
Optimized EWT-Seq2Seq-LSTM with Attention Mechanism to Insulators Fault Prediction

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
- The use of two separate experiments (measuring the leakage current rise of contaminated high-voltage power grid insulators) for Seq2Seq evaluation enhances the generalizability of the analysis. This contribution addresses the need for robustness in forecasting models, as it ensures that the model can generalize well to unseen data.
- Model optimization using Optuna improves the selection of appropriate hyperparameters for the model, and the attention mechanism improves the model’s ability to predict forward values, thereby achieving an optimized structure. This contribution addresses the need for improved accuracy in forecasting models, as it ensures that the model is optimized to perform well on the given dataset.
- The use of empirical wavelet transform reduces signal variations that are not representative and maintains the trend variability, which is the focus of the failure prediction analysis evaluated in this paper. This contribution addresses the need for improved data-preprocessing techniques, as it ensures that the model is trained on meaningful features that capture the underlying patterns in the data.
2. Related Works
Time Series Forecasting Using LSTM with Attention
3. Methodology
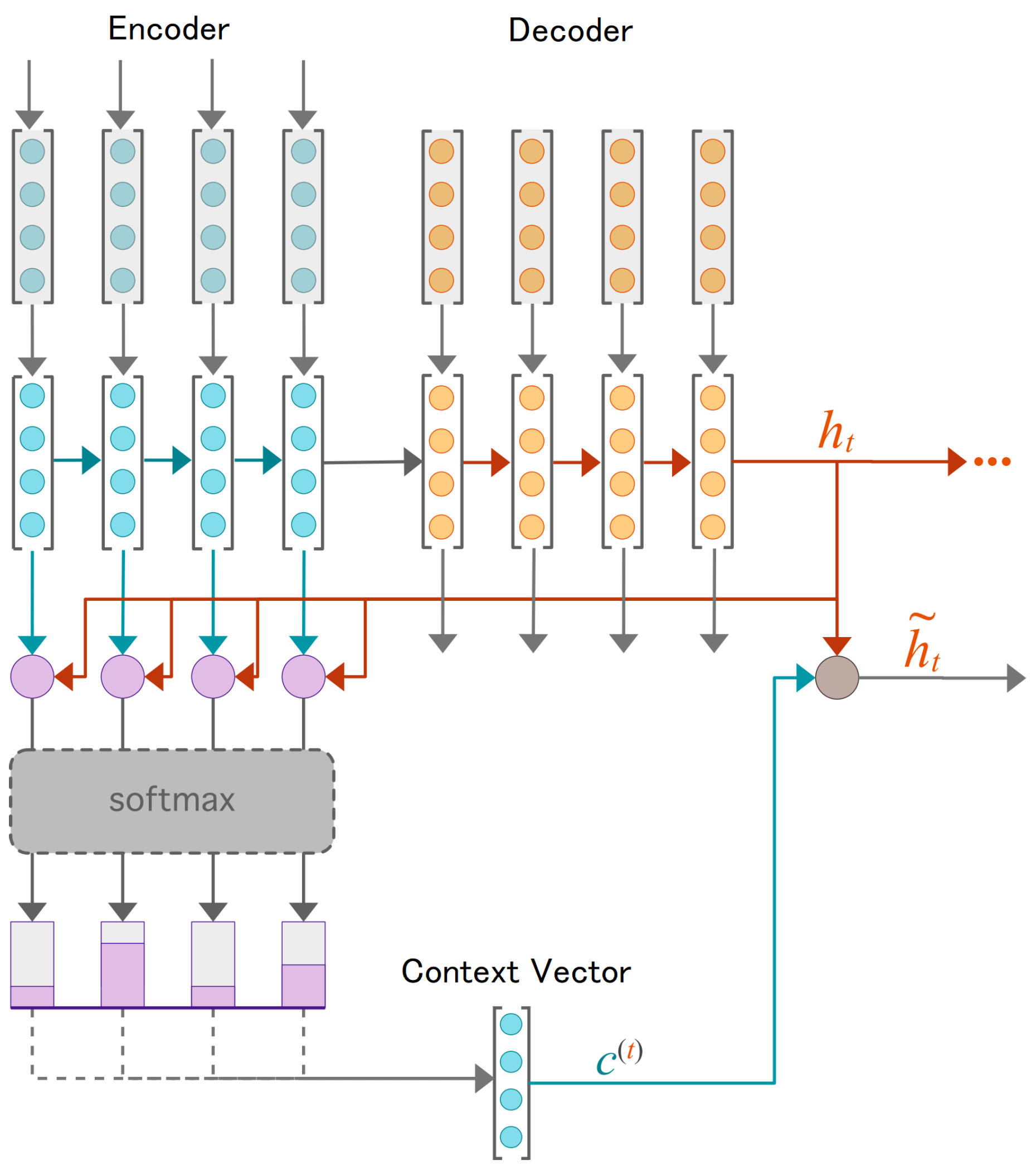
3.1. Luong Attention Mechanism
| Algorithm 1: Luong Attention Mechanism |
 |
3.2. Encoder–Decoder LSTM
3.3. Hypertuning
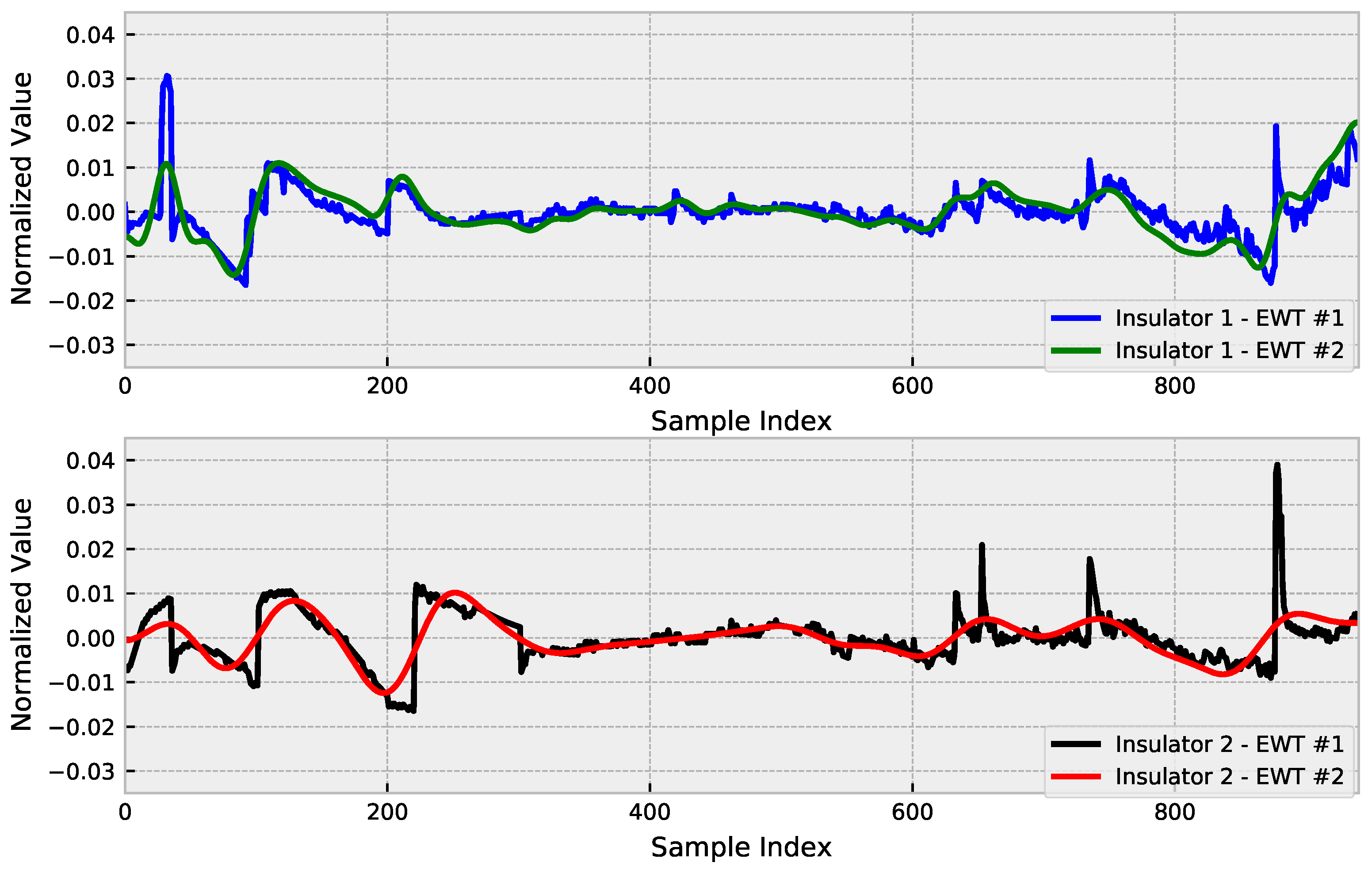
3.4. Empirical Wavelet Transform
4. Experiments and Results
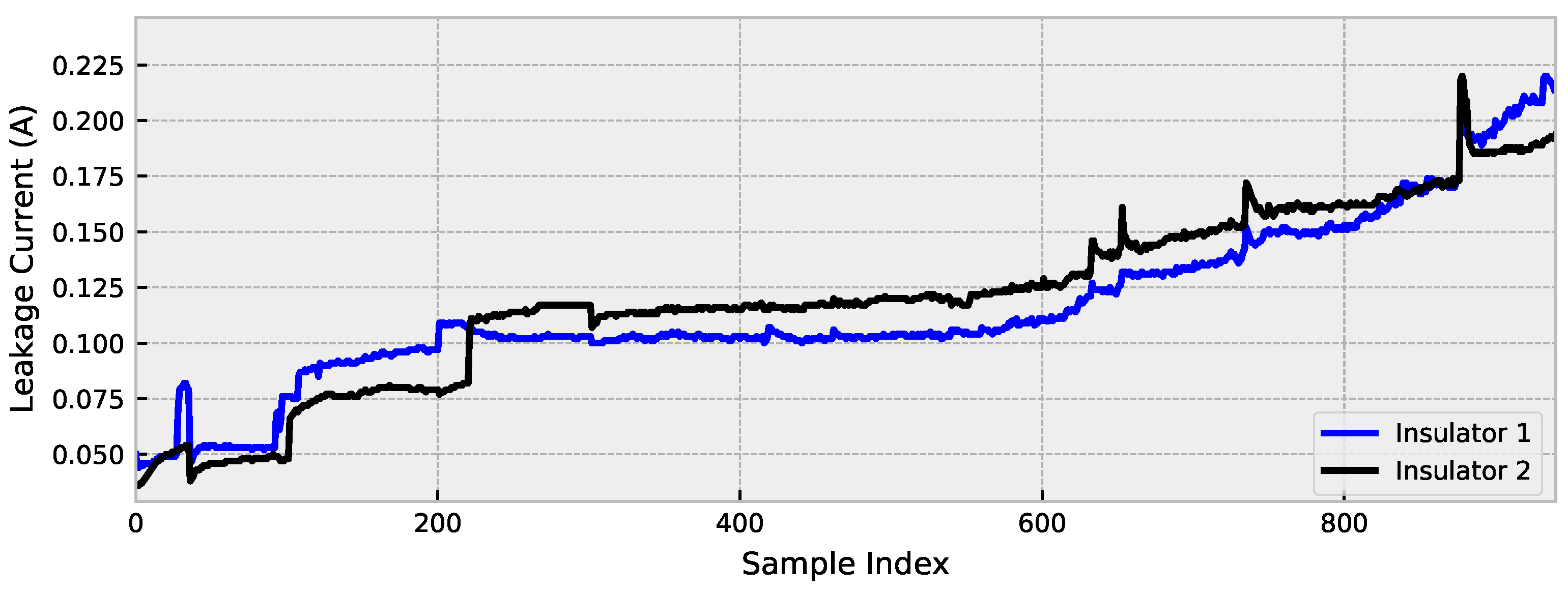
4.1. Dataset
4.2. Experiment Setup
4.3. Data Initialization
4.4. Denoising
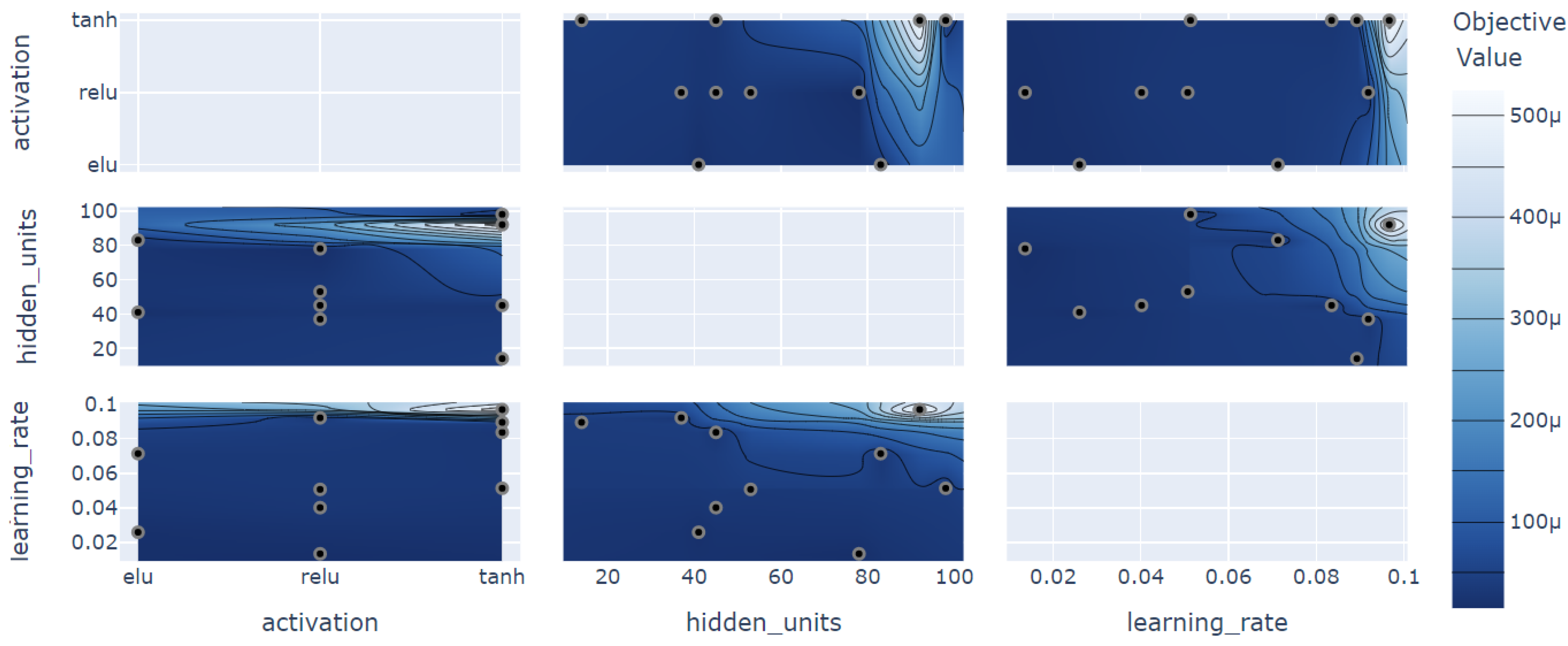
4.5. Hyperparameter Optimization
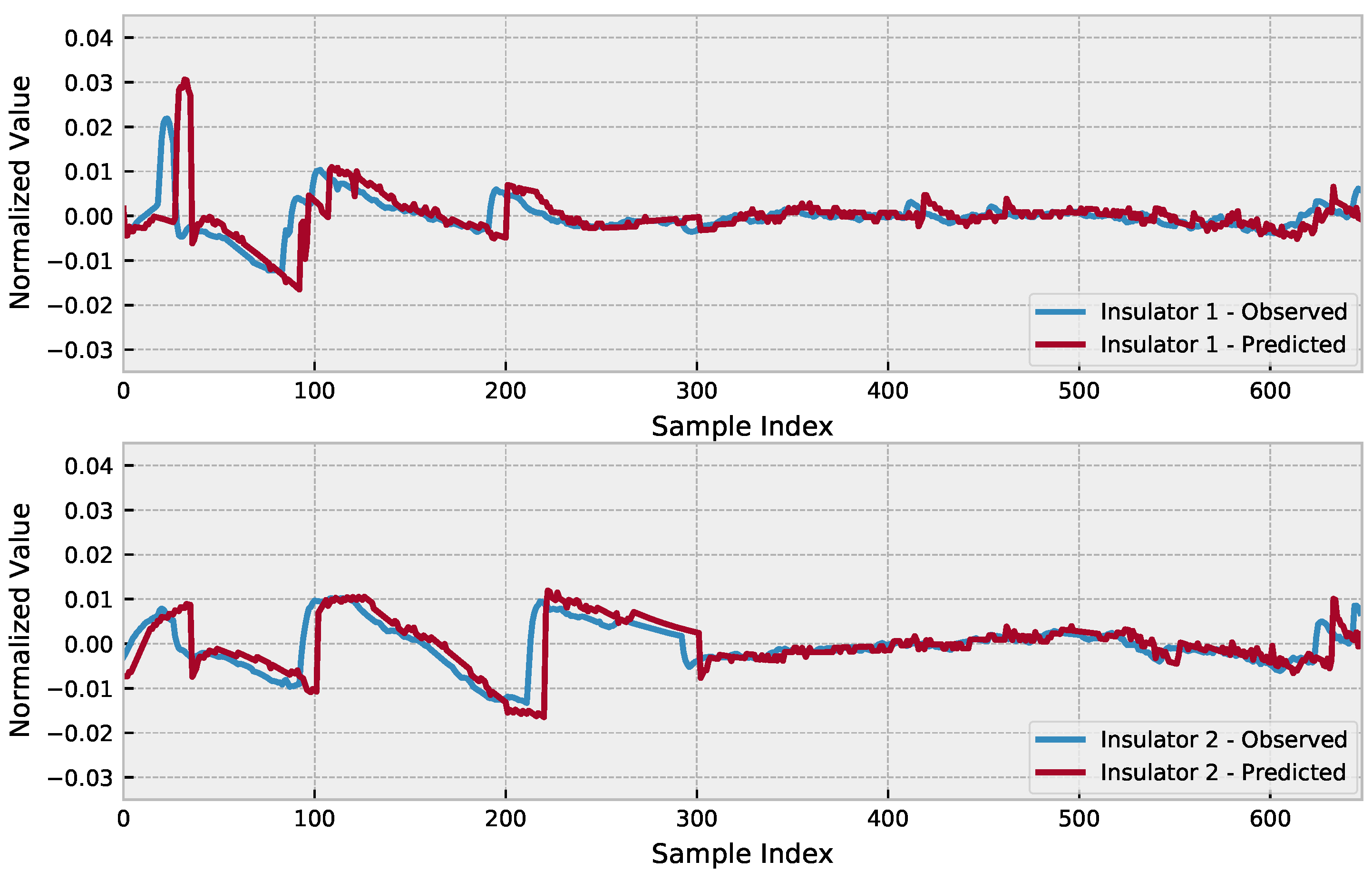
4.6. Benchmarking
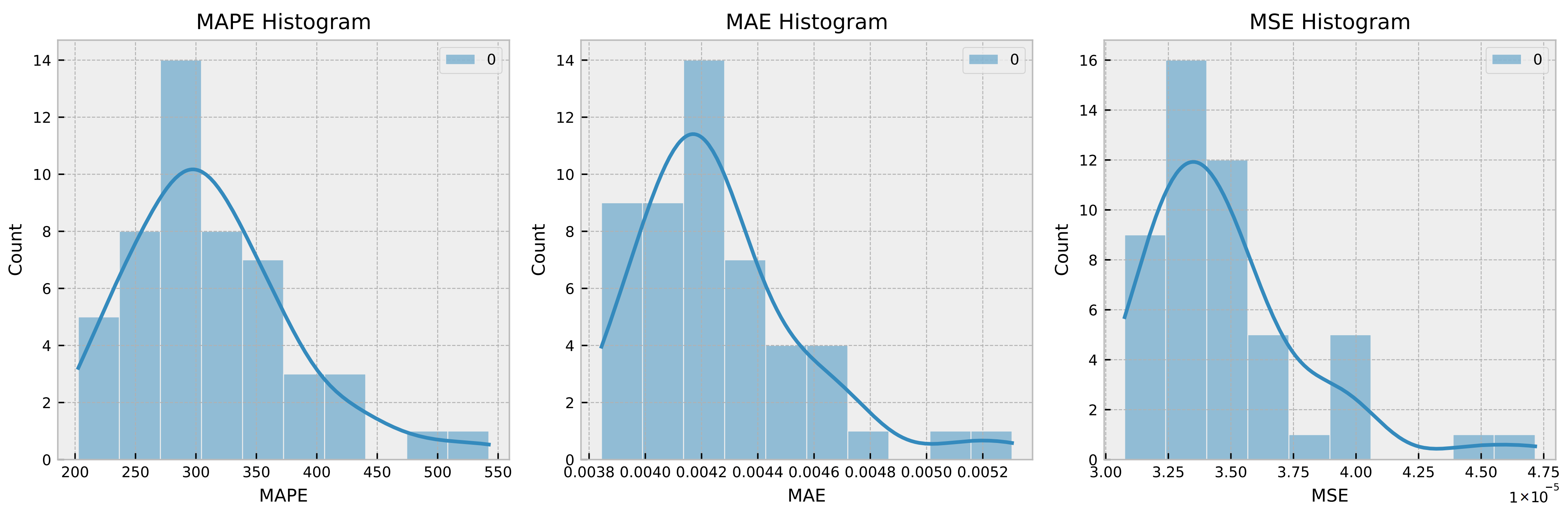
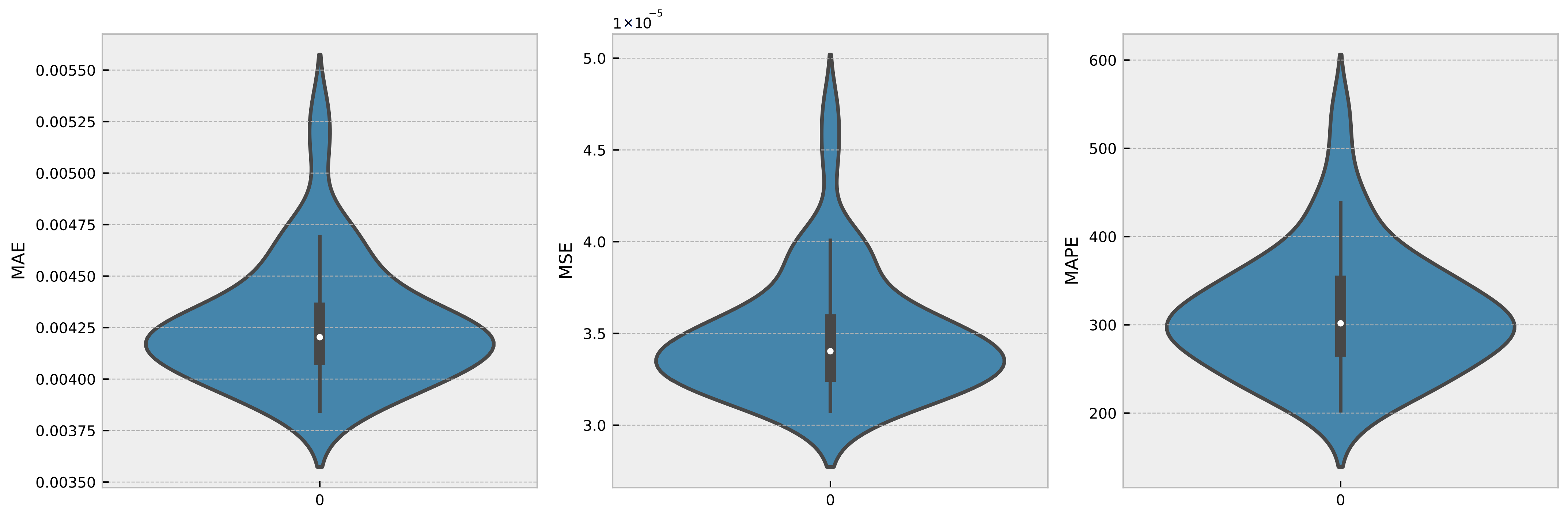
4.7. Statistical Assessment of the Proposed Method
5. Final Remarks and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Branco, N.W.; Cavalca, M.S.M.; Stefenon, S.F.; Leithardt, V.R.Q. Wavelet LSTM for fault forecasting in electrical power grids. Sensors 2022, 22, 8323. [Google Scholar] [CrossRef] [PubMed]
- Souza, B.J.; Stefenon, S.F.; Singh, G.; Freire, R.Z. Hybrid-YOLO for classification of insulators defects in transmission lines based on UAV. Int. J. Electr. Power Energy Syst. 2023, 148, 108982. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Yow, K.C.; Nied, A.; Meyer, L.H. Classification of distribution power grid structures using inception v3 deep neural network. Electr. Eng. 2022, 104, 4557–4569. [Google Scholar] [CrossRef]
- Sopelsa Neto, N.F.; Stefenon, S.F.; Meyer, L.H.; Ovejero, R.G.; Leithardt, V.R.Q. Fault prediction based on leakage current in contaminated insulators using enhanced time series forecasting models. Sensors 2022, 22, 6121. [Google Scholar] [CrossRef] [PubMed]
- Medeiros, A.; Sartori, A.; Stefenon, S.F.; Meyer, L.H.; Nied, A. Comparison of artificial intelligence techniques to failure prediction in contaminated insulators based on leakage current. J. Intell. Fuzzy Syst. 2022, 42, 3285–3298. [Google Scholar] [CrossRef]
- Masood, Z.; Gantassi, R.; Choi, Y. A multi-step time-series clustering-based Seq2Seq LSTM learning for a single household electricity load forecasting. Energies 2022, 15, 2623. [Google Scholar] [CrossRef]
- Zhou, K.; Wang, W.; Hu, T.; Deng, K. Time series forecasting and classification models based on recurrent with attention mechanism and generative adversarial networks. Sensors 2020, 20, 7211. [Google Scholar] [CrossRef] [PubMed]
- He, Y.L.; Chen, L.; Gao, Y.; Ma, J.H.; Xu, Y.; Zhu, Q.X. Novel double-layer bidirectional LSTM network with improved attention mechanism for predicting energy consumption. ISA Trans. 2022, 127, 350–360. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Wang, L.; Xia, D.; Gao, Q. Effective energy consumption forecasting using empirical wavelet transform and long short-term memory. Energy 2022, 238, 121756. [Google Scholar] [CrossRef]
- Peng, T.; Zhou, J.; Zhang, C.; Fu, W. Streamflow forecasting using empirical wavelet transform and artificial neural networks. Water 2017, 9, 406. [Google Scholar] [CrossRef] [Green Version]
- Stefenon, S.F.; Freire, R.Z.; Meyer, L.H.; Corso, M.P.; Sartori, A.; Nied, A.; Klaar, A.C.R.; Yow, K.C. Fault detection in insulators based on ultrasonic signal processing using a hybrid deep learning technique. IET Sci. Meas. Technol. 2020, 14, 953–961. [Google Scholar] [CrossRef]
- Xu, Y.; Cheng, J.; Liu, W.; Gao, W. Evaluation of the UHF method based on the investigation of a partial discharge case in post insulators. IEEE Trans. Dielectr. Electr. Insul. 2017, 24, 3669–3676. [Google Scholar] [CrossRef]
- Zheng, H.; Liu, Y.; Sun, Y.; Li, J.; Shi, Z.; Zhang, C.; Lai, C.S.; Lai, L.L. Arbitrary-oriented detection of insulators in thermal imagery via rotation region network. IEEE Trans. Ind. Inform. 2022, 18, 5242–5252. [Google Scholar] [CrossRef]
- Polisetty, S.; El-Hag, A.; Jayram, S. Classification of common discharges in outdoor insulation using acoustic signals and artificial neural network. High Volt. 2019, 4, 333–338. [Google Scholar] [CrossRef]
- Yeh, C.T.; Thanh, P.N.; Cho, M.Y. Real-time leakage current classification of 15kV and 25kV distribution insulators based on bidirectional long short-term memory networks with deep learning machine. IEEE Access 2022, 10, 7128–7140. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Singh, G.; Yow, K.C.; Cimatti, A. Semi-ProtoPNet deep neural network for the classification of defective power grid distribution structures. Sensors 2022, 22, 4859. [Google Scholar] [CrossRef]
- Villalobos, R.J.; Moran, L.A.; Huenupán, F.; Vallejos, F.; Moncada, R.; Pesce, G.C. A new current transducer for on-line monitoring of leakage current on HV insulator strings. IEEE Access 2022, 10, 78818–78826. [Google Scholar] [CrossRef]
- Araya, J.; Montaña, J.; Schurch, R. Electric field distribution and leakage currents in glass insulator under different altitudes and pollutions conditions using FEM simulations. IEEE Lat. Am. Trans. 2021, 19, 1278–1285. [Google Scholar] [CrossRef]
- Salem, A.A.; Abd-Rahman, R.; Al-Gailani, S.A.; Salam, Z.; Kamarudin, M.S.; Zainuddin, H.; Yousof, M.F.M. Risk assessment of polluted glass insulator using leakage current index under different operating conditions. IEEE Access 2020, 8, 175827–175839. [Google Scholar] [CrossRef]
- Park, J.; Hwang, E. A two-stage multistep-ahead electricity load forecasting scheme based on LightGBM and attention-BiLSTM. Sensors 2021, 21, 7697. [Google Scholar] [CrossRef]
- Park, S.H.; Lee, B.Y.; Kim, M.J.; Sang, W.; Seo, M.C.; Baek, J.K.; Yang, J.E.; Mo, C. Development of a soil moisture prediction model based on recurrent neural network long short-term memory (RNN-LSTM) in soybean cultivation. Sensors 2023, 23, 1976. [Google Scholar] [CrossRef]
- Hasan, F.; Huang, H. MALS-Net: A multi-head attention-based LSTM sequence-to-sequence network for socio-temporal interaction modelling and trajectory prediction. Sensors 2023, 23, 530. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, F.; Stefenon, S.F.; Seman, L.O.; Nied, A.; Ferreira, F.C.S.; Subtil, M.C.M.; Klaar, A.C.R.; Leithardt, V.R.Q. Long short-term memory stacking model to predict the number of cases and deaths caused by COVID-19. J. Intell. Fuzzy Syst. 2022, 6, 6221–6234. [Google Scholar] [CrossRef]
- Jiang, J.R.; Lee, J.E.; Zeng, Y.M. Time series multiple channel convolutional neural network with attention-based long short-term memory for predicting bearing remaining useful life. Sensors 2020, 20, 166. [Google Scholar] [CrossRef] [Green Version]
- Zang, H.; Xu, R.; Cheng, L.; Ding, T.; Liu, L.; Wei, Z.; Sun, G. Residential load forecasting based on LSTM fusing self-attention mechanism with pooling. Energy 2021, 229, 120682. [Google Scholar] [CrossRef]
- Qu, J.; Qian, Z.; Pei, Y. Day-ahead hourly photovoltaic power forecasting using attention-based CNN-LSTM neural network embedded with multiple relevant and target variables prediction pattern. Energy 2021, 232, 120996. [Google Scholar] [CrossRef]
- Fazlipour, Z.; Mashhour, E.; Joorabian, M. A deep model for short-term load forecasting applying a stacked autoencoder based on LSTM supported by a multi-stage attention mechanism. Appl. Energy 2022, 327, 120063. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J.; Cui, Y. Short-term load forecasting based on LSTM networks considering attention mechanism. Int. J. Electr. Power Energy Syst. 2022, 137, 107818. [Google Scholar] [CrossRef]
- Zhu, K.; Li, Y.; Mao, W.; Li, F.; Yan, J. LSTM enhanced by dual-attention-based encoder-decoder for daily peak load forecasting. Electr. Power Syst. Res. 2022, 208, 107860. [Google Scholar] [CrossRef]
- Li, Y.; Tong, Z.; Tong, S.; Westerdahl, D. A data-driven interval forecasting model for building energy prediction using attention-based LSTM and fuzzy information granulation. Sustain. Cities Soc. 2022, 76, 103481. [Google Scholar] [CrossRef]
- Meng, A.; Wang, P.; Zhai, G.; Zeng, C.; Chen, S.; Yang, X.; Yin, H. Electricity price forecasting with high penetration of renewable energy using attention-based LSTM network trained by crisscross optimization. Energy 2022, 254, 124212. [Google Scholar] [CrossRef]
- Qin, J.; Zhang, Y.; Fan, S.; Hu, X.; Huang, Y.; Lu, Z.; Liu, Y. Multi-task short-term reactive and active load forecasting method based on attention-LSTM model. Int. J. Electr. Power Energy Syst. 2022, 135, 107517. [Google Scholar] [CrossRef]
- Dai, Y.; Zhou, Q.; Leng, M.; Yang, X.; Wang, Y. Improving the Bi-LSTM model with XGBoost and attention mechanism: A combined approach for short-term power load prediction. Appl. Soft Comput. 2022, 130, 109632. [Google Scholar] [CrossRef]
- Xia, M.; Shao, H.; Ma, X.; de Silva, C.W. A stacked GRU-RNN-based approach for predicting renewable energy and electricity load for smart grid operation. IEEE Trans. Ind. Inform. 2021, 17, 7050–7059. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Dal Molin Ribeiro, M.H.; Nied, A.; Mariani, V.C.; dos Santos Coelho, L.; Menegat da Rocha, D.F.; Grebogi, R.B.; de Barros Ruano, A.E. Wavelet group method of data handling for fault prediction in electrical power insulators. Int. J. Electr. Power Energy Syst. 2020, 123, 106269. [Google Scholar] [CrossRef]
- Belagoune, S.; Bali, N.; Bakdi, A.; Baadji, B.; Atif, K. Deep learning through LSTM classification and regression for transmission line fault detection, diagnosis and location in large-scale multi-machine power systems. Measurement 2021, 177, 109330. [Google Scholar] [CrossRef]
- Thomas, J.B.; Shihabudheen, K.V. Neural architecture search algorithm to optimize deep transformer model for fault detection in electrical power distribution systems. Eng. Appl. Artif. Intell. 2023, 120, 105890. [Google Scholar] [CrossRef]
- Dashti, R.; Daisy, M.; Mirshekali, H.; Shaker, H.R.; Hosseini Aliabadi, M. A survey of fault prediction and location methods in electrical energy distribution networks. Measurement 2021, 184, 109947. [Google Scholar] [CrossRef]
- Vaish, R.; Dwivedi, U.; Tewari, S.; Tripathi, S. Machine learning applications in power system fault diagnosis: Research advancements and perspectives. Eng. Appl. Artif. Intell. 2021, 106, 104504. [Google Scholar] [CrossRef]
- Li, F.; Gui, Z.; Zhang, Z.; Peng, D.; Tian, S.; Yuan, K.; Sun, Y.; Wu, H.; Gong, J.; Lei, Y. A hierarchical temporal attention-based LSTM encoder-decoder model for individual mobility prediction. Neurocomputing 2020, 403, 153–166. [Google Scholar] [CrossRef]
- Cao, M.; Yao, R.; Xia, J.; Jia, K.; Wang, H. LSTM attention neural-network-based signal detection for hybrid modulated Faster-Than-Nyquist optical wireless communications. Sensors 2022, 22, 8992. [Google Scholar] [CrossRef]
- Shi, B.; Jiang, Y.; Bao, Y.; Chen, B.; Yang, K.; Chen, X. Weigh-in-motion system based on an improved kalman and LSTM-attention algorithm. Sensors 2023, 23, 250. [Google Scholar] [CrossRef]
- Sehovac, L.; Grolinger, K. Deep learning for load forecasting: Sequence to sequence recurrent neural networks with attention. IEEE Access 2020, 8, 36411–36426. [Google Scholar] [CrossRef]
- Nadeem, A.; Naveed, M.; Islam Satti, M.; Afzal, H.; Ahmad, T.; Kim, K.I. Depression detection based on hybrid deep learning SSCL framework using self-attention mechanism: An application to social networking data. Sensors 2022, 22, 9775. [Google Scholar] [CrossRef] [PubMed]
- Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.d.S. Aggregating prophet and seasonal trend decomposition for time series forecasting of Italian electricity spot prices. Energies 2023, 16, 1371. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, L.; Li, N.; Tian, J. Time series forecasting of motor bearing vibration based on informer. Sensors 2022, 22, 5858. [Google Scholar] [CrossRef]
- Wei, Y.; Liu, H. Convolutional long-short term memory network with multi-head attention mechanism for traffic flow prediction. Sensors 2022, 22, 7994. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Du, L.; Gao, R.; Suganthan, P.N.; Wang, D.Z. Bayesian optimization based dynamic ensemble for time series forecasting. Inf. Sci. 2022, 591, 155–175. [Google Scholar] [CrossRef]
- Nguyen, H.P.; Liu, J.; Zio, E. A long-term prediction approach based on long short-term memory neural networks with automatic parameter optimization by Tree-structured Parzen Estimator and applied to time-series data of NPP steam generators. Appl. Soft Comput. 2020, 89, 106116. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Chen, Z.; Li, X.; Yi, X.; Zhao, Y.; He, X.; Huang, Z.; Hassaan, M.A.; El Nemr, A.; Huang, M. Water quality soft-sensor prediction in anaerobic process using deep neural network optimized by Tree-structured Parzen Estimator. Front. Environ. Sci. Eng. 2023, 17, 67. [Google Scholar] [CrossRef]
- Rong, G.; Li, K.; Su, Y.; Tong, Z.; Liu, X.; Zhang, J.; Zhang, Y.; Li, T. Comparison of tree-structured parzen estimator optimization in three typical neural network models for landslide susceptibility assessment. Remote Sens. 2021, 13, 4694. [Google Scholar] [CrossRef]
- Gilles, J. Empirical wavelet transform. IEEE Trans. Signal Process. 2013, 61, 3999–4010. [Google Scholar] [CrossRef]
- Carvalho, V.R.; Moraes, M.F.; Braga, A.P.; Mendes, E.M. Evaluating five different adaptive decomposition methods for EEG signal seizure detection and classification. Biomed. Signal Process. Control 2020, 62, 102073. [Google Scholar] [CrossRef]
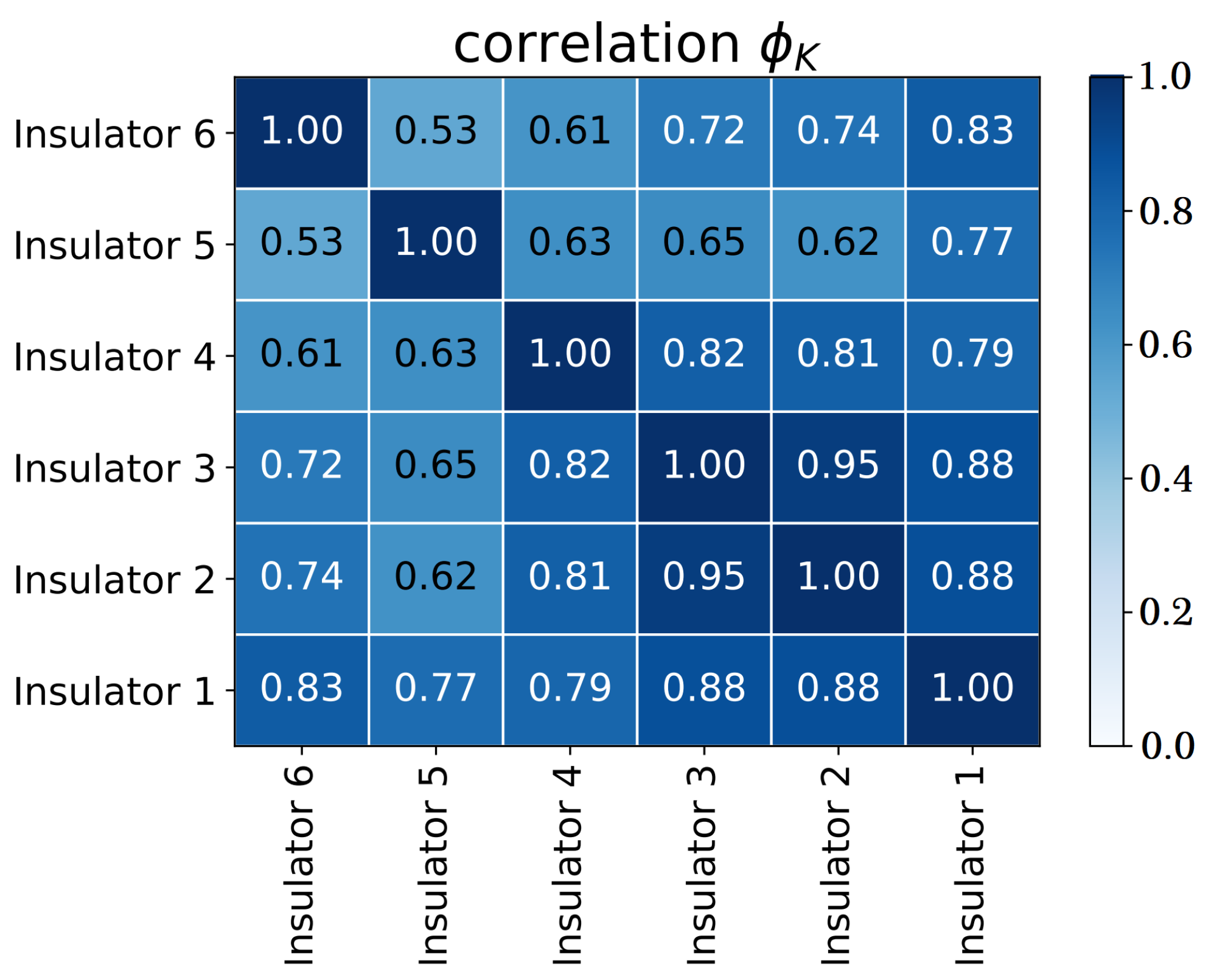
- Baak, M.; Koopman, R.; Snoek, H.; Klous, S. A new correlation coefficient between categorical, ordinal and interval variables with Pearson characteristics. arXiv 2018. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Methodology |
|---|---|
| Zang et al. [25] | LSTM with a self-attention mechanism for day-ahead residential load forecasting. |
| Qu et al. [26] | Attention-based LSTM model for short-term prediction. |
| Fazlipour et al. [27] | LSTM-based stackable autoencoder with attention mechanism for short-term load forecasting. |
| Lin et al. [28] | Dual-attention LSTM model for short-term load forecasting with probabilistic predictions. |
| Zhu et al. [29] | Dual-attention LSTM model for analyzing characteristics of daily peak load simultaneously. |
| Li et al. [30] | Deep learning-based interval prediction model combining attention mechanism and LSTM. |
| Meng et al. [31] | Attention mechanism for LSTM forecasting model with empirical wavelet transform % for electricity price prediction. |
| Qin et al. [32] | Multi-task LSTM model with attention mechanism for predicting loads of a substation. |
| Dai et al. [33] | Combined LSTM with attention mechanism and XGBoost for short-term load forecasting. |
| Insul. 1 | Insul. 2 | Insul. 3 | Insul. 4 | Insul. 5 | Insul. 6 | |
|---|---|---|---|---|---|---|
| Mean | 0.08947 | 0.11890 | 0.12323 | 0.06242 | 0.02737 | 0.04913 |
| Median | 0.13200 | 0.10400 | 0.11800 | 0.09500 | 0.03800 | 0.05000 |
| Mode | 0.00000 | 0.10300 | 0.11700 | 0.00000 | 0.00000 | 0.00000 |
| Range | 0.26400 | 0.22700 | 0.26600 | 0.19300 | 0.17100 | 0.75500 |
| Variance | 0.00594 | 0.00173 | 0.00186 | 0.00216 | 0.00058 | 0.00261 |
| Std. Dev. | 0.07710 | 0.04156 | 0.04309 | 0.04643 | 0.02403 | 0.05113 |
| 25th %ile | 0.00000 | 0.10200 | 0.11200 | 0.00000 | 0.00000 | 0.00000 |
| 50th %ile | 0.13200 | 0.10400 | 0.11800 | 0.09500 | 0.03800 | 0.05000 |
| 75th %ile | 0.13800 | 0.13800 | 0.15300 | 0.10100 | 0.04200 | 0.09000 |
| IQR | 0.13800 | 0.03600 | 0.04100 | 0.10100 | 0.04200 | 0.09000 |
| Skewness | 0.20900 | 0.88310 | 0.17629 | −0.31889 | 0.25156 | 2.92524 |
| Kurtosis | −1.05212 | 0.84858 | 0.36154 | −1.45492 | 0.20065 | 36.47633 |
| Train/Test (%) | Batch Size | MSE | MAE | MAPE | Time (s) |
|---|---|---|---|---|---|
| 70/30 | 8 | 1117.92 | |||
| 16 | 1.50 × | 330.82 | |||
| 32 | 148.29 | ||||
| 64 | 90.23 | ||||
| 80/20 | 8 | 628.88 | |||
| 16 | 281.13 | ||||
| 32 | 208.49 | ||||
| 64 | 60.34 | ||||
| 90/10 | 8 | 679.75 | |||
| 16 | 352.54 | ||||
| 32 | 1.17 × | 2.16 × | 2.44 × | 208.50 | |
| 64 | 148.19 |
| Model | MSE | MAE | MAPE | Time (s) |
|---|---|---|---|---|
| EWT-Seq2Seq-LSTM Standard | 1.18 × | 239.89 | ||
| EWT-Seq2Seq-LSTM with Attention | 328.68 | |||
| Proposed Method | 1.06× | 2.08 × | 2.11× | 277.59 |
| Solver | Function | MSE | MAE | MAPE | Time (s) |
|---|---|---|---|---|---|
| L1QP | Linear | 1.50 | 2.99 | 1.67 | 3.59 |
| RBF | 1.69 | ||||
| Polynomial | 1.67 | ||||
| ISDA | Linear | 1.48 | 2.98 | 1.66 | 1.38 |
| RBF | 0.53 | ||||
| Polynomial | 18.45 | ||||
| SMO | Linear | 1.45 | 2.94 | 1.65 | 0.92 |
| RBF | 0.47 | ||||
| Polynomial | 32.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klaar, A.C.R.; Stefenon, S.F.; Seman, L.O.; Mariani, V.C.; Coelho, L.d.S. Optimized EWT-Seq2Seq-LSTM with Attention Mechanism to Insulators Fault Prediction. Sensors 2023, 23, 3202. https://doi.org/10.3390/s23063202
Klaar ACR, Stefenon SF, Seman LO, Mariani VC, Coelho LdS. Optimized EWT-Seq2Seq-LSTM with Attention Mechanism to Insulators Fault Prediction. Sensors. 2023; 23(6):3202. https://doi.org/10.3390/s23063202
Chicago/Turabian StyleKlaar, Anne Carolina Rodrigues, Stefano Frizzo Stefenon, Laio Oriel Seman, Viviana Cocco Mariani, and Leandro dos Santos Coelho. 2023. "Optimized EWT-Seq2Seq-LSTM with Attention Mechanism to Insulators Fault Prediction" Sensors 23, no. 6: 3202. https://doi.org/10.3390/s23063202
APA StyleKlaar, A. C. R., Stefenon, S. F., Seman, L. O., Mariani, V. C., & Coelho, L. d. S. (2023). Optimized EWT-Seq2Seq-LSTM with Attention Mechanism to Insulators Fault Prediction. Sensors, 23(6), 3202. https://doi.org/10.3390/s23063202