


Decoding Mental Effort in a Quasi-Realistic Scenario: A Feasibility Study on Multimodal Data Fusion and Classification



Abstract
:
1. Introduction
2. Materials and Methods
2.1. Participants
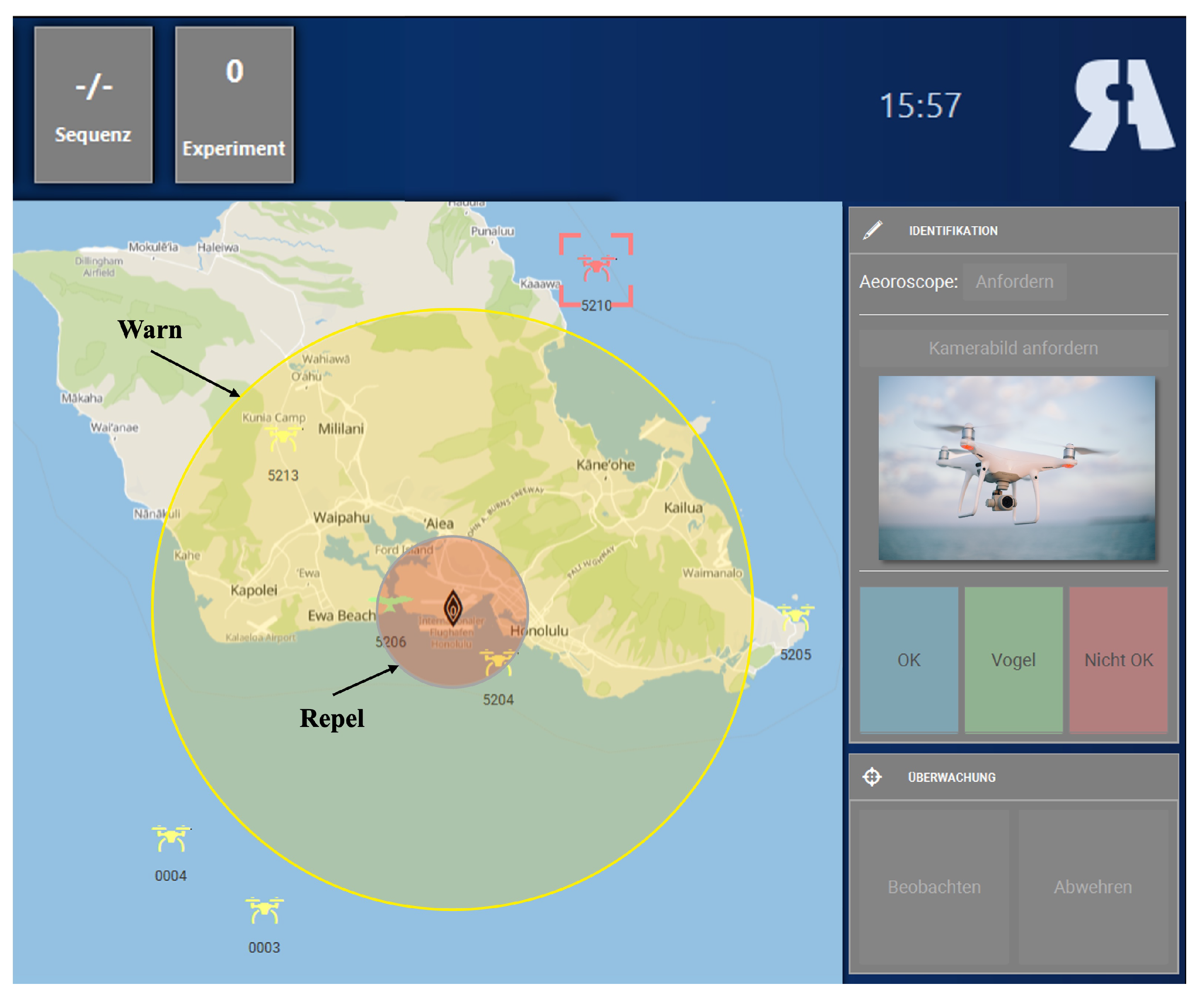
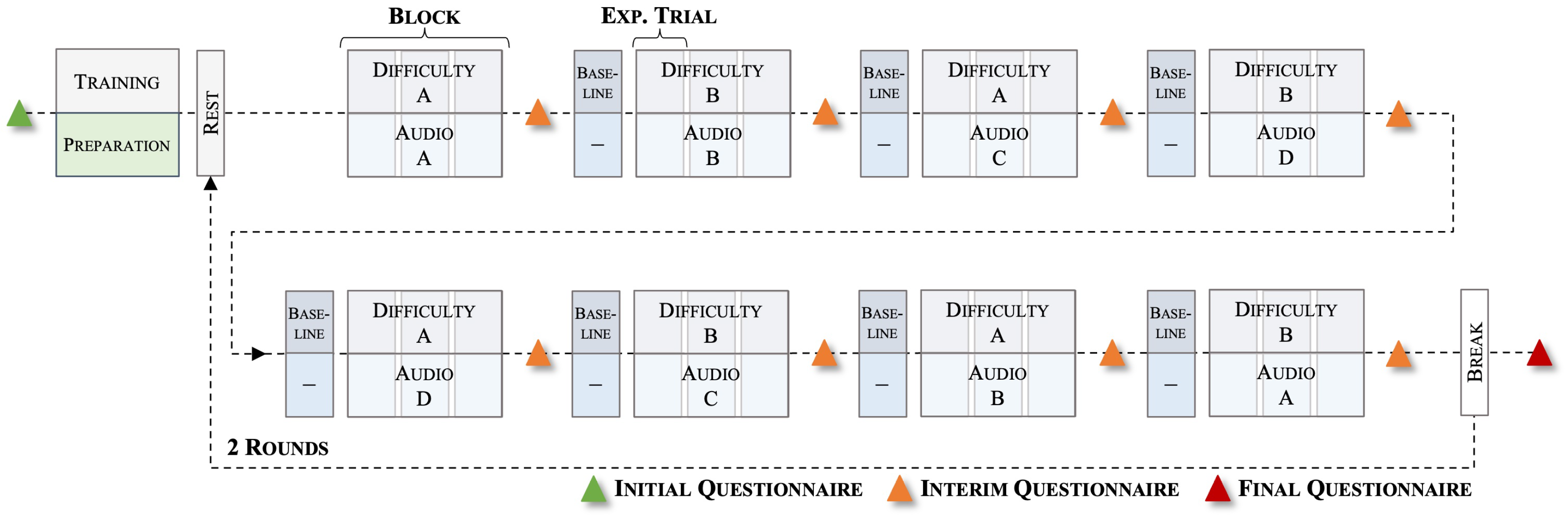
2.2. Experimental Task
2.3. Data Collection
2.3.1. Questionnaires
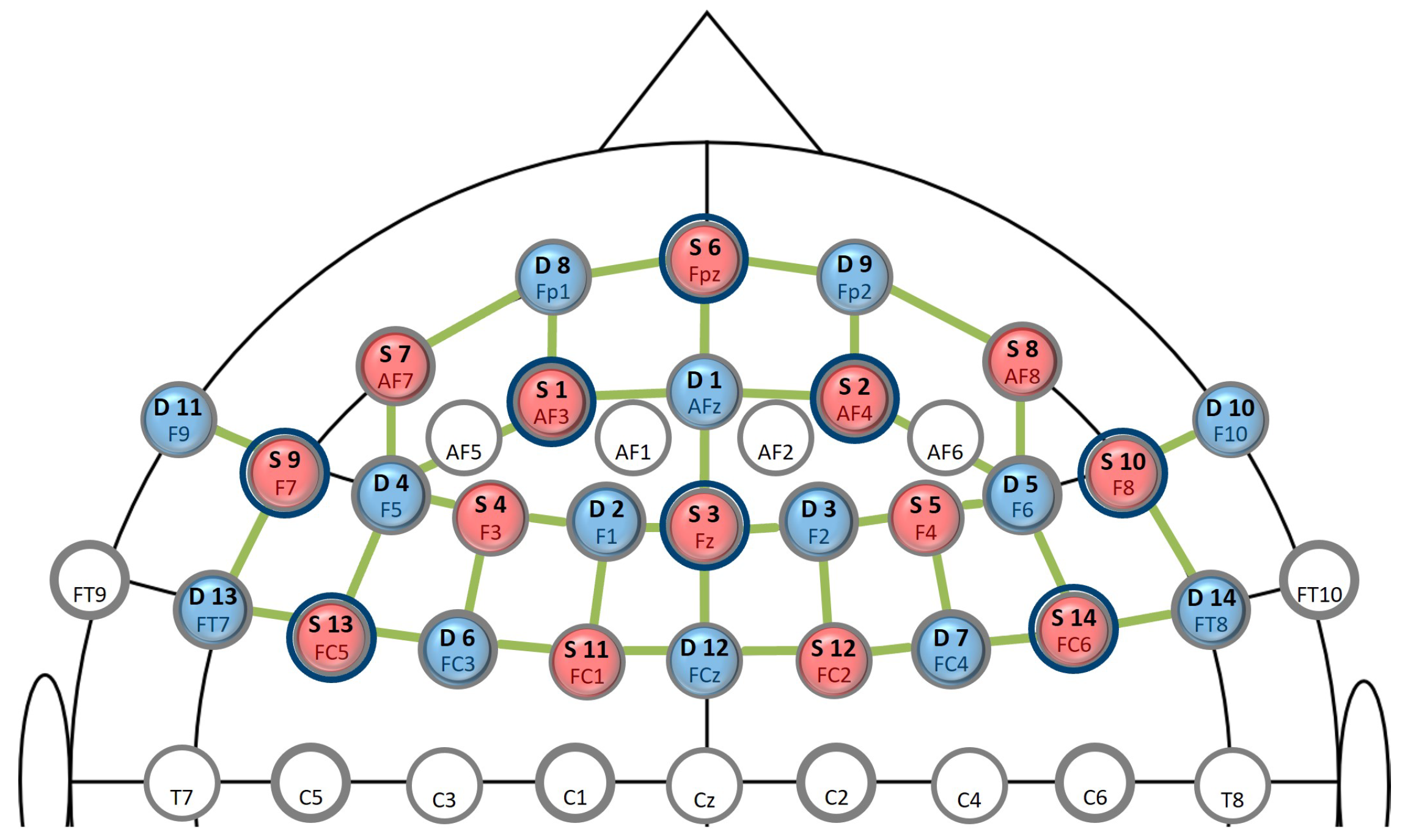
2.3.2. Eye-Tracking, Physiology, and Brain Activity
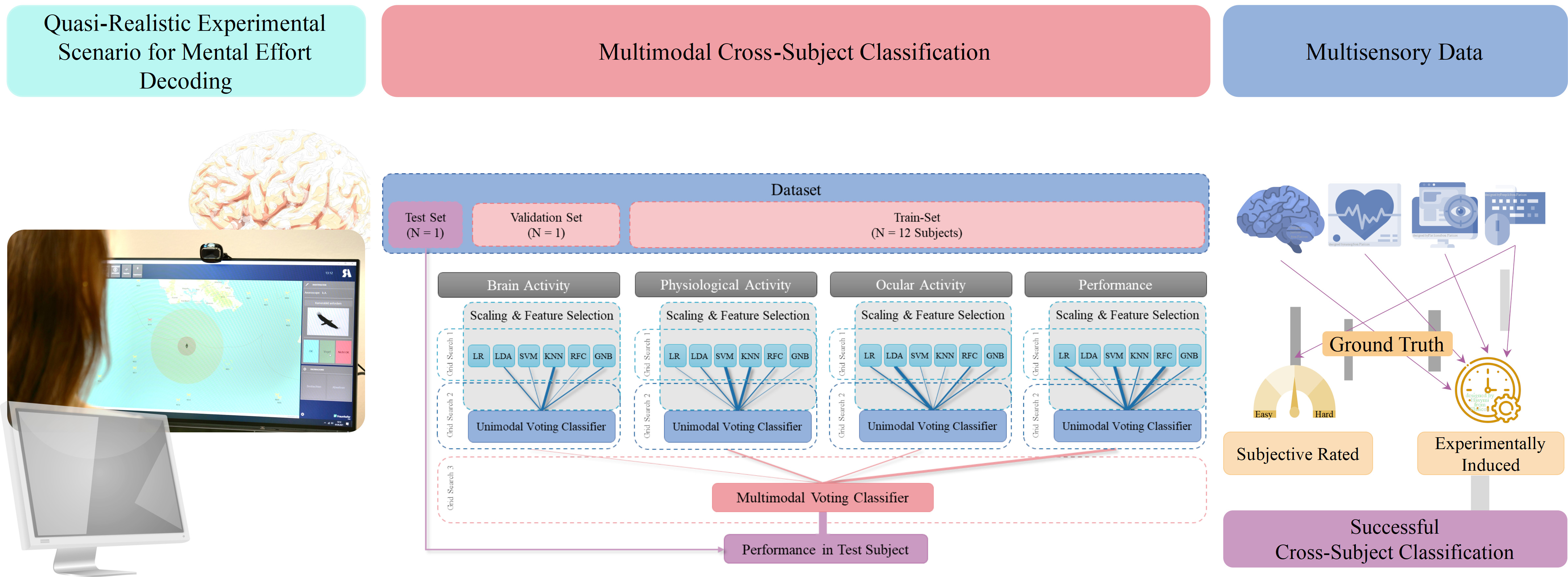
2.4. Data Preprocessing and Machine Learning
2.4.1. Preprocessing of Eye-Tracking Data
2.4.2. Preprocessing of Physiological Data
2.4.3. Preprocessing of fNIRS Data
2.4.4. Feature Extraction
2.4.5. Ground Truth for Machine Learning
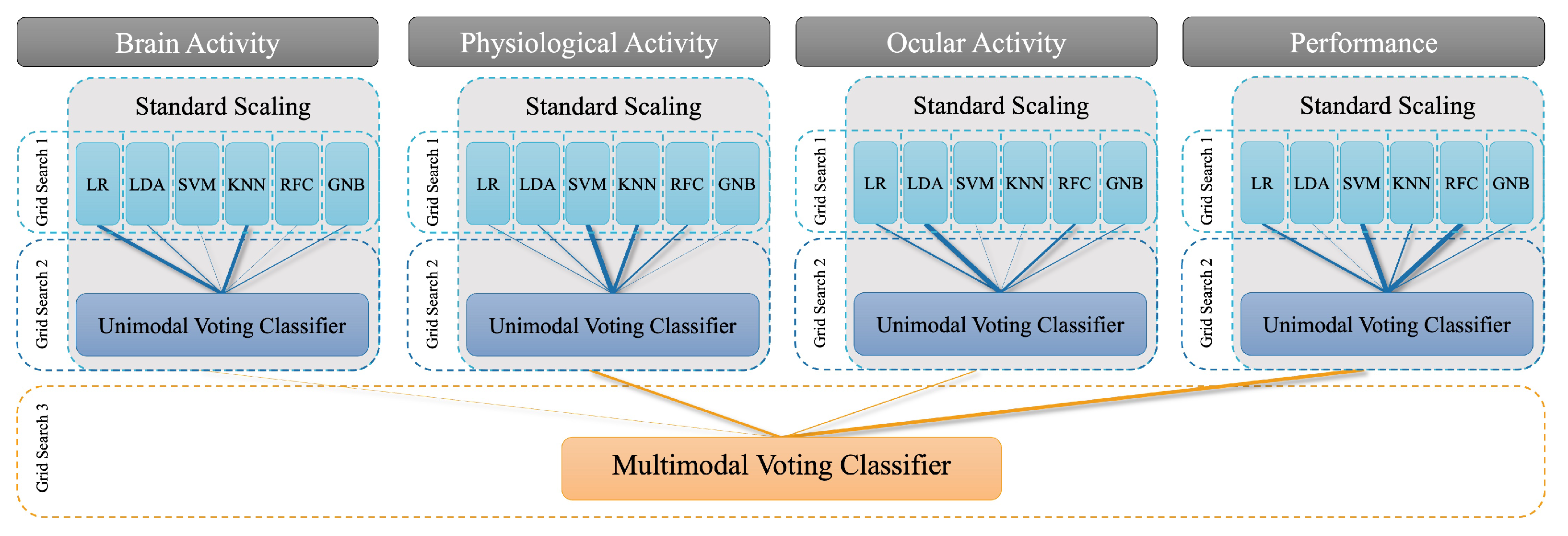
2.4.6. Model Evaluation
3. Results
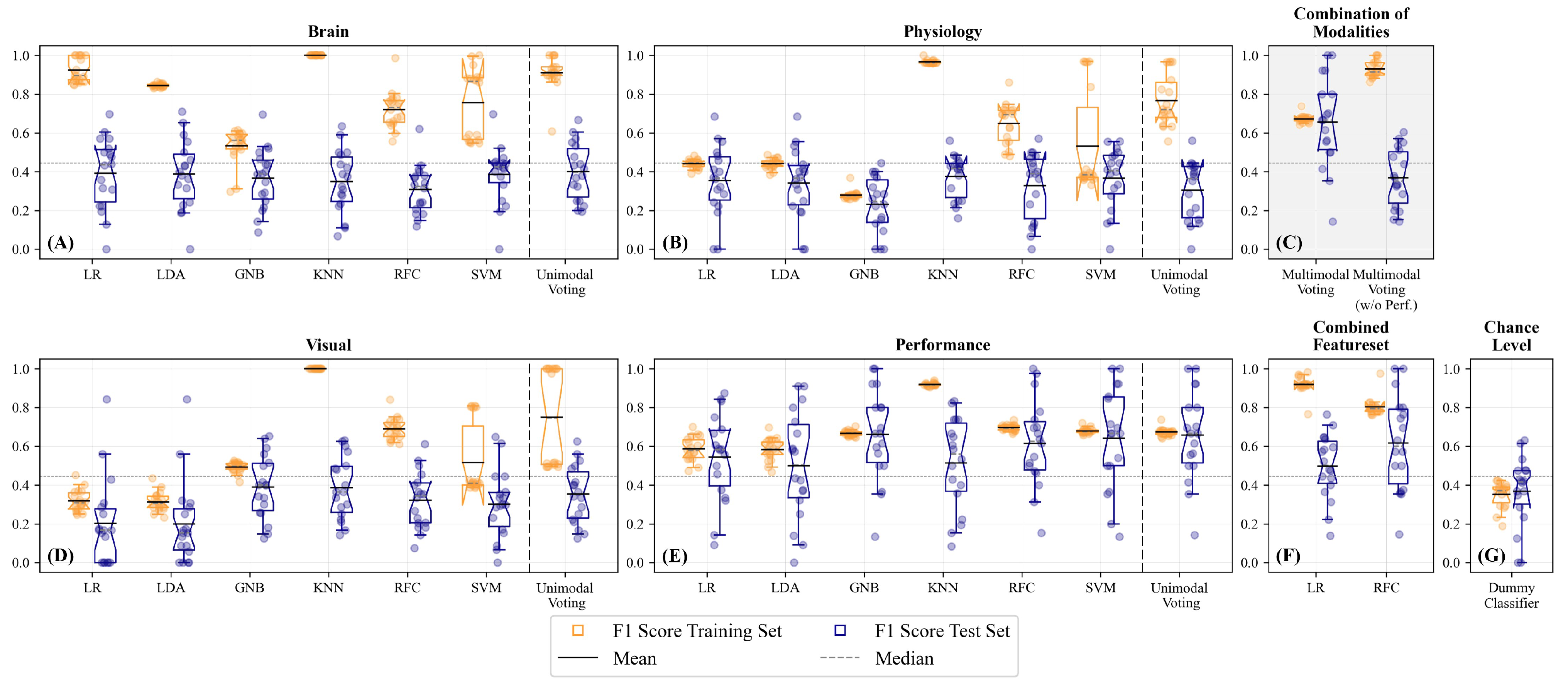
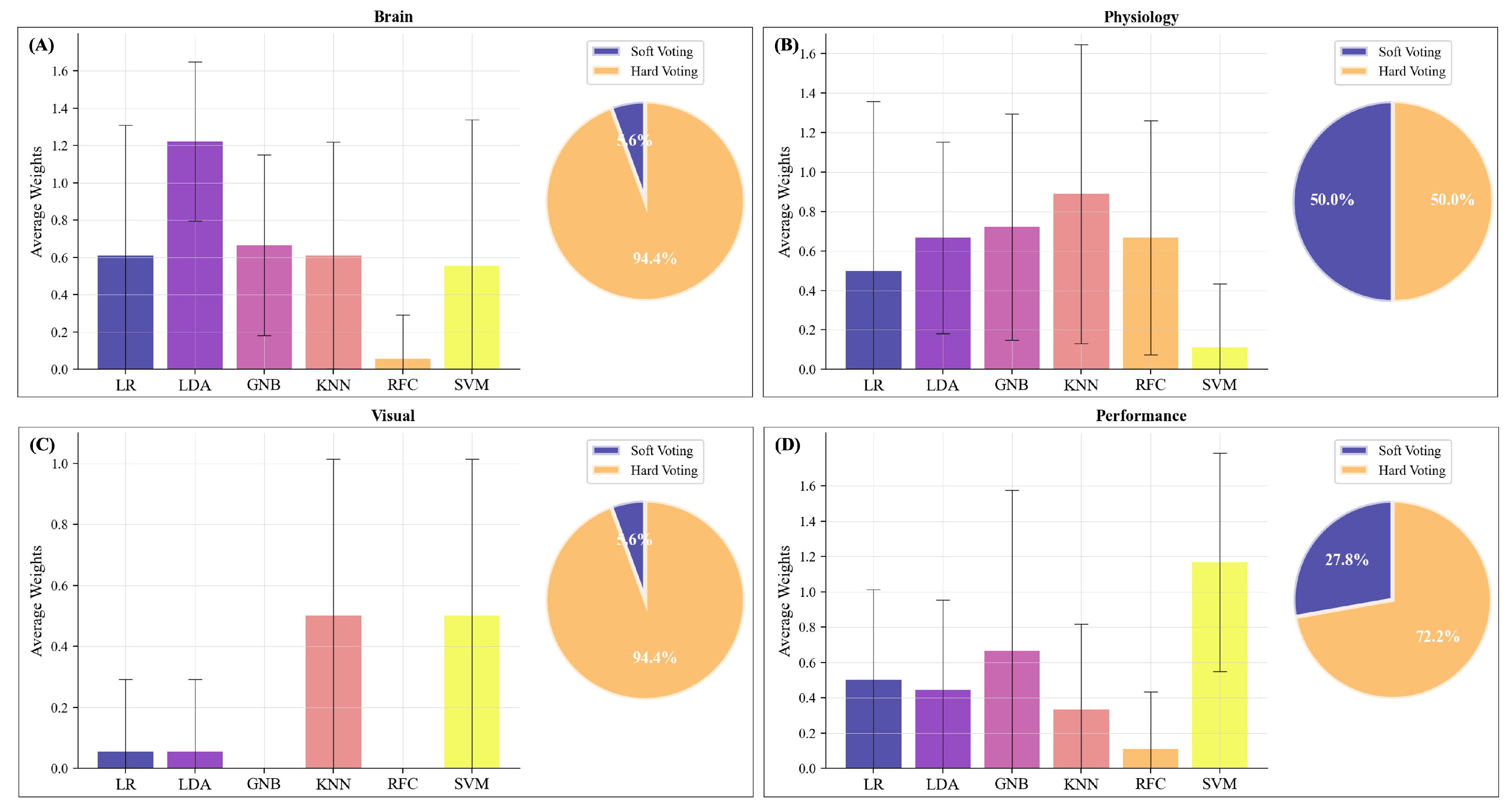
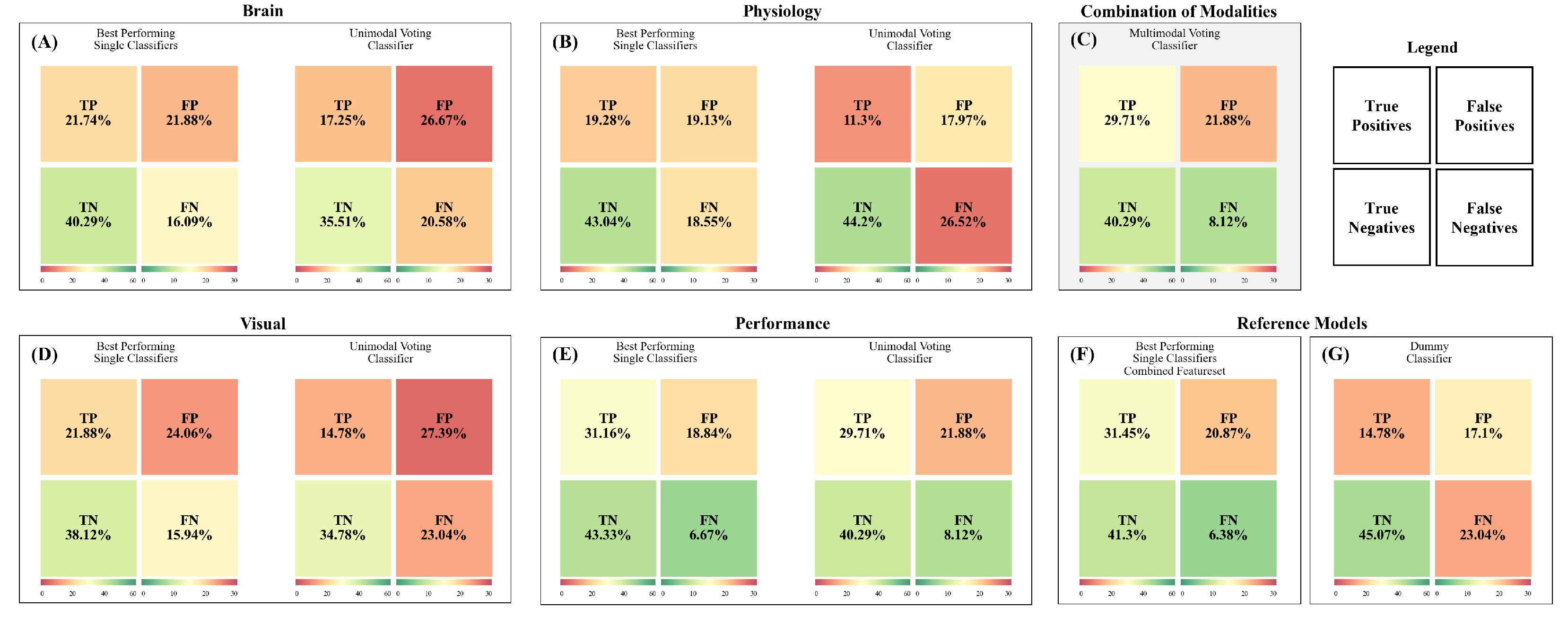
3.1. Unimodal Predictions

3.2. Unimodal Predictions—Brain Activity
3.3. Unimodal Predictions—Physiological Measures
3.4. Unimodal Predictions—Ocular Measures
3.5. Unimodal Predictions—Performance
3.6. Unimodal Predictions Based on the Upper Quartile Split
3.7. Unimodal Predictions Based on the Experimental Condition
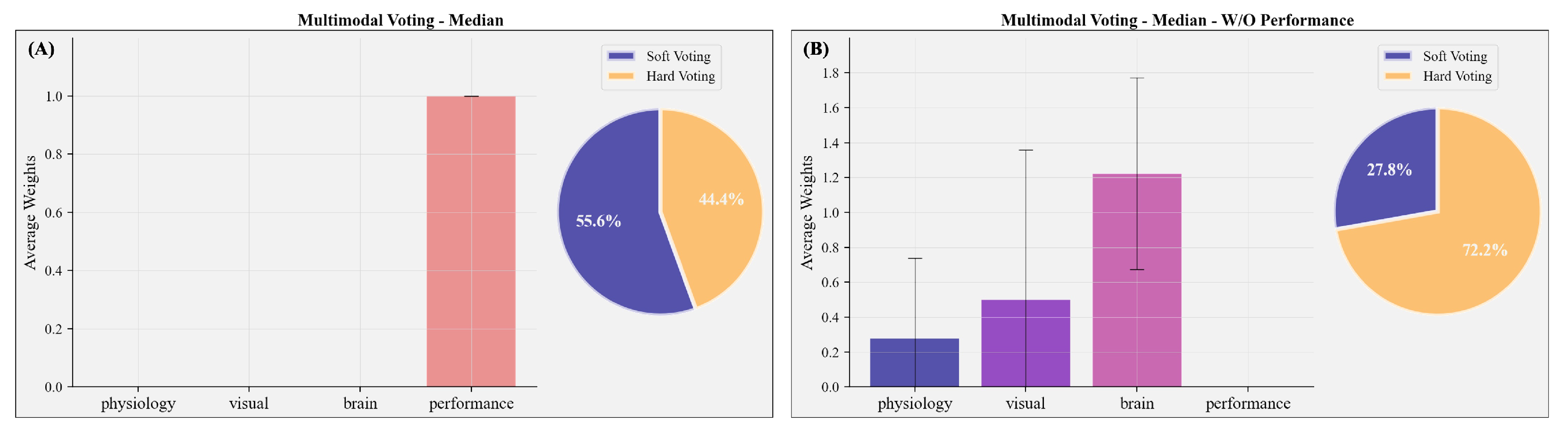
3.8. Multimodal Predictions Based on the Median Split
3.9. Multimodal Predictions Based on the Upper Quartile Split
3.10. Multimodal Predictions Based on the Experimental Condition
4. Discussion
4.1. Using Subjectively Perceived Mental Effort as Ground Truth
4.2. Using Experimentally Induced Mental Effort as Ground Truth
4.3. Generalisation across Subjects
4.4. Limitations and Future Research
4.5. Feature Selection and Data Fusion in Machine Learning
5. Practical Implications and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| fNIRS | functional Near-Infrared Spectroscopy |
| ECG | Electrocardiography |
| HbO | Oxy-Haemoglobin |
| HbR | Deoxy-Haemoglobin |
| PFC | Prefrontal Cortex |
| WCT | Warship Commander Task |
| SD | Standard Deviation |
| CI | Confidence Interval |
| ML | Machine Learning |
| LR | Logistic Regression |
| LDA | Linear Discriminant Analysis |
| GNB | Gaussian Naïve Bayes Classifier |
| KNN | K-Nearest Neighbour Classifier |
| RFC | Random Forest Classifier |
| SVM | Support Vector Machine Classifier |
References
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in Psychology; Hancock, P.A., Meshkati, N., Eds.; Elsevier: Amsterdam, The Netherlands, 1988; Volume 52, pp. 139–183. [Google Scholar] [CrossRef]
- Young, M.S.; Brookhuis, K.A.; Wickens, C.D.; Hancock, P.A. State of science: Mental workload in ergonomics. Ergonomics 2015, 58, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Paas, F.; Tuovinen, J.E.; Tabbers, H.; Van Gerven, P.W.M. Cognitive load measurement as a means to advance cognitive load theory. Educ. Psychol. 2003, 38, 63–71. [Google Scholar] [CrossRef]
- Chen, F.; Zhou, J.; Wang, Y.; Yu, K.; Arshad, S.Z.; Khawaji, A.; Conway, D. Robust Multimodal Cognitive Load Measurement; Human–Computer Interaction Series; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Zheng, R.Z. Cognitive Load Measurement and Application: A Theoretical Framework for Meaningful Research and Practice; Routledge: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- von Lühmann, A. Multimodal Instrumentation and Methods for Neurotechnology out of the Lab. Fakultät IV—Elektrotechnik und Informatik. Ph.D. Thesis, Technische Universität Berlin, Berlin, Germay, 2018. [Google Scholar] [CrossRef]
- Charles, R.L.; Nixon, J. Measuring mental workload using physiological measures: A systematic review. Appl. Ergon. 2019, 74, 221–232. [Google Scholar] [CrossRef] [PubMed]
- Curtin, A.; Ayaz, H. The age of neuroergonomics: Towards ubiquitous and continuous measurement of brain function with fNIRS. Jpn. Psychol. Res. 2018, 60, 374–386. [Google Scholar] [CrossRef] [Green Version]
- Benerradi, J.; Maior, H.A.; Marinescu, A.; Clos, J.; Wilson, M.L. Mental workload using fNIRS data from HCI tasks ground truth: Performance, evaluation, or condition. In Proceedings of the Halfway to the Future Symposium, 19–20 November 2019; Association for Computing Machinery: Nottingham, UK, 2019. [Google Scholar] [CrossRef] [Green Version]
- Midha, S.; Maior, H.A.; Wilson, M.L.; Sharples, S. Measuring mental workload variations in office work tasks using fNIRS. Int. J. Hum.-Comput. Stud. 2021, 147, 102580. [Google Scholar] [CrossRef]
- Izzetoglu, K.; Bunce, S.; Izzetoglu, M.; Onaral, B.; Pourrezaei, K. fNIR spectroscopy as a measure of cognitive task load. In Proceedings of the 25th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Cancun, Mexico, 17–21 September 2003; Volume 4, pp. 3431–3434. [Google Scholar] [CrossRef]
- Ayaz, H.; Shewokis, P.A.; Bunce, S.; Izzetoglu, K.; Willems, B.; Onaral, B. Optical brain monitoring for operator training and mental workload assessment. NeuroImage 2012, 59, 36–47. [Google Scholar] [CrossRef]
- Herff, C.; Heger, D.; Fortmann, O.; Hennrich, J.; Putze, F.; Schultz, T. Mental workload during n-back task—Quantified in the prefrontal cortex using fNIRS. Front. Hum. Neurosci. 2014, 7, 935. [Google Scholar] [CrossRef] [Green Version]
- Miller, E.K.; Freedman, D.J.; Wallis, J.D. The prefrontal cortex: Categories, concepts and cognition. Philos. Trans. R. Soc. Lond. 2002, 357, 1123–1136. [Google Scholar] [CrossRef] [Green Version]
- Dehais, F.; Lafont, A.; Roy, R.; Fairclough, S. A neuroergonomics approach to mental workload, engagement and human performance. Front. Neurosci. 2020, 14, 268. [Google Scholar] [CrossRef]
- Babiloni, F. Mental workload monitoring: New perspectives from neuroscience. In Proceedings of the Human Mental Workload: Models and Applications; Communications in Computer and Information Science; Longo, L., Leva, M.C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 1107, pp. 3–19. [Google Scholar] [CrossRef]
- Matthews, R.; McDonald, N.J.; Trejo, L.J. Psycho-physiological sensor techniques: An overview. In Foundations of Augmented Cognition; Schmorrow, D.D., Ed.; CRC Press: Boca Raton, FL, USA, 2005; Volume 11, pp. 263–272. [Google Scholar] [CrossRef]
- Wierwille, W.W. Physiological measures of aircrew mental workload. Hum. Factors 1979, 21, 575–593. [Google Scholar] [CrossRef]
- Kramer, A.F. Physiological metrics of mental workload: A review of recent progress. In Multiple-Task Performance; Damos, D.L., Ed.; CRC Press: London, UK, 1991; pp. 279–328. [Google Scholar] [CrossRef]
- Backs, R.W. Application of psychophysiological models to mental workload. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2000, 44, 464–467. [Google Scholar] [CrossRef]
- Dirican, A.C.; Göktürk, M. Psychophysiological measures of human cognitive states applied in human computer interaction. Procedia Comput. Sci. 2011, 3, 1361–1367. [Google Scholar] [CrossRef] [Green Version]
- Dan, A.; Reiner, M. Real time EEG based measurements of cognitive load indicates mental states during learning. J. Educ. Data Min. 2017, 9, 31–44. [Google Scholar] [CrossRef]
- Tao, D.; Tan, H.; Wang, H.; Zhang, X.; Qu, X.; Zhang, T. A systematic review of physiological measures of mental workload. Int. J. Environ. Res. Public Health 2019, 16, 2716. [Google Scholar] [CrossRef] [Green Version]
- Romine, W.L.; Schroeder, N.L.; Graft, J.; Yang, F.; Sadeghi, R.; Zabihimayvan, M.; Kadariya, D.; Banerjee, T. Using machine learning to train a wearable device for measuring students’ cognitive load during problem-solving activities based on electrodermal activity, body temperature, and heart rate: Development of a cognitive load tracker for both personal and classroom use. Sensors 2020, 20, 4833. [Google Scholar] [CrossRef]
- Uludağ, K.; Roebroeck, A. General overview on the merits of multimodal neuroimaging data fusion. NeuroImage 2014, 102, 3–10. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Dong, Z.; Wang, S.H.; Yu, X.; Yao, X.; Zhou, Q.; Hu, H.; Li, M.; Jiménez-Mesa, C.; Ramirez, J.; et al. Advances in multimodal data fusion in neuroimaging: Overview, challenges, and novel orientation. Inf. Fusion 2020, 64, 149–187. [Google Scholar] [CrossRef]
- Debie, E.; Rojas, R.F.; Fidock, J.; Barlow, M.; Kasmarik, K.; Anavatti, S.; Garratt, M.; Abbass, H.A. Multimodal fusion for objective assessment of cognitive workload: A review. IEEE Trans. Cybern. 2021, 51, 1542–1555. [Google Scholar] [CrossRef]
- Klimesch, W. Evoked alpha and early access to the knowledge system: The P1 inhibition timing hypothesis. Brain Res. 2011, 1408, 52–71. [Google Scholar] [CrossRef] [Green Version]
- Wirzberger, M.; Herms, R.; Esmaeili Bijarsari, S.; Eibl, M.; Rey, G.D. Schema-related cognitive load influences performance, speech, and physiology in a dual-task setting: A continuous multi-measure approach. Cogn. Res. Princ. Implic. 2018, 3, 46. [Google Scholar] [CrossRef]
- Lemm, S.; Blankertz, B.; Dickhaus, T.; Müller, K.R. Introduction to machine learning for brain imaging. Multivar. Decod. Brain Read. 2011, 56, 387–399. [Google Scholar] [CrossRef] [PubMed]
- Vu, M.A.T.; Adalı, T.; Ba, D.; Buzsáki, G.; Carlson, D.; Heller, K.; Liston, C.; Rudin, C.; Sohal, V.S.; Widge, A.S.; et al. A shared vision for machine learning in neuroscience. J. Neurosci. 2018, 38, 1601. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herms, R.; Wirzberger, M.; Eibl, M.; Rey, G.D. CoLoSS: Cognitive load corpus with speech and performance data from a symbol-digit dual-task. In Proceedings of the 11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; European Language Resources Association: Miyazaki, Japan, 2018. [Google Scholar]
- Ladouce, S.; Donaldson, D.I.; Dudchenko, P.A.; Ietswaart, M. Understanding minds in real-world environments: Toward a mobile cognition approach. Front. Hum. Neurosci. 2017, 10, 694. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lavie, N. Attention, distraction, and cognitive control under load. Curr. Dir. Psychol. Sci. 2010, 19, 143–148. [Google Scholar] [CrossRef] [Green Version]
- Baddeley, A.D.; Hitch, G. Working Memory. In Psychology of Learning and Motivation; Bower, G.H., Ed.; Academic Press: Cambridge, MA, USA, 1974; Volume 8, pp. 47–89. [Google Scholar] [CrossRef]
- Soerqvist, P.; Dahlstroem, O.; Karlsson, T.; Rönnberg, J. Concentration: The neural underpinnings of how cognitive load shields against distraction. Front. Hum. Neurosci. 2016, 10, 221. [Google Scholar] [CrossRef] [Green Version]
- Anikin, A. The link between auditory salience and emotion intensity. Cogn. Emot. 2020, 34, 1246–1259. [Google Scholar] [CrossRef] [Green Version]
- Dolcos, F.; Iordan, A.D.; Dolcos, S. Neural correlates of emotion–cognition interactions: A review of evidence from brain imaging investigations. J. Cogn. Psychol. 2011, 23, 669–694. [Google Scholar] [CrossRef] [Green Version]
- D’Andrea-Penna, G.M.; Frank, S.M.; Heatherton, T.F.; Tse, P.U. Distracting tracking: Interactions between negative emotion and attentional load in multiple-object tracking. Emotion 2017, 17, 900–904. [Google Scholar] [CrossRef]
- Schweizer, S.; Satpute, A.B.; Atzil, S.; Field, A.P.; Hitchcock, C.; Black, M.; Barrett, L.F.; Dalgleish, T. The impact of affective information on working memory: A pair of meta-analytic reviews of behavioral and neuroimaging evidence. Psychol. Bull. 2019, 145, 566–609. [Google Scholar] [CrossRef]
- Banbury, S.; Berry, D.C. Disruption of office-related tasks by speech and office noise. Br. J. Psychol. 1998, 89, 499–517. [Google Scholar] [CrossRef]
- Liebl, A.; Haller, J.; Jödicke, B.; Baumgartner, H.; Schlittmeier, S.; Hellbrück, J. Combined effects of acoustic and visual distraction on cognitive performance and well-being. Appl. Ergon. 2012, 43, 424–434. [Google Scholar] [CrossRef] [PubMed]
- Vuilleumier, P.; Schwartz, S. Emotional facial expressions capture attention. Neurology 2001, 56, 153–158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Waytowich, N.R.; Lawhern, V.J.; Bohannon, A.W.; Ball, K.R.; Lance, B.J. Spectral transfer learning using information geometry for a user-independent brain–computer interface. Front. Neurosci. 2016, 10, 430. [Google Scholar] [CrossRef] [PubMed]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [Green Version]
- Lyu, B.; Pham, T.; Blaney, G.; Haga, Z.; Sassaroli, A.; Fantini, S.; Aeron, S. Domain adaptation for robust workload level alignment between sessions and subjects using fNIRS. J. Biomed. Opt. 2021, 26, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Lan, Z.; Cui, J.; Sourina, O.; Müller-Wittig, W. EEG-based cross-subject mental fatigue recognition. In Proceedings of the International Conference on Cyberworlds 2019, Kyoto, Japan, 2–4 October 2019; pp. 247–252. [Google Scholar] [CrossRef]
- Becker, R.; Stasch, S.M.; Schmitz-Hübsch, A.; Fuchs, S. Quantitative scoring system to assess performance in experimental environments. In Proceedings of the 14th International Conference on Advances in Computer-Human Interactions, Nice, France, 18–22 July 2021; ThinkMind: Nice, France, 2021; pp. 91–96. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; Volume 5, p. 1520. [Google Scholar] [CrossRef]
- Liu, H.; Gamboa, H.; Schultz, T. Sensor-Based Human Activity and Behavior Research: Where Advanced Sensing and Recognition Technologies Meet. Sensors 2022, 23, 125. [Google Scholar] [CrossRef]
- The Pacific Science Engineering Group. Warship Commander 4.4; The Pacific Science Engineering Group: San Diego, CA, USA, 2003. [Google Scholar]
- St John, M.; Kobus, D.A.; Morrison, J.G. DARPA Augmented Cognition Technical Integration Experiment (TIE); Technical Report ADA420147; Pacific Science and Engineering Group: San Diego, CA, USA, 2003. [Google Scholar]
- Toet, A.; Kaneko, D.; Ushiama, S.; Hoving, S.; de Kruijf, I.; Brouwer, A.M.; Kallen, V.; van Erp, J.B.F. EmojiGrid: A 2D pictorial scale for the assessment of food elicited emotions. Front. Psychol. 2018, 9, 2396. [Google Scholar] [CrossRef] [Green Version]
- Cardoso, B.; Romão, T.; Correia, N. CAAT: A discrete approach to emotion assessment. In Proceedings of the Extended Abstracts on Human Factors in Computing Systems; Association for Computing Machinery: Paris, France, 2013; pp. 1047–1052. [Google Scholar] [CrossRef]
- Rammstedt, B.; John, O.P. Kurzversion des Big Five Inventory (BFI-K). Diagnostica 2005, 51, 195–206. [Google Scholar] [CrossRef]
- Laux, L.; Glanzmann, P.; Schaffner, P.; Spielberger, C.D. Das State-Trait-Angstinventar; Beltz: Weinheim, Germany, 1981. [Google Scholar]
- Bankstahl, U.; Görtelmeyer, R. APSA: Attention and Performance Self-Assessment— deutsche Fassung; Fragebogen; Elektronisches Testarchiv, ZPID (Leibniz Institute for Psychology Information)–Testarchiv: Trier, Germany, 2013. [Google Scholar]
- Hartmann, A.S.; Rief, W.; Hilbert, A. Psychometric properties of the German version of the Barratt Impulsiveness Scale, Version 11 (BIS–11) for adolescents. Percept. Mot. Ski. 2011, 112, 353–368. [Google Scholar] [CrossRef]
- Scheunemann, J.; Unni, A.; Ihme, K.; Jipp, M.; Rieger, J.W. Demonstrating brain-level interactions between visuospatial attentional demands and working memory load while driving using functional near-infrared spectroscopy. Front. Hum. Neurosci. 2019, 12, 542. [Google Scholar] [CrossRef] [PubMed]
- Zimeo Morais, G.A.; Balardin, J.B.; Sato, J.R. fNIRS Optodes’ Location Decider (fOLD): A toolbox for probe arrangement guided by brain regions-of-interest. Sci. Rep. 2018, 8, 3341. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dink, J.W.; Ferguson, B. eyetrackingR: An R Library for Eye-Tracking Data Analysis. 2015. Available online: http://www.eyetrackingr.com (accessed on 4 March 2022).
- Forbes, S. PupillometryR: An R package for preparing and analysing pupillometry data. J. Open Source Softw. 2020, 5, 2285. [Google Scholar] [CrossRef]
- Jackson, I.; Sirois, S. Infant cognition: Going full factorial with pupil dilation. Dev. Sci. 2009, 12, 670–679. [Google Scholar] [CrossRef] [PubMed]
- von der Malsburg, T. saccades: Detection of Fixations in Eye-Tracking Data. 2015. Available online: https://github.com/tmalsburg/saccades (accessed on 4 March 2022).
- Gramfort, A.; Luessi, M.; Larson, E.; Engemann, D.A.; Strohmeier, D.; Brodbeck, C.; Parkkonen, L.; Hämäläinen, M.S. MNE Software for Processing MEG and EEG Data. NeuroImage 2014, 86, 446–460. [Google Scholar] [CrossRef] [Green Version]
- Luke, R.; Larson, E.D.; Shader, M.J.; Innes-Brown, H.; Van Yper, L.; Lee, A.K.C.; Sowman, P.F.; McAlpine, D. Analysis methods for measuring passive auditory fNIRS responses generated by a block-design paradigm. Neurophotonics 2021, 8, 025008. [Google Scholar] [CrossRef]
- Yücel, M.A.; Lühmann, A.v.; Scholkmann, F.; Gervain, J.; Dan, I.; Ayaz, H.; Boas, D.; Cooper, R.J.; Culver, J.; Elwell, C.E.; et al. Best practices for fNIRS publications. Neurophotonics 2021, 8, 012101. [Google Scholar] [CrossRef]
- Pollonini, L.; Olds, C.; Abaya, H.; Bortfeld, H.; Beauchamp, M.S.; Oghalai, J.S. Auditory cortex activation to natural speech and simulated cochlear implant speech measured with functional near-infrared spectroscopy. Hear. Res. 2014, 309, 84–93. [Google Scholar] [CrossRef] [Green Version]
- Fishburn, F.A.; Ludlum, R.S.; Vaidya, C.J.; Medvedev, A.V. Temporal Derivative Distribution Repair (TDDR): A motion correction method for fNIRS. NeuroImage 2019, 184, 171–179. [Google Scholar] [CrossRef]
- Saager, R.B.; Berger, A.J. Direct characterization and removal of interfering absorption trends in two-layer turbid media. J. Opt. Soc. Am. A 2005, 22, 1874–1882. [Google Scholar] [CrossRef] [Green Version]
- Beer, A. Bestimmung der Absorption des rothen Lichts in farbigen Flüssigkeiten. Annalen der Physik und Chemie 1852, 86, 78–88. [Google Scholar] [CrossRef] [Green Version]
- Schiratti, J.B.; Le Douget, J.E.; Le Van Quyen, M.; Essid, S.; Gramfort, A. An ensemble learning approach to detect epileptic seizures from long intracranial EEG recordings. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing 2018, Calgary, AB, Canada, 15–20 April 2018; pp. 856–860. [Google Scholar] [CrossRef] [Green Version]
- Keles, H.O.; Cengiz, C.; Demiral, I.; Ozmen, M.M.; Omurtag, A. High density optical neuroimaging predicts surgeons’s subjective experience and skill levels. PLOS ONE 2021, 16, e0247117. [Google Scholar] [CrossRef] [PubMed]
- Minkley, N.; Xu, K.M.; Krell, M. Analyzing relationships between causal and assessment factors of cognitive load: Associations between objective and subjective measures of cognitive load, stress, interest, and self-concept. Front. Educ. 2021, 6, 632907. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3, 638. [Google Scholar] [CrossRef]
- Cumming, G.; Finch, S. Inference by eye: Confidence intervals and how to read pictures of data. Am. Psychol. 2005, 60, 170–180. [Google Scholar] [CrossRef] [Green Version]
- Ranchet, M.; Morgan, J.C.; Akinwuntan, A.E.; Devos, H. Cognitive workload across the spectrum of cognitive impairments: A systematic review of physiological measures. Neurosci. Biobehav. Rev. 2017, 80, 516–537. [Google Scholar] [CrossRef] [Green Version]
- Matthews, G.; De Winter, J.; Hancock, P.A. What do subjective workload scales really measure? Operational and representational solutions to divergence of workload measures. Theor. Issues Ergon. Sci. 2020, 21, 369–396. [Google Scholar] [CrossRef] [Green Version]
- Causse, M.; Chua, Z.; Peysakhovich, V.; Del Campo, N.; Matton, N. Mental workload and neural efficiency quantified in the prefrontal cortex using fNIRS. Sci. Rep. 2017, 7, 5222. [Google Scholar] [CrossRef] [Green Version]
- Allison, B.Z.; Neuper, C. Could anyone use a BCI? In Brain-Computer Interfaces: Applying our Minds to Human-Computer Interaction; Tan, D.S., Nijholt, A., Eds.; Springer: London, UK, 2010; pp. 35–54. [Google Scholar] [CrossRef]
- de Cheveigné, A.; Di Liberto, G.M.; Arzounian, D.; Wong, D.D.; Hjortkjær, J.; Fuglsang, S.; Parra, L.C. Multiway canonical correlation analysis of brain data. NeuroImage 2019, 186, 728–740. [Google Scholar] [CrossRef] [Green Version]
- Bzdok, D.; Meyer-Lindenberg, A. Machine learning for precision psychiatry: Opportunities and challenges. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2018, 3, 223–230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwyer, D.B.; Falkai, P.; Koutsouleris, N. Machine learning approaches for clinical psychology and psychiatry. Annu. Rev. Clin. Psychol. 2018, 14, 91–118. [Google Scholar] [CrossRef] [PubMed]
- Cearns, M.; Hahn, T.; Baune, B.T. Recommendations and future directions for supervised machine learning in psychiatry. Transl. Psychiatry 2019, 9, 271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Orrù, G.; Monaro, M.; Conversano, C.; Gemignani, A.; Sartori, G. Machine learning in psychometrics and psychological research. Front. Psychol. 2020, 10, 2970. [Google Scholar] [CrossRef] [Green Version]
- Lashgari, E.; Liang, D.; Maoz, U. Data augmentation for deep-learning-based electroencephalography. J. Neurosci. Methods 2020, 346, 108885. [Google Scholar] [CrossRef]
- Bird, J.J.; Pritchard, M.; Fratini, A.; Ekárt, A.; Faria, D.R. Synthetic biological signals machine-generated by GPT-2 improve the classification of EEG and EMG through data augmentation. IEEE Robot. Autom. Lett. 2021, 6, 3498–3504. [Google Scholar] [CrossRef]
- Zanini, R.A.; Colombini, E.L. Parkinson’s disease EMG data augmentation and simulation with DCGANs and Style Transfer. Sensors 2020, 20, 2605. [Google Scholar] [CrossRef]
- Abrams, M.B.; Bjaalie, J.G.; Das, S.; Egan, G.F.; Ghosh, S.S.; Goscinski, W.J.; Grethe, J.S.; Kotaleski, J.H.; Ho, E.T.W.; Kennedy, D.N.; et al. A standards organization for open and FAIR neuroscience: The international neuroinformatics coordinating facility. Neuroinformatics 2021, 20, 25–36. [Google Scholar] [CrossRef]
- von Lühmann, A.; Boukouvalas, Z.; Müller, K.R.; Adalı, T. A new blind source separation framework for signal analysis and artifact rejection in functional near-infrared spectroscopy. NeuroImage 2019, 200, 72–88. [Google Scholar] [CrossRef]
- Friedman, N.; Fekete, T.; Gal, K.; Shriki, O. EEG-based prediction of cognitive load in intelligence tests. Front. Hum. Neurosci. 2019, 13, 191. [Google Scholar] [CrossRef] [PubMed]
- Unni, A.; Ihme, K.; Jipp, M.; Rieger, J.W. Assessing the driver’s current level of working memory load with high density functional near-infrared spectroscopy: A realistic driving simulator study. Front. Hum. Neurosci. 2017, 11, 167. [Google Scholar] [CrossRef] [Green Version]
- García-Pacios, J.; Garcés, P.; del Río, D.; Maestú, F. Tracking the effect of emotional distraction in working memory brain networks: Evidence from an MEG study. Psychophysiology 2017, 54, 1726–1740. [Google Scholar] [CrossRef] [PubMed]
- Curtis, C. Prefrontal and parietal contributions to spatial working memory. Neuroscience 2006, 139, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Vázquez, P.; Gail, A. Directed interaction between monkey premotor and posterior parietal cortex during motor-goal retrieval from working memory. Cereb. Cortex 2018, 28, 1866–1881. [Google Scholar] [CrossRef] [PubMed]
- Vanneste, P.; Raes, A.; Morton, J.; Bombeke, K.; Van Acker, B.B.; Larmuseau, C.; Depaepe, F.; Van den Noortgate, W. Towards measuring cognitive load through multimodal physiological data. Cogn. Technol. Work 2021, 23, 567–585. [Google Scholar] [CrossRef]
- Yap, T.F.; Epps, J.; Ambikairajah, E.; Choi, E.H. Voice source under cognitive load: Effects and classification. Speech Commun. 2015, 72, 74–95. [Google Scholar] [CrossRef]
- Marquart, G.; Cabrall, C.; de Winter, J. Review of eye-related measures of drivers’ mental workload. Procedia Manuf. 2015, 3, 2854–2861. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Lo, J.C.; Sehic, E.; Meijer, S.A. Measuring mental workload with low-cost and wearable sensors: Insights into the accuracy, obtrusiveness, and research usability of three instruments. J. Cogn. Eng. Decis. Mak. 2017, 11, 323–336. [Google Scholar] [CrossRef] [Green Version]
- Tsow, F.; Kumar, A.; Hosseini, S.H.; Bowden, A. A low-cost, wearable, do-it-yourself functional near-infrared spectroscopy (DIY-fNIRS) headband. HardwareX 2021, 10, e00204. [Google Scholar] [CrossRef]
- Niso, G.; Romero, E.; Moreau, J.T.; Araujo, A.; Krol, L.R. Wireless EEG: A survey of systems and studies. NeuroImage 2023, 269, 119774. [Google Scholar] [CrossRef]
- Mantuano, A.; Bernardi, S.; Rupi, F. Cyclist gaze behavior in urban space: An eye-tracking experiment on the bicycle network of Bologna. Case Stud. Transp. Policy 2017, 5, 408–416. [Google Scholar] [CrossRef]
- Ahmadi, N.; Sasangohar, F.; Yang, J.; Yu, D.; Danesh, V.; Klahn, S.; Masud, F. Quantifying workload and stress in intensive care unit nurses: Preliminary evaluation using continuous eye-tracking. Hum. Factors 2022, 00187208221085335. [Google Scholar] [CrossRef] [PubMed]
- Gottemukkula, V.; Derakhshani, R. Classification-guided feature selection for NIRS-based BCI. In Proceedings of the 5th International IEEE/EMBS Conference on Neural Engineering 2011, Cancun, Mexico, 27 April–1 May 2011; pp. 72–75. [Google Scholar] [CrossRef]
- Aydin, E.A. Subject-Specific feature selection for near infrared spectroscopy based brain–computer interfaces. Comput. Methods Programs Biomed. 2020, 195, 105535. [Google Scholar] [CrossRef]
- Chakraborty, S.; Aich, S.; Joo, M.i.; Sain, M.; Kim, H.C. A multichannel convolutional neural network architecture for the detection of the state of mind using physiological signals from wearable devices. J. Healthc. Eng. 2019, 2019, 5397814. [Google Scholar] [CrossRef] [Green Version]
- Asgher, U.; Khalil, K.; Khan, M.J.; Ahmad, R.; Butt, S.I.; Ayaz, Y.; Naseer, N.; Nazir, S. Enhanced accuracy for multiclass mental workload detection using long short-term memory for brain–computer interface. Front. Neurosci. 2020, 14, 584. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Features |
|---|---|
| Brain Activity | Mean, standard deviation, peak-to-peak (PTP) amplitude, skewness, and kurtosis of the 82 optical channels |
| Physiology | |
| Heart Rate | Mean, standard deviation, skewness, and kurtosis of heart rate |
| Mean, standard deviation, skewness, and kurtosis of heart rate variability | |
| Respiration | Mean, standard deviation, skewness, and kurtosis of respiration rate |
| Mean, standard deviation, skewness, and kurtosis of respiration amplitude | |
| Temperature | Mean, standard deviation, skewness, and kurtosis of body temperature |
| Ocular Measures | |
| Fixations | Number of fixations, total duration and average duration of fixations, and standard deviation of the duration of fixations |
| Pupillometry | Mean, standard deviation, skewness, and kurtosis of pupil dilation |
| Performance | Average reaction time and cumulative accuracy |
| Training Set | Test Set | |
|---|---|---|
| Chance Level | ||
| Dummy Classifier | 0.351, 95% CI [0.320; 0.379] | 0.368, 95% CI [0.284; 0.444] |
| Unimodal Predictions Based on fNIRS | ||
| LR | 0.924, 95% CI [0.889; 0.962] | 0.392, 95% CI [0.278; 0.500] |
| LDA | 0.845, 95% CI [0.840; 0.850] | 0.387, 95% CI [0.271; 0.495] |
| GNB | 0.532, 95% CI [0.469; 0.577] | 0.366, 95% CI [0.275; 0.457] |
| KNN | 1.0, 95% CI [1.0; 1.0] | 0.348, 95% CI [0.248; 0.451] |
| RFC | 0.721, 95% CI [0.667; 0.786] | 0.308, 95% CI [0.235; 0.387] |
| SVM | 0.756, 95% CI [0.644; 0.862] | 0.386, 95% CI [0.287; 0.473] |
| Unimodal Voting | 0.911, 95% CI [0.848; 0.954] | 0.401, 95% CI [0.314; 0.489] |
| Unimodal Predictions Based on Physiology | ||
| LR | 0.441, 95% CI [0.426; 0.454] | 0.354, 95% CI [0.246; 0.464] |
| LDA | 0.441, 95% CI [0.424; 0.456] | 0.341, 95% CI [0.226; 0.448] |
| GNB | 0.279, 95% CI [0.269; 0.297] | 0.231, 95% CI [0.141; 0.318] |
| KNN | 0.966, 95% CI [0.962; 0.973] | 0.377, 95% CI [0.309; 0.439] |
| RFC | 0.648, 95% CI [0.585; 0.708] | 0.327, 95% CI [0.217; 0.425] |
| SVM | 0.532, 95% CI [0.379; 0.715] | 0.366, 95% CI [0.262; 0.455] |
| Unimodal Voting | 0.767, 95% CI [0.691; 0.848] | 0.305, 95% CI [0.212; 0.396] |
| Unimodal Predictions Based on Visual Measures | ||
| LR | 0.318, 95% CI [0.287; 0.355] | 0.201, 95% CI [0.080; 0.354] |
| LDA | 0.314, 95% CI [0.285; 0.345] | 0.198, 95% CI [0.087; 0.346] |
| GNB | 0.492, 95% CI [0.472; 0.506] | 0.390, 95% CI [0.294; 0.485] |
| KNN | 1.0, 95% CI [1.0; 1.0] | 0.386, 95% CI [0.291; 0.485] |
| RFC | 0.690, 95% CI [0.658; 0.728] | 0.322, 95% CI [0.237; 0.415] |
| SVM | 0.517, 95% CI [0.422; 0.630] | 0.301, 95% CI [0.198; 0.401] |
| Unimodal Voting | 0.751, 95% CI [0.589; 0.915] | 0.354, 95% CI [0.262; 0.442] |
| Unimodal Predictions Based on Performance Measures | ||
| LR | 0.586, 95% CI [0.549; 0.624] | 0.543, 95% CI [0.399; 0.676] * |
| LDA | 0.584, 95% CI [0.548; 0.618] | 0.499, 95% CI [0.325; 0.663] * |
| GNB | 0.667, 95% CI [0.659; 0.677] | 0.661, 95% CI [0.514; 0.792] ** |
| KNN | 0.919, 95% CI [0.914; 0.924] | 0.513, 95% CI [0.367; 0.650] * |
| RFC | 0.696, 95% CI [0.686; 0.707] | 0.616, 95% CI [0.472; 0.752] ** |
| SVM | 0.679, 95% CI [0.672; 0.689] | 0.641, 95% CI [0.467; 0.799] ** |
| Unimodal Voting | 0.673, 95% CI [0.662; 0.687] | 0.656, 95% CI [0.509; 0.789] ** |
| Multimodal Predictions | ||
| LR | 0.919, 95% CI [0.892; 0.939] | 0.498, 95% CI [0.412; 0.581] * |
| RFC | 0.803, 95% CI [0.784; 0.830] | 0.617, 95% CI [0.499; 0.742] ** |
| Multimodal Voting | 0.673, 95% CI [0.663; 0.686] | 0.658, 95% CI [0.515; 0.797] ** |
| Multimodal Voting (w/o Perf.) | 0.930, 95% CI [0.905; 0.957] | 0.369, 95% CI [0.276; 0.464] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gado, S.; Lingelbach, K.; Wirzberger, M.; Vukelić, M. Decoding Mental Effort in a Quasi-Realistic Scenario: A Feasibility Study on Multimodal Data Fusion and Classification. Sensors 2023, 23, 6546. https://doi.org/10.3390/s23146546
Gado S, Lingelbach K, Wirzberger M, Vukelić M. Decoding Mental Effort in a Quasi-Realistic Scenario: A Feasibility Study on Multimodal Data Fusion and Classification. Sensors. 2023; 23(14):6546. https://doi.org/10.3390/s23146546
Chicago/Turabian StyleGado, Sabrina, Katharina Lingelbach, Maria Wirzberger, and Mathias Vukelić. 2023. "Decoding Mental Effort in a Quasi-Realistic Scenario: A Feasibility Study on Multimodal Data Fusion and Classification" Sensors 23, no. 14: 6546. https://doi.org/10.3390/s23146546
APA StyleGado, S., Lingelbach, K., Wirzberger, M., & Vukelić, M. (2023). Decoding Mental Effort in a Quasi-Realistic Scenario: A Feasibility Study on Multimodal Data Fusion and Classification. Sensors, 23(14), 6546. https://doi.org/10.3390/s23146546