

A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels

Abstract
:1. Introduction
- We propose a pseudo label generation module, which generates bipartite maps of maize and weeds by using Exceed green feature Graying (EXG) and Otsu, generates maize masks by the GrabCut method, and obtains the mask images of maize and weeds, respectively, by using the dissimilar-or operation, and then refines the generated pseudo labels by the erosion and DenseCRF methods to reduce the annotation cost.
- We design an encoder–decoder-based semantic segmentation network, introducing the lightweight model MobileNet-V2 and the Atrous Spatial Pyramid Pooling (ASPP) module to obtain high-accuracy semantic segmentation results.
- We demonstrate the feasibility of the proposed method by comparing it with existing methods. The proposed method outperforms the semantic segmentation accuracy of DeepLab-V3+ and PSPNet under weakly and fully supervised learning conditions, and experiments on the corn and weed image dataset demonstrate the effectiveness of our model.
2. Materials and Methods
2.1. Datasets and Labels
2.1.1. Data Acquisition and Preprocessing
2.1.2. Scrawl Label
2.2. SL-Net Modeling Framework
2.2.1. Pseudo Label Generation Module
2.2.2. Encoder and Decoder Structure
3. Experiments and Discussions
3.1. Experimental Environment and Parameters
3.2. Loss Functions and Evaluation Indicators
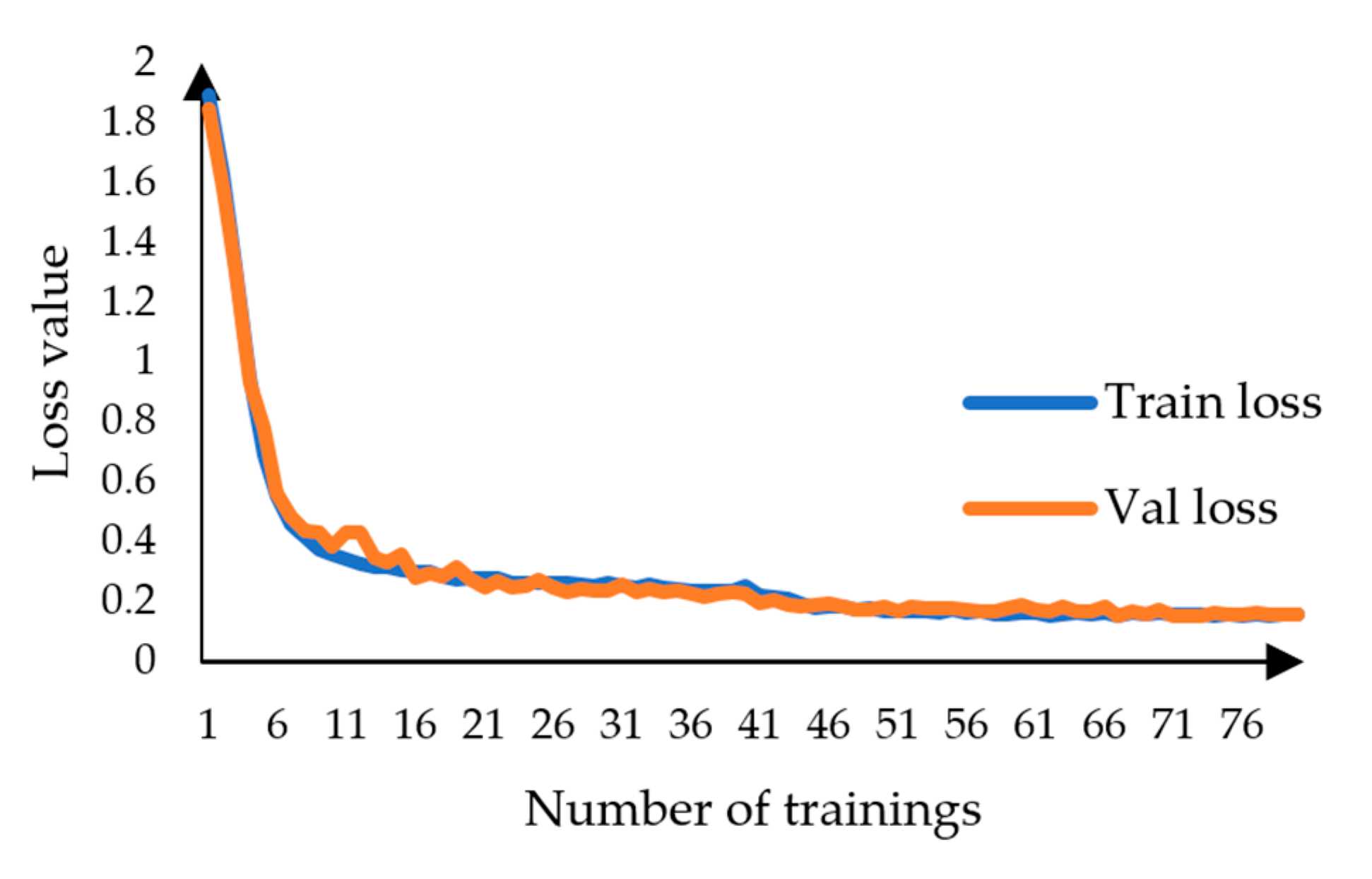
3.3. Experimental Results and Analysis
4. Conclusions
- (1)
- We designed a pseudo label generation module, which can alleviate the labeling cost of data and improve training efficiency. Using scrawl labels as annotations, pixel-level pseudo labels are generated by combining Exceed green feature Graying (EXG) with DenseCRF conditional random fields, and the MIoU and merger ratio and cosine similarity between pseudo labels and the true values reach 83.32% and 93.55%, respectively.
- (2)
- A weakly supervised semantic segmentation model based on scrawl labels, with pseudo labels instead of manually labeled pixel-level labels as input for model training, using the lightweight network MobileNet-V2 as the backbone network and introducing the ensemble similarity measure function Dice loss function, was developed to achieve high-precision semantic segmentation of seedling maize and weed images. The MIoU and MPA of the model reached 87.30% and 94.06%, respectively, and in the weakly supervised learning mode with pseudo labels as training samples, the MIoU improved by 3.48% and 9.39% compared with the original DeepLab-V3+ model and the PSPNet model, and by 13.32% when comparing with the **PSPNet model, which was improved by the same method.
- (3)
- In the semantic segmentation task of seedling maize and weed images, the SL-Net model can achieve comparable or even better accuracy than the fully supervised model. Compared with the DeepLab-V3+ series of models for fully supervised learning, the semantic segmentation accuracy of the SL-Net model can reach 101.39% of the DeepLab-V3+ model in the series, and compared with the fully supervised learning of the PSPNet series model, the SL-Net model has a higher accuracy in semantic segmentation tasks, in which the highest accuracy of 109.02% is achieved compared to the **PSPNet model in the series.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Munz, S.; Reiser, D. Approach for Image-Based Semantic Segmentation of Canopy Cover in Pea–Oat Intercropping. Agriculture 2020, 10, 354. [Google Scholar] [CrossRef]
- Hadisseh, R.; Mojtaba, D.; Romina, H. Leaf area estimation in lettuce: Comparison of artificial intelligence-based methods with image analysis technique. Measurement 2023, 222, 113636. [Google Scholar]
- Gao, M.; Lu, T.; Wang, L. Crop Mapping Based on Sentinel-2 Images Using Semantic Segmentation Model of Attention Mechanism. Sensors 2023, 23, 7008. [Google Scholar] [CrossRef] [PubMed]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Ahmadi, P.; Mansor, S.; Farjad, B.; Ghaderpour, E. Unmanned Aerial Vehicle (UAV)-Based Remote Sensing for Early-Stage Detection of Ganoderma. Remote Sens. 2022, 14, 1239. [Google Scholar] [CrossRef]
- Fathipoor, H.; Arefi, H. Crop and Weed Segmentation on Ground-Based Images Using Deep Convolutional Neural Network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, X-4/W1-2022, 195–200. [Google Scholar] [CrossRef]
- Genze, N.; Wirth, M.; Schreiner, C.; Ajekwe, R.; Grieb, M.; Grimm, D.G. Improved weed segmentation in UAV imagery of sorghum fields with a combined deblurring segmentation model. Plant Methods 2023, 19, 87. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Wang, S.; Lu, Y. Real-time segmentation of weeds in cornfields based on depthwise separable convolution residual network. Int. J. Comput. Sci. Eng. 2021, 23, 307–318. [Google Scholar] [CrossRef]
- Jiang, K.; Afzaal, U.; Lee, J. Transformer-Based Weed Segmentation for Grass Management. Sensors 2023, 23, 65. [Google Scholar] [CrossRef] [PubMed]
- Andres, M.; Philipp, L.; Cyrill, S. Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in CNNS. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Chen, S.; Zhang, K.; Wu, S.; Tang, Z.; Zhao, Y.; Sun, Y.; Shi, Z. A Weakly Supervised Approach for Disease Segmentation of Maize Northern Leaf Blight from UAV Images. Drones 2023, 7, 173. [Google Scholar] [CrossRef]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly Supervised Deep Learning for Segmentation of Remote Sensing Imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef]
- Kim, W.-S.; Lee, D.-H.; Kim, T.; Kim, H.; Sim, T.; Kim, Y.-J. Weakly Supervised Crop Area Segmentation for an Autonomous Combine Harvester. Sensors 2021, 21, 4801. [Google Scholar] [CrossRef] [PubMed]
- Rostom, K.; Mahmoud, S.; Mohamed, A. Unsupervised image segmentation based on local pixel clustering and low-level region merging. In Proceedings of the 2016 2nd International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Monastir, Tunisia, 21–23 March 2016; pp. 177–182. [Google Scholar]
- Shaji, S.S.; Varghese, A. Unsupervised Segmentation of Images using CNN. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 403–406. [Google Scholar]
- Zhou, Z. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Deepak, P.; Evan, S.; Jonathan, L.; Trevor, D. Fully Convolutional Multi-Class Multiple Instance Learning. arXiv 2014, arXiv:1412.7144. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the 2016 European Conference on Computer Vision 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 549–565. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoderdecoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Volume 11211. [Google Scholar]
- Carsten, R.; Vladimir, K.; Andrew, B. “GrabCut”: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar]
- Philipp, K.; Vladlen, K. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS’11) 2011, Granada, Spain, 12–15 December 2011; pp. 109–117. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Li, Z.; Wang, L.; Liu, J. Research on image recognition algorithm of valve switch state based on Cosine similarity. In Proceedings of the 2020 International Conference on Virtual Reality and Intelligent Systems (ICVRIS) 2020, Zhangjiajie, China, 18–19 July 2020; pp. 458–461. [Google Scholar] [CrossRef]
- Mark, S.; Andrew, H.; Menglong, Z.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Shao, L.; Zhu, F.; Li, X. Transfer Learning for Visual Categorization: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1019–1034. [Google Scholar] [CrossRef] [PubMed]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| Image batch | 2 |
| Max learning rate | 0.0005 |
| Min learning rate | 0.000005 |
| Training epoch | 40 |
| Weight decay | 0 |
| Momentum factor | 0.9 |
| Input size | 1024 × 1024 |
| Model Name | Network of Features | Loss Function | MIoU/% | MPA/% | FPS/Frames × s−1 |
|---|---|---|---|---|---|
| DeepLab-V3+ | Xception | LCE | 83.82 | 90.92 | 7.52 |
| *DeepLab-V3+ | Xception | LCE + LDic | 84.36 | 92.04 | 7.46 |
| **DeepLab-V3+ | MobileNet-V2 | LCE | 87.19 | 93.48 | 20.32 |
| PSPNet | Resnet50 | LCE | 77.91 | 84.41 | 12.16 |
| *PSPNet | Resnet50 | LCE + LDic | 79.05 | 87.16 | 12.17 |
| **PSPNet | MobileNet-V2 | LCE + LDic | 73.98 | 85.30 | 38.09 |
| SL-Net | MobileNet-V2 | LCE + LDic | 87.30 | 94.06 | 21.20 |
| Fully Supervised Model Name | Semantic Segmentation Accuracy/% | Semantic Segmentation Accuracy of SL-Net/% | Accuracy Ratio (SL-Net/Fully Supervised)/% |
|---|---|---|---|
| DeepLab-V3+ | 86.10 | 87.30 | 101.39 |
| *DeepLab-V3+ | 86.54 | 100.88 | |
| **DeepLab-V3+ | 87.51 | 99.76 | |
| PSPNet | 83.52 | 104.53 | |
| *PSPNet | 84.14 | 103.76 | |
| **PSPNet | 80.08 | 109.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhao, Y.; Liu, T.; Deng, H. A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels. Sensors 2023, 23, 9846. https://doi.org/10.3390/s23249846
Zhao L, Zhao Y, Liu T, Deng H. A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels. Sensors. 2023; 23(24):9846. https://doi.org/10.3390/s23249846
Chicago/Turabian StyleZhao, Lulu, Yanan Zhao, Ting Liu, and Hanbing Deng. 2023. "A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels" Sensors 23, no. 24: 9846. https://doi.org/10.3390/s23249846
APA StyleZhao, L., Zhao, Y., Liu, T., & Deng, H. (2023). A Weakly Supervised Semantic Segmentation Model of Maize Seedlings and Weed Images Based on Scrawl Labels. Sensors, 23(24), 9846. https://doi.org/10.3390/s23249846