
Skeleton-Based Fall Detection with Multiple Inertial Sensors Using Spatial-Temporal Graph Convolutional Networks



Abstract
:1. Introduction
2. Related Works
3. Methods and Data
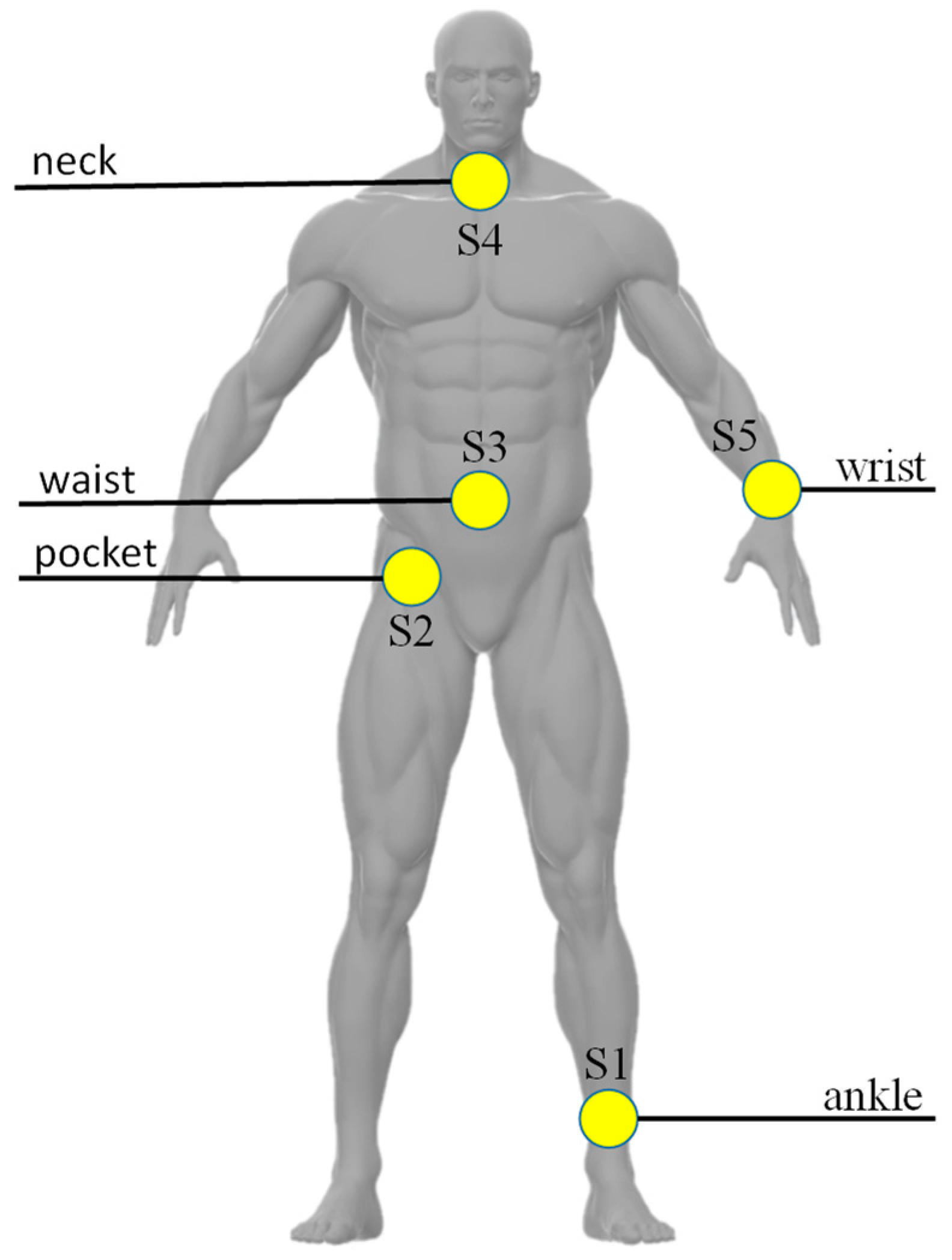
3.1. Dataset
3.2. ST-GCN-Based Fall Detection
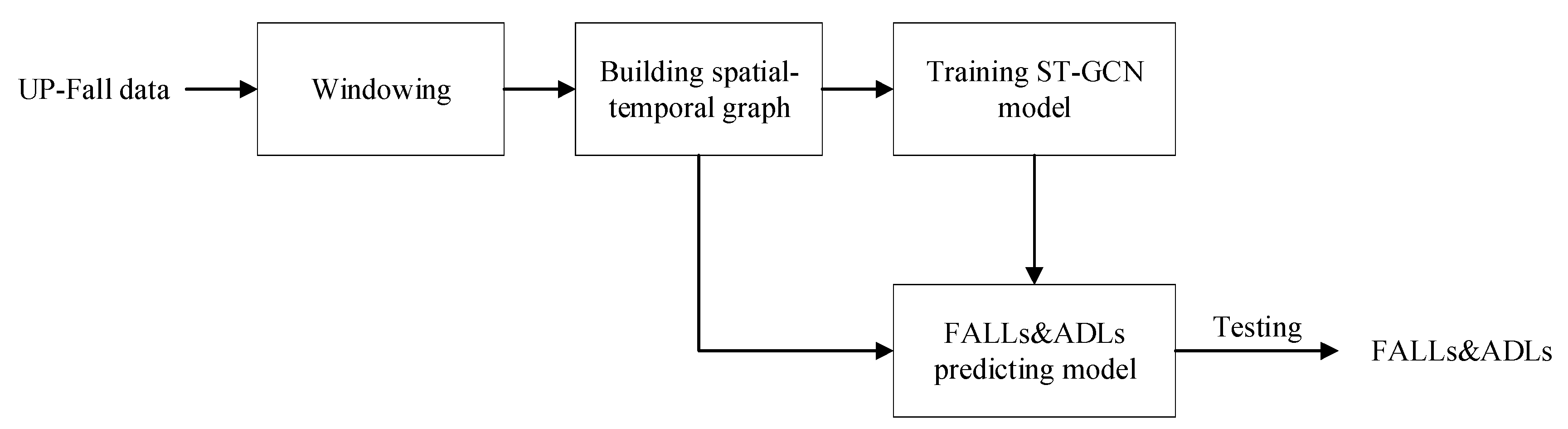
3.2.1. Workflow of Fall Detection
3.2.2. Graph and Graph Neural Networks
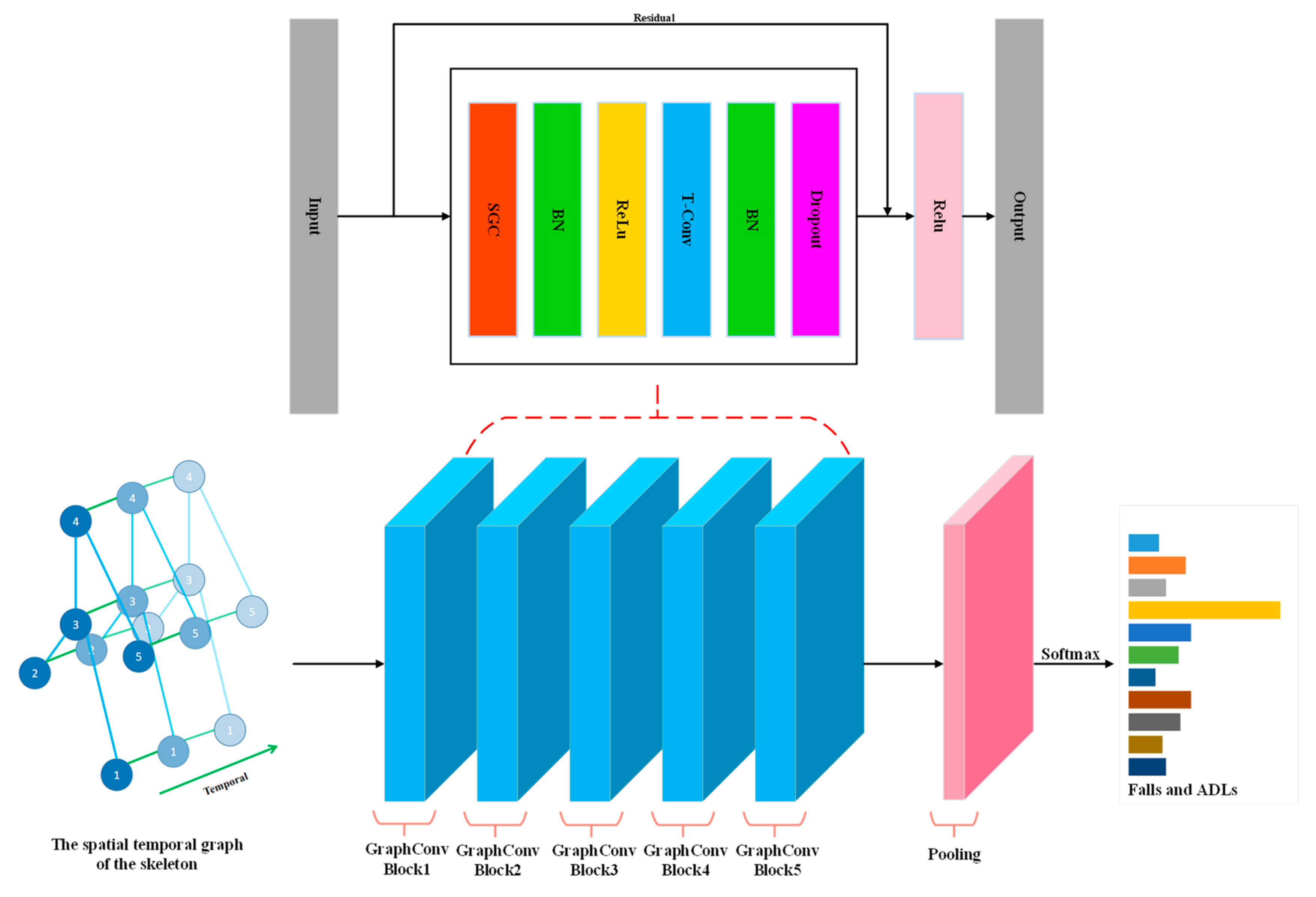
3.2.3. ST-GCN-Based Fall-Detection Algorithm
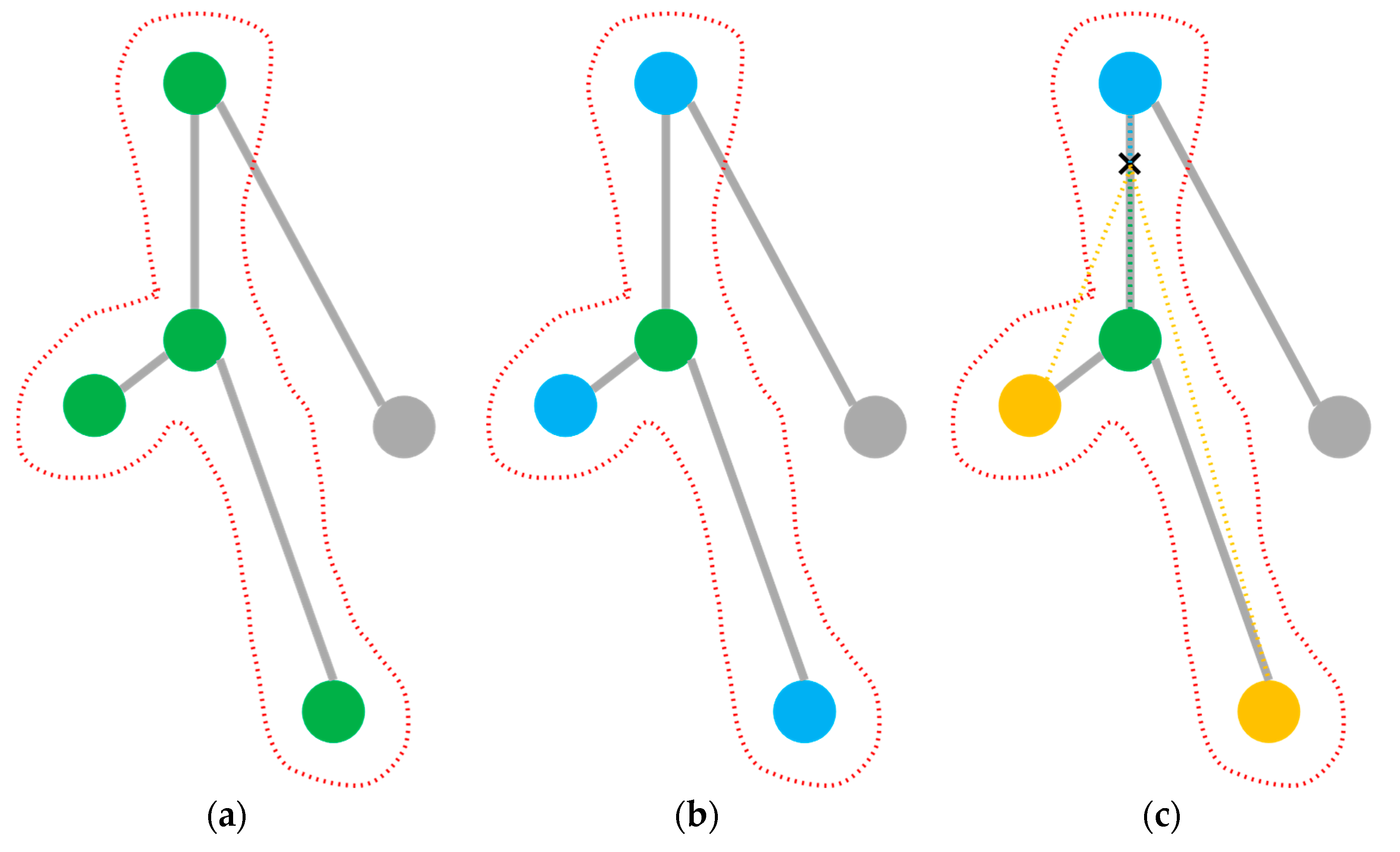
- (a)
- Uni-labeling partitioning. All nodes in their central node neighborhood have the same label. As shown in Figure 4a, all green nodes in the neighborhood are all with the same label.
- (b)
- Distance partitioning. By the distance between a node and the target node, a graph (such as a local skeleton graph of the human body composed of nodes) is divided into two parts. As shown in Figure 4b, the green nodes are nodes with distance of 0, that is, the nodes themselves, and the blue nodes are neighboring nodes with a distance of 1, that is, the nodes directly connected to the root node.
- (c)
- Spatial configuration partitioning. As shown in Figure 4c, the distance from the root node (green) to the center of gravity of the skeleton (black cross) is taken as the baseline, and the nodes with a shorter distance to the center of gravity than the baseline are marked as centripetal nodes (blue), while the centrifugal nodes (yellow) have a longer distance than the baseline.

4. Experiments
4.1. Experimental Setup
4.2. Experimental Results
4.2.1. Determination of Model Parameters
4.2.2. Experimental Results of Different Window Sizes
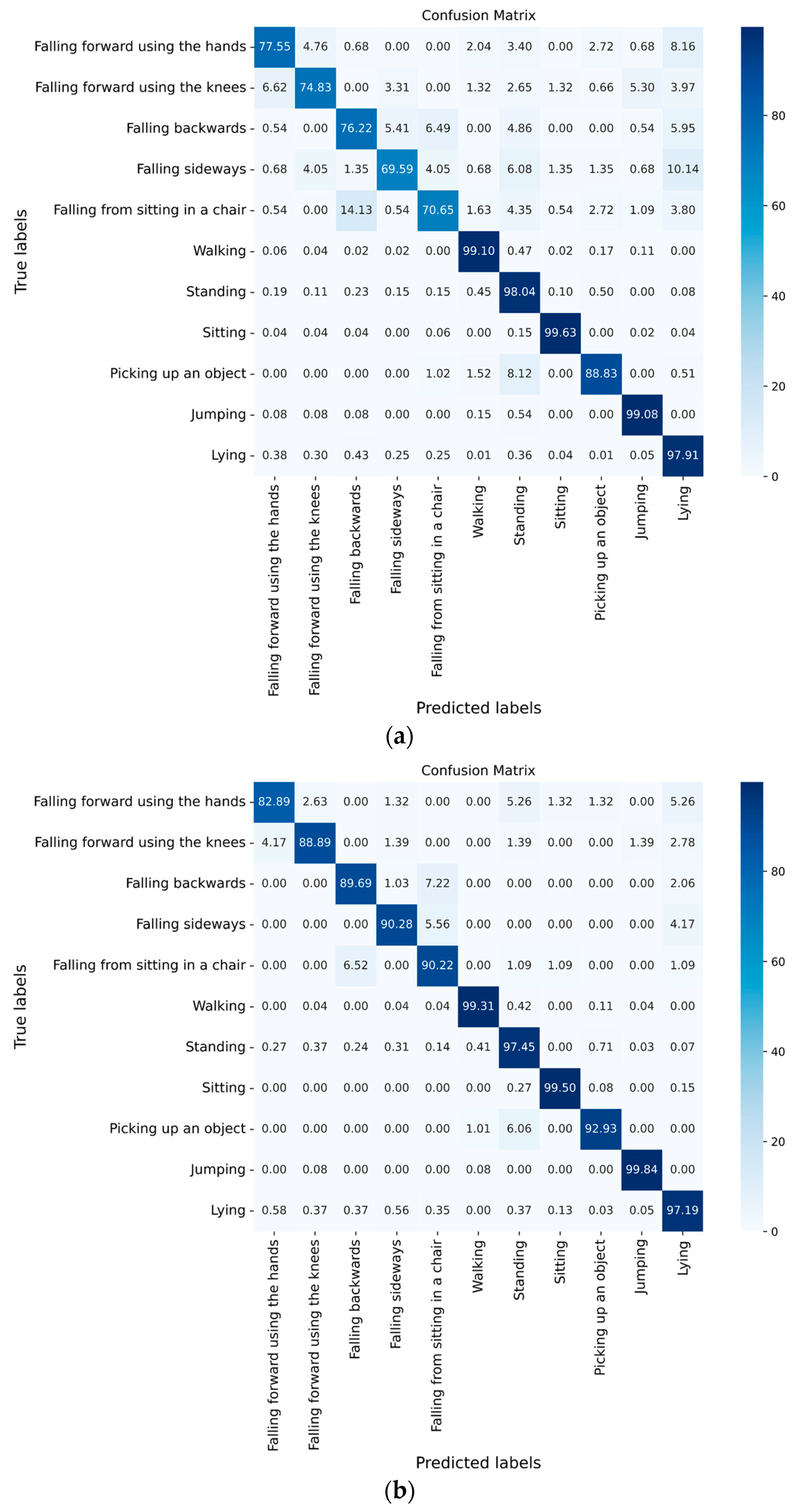
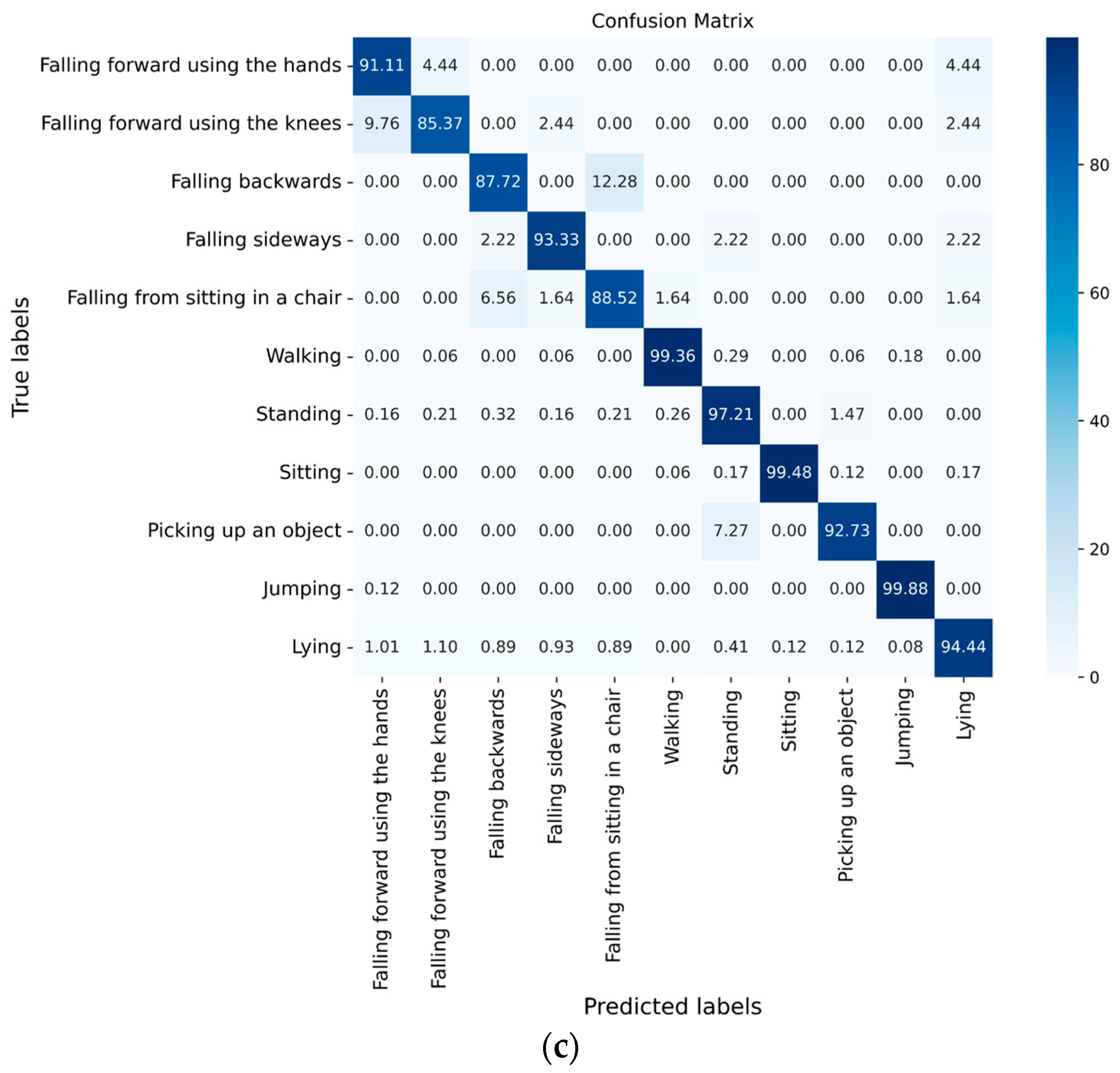
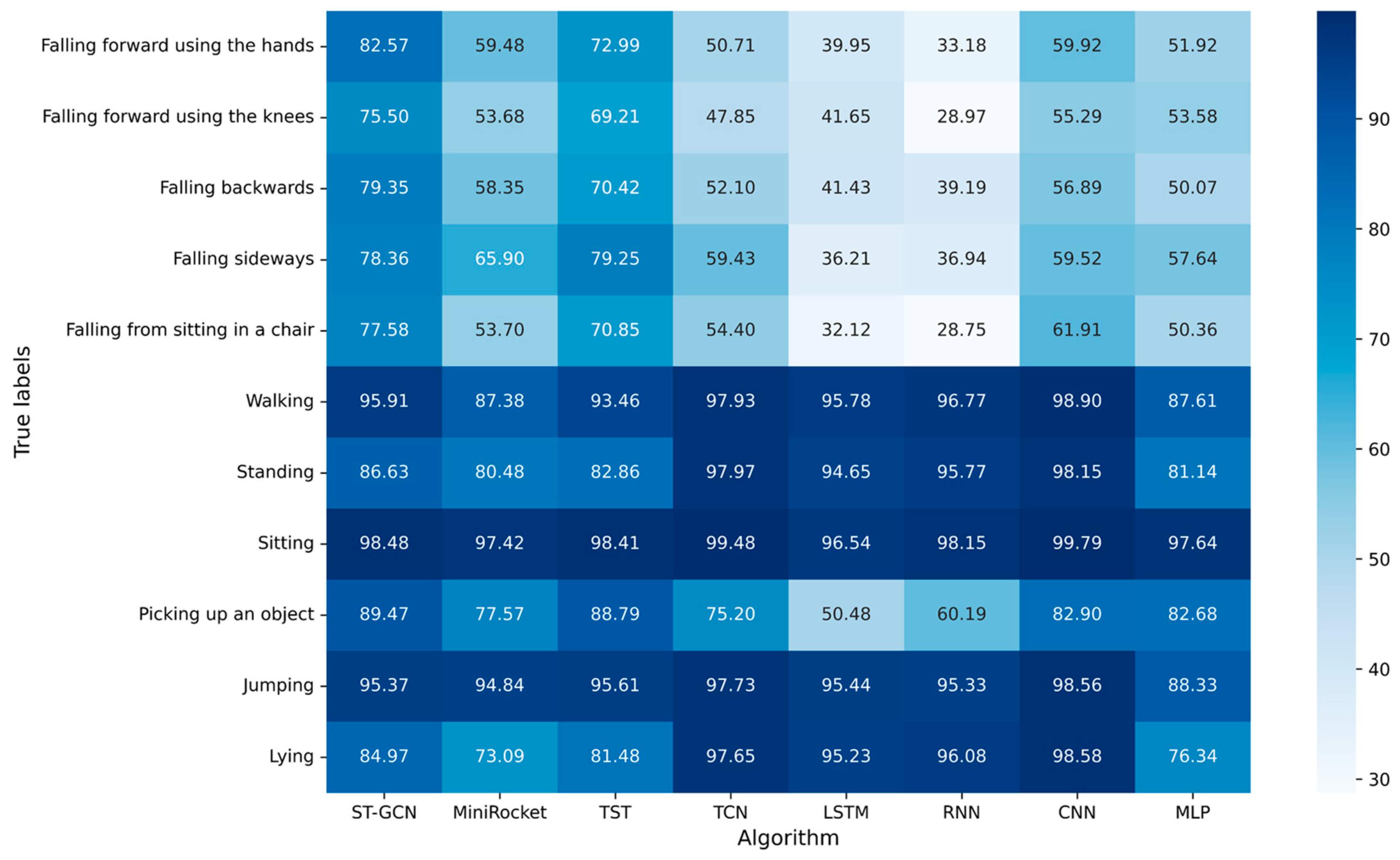
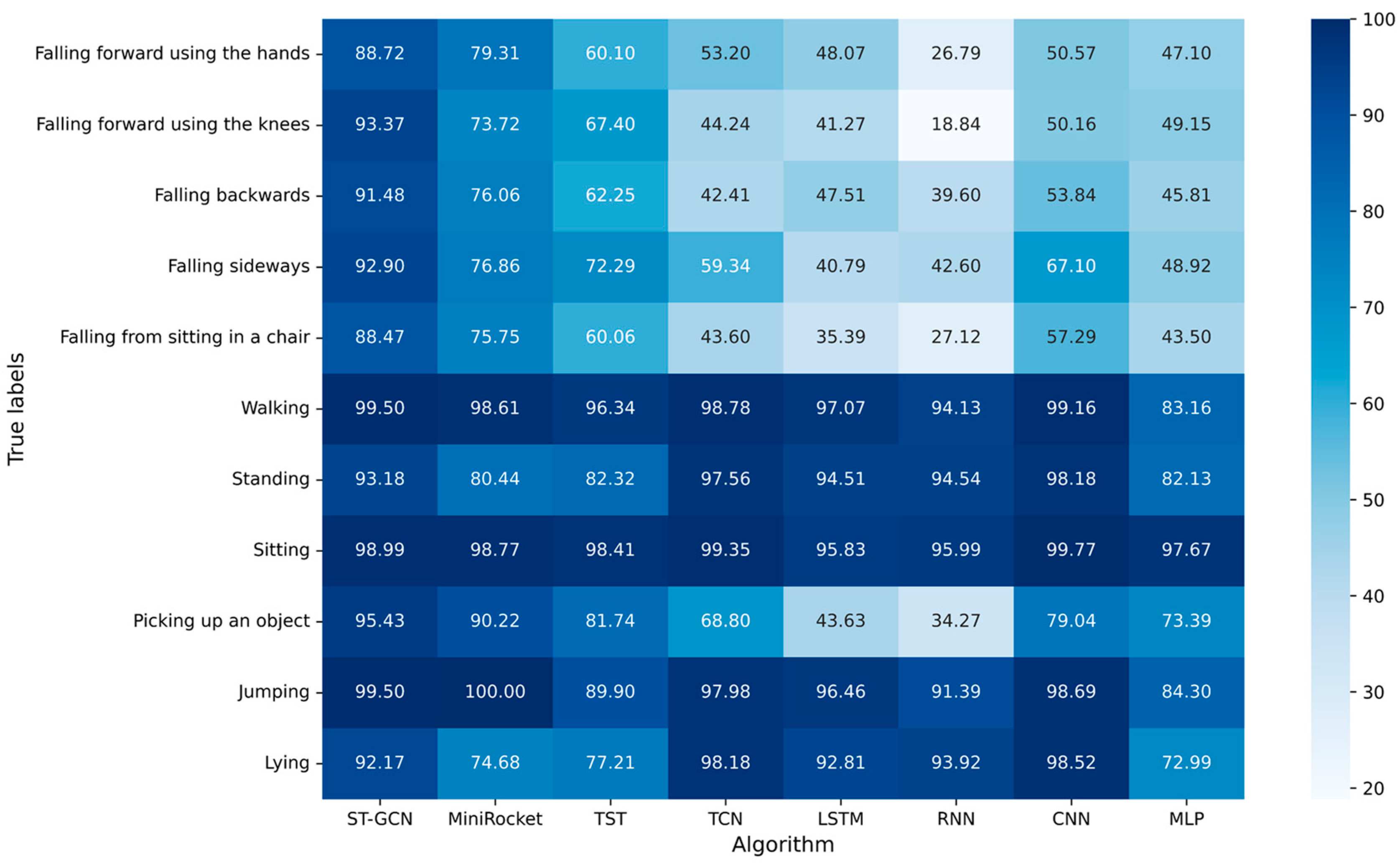
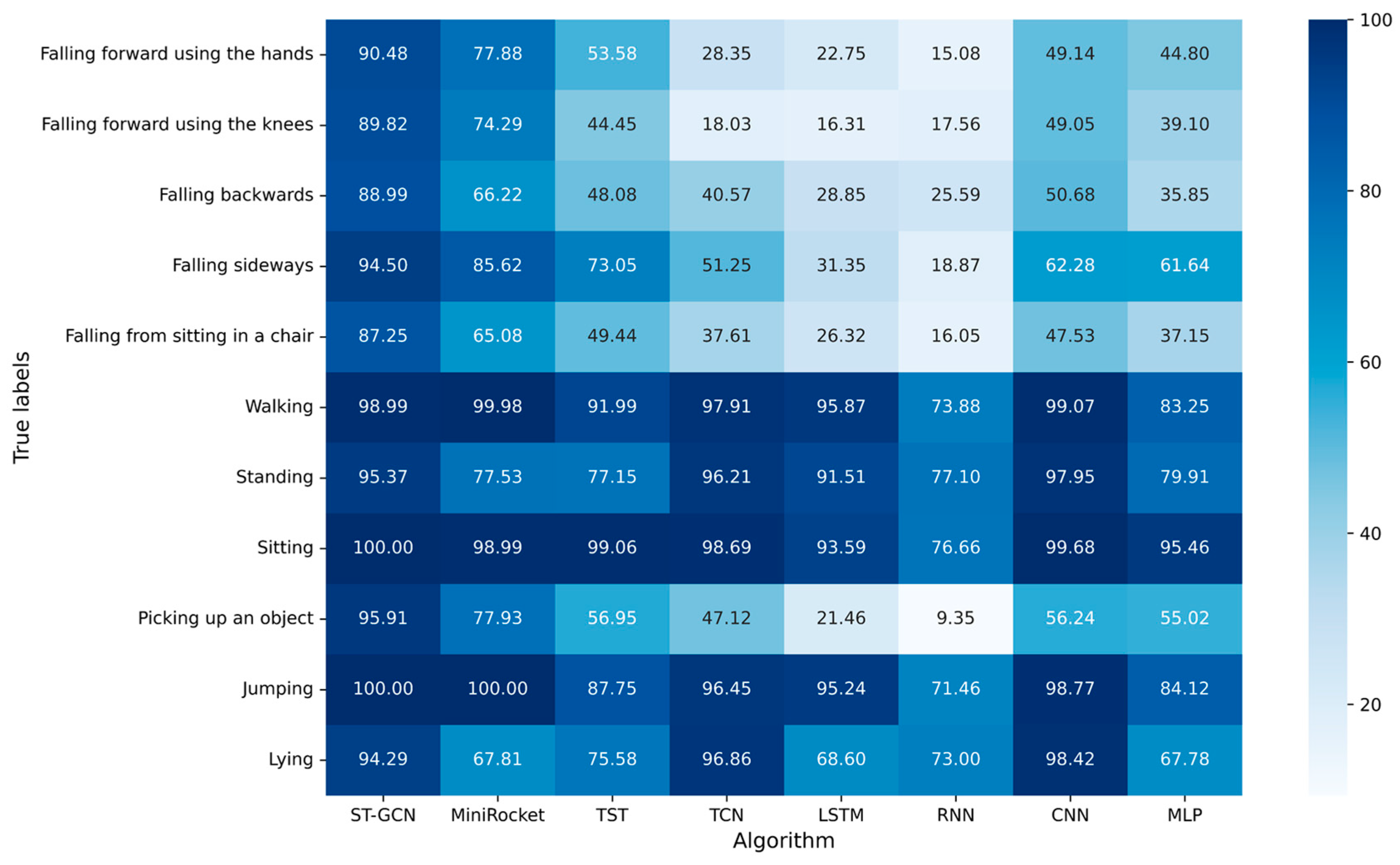
4.2.3. Experimental Results of Different Algorithms
5. Discussion
5.1. Effects of Partition Strategies on ST-GCN Performance
5.2. Effects of Different Window Sizes on ST-GCN Performance
5.3. Performance Comparison of Different Algorithms
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Falls [EB/OL]; World Health Organization: Geneva, Switzerland, 2021; Available online: https://www.who.int/news-room/fact-sheets/detail/falls (accessed on 26 April 2021).
- Sowmyayani, S.; Murugan, V.; Kavitha, J. Fall detection in elderly care system based on group of pictures. Vietnam J. Comput. Sci. 2021, 8, 199–214. [Google Scholar] [CrossRef]
- Galvão, Y.M.; Ferreira, J.; Albuquerque, V.A.; Barros, P.; Fernandes, B.J. A multimodal approach using deep learning for fall detection. Expert Syst. Appl. 2021, 168, 114226. [Google Scholar] [CrossRef]
- Zhu, N.; Zhao, G.; Zhang, X.; Jin, Z. Falling motion detection algorithm based on deep learning. IET Image Process. 2022, 16, 2845–2853. [Google Scholar] [CrossRef]
- Lu, K.-L.; Chu, E.T.-H. An Image-based fall detection system for the elderly. Appl. Sci. 2018, 8, 1995. [Google Scholar] [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home camera-based fall detection system for the elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef]
- Mrozek, D.; Koczur, A.; Małysiak-Mrozek, B. Fall detection in older adults with mobile IoT devices and machine learning in the cloud and on the edge. Inf. Sci. 2020, 537, 132–147. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, M.; Yuan, Y.; Kan, K.Y. Fall detection and personnel tracking system using infrared array sensors. IEEE Sens. J. 2020, 20, 9558–9566. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Liu, K.-C.; Huang, C.-N.; Chu, W.-C.; Chan, C.-T. Novel hierarchical fall detection algorithm using a multiphase fall model. Sensors 2017, 17, 307. [Google Scholar] [CrossRef]
- Al-Kababji, A.; Amira, A.; Bensaali, F.; Jarouf, A.; Shidqi, L.; Djelouat, H. An IoT-based framework for remote fall monitoring. Biomed. Signal Process. Control. 2021, 67, 102532. [Google Scholar] [CrossRef]
- Bhattacharjee, P.; Biswas, S. Smart walking assistant (SWA) for elderly care using an intelligent realtime hybrid model. Evol. Syst. 2022, 13, 265–279. [Google Scholar] [CrossRef]
- Sheikh, S.Y.; Jilani, M.T. A ubiquitous wheelchair fall detection system using low-cost embedded inertial sensors and unsupervised one-class SVM. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 147–162. [Google Scholar] [CrossRef]
- Nho, Y.H.; Ryu, S.; Kwon, D.S. UI-GAN: Generative adversarial network-based anomaly detection using user initial information for wearable devices. IEEE Sens. J. 2021, 21, 9949–9958. [Google Scholar] [CrossRef]
- Wu, F.; Zhao, H.; Zhao, Y.; Zhong, H. Development of a wearable-sensor-based fall detection system. Int. J. Telemed. Appl. 2015, 2015, 576364. [Google Scholar] [CrossRef]
- Hashim, H.A.; Mohammed, S.L.; Gharghan, S.K. Accurate fall detection for patients with Parkinson’s disease based on a data event algorithm and wireless sensor nodes. Measurement 2020, 156, 107573. [Google Scholar] [CrossRef]
- Wang, G.; Li, Q.; Wang, L.; Zhang, Y.; Liu, Z. CMFALL: A cascade and parallel multi-state fall detection algorithm using waist-mounted tri-axial accelerometer signals. IEEE Trans. Consum. Electron. 2020, 66, 261–270. [Google Scholar] [CrossRef]
- Montanini, L.; Del Campo, A.; Perla, D.; Spinsante, S.; Gambi, E. A footwear-based methodology for fall detection. IEEE Sens. J. 2017, 18, 1233–1242. [Google Scholar] [CrossRef]
- Wang, C.; Lu, W.; Redmond, S.J.; Stevens, M.C.; Lord, S.R.; Lovell, N.H. A low-power fall detector balancing sensitivity and false alarm rate. IEEE J. Biomed. Health Inform. 2017, 22, 1929–1937. [Google Scholar] [CrossRef]
- Martínez-Villaseñor, L.; Ponce, H.; Brieva, J.; Moya-Albor, E.; Núñez-Martínez, J.; Peñafort-Asturiano, C. UP-fall detection dataset: A multimodal approach. Sensors 2019, 19, 1988. [Google Scholar] [CrossRef]
- Delgado-Escano, R.; Castro, F.M.; Cozar, J.R.; Marín-Jiménez, M.J.; Guil, N.; Casilari, E. A cross-dataset deep learning-based classifier for people fall detection and identification. Comput. Methods Programs Biomed. 2020, 184, 105265. [Google Scholar] [CrossRef]
- Torti, E.; Fontanella, A.; Musci, M.; Blago, N.; Pau, D.; Leporati, F.; Piastra, M. Embedding recurrent neural networks in wearable systems for real-time fall detection. Microprocess. Microsyst. 2019, 71, 102895. [Google Scholar] [CrossRef]
- García, E.; Villar, M.; Fáñez, M.; Villar, J.R.; de la Cal, E.; Cho, S.-B. Towards effective detection of elderly falls with CNN-LSTM neural networks. Neurocomputing 2022, 500, 231–240. [Google Scholar] [CrossRef]
- Alarifi, A.; Alwadain, A. Killer heuristic optimized convolution neural network-based fall detection with wearable IoT sensor devices. Measurement 2021, 167, 108258. [Google Scholar] [CrossRef]
- Xu, T.; Liu, J. A low-power fall detection method based on optimized TBM and RNN. Digit. Signal Process. 2022, 126, 103525. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Cheng, Y.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar] [CrossRef]
- Li, Y.; Zuo, Z.; Pan, J. Sensor-based fall detection using a combination model of a temporal convolutional network and a gated recurrent unit. Future Gener. Comput. Syst. 2023, 139, 53–63. [Google Scholar] [CrossRef]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A Transformer-based Framework for Multivariate Time Series Representation Learning. arXiv 2020, arXiv:2010.02803. [Google Scholar] [CrossRef]
- Dempster, A.; Schmidt, D.F.; Webb, G.I. Minirocket: A very fast (almost) deterministic transform for time series classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 248–257. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Range | Average | Standard Deviation | Median |
|---|---|---|---|---|
| Age | [18–24] | 20.47 | ±1.66 | 20 |
| Weight (kg) | [53–99] | 66.82 | ±12.49 | 68 |
| Height (cm) | [157–175] | 166.47 | ±5.47 | 168 |
| Category | Activity ID | Description | Duration(s) |
|---|---|---|---|
| Fall | 1 | Falling forward using the hands | 10 |
| 2 | Falling forward using the knees | 10 | |
| 3 | Falling backwards | 10 | |
| 4 | Falling sideways | 10 | |
| 5 | Falling from sitting in a chair | 10 | |
| ADL | 6 | Walking | 60 |
| 7 | Standing | 60 | |
| 8 | Sitting | 60 | |
| 9 | Picking up an object | 10 | |
| 10 | Jumping | 30 | |
| 11 | Lying | 60 |
| Name | Configuration Information |
|---|---|
| OS | Windows10 |
| Hardware | CPU:Intel i7-6700H Memory:16 GB Graphics card:RTX1060, 6 GB |
| Python library | Python3.8 Pytorch1.11.0 Skelarn0.23.1 Pandas1.0.5 Keras2.4.3 |
| Parameter | Value |
|---|---|
| Minibatch_size | 128 |
| Learning_rate | 0.0001 |
| Max_epochs | 1000 |
| Patience | 50/minibatches |
| Optimizer | Adam |
| Parameter | Range |
|---|---|
| PS | [Uni-labeling, distance, spatial configuration] |
| MD | [1, 2] |
| Uni-Labeling | Distance | Spatial Configuration | |
|---|---|---|---|
| MD = 1 | 97.68 | 97.81 | 98.05 |
| MD = 2 | 96.87 | 97.88 | 97.95 |
| Window (s) | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| 1.0 s | 97.84 | 83.27 | 86.47 | 84.42 |
| 2.0 s | 98.05 | 85.02 | 93.46 | 88.30 |
| 3.0 s | 97.28 | 78.05 | 93.58 | 83.57 |
| Model | Window (s) | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| MLP | 1 | 97.32 | 77.47 | 72.58 | 74.45 |
| 2 | 96.72 | 73.75 | 68.87 | 70.35 | |
| 3 | 96.40 | 74.93 | 65.56 | 67.74 | |
| CNN | 1 | 97.45 | 78.84 | 79.57 | 78.80 |
| 2 | 97.33 | 78.77 | 77.18 | 76.99 | |
| 3 | 97.13 | 75.72 | 74.11 | 73.52 | |
| RNN | 1 | 94.95 | 64.79 | 69.61 | 66.49 |
| 2 | 88.68 | 56.11 | 63.60 | 57.58 | |
| 3 | 72.25 | 45.28 | 53.82 | 44.85 | |
| LSTM | 1 | 93.21 | 63.22 | 75.57 | 67.21 |
| 2 | 91.11 | 59.92 | 71.87 | 63.06 | |
| 3 | 85.07 | 53.59 | 65.47 | 55.10 | |
| TCN | 1 | 97.21 | 78.22 | 73.10 | 74.81 |
| 2 | 96.81 | 74.98 | 70.72 | 71.76 | |
| 3 | 95.70 | 67.45 | 63.50 | 63.75 | |
| TST | 1 | 97.77 | 82.10 | 78.42 | 79.88 |
| 2 | 97.57 | 81.81 | 79.30 | 79.68 | |
| 3 | 97.45 | 80.07 | 75.38 | 76.42 | |
| MiniRocket | 1 | 96.17 | 72.29 | 62.63 | 65.75 |
| 2 | 96.19 | 71.45 | 62.87 | 65.39 | |
| 3 | 96.32 | 70.38 | 61.92 | 64.13 | |
| ST-GCN | 1 | 97.84 | 83.27 | 86.47 | 84.42 |
| 2 | 98.05 | 85.02 | 93.46 | 88.30 | |
| 3 | 97.28 | 78.05 | 93.58 | 83.57 |
| Window Size (s) | MLP | CNN | RNN | LSTM | TCN | TST | MiniRocket | ST-GCN |
|---|---|---|---|---|---|---|---|---|
| Prediction Time per Window (ms) | ||||||||
| 1.0 | 1.11 | 0.10 | 0.26 | 0.31 | 0.33 | 11.21 | 16.82 | 0.16 |
| 2.0 | 1.50 | 0.07 | 0.29 | 0.28 | 0.23 | 13.32 | 26.13 | 0.13 |
| 3.0 | 0.54 | 0.07 | 0.35 | 0.26 | 0.21 | 12.70 | 36.74 | 0.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Wang, X.; Shi, J.; Hu, S. Skeleton-Based Fall Detection with Multiple Inertial Sensors Using Spatial-Temporal Graph Convolutional Networks. Sensors 2023, 23, 2153. https://doi.org/10.3390/s23042153
Yan J, Wang X, Shi J, Hu S. Skeleton-Based Fall Detection with Multiple Inertial Sensors Using Spatial-Temporal Graph Convolutional Networks. Sensors. 2023; 23(4):2153. https://doi.org/10.3390/s23042153
Chicago/Turabian StyleYan, Jianjun, Xueqiang Wang, Jiangtao Shi, and Shuai Hu. 2023. "Skeleton-Based Fall Detection with Multiple Inertial Sensors Using Spatial-Temporal Graph Convolutional Networks" Sensors 23, no. 4: 2153. https://doi.org/10.3390/s23042153
APA StyleYan, J., Wang, X., Shi, J., & Hu, S. (2023). Skeleton-Based Fall Detection with Multiple Inertial Sensors Using Spatial-Temporal Graph Convolutional Networks. Sensors, 23(4), 2153. https://doi.org/10.3390/s23042153