1. Introduction
Spectroscopy has received much attention in the last two decades and been used in many fields, such as food, pharmaceuticals, chemical analysis, environmental monitoring, and precision agriculture [
1].
However, high-resolution spectral data overlap with extensive data redundancy and contain many bands of information unrelated to the measured components, adversely affecting the modeling effect. Thus, accurately extracting valuable features from the “high-dimensional” spectral information for modeling has become particularly important and is an urgent problem to be optimized and solved in this field of research.
The simulated annealing (SA) algorithm was first developed by N. Metropolis et al. in 1953 [
2]. In 1983, S. Kirkpatrick [
3,
4] and others successfully introduced the idea of annealing into combinatorial optimization. It is a stochastic global-search combinatorial optimization method with the feature of fast global optimization. The SA algorithm considers spectral characteristics from the global view of data and extracts features in an optimized combination. It avoids overfitting the model training owing to less feature information. It does not transform the original data information, thus ensuring the correct interpretation of the meaning of the data information. However, the SA algorithm tends to have slow convergence when solving larger-scale combinatorial optimization practical problems. Moreover, the information in the optimization results is often unrelated to or has a weak correlation with the dependent variable. Many scholars have combined their research areas to improve the SA algorithm. Xiutang Geng [
5] et al. used three different probability combinations based on the standard SA algorithm in the search process. They then used greedy search techniques to speed up the algorithm’s convergence. Dimitris N. Simopoulos [
6] et al. combined the SA algorithm with a dynamic economic scheduling method. They proposed new rules concerning the adjustment of the control parameters of the SA algorithm. Bernardo Morales-Castañeda [
7] et al. modified the original SA incorporating two new operators, folding and reheating, to improve its search capability. Eduardo Rodriguez-Tello [
8] et al. proposed a SA algorithm for solving the graph bandwidth minimization problem. The algorithm is based on three salient features, including the original internal representation of the solution, a highly discriminative evaluation function, and an effective neighborhood. When the SA algorithm is used for spectral feature extraction, the algorithm still has slow convergence and poor stability, resulting in low modeling accuracy. Still, there are a few reports of optimization improvements for its use in spectral feature extraction.
The SA algorithm uses random substitution in the global optimization process to update the spectral feature combinations, which has a high probability of causing unrelated or weakly correlated information with the dependent variable to enter the feature combinations. The SA algorithm itself cannot discriminate correlations. Moreover, the algorithm relies only on global optimization, which can lead to the problem of jumping out of important bands too quickly when updating combinations, leading to poor modeling results.
The Boruta algorithm is a wrapper method built around a random forest classifier and is widely used in feature extraction [
9]. Shaheen et al. used geostatistical methods to assess the spatial distribution of the heavy metals, chromium (Cr), cadmium (Cd), and lead (Pb), at three soil depths and used the random forest (RF) function of the Boruta algorithm to select the significant contributing variables to soil contamination [
10]. Subbiah S et al. overcame the problem of poor accuracy and misclassification of network intrusion detection by the Boruta feature selection and grid search random forest (BFS-GSRF) algorithm [
11]. Kent B et al. used the Boruta algorithm to successfully find the impedance spectrum characteristics of the studied biological tissue [
12]. Modeling accuracy cannot be relied upon as the sole criterion for judging the importance of features. The decrease in modeling accuracy after removing features is enough to show the importance of features, but the lack of this effect is not enough to show that it is not essential. The Boruta algorithm determines the variable correlation by comparing the correlation between real features and shaded features. It iteratively removes irrelevant information that is proven by statistical validation and can select all sets of features relevant to the dependent variable, helping the algorithmic model more fully understand the factors influencing the dependent variable. Therefore, the Boruta algorithm was chosen to determine the importance of feature information in this study.
To address the above problems, this paper introduces the “Boruta algorithm-based local optimization process” based on the traditional simulated annealing algorithm. It proposes the two-step simulated annealing algorithm (TSSA) for spectral feature extraction. The TSSA algorithm combines global optimization and local optimization to improve modeling accuracy while ensuring that the search results are free of weakly correlated bands, reducing the redundancy of extracted features and improving model stability.
The organization of the paper is as follows.
Section 1 is an introduction. This chapter introduces the main factors that currently limit the detection accuracy of high-resolution spectral data, describes the simulated annealing algorithm’s advantages and shortcomings, and introduces this paper’s research content and research methods in response to these problems.
Section 2 first analyzes the main reasons for the poor performance of the traditional simulated annealing algorithm in practice and proposes the TSSA algorithm for these main reasons. The principle of the TSSA algorithm, the structure of the algorithm, and the steps of how the algorithm processes data are detailed.
Section 3 describes the dataset source and acquisition. First, the experimental conditions and experimental apparatus are described. Then, the detailed operational steps for collecting spectral data and the chemical assay for chlorophyll a (Chla, μg/L) concentration of the samples are described.
Section 4 introduces the data processing approach and operating procedures to establish a quantitative inversion algorithm for cyanobacterial Chla in eutrophic shallow-water lakes and discusses the modeling accuracy. Six approaches are used in the feature extraction section. The experimental results are discussed to demonstrate the superiority of the TSSA algorithm proposed in this paper.
Section 5 summarizes the research content of this paper and shares the future outlook.
2. Two-Step Simulated Annealing Algorithm
According to the characteristics of high-dimensional spectral data, there are two main reasons for the unsatisfactory effect of the SA algorithm in spectral feature extraction: (1) The presence of information in the spectral band combination is unrelated or weakly correlated with the dependent variable; (2) The algorithm is globally optimized to jump out of important information too quickly when randomly updating the wave combinations. To address the above problems, this paper introduces a Boruta algorithm-based local optimization process based on the traditional SA algorithm. The new algorithm is called the two-step simulated annealing algorithm (TSSA).
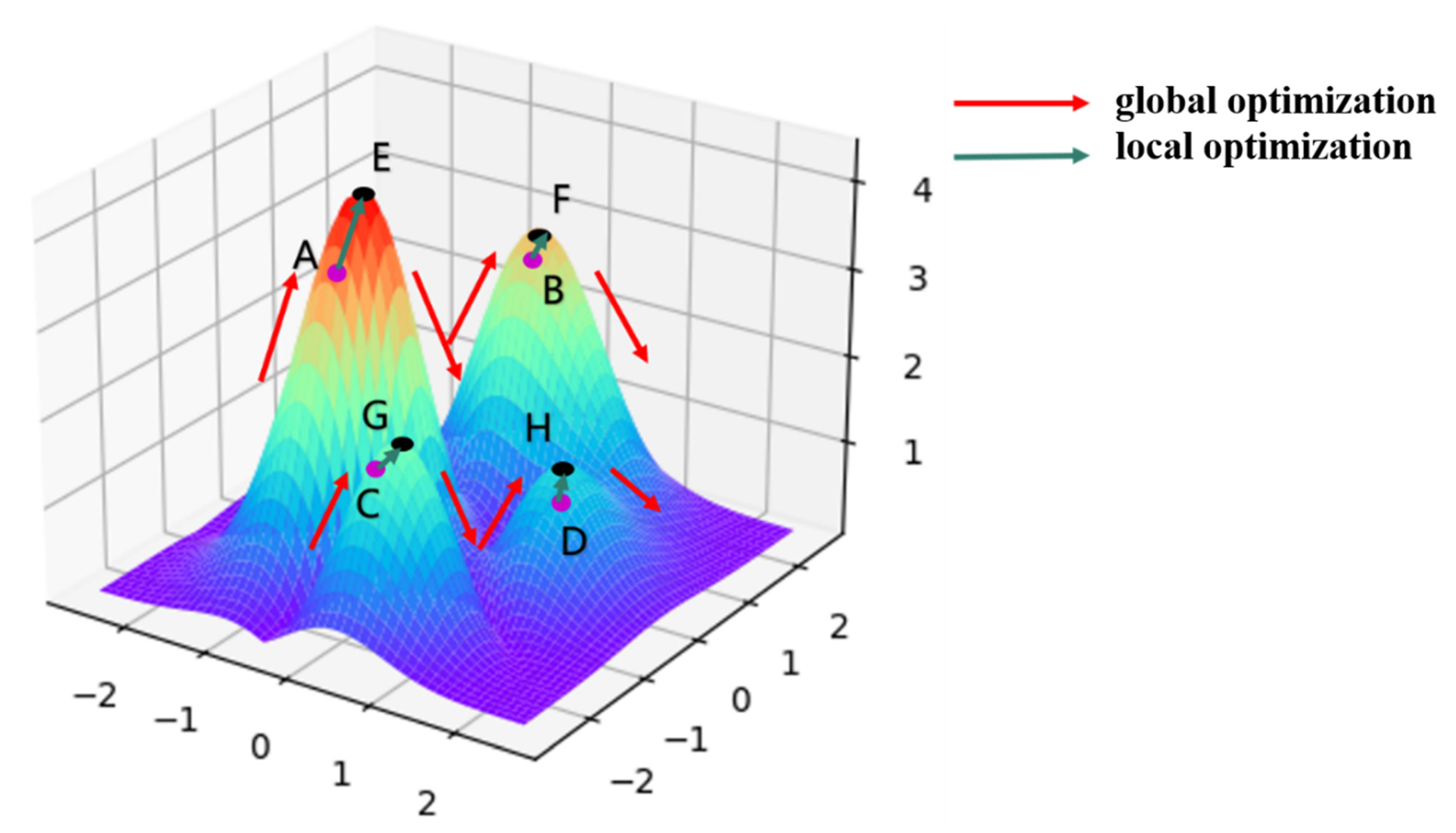
As shown in
Figure 1, the optimization process of the TSSA algorithm is analogous to the optimization process with the aim of climbing to the highest point (E) of a mountain peak. Owing to the two problems mentioned earlier, the SA algorithm does not reach the top of the peak during the global optimization search but jumps out of the section after reaching points A, B, C, and D under the conventional initial parameter settings. Point B is the optimal solution filtered on this basis, which still has a large gap with objective (E). TSSA’s unique “Boruta algorithm-based local optimization process” can quickly complete the local optimization operations from A to E, B to F, C to G, and D to H and find the highest point (E) using less time and computational resources.
2.1. The Global Optimization Search Process for Simulated Annealing
The TSSA algorithm has a structure with a memory function. Let the initial band combination of the algorithm be
x = {w
1, w
2, ..., w
n} and the optimal band combination be
xb. Then, initialize
xb =
x. The first step of the algorithm is the global optimization process. At this point, for
x randomly replacing
m non-coincident bands to form
x’, the value of
m is determined by Equation (1):
where
T is the temperature at the current moment of the algorithm and
n is the number of bands in the combination.
Statistical mechanics studies have shown that the probability of a particle staying in the state
i at temperature
T satisfies the Boltzmann distribution:
where
E(
i) is the energy of state
I;
kb > 0 is the Boltzmann constant;
T is the temperature; and
x denotes the random variable of the current state of the material.
Z(
T) is the normalization factor of the probability distribution, and
S represents the set of state spaces.
In the high-temperature state, there is obviously the following:
where |
S| denotes the number of states in the set
S. This indicates that all states have the same probability at high temperatures.
Assuming that the current annealing temperature is
T, whether or not to accept the update of
x =
x′ depends on the probability calculated by Equation (5). This is the famous Metropolis criterion, which is the core idea of the SA algorithm:
2.2. Boruta Algorithm-Based Local Optimization Process
The degree to which the bands in x contribute to improving the modeling effect during the algorithm annealing search varies, and information unrelated or weakly correlated with the dependent variable adversely affects the results. Replacing it in the global optimization process causes the algorithm to fall into a local optimum, which violates the core idea of the SA algorithm. For this purpose, the algorithm introduces the Boruta algorithm-based local optimization process.
When the global optimization process in the first step satisfies the condition f(x′) > f(xb), the algorithm enters the second step: the Boruta algorithm-based local optimization process. The process first uses the Boruta algorithm to filter out s irrelevant and weakly correlated bands in x′ and then replaces them with s randomly selected, not coinciding bands to obtain xp.
In the SA process, when the temperature decreases,
where
, and
.
The above equation shows that when the temperature drops to a deficient level, the material enters the minimum energy state with a high probability. This algorithm plunges the temperature to 0 degrees directly in the second step and uses Equation (7) as the basis for determining whether to accept the
xb =
xp update:
At this time, the material enters the minimum energy state, the algorithm follows the principle of local optimization, and after iterating this process Lp times, the algorithm returns to the first step of the global optimization process until the temperature T has dropped to less than the termination temperature Tmin, the algorithm operation ends, and xb is the final optimization result.
In
Figure 2a,b the flow chart of simulated annealing and TSSA algorithms is shown, respectively. The TSSA algorithm has the same termination conditions as the SA algorithm. The algorithm terminates when the temperature T is less than the termination temperature T
min.
The objective function of the algorithm is defined as
f(
x):
where
t(
x) is the mean square error (MSE) of the prediction results obtained by cross-validating the training set data using the bands in
x. The larger the value of the objective function
f(
x), the better:
4. Results and Discussion
4.1. Data Preprocessing
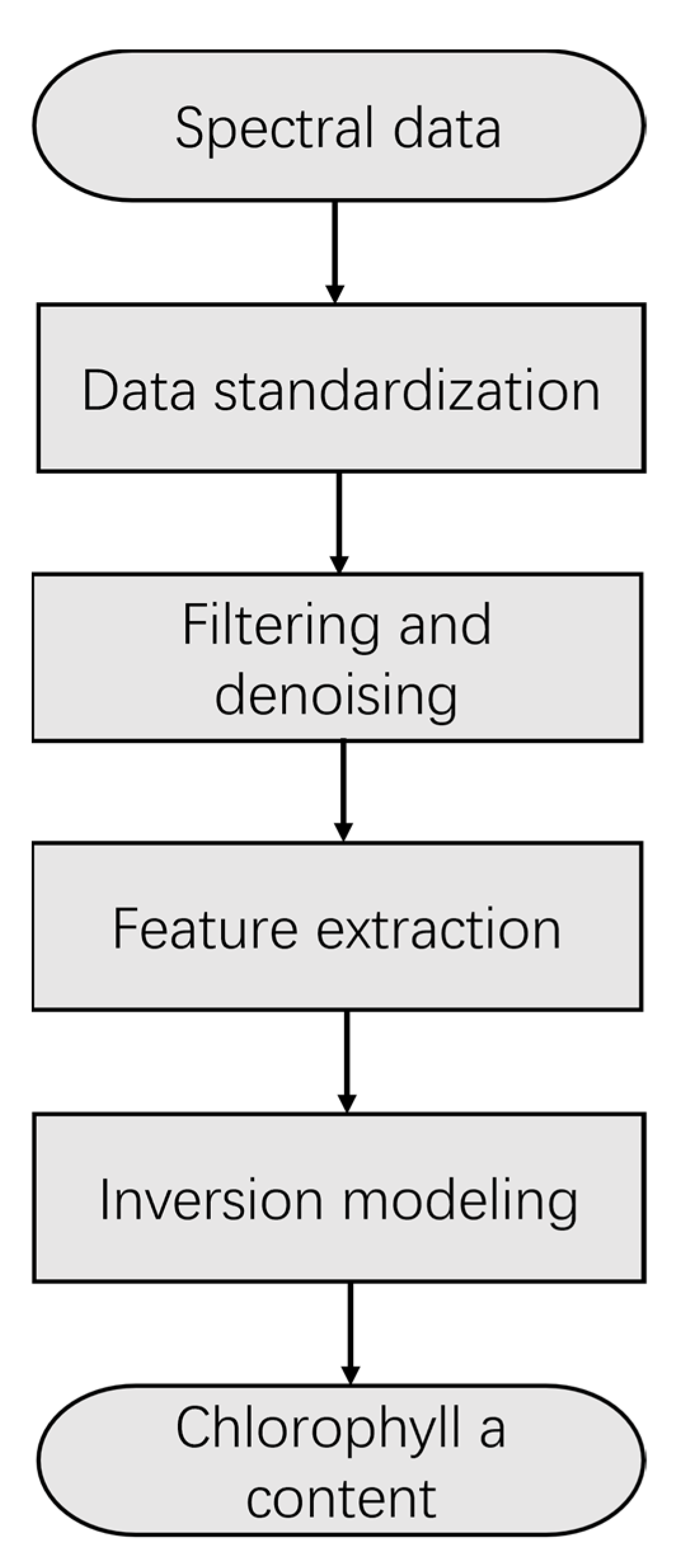
In this paper, the spectral data collected from field experiments in Chaohu Lake and Taihu Lake were analyzed together with the results of water sample assays to construct an algorithmic model for the inversion of cyanobacterial Chla in the water column of eutrophic shallow lakes. The data processing mainly included four steps: data normalization, filtering and denoising, feature extraction, and inversion modeling. The data processing flow is shown in
Figure 6.
The spectral range of the device was 200–1000 nm, covering UV–visible–-near infrared waves. The water absorbs significantly in the near-infrared band, so the spectral data of detection bin 3 were used as a standard to make a difference in the spectrum with the spectral data of detection bin 2. The absorption spectrum was calculated using Equation (10) for calibration, and the SG filter is used for denoising:
In the formula, I3 is the spectral data of the distilled water in the No. 3 detection bin, and I2 is the spectral data of the lake water in the No. 2 detection bin.
The spectral differentiation operation was performed by numerically simulating the original spectrum and calculating the differentiation values of different orders to obtain the inflection points of the differentiated spectrum as well as the maximum and minimum values and wavelength positions of the absorption spectrum. The spectral differentiation process can eliminate some noise effects in the original spectrum. Continuum removal is a common method of spectral feature-enhancement processing. It normalizes the spectral reflectance to 0 to 1, highlighting the absorption and reflection features of the spectrum and normalizing them to a uniform spectral background, which facilitates feature comparison with the spectral curves of other sampling points.
Figure 7a shows the spectral absorption curve of the water sample calculated using Equation (10). The calibrated data were processed using first-order differentiation, second-order differentiation, and continuum removal to highlight features that were difficult to represent in the original spectra. The data obtained after first- and second-order differentiation of the spectral curves in
Figure 7a are too small in order of magnitude. The spectral curves shown in
Figure 7b,c are the results obtained by subjecting the spectral curves in
Figure 7a to first-order and second-order differentiation, respectively, and then enlarging them by a factor of 100 in equal proportion. As
Figure 7d shows, the spectral curve is obtained after continuum removal processing of the spectral curve in
Figure 7a.
4.2. Feature Extraction
A total of 107 data samples were collected from the field experiments conducted at Chaohu Lake and Taihu Lake, which were randomly divided into a training set and validation with 79 data samples and 28 data samples, respectively. Feature extraction of the normalized spectral data was performed using the correlation coefficient method, band ratio method, principal component analysis (PCA), successive projections algorithm (SPA), SA algorithm, and TSSA. The SA algorithm had an initial temperature (Tmax) of 200, an end temperature (Tmin) of 1, a temperature decay coefficient (k) of 0.95, and a maximum Markov chain length (Lw) of 50. The TSSA algorithm had the parameters Tmax as 100, Tmin as 1, k as 0.95, Lw as 50, and the number of local optimization iterations as Lp as 1000. The number of bands n in the optimized combination of SA and TSSA algorithms was taken from 2 to 30 to calculate, and the value of n when the objective function was optimal was its best value.
4.3. Model Building and Accuracy Comparison
Inputting the extracted feature bands into a back-propagation (BP) neural network to model a quantitative inversion algorithm for cyanobacterial Chla in eutrophic shallow water lakes. A three-layer BP neural network was used for training. The number of neurons in the hidden layer was 100, the activation function was sigmoid, and L1 regularization was used. The calculation results show that the best modeling results were obtained by using the data obtained from the first-order differentiation of the original absorption spectrum among the four normalization methods. The spectral feature bands obtained using the six feature extraction methods are shown in
Table 1, and the modeling accuracy comparison is shown in
Table 2.
Compared with the other five feature extraction methods, the TSSA algorithm has obvious superiority in spectral feature extraction. First, in principle, the “correlation coefficient method” and the “band ratio method” only rely on a small amount of band information to establish a linear fit to the calibration data. The models are easily overfitted in the training set and poorly predicted in the validation set [
23,
24]. “Principal component analysis” (PCA) is suitable for data with a strong correlation between variables, but if the correlation of the original data is weak, it will not play a good role in dimensionality reduction, and the meaning of principal components will be more ambiguous than that of the original data [
25,
26]. The “Successive projections algorithm” (SPA) does not consider the maximization of irrelevance globally, only locally [
27,
28]. The SA algorithm has only a global optimization process and jumps out of important bands too quickly when updating combinations, leading to poor modeling results. Moreover, the algorithm cannot determine feature relevance [
2,
3,
4]. The TSSA algorithm has both global and local optimization, which can ensure the efficient operation of the algorithm and does not transform the original data. It has a clear interpretation of the meaning of the feature extraction results. The combined optimized feature extraction avoids the overfitting caused by fewer features. The addition of the Boruta algorithm enables it to accurately determine the correlation between spectral features and dependent variables. It can eliminate irrelevant variable interference and reduce data redundancy. Second, in terms of modeling accuracy comparison results, as shown in
Table 2, compared with the other five feature extraction methods, using the TSSA algorithm for feature extraction, the modeling accuracy indexes are significantly improved, with the determination coefficient R2 increased by 0.1908–0.4623, RMSE decreased by 5.7039–10.249 μg/L, and MAE decreased by 4.1575–7.6202 μg/L. As the comparison in
Figure 8 shows, the fitted straight line between the predicted and measured values of the validation dataset using the TSSA algorithm is y = 0.99x + 0.05, which has the highest overlap with y = x, indicating the best modeling effect.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}