
A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter


Abstract
:1. Introduction
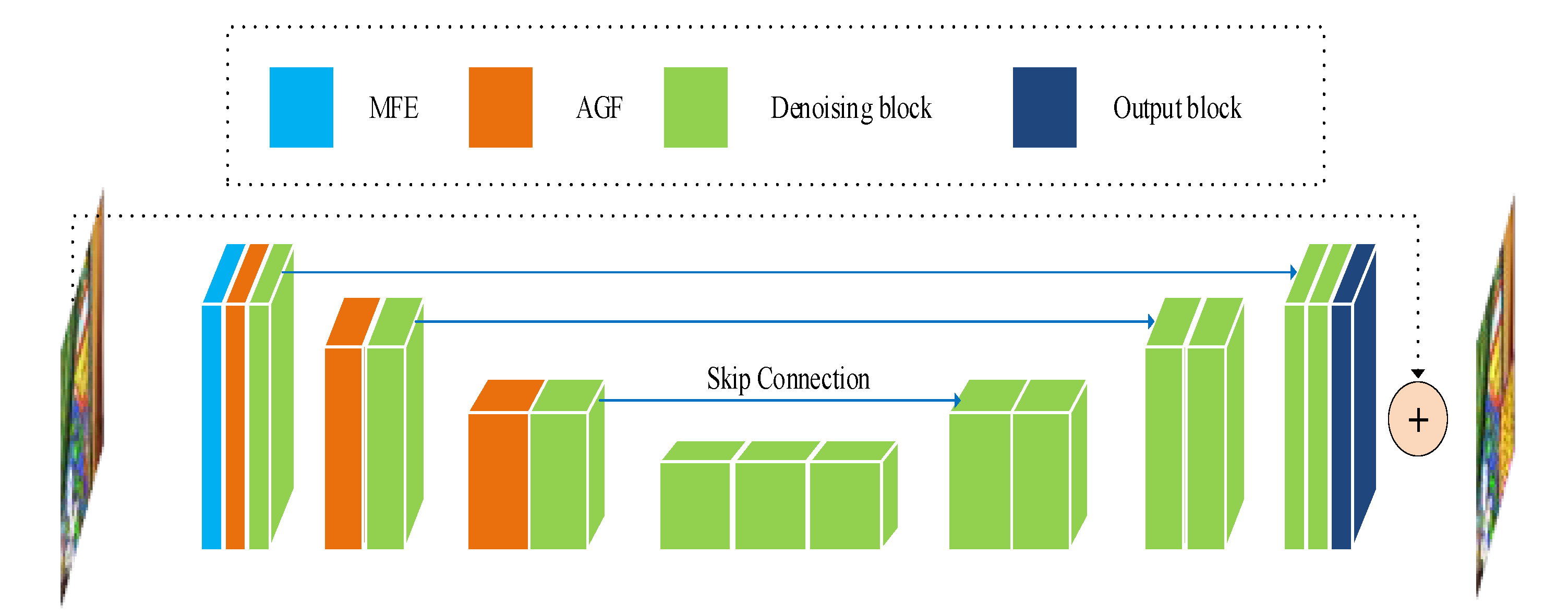
- This paper proposes the MAGUNet model, which extracts more useful features by expanding the acceptance domain, so that our model can achieve a better balance between efficiency and performance.
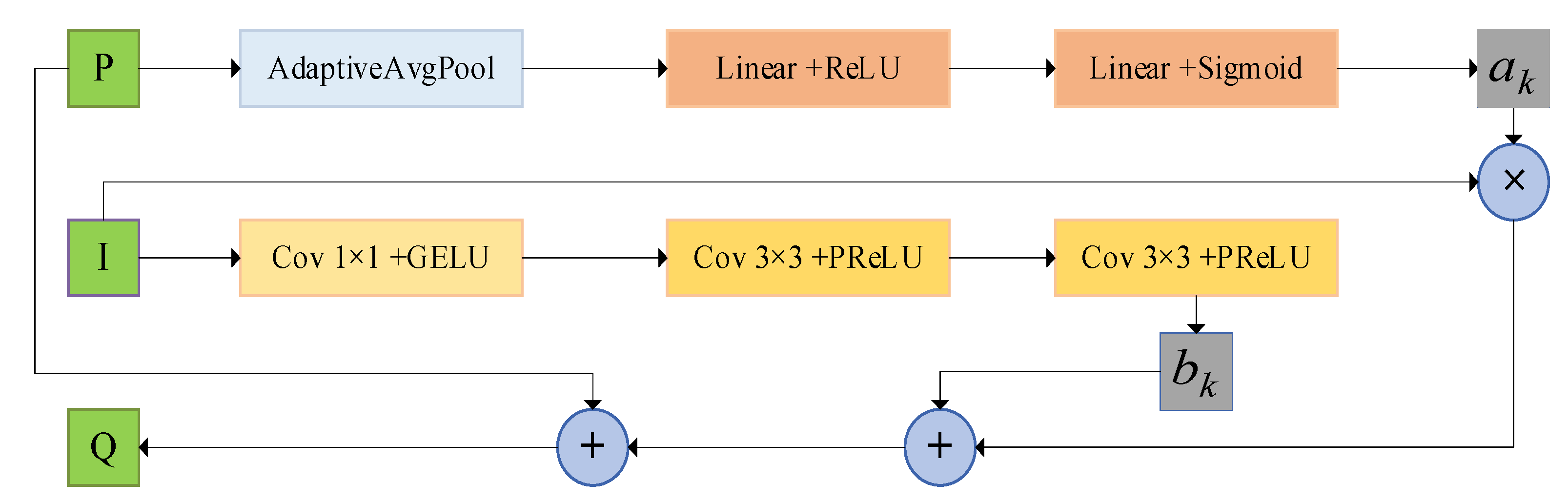
- The attention-guided filter block is designed to retain the details of the image information after each down-sampling operation.
- The experiment results demonstrate the superiority of the MAGUNet model against the competing methods.
2. Related Work
2.1. CNNs for Image Denoising
2.2. Multi-Scale Feature Extraction
2.3. Attentional Mechanisms
3. Methods
3.1. Network Structure
3.2. Main Structure Module
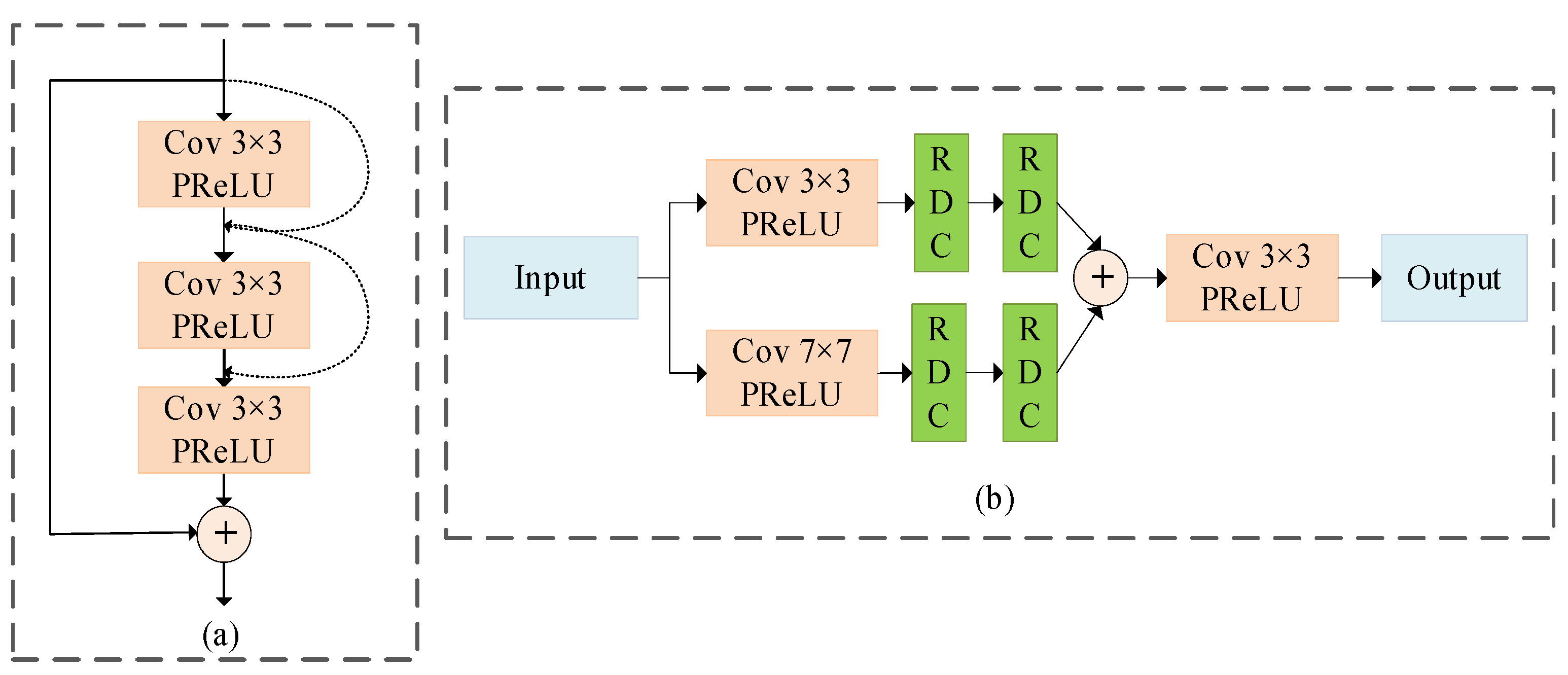
3.2.1. Multi-Scale Feature Extraction Block
3.2.2. Attention-Guided Filter Block
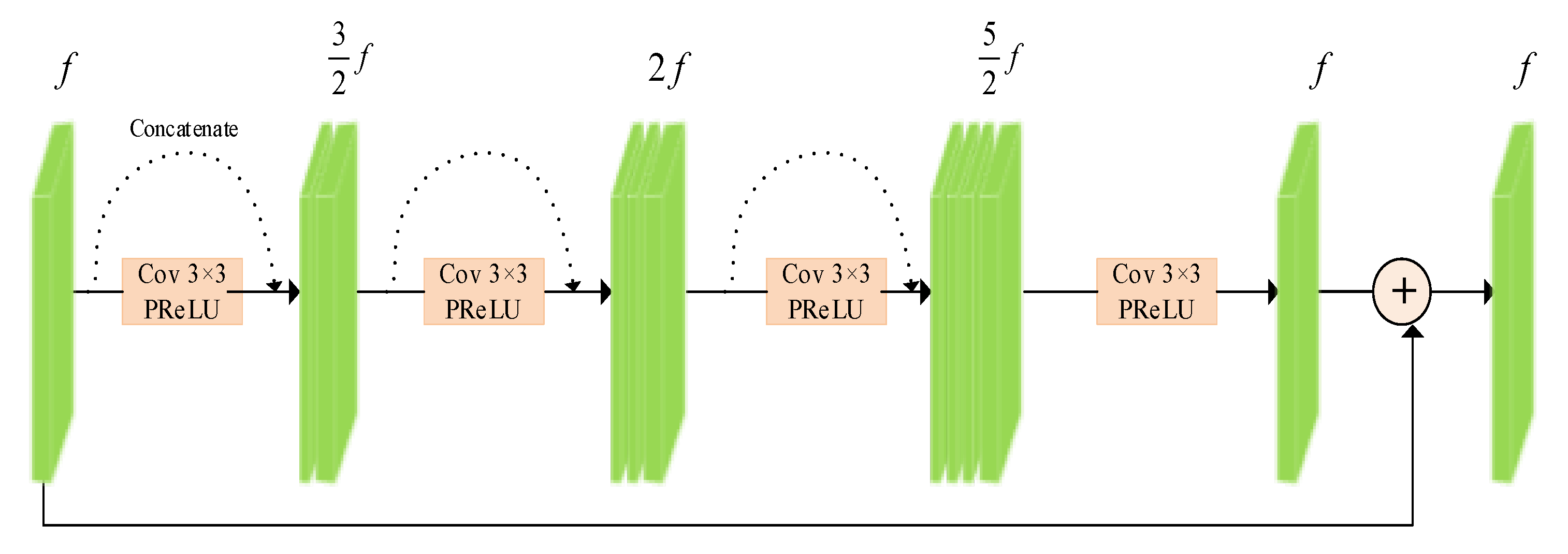
3.2.3. Residual Denoising Block
4. Results and Discussion
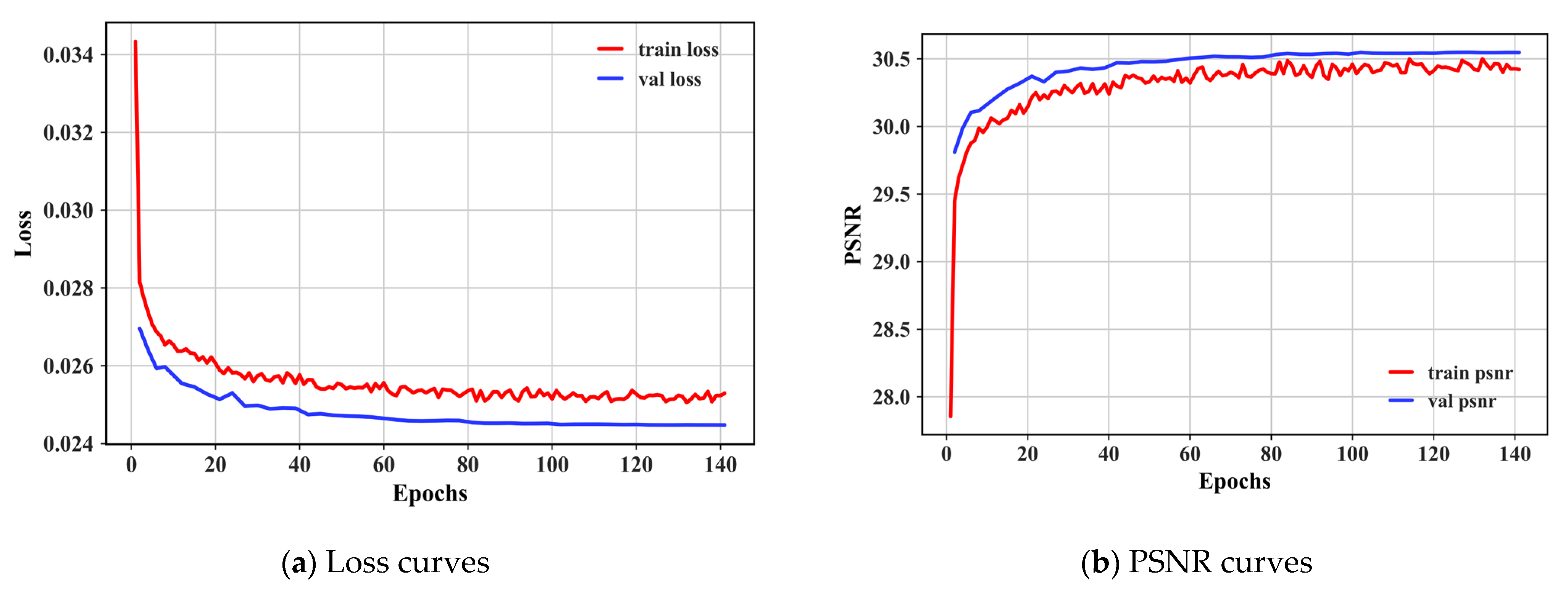
4.1. Experimental Setup
4.2. Grayscale Common Image Denoising
4.3. Color Common Image Denoising
4.4. Remote Sensing Image Denoising
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buades, A.; Coll, B.; Morel, J.-M. A non-local algorithm for image denoising. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [PubMed]
- Rabbouch, H.; Saâdaoui, F.; Vasilakos, A. A wavelet assisted subband denoising for tomographic image reconstruction. J. Vis. Commun. Image Represent. 2018, 55, 115–130. [Google Scholar]
- Kaur, G.; Kaur, R. Image de-noising using wavelet transform and various filters. Int. J. Res. Comput. Sci. 2012, 2, 15–21. [Google Scholar]
- Song, Q.; Ma, L.; Cao, J.; Han, X. Image denoising based on mean filter and wavelet transform. In Proceedings of the 2015 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Harbin, China, 21–23 August 2015; pp. 21–23. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar]
- Romano, Y.; Elad, M.; Milanfar, P. The little engine that could: Regularization by denoising (red). SIAM J. Imaging Sci. 2017, 10, 1–50. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Feng, W.; Qiao, P.; Chen, Y. Fast and accurate poisson denoising with trainable nonlinear diffusion. IEEE Trans. Cybern. 2018, 48, 1708–1719. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. MemNet: A persistent memory network for image restoration. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward convolutional blind denoising of real photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1712–1722. [Google Scholar]
- Varga, D. No-Reference Image Quality Assessment with Multi-Scale Orderless Pooling of Deep Features. J. Imaging 2021, 7, 112. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, P.; Yu, B. Boosting with the L2 loss: Regression and classification. J. Am. Stat. Assoc. 2003, 98, 324–339. [Google Scholar]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level wavelet-CNN for image restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake, UT, USA, 18–22 June 2018; pp. 773–782. [Google Scholar]
- Jain, V.; Seung, S. Natural image denoising with convolutional networks. In Proceedings of the 21st International Conference on Neural Information Processing Systems (NIPS’08), Vancouver, BC, Canada, 8–11 December 2008; Curran Associates Inc.: Red Hook, NY, USA; pp. 769–776. [Google Scholar]
- Burger, H.C.; Schuler, C.J.; Harmeling, S. Image denoising: Can plain neural networks compete with BM3D? In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2392–2399. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image blind denoising with generative adversarial network-based noise modeling. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3155–3164. [Google Scholar]
- Park, B.; Yu, S.; Jeong, J. Densely connected hierarchical network for image denoising. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2104–2113. [Google Scholar] [CrossRef]
- Yu, S.; Park, B.; Jeong, J. Deep iterative down-up CNN for image denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2095–2103. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2480–2495. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Broxz, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, S.-F.; Yu, W.-K.; Li, Y.-X. Multi-wavelet residual dense convolutional neural network for image denoising. IEEE Access 2020, 8, 214413–214424. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Sun, L.; Yan, C.; Ji, X.; Dai, Q. Adaptive residual networks for high-quality image restoration. IEEE Trans. Image Process. 2018, 27, 3150–3163. [Google Scholar]
- Gurrola-Ramos, J.; Dalmau, O.; Alarcón, T.E. A residual dense U-Net neural network for image denoising. IEEE Access 2021, 9, 31742–31754. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Wei, Y.; Yang, Y. Collaborative video object segmentation by multi-scale foreground-background integration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4701–4712. [Google Scholar] [CrossRef]
- Gou, Y.; Hu, P.; Lv, J.; Peng, X. Multi-scale adaptive network for single image denoising. Adv. Neural Inf. Process. Syst. 2022, 35, 14099–14112. [Google Scholar]
- Zou, P.; Teng, Y.; Niu, T. Multi scale feature extraction and fusion for online knowledge distillation. In Proceedings of the International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022; Springer: Cham, Switzerland, 2022; Volume 13532. [Google Scholar] [CrossRef]
- Li, Z.; Liu, Y.; Shu, H.; Lu, J.; Kang, J.; Chen, Y.; Gui, Z. Multi-scale feature fusion network for low-dose CT denoising. J. Digit Imaging 2023, 36, 1808–1825. [Google Scholar] [CrossRef]
- Zhu, Z.; Wu, W.; Zou, W.; Yan, J. End-to-end flow correlation tracking with spatial-temporal attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 548–557. [Google Scholar] [CrossRef] [Green Version]
- Karri, M.; Annavarapu, C.S.R.; Acharya, U.R. Explainable multi-module semantic guided attention-based network for medical image segmentation. Comput. Biol. Med. 2022, 151, 106231. [Google Scholar] [CrossRef]
- Fan, S.; Liang, W.; Ding, D.; Yu, H. LACN: A lightweight attention-guided ConvNeXt network for low-light image enhancement. Eng. Appl. Artif. Intell. 2023, 117, 105632. [Google Scholar]
- Yan, X.; Qin, W.; Wang, Y.; Wang, G.; Fu, X. Attention-guided dynamic multi-branch neural network for underwater image enhancement. Knowl.-Based Syst. 2022, 258, 110041. [Google Scholar]
- Wang, J.; Yu, L.; Tian, S.; Wu, W.; Zhang, D. AMFNet: An attention-guided generative adversarial network for multi-model image fusion. Biomed. Signal Process. Control 2022, 78, 103990. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 6, 1397–1409. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1838–1847. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Gong, Y.; Qiu, G. Guided filter bank. In Intelligent Computing: Proceedings of the 2021 Computing Conference; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2021; Volume 1, pp. 783–792. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Roth, S.; Black, M. Fields of Experts: A framework for learning image priors. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 860–867. [Google Scholar]
- Franzen, R. Kodak Lossless True Color Image Suite: PhotoCD PCD0992. Available online: http://r0k.us/graphics/kodak (accessed on 14 July 2023).
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Sheikh, H.; Sabir, M.; Bovik, A. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 023016. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method\Gray | Set12 | BSD68 | Kodak24 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.00 | 30.00 | 50.00 | 10.00 | 30.00 | 50.00 | 10.00 | 30.00 | 50.00 | ||||||||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 34.08 | 0.9204 | 28.69 | 0.8199 | 26.18 | 0.7411 | 33.16 | 0.9160 | 27.59 | 0.7671 | 25.41 | 0.6722 | 34.07 | 0.9113 | 28.68 | 0.7779 | 26.42 | 0.6918 |
| DnCNN | 34.52 | 0.9241 | 29.52 | 0.8422 | 27.18 | 0.7816 | 33.73 | 0.9241 | 28.35 | 0.7982 | 26.23 | 0.7164 | 34.68 | 0.9207 | 29.52 | 0.8082 | 27.39 | 0.7364 |
| IRCNN | 34.71 | 0.9272 | 29.45 | 0.8393 | 27.12 | 0.7804 | 33.75 | 0.9263 | 28.27 | 0.7993 | 26.19 | 0.7169 | 34.67 | 0.9212 | 29.42 | 0.8064 | 27.33 | 0.7354 |
| FFDnet | 34.64 | 0.9270 | 29.60 | 0.8464 | 27.30 | 0.7899 | 33.77 | 0.9266 | 28.39 | 0.8031 | 26.29 | 0.7239 | 34.72 | 0.9223 | 29.58 | 0.8122 | 27.49 | 0.7434 |
| ADNet | 34.63 | 0.9247 | 29.62 | 0.8449 | 27.29 | 0.7874 | 33.65 | 0.9216 | 28.32 | 0.7949 | 26.22 | 0.7148 | 34.67 | 0.9200 | 29.51 | 0.8066 | 27.4 | 0.7367 |
| RDUNet | 34.99 | 0.9315 | 29.96 | 0.8552 | 27.72 | 0.8044 | 33.97 | 0.9297 | 28.58 | 0.8099 | 26.48 | 0.7346 | 35.00 | 0.9262 | 29.86 | 0.8228 | 27.78 | 0.7577 |
| MSANet | \ | \ | 30.00 | 0.8366 | 27.72 | 0.7864 | \ | \ | 28.62 | 0.7939 | 26.52 | 0.7229 | \ | \ | 29.91 | 0.8112 | 27.82 | 0.7516 |
| Ours | 35.03 | 0.9320 | 29.96 | 0.8548 | 27.70 | 0.8044 | 33.99 | 0.9298 | 28.56 | 0.8081 | 26.45 | 0.7318 | 35.04 | 0.9263 | 29.86 | 0.8222 | 27.75 | 0.7559 |
| Ours+ | 35.07 | 0.9324 | 30.01 | 0.8556 | 27.76 | 0.8057 | 34.02 | 0.9301 | 28.59 | 0.8090 | 26.48 | 0.7329 | 35.08 | 0.9267 | 29.91 | 0.8233 | 27.81 | 0.7574 |
| Method\Color | Set5 | LIVE1 | McMaster | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 30 | 50 | 10 | 30 | 50 | 10 | 30 | 50 | ||||||||||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 36.02 | 0.9392 | 30.93 | 0.8592 | 28.69 | 0.8092 | 35.82 | 0.9484 | 30.08 | 0.8542 | 27.66 | 0.7816 | 35.91 | 0.9336 | 30.84 | 0.8512 | 28.54 | 0.79 |
| DnCNN | 35.74 | 0.9321 | 31.15 | 0.864 | 28.96 | 0.8146 | 35.69 | 0.9485 | 30.35 | 0.864 | 27.95 | 0.7951 | 34.79 | 0.9226 | 30.79 | 0.854 | 28.62 | 0.7986 |
| IRCNN | 36.13 | 0.9392 | 31.17 | 0.8655 | 29.00 | 0.8172 | 36.00 | 0.9497 | 30.36 | 0.8648 | 27.97 | 0.7979 | 36.45 | 0.9406 | 31.31 | 0.8642 | 28.93 | 0.8069 |
| FFDNet | 36.16 | 0.9397 | 31.35 | 0.8689 | 29.24 | 0.8252 | 36.07 | 0.9508 | 30.49 | 0.8663 | 28.10 | 0.7988 | 36.45 | 0.9414 | 31.53 | 0.8701 | 29.19 | 0.8149 |
| ADNet | 35.97 | 0.9355 | 31.21 | 0.8664 | 28.99 | 0.8158 | 35.97 | 0.9501 | 30.37 | 0.8639 | 27.93 | 0.792 | 36.27 | 0.939 | 31.33 | 0.8658 | 29.03 | 0.936 |
| RDUNet | 36.54 | 0.9422 | 31.83 | 0.8797 | 29.69 | 0.8398 | 36.51 | 0.9546 | 31.00 | 0.8789 | 28.64 | 0.8195 | 36.95 | 0.9469 | 32.09 | 0.885 | 29.79 | 0.8378 |
| MSANet | \ | \ | 31.83 | 0.8865 | 29.69 | 0.8437 | \ | \ | 30.96 | 0.8816 | 28.64 | 0.8224 | \ | \ | 32.10 | 0.8884 | 29.82 | 0.8409 |
| Ours | 36.57 | 0.9426 | 31.84 | 0.8786 | 29.72 | 0.8387 | 36.54 | 0.9546 | 31.01 | 0.8782 | 28.64 | 0.8181 | 37.05 | 0.9477 | 32.13 | 0.8851 | 29.82 | 0.8373 |
| Ours+ | 36.61 | 0.9429 | 31.89 | 0.8795 | 29.76 | 0.8396 | 36.58 | 0.9549 | 31.06 | 0.8790 | 28.70 | 0.8192 | 37.11 | 0.9483 | 32.20 | 0.8864 | 29.90 | 0.8393 |
| Method | 10 | 30 | 50 | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| BM3D | 36.81 | 0.9416 | 31.51 | 0.8349 | 29.30 | 0.7579 |
| DnCNN | 36.71 | 0.9401 | 31.49 | 0.8336 | 29.32 | 0.7588 |
| IRCNN | 36.75 | 0.9408 | 31.43 | 0.8333 | 29.31 | 0.7607 |
| FFDNet | 36.81 | 0.9415 | 31.58 | 0.8348 | 29.43 | 0.7600 |
| ADNet | 36.76 | 0.9408 | 31.49 | 0.8325 | 29.31 | 0.7553 |
| RDUNet | 37.06 | 0.9446 | 31.96 | 0.8482 | 29.87 | 0.7814 |
| Ours | 37.25 | 0.9462 | 32.04 | 0.8500 | 29.90 | 0.7822 |
| Ours+ | 37.28 | 0.9466 | 32.07 | 0.8509 | 29.95 | 0.7838 |
| Case 0 | Case 1 | Case 2 | Case 3 | Case 4 | |
|---|---|---|---|---|---|
| MFE | √ | × | √ | × | × |
| RDB | √ | √ | √ | √ | √ |
| AGF | √ | √ | × | × | × |
| PSNR | 29.8235 | 29.8107 | 29.7970 | 29.7907 | 29.7895 |
| SSIM | 0.8373 | 0.8360 | 0.8347 | 0.8328 | 0.8327 |
| Complexity | 2.61 GMac | 2.26 GMac | 2.55 GMac | 2.20 GMac | 2.48 GMac |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, Z.; Lin, S.; Cheng, L. A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter. Sensors 2023, 23, 7044. https://doi.org/10.3390/s23167044
Liu H, Li Z, Lin S, Cheng L. A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter. Sensors. 2023; 23(16):7044. https://doi.org/10.3390/s23167044
Chicago/Turabian StyleLiu, Hualin, Zhe Li, Shijie Lin, and Libo Cheng. 2023. "A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter" Sensors 23, no. 16: 7044. https://doi.org/10.3390/s23167044
APA StyleLiu, H., Li, Z., Lin, S., & Cheng, L. (2023). A Residual UNet Denoising Network Based on Multi-Scale Feature Extraction and Attention-Guided Filter. Sensors, 23(16), 7044. https://doi.org/10.3390/s23167044