1. Introduction
Artificial intelligence and particularly deep learning methods have achieved outstanding results for various Machine Learning (ML) tasks in the past few years. In particular, modern Deep Learning (DL) architectures yield results that are equivalent to human performance for image classification and sometimes even outperform them. It is therefore not surprising that attempts were made to develop ML models that compete with experts in their respective fields. For example, in the area of medicine, automated systems have been built to classify skin cancer [
1], segment Optical Coherence Tomography (OCT) images [
2], classify COVID-19 patients from chest CT images [
3], classify Parkinson’s disease based on audio files [
4] and many more to replace or enhance their current gold standard based on expert knowledge. Moreover, the increasing simplicity to acquire physiological sensor data by using cheap and simple-to-use wearables has opened completely new research areas such as automated emotion recognition [
5], sleep stage classification [
6], Human Activity Recognition (HAR) [
7], hunger detection [
8], and countless others. Similarly, efforts were undertaken to automatize the clinical recognition of pain. As pain constitutes both a symptom and disease [
9], it is a crucial indicator in any medical application. Currently, the gold standard for pain detection is represented by Numerical Rating Scales (NRSs), which ask patients about the pain they felt using a numerical scale between 0 and 10 and its corresponding anchors “no pain” and “worst imaginable pain”. While there are several versions of this concept, such as Visual Analogue Scales (VASs) or special types of scales targeted for children (Faces Pain Scale) [
10], and even pain observation tools used for patients with disorders of consciousness such as the Nociception Coma Scale (NCS) [
11], these questionnaires have several drawbacks. On the one hand, pain is a highly subjective concept that is hard to communicate and is influenced by past experiences. On the other hand, even accurate estimates of pain identified by the gold standard are sporadic rather than continuous measurements. Further, these questionnaires fail whenever patients are unable to (reliably) communicate their pain, such as with coma patients, elderly (dementia) patients or children. Thus, various medical applications would benefit from a continuous, objective and automated pain recognition system. In the past, several attempts to build such systems were made by training a ML model to associate physiological signals with their corresponding pain categories. Initial efforts relied on the use of classical ML models trained on features obtained from expert knowledge, such as Support Vector Machines (SVMs) [
12]. More recent publications evaluated the use of DL approaches to overcome the need for explicit expertise in pain physiology [
13].
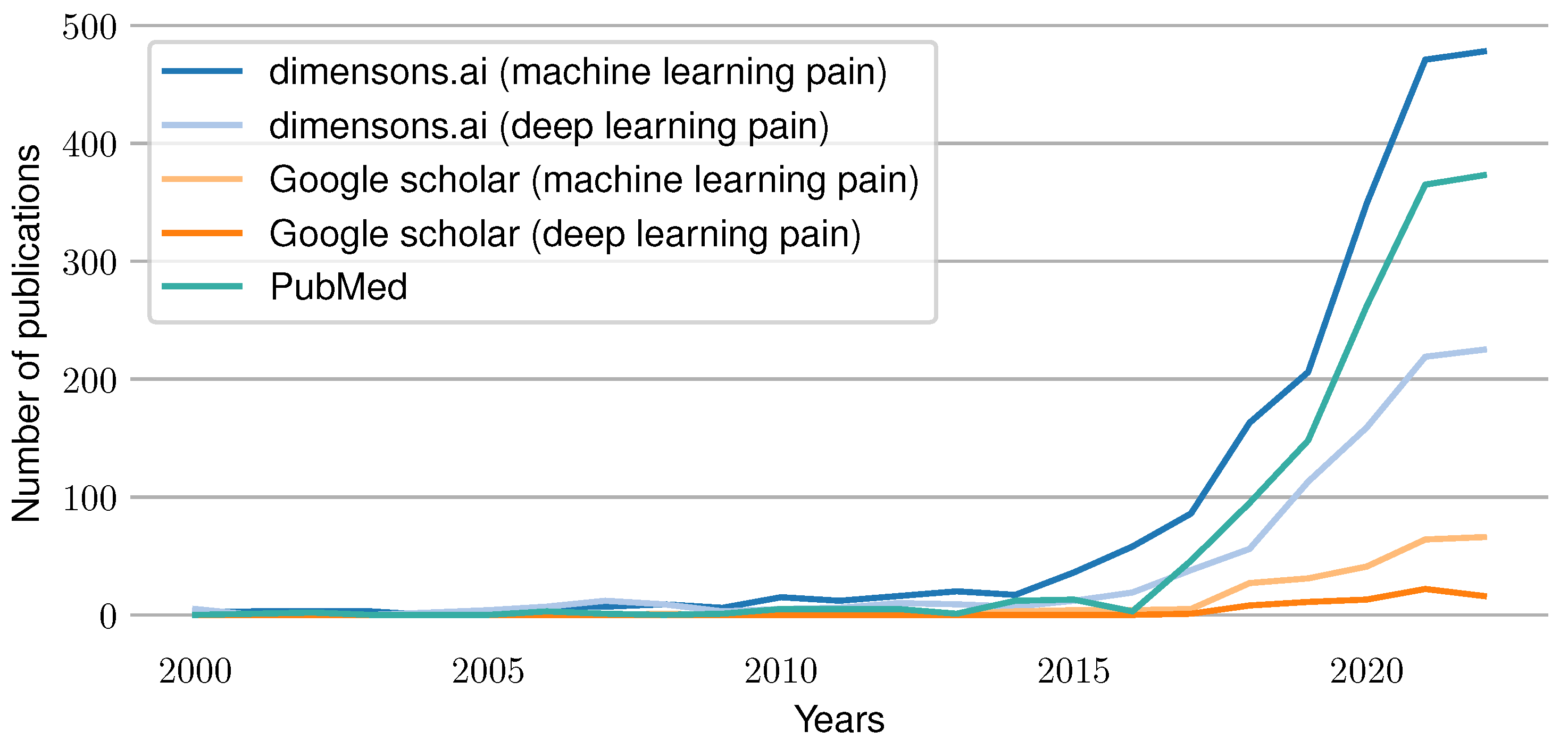
Figure 1 summarizes the current trend of work in the area of automated pain assessment. It visualizes the number of published papers for each year since 2000 that were found through different search engines. A search using the website “dimensions.ai” in combination with the search keys “machine learning pain” and “deep learning pain” in the title and abstract was conducted. In addition, a PubMed search was performed with “pain machine learning[title/abstract]” as the search term. Furthermore, a Google Scholar retrieval for “machine learning pain” and “deep learning pain” was performed (searching for papers having all keywords in the title). The results show an increasing amount of publications over time, which reflects the rise of interest and importance of the research field in recent years.
The creation of publicly available datasets, such as the UNBC-McMaster shoulder pain expression archive database [
14] and BioVid Heat Pain Database (BVDB) [
15], significantly increased the number of new ML models in the scope of automated pain recognition. Cited numerous times, the BVDB induced pain-inducing heat stimuli with varying intensity. While applying four calibrated heat temperatures (called
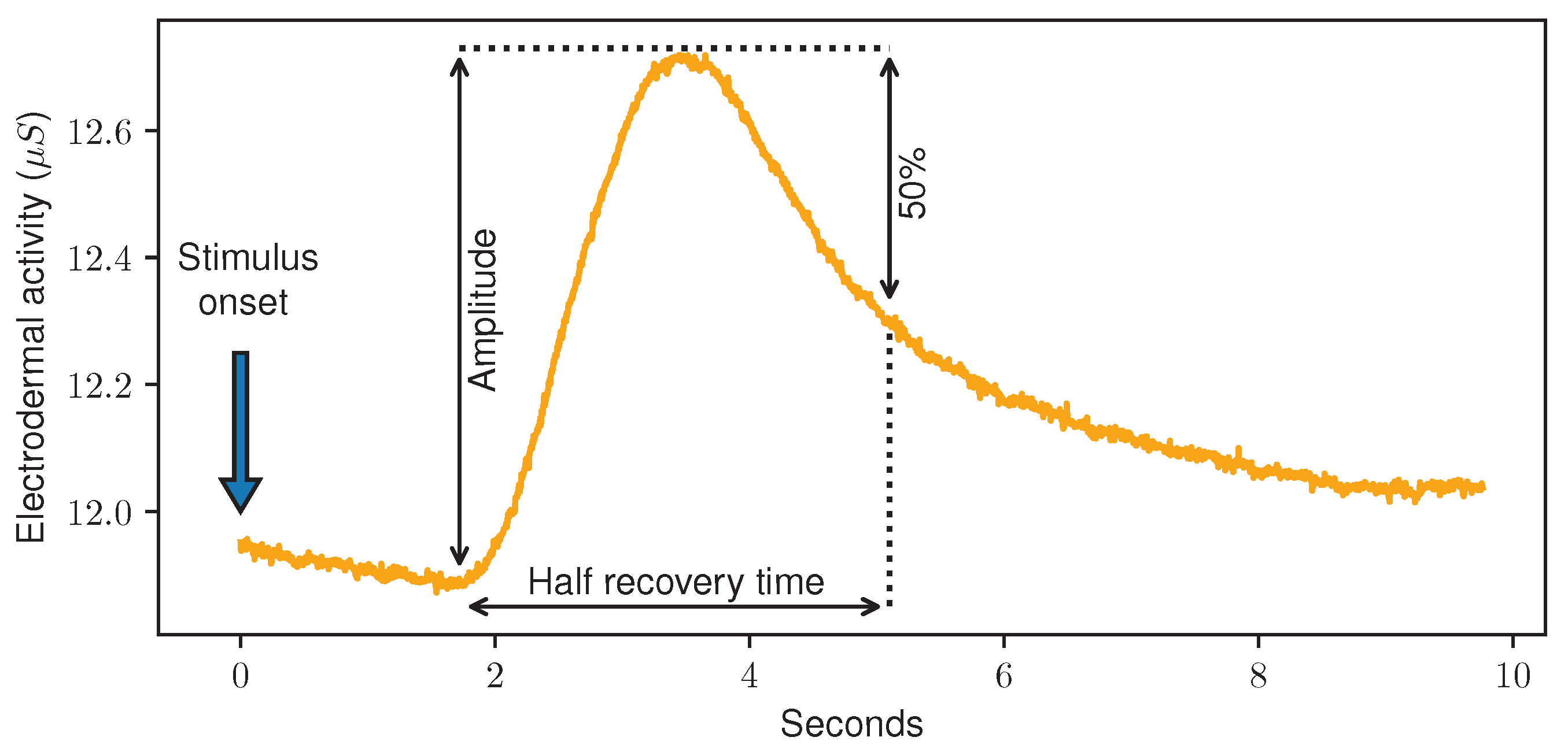
) corresponding each to a different pain level, the physiological signals Electromyogram (EMG), Electrocardiogram (ECG) and Electrodermal Activity (EDA) were recorded. Usually, pain recognition tasks are then built in a binary way, distinguishing between baseline data associated with no pain (
) and data associated with a certain pain level. Because it consistently led to the best classification results, the task
vs.
, i.e., “no pain” vs. “high pain”, was investigated intensively in the past.
Table 1 summarizes previously published results achieved on the BVDB. A more detailed description of the dataset can be found in
Section 2.1.2.
Previous outcomes on the automated recognition of pain can be summarised as follows. The classification of physiological sensor data yields better results compared to the ones based on behaviour input such as video data [
21,
22,
23,
24,
25,
26,
27]. Regarding physiological modalities, EDA was detected as the individual modality with the highest impact on the classification outcome [
13,
20,
26,
28]. In addition, feature engineering and learning perform roughly equivalently, where tasks such as “no pain” vs. “low pain” remain relatively challenging in contrast to “no pain” vs. “high pain” [
20]. In contrast, other work has shown that feature learning can outperform approaches based on Hand-Crafted Features (HCFs) [
13]. Finally, the use of a subjective pain label (patient feedback) can boost the classification performance of such systems [
20,
29]. The performance of the presented systems and accuracy of such ML models were increased incrementally over time. However, despite the numerous works published in this area each year, the understandability and transparency of these systems were not thoroughly investigated by the research community. However, the medical field could benefit from insights created by interpretable ML models that would help them grasp a deeper understanding of pain. Moreover, knowing what ML models rely on to make their decision could be investigated to further fine-tune them. Thus, in this work, several ML models are evaluated and compared on two different datasets for automated pain recognition. First, classical ML models such as Random Forest (RF) based on HCFs are trained and analysed with Recursive Feature Elimination (RFE) to determine the most important data characteristics. Then, interpretability approaches such as Gradient-weighted Class Activation Mapping (Grad-CAM) are similarly applied to DL models such as Convolutional Neural Networks (CNNs). Being the most discriminative modality for pain recognition, only the EDA signal is analysed in the current work. Furthermore, several outcomes and insights of Explainable Artificial Intelligence techniques for automated pain recognition are presented to further understand the mechanisms of pain in detail. The main contributions of this study are highlighted below:
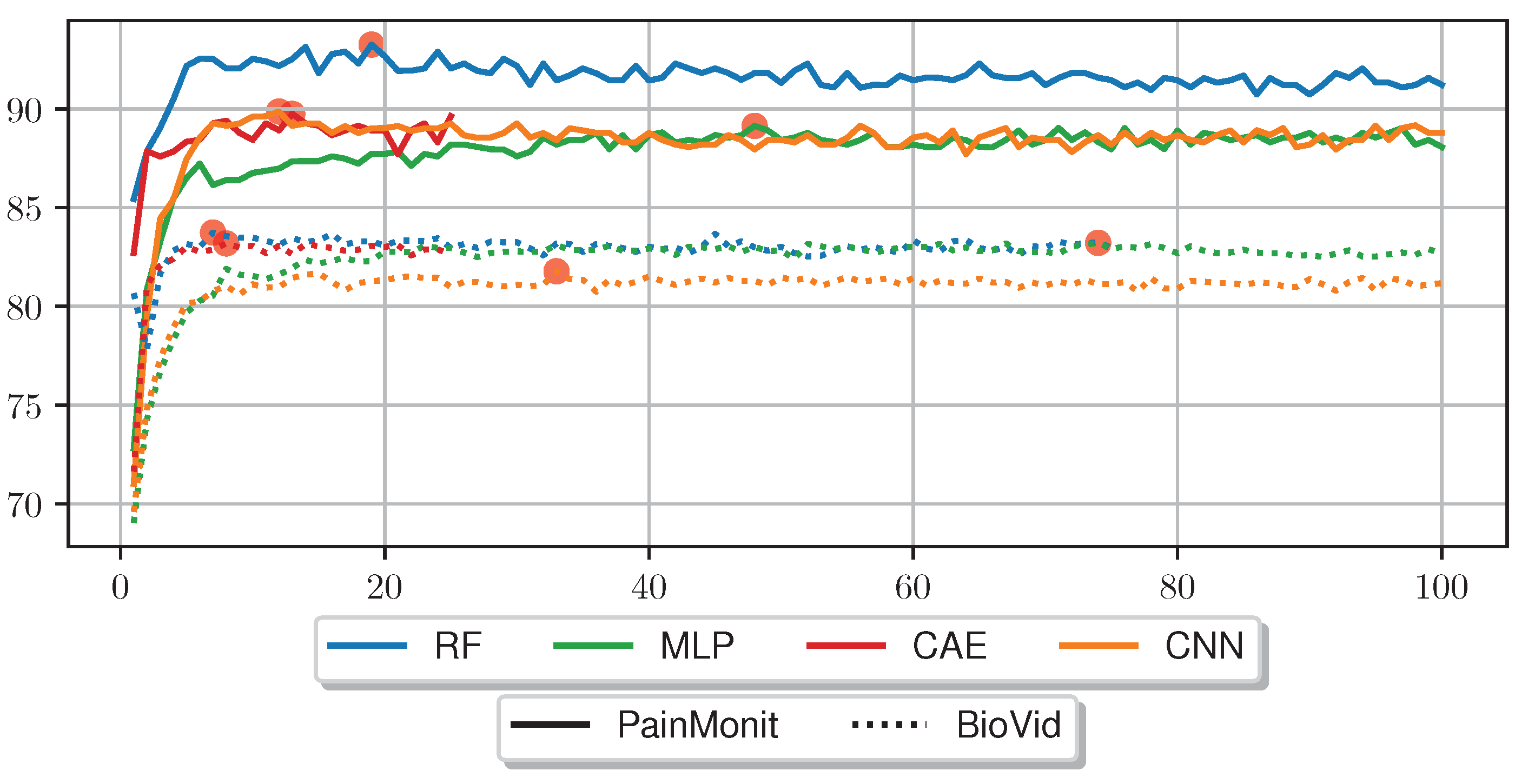
A comparison of various ML models based on feature engineering and end-to-end feature learning including recent state-of-the-art DL methods evaluated on the PainMonit Database (PMDB) and BVDB.
The interpretation of the decisions of both HCFs and DL models in the scope of automated pain recognition using Explainable Artificial Intelligence (XAI).
The proposal of rules based on simplistic manually-crafted features to distinguish between “no pain” and “high pain” using EDA data only.
Moreover, our studies highlight the following insights: (1) single simplistic features can still compete with complex DL models with millions of parameters. (2) Both approaches, based on HCFs and DL features, focus on straightforward characteristics of the given time series data in the context of automated pain recognition. The remainder of the work is organised as follows. The used datasets, models and approaches for XAI are explained in
Section 2. The resulting outcomes are presented in
Section 3 and discussed in
Section 4. Eventually, the main conclusions are summarised in
Section 5.
4. Discussion
The following section offers a detailed discussion concerning the presented results. First, the comprehensive investigations carried out with various ML approaches reveal that despite being stated differently in the past [
13], HCFs can outperform the models based on automated feature learning methods. In particular, RFE can boost the performance of HCF-based approaches and broaden their superiority over DL techniques. One benefit of the leveraged RF model based on HCFs is the immediate exploitation of the raw data, whereas DL rely on a normalisation step to quicken convergence. Here, it is also assumed that the loss of information regarding the raw data values caused by the normalisation step explains the weaker performance results yielded by the NN architectures. Moreover, the training time of the RF is significantly shorter than the ones of the DL models. Nevertheless, all models yield comparable results as they managed to retrieve the needed information for the given task. Although the same approaches were applied on both BVDB and PMDB datasets, a difference of ∼10% in the best classification accuracy can be observed for “no pain” vs. “high pain” between the two datasets. This could be explained by the longer stimuli and time series windows in the PMDB that permit the detection of long responses in EDA. Despite intensive efforts to further optimise and improve the classification results of DL models, the performance yielded with HCFs still competes with DL. For this reason, the importance of single features for classification performance was investigated in the scope of pain. Results for our feature importance analysis (
Table 5) suggest that classifiers trained on both datasets are dominated by individual characteristics rather than an accumulation of many features, clearly visible on the margin between the most dominant feature and consecutive ones. Moreover, RFE on both datasets indicates that 7 to 19 features are sufficient for the classification task of “no pain” vs. “high pain” based on EDA time series data. Here, a great proportion of features are basic statistical features describing the outer shape of the given data sample such as “min”, “max”, “argmin”, “argmax”, “diff_start_end”, “mean_phasic”, “norm_var”, “iqr”, “rms”, “sd_tonic”, and “range_tonic”.To further investigate the validity of simple statistical features, a small study in which simple naive features were calculated and used to individually classify “no pain” against “high pain” was conducted. These classification rules, based on simple Boolean tests, are carried out on a single feature of the EDA signal, either confirming the class “high pain” or rejecting a painful class, thus categorising the sample as “no pain”. The terms can be applied to all samples of a given dataset and be compared with the actual label to estimate the accuracy. Furthermore, the tested classification rules were found in a trial and error fashion, based on the analysis of the most important features derived from the feature importance analysis. For the given conditions, the EDA samples are considered as sequences expressed by
, with
being the index of a value and
l the length of the time series. First, the “diff_start_end” feature is evaluated on its own by checking whether the last element is greater than the first element of the given time series (
). Afterwards, calculations around the “argmin”/“argmax” in relation to the length of the time series data to evaluate when the highest values occur and how much the signal is increasing were tested. More specifically, it is tested whether the “argmax” is found after
of the sample’s time and whether the difference between “argmax” and “argmin” is greater than
of the time series length. Finally, categorisation is carried out by examining whether the signal tends to rise or fall by checking whether the sum of the discrete derivative is greater than zero. The discrete derivative of a time series
x with length
l is defined by
where
is arbitrarily set to 0. This simplicity contrasts with the complexity of the training process of DL models and the complexity of the DL models themselves.
Table 7 summarises the accuracies obtained with these classification rules based on simple features and compares them to the RF and MLP approaches on the PMDB and BVDB.
Similar to the RFE, various simplistic features could be introduced to classify EDA into “no pain” and “high pain” classes with comparable performance results to various ML models. It is important to note that no training of complex ML models is performed here, but the classification is based on a decision involving the computation of a single feature. It again underscores the point that the general shape of the time series and whether the EDA signal increases or decreases are important—even to the point that individual features are sufficient for classification. Different features showed varying results on both datasets, where some performed better on PMDB and some were preferable on the BVDB. Overall “argmax” and “argmin” values, which characterise the peak and low points of the EDA signal, and when they occur seem to be highly relevant for the given task. In addition, it should be noted that there could be even better features, as the ones presented (
Table 7) were found through trial and error. The simple relationship between individual features and class association becomes apparent when the distribution of a single feature is plotted individually for the various classes.
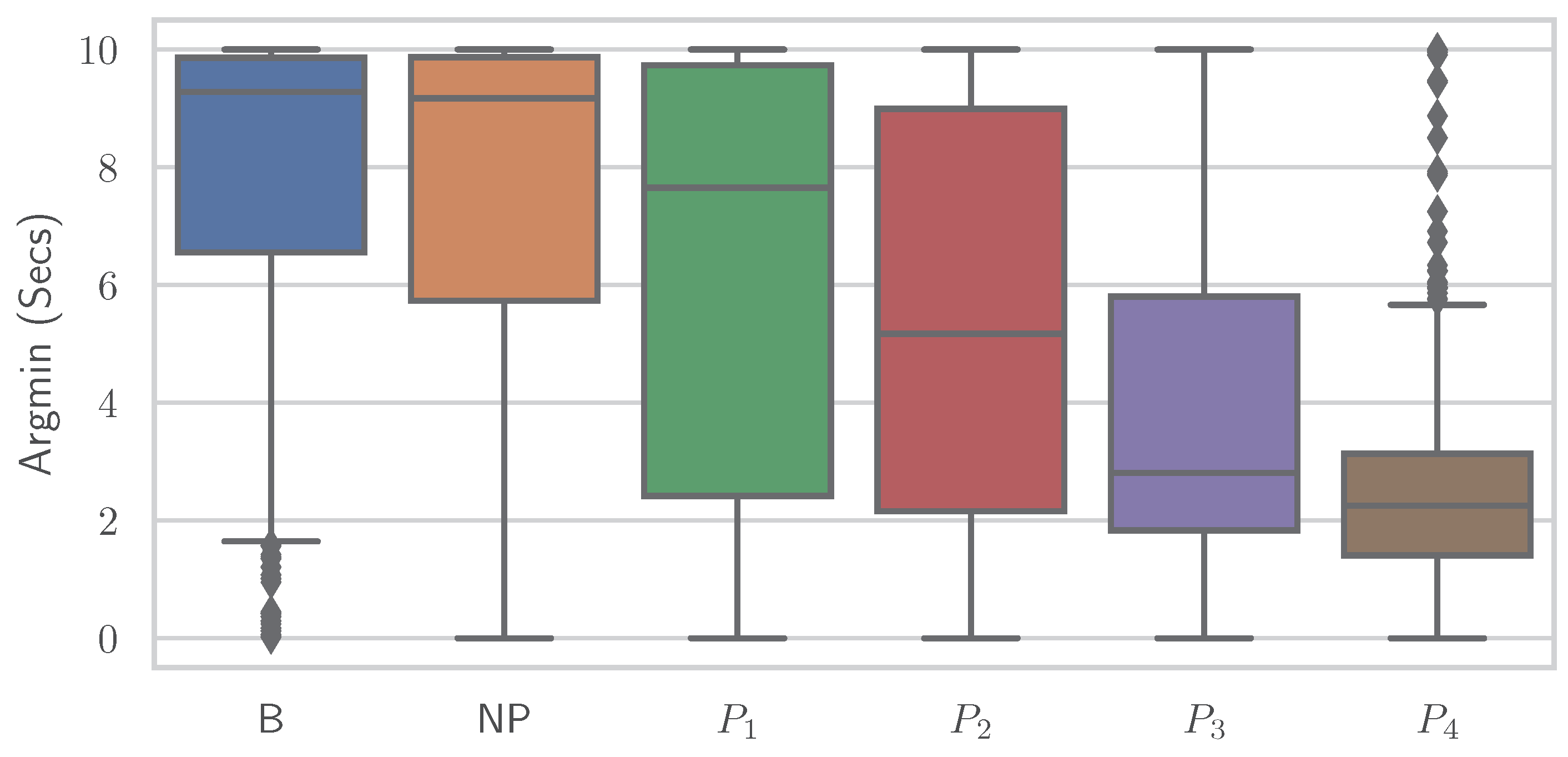
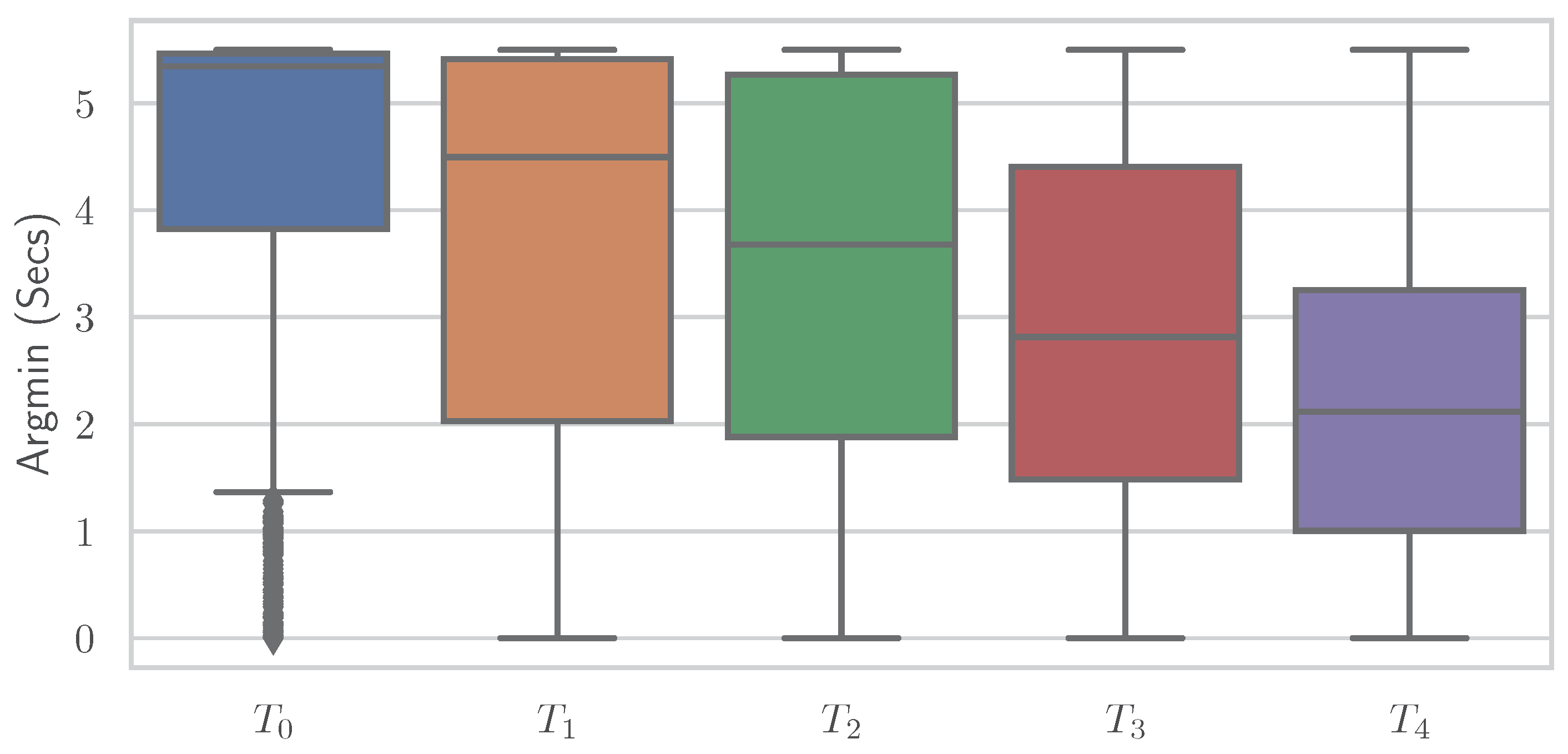
Figure 8 and
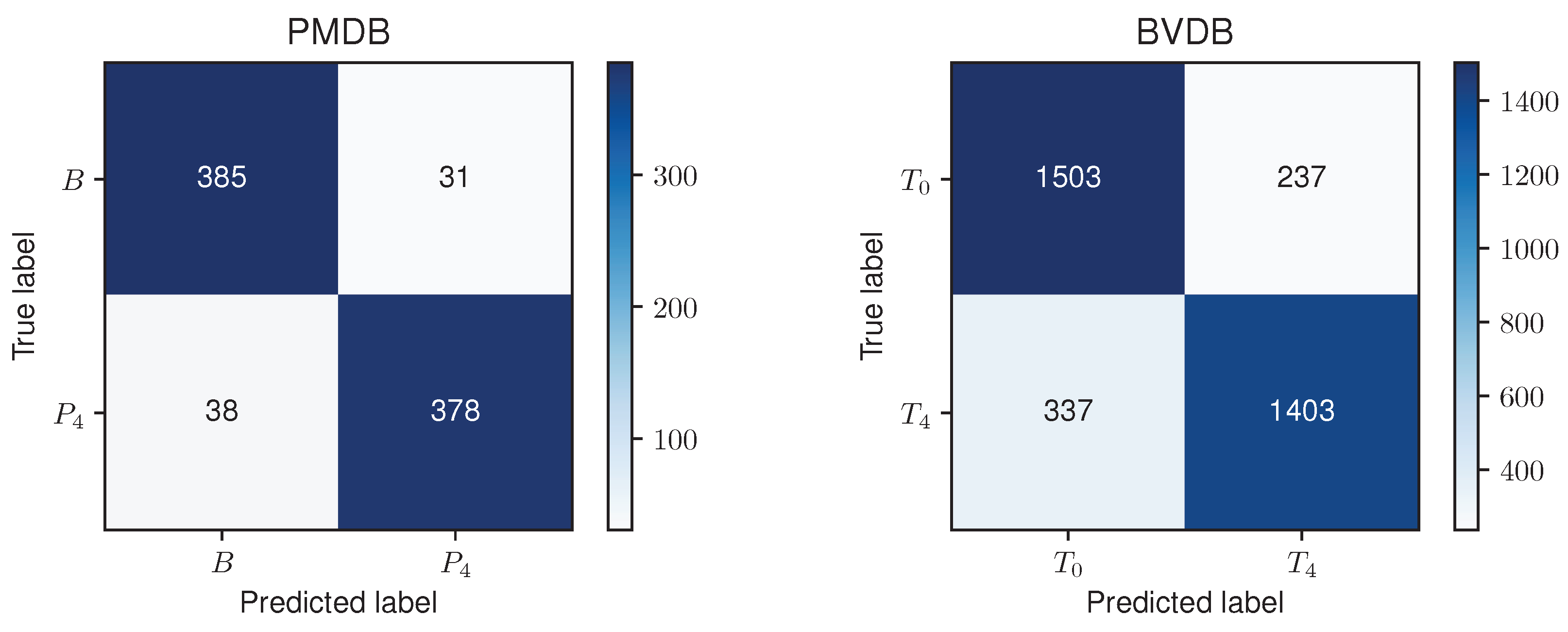
Figure 9 show boxplots for the “argmin” feature for the classes of the PMDB and BVDB, respectively. The “argmin” value describes the position of the minimum element in the time series. After conversion into seconds, it describes at what point in time the minimum of the series is reached. Whereas high values are clearly dominant in low-pain classes, low values are outweighing those in high-pain classes. In simpler words, a decrease of EDA over time is often seen in resting phases without stimulus (thus minimum being at the end of the window samples), while an increase (and thus minimum at the beginning of window samples) is present in time series belonging to high pain classes. Again, the better classification results yielded on the PMDB outlined in greater differentiation of “no pain” vs. “high pain” in PMDB (
B vs.
) in comparison to BVDB (
vs.
) can be explained by the longer time windows in samples.
While retrieving the feature importance in classical ML models, as with the impurity score in RFs, is relatively simple, NNs lack deeper interpretation tools despite their recent success. Thus, the research community worked on the interpretability of such models by creating grey-box classifiers from black-box ones [
52] or relying on white-box algorithms [
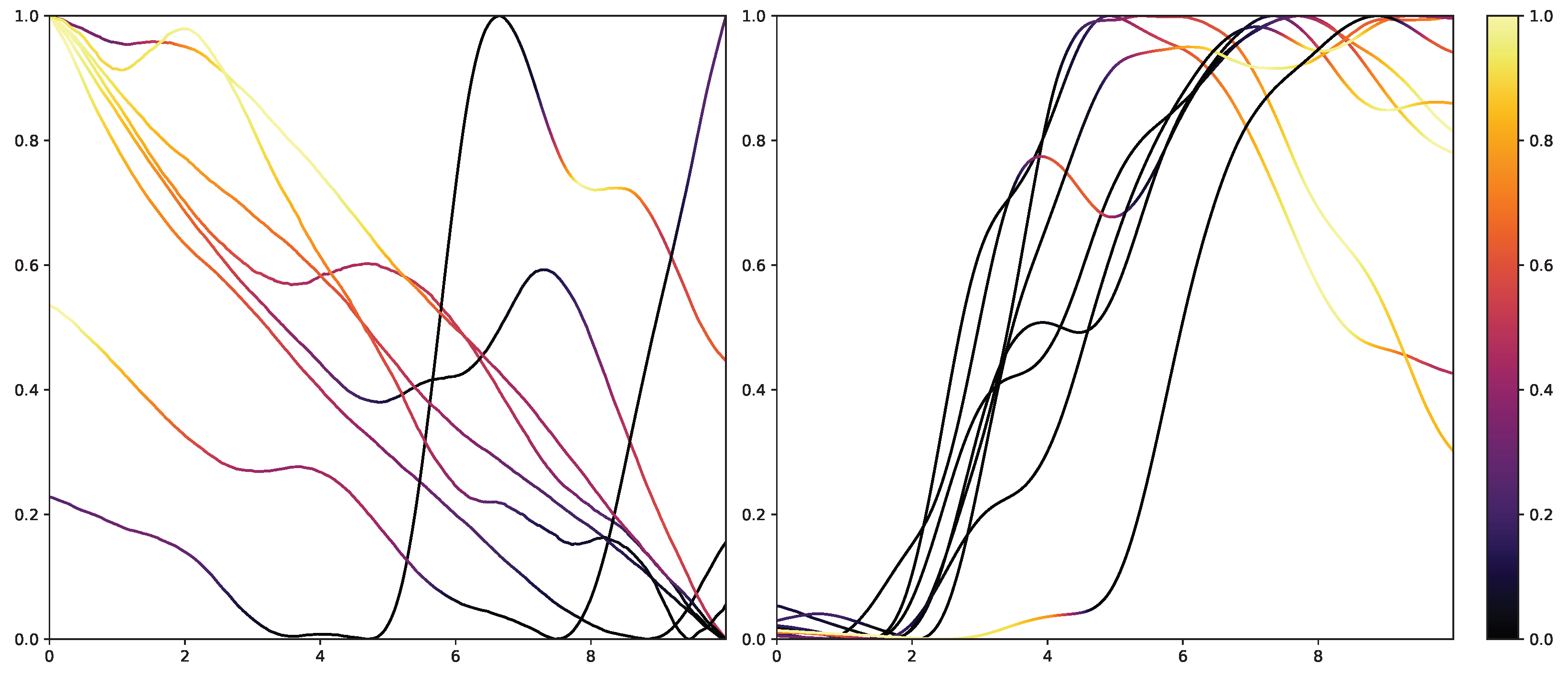
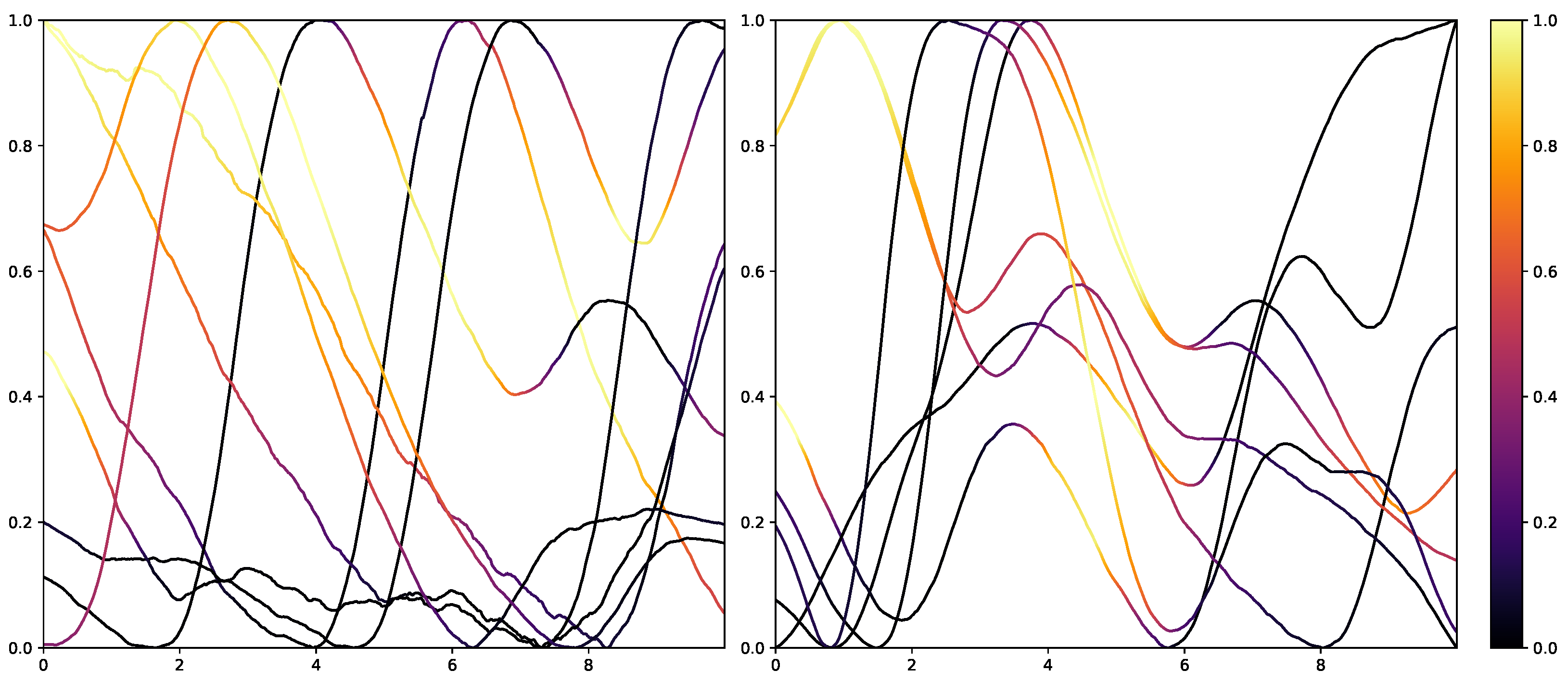
53]. To not alter the classification system itself, the interpretability in NNs is mainly investigated in the form of heat maps that highlight areas in the input data that are relevant to the classification outcomes. Examples of the results of Grad-CAM on the PMDB for the CNN architecture can be seen in
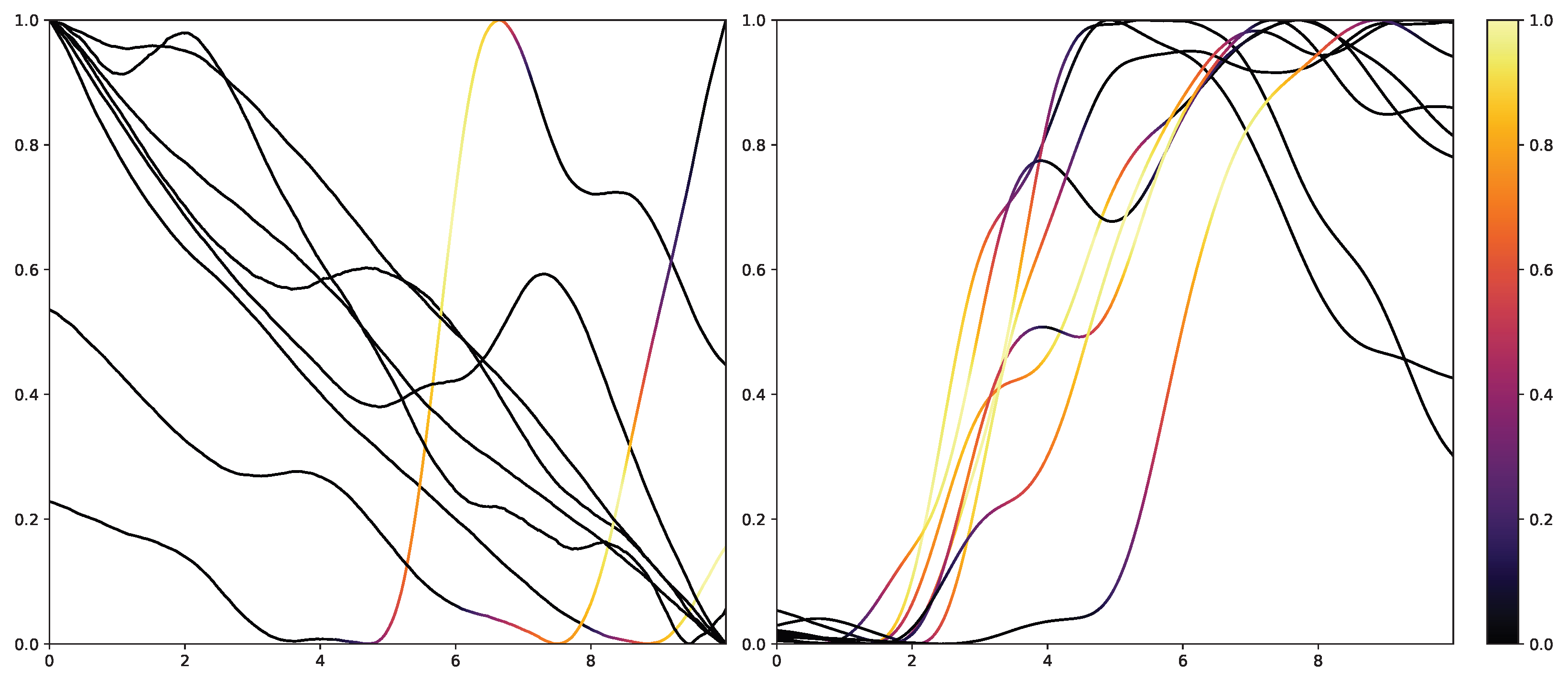
Figure 10 and
Figure 11. The EDA data for the eight stimulus repetitions for the respective classes “no pain” (left) and “high pain” (right) of a subject are presented in two different graphs. In addition, Grad-CAM highlights once which parts are relevant for the class “no pain” (
Figure 10) and once for the class “high pain” (
Figure 10) with the colour coding specified by the existing colour bar on the right side. All of the subject’s samples were correctly classified by the CNN approach. See
Appendix A.3 for more examples, especially for a subject where the DL architecture struggles to classify all the samples well.
The resulting plots differ greatly for the activation towards “no pain” and “high pain”. More specifically, areas with decreasing EDA are highlighted for the samples with no pain, while areas with increasing EDA are emphasised for the classification towards pain in contrast. Heat maps, similar to saliency, CAMs, Grad-CAM or grad-CAM++, have been investigated heavily on image databases in the past. Although the interpretation of these heat maps for images created by Grad-CAM is trivial, the output of these techniques is not clear for time series data, and an objective analysis remains challenging. From the examination of
Figure 10 and
Figure 11, it is apparent that there is a correlation between the slope of the signal and the class association of the CNN for the given subject. To evaluate this finding for all subjects of the dataset, a naive approach to objectify the class importance given by Grad-CAM with regard to the available classes and raising and falling slopes of the given time series data is presented. For this purpose, heat maps for all samples of the PMDB are calculated using Grad-CAM first. The CNN model used to retrieve a classification output and Grad-CAM heat map were trained in a LOSO manner as well. Next, the resulting maps are masked depending on the discrete derivative of the curve to estimate the focus of the NN for areas with positive and negative slopes in the samples with respect to the classification outcome for each class individually. An overall estimation is calculated by summing up and normalising all the masked scores of all available samples. In the following, the calculation of this score is described in more detail. To begin with, the following notation is used:
Dataset: where and is the example index.
Length of one data sample: l.
Grad-CAM method: .
To investigate the activation during areas with positive and negative slopes of the time series, two helper functions
and
for
to mask the activation are used. The function
enables areas with a positive slope by leveraging only the outcome greater than 0 of the discrete derivative introduced in Equation (
12) by:
Afterwards, an importance score
can be calculated for any given sample
in relation to the class
c and positive slope by masking the general Grad-CAM output with the created function
:
The above step is performed for all samples in the database. The individual results are summed up leading to a weights value, but representing the class activation for the given class in parts of a positive slope for the whole dataset:
By adopting Equation (
13) to
and updating Equations (
14) and (
15) accordingly, the activation for negative slope (
) can be calculated equally. To have an interpretable value between 0 and 1, and to compare it with other classes, the values are normalised per class at this point. Here, each weight value is divided by the sum of weights inside its class. The following equation summarises the normalisation step:
and
The resulting values for
and
represent a score estimating the importance of parts with increasing and decreasing EDA signals, respectively, for the classification outcome towards class
c.
Figure 12 visualises
and
for the classes “no pain” and “high pain” of the PMDB. For the class “high pain”,
exceeds
, whereas
outweighs
for the class “no pain”. In other words, the attention scores, and thus the focus of the DL model, are mostly concentrated in areas where the EDA rises for “high pain”, and decreases for “no pain”.
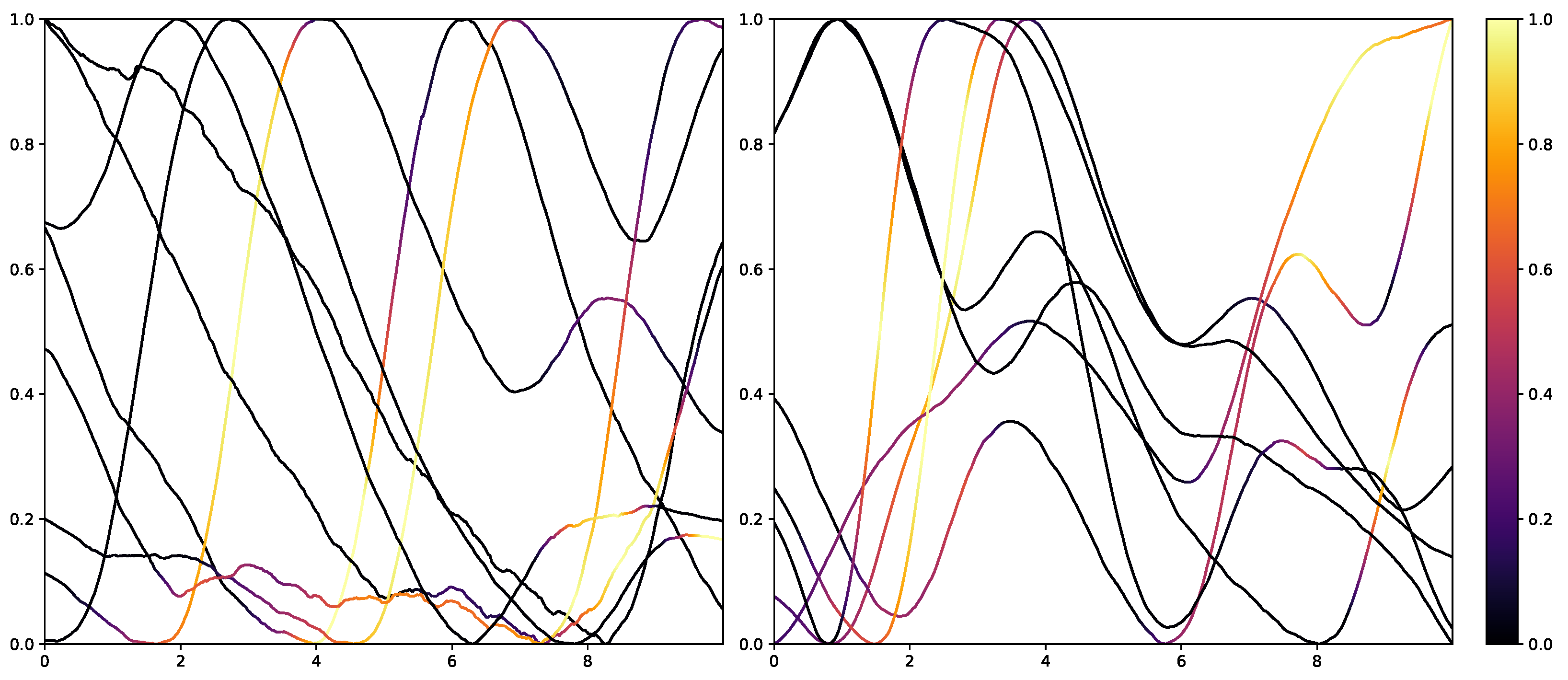
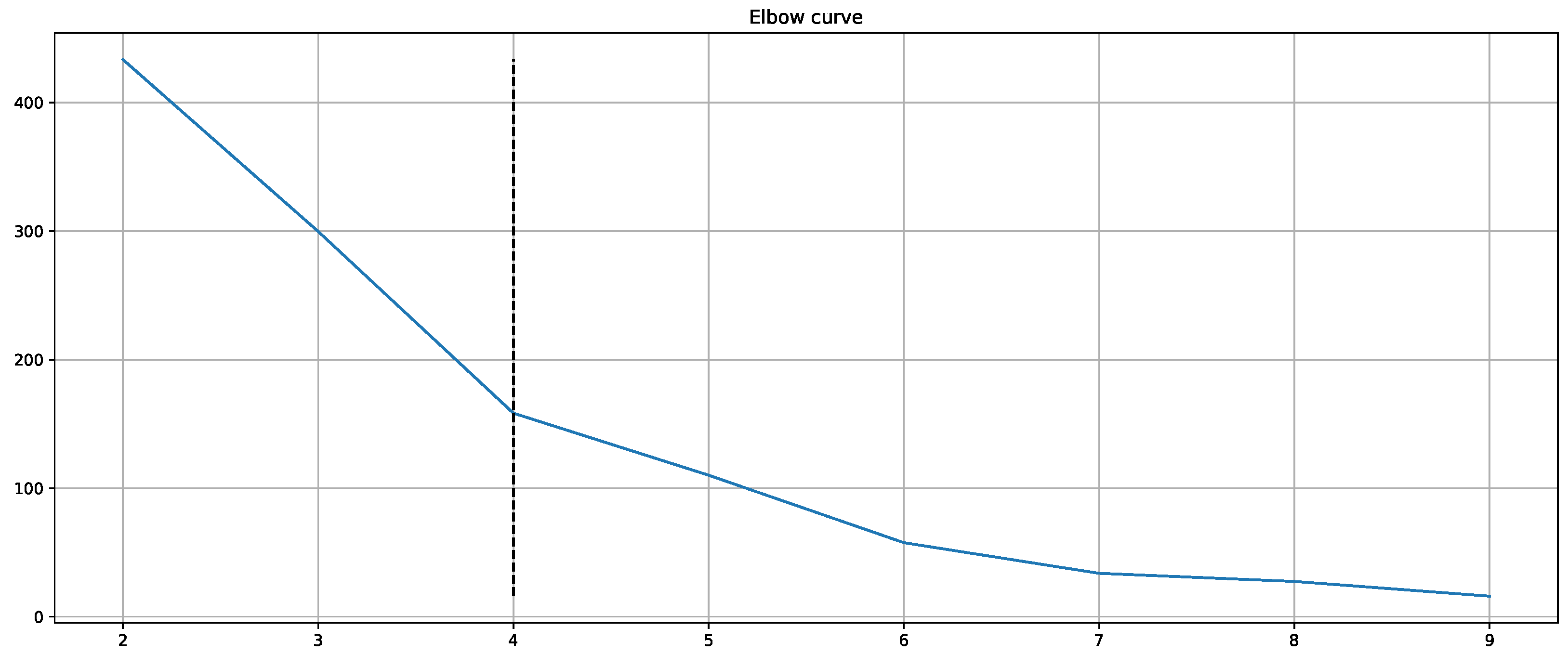
Moreover, the presented importance score based on Grad-CAM for DL architectures indicates that simple characteristics of the time series samples have a high impact on the classification results similar to the HCF approach. In simple words, areas with positive and negative slopes highly influence the results towards the classes “high pain” and “no pain”, respectively. An SCR event is associated with pain, whereas no EDA reaction, i.e., constant or decreasing SCL, is associated with no pain. Despite their complexity and numerous parameters, NN architectures may learn simplistic characteristics of EDA samples in the scope of automated pain research. In summary, the in-depth analysis of the feature importance in RF models and the characteristics that are influencing the DL outcome shows that straightforward features are the most relevant for the task of automated pain recognition based on EDA data. The results showed that “argmin”, “argmax”, the difference between the first and last values, and the sum of the slope (derivative) of the given sequence are of high importance. Here, it is assumed that certain increases in EDA data, also referred to as SCR, are greatly connected to the classes associated with pain. Although not all samples with an SCR are categorised as painful, the two concepts are affiliated strongly. To further investigate possibilities to improve the classification performance, the wrongly classified samples for the best model (RF) on the PMDB were examined. For better readability, the samples were clustered using K-Means clustering based on DTW Barycenter Averaging and plotted for their respective classes individually. The number of clusters was found using the Elbow method. A more detailed description can be found in
Appendix A.4.
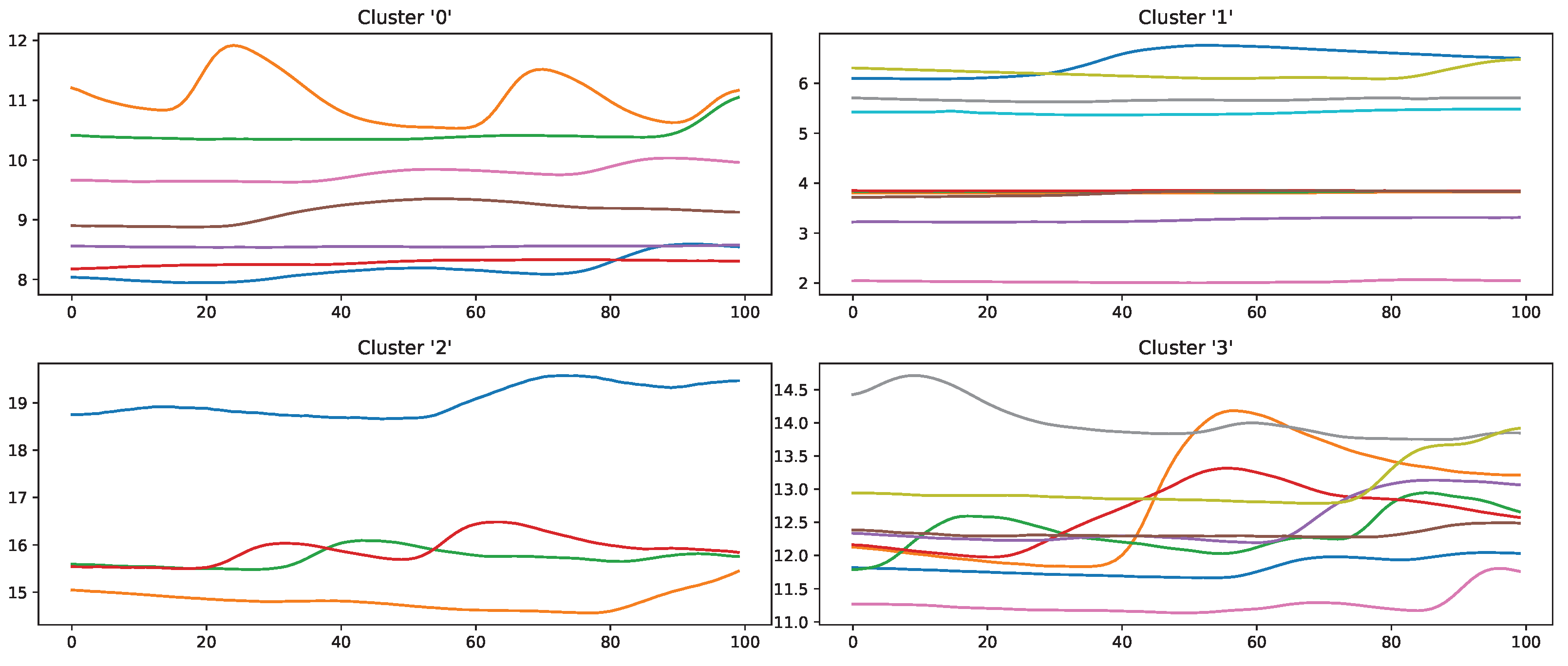
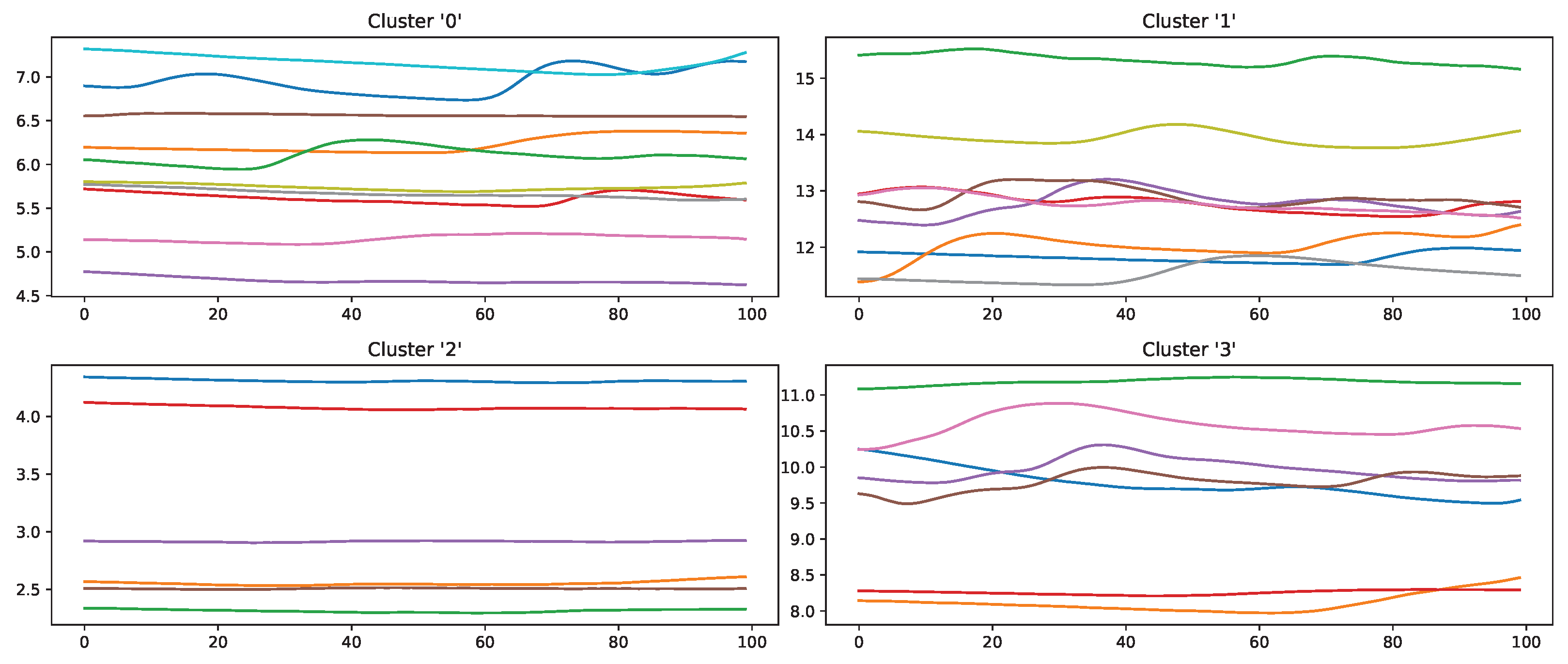
Figure 13 and
Figure 14 summarise the samples for the classes “no pain” and “high pain”, respectively.
Samples that should be classified as “no pain” but were labelled as “high pain” (
Figure 13) are clustered into four groups. Clusters 0, 2 and 3 seem to have a major increase in the EDA data, which could explain why the classifier decided to choose “high pain”. Probably, the SCR observed for these examples was triggered by another event not related to the study, as SCRs are not specific to pain but can be introduced by various incidents [
54] (p. 13), such as strong emotions or a demanding task. The samples in cluster 1 seem to have little variation in the signal, so understanding why the classifier made the wrong decision is difficult. On the other hand, wrongly classified “high pain” samples are categorised into four clusters (
Figure 14). The instances are clustered into groups with almost no variation (clusters 2 and 3) and small fluctuations (clusters 0 and 1), which are not unambiguously considered as pain by the ML models. The absence of strong reactions in the EDA signal can be reasoned by the existence of subjects with little EDA activity despite environmental factors, who are commonly referred to as non-responders in the literature [
55]. Because of the aforementioned discrepancies between classes and association with autonomic responses in the EDA signal, it is believed that it will be difficult to further improve classification results for automated pain recognition on both the PMDB and BVDB significantly. This assumption is further underlined by the trend of smaller performance increments in novel proposed classification systems (as shown in
Table 1), which suggests a “natural boundary of maximal classification performance” being present in datasets in relation to complex tasks such as pain recognition based on physiological sensor data.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
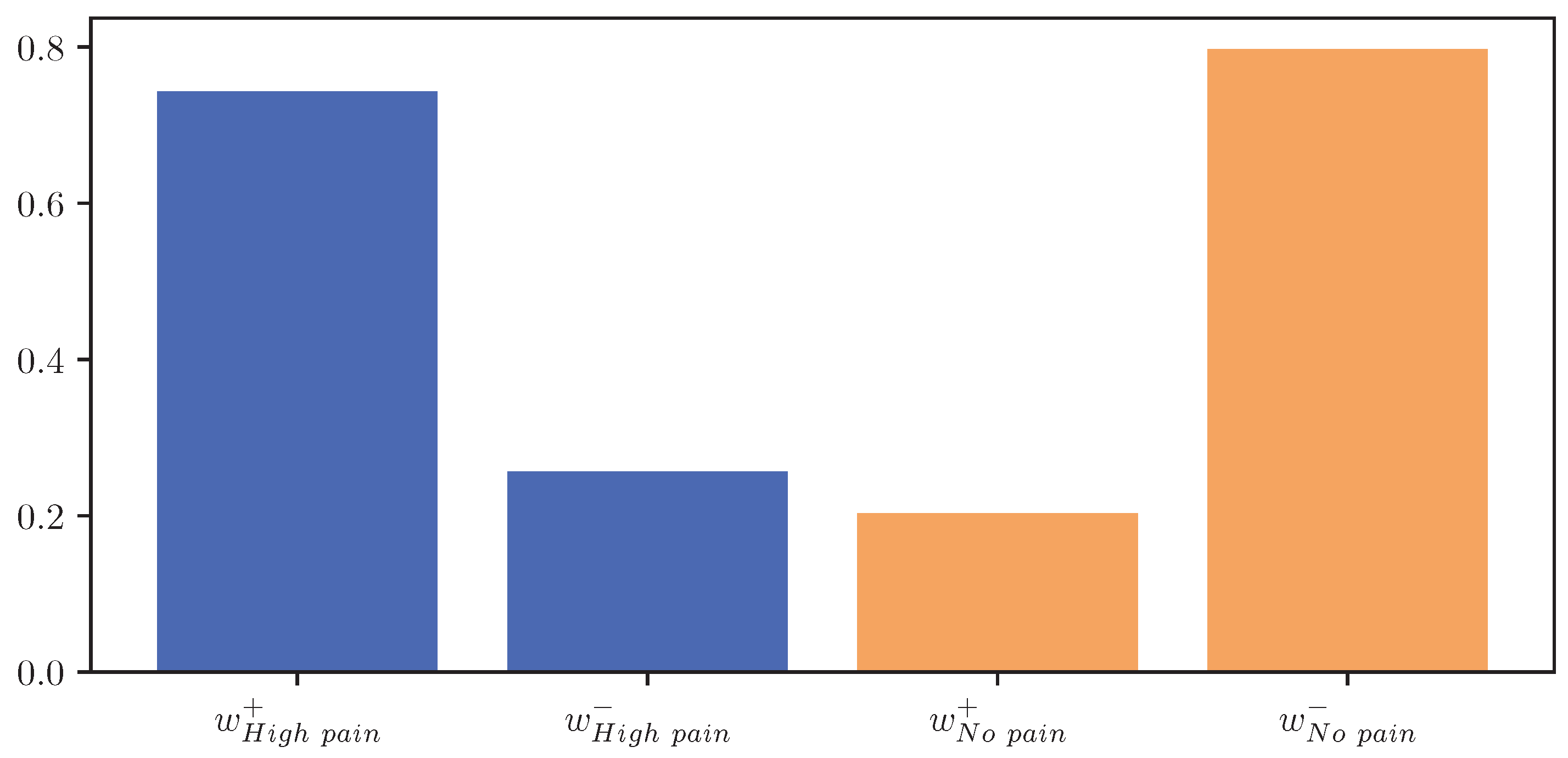{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















