
Inertia-Constrained Reinforcement Learning to Enhance Human Motor Control Modeling



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Musculoskeletal Simulations
1.2. Reinforcement Learning for Simulation of Human Locomotion
2. Materials and Methods
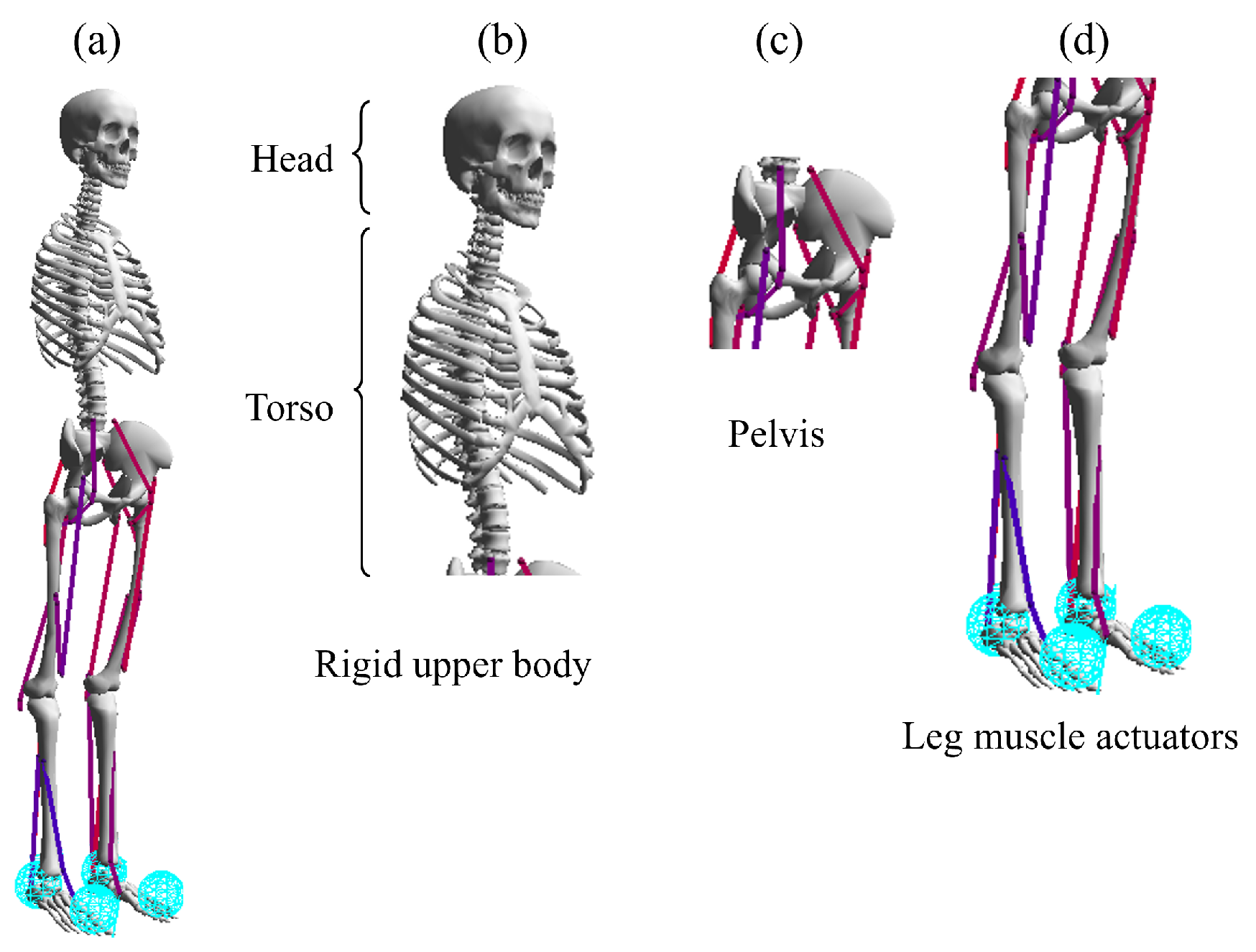
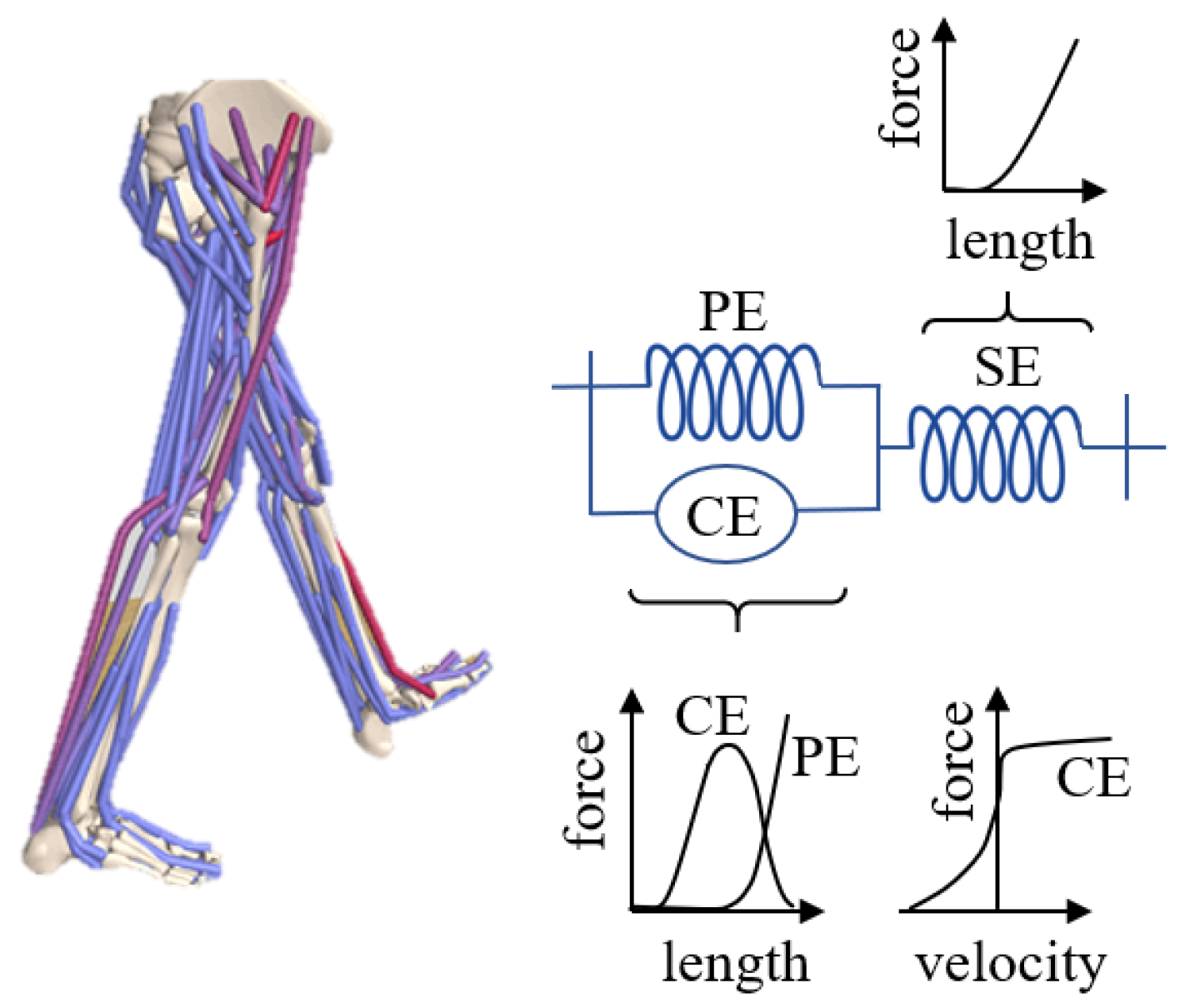
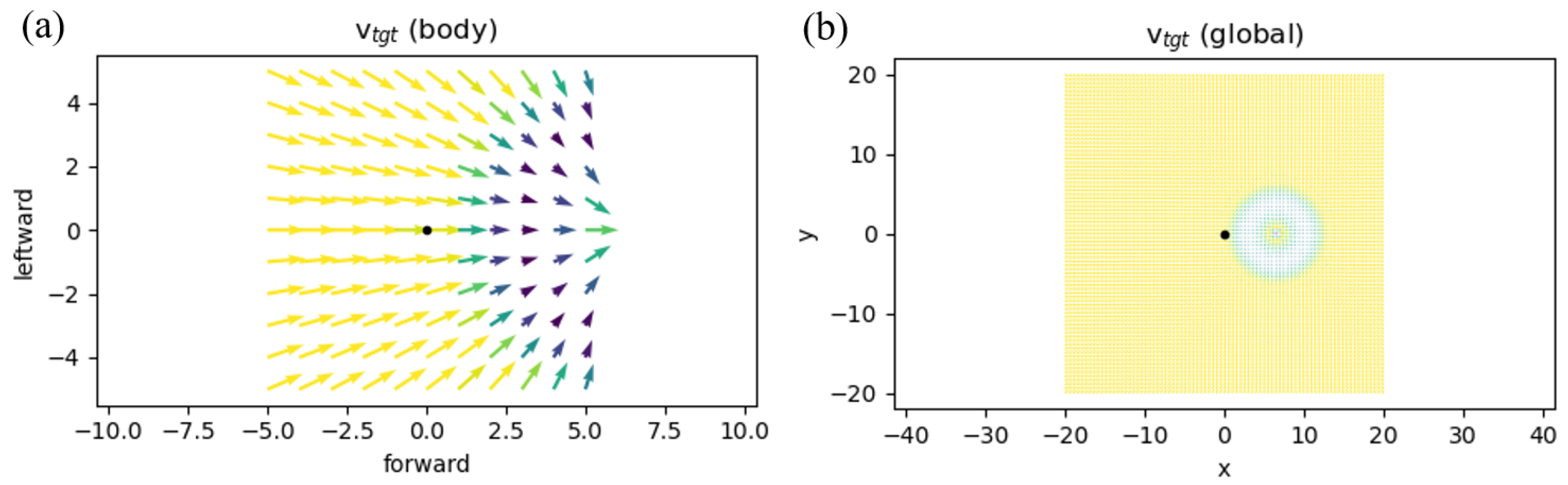
2.1. Simulation Environment
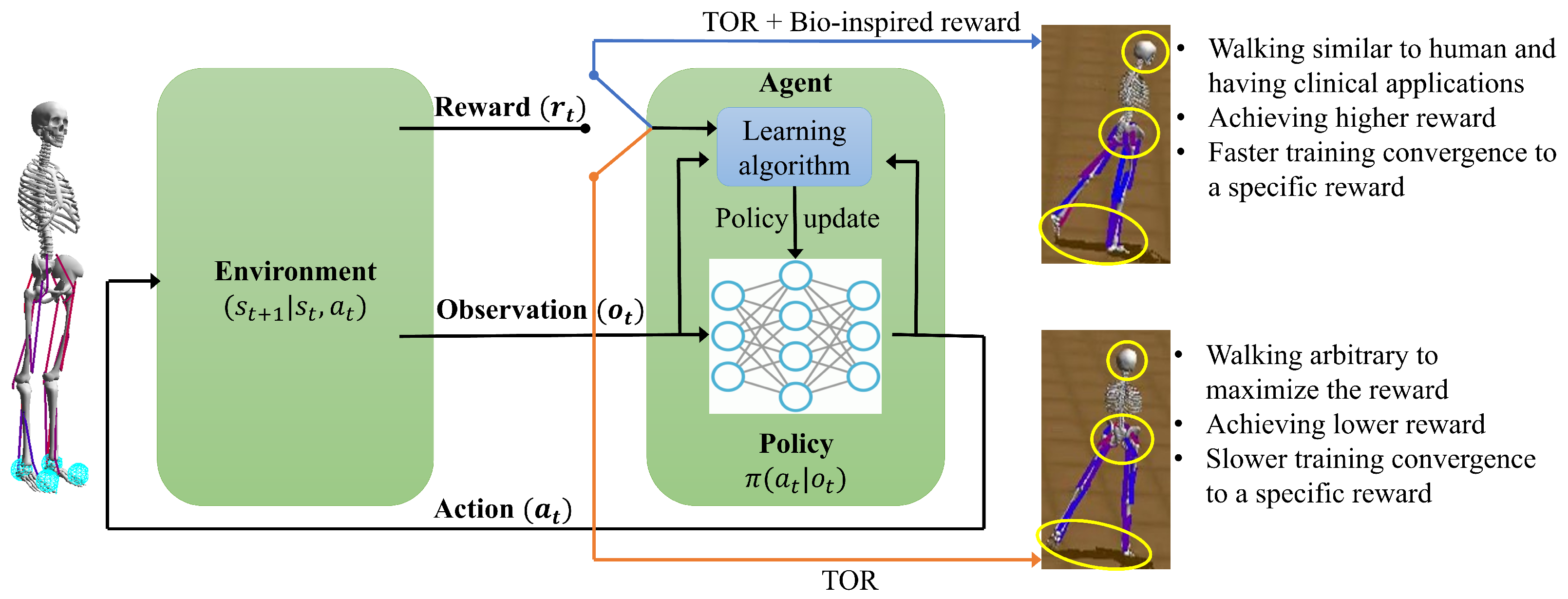
2.2. Reward Shaping
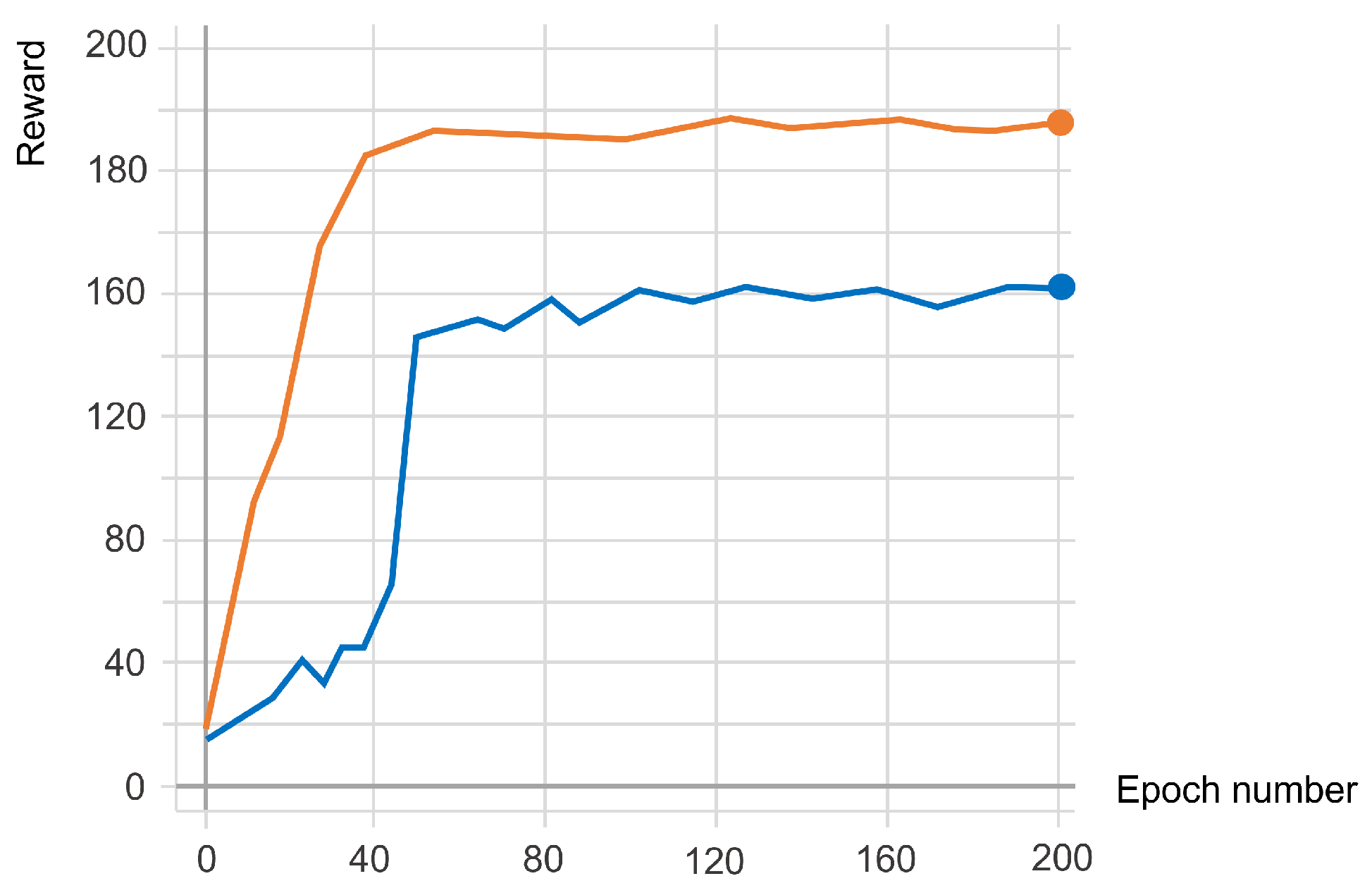
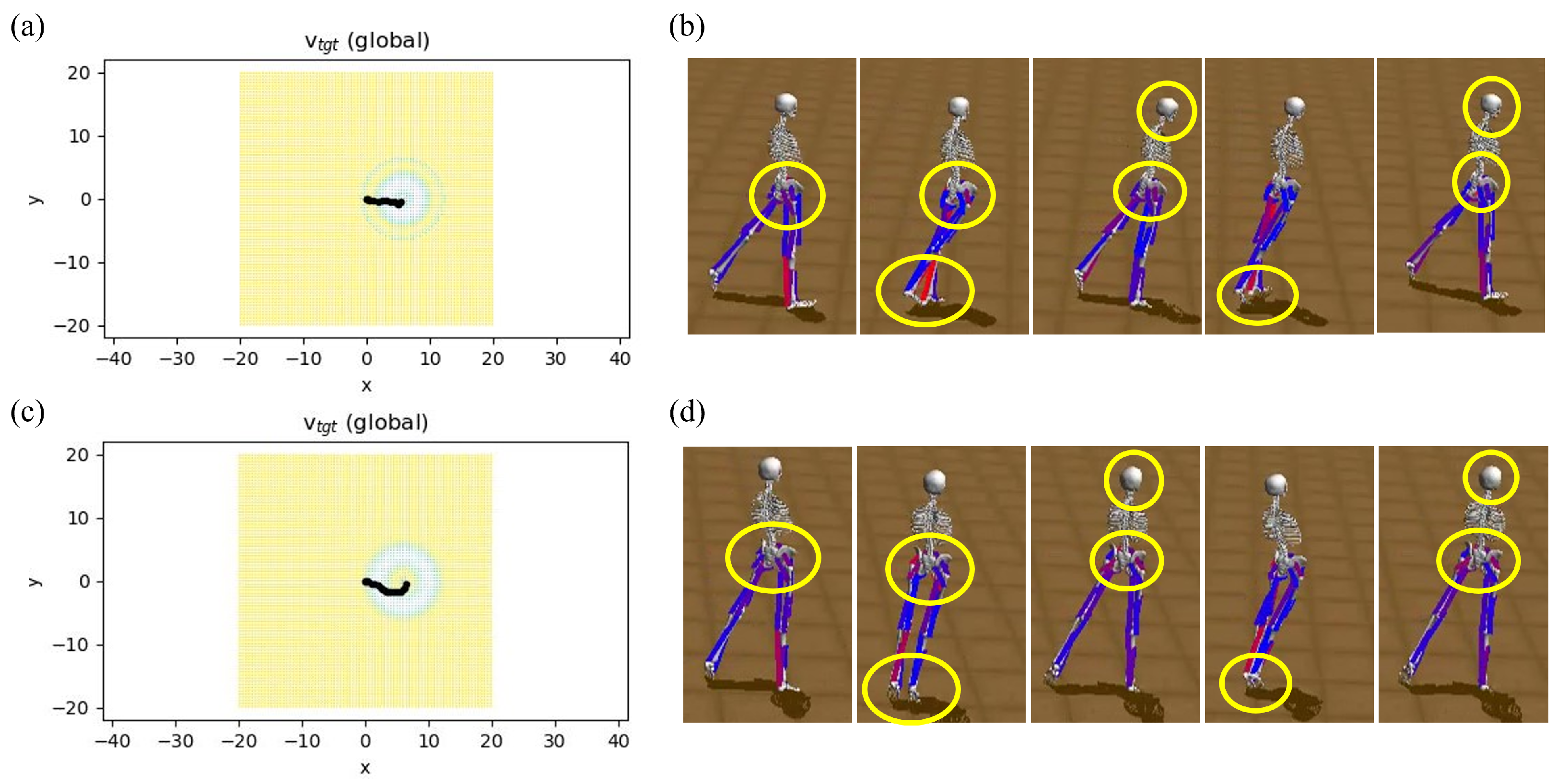
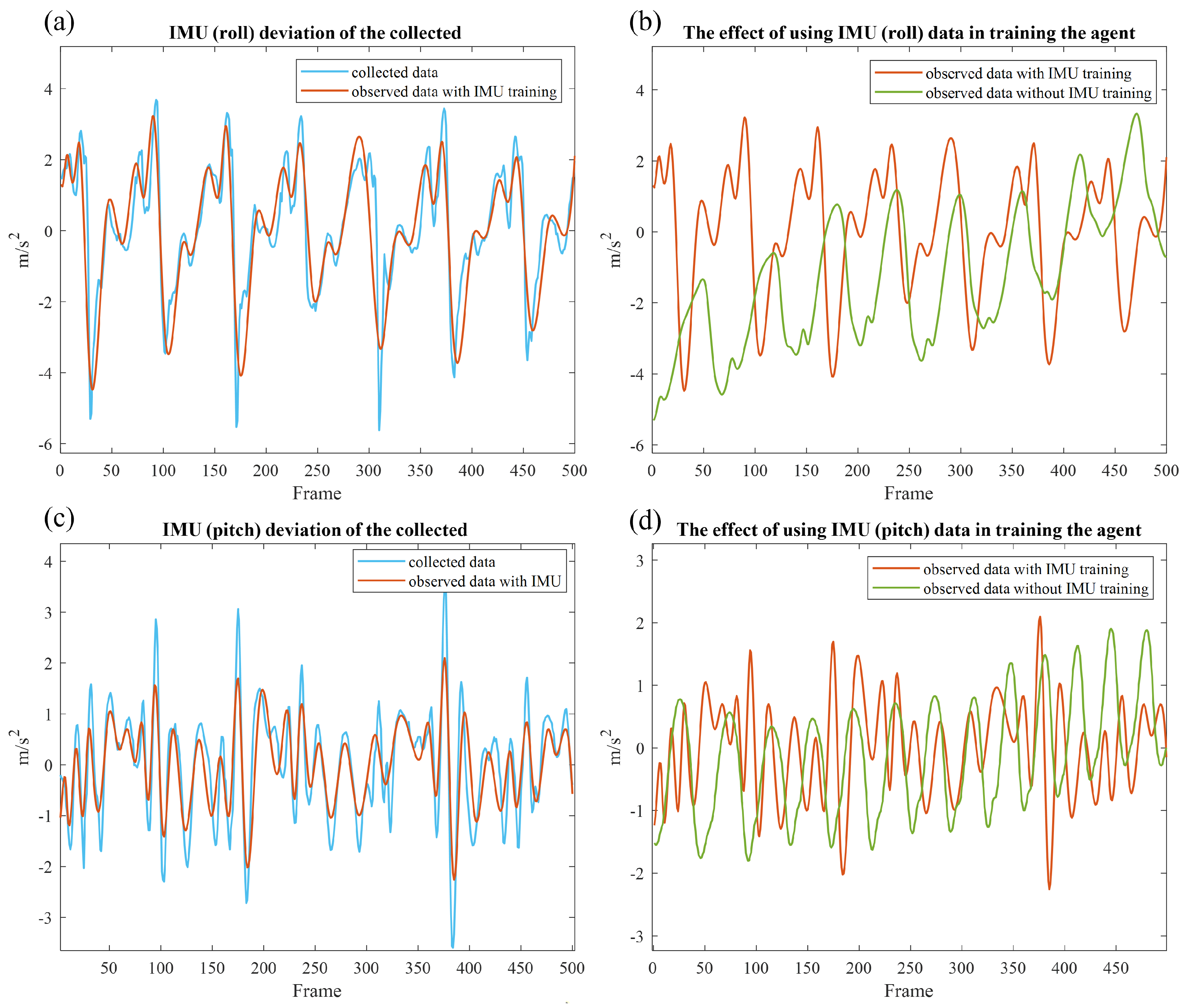
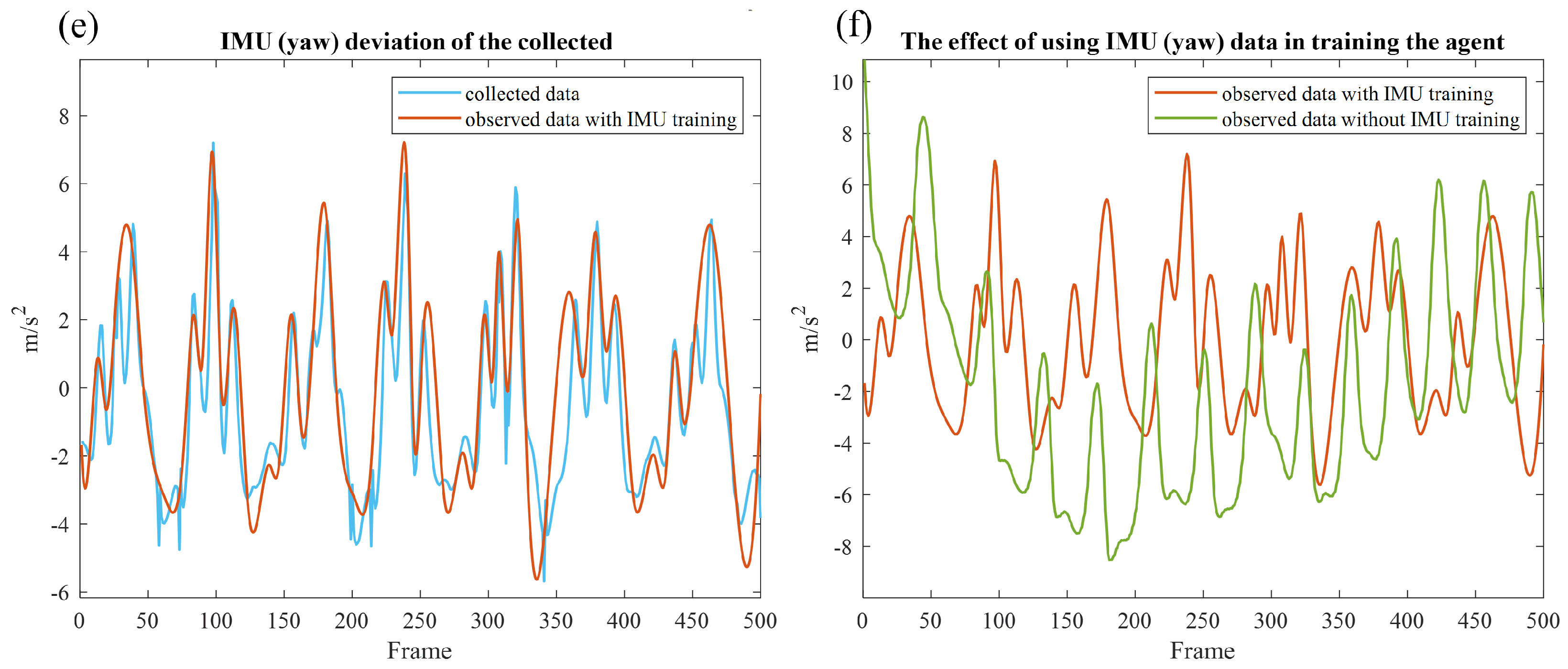
3. Results
4. Discussion
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kidziński, Ł.; Mohanty, S.P.; Ong, C.F.; Hicks, J.L.; Carroll, S.F.; Levine, S.; Salathé, M.; Delp, S.L. Learning to run challenge: Synthesizing physiologically accurate motion using deep reinforcement learning. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 101–120. [Google Scholar]
- Gentile, C.; Cordella, F.; Zollo, L. Hierarchical Human-Inspired Control Strategies for Prosthetic Hands. Sensors 2022, 22, 2521. [Google Scholar] [CrossRef]
- Richards, B.A.; Lillicrap, T.P.; Beaudoin, P.; Bengio, Y.; Bogacz, R.; Christensen, A.; Clopath, C.; Costa, R.P.; de Berker, A.; Ganguli, S.; et al. A deep learning framework for neuroscience. Nat. Neurosci. 2019, 22, 1761–1770. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Kidziński, Ł.; Peng, X.B.; Ong, C.; Hicks, J.; Levine, S.; Atkeson, C.G.; Delp, S.L. Deep reinforcement learning for modeling human locomotion control in neuromechanical simulation. J. Neuroeng. Rehabil. 2021, 18, 126. [Google Scholar] [CrossRef] [PubMed]
- Seth, A.; Dong, M.; Matias, R.; Delp, S. Muscle contributions to upper-extremity movement and work from a musculoskeletal model of the human shoulder. Front. Neurorobot. 2019, 13, 90. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajagopal, A.; Dembia, C.L.; DeMers, M.S.; Delp, D.D.; Hicks, J.L.; Delp, S.L. Full-body musculoskeletal model for muscle-driven simulation of human gait. IEEE Trans. Biomed. Eng. 2016, 63, 2068–2079. [Google Scholar] [CrossRef]
- Haeufle, D.; Günther, M.; Bayer, A.; Schmitt, S. Hill-type muscle model with serial damping and eccentric force–velocity relation. J. Biomech. 2014, 47, 1531–1536. [Google Scholar] [CrossRef] [PubMed]
- Hill, A.V. The heat of shortening and the dynamic constants of muscle. Proc. R. Soc. London Ser. Biol. Sci. 1938, 126, 136–195. [Google Scholar]
- Geyer, H.; Herr, H. A muscle-reflex model that encodes principles of legged mechanics produces human walking dynamics and muscle activities. IEEE Trans. Neural Syst. Rehabil. Eng. 2010, 18, 263–273. [Google Scholar] [CrossRef]
- Millard, M.; Uchida, T.; Seth, A.; Delp, S.L. Flexing computational muscle: Modeling and simulation of musculotendon dynamics. J. Biomech. Eng. 2013, 135, 021005. [Google Scholar] [CrossRef] [Green Version]
- Scheys, L.; Loeckx, D.; Spaepen, A.; Suetens, P.; Jonkers, I. Atlas-based non-rigid image registration to automatically define line-of-action muscle models: A validation study. J. Biomech. 2009, 42, 565–572. [Google Scholar] [CrossRef]
- Fregly, B.J.; Boninger, M.L.; Reinkensmeyer, D.J. Personalized neuromusculoskeletal modeling to improve treatment of mobility impairments: A perspective from European research sites. J. Neuroeng. Rehabil. 2012, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Seth, A.; Hicks, J.L.; Uchida, T.K.; Habib, A.; Dembia, C.L.; Dunne, J.J.; Ong, C.F.; DeMers, M.S.; Rajagopal, A.; Millard, M.; et al. OpenSim: Simulating musculoskeletal dynamics and neuromuscular control to study human and animal movement. PLoS Comput. Biol. 2018, 14, e1006223. [Google Scholar] [CrossRef] [Green Version]
- Chandler, R.; Clauser, C.E.; McConville, J.T.; Reynolds, H.; Young, J.W. Investigation of Inertial Properties of the Human Body; Technical Report; Air Force Aerospace Medical Research Lab: Wright-Patterson, OH, USA, 1975. [Google Scholar]
- Visser, J.; Hoogkamer, J.; Bobbert, M.; Huijing, P. Length and moment arm of human leg muscles as a function of knee and hip-joint angles. Eur. J. Appl. Physiol. Occup. Physiol. 1990, 61, 453–460. [Google Scholar] [CrossRef] [PubMed]
- Ward, S.R.; Eng, C.M.; Smallwood, L.H.; Lieber, R.L. Are current measurements of lower extremity muscle architecture accurate? Clin. Orthop. Relat. Res. 2009, 467, 1074–1082. [Google Scholar] [CrossRef] [Green Version]
- De Groote, F.; Van Campen, A.; Jonkers, I.; De Schutter, J. Sensitivity of dynamic simulations of gait and dynamometer experiments to hill muscle model parameters of knee flexors and extensors. J. Biomech. 2010, 43, 1876–1883. [Google Scholar] [CrossRef] [PubMed]
- Thelen, D.G.; Anderson, F.C.; Delp, S.L. Generating dynamic simulations of movement using computed muscle control. J. Biomech. 2003, 36, 321–328. [Google Scholar] [CrossRef]
- Liu, M.Q.; Anderson, F.C.; Schwartz, M.H.; Delp, S.L. Muscle contributions to support and progression over a range of walking speeds. J. Biomech. 2008, 41, 3243–3252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamner, S.R.; Seth, A.; Delp, S.L. Muscle contributions to propulsion and support during running. J. Biomech. 2010, 43, 2709–2716. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Zeng, L.; Li, Y.; Shi, C.; Peng, Y.; Pan, R.; Huang, M.; Wang, S.; Zhang, J.; Li, H. Decabromodiphenyl ethane induces locomotion neurotoxicity and potential Alzheimer’s disease risks through intensifying amyloid-beta deposition by inhibiting transthyretin/transthyretin-like proteins. Environ. Int. 2022, 168, 107482. [Google Scholar] [CrossRef]
- Wong, Y.B.; Chen, Y.; Tsang, K.F.E.; Leung, W.S.W.; Shi, L. Upper extremity load reduction for lower limb exoskeleton trajectory generation using ankle torque minimization. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 773–778. [Google Scholar]
- De Groote, F.; Kinney, A.L.; Rao, A.V.; Fregly, B.J. Evaluation of direct collocation optimal control problem formulations for solving the muscle redundancy problem. Ann. Biomed. Eng. 2016, 44, 2922–2936. [Google Scholar] [CrossRef] [Green Version]
- Cavallaro, E.E.; Rosen, J.; Perry, J.C.; Burns, S. Real-time myoprocessors for a neural controlled powered exoskeleton arm. IEEE Trans. Biomed. Eng. 2006, 53, 2387–2396. [Google Scholar] [CrossRef] [PubMed]
- Bassiri, Z.; Austin, C.; Cousin, C.; Martelli, D. Subsensory electrical noise stimulation applied to the lower trunk improves postural control during visual perturbations. Gait Posture 2022, 96, 22–28. [Google Scholar] [CrossRef] [PubMed]
- Lotti, N.; Xiloyannis, M.; Durandau, G.; Galofaro, E.; Sanguineti, V.; Masia, L.; Sartori, M. Adaptive model-based myoelectric control for a soft wearable arm exosuit: A new generation of wearable robot control. IEEE Robot. Autom. Mag. 2020, 27, 43–53. [Google Scholar] [CrossRef]
- Uchida, T.K.; Seth, A.; Pouya, S.; Dembia, C.L.; Hicks, J.L.; Delp, S.L. Simulating ideal assistive devices to reduce the metabolic cost of running. PLoS ONE 2016, 11, e0163417. [Google Scholar] [CrossRef] [Green Version]
- Fox, M.D.; Reinbolt, J.A.; Õunpuu, S.; Delp, S.L. Mechanisms of improved knee flexion after rectus femoris transfer surgery. J. Biomech. 2009, 42, 614–619. [Google Scholar] [CrossRef] [Green Version]
- De Groote, F.; Falisse, A. Perspective on musculoskeletal modelling and predictive simulations of human movement to assess the neuromechanics of gait. Proc. R. Soc. 2021, 288, 20202432. [Google Scholar] [CrossRef]
- Anderson, F.C.; Pandy, M.G. Dynamic optimization of human walking. J. Biomech. Eng. 2001, 123, 381–390. [Google Scholar] [CrossRef] [Green Version]
- Falisse, A.; Serrancolí, G.; Dembia, C.L.; Gillis, J.; Jonkers, I.; De Groote, F. Rapid predictive simulations with complex musculoskeletal models suggest that diverse healthy and pathological human gaits can emerge from similar control strategies. J. R. Soc. Interface 2019, 16, 20190402. [Google Scholar] [CrossRef] [Green Version]
- Ackermann, M.; Van den Bogert, A.J. Optimality principles for model-based prediction of human gait. J. Biomech. 2010, 43, 1055–1060. [Google Scholar] [CrossRef] [Green Version]
- Miller, R.H.; Umberger, B.R.; Hamill, J.; Caldwell, G.E. Evaluation of the minimum energy hypothesis and other potential optimality criteria for human running. Proc. R. Soc. Biol. Sci. 2012, 279, 1498–1505. [Google Scholar] [CrossRef] [Green Version]
- Miller, R.H.; Umberger, B.R.; Caldwell, G.E. Limitations to maximum sprinting speed imposed by muscle mechanical properties. J. Biomech. 2012, 45, 1092–1097. [Google Scholar] [CrossRef] [PubMed]
- Handford, M.L.; Srinivasan, M. Energy-optimal human walking with feedback-controlled robotic prostheses: A computational study. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1773–1782. [Google Scholar] [CrossRef]
- Zhang, J.; Fiers, P.; Witte, K.A.; Jackson, R.W.; Poggensee, K.L.; Atkeson, C.G.; Collins, S.H. Human-in-the-loop optimization of exoskeleton assistance during walking. Science 2017, 356, 1280–1284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, X.; Korivand, S.; Hamill, K.; Jalili, N.; Gong, J. A comprehensive decoding of cognitive load. Smart Health 2022, 26, 100336. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Levine, S. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv 2018, arXiv:1805.00909. [Google Scholar]
- Kuang, N.L.; Leung, C.H.; Sung, V.W. Stochastic reinforcement learning. In Proceedings of the 2018 IEEE First International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 26–28 September 2018; pp. 244–248. [Google Scholar]
- Azimirad, V.; Ramezanlou, M.T.; Sotubadi, S.V.; Janabi-Sharifi, F. A consecutive hybrid spiking-convolutional (CHSC) neural controller for sequential decision making in robots. Neurocomputing 2022, 490, 319–336. [Google Scholar] [CrossRef]
- Schulman, J.; Heess, N.; Weber, T.; Abbeel, P. Gradient estimation using stochastic computation graphs. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Badnava, B.; Kim, T.; Cheung, K.; Ali, Z.; Hashemi, M. Spectrum-Aware Mobile Edge Computing for UAVs Using Reinforcement Learning. In Proceedings of the 2021 IEEE/ACM Symposium on Edge Computing (SEC), San Jose, CA, USA, 14–17 December 2021; pp. 376–380. [Google Scholar]
- Akhavan, Z.; Esmaeili, M.; Badnava, B.; Yousefi, M.; Sun, X.; Devetsikiotis, M.; Zarkesh-Ha, P. Deep Reinforcement Learning for Online Latency Aware Workload Offloading in Mobile Edge Computing. arXiv 2022, arXiv:2209.05191. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1–7. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Peng, X.B.; van de Panne, M. Learning locomotion skills using deeprl: Does the choice of action space matter? In Proceedings of the Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Los Angeles, CA, USA, 28–30 July 2017; pp. 1–13. [Google Scholar]
- Lee, S.; Park, M.; Lee, K.; Lee, J. Scalable muscle-actuated human simulation and control. ACM Trans. Graph. (TOG) 2019, 38, 1–13. [Google Scholar] [CrossRef]
- Akimov, D. Distributed soft actor-critic with multivariate reward representation and knowledge distillation. arXiv 2019, arXiv:1911.13056. [Google Scholar]
- Peng, X.B.; Abbeel, P.; Levine, S.; Van de Panne, M. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Hodgins, J. Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning. ACM Trans. Graph. (TOG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Uhlenberg, L.; Amft, O. Comparison of Surface Models and Skeletal Models for Inertial Sensor Data Synthesis. In Proceedings of the 2022 IEEE-EMBS International Conference on Wearable and Implantable Body Sensor Networks (BSN), Ioannina, Greece, 27–30 September 2022; pp. 1–5. [Google Scholar]
- Romijnders, R.; Warmerdam, E.; Hansen, C.; Welzel, J.; Schmidt, G.; Maetzler, W. Validation of IMU-based gait event detection during curved walking and turning in older adults and Parkinson’s Disease patients. J. Neuroeng. Rehabil. 2021, 18, 28. [Google Scholar] [CrossRef]
- Wilson, C.M.; Kostsuca, S.R.; Boura, J.A. Utilization of a 5-meter walk test in evaluating self-selected gait speed during preoperative screening of patients scheduled for cardiac surgery. Cardiopulm. Phys. Ther. J. 2013, 24, 36. [Google Scholar] [CrossRef] [Green Version]
- Korivand, S.; Jalili, N.; Gong, J. Experiment Protocols for Brain-Body Imaging of Locomotion: A Systematic Review. Front. Neurosci. 2023, 17, 214. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sun, R.; Li, D.; Liang, S.; Ding, T.; Srikant, R. The global landscape of neural networks: An overview. IEEE Signal Process. Mag. 2020, 37, 95–108. [Google Scholar] [CrossRef]
- Delp, S.L.; Anderson, F.C.; Arnold, A.S.; Loan, P.; Habib, A.; John, C.T.; Guendelman, E.; Thelen, D.G. OpenSim: Open-source software to create and analyze dynamic simulations of movement. IEEE Trans. Biomed. Eng. 2007, 54, 1940–1950. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clermont, C.A.; Benson, L.C.; Edwards, W.B.; Hettinga, B.A.; Ferber, R. New considerations for wearable technology data: Changes in running biomechanics during a marathon. J. Appl. Biomech. 2019, 35, 401–409. [Google Scholar] [CrossRef] [PubMed]
- Bini, S.A.; Shah, R.F.; Bendich, I.; Patterson, J.T.; Hwang, K.M.; Zaid, M.B. Machine learning algorithms can use wearable sensor data to accurately predict six-week patient-reported outcome scores following joint replacement in a prospective trial. J. Arthroplast. 2019, 34, 2242–2247. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Korivand, S.; Jalili, N.; Gong, J. Inertia-Constrained Reinforcement Learning to Enhance Human Motor Control Modeling. Sensors 2023, 23, 2698. https://doi.org/10.3390/s23052698
Korivand S, Jalili N, Gong J. Inertia-Constrained Reinforcement Learning to Enhance Human Motor Control Modeling. Sensors. 2023; 23(5):2698. https://doi.org/10.3390/s23052698
Chicago/Turabian StyleKorivand, Soroush, Nader Jalili, and Jiaqi Gong. 2023. "Inertia-Constrained Reinforcement Learning to Enhance Human Motor Control Modeling" Sensors 23, no. 5: 2698. https://doi.org/10.3390/s23052698
APA StyleKorivand, S., Jalili, N., & Gong, J. (2023). Inertia-Constrained Reinforcement Learning to Enhance Human Motor Control Modeling. Sensors, 23(5), 2698. https://doi.org/10.3390/s23052698