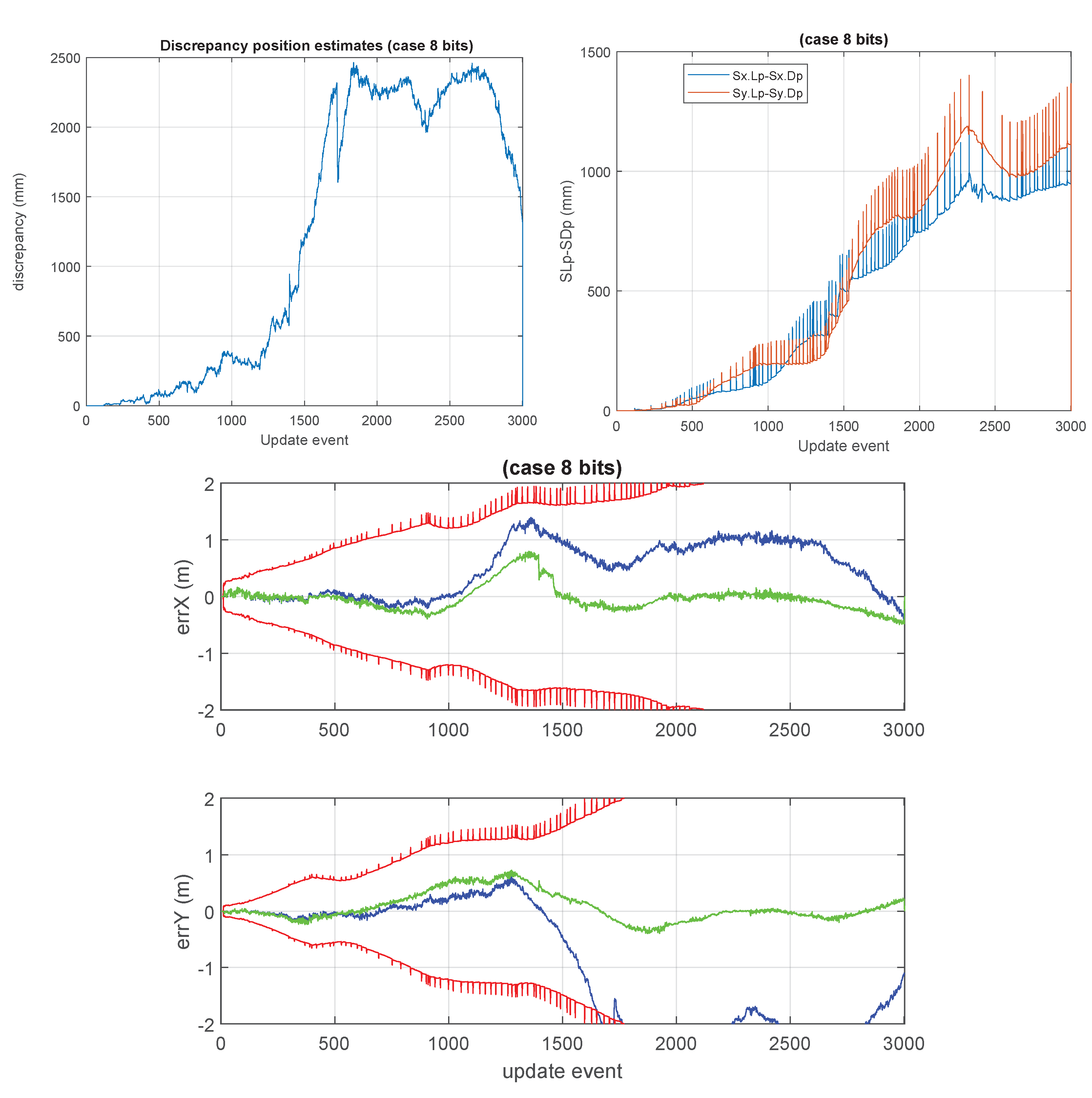
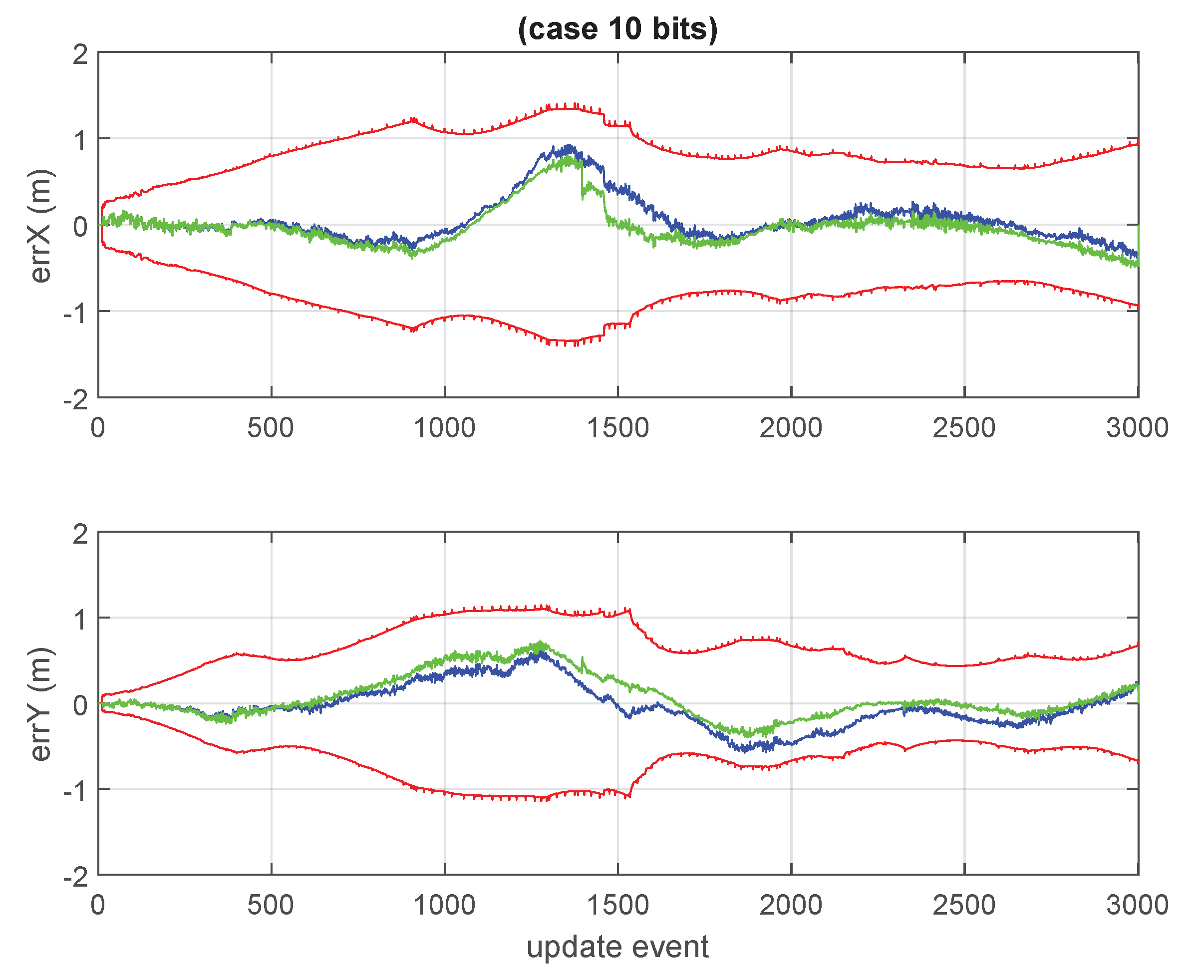
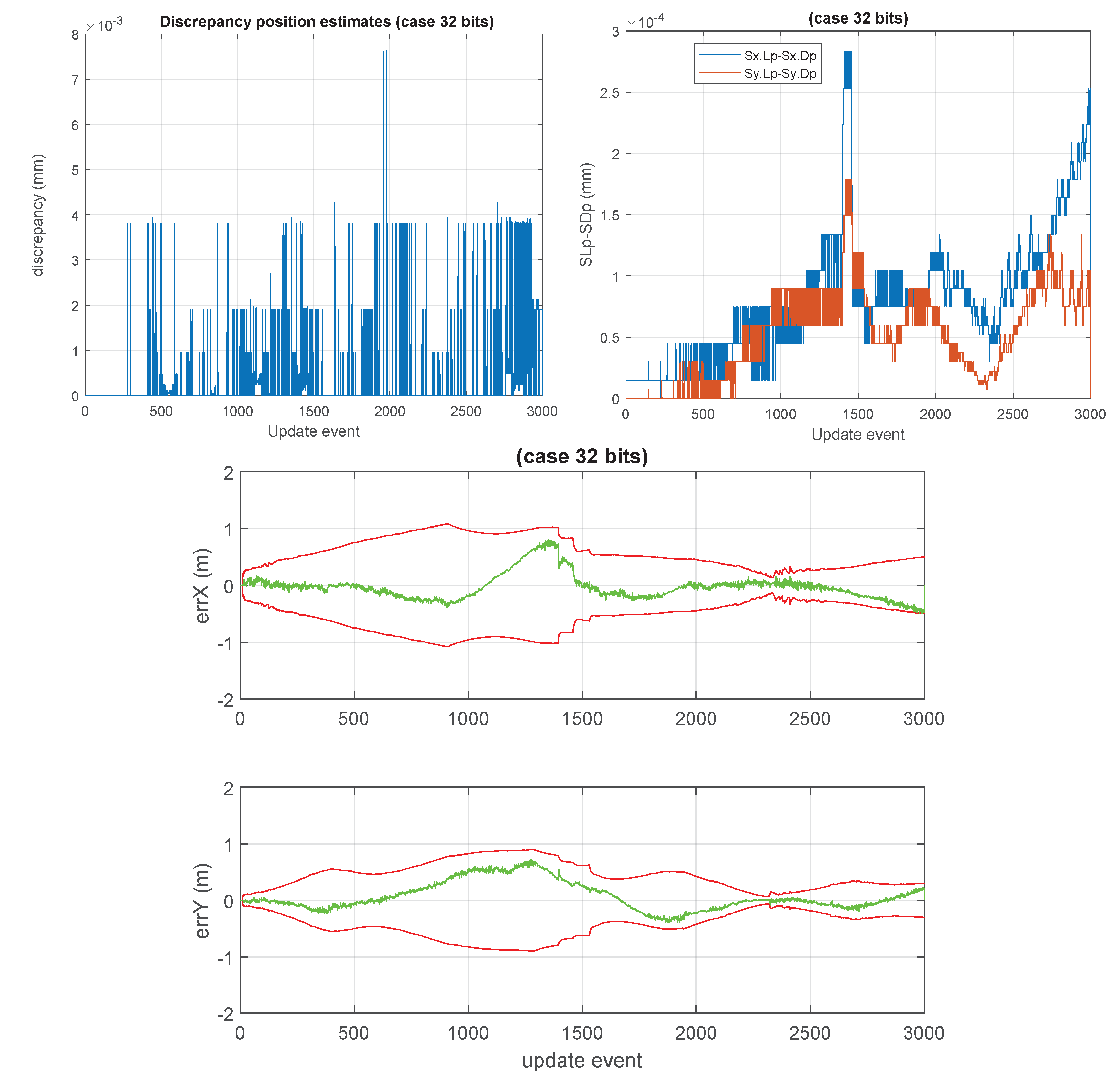
Figure 1, a high number of cases, with high values of
n, were processed. In each individual case, a covariance matrix was generated randomly, and its bound was evaluated by an optimization process. All the obtained values were lower than
.
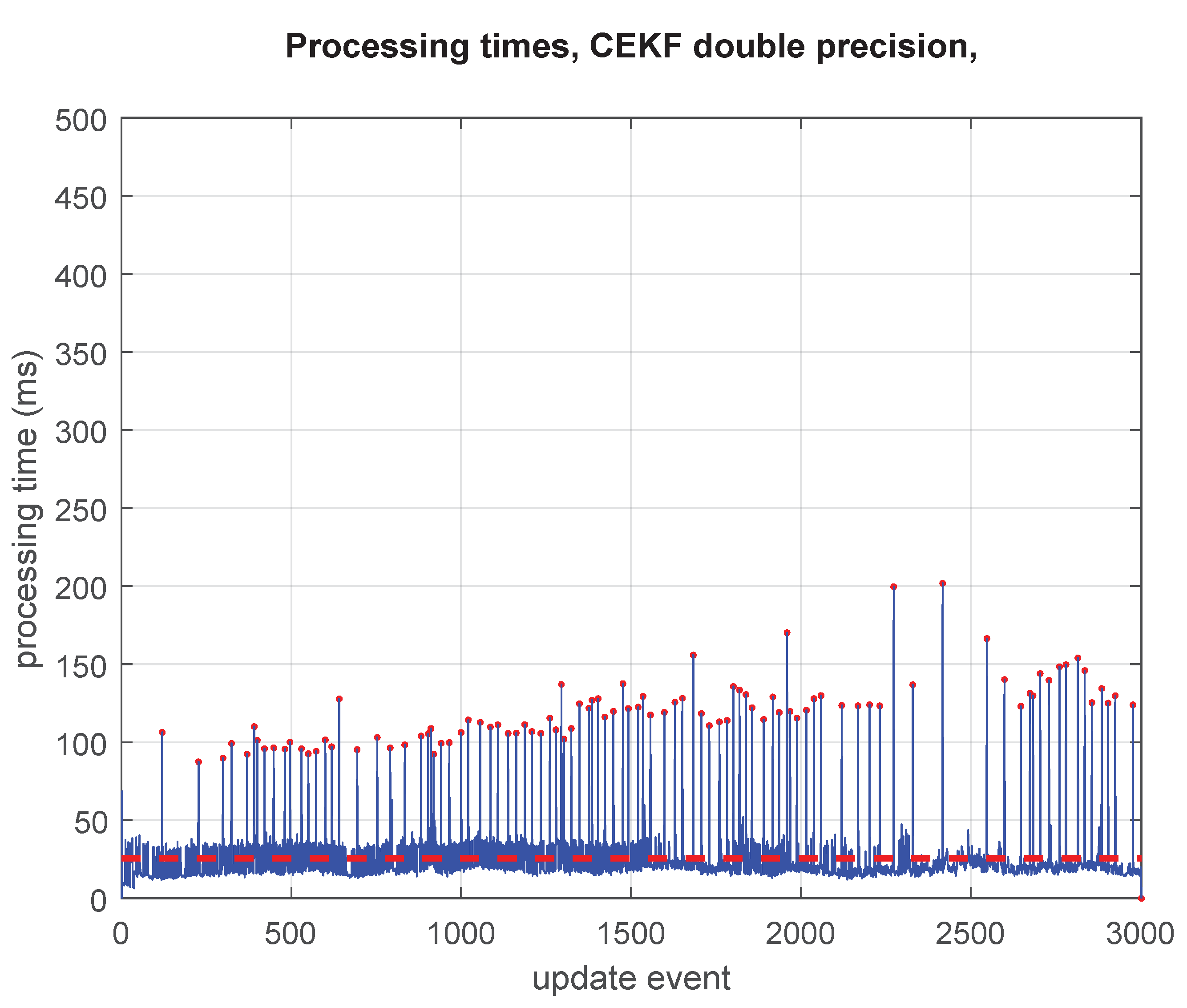
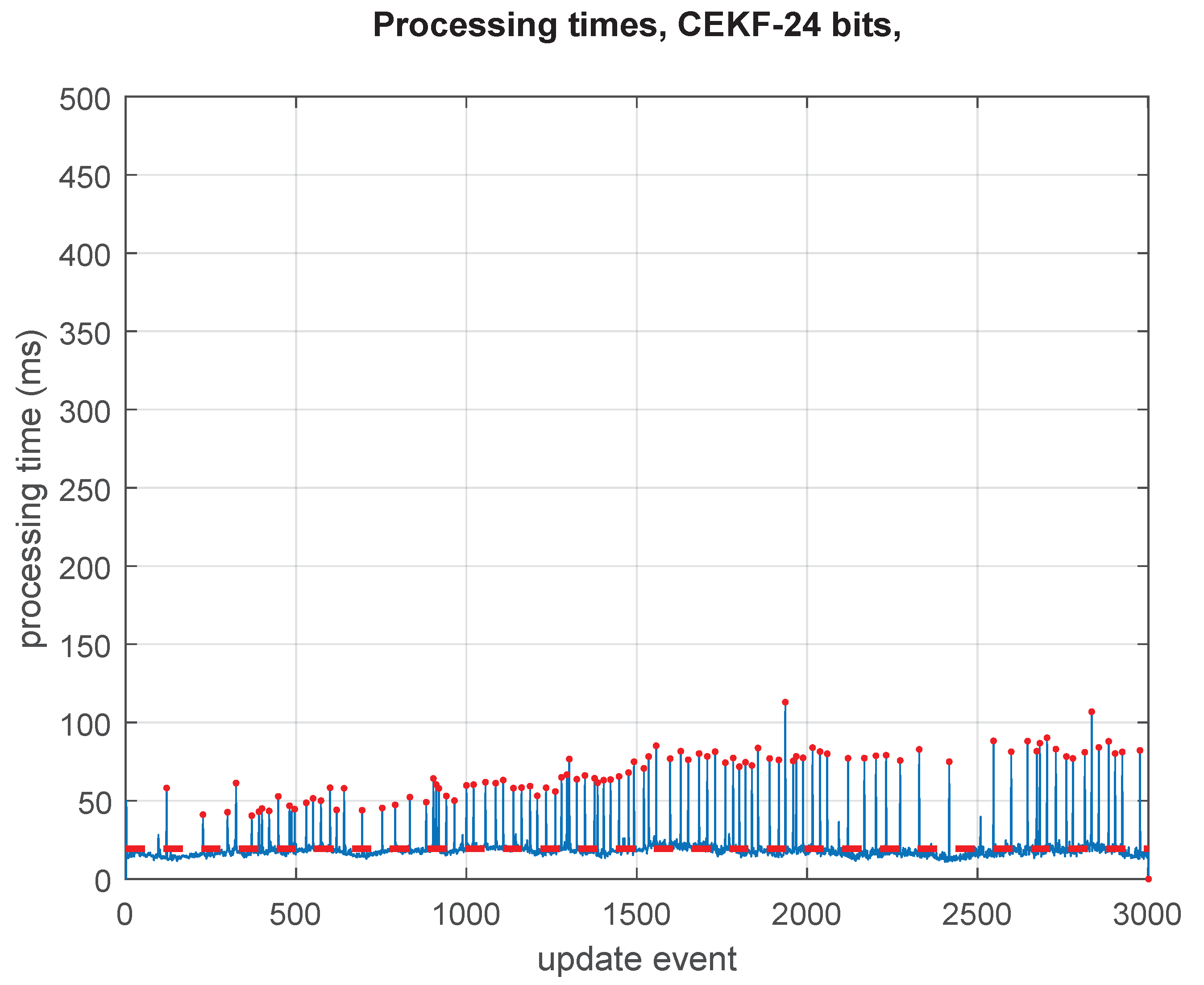
The most relevant operation in which the full covariance matrix is fully updated does occur at low processing rate, in the GCKF global update (GU). Still, we process it achieving high precision in the intermediate steps while still using it in its low precision storage. The fact that the
matrix is usually sparse, and of a narrow rectangular shape of size
m by
n, with
, implies relevant benefits in the way we can exploit this approach. The
matrix is sparse in the usual cases, and it is also sparse in the virtual update associated with the GU of the GCKF. We can adapt the approach to different modalities of performing a Bayesian update for a Gaussian prior PDF and a Gaussian likelihood function; we give details using the standard KF update equations, as it is one of the ways to perform it. In this section, we explain how to do it for the well-known standard KF update. We focus our analysis on obtaining the posterior covariance matrix, which we call
, while that of the prior PDF is simply indicated as
.
We exploit the fact that the observation function is a function of just a subset of the states of the full state vector being estimated. We address those by using integer indexes (which we call here
), to select only those columns of
which do contain at least one element different to zero. We here express the previous operations using Matlab notation (by which we can clearly indicate the indexing procedure).
This indicates that only a part of the prior matrix
is needed for calculating the variation of
. It means that the intermediate calculations, related to
can be performed incrementally and just requires converting those parts of
to double (or even long double precision, if we wanted). After those parts of
are calculated in high precision we can immediately apply the update to the stored
matrix, which is in single precision, never needing to be entirely converted to double or long double precision. In this way, we obtain the benefits of achieving the accuracy of double (or long double) precision but operating and storing
in low precision, not requiring extra processing, but consuming lower processing time due to the better performance of the CPU (or GPU) memory cache. It is worth noting that
is never fully stored in memory (neither in low nor high precision). The intermediate calculations (usually massive linear combinations) are guaranteed to be performed in high precision (double or even long double), so that numerical errors are minimized, in the same way it would happen if we used double (or long double) representation in the overall process.
By exploiting those indexed operations, the nominal cost of updating the covariance matrix is
.
The only required temporary matrix to be briefly kept in double precision is , which is n by m (with ).
We can operate on the matrix
,
If, in the estimator update, we operate in terms of the normalized covariance matrix,
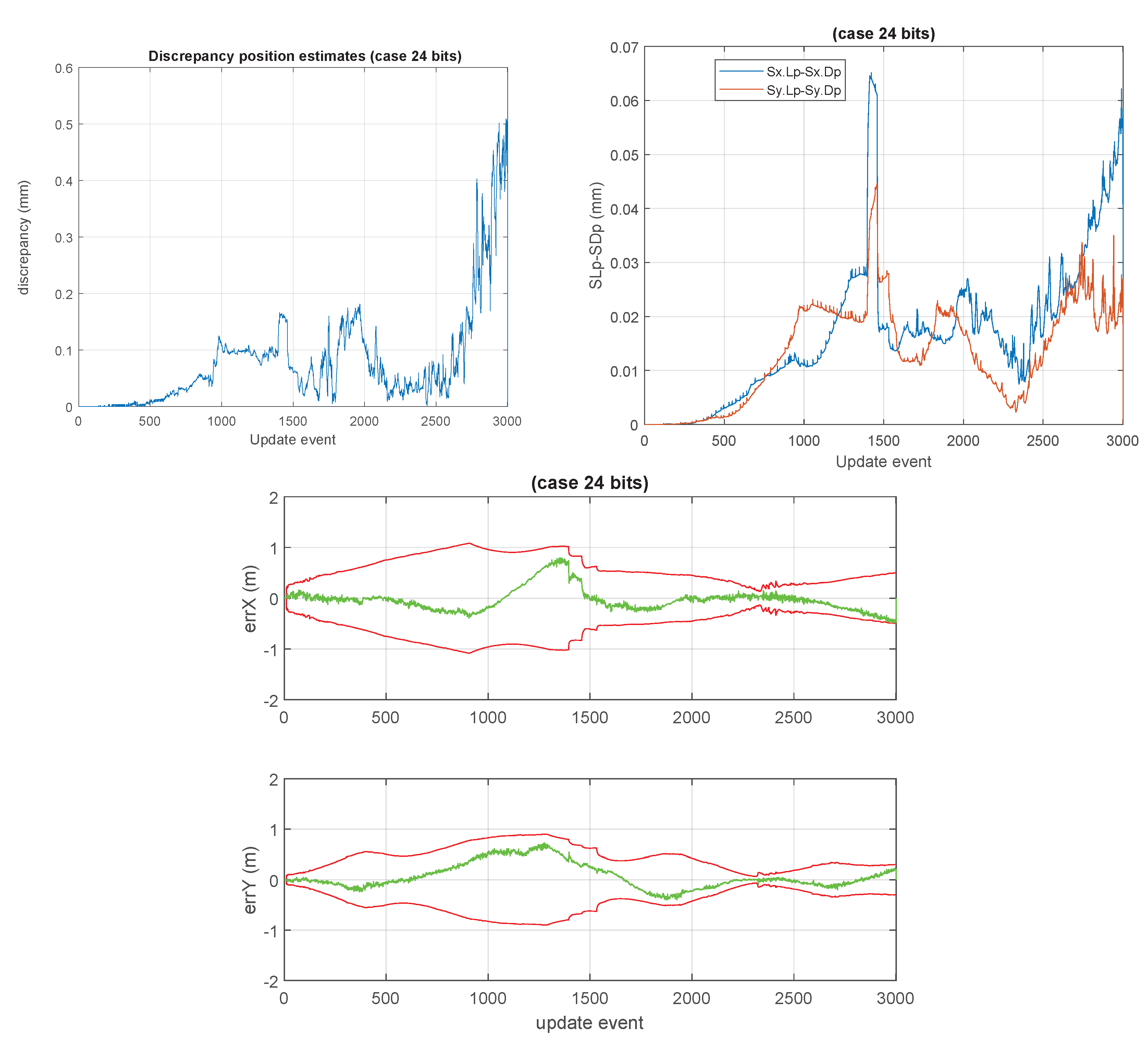
The inner product should be done through a high precision accumulator, even being the elements of represented in low precision (the same has been assumed in other operations involving linear combinations of low precision items, in the previous calculations). After this operation, the updated normalized covariance matrix is usually not normalized anymore. That fact does not mean, anyway, that it needs to be normalized immediately. It can be kept in that way except we infer some of its diagonal elements are far from being . We try to maintain a balance between keeping close to being normalized, not necessarily being strictly normalized. Due to that, we just normalize it partially, trying to maintain its diagonal elements , but still minimizing the frequency of re-scaling (full normalizations). Still, in the GCKF framework, normalizing it after each (usually sporadic) global update is not a high processing cost, due to the low frequency nature of the GUs.
In the previous discussion, we have not described the steps for efficiently obtaining (which is needed for obtaining the necessary component ), because those operations are not expensive as m and are usually well lower than n.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















