
Hardware-Based Architecture for DNN Wireless Communication Models

Abstract
:1. Introduction
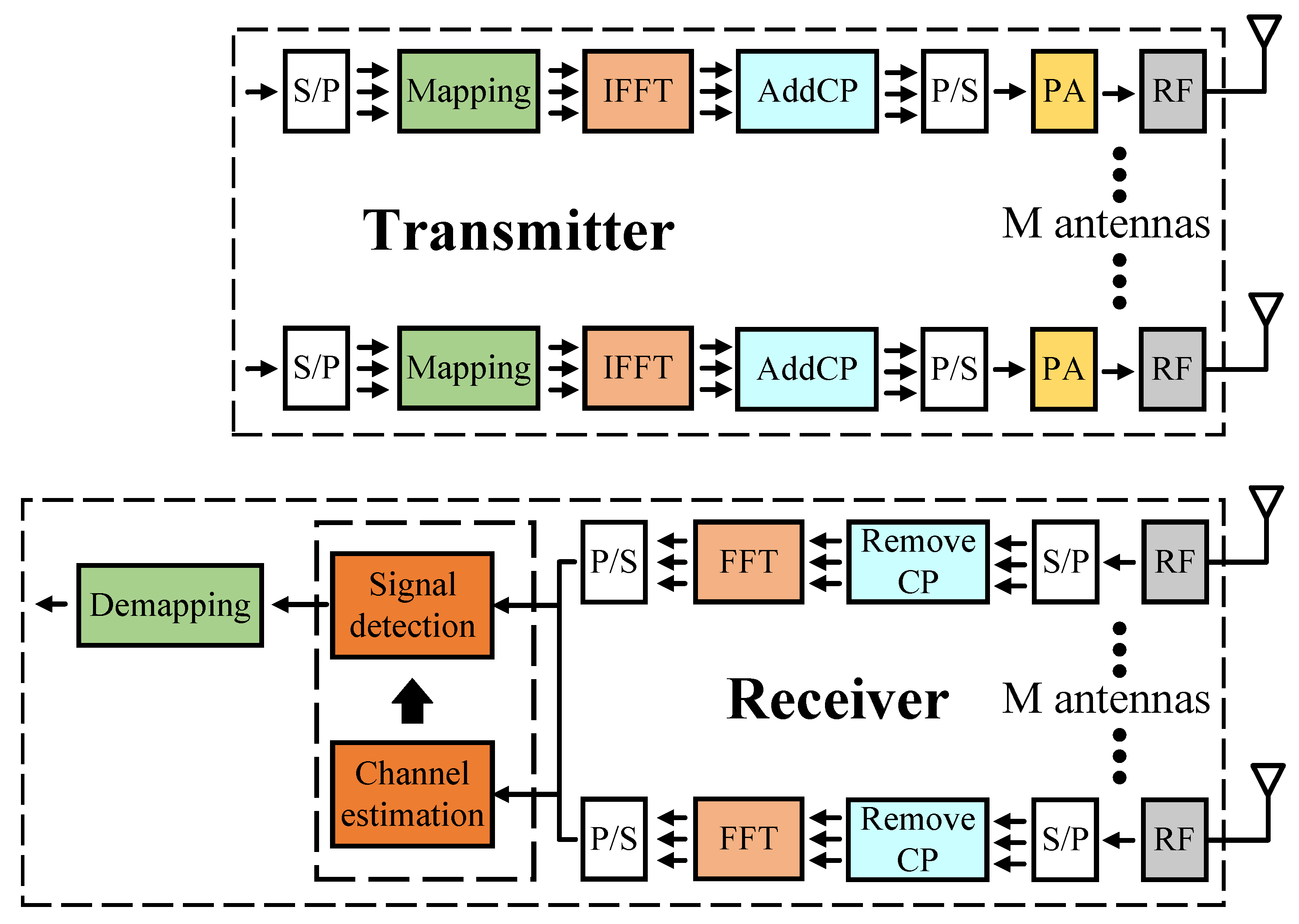
2. System Model
3. Background
3.1. Channel Estimator
3.2. Conventional Detector
3.2.1. ZF Detector
3.2.2. MMSE Detector
3.2.3. MLD Detector
3.3. Non-Linear Noise in MIMO OFDM Systems
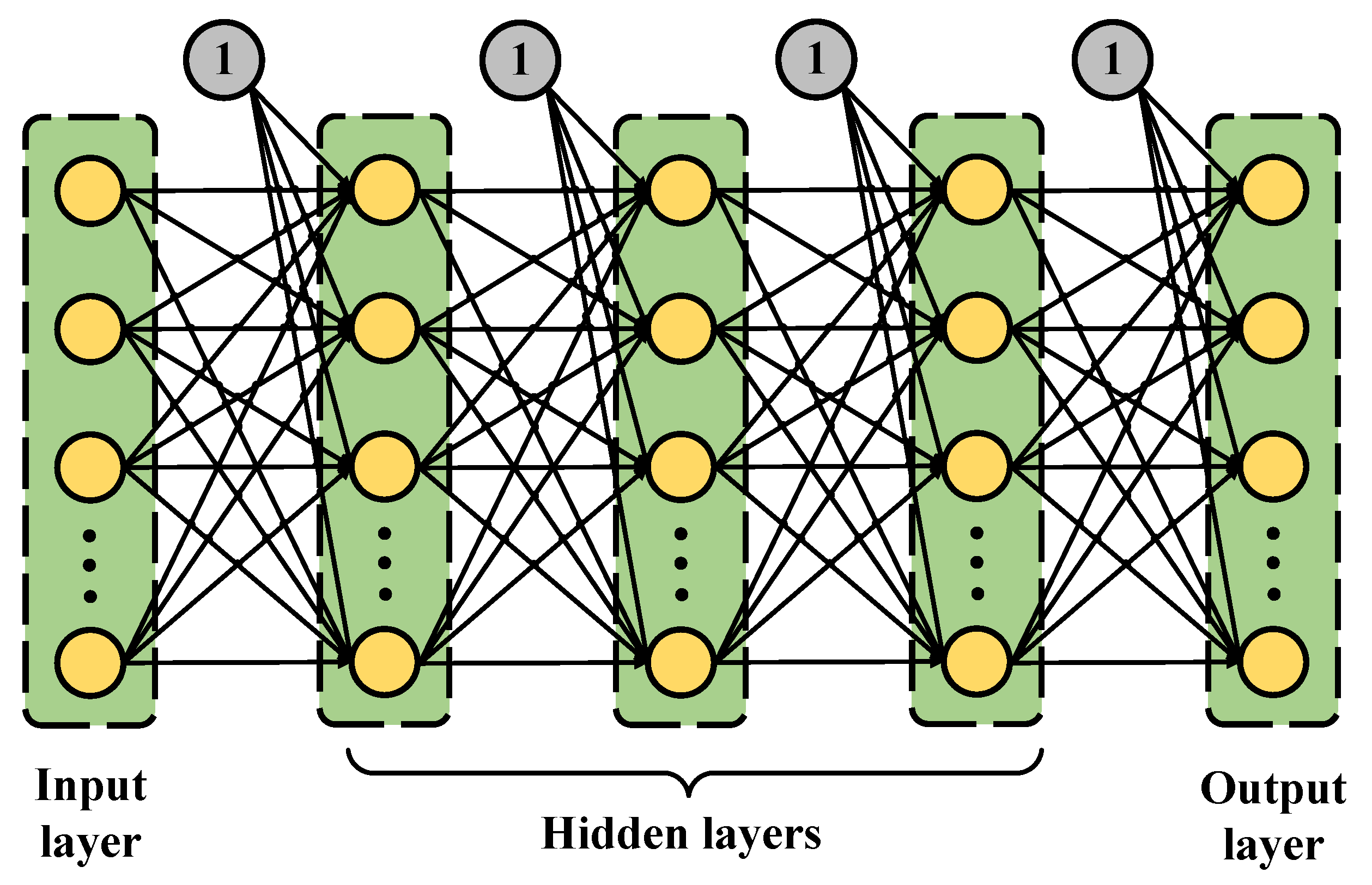
4. Proposed DNN-Based MIMO OFDM Models
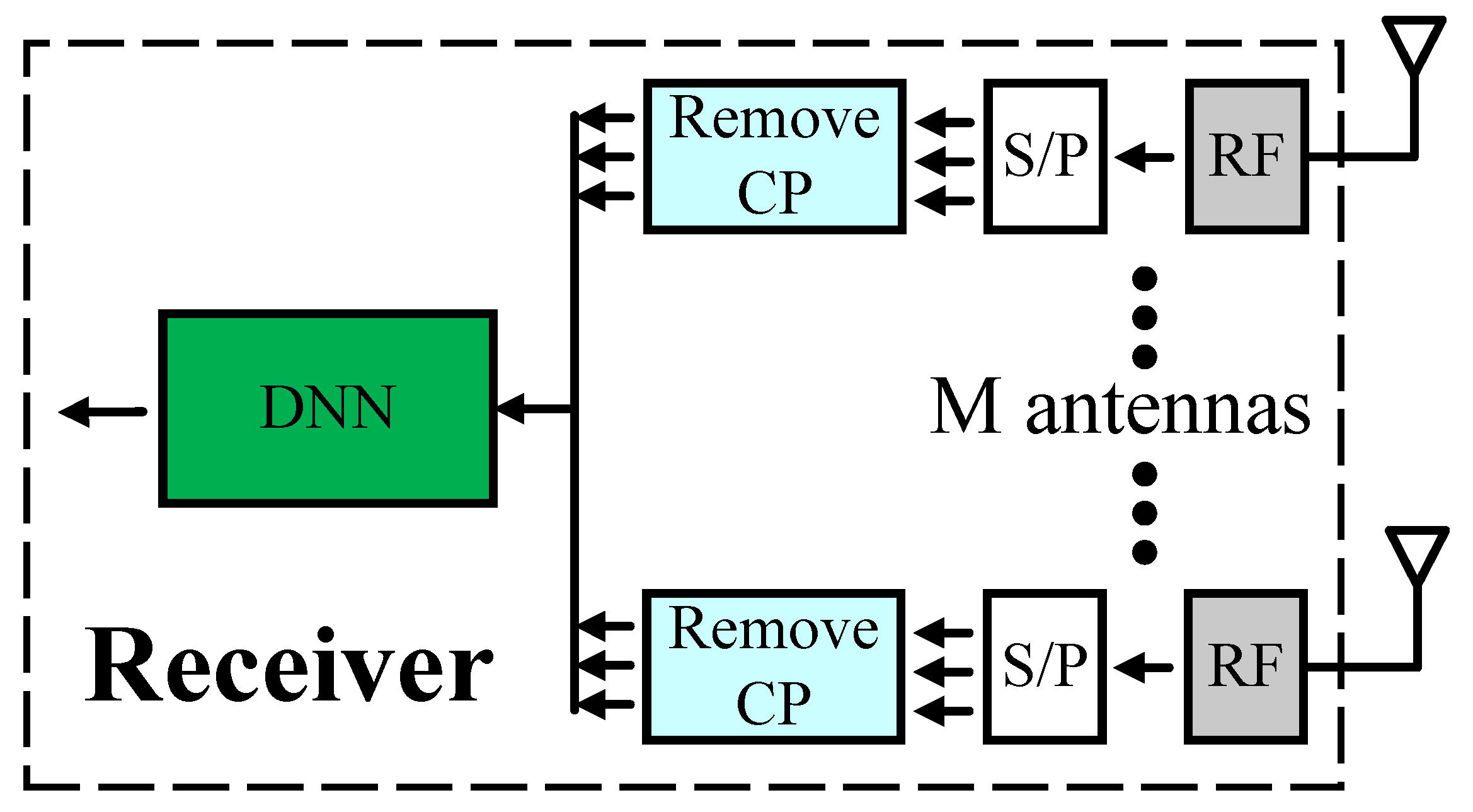
4.1. Model Type I
4.2. Model Type II
4.3. Model Type III
5. Hardware Architectures
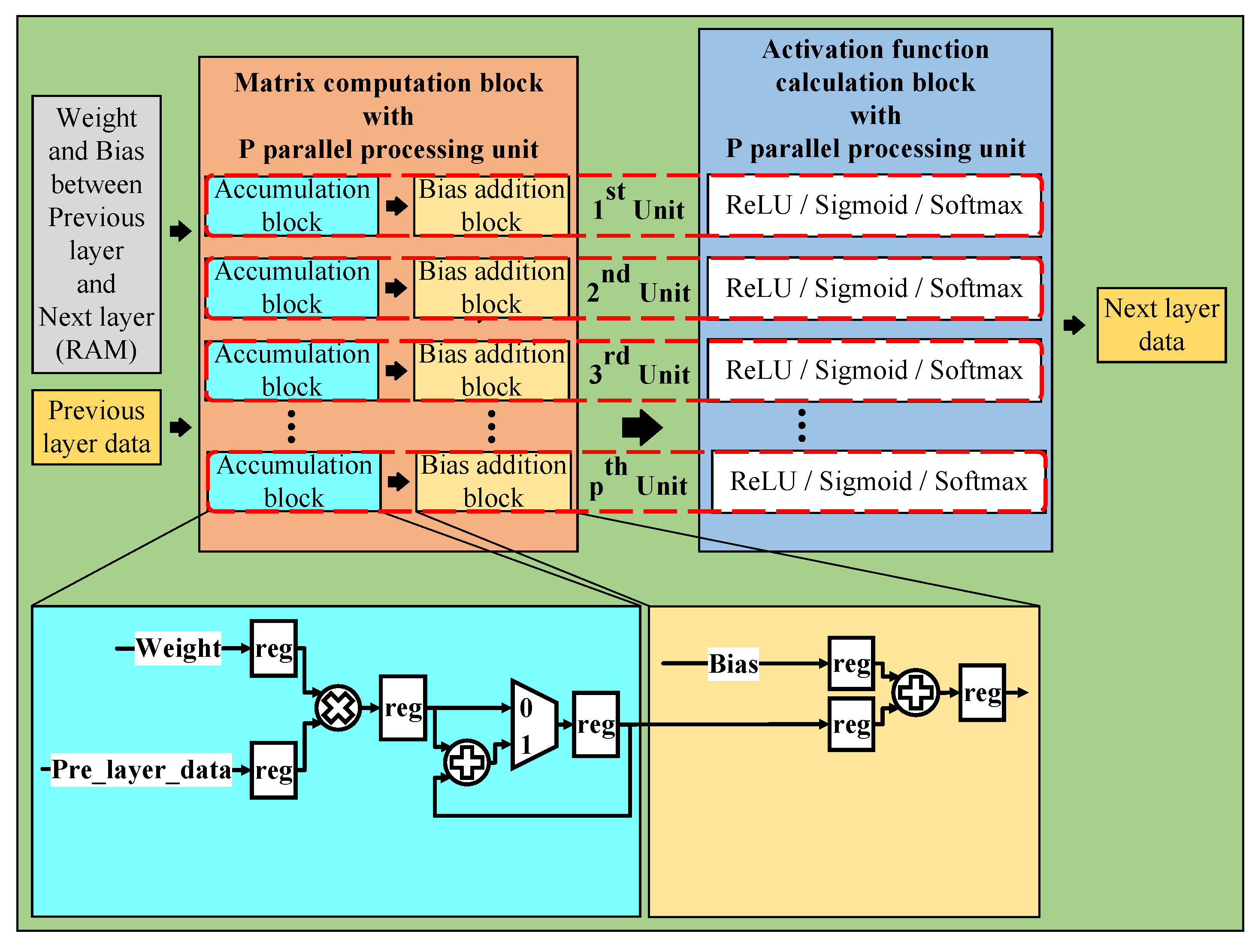
5.1. The Usual Neural Network Hardware Architecture
5.1.1. Matrix Computation Block
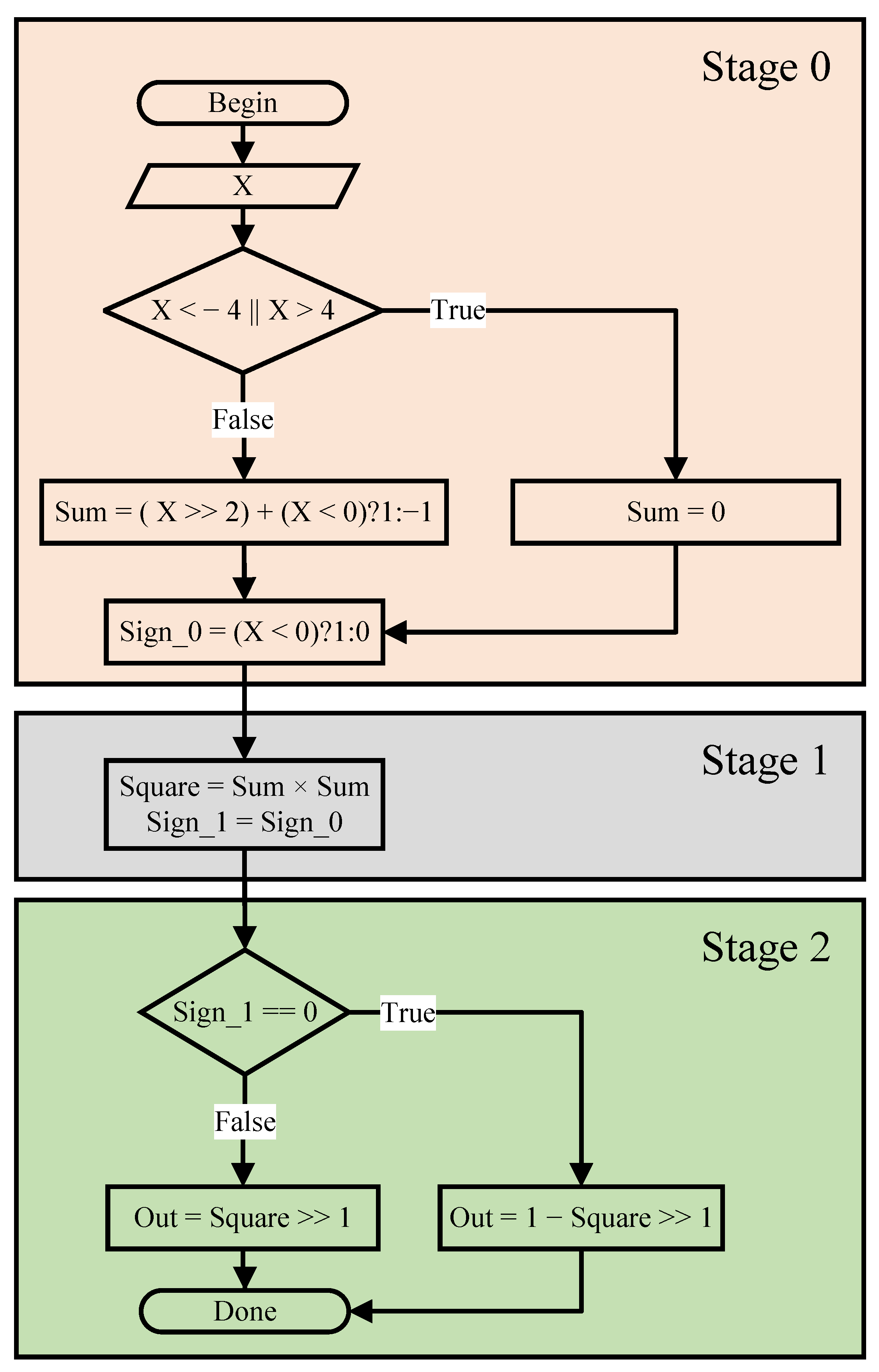
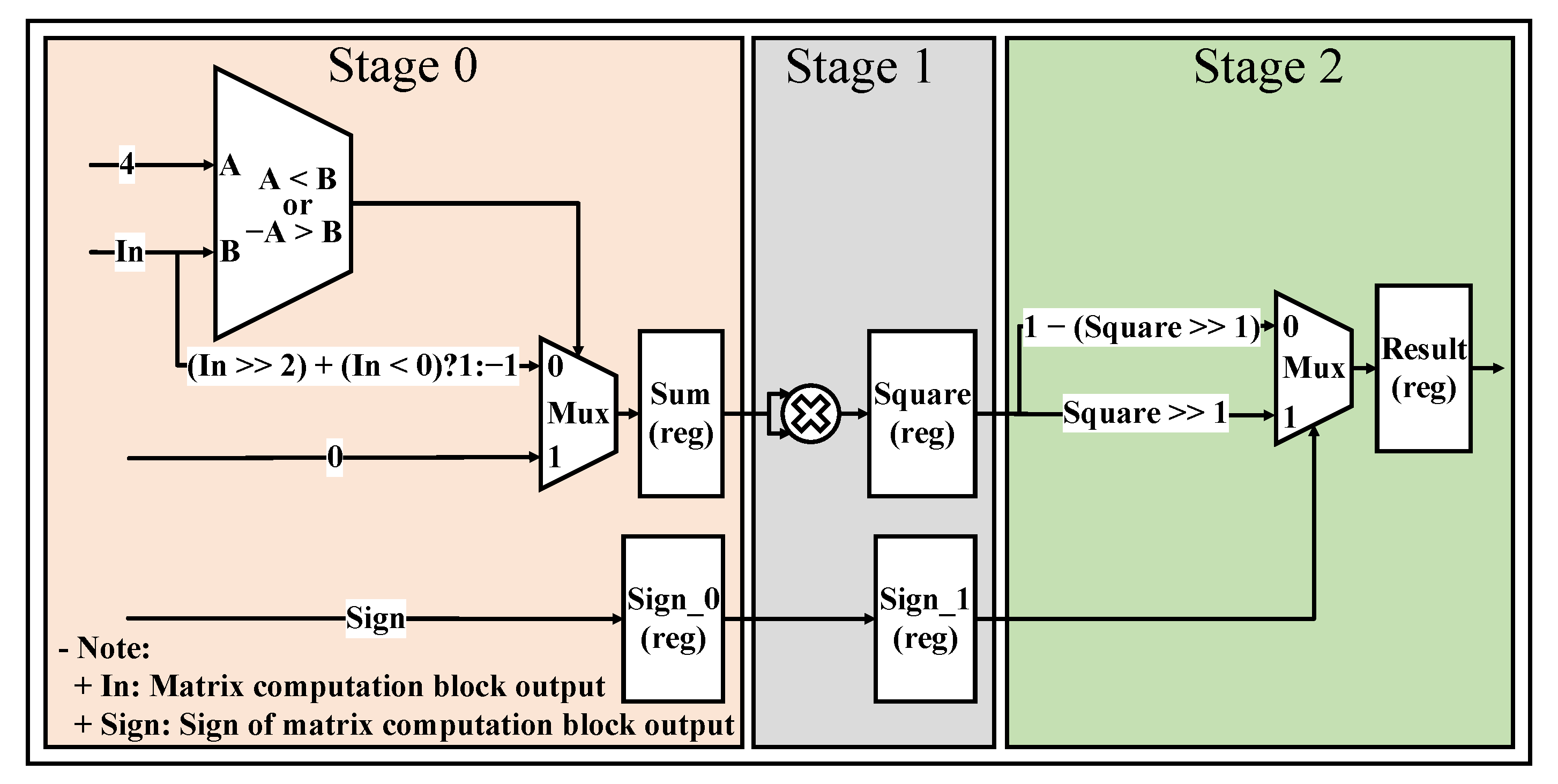
5.1.2. Activation Function Calculation Block
5.2. The Quantized Neural Network Hardware Architecture
5.2.1. Quantization Technique
5.2.2. Hardware Design for the Quantized Neural Network
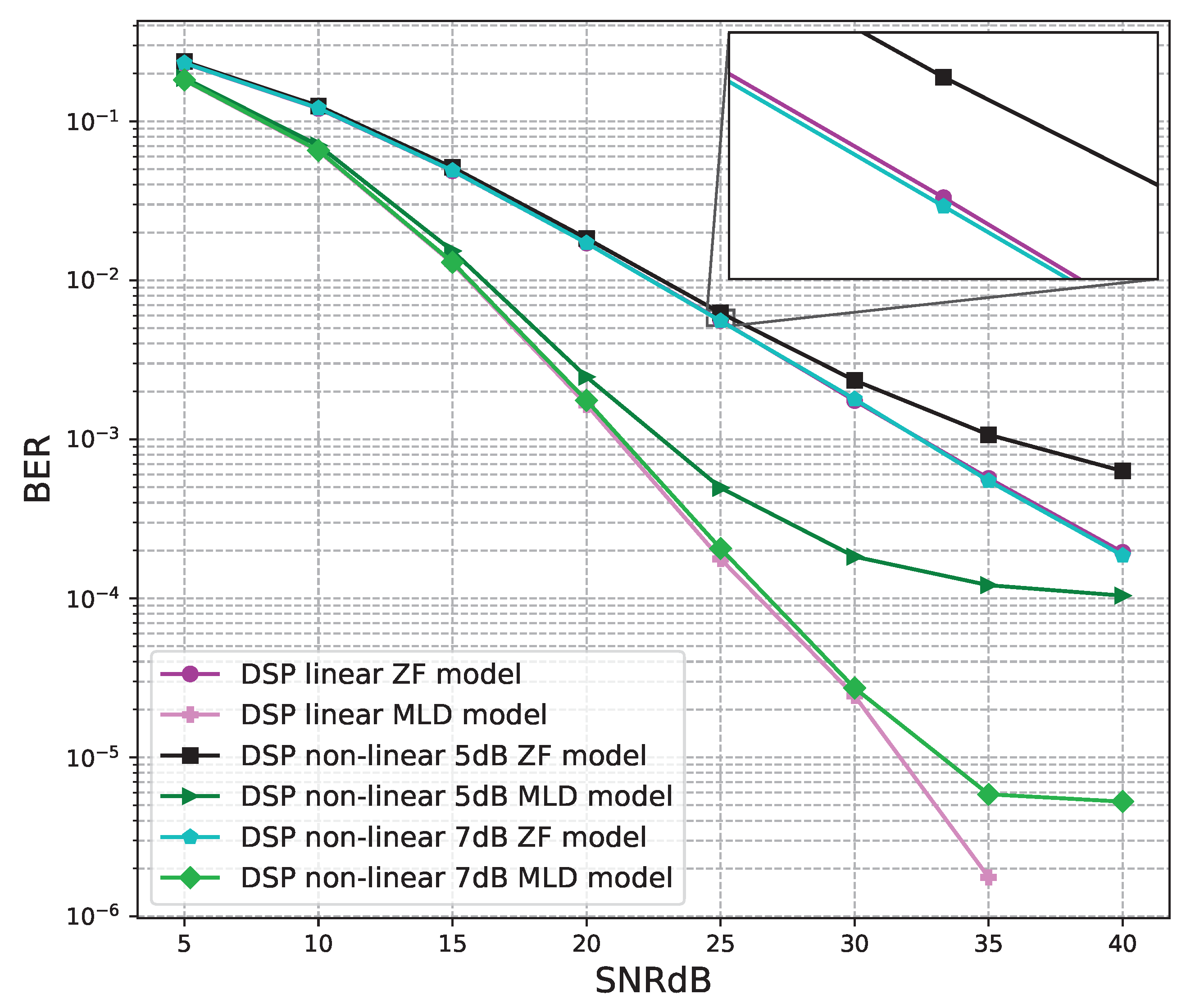
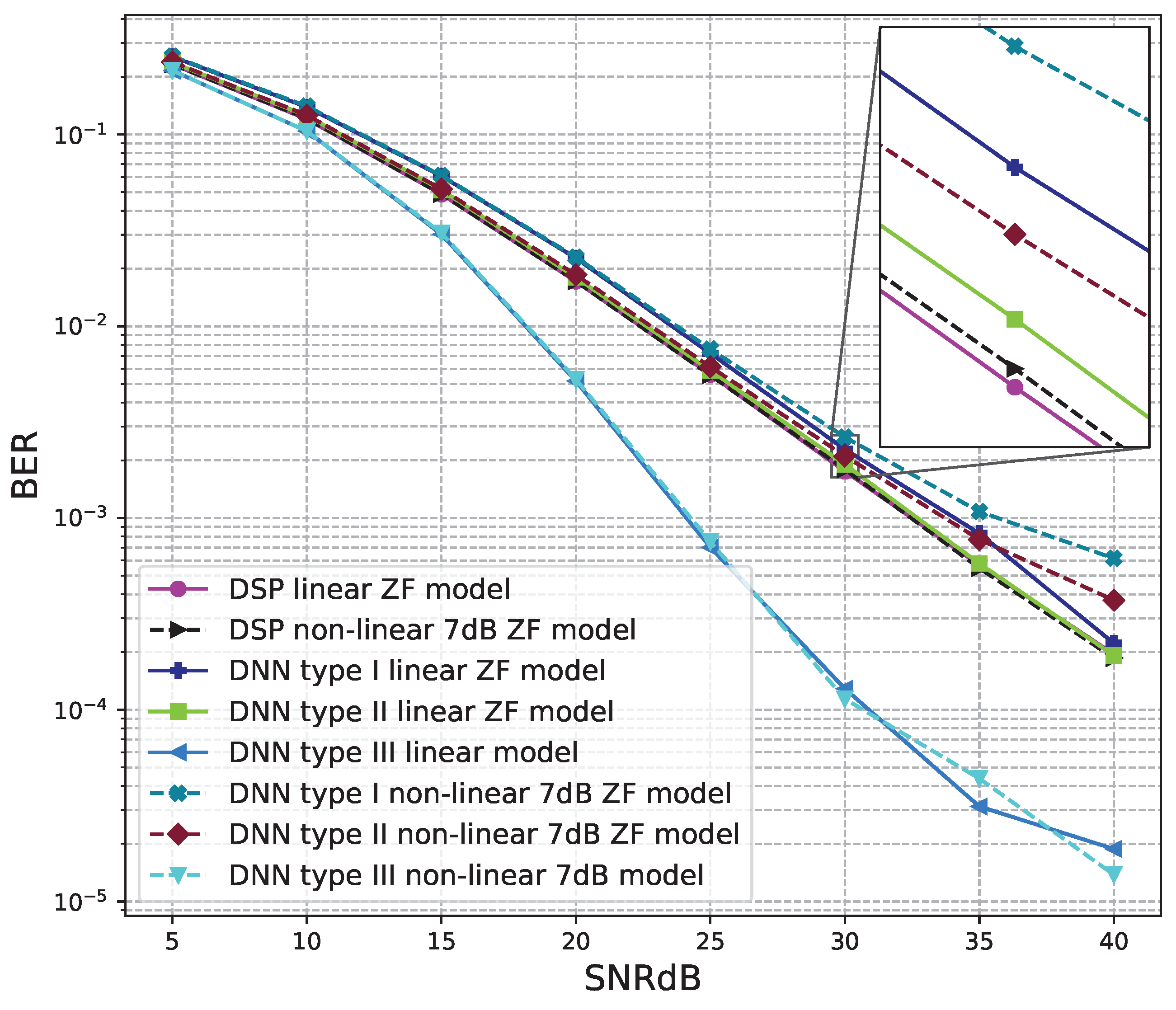
6. Experimental Results and Discussions
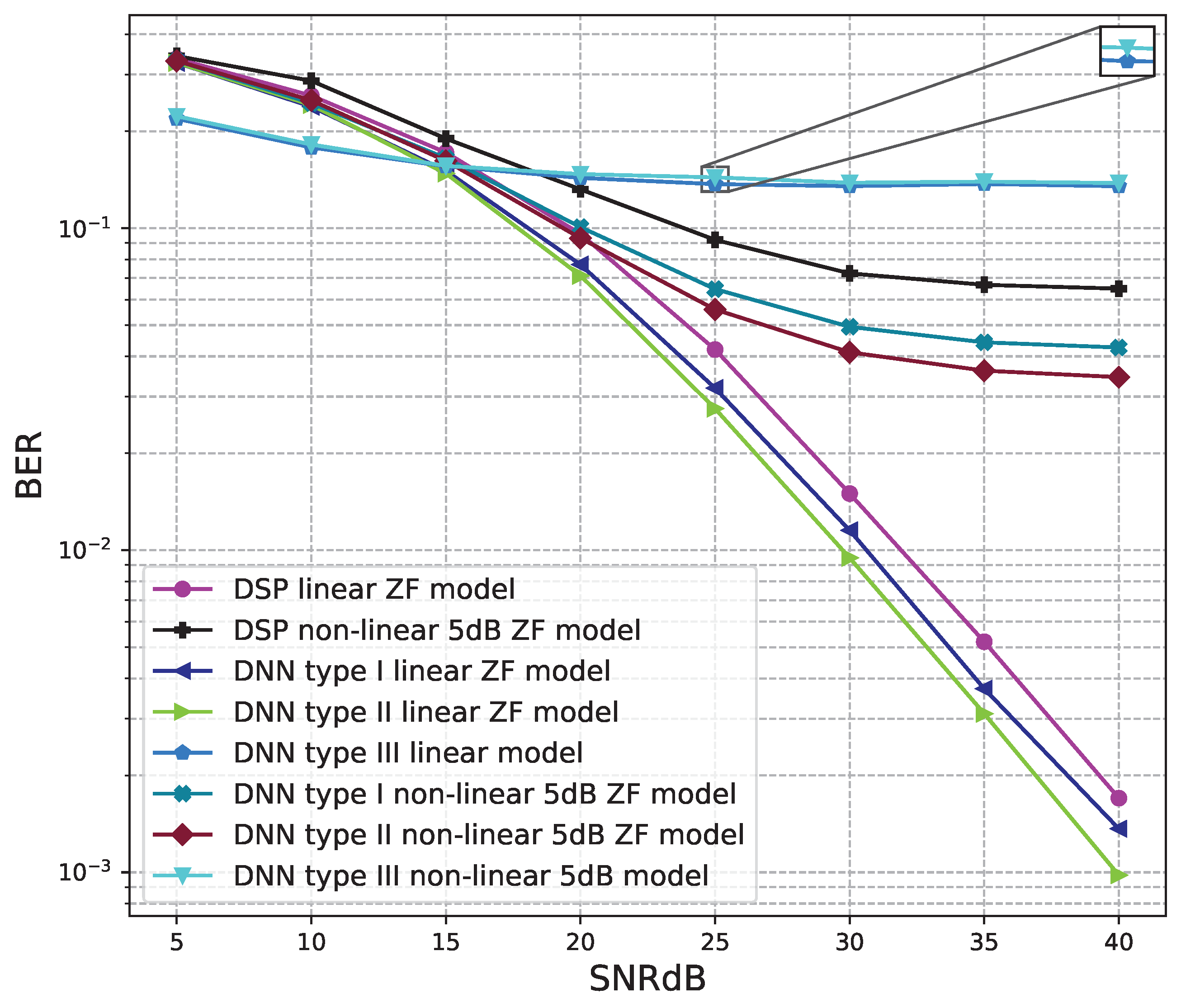
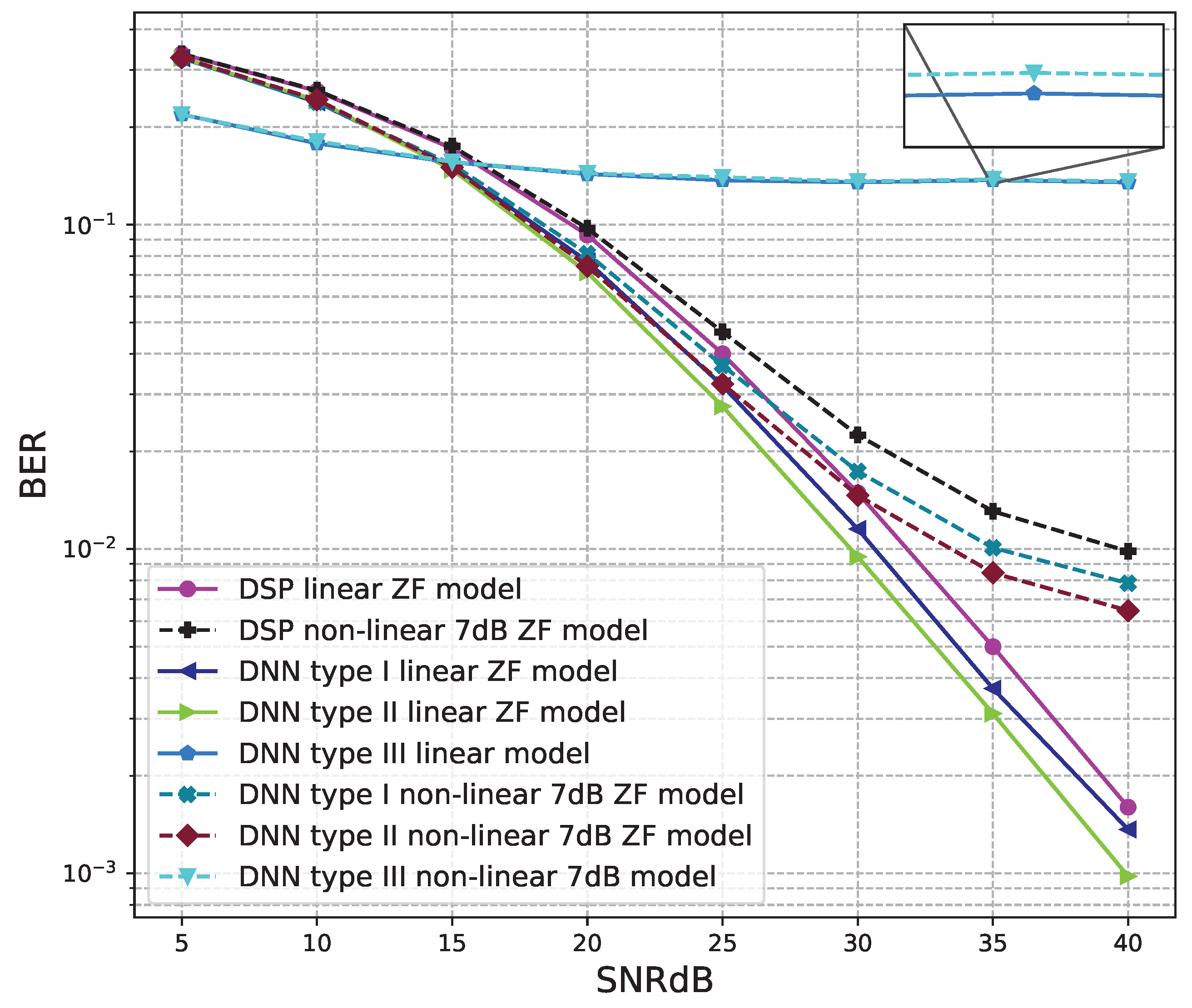
6.1. Software Results
6.1.1. 2 × 2 MIMO OFDM Model
6.1.2. 4 × 4 MIMO OFDM Model
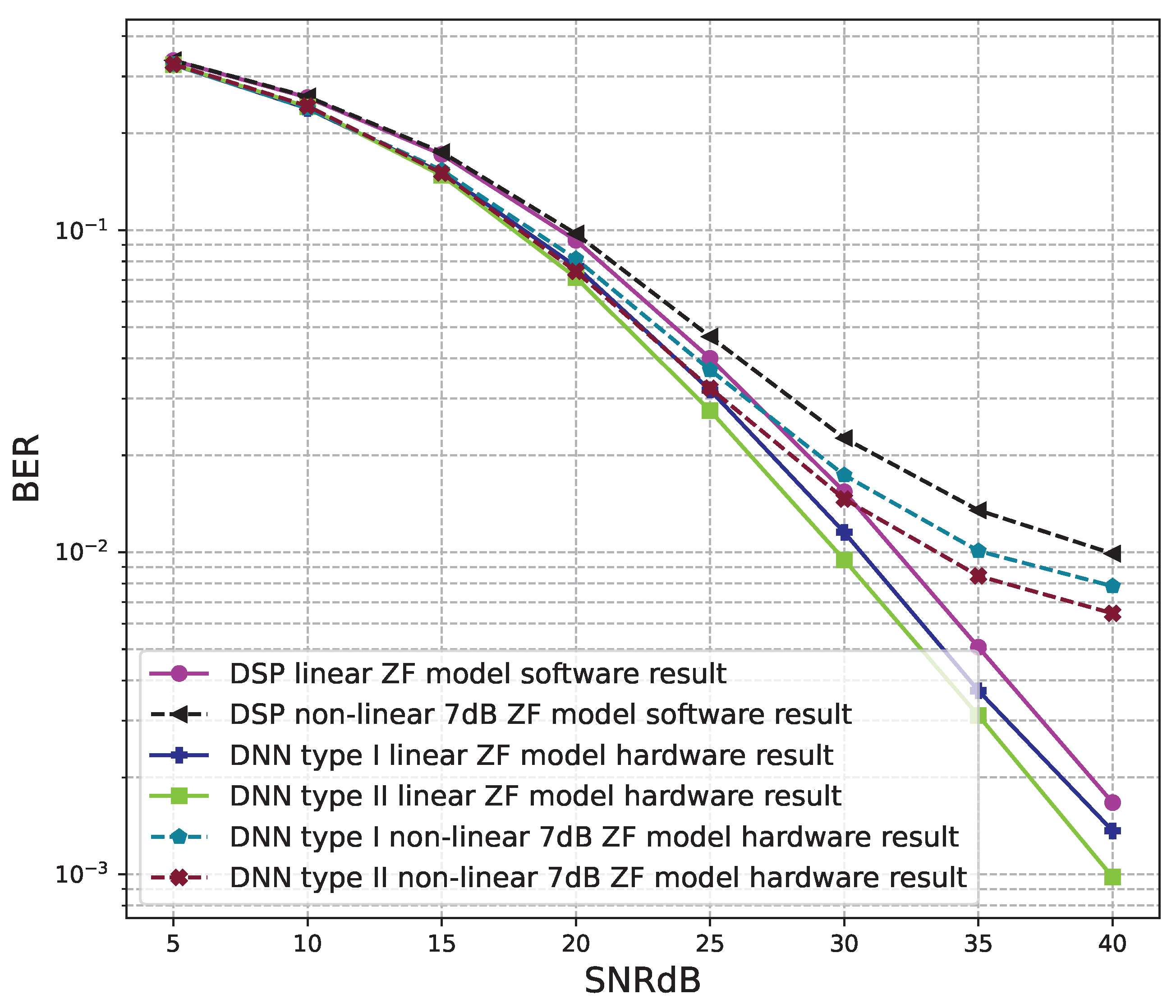
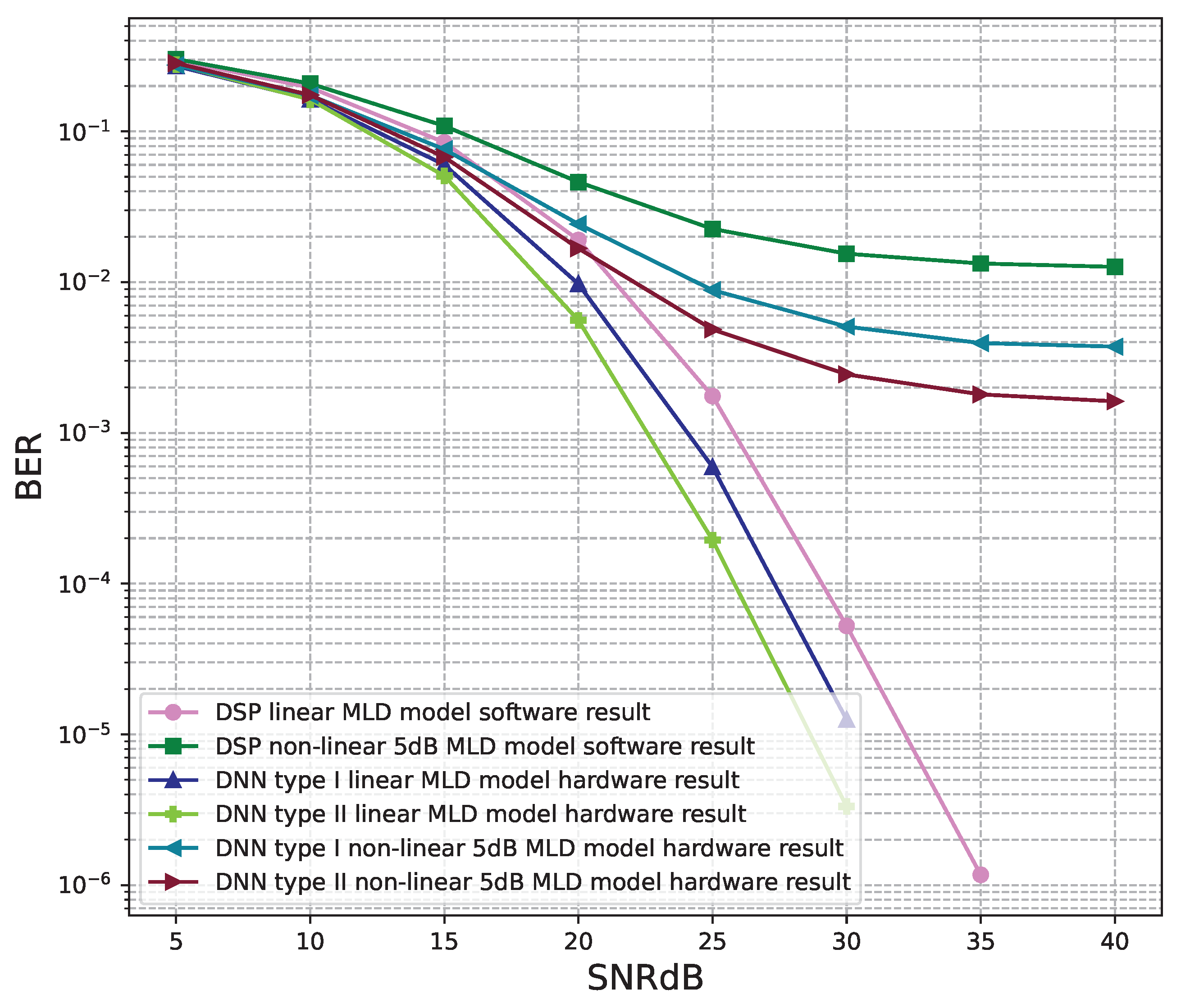
6.2. Hardware Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hammed, Z.S.; Ameen, S.Y.; Zeebaree, S.R.M. Massive MIMO-OFDM Performance Enhancement on 5G. In Proceedings of the 2021 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Hvar, Croatia, 23–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Riadi, A.; Boulouird, M.; Hassani, M.M. Least Squares Channel Estimation of an OFDM Massive MIMO System for 5G Wireless Communications. In Proceedings of the 8th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT’18), Genoa, Italy, 18–20 December 2018; Volume 2, pp. 440–450. [Google Scholar]
- He, H.; Wen, C.K.; Jin, S. Bayesian Optimal Data Detector for Hybrid mmWave MIMO-OFDM Systems With Low-Resolution ADCs. IEEE J. Sel. Top. Signal Process. 2018, 12, 469–483. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Jian, M.; Gao, F.; Li, G.Y.; Lin, H. Beam Squint and Channel Estimation for Wideband mmWave Massive MIMO-OFDM Systems. IEEE Trans. Signal Process. 2019, 67, 5893–5908. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Yin, Q.; Gao, F. Computationally Efficient Blind Estimation of Carrier Frequency Offset for MIMO-OFDM Systems. IEEE Trans. Wirel. Commun. 2016, 15, 7644–7656. [Google Scholar] [CrossRef]
- Singal, A.; Kedia, D. Performance Analysis of MIMO-OFDM System Using SLM with Additive Mapping and U2 Phase Sequence for PAPR Reduction. Wirel. Pers. Commun. 2020, 111, 1377–1390. [Google Scholar] [CrossRef]
- Li, X.; Cimini, L.J. Effects of clipping and filtering on the performance of OFDM. IEEE Commun. Lett. 1998, 2, 131–133. [Google Scholar] [CrossRef]
- Baek, M.S.; Kwak, S.; Jung, J.Y.; Kim, H.M.; Choi, D.J. Implementation Methodologies of Deep Learning-Based Signal Detection for Conventional MIMO Transmitters. IEEE Trans. Broadcast. 2019, 65, 636–642. [Google Scholar] [CrossRef]
- Xia, J.; He, K.; Xu, W.; Zhang, S.; Fan, L.; Karagiannidis, G.K. A MIMO Detector With Deep Learning in the Presence of Correlated Interference. IEEE Trans. Veh. Technol. 2020, 69, 4492–4497. [Google Scholar] [CrossRef]
- He, K.; Wang, Z.; Huang, W.; Deng, D.; Xia, J.; Fan, L. Generic Deep Learning-Based Linear Detectors for MIMO Systems Over Correlated Noise Environments. IEEE Access 2020, 8, 29922–29929. [Google Scholar] [CrossRef]
- He, K.; Wang, Z.; Li, D.; Zhu, F.; Fan, L. Ultra-reliable MU-MIMO detector based on deep learning for 5G/B5G-enabled IoT. Phys. Commun. 2020, 43, 101181. [Google Scholar] [CrossRef]
- Xu, L.; Gao, F.; Zhang, W.; Ma, S. Model Aided Deep Learning Based MIMO OFDM Receiver With Nonlinear Power Amplifiers. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H. Power of Deep Learning for Channel Estimation and Signal Detection in OFDM Systems. IEEE Wirel. Commun. Lett. 2018, 7, 114–117. [Google Scholar] [CrossRef]
- Cho, Y.S.; Kim, J.; Yang, W.Y.; Kang, C.G. MIMO-OFDM Wireless Communications with MATLAB; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Li, X.; Cimini, L.J. Effects of clipping and filtering on the performance of OFDM. In Proceedings of the 1997 IEEE 47th Vehicular Technology Conference, Technology in Motion, Phoenix, AZ, USA, 4–7 May 1997; pp. 1634–1638. [Google Scholar]
- Zhang, M.; Vassiliadis, S.; Delgado-Frias, J. Sigmoid generators for neural computing using piecewise approximations. IEEE Trans. Comput. 1996, 45, 1045–1049. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bits | One-Hot Vectors |
|---|---|
| 0 0 0 0 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 |
| 0 0 0 1 | 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 |
| 0 0 1 0 | 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 |
| 0 0 1 1 | 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 |
| 0 1 0 0 | 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 |
| 0 1 0 1 | 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 |
| 0 1 1 0 | 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 |
| 0 1 1 1 | 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 |
| 1 0 0 0 | 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 |
| 1 0 0 1 | 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 |
| 1 0 1 0 | 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 |
| 1 0 1 1 | 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 |
| 1 1 0 0 | 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 |
| 1 1 0 1 | 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 |
| 1 1 1 0 | 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
| 1 1 1 1 | 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 |
| Model Type I | Model Type II | Model Type III | Model Type I | Model Type II | Model Type III | |
|---|---|---|---|---|---|---|
| Tx antennas × Rx antennas | 2 × 2 | 2 × 2 | 2 × 2 | 4 × 4 | 4 × 4 | 4 × 4 |
| Number of subcarriers | 64 | 64 | 64 | 64 | 64 | 64 |
| Number of epochs | 5000 | 5000 | 5000 | 5000 | 5000 | 5000 |
| Batch size | 300 | 300 | 1000 | 300 | 300 | 300 |
| Total batches every epoch | 5 | 5 | 50 | 5 | 5 | 20 |
| Number of test cases | 200,000 | 200,000 | 200,000 | 200,000 | 200,000 | 200,000 |
| Neural network size | 32;
256;
128; 64; 16 | 256;
512;
512; 512; 256 | 512;
512;
256; 128; 16 | 32;
256;
128; 64; 16 | 512;
1024;
1024; 1024; 512 | 1024;
512;
256; 128; 8 |
| Initial LR | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| LR decreasing step | 500 | 500 | 1000 | 500 | 500 | 500 |
| Parameters | The 4 × 4 Model Type I | The 4 × 4 Model Type II | The 2 × 2 Model Type III |
|---|---|---|---|
| LUT | 50,972 (11.77%) | 312,123 (72.05%) | 192,633 (44.47%) |
| LUT RAM | 15 (0.01%) | 112 (0.06%) | 44 (0.03%) |
| FF | 35,027 (4.04%) | 186,990 (21.58%) | 130,400 (15.05%) |
| BRAM | 11.5 (0.78%) | 384 (26.12%) | 127.5 (8.67%) |
| DSP | 402 (11.17%) | 1536 (42.67%) | 3344 (92.89%) |
| IO | 61 (7.18%) | 43 (5.06%) | 99 (11.65%) |
| BUFG | 1 (3.13%) | 1 (3.13%) | 2 (6.26%) |
| Power (W) | 2.029 | 7.531 | 6.48 |
| Frequency (MHz) | 188.679 | 119.047 | 135.135 |
| Latency of inference phase, (cycles) | 2065 | 16,521 | 4106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, V.D.; Lam, D.K.; Tran, T.H. Hardware-Based Architecture for DNN Wireless Communication Models. Sensors 2023, 23, 1302. https://doi.org/10.3390/s23031302
Tran VD, Lam DK, Tran TH. Hardware-Based Architecture for DNN Wireless Communication Models. Sensors. 2023; 23(3):1302. https://doi.org/10.3390/s23031302
Chicago/Turabian StyleTran, Van Duy, Duc Khai Lam, and Thi Hong Tran. 2023. "Hardware-Based Architecture for DNN Wireless Communication Models" Sensors 23, no. 3: 1302. https://doi.org/10.3390/s23031302
APA StyleTran, V. D., Lam, D. K., & Tran, T. H. (2023). Hardware-Based Architecture for DNN Wireless Communication Models. Sensors, 23(3), 1302. https://doi.org/10.3390/s23031302