

Improving the Efficiency of 3D Monocular Object Detection and Tracking for Road and Railway Smart Mobility

 , ,
, ,  , ,
, ,  ,
,
Abstract
:1. Introduction
- Mapping and localization: this represents the establishment of spatial relationships between the vehicle and static surrounding objects.
- Detection and tracking of moving objects
- Object classification (car, bus, pedestrian, cyclist…): The vehicles need to be able to detect each different class precisely, as each class has its own behavior, and properly identifying each object is key to understanding the environment.
- Classification and localization algorithms draw bounding boxes around each object detected.
- Instance segmentation associates each pixel with a class to uniquely identify it. The segmentation trims the object and is more accurate than the bounding box detection.
2. Related Works
2.1. Object Detection Methods
2.2. Datasets
2.3. Object Tracking
- Occlusion and truncation, when an object is totally or partially hidden by another, or when it goes out of the camera’s field of view, cause the algorithm to forget the object, and once it is back in the frame, the algorithm considers it to be a new object.
- Fast camera or point of view movements can cause the algorithm to predict erroneous trajectories, as it attributes these sudden important changes in the frame to the objects’ movements.
2.4. Knowledge Distillation
3. Improvements on 3D Object Detection and Tracking
3.1. Object 3D Detection & Classification: Improvements on YOLOv5-3D [1]
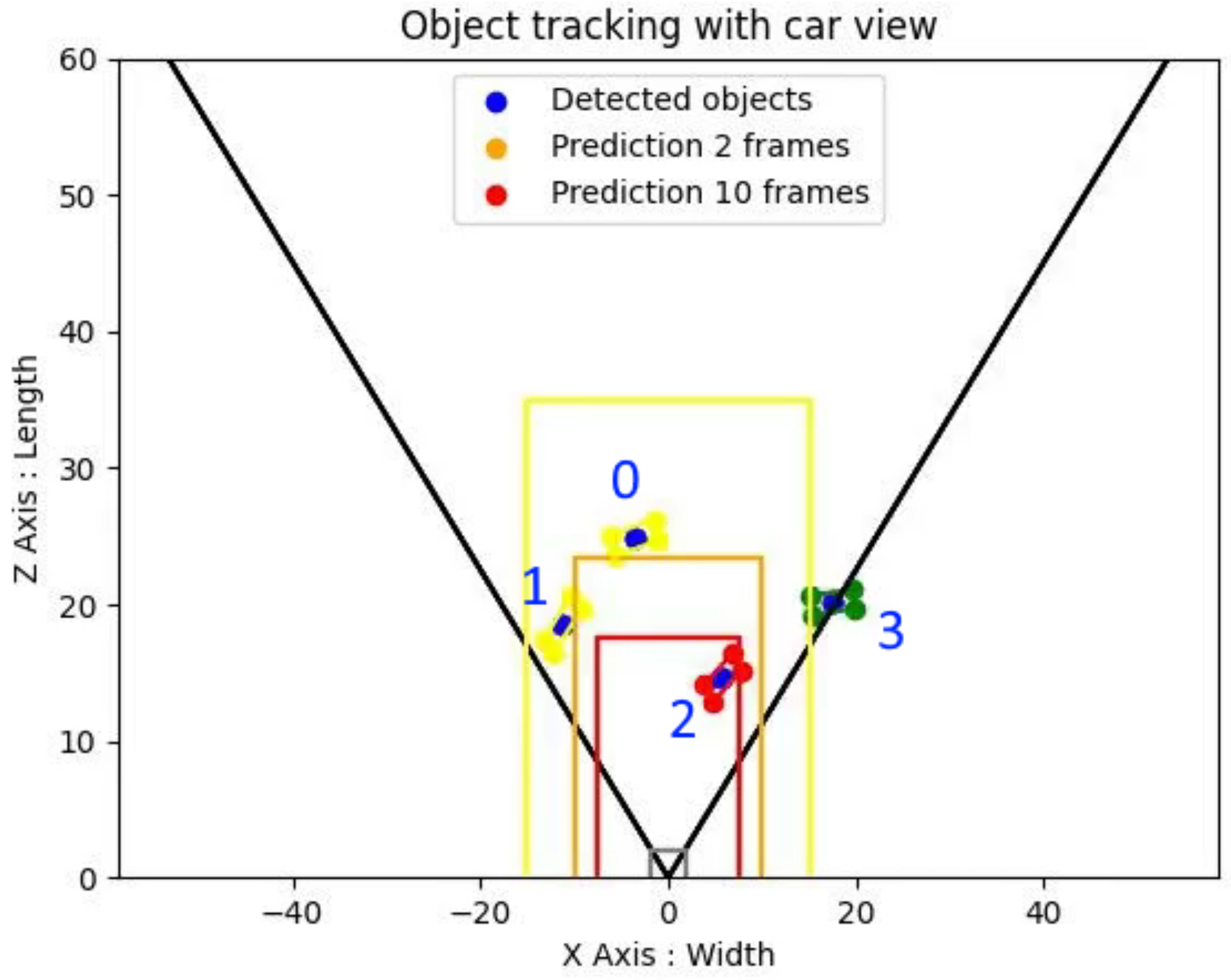
3.2. Object Tracking & Visualization
3.3. Dataset Combination
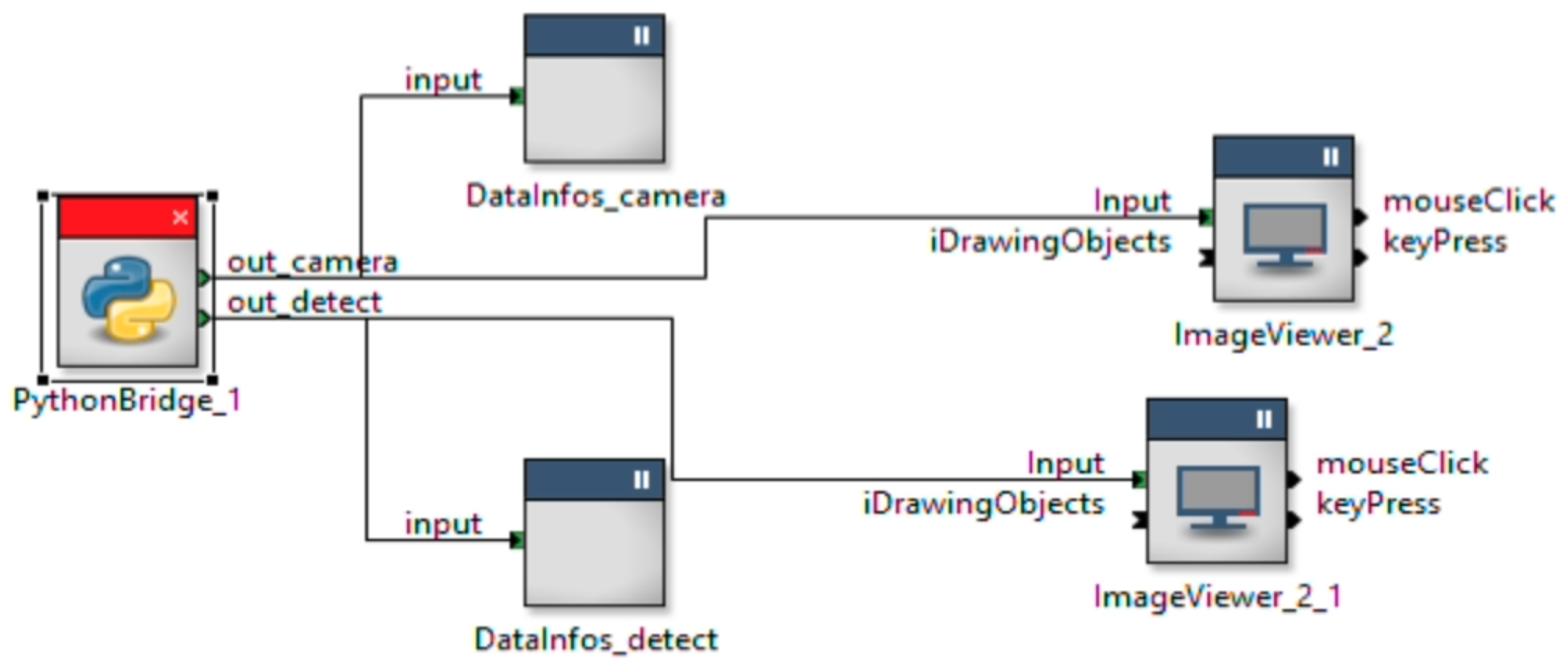
4. Field Integration
5. Experimental Results
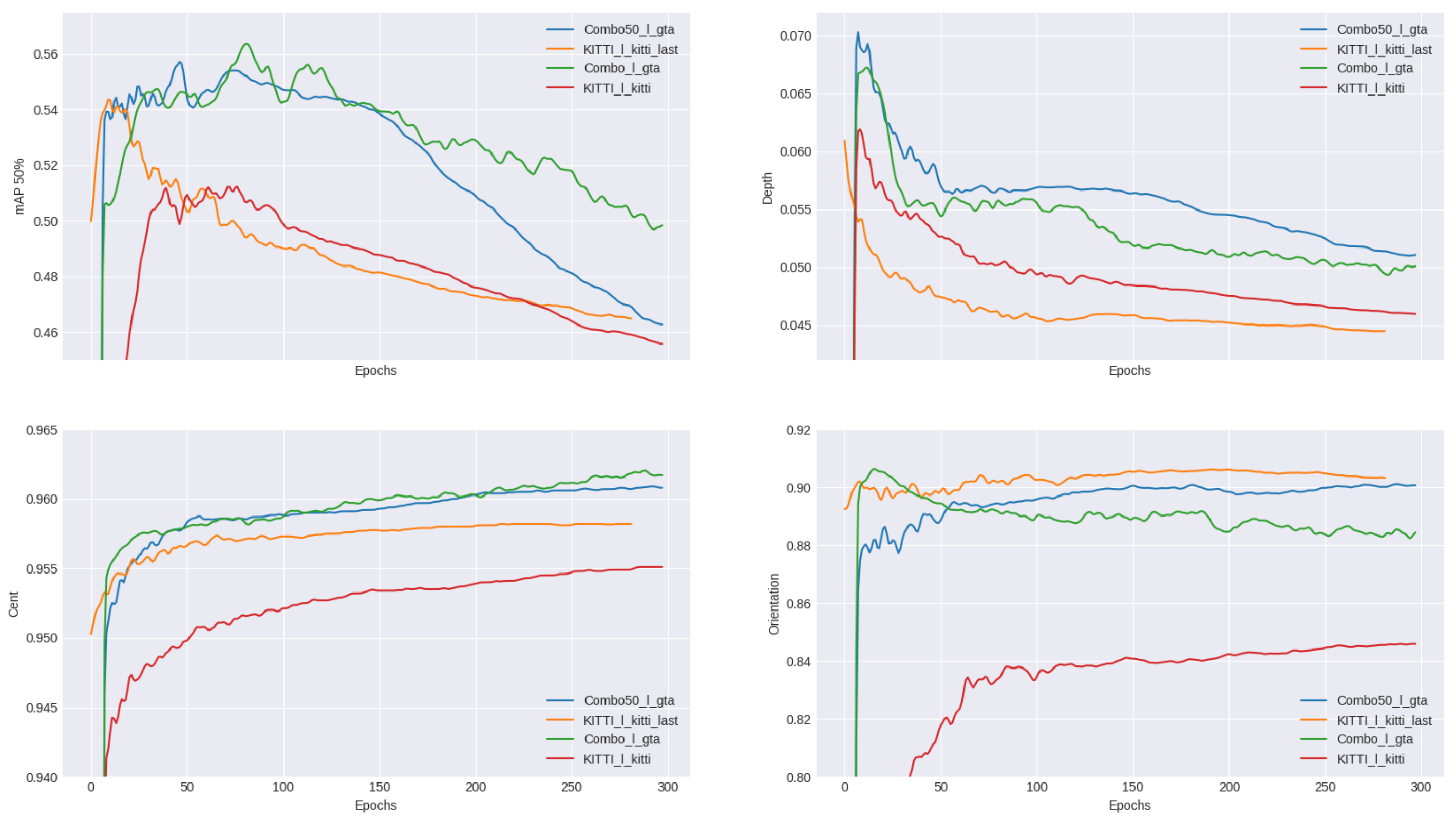
5.1. Dataset Combination
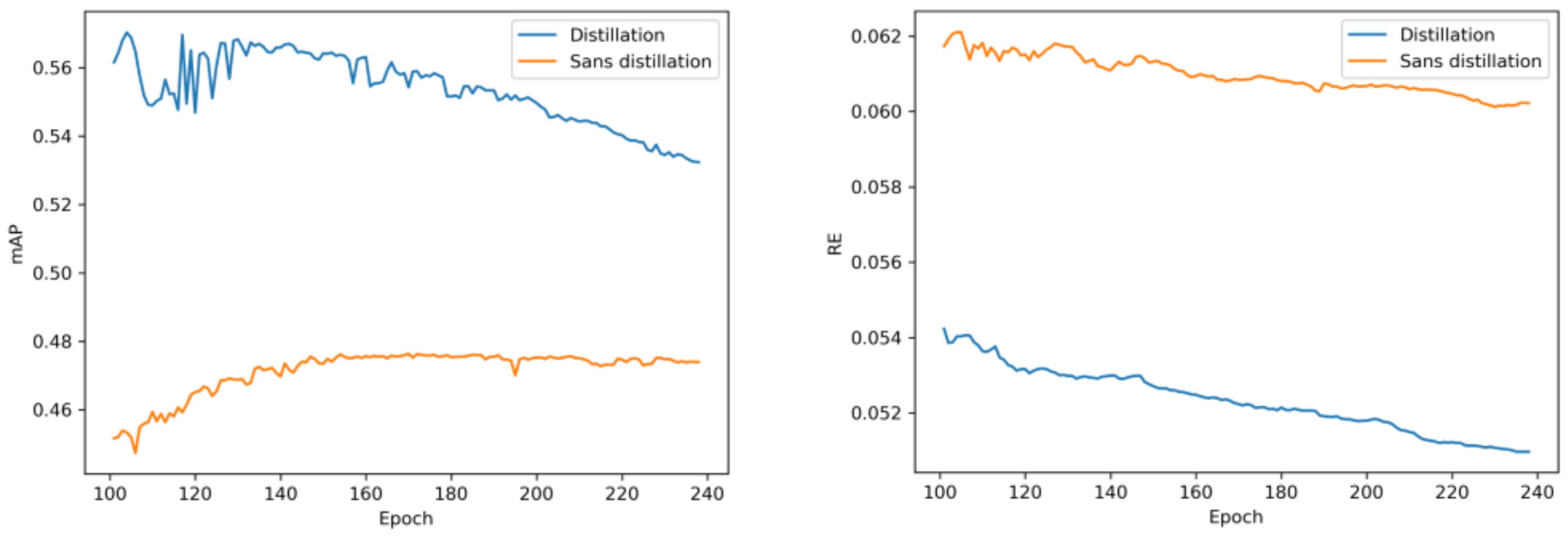
5.2. Knowledge Distillation
5.3. Field Integration
5.4. Lightweight Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| CNN | Convolutional Neural Networks |
| COCO | Common Objects in Context |
| CRIANN | Centre Régional Informatique et d’Applications Numériques de Normandie |
| (Regional Center for Computer Science and Digital Applications of Normandy) | |
| ESRORAD | Esigelec engineering high school and Segula technologies ROad and RAilway Dataset |
| FPS | Frame-Per-Second |
| GPS | Global Positioning System |
| GTA | Grand Theft Auto |
| IMU | Inertial Measurement Unit |
| KITTI | Karlsruhe Institute of Technology & Toyota Technological Institute at Chicago |
| vision benchmark suite | |
| LIDAR | Light Detection And Ranging |
| mAP | mean Average Precision |
| MOT | Multi-Object Tracking |
| NUScenes | NuTonomy Scenes |
| SORT | Simple Online and Realtime Tracking |
| SOTA | State Of The Art |
| SYNTHIA | SYNTHetic Collection of Imagery and Annotations |
| YOLO | You Look Only Once |
References
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Lightweight convolutional neural network for real-time 3D object detection in road and railway environments. J.-Real-Time Image Process. 2022, 19, 499–516. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Xie, T.; Michael, K.; Fang, J.; Imyhxy; et al. Ultralytics/yolov5: v6.2—YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai Integrations. 2022. Available online: https://zenodo.org/record/7002879#.ZBMIUHYo9PY (accessed on 13 March 2023). [CrossRef]
- Liu, Y.; Wang, L.; Liu, M. YOLOStereo3D: A Step Back to 2D for Efficient Stereo 3D Detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13018–13024. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7074–7082. [Google Scholar]
- Liu, Y.; Yuan, Y.; Liu, M. Ground-aware Monocular 3D Object Detection for Autonomous Driving. IEEE Robot. Autom. Lett. 2021, 6, 919–926. [Google Scholar] [CrossRef]
- Wang, C.; Yeh, I.; Liao, H.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Wang, T.; Pang, J.; Lin, D. Monocular 3D Object Detection with Depth from Motion. arXiv 2022, arXiv:2207.12988. [Google Scholar] [CrossRef]
- Qin, Z.; Li, X. MonoGround: Detecting Monocular 3D Objects from the Ground. arXiv 2022, arXiv:2206.07372. [Google Scholar] [CrossRef]
- Huang, K.C.; Wu, T.H.; Su, H.T.; Hsu, W.H. MonoDTR: Monocular 3D Object Detection with Depth-Aware Transforme. arXiv 2022, arXiv:2203.10981. [Google Scholar] [CrossRef]
- Zhou, Y.; He, Y.; Zhu, H.; Wang, C.; Li, H.; Jiang, Q. Monocular 3D Object Detection: An Extrinsic Parameter Free Approach. arXiv 2021, arXiv:2106.15796. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are Different: Flexible Monocular 3D Object Detection. arXiv 2021, arXiv:2104.02323. [Google Scholar] [CrossRef]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving. arXiv 2020, arXiv:2001.03343. [Google Scholar] [CrossRef]
- Liu, Z.; Zhou, D.; Lu, F.; Fang, J.; Zhang, L. AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection. arXiv 2021, arXiv:2108.11127. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Proceedings of the European Conference on Computer Vision (ECCV); Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Amsterdam, The Netherlands, 2016; Volume 9906, pp. 102–118, LNCS. [Google Scholar]
- Krḧenbühl, P. Free Supervision from Video Games. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Khemmar, R.; Mauri, A.; Dulompont, C.; Gajula, J.; Vauchey, V.; Haddad, M.; Boutteau, R. Road and railway smart mobility: A high-definition ground truth hybrid dataset. Sensors 2022, 22, 3922. [Google Scholar] [CrossRef]
- Zendel, O.; Murschitz, M.; Zeilinger, M.; Steininger, D.; Abbasi, S.; Beleznai, C. RailSem19: A Dataset for Semantic Rail Scene Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Harb, J.; Rébéna, N.; Chosidow, R.; Roblin, G.; Potarusov, R.; Hajri, H. FRSign: A Large-Scale Traffic Light Dataset for Autonomous Trains. arXiv 2020, arXiv:2002.05665. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixé, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 8844–8854. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Asif, U.; Tang, J.; Harrer, S. Ensemble Knowledge Distillation for Learning Improved and Efficient Network. arXiv 2019, arXiv:1909.08097. [Google Scholar] [CrossRef]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. Proc. AAAI Conf. Artif. Intell. 2020, 34. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. PMLR 2019, 97, 6105–6114. [Google Scholar]
- Koonce, B. EfficientNet. In Convolutional Neural Networks with Swift for Tensorflow; Springer: Cham, Switzerland, 2021; pp. 109–123. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database (Model) | Resolution | 2D Detection | Distance | Dimensions | Centre | Orientation | # Parameters | Time/img | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | R | [email protected] | RE | SRE | RMSE | log RMSE | DS | CS | OS | |||||||
| KITTI (Small) | 672 × 224 | 0.722 | 0.520 | 0.500 | 0.069 | 0.163 | 2.27 | 0.094 | 0.978 | 0.997 | 0.999 | 0.863 | 0.942 | 0.879 | 7.3 M | 70 ms |
| KITTI (LW) | 608 × 192 | 0.642 | 0.518 | 0.469 | 0.056 | 0.133 | 2.15 | 0.081 | 0.985 | 0.998 | 0.999 | 0.871 | 0.953 | 0.863 | 6.0 M | 28 ms |
| NuScenes (LW) | 608 × 352 | 0.527 | 0.431 | 0.374 | 0.054 | 0.205 | 3.11 | 0.074 | 0.985 | 1 | 1 | 0.838 | 0.962 | 0.920 | 6.0 M | 28 ms |
| Training Database | Training Resolution | Inference Resolution | 2D Detection | Distance | Dimension DS | Centre CS | Orientation OS | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | R | [email protected] | RE | SRE | RMSE | log RMSE | |||||||||
| KITTI | 672 × 244 | 672 × 244 | 0.897 | 0.752 | 0.732 | 0.0483 | 0.0987 | 1.82 | 0.0733 | 0.989 | 0.998 | 0.999 | 0.883 | 0.959 | 0.906 |
| 672 × 244 | 1312 × 416 | 0.835 | 0.821 | 0.779 | 0.178 | 1.15 | 6.61 | 0.218 | 0.6 | 0.997 | 0.999 | 0.866 | 0.949 | 0.928 | |
| GTA | 1312 × 768 | 1312 × 416 | 0.839 | 0.603 | 0.584 | 0.140 | 0.784 | 5.21 | 0.157 | 0.846 | 0.999 | 1.0 | 0.851 | 0.967 | 0.955 |
| 1312 × 768 | 1312 × 768 | 0.823 | 0.593 | 0.571 | 0.114 | 0.584 | 4.63 | 0.134 | 0.913 | 1.0 | 1.0 | 0.848 | 0.962 | 0.955 | |
| NuScenes | 1312 × 768 | 1312 × 416 | 0.857 | 0.678 | 0.697 | 0.455 | 5.97 | 14.7 | 0.378 | 0.0766 | 0.945 | 0.999 | 0.651 | 0.965 | 0.977 |
| 1312 × 768 | 1312 × 768 | 0.843 | 0.642 | 0.635 | 0.0654 | 0.198 | 2.72 | 0.0776 | 0.994 | 1.0 | 1.0 | 0.654 | 0.964 | 0.986 | |
| Real Data | Synthetic Data | Combined Data | |
|---|---|---|---|
| Dataset | KITTI | GTA V | KITTI + GTA V |
| N° of Pictures | 11,193 | 110,271 | 121,464 |
| Resolution | 1224 × 370 | 1280 × 720 | 1280 × 720 |
| N° of classes | 3 (cars, pedestrians, cyclists) | 3 (cars, pedestrians, cyclists) | 3 (cars, pedestrians, cyclists) |
| Training Split | Validation Split (KITTI) | Hyper-Parameters | Model/Pre-Training | |
|---|---|---|---|---|
| Combo | 114,688 | 3769 | GTA V | Large |
| Combo 50% synthetic | 7424 synthetic + 7424 real | 3769 | GTA V | Large/last_15 |
| KITTI (reference) | 7424 | 3769 | KITTI | Large |
| KITTI | 7424 | 3769 | KITTI | Large/large_15 |
| Method | GTA Pre-Training | Resolution | [val] | [val] | Time/img (ms) | Memory Consumption | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| IOU 0.7 | IOU 0.5 | |||||||||
| Easy | Mod | Hard | Easy | Mod | Hard | |||||
| Small | 672 × 224 | 7.29 | 5.48 | 5.34 | 44.35 | 31.80 | 29.91 | 1.5 | 1.6 GB | |
| 1312 × 416 | 15.52 | 13.27 | 13.19 | 48.24 | 36.14 | 31.78 | 4.4 | 1.7 GB | ||
| X | 1312 × 416 | 15.59 | 13.50 | 13.14 | 49.71 | 38.02 | 32.70 | 4.4 | 1.6 GB | |
| Small (with distillation) | X | 672 × 224 | 16.60 | 13.49 | 12.01 | 53.62 | 35.97 | 33.32 | 1.5 | 1.7 GB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evain, A.; Mauri, A.; Garnier, F.; Kounouho, M.; Khemmar, R.; Haddad, M.; Boutteau, R.; Breteche, S.; Ahmedali, S. Improving the Efficiency of 3D Monocular Object Detection and Tracking for Road and Railway Smart Mobility. Sensors 2023, 23, 3197. https://doi.org/10.3390/s23063197
Evain A, Mauri A, Garnier F, Kounouho M, Khemmar R, Haddad M, Boutteau R, Breteche S, Ahmedali S. Improving the Efficiency of 3D Monocular Object Detection and Tracking for Road and Railway Smart Mobility. Sensors. 2023; 23(6):3197. https://doi.org/10.3390/s23063197
Chicago/Turabian StyleEvain, Alexandre, Antoine Mauri, François Garnier, Messmer Kounouho, Redouane Khemmar, Madjid Haddad, Rémi Boutteau, Sébastien Breteche, and Sofiane Ahmedali. 2023. "Improving the Efficiency of 3D Monocular Object Detection and Tracking for Road and Railway Smart Mobility" Sensors 23, no. 6: 3197. https://doi.org/10.3390/s23063197
APA StyleEvain, A., Mauri, A., Garnier, F., Kounouho, M., Khemmar, R., Haddad, M., Boutteau, R., Breteche, S., & Ahmedali, S. (2023). Improving the Efficiency of 3D Monocular Object Detection and Tracking for Road and Railway Smart Mobility. Sensors, 23(6), 3197. https://doi.org/10.3390/s23063197