



Atmospheric Turbulence Degraded Video Restoration with Recurrent GAN (ATVR-GAN)



Abstract
:1. Introduction
- A novel RNN generator architecture which includes:
- o
- A preprocessing stage dedicated to acquiring an initial estimation of the turbulence flow.
- o
- Customized memory cells specifically aimed for the propagation of AT knowledge across timestamps.
- o
- A post-processing stage aimed at producing both temporal and spatial updates for the network’s knowledge given the scene and turbulence predictions.
- o
- An AT prediction sub-network, trained to predict the current AT optical flow map by learning from the posterior knowledge of the scene.
2. Method
2.1. Problem Definition
- We focus our research on ground-level imaging under anisoplanatic atmospheric turbulence, where the medium is assumed to be of the same level along the path of propagation [32] and where the size of the objects is relatively small with respect to propagation length.
- The video is taken from a constant position, which may move radially in yaw and pitch angles but not axially. The justification for such a constraint is due to the prime intended use of our algorithm, which is intended for surveillance missions or long-distance capturing under relatively high zoom ratios for several to tens of kilometers where movements in yaw, pitch and zoom are most relevant but axial movements are not.
- The scene may alter and contain dynamic objects and zoom in/out scenarios.
2.2. Algorithm and Arcitecture
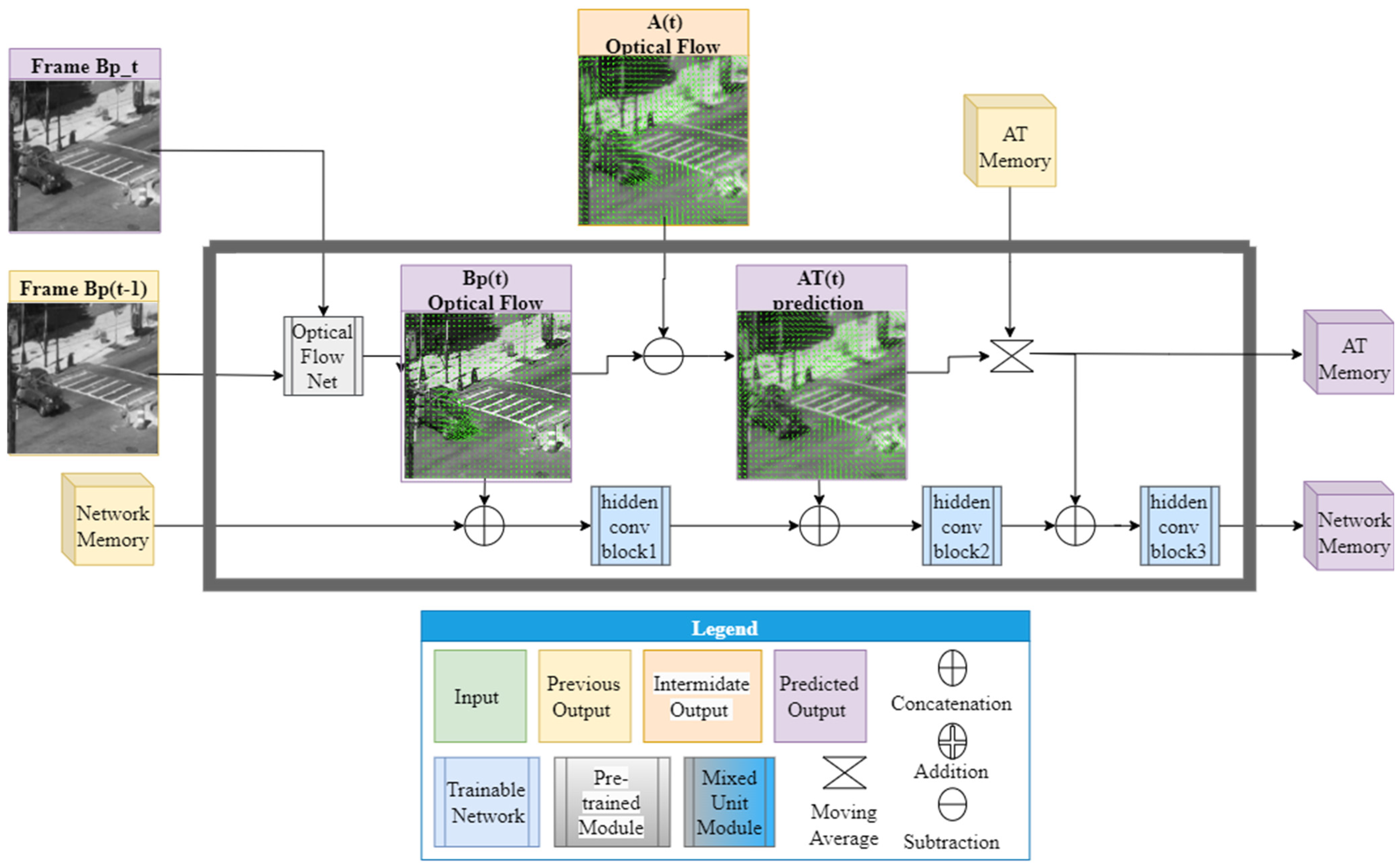
2.2.1. Stage 1: Preliminary Flow Prediction
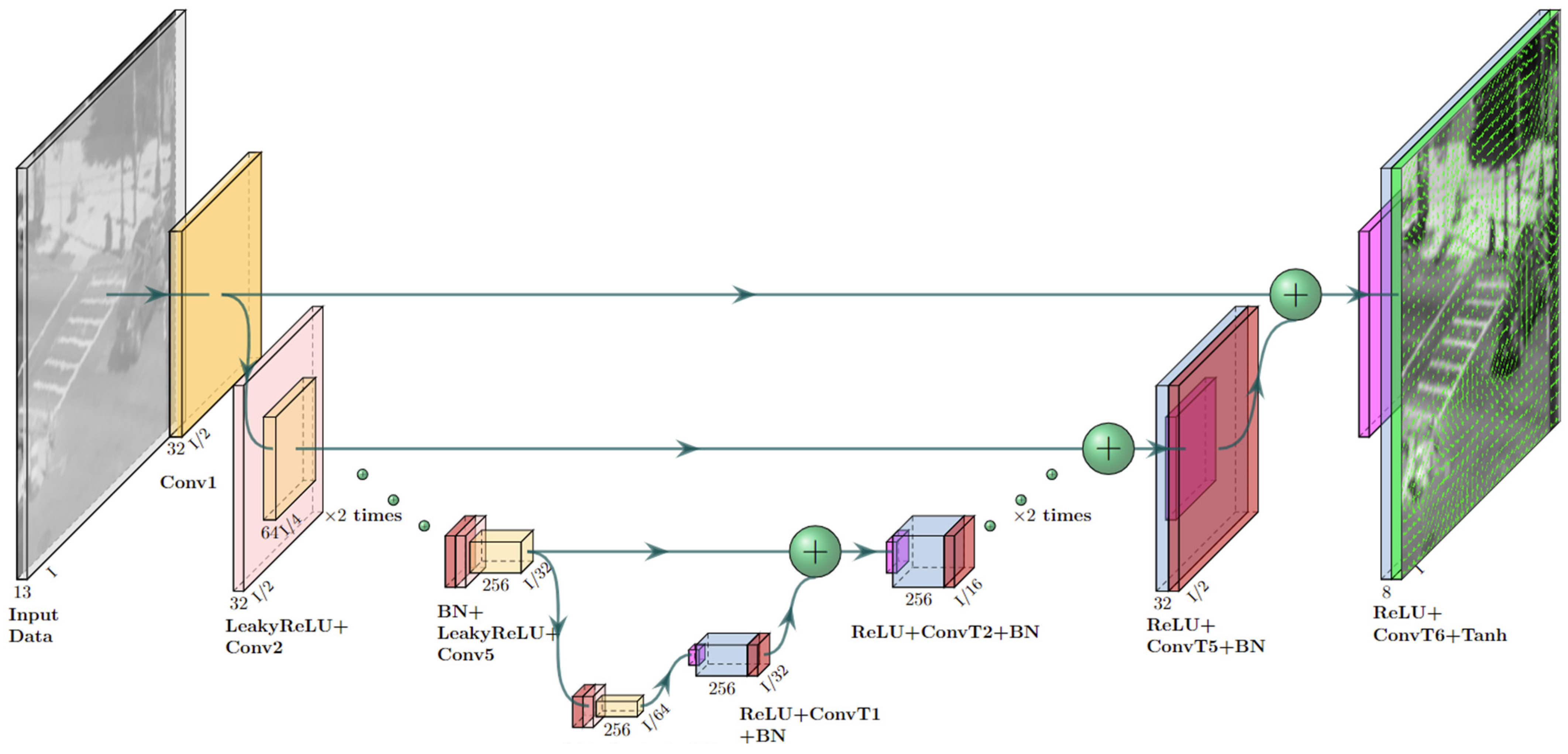
2.2.2. Stage 2: Frame Reconstruction
2.2.3. Stage 3: Auxiliary Update
2.3. Loss Function
2.3.1. Adversarial Loss
2.3.2. Perceptual Loss
2.3.3. Optical Flow Loss
2.3.4. Total Variation Loss
2.3.5. Atmospheric Turbulence Loss
2.3.6. Overall Loss
3. Results
3.1. Dataset and Data Preparation
3.2. Training Details
3.3. Testing Details
3.4. Results on Synthetic Data
3.5. Results on Real Data
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, E.; Haik, O.; Yitzhaky, Y. Classification of Moving Objects in Atmospherically Degraded Video. Opt. Eng. 2012, 51, 101710. [Google Scholar] [CrossRef]
- Haik, O.; Yitzhaky, Y. Effects of Image Restoration on Automatic Acquisition of Moving Objects in Thermal Video Sequences Degraded by the Atmosphere. Appl. Opt. 2007, 46, 8562–8572. [Google Scholar] [CrossRef] [PubMed]
- Chen, E.; Haik, O.; Yitzhaky, Y. Detecting and Tracking Moving Objects in Long-Distance Imaging through Turbulent Medium. Appl. Opt. 2014, 53, 1181–1190. [Google Scholar] [CrossRef]
- Shacham, O.; Haik, O.; Yitzhaky, Y. Blind restoration of atmospherically degraded images by automatic best step edge detection. Pattern Recognit. Lett. 2007, 28, 2094–2103. [Google Scholar] [CrossRef]
- Deledalle, C.; Gilles, J. Blind Atmospheric Turbulence Deconvolution. IET Image Process. 2020, 14, 3422. [Google Scholar] [CrossRef]
- Bai, X.; Liu, M.; He, C.; Dong, L.; Zhao, Y.; Liu, X. Restoration of Turbulence-Degraded Images Based on Deep Convolutional Network. In Applications of Machine Learning; SPIE: Bellingham, WA, USA, 2019. [Google Scholar]
- Chen, G.; Gao, Z.; Wang, Q.; Luo, Q. Blind De-Convolution of Images Degraded by Atmospheric Turbulence. Appl. Soft Comput. 2020, 89, 106131. [Google Scholar] [CrossRef]
- Lau, C.P.; Souri, H.; Chellappa, R. ATFaceGAN: Single Face Image Restoration and Recognition from Atmospheric Turbulence. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; IEEE Press: Piscataway, NJ, USA, 2020; pp. 32–39. [Google Scholar]
- Yasarla, R.; Patel, V.M. Learning to Restore Images Degraded by Atmospheric Turbulence Using Uncertainty. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1694–1698. [Google Scholar]
- Zhu, X.; Milanfar, P. Image Reconstruction from Videos Distorted by Atmospheric Turbulence. In Visual Information Processing and Communication; SPIE: Bellingham, WA, USA, 2010; Volume 7543. [Google Scholar] [CrossRef]
- Zhu, X.; Milanfar, P. Removing Atmospheric Turbulence via Space-Invariant Deconvolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 157–170. [Google Scholar] [CrossRef] [PubMed]
- Anantrasirichai, N.; Achim, A.; Kingsbury, N.; Bull, D. Atmospheric Turbulence Mitigation Using Complex Wavelet-Based Fusion. IEEE Trans. Image Process. 2013, 22, 2398–2408. [Google Scholar] [CrossRef] [PubMed]
- Lau, C.P.; Lai, Y.H.; Lui, L.M. Restoration of Atmospheric Turbulence-Distorted Images via RPCA and Quasiconformal Maps. Inverse Probl. 2019, 35, 074002. [Google Scholar] [CrossRef]
- Lau, C.P.; Lai, Y.; Lui, L.M. Variational Models for Joint Subsampling and Reconstruction of Turbulence-Degraded Images. J. Sci. Comput. 2019, 78, 1488–1525. [Google Scholar] [CrossRef]
- Mao, Z.; Chimitt, N.; Chan, S. Image Reconstruction of Static and Dynamic Scenes Through Anisoplanatic Turbulence. IEEE Trans. Comput. Imaging 2020, 6, 1415–1428. [Google Scholar] [CrossRef]
- Frakes, D.; Monaco, J.W.; Smith, M.J.T. Suppression of Atmospheric Turbulence in Video Using an Adaptive Control Grid Interpolation Approach. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Volume 3, p. 1884, ISBN 978-0-7803-7041-8. [Google Scholar]
- Gepshtein, S.; Shtainman, A.; Fishbain, B.; Yaroslavsky, L.P. Restoration of Atmospheric Turbulent Video Containing Real Motion Using Rank Filtering and Elastic Image Registration. In Proceedings of the 12th European Signal Processing Conference, EUSIPCO 2004, New York, NY, USA, 6–10 September 2004; pp. 477–480. [Google Scholar]
- Lou, Y.; Kang, S.; Soatto, S.; Bertozzi, A. Video Stabilization of Atmospheric Turbulence Distortion. Inverse Probl. Imaging 2013, 7, 839–861. [Google Scholar] [CrossRef]
- Anantrasirichai, N. Atmospheric Turbulence Removal with Complex-Valued Convolutional Neural Network. Pattern Recognit. Lett. 2023, 171, 69–75. [Google Scholar] [CrossRef]
- Bansal, A.; Ma, S.; Ramanan, D.; Sheikh, Y. Recycle-GAN: Unsupervised Video Retargeting. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part V. pp. 122–138, ISBN 978-3-030-01227-4. [Google Scholar]
- Chadha, A.; Britto, J.; Roja, M. ISeeBetter: Spatio-Temporal Video Super-Resolution Using Recurrent Generative Back-Projection Networks. Comput. Vis. Media 2020, 6, 307–317. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; WOO, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Gilles, J.; Osher, S. Fried Deconvolution. In Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXIII; SPIE: Bellingham, WA, USA, 2012; Volume 8355. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part II 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 9906, p. 711. ISBN 978-3-319-46474-9. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Volume 9351, p. 241. ISBN 978-3-319-24573-7. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; p. 8192. [Google Scholar]
- Rudin, L.; Osher, S.; Fatemi, E. Nonlinear Total Variation Based Noise Removal Algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Chimitt, N.; Chan, S. Simulating Anisoplanatic Turbulence by Sampling Inter-Modal and Spatially Correlated Zernike Coefficients. Opt. Eng. 2020, 59, 083101. [Google Scholar] [CrossRef]
- Chen, Y.; Pan, Y.; Yao, T.; Tian, X.; Mei, T. Mocycle-GAN: Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks Video-to-Video Translation; IEEE: Piscataway, NJ, USA, 2019; p. 655. ISBN 978-1-4503-6889-6. [Google Scholar]
- Jiang, S.; Campbell, D.; Lu, Y.; Li, H.; Hartley, R. Learning to Estimate Hidden Motions with Global Motion Aggregation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9752–9761. [Google Scholar]
- Liu, S.; Deng, W. Very Deep Convolutional Neural Network Based Image Classification Using Small Training Sample Size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14816–14826. [Google Scholar]
- Anantrasirichai, N.; Achim, A.; Bull, D. Atmospheric Turbulence Mitigation for Sequences with Moving Objects Using Recursive Image Fusion; IEEE: Piscataway, NJ, USA, 2018; p. 2899. [Google Scholar]
- Wang, Y.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Benezeth, Y.; Ishwar, P. CDnet 2014: An Expanded Change Detection Benchmark Dataset. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Dimension * | Layer | Output Dimension |
|---|---|---|
| Conv2D ( Instance Normalization ReLU | ||
| Conv2D ( Instance Normalization |
| Videos/Number of Frames | Training | Validation | Testing |
|---|---|---|---|
| Synthetic AT dataset | 10 different videos per set (80 videos) ~100,000 frames | 3 different videos per set (24 videos) ~30,000 frames | 7 different videos with setting from set6 and set1 (14 videos) ~11,000 frames |
| Real AT dataset | 4 videos |
| Simulations Sets | Propagation | Refractive | Fried | Aperture |
|---|---|---|---|---|
| set1 | 4000 | 1 | 0.1 | |
| Set2 | 4000 | 2 | 0.1 | |
| Set3 | 4000 | 3 | 0.1 | |
| Set4 | 4000 | 4 | 0.1 | |
| Set5 | 1000 | 0.05 | 0.2 | |
| Set6 | 1500 | 0.05 | 0.2 | |
| Set7 | 2000 | 0.05 | 0.2 | |
| Set8 | 2500 | 0.05 | 0.2 |
| Dataset/ Degradation Level | AT Raw Input | CLEAR [12] | MPRNET [36] | BATUD [5] | AT-Net [9] | Ours ATVR-GAN |
|---|---|---|---|---|---|---|
| D = 0.1|L = 4000|r0 = 1 | 20.98/ 0.586 | 20.64/ 0.571 | 21.55/ 0.635 | 20.02/ 0.567 | 22.77/ 0.692 | 23.96/ 0.741 |
| D = 0.2|L = 1500|r0 = 0.05 | 22.58/ 0.703 | 22.00/ 0.692 | 23.21/ 0.753 | 21.96/ 0.685 | 23.34/ 0.738 | 24.05/ 0.770 |
| Average Test Scores | 21.78/ 0.644 | 21.32/ 0.631 | 22.38/ 0.694 | 20.99/ 0.626 | 23.05/ 0.715 | 24.01/ 0.756 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ettedgui, B.; Yitzhaky, Y. Atmospheric Turbulence Degraded Video Restoration with Recurrent GAN (ATVR-GAN). Sensors 2023, 23, 8815. https://doi.org/10.3390/s23218815
Ettedgui B, Yitzhaky Y. Atmospheric Turbulence Degraded Video Restoration with Recurrent GAN (ATVR-GAN). Sensors. 2023; 23(21):8815. https://doi.org/10.3390/s23218815
Chicago/Turabian StyleEttedgui, Bar, and Yitzhak Yitzhaky. 2023. "Atmospheric Turbulence Degraded Video Restoration with Recurrent GAN (ATVR-GAN)" Sensors 23, no. 21: 8815. https://doi.org/10.3390/s23218815
APA StyleEttedgui, B., & Yitzhaky, Y. (2023). Atmospheric Turbulence Degraded Video Restoration with Recurrent GAN (ATVR-GAN). Sensors, 23(21), 8815. https://doi.org/10.3390/s23218815