
Electromyographic Validation of Spontaneous Facial Mimicry Detection Using Automated Facial Action Coding



Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Facilities
2.3. Paradigm and Procedures
2.4. Prerecorded and Live Videos
2.5. EMG Data Preprocessing
2.6. Automated AU Estimation
2.6.1. FaceReader
2.6.2. OpenFace
2.6.3. Py-Feat
2.7. Statistical Analysis
2.7.1. AU Response Accuracy
2.7.2. Spontaneous Mimicry Detection Accuracy
2.7.3. Correlation between ZM and AU12 Responses
2.7.4. Detection of Emotional and Presentation Condition Interactions Using AU12 Responses
2.7.5. Visualization of Condition-Wise ZM and AU12 Time Series Per Trial
2.7.6. Cross-Correlation between ZM and Automated FACS AU12 Time Series
3. Results
3.1. AU Response and Spontaneous Mimicry Detection Accuracy
3.2. Repeated Measure Correlation between ZM and AU12 Responses
3.3. Detection of Emotional and Presentation Condition Interactions Using AU12 Responses
3.4. Visualization of Condition-Wise ZM and AU12 Time Series
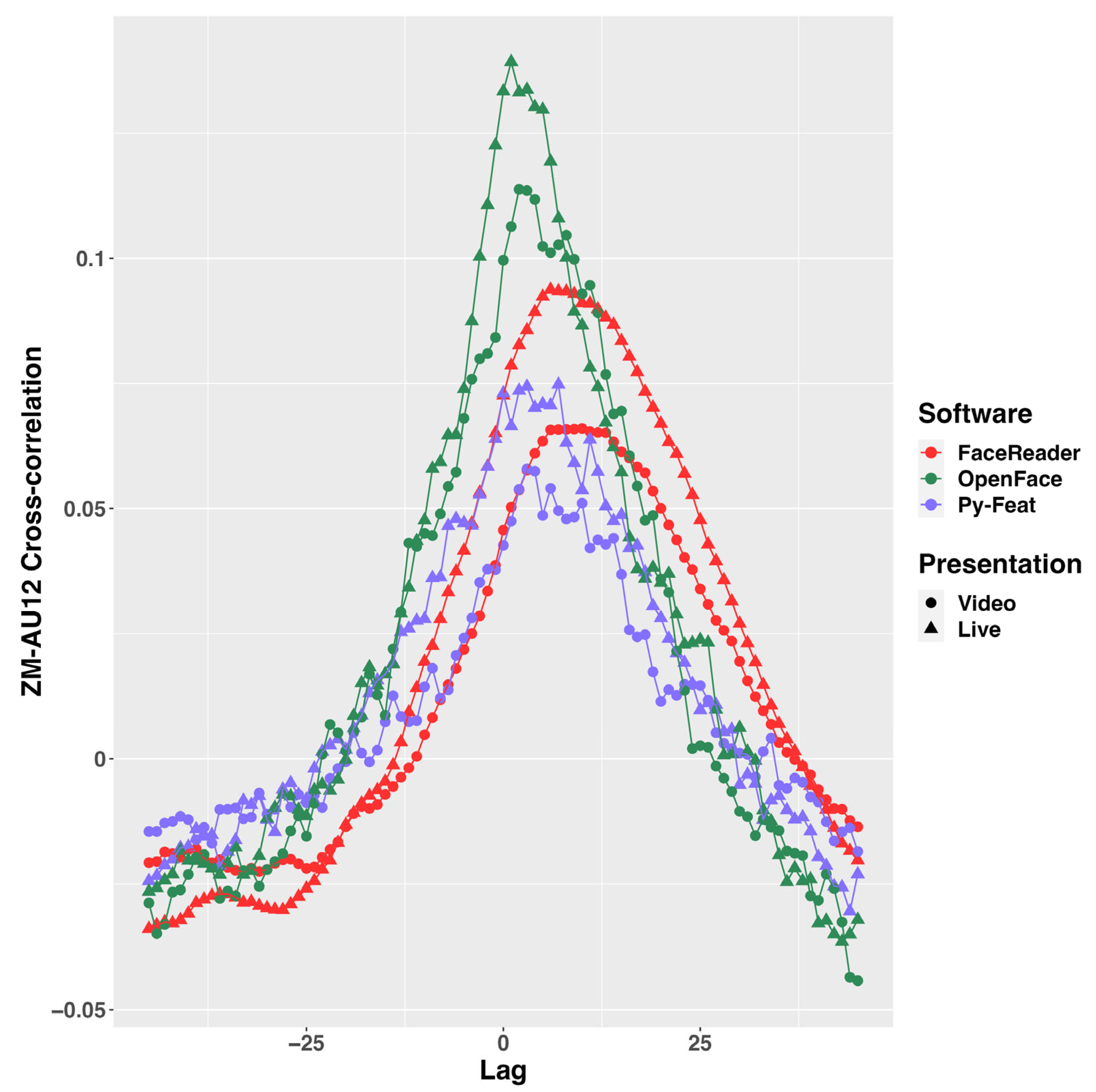
3.5. Cross-Correlation between ZM and Automated FACS AU12 Time Series
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fernández-Dols, J.-M.; Crivelli, C. Emotion and Expression: Naturalistic Studies. Emot. Rev. 2013, 5, 24–29. [Google Scholar] [CrossRef]
- Crivelli, C.; Fridlund, A.J. Facial Displays Are Tools for Social Influence. Trends Cogn. Sci. 2018, 22, 388–399. [Google Scholar] [CrossRef]
- Heintz, C.; Scott-Phillips, T. Expression Unleashed: The Evolutionary & Cognitive Foundations of Human Communication. Behav. Brain Sci. 2022, 46, E1. [Google Scholar] [CrossRef]
- Bernieri, F.J.; Rosenthal, R. Interpersonal Coordination: Behavior Matching and Interactional Synchrony. In Fundamentals of Nonverbal Behavior; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Shamay-Tsoory, S.G.; Saporta, N.; Marton-Alper, I.Z.; Gvirts, H.Z. Herding Brains: A Core Neural Mechanism for Social Alignment. Trends Cogn. Sci. 2019, 23, 174–186. [Google Scholar] [CrossRef]
- Dimberg, U. Facial Reactions to Facial Expressions. Psychophysiology 1982, 19, 643–647. [Google Scholar] [CrossRef]
- Dimberg, U.; Thunberg, M.; Elmehed, K. Unconscious Facial Reactions to Emotional Facial Expressions. Psychol. Sci. 2000, 11, 86–89. [Google Scholar] [CrossRef]
- Hess, U.; Blairy, S. Facial Mimicry and Emotional Contagion to Dynamic Emotional Facial Expressions and Their Influence on Decoding Accuracy. Int. J. Psychophysiol. 2001, 40, 129–141. [Google Scholar] [CrossRef]
- McIntosh, D.N. Spontaneous Facial Mimicry, Liking and Emotional Contagion. Pol. Psychol. Bull. 2006, 37, 31–42. [Google Scholar]
- Oberman, L.M.; Winkielman, P.; Ramachandran, V.S. Face to Face: Blocking Facial Mimicry Can Selectively Impair Recognition of Emotional Expressions. Soc. Neurosci. 2007, 2, 167–178. [Google Scholar] [CrossRef]
- Sato, W.; Fujimura, T.; Suzuki, N. Enhanced Facial EMG Activity in Response to Dynamic Facial Expressions. Int. J. Psychophysiol. 2008, 70, 70–74. [Google Scholar] [CrossRef]
- Sims, T.B.; Van Reekum, C.M.; Johnstone, T.; Chakrabarti, B. How Reward Modulates Mimicry: EMG Evidence of Greater Facial Mimicry of More Rewarding Happy Faces. Psychophysiology 2012, 49, 998–1004. [Google Scholar] [CrossRef]
- Sonnby–Borgström, M. Automatic Mimicry Reactions as Related to Differences in Emotional Empathy. Scand. J. Psychol. 2002, 43, 433–443. [Google Scholar] [CrossRef]
- Murata, A.; Saito, H.; Schug, J.; Ogawa, K.; Kameda, T. Spontaneous Facial Mimicry Is Enhanced by the Goal of Inferring Emotional States: Evidence for Moderation of “Automatic” Mimicry by Higher Cognitive Processes. PLoS ONE 2016, 11, e0153128. [Google Scholar] [CrossRef]
- Sato, W.; Yoshikawa, S. Spontaneous Facial Mimicry in Response to Dynamic Facial Expressions. Cognition 2007, 104, 1–18. [Google Scholar] [CrossRef]
- Weiss, E.M.; Rominger, C.; Hofer, E.; Fink, A.; Papousek, I. Less Differentiated Facial Responses to Naturalistic Films of Another Person’s Emotional Expressions in Adolescents and Adults with High-Functioning Autism Spectrum Disorder. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2019, 89, 341–346. [Google Scholar] [CrossRef]
- Yoshimura, S.; Sato, W.; Uono, S.; Toichi, M. Impaired Overt Facial Mimicry in Response to Dynamic Facial Expressions in High-Functioning Autism Spectrum Disorders. J. Autism Dev. Disord. 2015, 45, 1318–1328. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; Hager, J. Facial Action Coding System; Research Nexus: Salt Lake City, UT, USA, 2002; ISBN 978-0-931835-01-8. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System. APA PsycTests. 1978. Available online: https://psycnet.apa.org/doi/10.1037/t27734-000 (accessed on 25 September 2023).
- Hjortsjö, C.H. Man’s Face and Mimic Language; Studentlitteratur: Lund, Sweden, 1969. [Google Scholar]
- Gudi, A.; Tasli, H.E.; Den Uyl, T.M.; Maroulis, A. Deep Learning Based FACS Action Unit Occurrence and Intensity Estimation. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–5. [Google Scholar]
- Lewinski, P.; den Uyl, T.M.; Butler, C. Automated Facial Coding: Validation of Basic Emotions and FACS AUs in FaceReader. J. Neurosci. Psychol. Econ. 2014, 7, 227–236. [Google Scholar] [CrossRef]
- Namba, S.; Sato, W.; Osumi, M.; Shimokawa, K. Assessing Automated Facial Action Unit Detection Systems for Analyzing Cross-Domain Facial Expression Databases. Sensors 2021, 21, 4222. [Google Scholar] [CrossRef]
- Namba, S.; Sato, W.; Yoshikawa, S. Viewpoint Robustness of Automated Facial Action Unit Detection Systems. Appl. Sci. 2021, 11, 11171. [Google Scholar] [CrossRef]
- Skiendziel, T.; Rösch, A.G.; Schultheiss, O.C. Assessing the Convergent Validity between the Automated Emotion Recognition Software Noldus FaceReader 7 and Facial Action Coding System Scoring. PLoS ONE 2019, 14, e0223905. [Google Scholar] [CrossRef]
- Küntzler, T.; Höfling, T.T.A.; Alpers, G.W. Automatic Facial Expression Recognition in Standardized and Non-Standardized Emotional Expressions. Front. Psychol. 2021, 12, 627561. [Google Scholar] [CrossRef] [PubMed]
- D’Arcey, J.T. Assessing the Validity of FaceReader Using Facial EMG. Master’s Thesis, California State University, Chico, CA, USA, 2013. [Google Scholar]
- Beringer, M.; Spohn, F.; Hildebrandt, A.; Wacker, J.; Recio, G. Reliability and Validity of Machine Vision for the Assessment of Facial Expressions. Cogn. Syst. Res. 2019, 56, 119–132. [Google Scholar] [CrossRef]
- Bishay, M.; Preston, K.; Strafuss, M.; Page, G.; Turcot, J.; Mavadati, M. AFFDEX 2.0: A Real-Time Facial Expression Analysis Toolkit. arXiv 2022, arXiv:2202.12059. [Google Scholar]
- Kulke, L.; Feyerabend, D.; Schacht, A. A Comparison of the Affectiva iMotions Facial Expression Analysis Software With EMG for Identifying Facial Expressions of Emotion. Front. Psychol. 2020, 11, 329. [Google Scholar] [CrossRef] [PubMed]
- Cacioppo, J.T.; Petty, R.E.; Kim, H.S. Electromyographic Activity Over Facial Muscle Regions Can Differentiate the Valence and Intensity of Affective Reactions. J. Pers. Soc. Psychol. 1986, 50, 260–268. [Google Scholar] [CrossRef]
- Tassinary, L.G.; Cacioppo, J.T. Unobservable Facial Actions and Emotion. Psychol. Sci. 1992, 3, 28–33. [Google Scholar] [CrossRef]
- Höfling, T.T.A.; Gerdes, A.B.M.; Föhl, U.; Alpers, G.W. Read My Face: Automatic Facial Coding Versus Psychophysiological Indicators of Emotional Valence and Arousal. Front. Psychol. 2020, 11, 1388. [Google Scholar] [CrossRef]
- Höfling, T.T.A.; Alpers, G.W.; Gerdes, A.B.M.; Föhl, U. Automatic Facial Coding versus Electromyography of Mimicked, Passive, and Inhibited Facial Response to Emotional Faces. Cogn. Emot. 2021, 35, 874–889. [Google Scholar] [CrossRef]
- Drimalla, H.; Scheffer, T.; Landwehr, N.; Baskow, I.; Roepke, S.; Behnia, B.; Dziobek, I. Towards the Automatic Detection of Social Biomarkers in Autism Spectrum Disorder: Introducing the Simulated Interaction Task (SIT). NPJ Digit. Med. 2020, 3, 25. [Google Scholar] [CrossRef]
- Kovalchuk, Y.; Budini, E.; Cook, R.M.; Walsh, A. Investigating the Relationship between Facial Mimicry and Empathy. Behav. Sci. 2022, 12, 250. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Song, Y. Atypical Facial Mimicry for Basic Emotions in Children with Autism Spectrum Disorder. Autism Res. 2023, 16, 1375–1388. [Google Scholar] [CrossRef] [PubMed]
- Mauersberger, H.; Kastendieck, T.; Hetmann, A.; Schöll, A.; Hess, U. The Different Shades of Laughter: When Do We Laugh and When Do We Mimic Other’s Laughter? Phil. Trans. R. Soc. B 2022, 377, 20210188. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-T.; Sato, W.; Yoshikawa, S. Enhanced Emotional and Motor Responses to Live versus Videotaped Dynamic Facial Expressions. Sci. Rep. 2020, 10, 16825. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-T.; Sato, W.; Kochiyama, T.; Nakai, R.; Asano, K.; Abe, N.; Yoshikawa, S. Enhanced Mirror Neuron Network Activity and Effective Connectivity during Live Interaction among Female Subjects. NeuroImage 2022, 263, 119655. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.-P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Cheong, J.H.; Jolly, E.; Xie, T.; Byrne, S.; Chang, L.J. Py-Feat: Python Facial Expression Analysis Toolbox. arXiv 2021, arXiv:2104.03509. [Google Scholar] [CrossRef]
- Green, P.; MacLeod, C.J. SIMR: An R Package for Power Analysis of Generalized Linear Mixed Models by Simulation. Methods Ecol. Evol. 2016, 7, 493–498. [Google Scholar] [CrossRef]
- Frith, C.D. The Role of Metacognition in Human Social Interactions. Phil. Trans. R. Soc. B 2012, 367, 2213–2223. [Google Scholar] [CrossRef]
- Hamilton, A.F.d.C.; Lind, F. Audience Effects: What Can They Tell Us about Social Neuroscience, Theory of Mind and Autism? Cult. Brain 2016, 4, 159–177. [Google Scholar] [CrossRef]
- Conty, L.; George, N.; Hietanen, J.K. Watching Eyes Effects: When Others Meet the Self. Conscious. Cogn. 2016, 45, 184–197. [Google Scholar] [CrossRef] [PubMed]
- Zafeiriou, S.; Zhang, C.; Zhang, Z. A Survey on Face Detection in the Wild: Past, Present and Future. Comput. Vis. Image Underst. 2015, 138, 1–24. [Google Scholar] [CrossRef]
- Van Der Schalk, J.; Hawk, S.T.; Fischer, A.H.; Doosje, B. Moving Faces, Looking Places: Validation of the Amsterdam Dynamic Facial Expression Set (ADFES). Emotion 2011, 11, 907–920. [Google Scholar] [CrossRef] [PubMed]
- Olszanowski, M.; Pochwatko, G.; Kuklinski, K.; Scibor-Rylski, M.; Lewinski, P.; Ohme, R.K. Warsaw Set of Emotional Facial Expression Pictures: A Validation Study of Facial Display Photographs. Front. Psychol. 2015, 5, 1516. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Zadeh, A.; Lim, Y.C.; Baltrusaitis, T.; Morency, L.-P. Convolutional Experts Constrained Local Model for 3D Facial Landmark Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2519–2528. [Google Scholar]
- Baltrušaitis, T.; Mahmoud, M.; Robinson, P. Cross-Dataset Learning and Person-Specific Normalisation for Automatic Action Unit Detection. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 6, pp. 1–6. [Google Scholar]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. DISFA: A Spontaneous Facial Action Intensity Database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
- McKeown, G.; Valstar, M.F.; Cowie, R.; Pantic, M. The SEMAINE Corpus of Emotionally Coloured Character Interactions. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, Singapore, 19–23 July 2010; pp. 1079–1084. [Google Scholar]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. BP4D-Spontaneous: A High-Resolution Spontaneous 3D Dynamic Facial Expression Database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Prkachin, K.M.; Solomon, P.E.; Matthews, I. Painful Data: The UNBC-McMaster Shoulder Pain Expression Archive Database. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 57–64. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus Database for 3D Face Analysis. In Proceedings of the Biometrics and Identity Management; Schouten, B., Juul, N.C., Drygajlo, A., Tistarelli, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Valstar, M.F.; Jiang, B.; Mehu, M.; Pantic, M.; Scherer, K. The First Facial Expression Recognition and Analysis Challenge. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 921–926. [Google Scholar]
- Kostinger, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Annotated Facial Landmarks in the Wild: A Large-Scale, Real-World Database for Facial Landmark Localization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2144–2151. [Google Scholar]
- Jain, V.; Learned-Miller, E. FDDB: A Benchmark for Face Detection in Unconstrained Settings; University of Massachusetts: Amherst, MA, USA, 2010. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices. In Proceedings of the Biometric Recognition; Zhou, J., Wang, Y., Sun, Z., Jia, Z., Feng, J., Shan, S., Ubul, K., Guo, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 428–438. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning Face Representation from Scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The First Manually Collected, In-the-Wild Age Database. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1997–2005. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Zhang, Z.; Girard, J.M.; Wu, Y.; Zhang, X.; Liu, P.; Ciftci, U.; Canavan, S.; Reale, M.; Horowitz, A.; Yang, H.; et al. Multimodal Spontaneous Emotion Corpus for Human Behavior Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mavadati, S.M.; Sanger, P.; Mahoor, M.H. Extended DISFA Dataset: Investigating Posed and Spontaneous Facial Expressions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A Complete Dataset for Action Unit and Emotion-Specified Expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lyons, M.; Kamachi, M.; Gyoba, J. The Japanese Female Facial Expression (JAFFE) Dataset. 1998. Available online: https://zenodo.org/records/3451524 (accessed on 25 September 2023).
- Benitez-Quiroz, C.F.; Srinivasan, R.; Feng, Q.; Wang, Y.; Martinez, A.M. EmotioNet Challenge: Recognition of Facial Expressions of Emotion in the Wild. arXiv 2017, arXiv:1703.01210. [Google Scholar]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 Faces In-The-Wild Challenge. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef]
- Fanelli, G.; Dantone, M.; Gall, J.; Fossati, A.; Van Gool, L. Random Forests for Real Time 3D Face Analysis. Int. J. Comput. Vis. 2013, 101, 437–458. [Google Scholar] [CrossRef]
- Bakdash, J.Z.; Marusich, L.R. Repeated Measures Correlation. Front. Psychol. 2017, 8, 456. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious Mixed Models. arXiv 2018, arXiv:1506.04967. [Google Scholar]
- Baayen, R.H.; Milin, P. Analyzing Reaction Times. Int. J. Psychol. Res. 2010, 3, 12–28. [Google Scholar] [CrossRef]
- Loy, A.; Hofmann, H. Diagnostic Tools for Hierarchical Linear Models: Diagnostic Tools for Hierarchical Linear Models. WIREs Comp. Stat. 2013, 5, 48–61. [Google Scholar] [CrossRef]
- Loy, A.; Hofmann, H. HLMdiag: A Suite of Diagnostics for Hierarchical Linear Models in R. J. Stat. Soft. 2014, 56, 1–28. [Google Scholar] [CrossRef]
- Workman, C.I.; Chatterjee, A. The Face Image Meta-Database (fIMDb) & ChatLab Facial Anomaly Database (CFAD): Tools for Research on Face Perception and Social Stigma. Methods Psychol. 2021, 5, 100063. [Google Scholar] [CrossRef]
- Thiesen, G.; Gribel, B.F.; Freitas, M.P.M. Facial Asymmetry: A Current Review. Dent. Press J. Orthod. 2015, 20, 110–125. [Google Scholar] [CrossRef] [PubMed]
- Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A.; Jauregui-Correa, J.C. Support Vector Machine-Based EMG Signal Classification Techniques: A Review. Appl. Sci. 2019, 9, 4402. [Google Scholar] [CrossRef]
- Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A Study of Computing Zero Crossing Methods and an Improved Proposal for EMG Signals. IEEE Access 2020, 8, 8783–8790. [Google Scholar] [CrossRef]
- Aviles, M.; Sánchez-Reyes, L.-M.; Fuentes-Aguilar, R.Q.; Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J. A Novel Methodology for Classifying EMG Movements Based on SVM and Genetic Algorithms. Micromachines 2022, 13, 2108. [Google Scholar] [CrossRef]
- Aviles, M.; Rodríguez-Reséndiz, J.; Ibrahimi, D. Optimizing EMG Classification through Metaheuristic Algorithms. Technologies 2023, 11, 87. [Google Scholar] [CrossRef]
- Hermans, E.J.; van Wingen, G.; Bos, P.A.; Putman, P.; van Honk, J. Reduced Spontaneous Facial Mimicry in Women with Autistic Traits. Biol. Psychol. 2009, 80, 348–353. [Google Scholar] [CrossRef] [PubMed]
- Varcin, K.J.; Bailey, P.E.; Henry, J.D. Empathic Deficits in Schizophrenia: The Potential Role of Rapid Facial Mimicry. J. Int. Neuropsychol. Soc. 2010, 16, 621–629. [Google Scholar] [CrossRef] [PubMed]
- Sato, W.; Murata, K.; Uraoka, Y.; Shibata, K.; Yoshikawa, S.; Furuta, M. Emotional Valence Sensing Using a Wearable Facial EMG Device. Sci. Rep. 2021, 11, 5757. [Google Scholar] [CrossRef] [PubMed]
- Holland, A.C.; O’Connell, G.; Dziobek, I. Facial Mimicry, Empathy, and Emotion Recognition: A Meta-Analysis of Correlations. Cogn. Emot. 2020, 35, 150–168. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Authors | Software | Measurements | Task | FACS-EMG Comparisons |
|---|---|---|---|---|
| D’Arcey (2013) [27] | FaceReader 4.0 | FACS: happy, angry, disgusted, and sad. EMG: CS and ZM. | Volitional mimicry. | EMG–emotion intensity correlation. |
| Beringer et al. (2019) [28] | FACET 6.1.2667.3 | FACS: AU4 and AU12. EMG: CS and ZM. | Volitional facial expressions. | ROC characteristics. Comparison of priming effects on the reaction time. Visualization of time series. |
| Höfling et al. (2020) [33] | FaceReader 7.0 | FACS: valence, arousal, AU4, and AU12. EMG: CS and ZM. | Passive viewing (spontaneous facial mimicry). | Separate ANOVA for EMG and FACS outputs. Visualization of time series. |
| Höfling et al. (2021) [34] | FaceReader 7.0 | FACS: valence, arousal. EMG: CS and ZM. | Volitional mimicry. Passive viewing (spontaneous facial mimicry). Mimicry inhibition. | Separate ANOVA for EMG and FACS outputs. Visualization of time series. |
| Kulke et al. (2020) [30] | AFFDEX 1.0 | FACS: AU4 and AU 12. EMG: CS, ZM, and orbicularis oculi. | Volitional mimicry. | Correlation between the difference of the FACS estimations and EMG measurements. |
| The present study | FaceReader 9.0 OpenFace 2.2.0 Py-Feat 0.6.0 | FACS: AU4 and AU 12. EMG: CS and ZM. | Passive viewing (spontaneous facial mimicry). Live effect vs. prerecorded videos. | ROC characteristics. Correlation between the difference of the FACS estimations and EMG measurements. Separate LME analysis for EMG and FACS outputs to test the live effect. Cross-correlation to test latency. Visualization of time series. |
| AU12 | AU4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Res. Acc | Mimicry | Res. Acc | Mimicry | |||||||
| Sensitivity | Specificity | PPV | F1 | Sensitivity | Specificity | PPV | F1 | |||
| FRB | 0.564 | 0.624 | 0.482 | 0.612 | 0.618 | 0.507 | 0.526 | 0.493 | 0.497 | 0.511 |
| FRL | 0.560 | 0.627 | 0.501 | 0.622 | 0.625 | 0.507 | 0.529 | 0.492 | 0.497 | 0.513 |
| FRR | 0.534 | 0.557 | 0.488 | 0.588 | 0.572 | 0.501 | 0.519 | 0.488 | 0.491 | 0.505 |
| PF | 0.554 | 0.668 | 0.481 | 0.628 | 0.647 | 0.486 | 0.529 | 0.438 | 0.473 | 0.499 |
| OF | 0.288 | 0.475 | 0.638 | 0.632 | 0.543 | 0.480 | 0.475 | 0.523 | 0.487 | 0.481 |
| OF* | 0.556 | 0.856 | 0.235 | 0.632 | 0.727 | |||||
| r | df | 95% CI | p | |
|---|---|---|---|---|
| FRB | 0.505 | 2945 | (0.431, 0.573) | 1.095 × 10−190 |
| FRL | 0.360 | 2945 | (0.260, 0.452) | 1.026 × 10−90 |
| FRR | 0.471 | 2945 | (0.399, 0.539) | 2.338 × 10−162 |
| PF | 0.338 | 2945 | (0.246, 0.423) | 1.999 × 10−79 |
| OF | 0.445 | 2945 | (0.367, 0.512) | 2.460 × 10−143 |
| OF* | 0.517 | 1588 | (0.433, 0.589) | 2.788 × 10−109 |
| Mean | SE | df | Lower CI | Upper CI | t | p | |
|---|---|---|---|---|---|---|---|
| EMG ZM Responses | |||||||
| Intercept | 5.242 × 10−3 | 5.500 × 10−3 | 43.99 | −5.640 × 10−3 | 0.01614 | 0.953 | 0.3458 |
| Emotion | 2.601 × 10−2 | 7.362 × 10−3 | 43.98 | 0.01145 | 0.04061 | 3.532 | <0.0001 * |
| Presentation | 5.262 × 10−3 | 2.113 × 10−3 | 2296 | 0.01120 | 0.00940 | 2.490 | 0.0128 * |
| E*P | 5.917 × 10−3 | 2.989 × 10−3 | 2296 | 5.507 × 10−5 | 0.01177 | 1.980 | 0.0478 * |
| Simple effects according to the emotional condition | |||||||
| PL | 0.0303 | 0.0102 | 48.3 | 0.00989 | 0.05073 | ||
| PV | 0.0170 | 0.0101 | 47.8 | −0.00343 | 0.03733 | ||
| PL-PV | 0.0134 | 0.0042 | 2293 | 3.167 | 0.0016 * | ||
| NL | −0.0124 | 0.0046 | 71.8 | −0.02147 | −0.00330 | ||
| NV | −0.0139 | 0.0045 | 71.0 | −0.02296 | −0.00485 | ||
| NL-NV | 0.0015 | 0.0042 | 2298 | 0.360 | 0.7190 | ||
| Simple effects according to the presentation condition | |||||||
| PL-NL | 0.0427 | 0.0108 | 51.8 | 3.936 | 0.0002 * | ||
| PV-NV | 0.0309 | 0.0108 | 51.2 | 2.853 | 0.0062 * | ||
| FaceReader Bilateral AU12 | |||||||
| Intercept | 7.592 × 10−4 | 5.601 × 10−4 | 43.99 | −0.00035 | 0.00187 | 1.355 | 0.1822 |
| Emotion | 1.779 × 10−3 | 6.263 × 10−4 | 43.97 | 0.00054 | 0.00303 | 2.840 | 0.0068 * |
| Presentation | 4.607 × 10−4 | 1.261 × 10−4 | 2273 | 0.00021 | 0.00071 | 3.654 | 0.0003 * |
| E*P | 7.971 × 10−4 | 1.783 × 10−4 | 2273 | 0.00045 | 0.00115 | 4.470 | <0.0001 * |
| Simple effects according to the emotional condition | |||||||
| PL | 0.0027 | 0.0010 | 45.6 | 0.00079 | 0.00470 | ||
| PV | 0.0013 | 0.0010 | 45.5 | −0.00066 | 0.00325 | ||
| PL-PV | 0.0014 | 0.0003 | 2270 | 5.729 | <0.0001 * | ||
| NL | −0.0006 | 0.0003 | 59.8 | −0.0012 | 0.00009 | ||
| NV | −0.0004 | 0.0003 | 59.3 | −0.0011 | 0.00024 | ||
| NL-NV | −0.0001 | 0.0003 | 2276 | 0.579 | 0.5629 | ||
| Simple effects according to the presentation condition | |||||||
| PL-NL | 0.0033 | 0.0009 | 47.7 | −3.664 | 0.0006 * | ||
| PV-NV | 0.0017 | 0.0009 | 47.5 | −1.903 | 0.0631 | ||
| Py-Feat AU12 | |||||||
| Intercept | 1.117 × 10−3 | 3.553 × 10−4 | 46.00 | 0.00042 | 0.00182 | 3.145 | 0.0029 * |
| Emotion | 1.271 × 10−3 | 1.394 × 10−4 | 2563 | 0.00100 | 0.00154 | 9.115 | <0.0001 * |
| Presentation | 6.478 × 10−4 | 1.393 × 10−4 | 2562 | 0.00037 | 0.00092 | 4.651 | <0.0001 * |
| E*P | 7.813 × 10−4 | 1.968 × 10−4 | 2561 | 0.00040 | 0.00117 | 3.969 | <0.0001 * |
| Simple effects according to the emotional condition | |||||||
| PL | 0.0029 | 0.0004 | 71.9 | 0.00207 | 0.00366 | ||
| PV | 0.0012 | 0.0004 | 68.8 | 0.00038 | 0.00195 | ||
| PL-PV | 0.0017 | 0.0003 | 2561 | 6.035 | <0.0001 * | ||
| NL | 0.00029 | 0.0004 | 69.0 | −0.00050 | 0.00107 | ||
| NV | 0.00015 | 0.0004 | 68.6 | −0.00063 | 0.00094 | ||
| NL-NV | 0.00014 | 0.0003 | 2561 | 0.489 | 0.6248 | ||
| Simple effects according to the presentation condition | |||||||
| PL-NL | 0.0026 | 0.0003 | 2563 | 9.146 | <0.0001 * | ||
| PV-NV | 0.0001 | 0.0003 | 2561 | 3.691 | 0.0002 * | ||
| OpenFace AU12 | |||||||
| Intercept | 1.550 × 10−2 | 4.261 × 10−3 | 42.78 | 0.00707 | 0.02395 | 3.637 | 0.0007 * |
| Emotion | 4.797 × 10−3 | 1.589 × 10−3 | 35.54 | 0.00167 | 0.00799 | 3.019 | 0.0047 * |
| Presentation | 3.628 × 10−3 | 5.753 × 10−4 | 2292 | 0.00250 | 0.00476 | 6.306 | <0.0001 * |
| E*P | 2.178 × 10−3 | 8.136 × 10−4 | 2292 | 0.00058 | 0.00377 | 2.677 | 0.0075 * |
| Simple effects according to the emotional condition | |||||||
| PL | 0.0225 | 0.0051 | 45.2 | 0.01228 | 0.0328 | ||
| PV | 0.0152 | 0.0051 | 45.1 | 0.00498 | 0.0255 | ||
| PL-PV | 0.0073 | 0.0012 | 2300 | 6.362 | <0.0001 * | ||
| NL | 0.0136 | 0.0037 | 46.2 | 0.00617 | 0.0210 | ||
| NV | 0.0106 | 0.0037 | 46.2 | 0.00322 | 0.0180 | ||
| NL-NV | 0.0030 | 0.0012 | 2299 | 2.562 | 0.0105 * | ||
| Simple effects according to the presentation condition | |||||||
| PL-NL | 0.0090 | 0.0024 | 56.1 | 3.746 | 0.0004 * | ||
| PV-NV | 0.0046 | 0.0024 | 55.9 | 1.928 | 0.0589 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-T.; Sato, W. Electromyographic Validation of Spontaneous Facial Mimicry Detection Using Automated Facial Action Coding. Sensors 2023, 23, 9076. https://doi.org/10.3390/s23229076
Hsu C-T, Sato W. Electromyographic Validation of Spontaneous Facial Mimicry Detection Using Automated Facial Action Coding. Sensors. 2023; 23(22):9076. https://doi.org/10.3390/s23229076
Chicago/Turabian StyleHsu, Chun-Ting, and Wataru Sato. 2023. "Electromyographic Validation of Spontaneous Facial Mimicry Detection Using Automated Facial Action Coding" Sensors 23, no. 22: 9076. https://doi.org/10.3390/s23229076
APA StyleHsu, C. -T., & Sato, W. (2023). Electromyographic Validation of Spontaneous Facial Mimicry Detection Using Automated Facial Action Coding. Sensors, 23(22), 9076. https://doi.org/10.3390/s23229076