1. Introduction
Biometric identifiers refer to unique physical (iris, face, fingerprints, etc.), behavioural (gait, typing patterns), or physiological (EEG) traits that can be used to identify and describe individuals. The COVID-19 pandemic has caused a major decline in the performance of existing face identification systems [
1], as a result of a large data drift. This is because many people wear protective masks that conceal most of the face area, leaving only the periocular region and the forehead visible.
Although there is no standardised definition from organisations such as NIST or ISO/IEC, the term periocular refers to the area around the eyes (i.e., the eyebrows, eyelashes, eye-folds, skin texture, tear ducts, etc.).
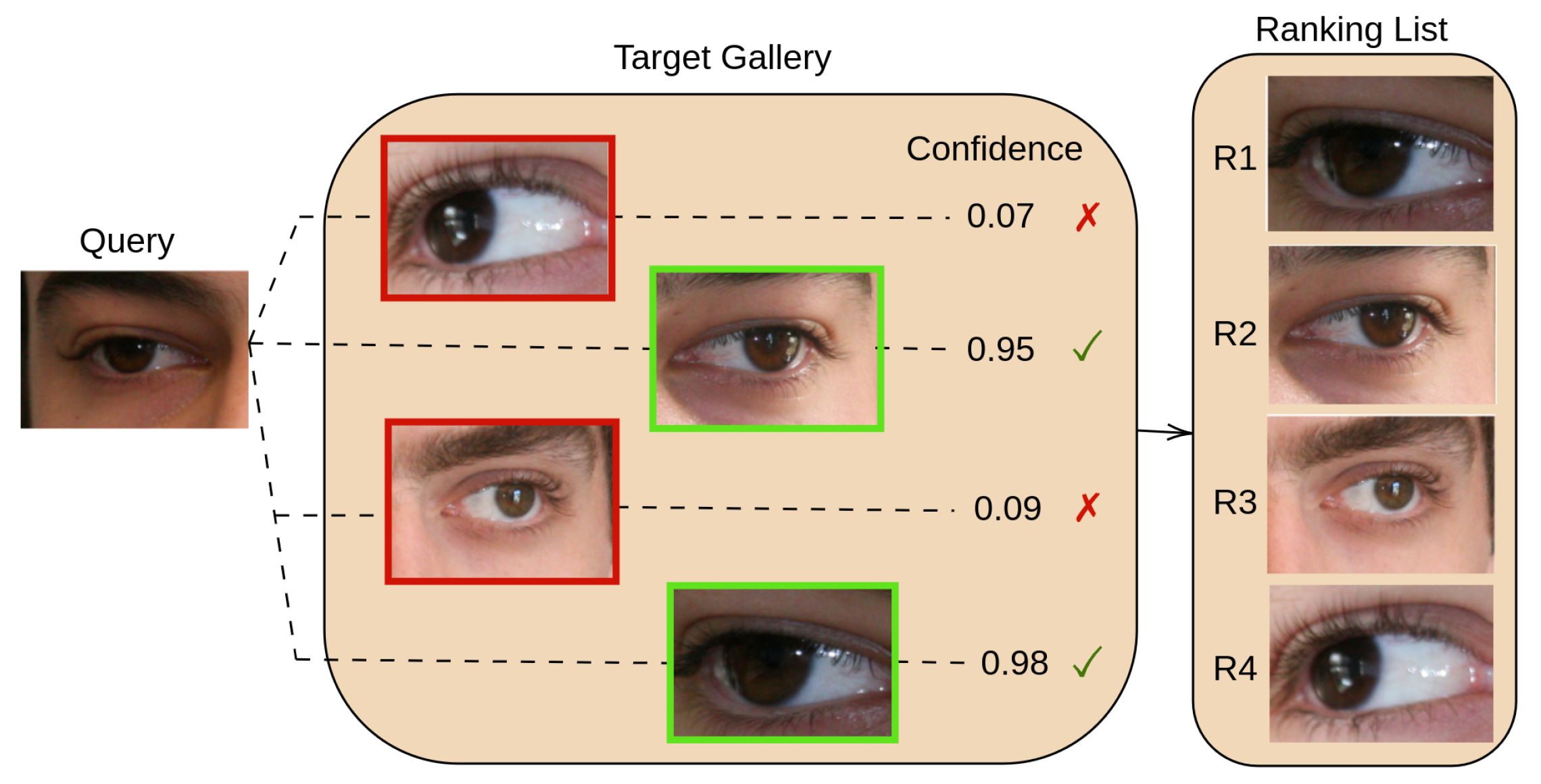
Figure 1 shows an overview of a periocular re-identification system, in which the area surrounding the eye is used as a cue to determine the correct match between the query and the gallery individuals.
Ref [
2], the periocular cues are categorised into (1) level one features, which are more dominant in nature and deal with geometry or shape (eyelids, eye corners, eyebrows), and (2) level two features, which are more related to colour and texture (skin appearance, skin pores, wrinkles, colour). Studies [
3] have shown that the periocular region contains relevant cues for person identification both in visible (VIS) and near-infrared images (NIR), and that, in general, level two features are more efficient in VIS images, while level one features are useful in NIR images. Moreover, Ref. [
4] showed that humans and computers rely on the same periocular cues for person identification, in both NIR and VIS scenarios.
In recent years, periocular recognition has become a prominent research area in biometric systems, because it has proved to be a valuable biometric approach and it offers several advantages. First of all, it can be captured with the same imaging devices used for facial or iris identification [
3], it is non-intrusive and can be performed without the need for physical contact or cooperation from the subjects. In addition, periocular recognition can be performed in different spectra (both in visible-light and infrared spectrum), making it a versatile method of biometric identification.
All the cues present in the periocular area are prone to occlusions or other factors that influence their applicability:
The iris and the sclera are sensitive to corneal reflexions (the Purkinje images);
Accessories—such as eyeglasses or bangs—can occlude the eyebrows;
Head/eye movements can lead to capturing blurry data;
Makeup can influence the overall appearance of the eye.
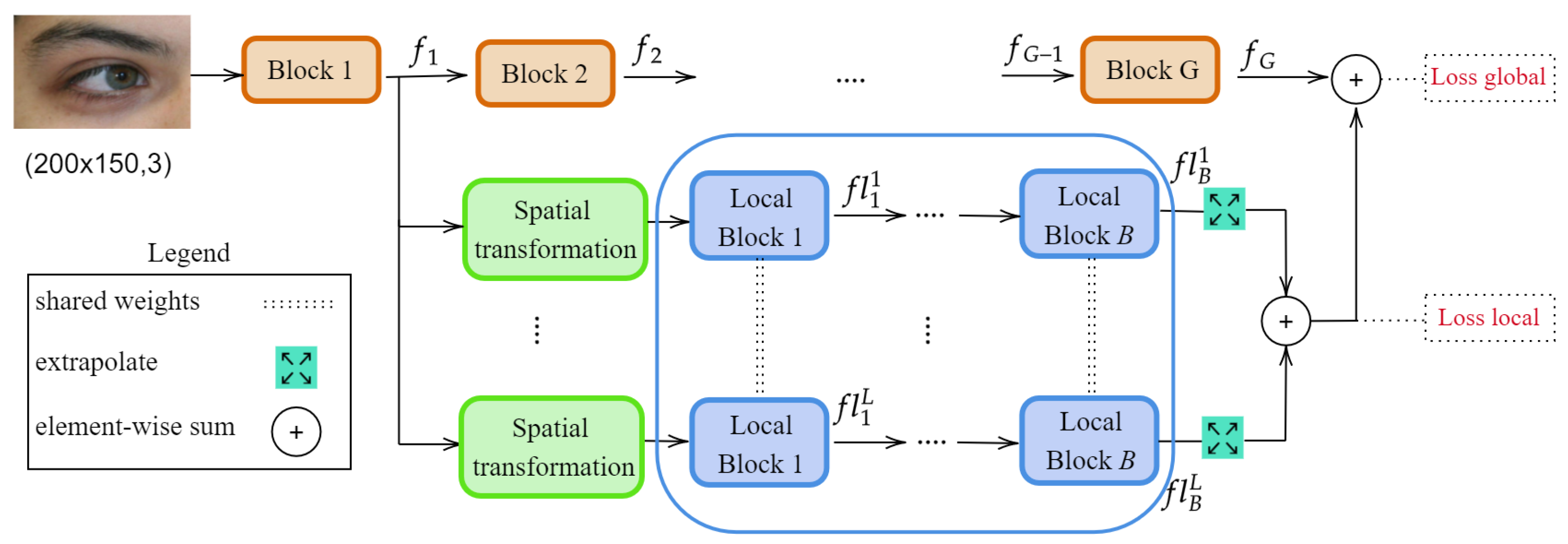
With these challenges in mind, the key idea of this paper is to design a convolutional neural network that can adapt to these challenging environmental changes and automatically focus on the most relevant cues visible in the input image. To this end, we propose a multi-branch architecture that can focus on several bio-metrical traits at different granularities, by adding several local branches to focus on different regions of the image. Each local branch learns a geometrical transformation matrix (allowing for scaling and translation), which is then used to sample a region of interest (ROI) from an intermediate feature map. These ROIs are further analysed by a set of shared local layers, and then merged (via feature map summation) with the global branch. The workflow of the proposed solution is illustrated in
Figure 2. By adding additional local branches to the model, we effectively exploit different bio-metrical traits and boost their performance in challenging environmental scenarios. Although the model design involves setting several hyperparameters, the features and the spatial transformation are automatically learned, and the proposed model can be trained in an end-to-end manner. Extensive ablation studies were performed to determine the impact of each hyperparameter.
The main contributions of this article are threefold: (1) we employ a spatial transformation module, which learns, in a semi-supervised manner, to identify the most prominent regions of the periocular area; (2) the periocular area is analysed both holistically, but also at the local level within the selected regions; and (3) the global and local information are fused to solve the recognition problem, and the loss function is applied to both the global and local branches to ensure that relevant features are extracted. Last but not least, the proposed method is generic, and can be easily adapted to other computer vision tasks.
The remainder of this manuscript is organized as follows:
Section 2 reviews the existing approaches for periocular recognition, while the methodology used for conducting this study and the proposed method are introduced in
Section 3.
Section 4 presents the experimental results and a comparison with state-of-the-art works. The conclusions of the paper and several future research directions are summarized in
Section 6.
2. Literature Survey
The pioneering work of Ref. [
5] analysed the feasibility of periocular biometrics and proposed a system that exploits a set of global (LBP—Local Binary Patterns, HoGl—Histogram of Oriented Gradients) and local (SIFTl—Scale-Invariant Feature Transform) descriptors, fused together at the score level based on a weighted sum with min-max normalisation. Early works focused on designing effective feature descriptors to capture textual information around the eyes, either at a global level—(variants of) LBP [
6,
7], Gabor filters [
8]—or at a local level—SIFT [
9], SURF (Speeded Up Robust Features) [
10], or SAFE (Symmetry Assessment by Feature Expansion) [
11].
Global-based methods operate holistically on the entire periocular region and extract a feature vector based on texture or shape information. Several methods rely on LBP descriptors, which determine binary patterns by comparing each pixel with its neighbours. The global descriptor is then obtained by concatenating histograms of binary patterns computed across image cells. Ref. [
7] investigated several feature extraction methods and determined that LBP substantially improved the performance of both verification and identification methods. In addition, they proposed the Local Walsh-Transform Binary Pattern feature representation, an effective variant of LBP. Other works use Gabor filters—with different orientations and frequencies—to analyse the texture in the periocular region.
A matching algorithm based on Gabor filters and a feature encoding scheme that relies on three operators to extract robust features in different spectral bands, was proposed in [
8]. Two operators—Weber Local Descriptor (WLD) and uniform LBP—work on the magnitude of the filtered images, while another one—uniform generalised LBP operator (GLBP)—operates on the phase.
PPDM (Periocular Probabilistic Deformation Model) [
12] applied a probabilistic inference model to compute 1:1 matching scores (between query and gallery images) based on correlation filters extracted from periocular image patches. Subsequently, the match performance was improved [
13] with an unsupervised method used to select discriminate regions from the periocular area.
Local-based methods employ a multi-stage process: first, prominent keypoints are located within the periocular area, and then features are extracted from their vicinity. In Ref. [
11], the authors adapted the Symmetry Assessment by Finite Expansion (SAFE) algorithm, previously used in fingerprint analysis, to the problem of periocular recognition. The key idea is to sample several keypoints based on a rectangular grid positioned in the eye centre, and then project ring-shaped areas of different sizes onto a space of harmonic functions used to determine symmetric curve families. A multi-modal authentication system that analyses and fuses features from the face, periocular and, if visible, iris area, is introduced in Ref. [
10]. The system extracts three feature descriptors—SIFT, SURF, and Binarised Statistical Image Features (BSIF)—and explores various fusion strategies to effectively combine information from all three modalities. Ref. [
14] identifies four prominent regions in the periocular area (eyebrows, upper eye fold, lower eye fold, and eye corners) and then computes a feature representation vector based on HOG, KAZE, and SING descriptors, as well as shape information. Finally, a Naïve Bayes classifier is used to perform the periocular recognition based on the extracted feature vector. The main drawback of this method is that it also requires the accurate segmentation of the features in the periocular area.
With the impressive advances of deep learning in the fields of computer vision and image recognition, recent developments in periocular biometrics focus exclusively on deep convolutional neural networks. Before CNNs, traditional pattern recognition methods used handcrafted features, such as LBP, HoG, Zernike moments [
15], fast block processing feature extraction [
16] etc., which were manually designed, taking into consideration the specific task and problem. On the other hand, in CNNs the features are automatically learned from the input data by convolutional layers. In general, deep learning methods tend to outperform traditional hand-crafted feature extraction techniques in computer vision tasks due to their ability to automatically learn relevant features from the data. The interested reader can refer to Refs. [
3,
17,
18] for an in-depth presentation on early periocular research.
In Ref. [
19], using transfer learning, seven CNN architectures were trained and compared in the context of periocular recognition. Ref. [
20] proposed an original augmentation strategy based on multi-class region swapping, such that the network learns to consider the iris and the sclera regions as not reliable for biometric recognition, and only focus on the information surrounding the eyes. Although the method does not involve additional parameters or an increase in inference time, it completely disregards some regions in the periocular area that contain powerful biometric traits.
Other works [
21,
22] employed multi-task models to boost the performance of periocular recognition systems. Ref. [
22] proposed semantics-assisted convolutional neural networks (SCNN) to incorporate explicit semantic information (gender and eye side): two separate CNNs are trained on these two tasks (identification and semantic task), and in the end are joined to obtain more powerful feature representations or to perform score fusion. Similarly, Ref. [
21] introduced an end-to-end biometric system, based on a multi-task architecture. The framework features a shared convolutional backbone and two separate, dedicated branches, one for biometric identification and one for soft biometric recognition. These branches are fused together for the final periocular recognition, while also predicting soft biometrics. However, the main disadvantage of these approaches is the need for annotated datasets with identity and soft biometric attributes, which are not always available. In addition, they tend to involve more parameters for the supporting tasks.
In Ref. [
23], the authors proposed a two-branch deep learning model to analyse iris and periocular cues, and then fuse the corresponding predictions through a multilayer perceptron (MLP). The training procedure is rather complicated, as it requires several stages. In addition, the inputs to each branch require different pre-processing techniques and, as two CNNs are used, the system has more learnable parameters, which leads to longer inference times.
Ref. [
24] designed a multimodal biometric system to exploit facial and periocular cues. The proposed model features a shared convolutional backbone, as well as two predictor branches to accommodate the two modalities. During training, additional loss functions are defined to decrease the distance between feature embeddings or periocular-face intra-subjects, while simultaneously maximising feature embeddings of the periocular-face inter-subjects. In Ref. [
25] the authors proposed AttenMidNet, a lightweight CNN based on attention mechanisms. The building blocks of the architecture are the MCRS blocks that comprise a convolutional layer, a squeeze-and-excitation block [
26], and a residual connection. Ref. [
27] proposed a Siamese-like dual stream network, which analyses in parallel the left and right periocular regions of a subject, and then investigates the feature aggregation techniques of the two streams.
Table 1 provides a summary (features, highlight, brief methodology) of the related periocular recognition methods discussed in this section.
Despite their impressive performance, a major caveat of deep learning methods is their lack of explainability. As a result, some works [
29,
30] tackled the problem of visual explanations and interpretable artificial intelligence in the context of periocular recognition.
3. Materials and Methods
3.1. Problem Setting
We formulate the biometric recognition problem as a re-identification problem. Consider a training image-based set of N different identities, each containing samples. The purpose of a re-identification system is to learn a function that will find the best match between a query image and a gallery set of images. The query set contains images of the periocular area of a subject we want to identify in another image or set of images (the gallery set). The gallery set contains the potential matches (periocular images) for the target person in the query set.
3.2. Solution Outline
The periocular area comprises various anatomical cues suitable for recognizing individuals and numerous studies have analysed their significance for this process (refer to Ref. [
3] for a detailed survey on this matter). However, the applicability of the periocular biometric traits is influenced by environmental factors, and depending on the overall appearance of the eye area and the image capture modality (VIS or NIR), one cue might be more relevant than the other. As an example, the skin texture and the overall eye shape are suitable cues for VIS images [
4], but make-up can influence their appearance and therefore degrade the performance of a machine learning model that has been trained to focus on such features. With this in mind, we devised a deep learning model which uses several local branches trained to locate (in a semi-supervised manner) and analyse several discriminative regions in the periocular area (
Figure 2).
The proposed method can be easily integrated into any network architecture, and it can effectively boost the performance of (re-)identification systems with a small increase in inference time. Additionally, this strategy can be easily adapted to other image recognition tasks.
3.3. Model Architecture
The key idea of our method is to employ L branches, branched from the ith level of a neural network architecture, which will learn to extract prominent ROIs within the periocular area and analyse them for biometric identification. Each local branch starts with a Spatial transformationmodule, responsible for the selection of an ROI in the input feature map . Then, a set of B shared convolutional layers (between all the L branches) process the selected areas, and finally, their corresponding feature maps are fused through element-wise summation. This summation result is also added to the global branch. To ensure that the local branches actually learn relevant information, we apply the loss function to both the global branch’s output and the summation of the local branches.
3.3.1. The Local Branch
The local branches learn to spot the most relevant regions on the input feature map and attempt to solve the identification problem based solely on the features from these areas.
Inspired by Refs. [
31,
32], we employ a visual attention mechanism to locate the discriminative parts of a feature map
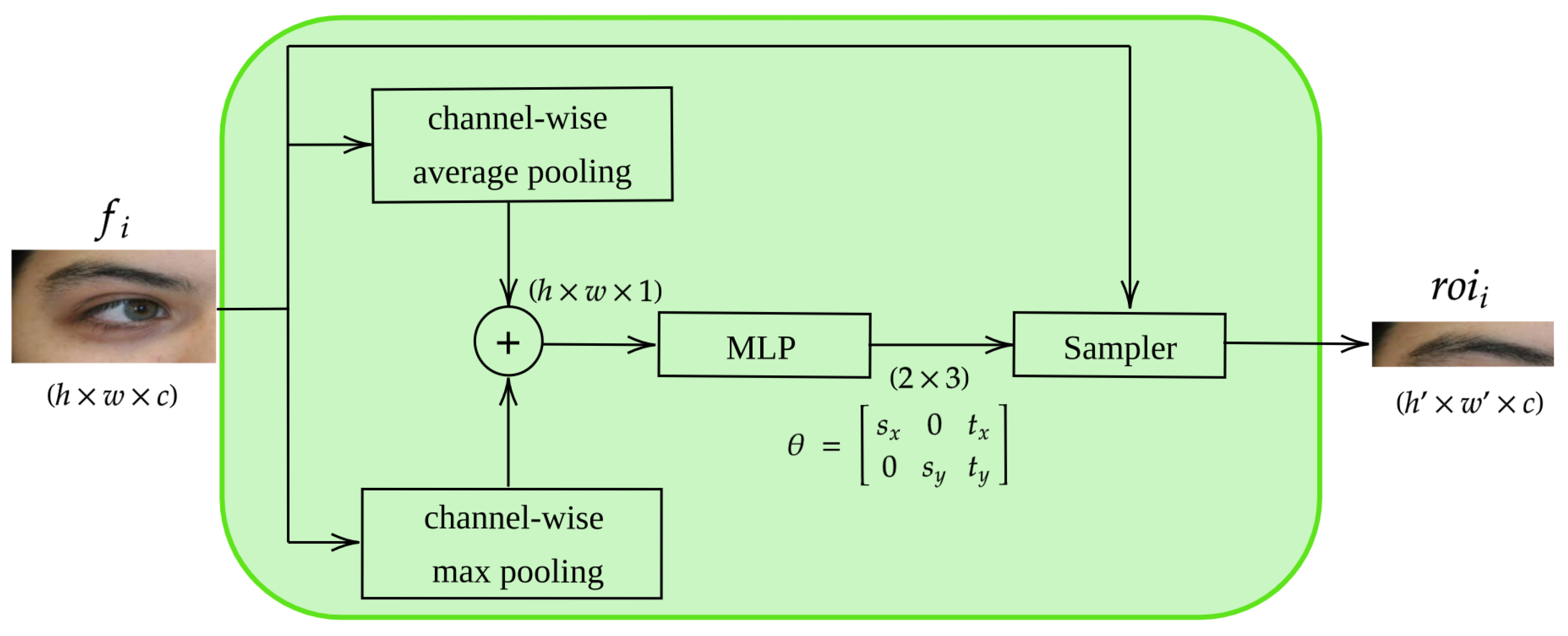
. To achieve this, each local branch starts with a
Spatial transformation module, which learns to select an ROI from the input feature map. Similar to [
33], we generate a spatial map using grouping operations to compute two bi-dimensional maps:
and
and aggregate them into a single map
using element-wise summation.
is then passed to a feed-forward multi-layer perceptron that regresses an affine spatial transformation matrix
:
This matrix allows for cropping and translation (2D spatial parameters
and
) and image scaling (scaling parameters
and
). The transformation is not learned explicitly from the dataset labels; instead, the model automatically optimises these parameters such that it boosts the recognition accuracy. At the beginning of the training process, the weight and biases of the linear layer are initialised with the identity transformation (i.e., all weights initialised to 0, biases for
and
initialised to 1, biases for
and
set to 0). After the transformation matrix
(Equation (
1)) is determined, the
grid generator module computes a 2D flow-field grid based on
to generate the coordinates from the input image corresponding to each position in the output. The
grid sampling module applies the transformation parameters to the input and returns an ROI
from the input feature map. The structure of this
Spatial transformation module is depicted in
Figure 3, and, for clarity, is also detailed in Algorithm 1. As illustrated in
Figure 2, the selected ROI
is further passed through a set of shared convolutional layers. In the end, all the outputs of the local branches are brought to agree with the shapes via an extrapolation layer, and they are added to the output of the global branch.
To guarantee that the features learned by the local branches are in fact useful in the periocular identification task, the loss function is also applied to their summation. More precisely, during training, the model has multiple outputs, one corresponding to the global branch and one corresponding to the summation of the local branches’ output. However, at test time, only the global branch output is used and evaluated. This is inspired by Ref. [
34], where the authors used several small classifiers (discarded at test time) on top of come convolutional blocks to ensure that the layers in the middle of the network are also very discriminative.
| Algorithm 1: Spatial transformation module. |
| Input: - feature map. |
| Output: - ROI in |
| /* compute channel-wise mean */ |
| ; |
| /* compute m channel-wise maximum */ |
| ; |
| /* fuse(addition) and m and flatten result */ |
| flatten(); |
| /* apply multi-layer perceptron to compute transformation matrix */ |
| |
| /* generate affine grid based on and sample */ |
| sample(); |
| return |
3.3.2. Closed vs. Open-World Operating Modes
In the context of periocular identification, AI models can operate in closed or open-world modes, depending on whether the identities of the subjects to be recognised are known or not.
In the closed-world setting (i.e., when all the subjects are known in advance), the identification problem can be formulated as a classification task, and a softmax layer can be used to predict the identities. In this case, the final layer of CNN is a dense layer with softmax activation, and its number of neurons is equal to the number of identities in the dataset. This problem can be seen as a watch-list identification problem [
20], in which the model aims to spot some subjects from a predefined list.
On the other hand, in the open-world setting, when the set of identities is unknown, the model needs to be trained to distinguish between unseen subjects. In this case, the identification problems are formulated as a distance learning task or a retrieval ranking problem. Therefore, the learning process aims to encode an input image into an embedding space, such that the distance between the images of the same identity is small, while the distance between images from different identities is large. Consequently, the final layer of the model is used as a feature descriptor (and not as a classification layer as in the closed-world setting). For this setup we employed the triplet loss (
3) to optimize the model. Once the model is trained, the recognition and verification task becomes straightforward in the embedding space, as it simply involves the computation between the computed embeddings. The forward pass of the proposed network architecture is illustrated in Algorithm 2.
We evaluated the proposed method for both closed-world and open-world settings.
3.4. Training Process
The proposed method is trained in an end-to-end manner. As mentioned above, biometric identification systems can operate in either closed-world or open-world settings.
In closed-world settings, test subjects are known at train time, and the identification task becomes essentially a classification problem. For this test setup, the identification loss is the standard categorical cross entropy loss: , where y is the ground truth identity for the x sample, is the model prediction (logits), and is the softmax function: .
During training for closed-world scenarios, the model has two outputs:
, the response of the classification layer in the global branch, and
, the response of the classification layer applied on the summation of the feature maps from the local branches. The final loss function
for the closed-world setting is given in Equation (
2):
On the other hand, in open-world scenarios, the output of the network does not consist of class probabilities, but in a feature vector in a lower dimensional embedding space in which the L2 distances correspond to subject similarities. In this case, a variant [
35] of the triplet loss function [
36] is used:
The triplet loss ensures that given an anchor point , the projection of a positive sample (belonging to the identity ) is closer to the anchor’s projection than that of a negative sample of a different identity , by at least a margin of . In addition, during training, we also apply a final classification layer with the number of neurons equal to the number of identities in the training set, on top of the global branch , and on top of each local branch .
To sum up, the loss function for the open-world setting is specified in Equation (
4):
where
and
are the weights for the triplet and identification losses. In our experiments we set
and
.
All models were trained using transfer learning (using pre-trained weights from ImageNet—from python torch library version 1.13.0 [
37]) for 70 epochs, using the Adam optimiser, with an initial learning rate of
, updated with a step decay scheduler at epochs 25 and 50.
| Algorithm 2: Forward function of the proposed network architecture. |
![Sensors 23 02456 i001]() |
5. Ablation Studies
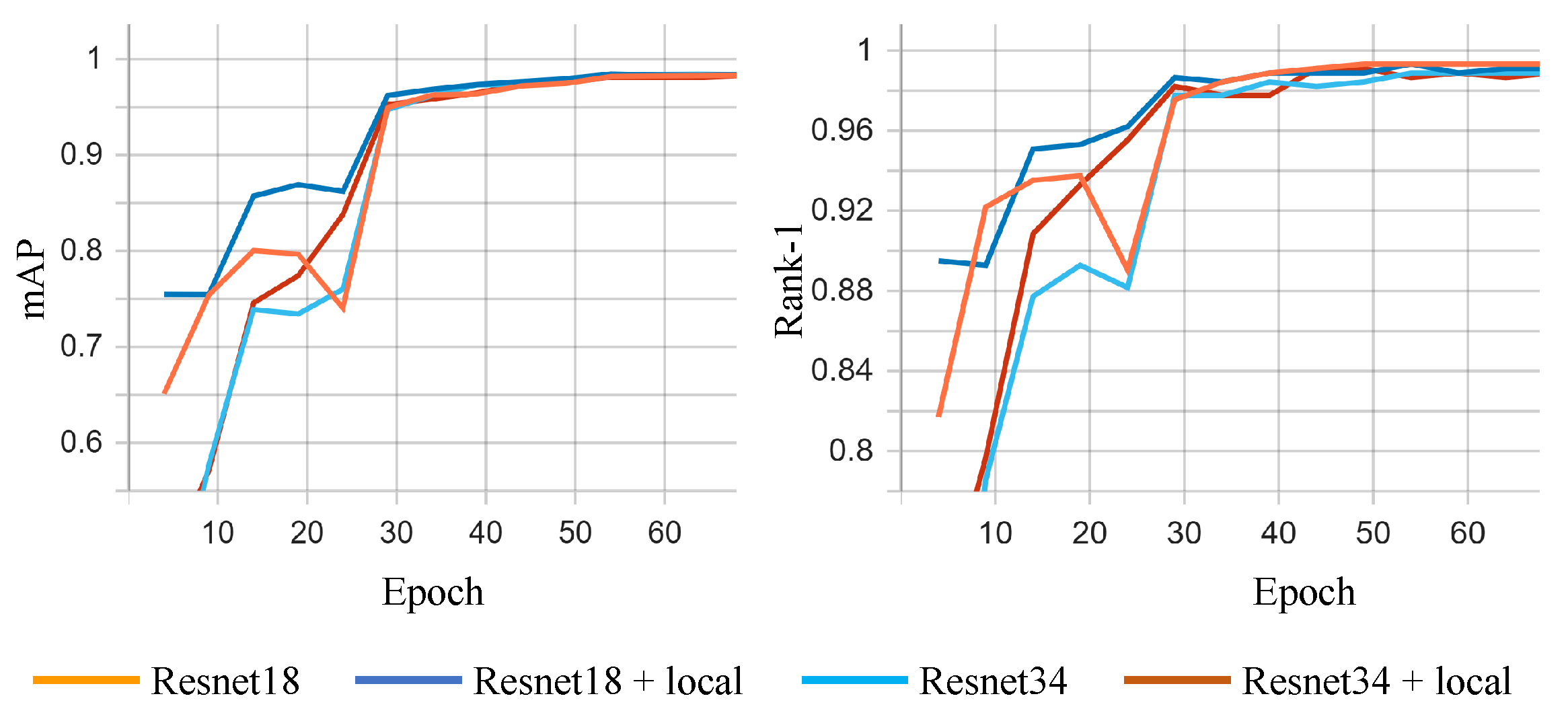
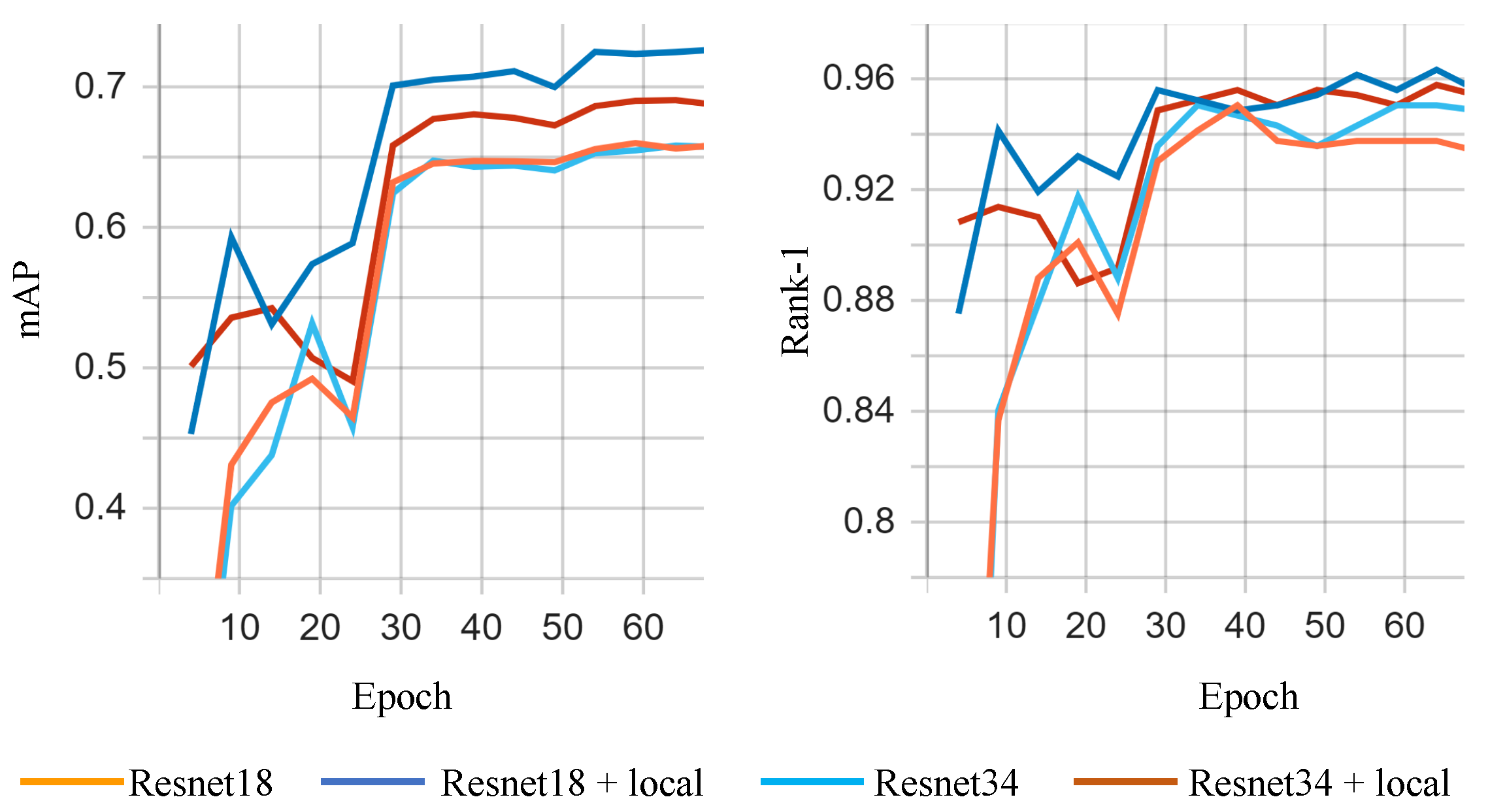
The idea of this paper is to add additional local branches to a neural network architecture, which will learn to identify and analyse the most relevant regions in the input. There are several hyper-parameters that can influence the effectiveness of the proposed method, and, in this section, we will analyse their effect on the model’s performance. All experiments for this ablation study were performed using the ResNet-18 architecture.
The first hyper-parameter is the depth (layer number) at which the local branches are added to the model. In
Table 5, the column
depth indicates the value of this parameter. As discussed in
Section 4.1, ResNet-18 architecture comprises a convolutional layer, followed by four types of ResNet block, each repeated twice (
Table 2). In other words, the local branches were added before the second, third, and fourth ResNet block pairs of the ResNet-18 architecture. The results indicate that better results are obtained when the local branches are added deeper into the network architecture. This is somewhat expected, as deeper layers operate with more semantically meaningful features. In addition, this setup allows the model to use the shallower layers as a shared local feature extractor, and therefore to reduce the inference time and learnable parameters.
Another experiment we performed is related to the way the feature map from the global branch is being preprocessed by the
Spatial transformation module (
Figure 3). To this end, we experimented with three strategies:
Bottleneck,
Channel, and
Spatial.
For the
Bottleneck setup (in
Table 5,
Bottleneck in the column
Preprocessing), the feature map is first passed through a
convolutional layer to reduce its depth to
, thus making the computations more feasible (Equation (5)). Next, the processed feature map
is flattened and then processed by the MLP to compute the transformation matrix
.
where
denotes a
convolutional layer with 32 filters.
The results show that this strategy achieves the lowest performance—even lower than the baseline ResNet18 architecture. The MLP layer needs to process a high dimensional (, where represents the spatial size of the feature map) flattened feature vector. This can lead to optimisation issues (overfitting) as the input layer in the MLP has a large number of neurons. Moreover, local branches might fail to extract semantically meaningful information from the flattened input feature.
Another strategy is to use global average pooling operations as a preprocessing step, as given in Equation (5):
where
and
represent the global average pooling and global max pooling operators, respectively.
This is similar to the Channel Attention from Ref. [
33]. In this case, the input size of the MLP layer is
, where
is the number of channels in the input feature map and this vector models the information about the channels with the most prominent features responses. With this setup, when local branches are added to deeper layers of the network, the baseline ResNet-18 architecture is surpassed in both mAP and Rank-1.
However, the best result is obtained with the
Spatial preprocessing (Equation (
7)). For this setup, the MLP takes as input the sum between the channel-wise average and maximum pooling operations, similar to the spatial attention component from Ref. [
33]:
where
and
represent the channel-wise average pooling and max pooling, respectively. With this configuration, the proposed method surpasses the baseline ResNet-18 architecture with more than 6% in mAP and 2.56% in Rank-1. Intuitively, this seems to be the most promising choice, since the goal of the
Spatial transformation module is to select the most discriminative periocular areas. Equation (
7) returns a map of dimensions
, in which higher values indicate areas with prominent features.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}