
Real-Time Fire Smoke Detection Method Combining a Self-Attention Mechanism and Radial Multi-Scale Feature Connection


Abstract
:1. Introduction
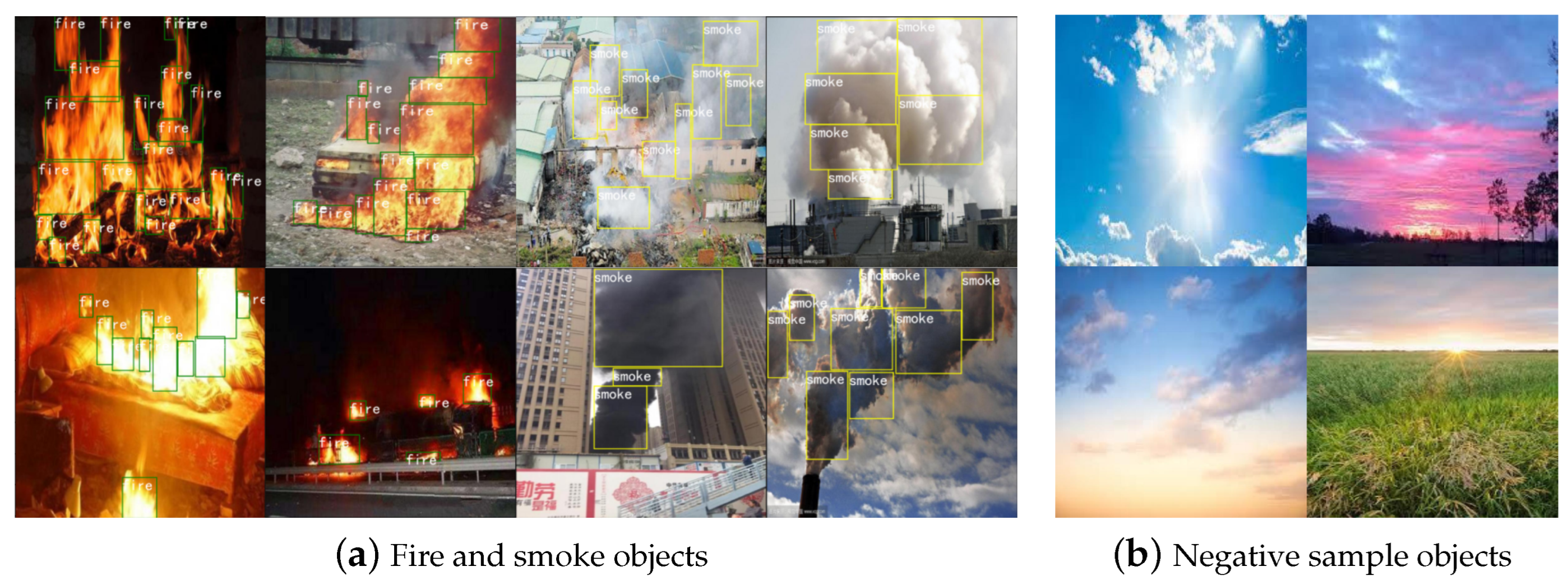
- We constructed a dataset containing hundreds of real-life scenarios featuring fire smoke. To mitigate the impact of environmental factors, we also included negative samples, such as sun, clouds, smoke, and lighting, among others.
- We propose improved structures and strategies specifically designed for detecting fire smoke characteristics. Our improved structures include CDPB, RC FPN-PAN, and PSA, which aim to enhance the model’s feature extraction capabilities. In addition, we have developed a cross-grid matching strategy and a weighted decay loss function to address the unbalanced matching of positive and negative samples that often causes problematic convergence of the loss function.
- We conducted sufficient experiments to verify a number of possibilities that could affect the results of fire smoke detection.
2. Related Works
2.1. Multi-Scale Feature
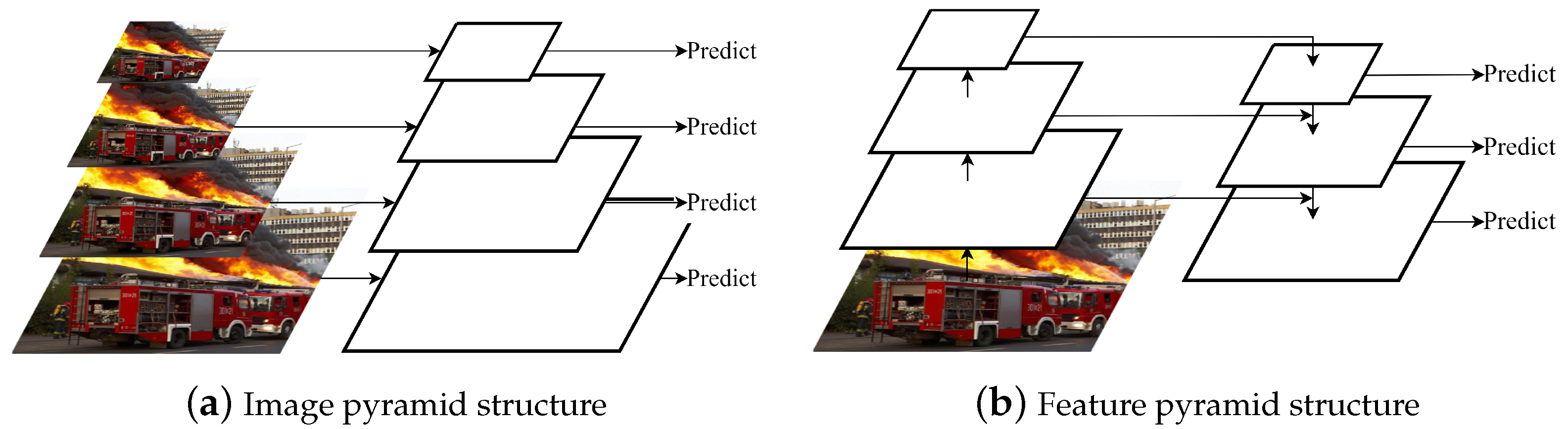
2.1.1. Image Pyramid Structure
2.1.2. Feature Pyramid Structure
2.2. Attention Mechanisms
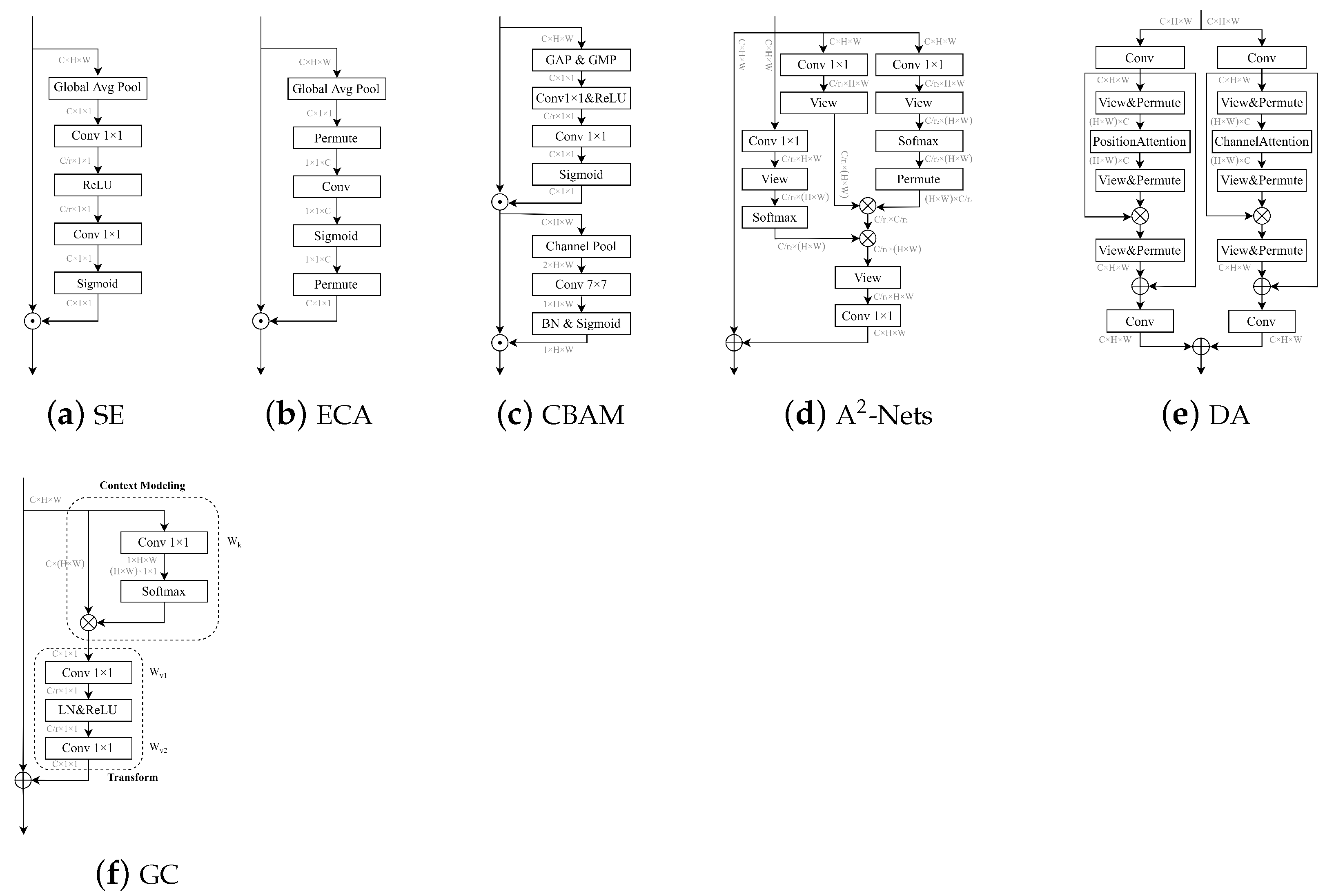
2.2.1. Channel Attention
2.2.2. Spatial Attention
2.2.3. Self-Attention
3. The Proposed Method
3.1. Overview
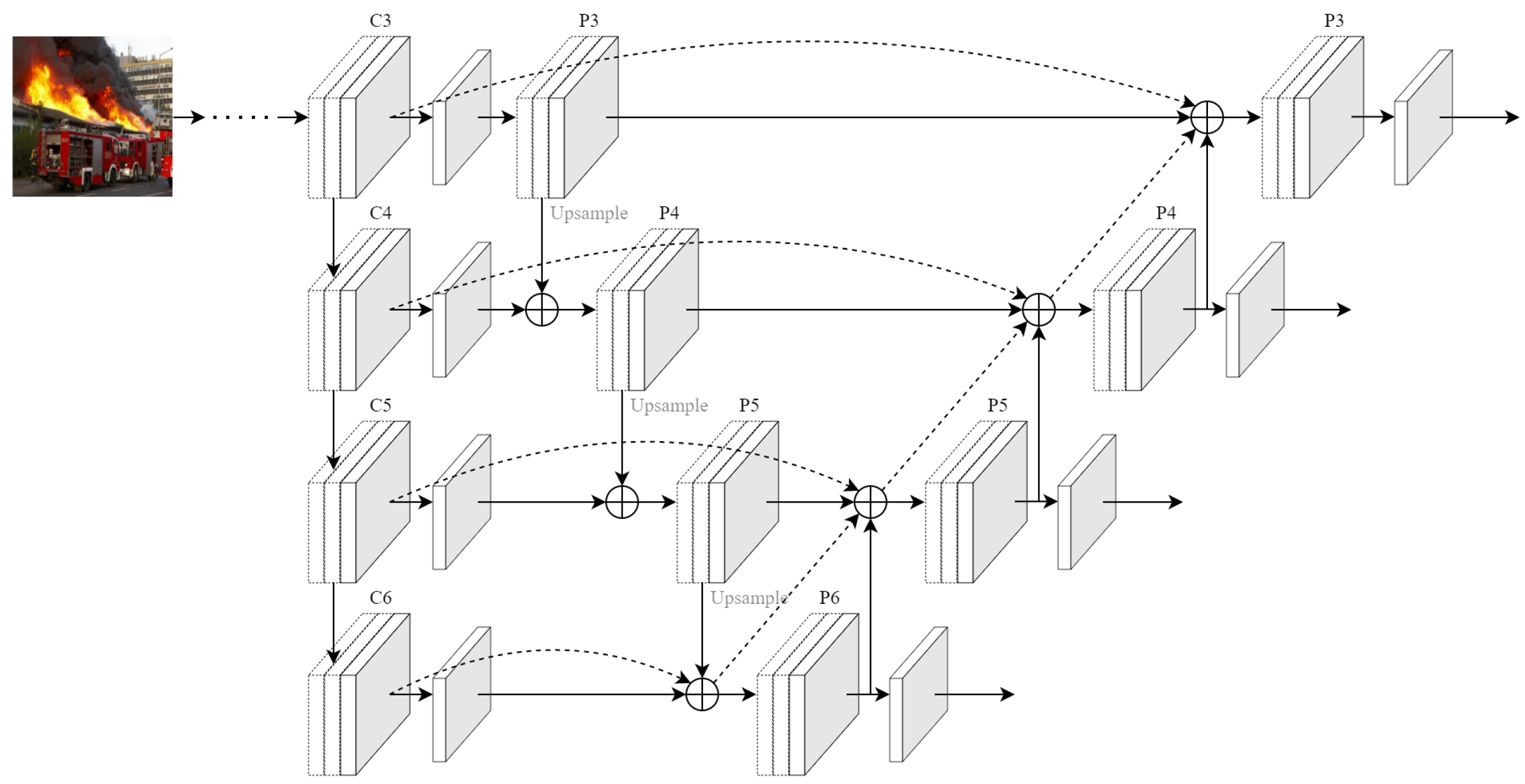
3.2. FPN-PAN Structure with Radial Connection
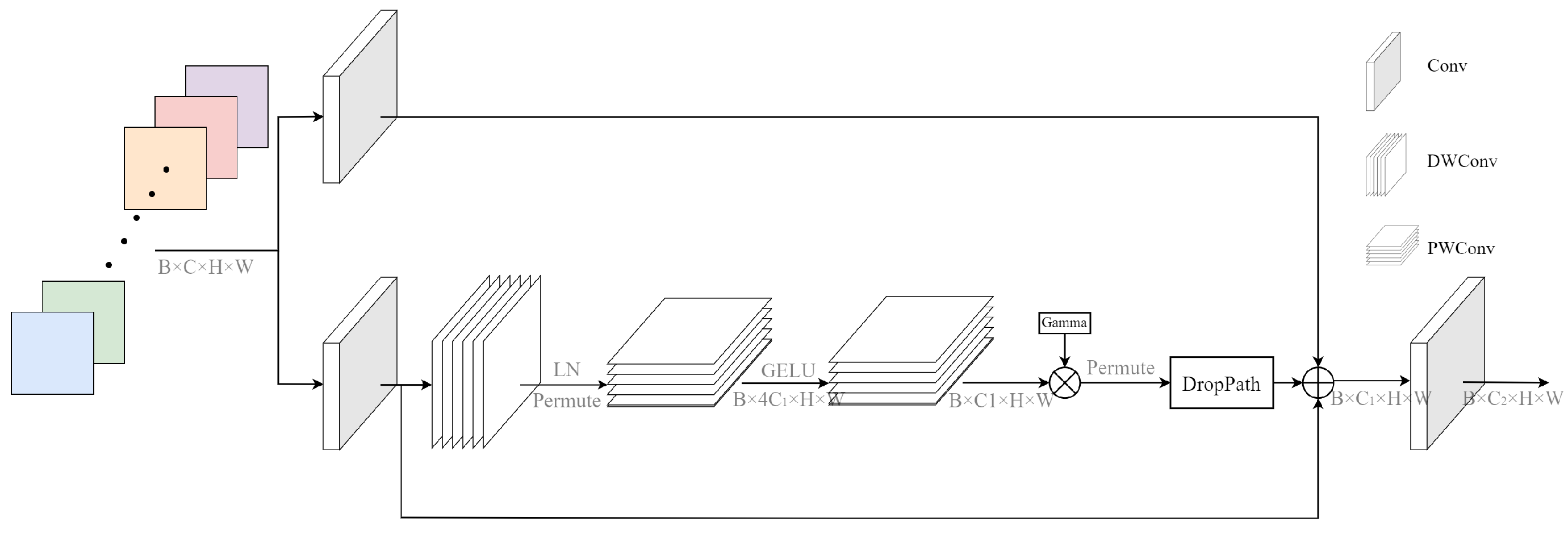
3.3. CDPB Structure
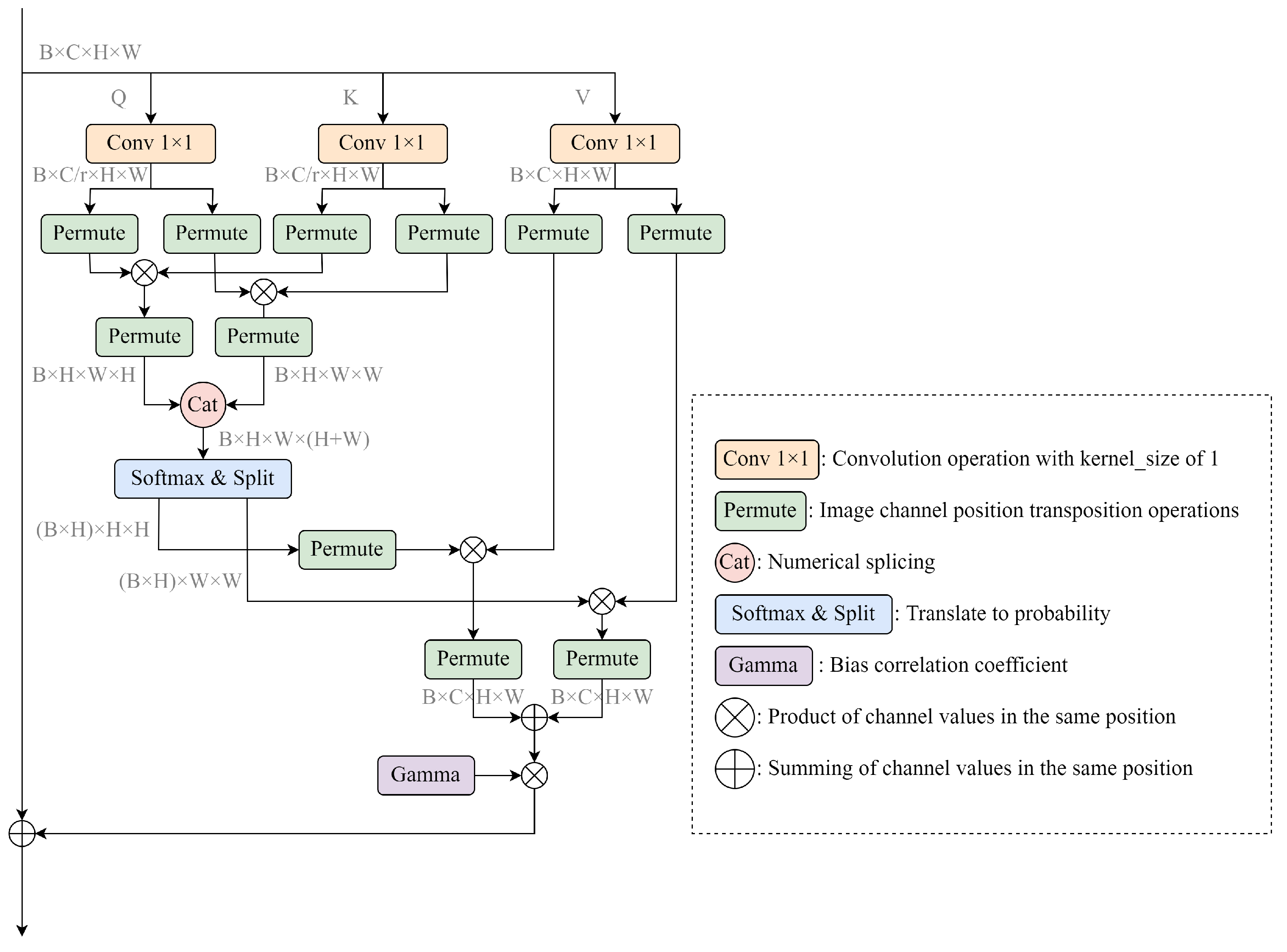
3.4. Permutation Self-Attention
3.5. Matching Strategies and Loss Functions
3.5.1. Dynamic Matching Strategies across Grids
3.5.2. Weighted Decay Loss Function for Object Detection
4. Experiments
4.1. Experimental Environment
4.2. Experimental Data and Preprocessing
4.3. Parameter Settings
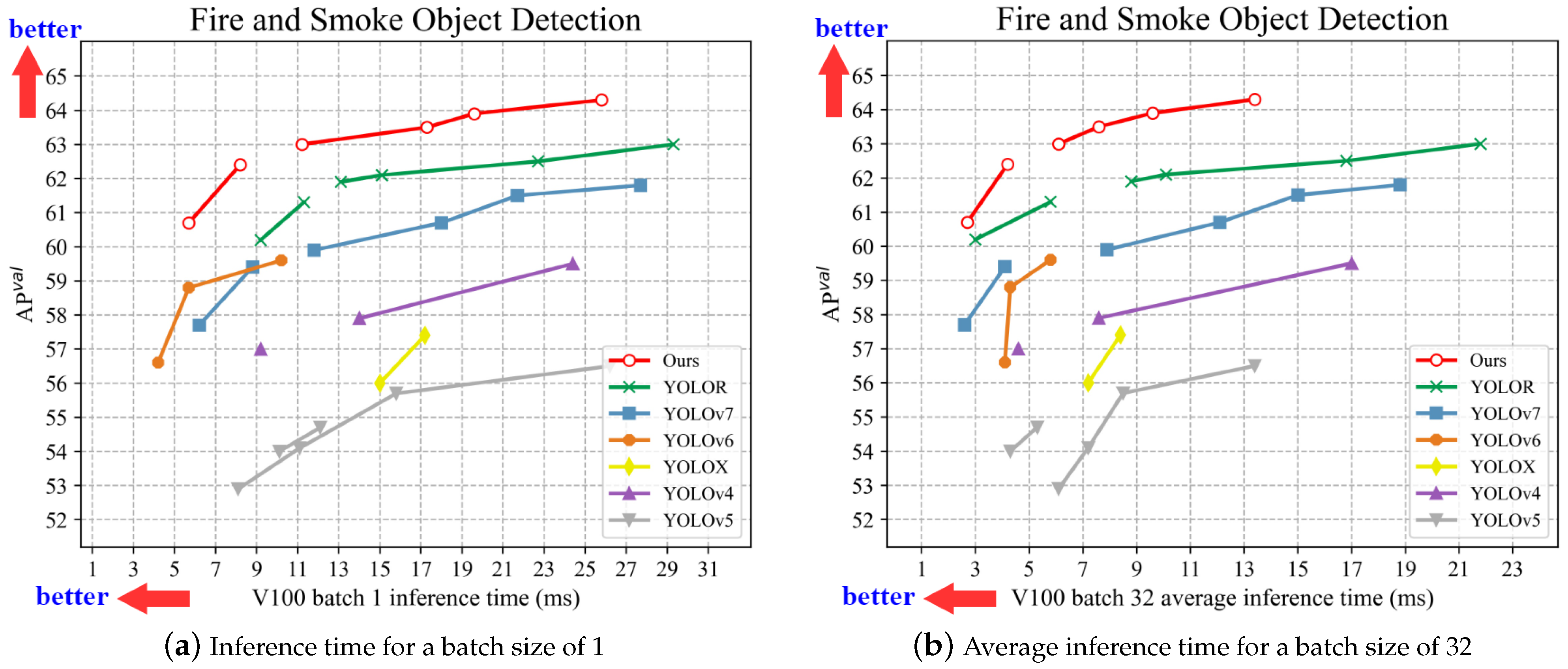
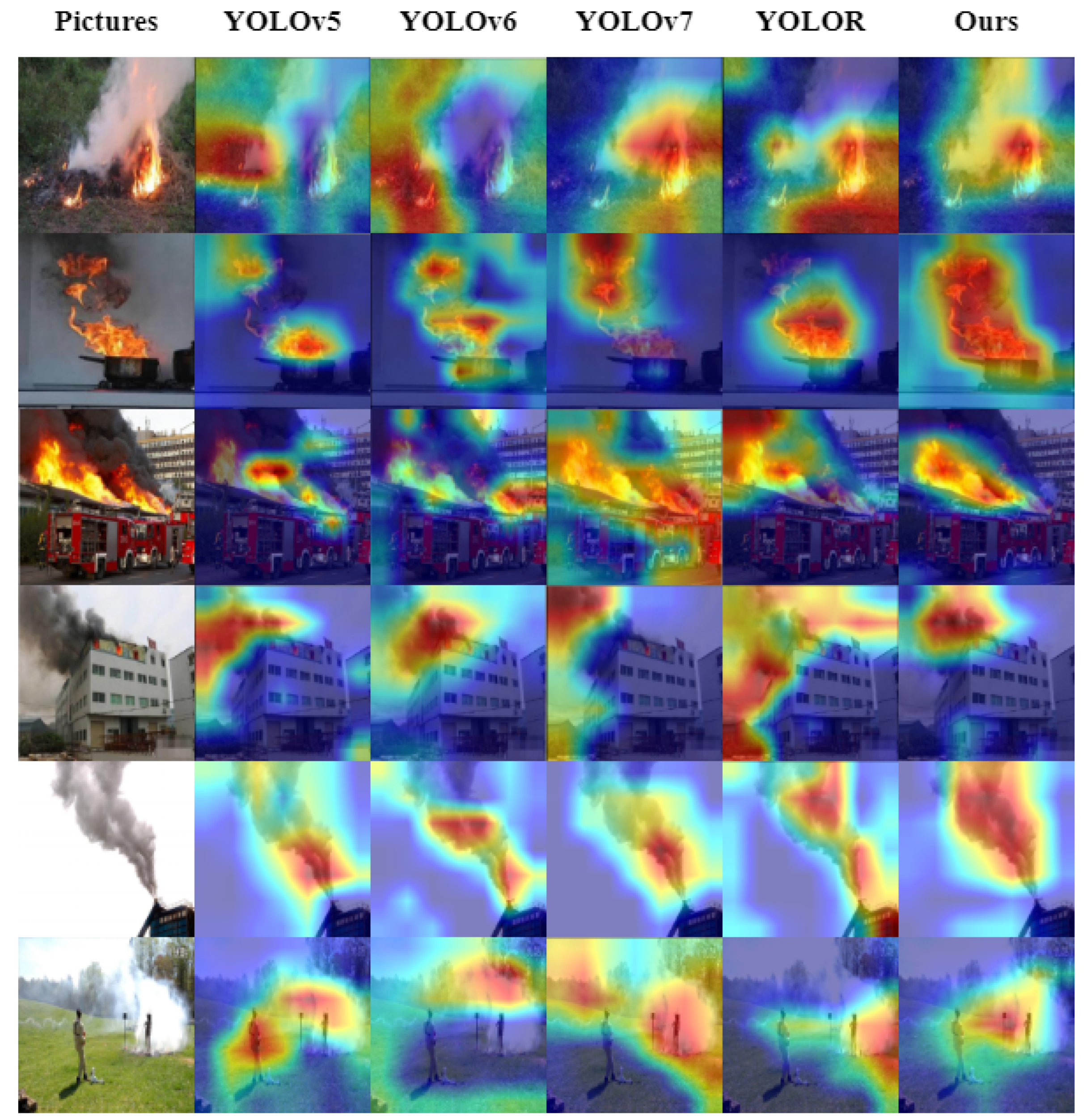
4.4. Experimental Results and Analysis
4.5. Ablation Study
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chi, R.; Lu, Z.M.; Ji, Q.G. Real-time multi-feature based fire flame detection in video. IET Image Process. 2017, 11, 31–37. [Google Scholar] [CrossRef]
- Cetin, A.E.; Dimitropoulos, K.; Gouverneur, B.; Grammalidis, N.; Günay, O.; Habiboǧlu, Y.H.; Töreyin, B.U.; Verstockt, S. Video fire detection–review. Digit. Signal Process. 2013, 23, 1827–1843. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Sun, L.; Huang, Y. Forest fire smoke recognition based on convolutional neural network. J. For. Res. 2021, 32, 1921–1927. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. Lect. Notes Comput. Sci. 2006, 3951, 404–417. [Google Scholar]
- Chiew, K.; Wang, Y. Shape feature representation in partial object matching. In Proceedings of the 2006 International Conference on Computing & Informatics, Vilnius, Lithuania, 7–11 November 2006; pp. 1–6. [Google Scholar]
- Chunyu, Y.; Jun, F.; Jinjun, W.; Yongming, Z. Video fire smoke detection using motion and color features. Fire Technol. 2010, 46, 651–663. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, J. Automatic fire smoke detection based on image visual features. In Proceedings of the 2007 International Conference on Computational Intelligence and Security Workshops (CISW 2007), Harbin, China, 15–19 December 2007; pp. 316–319. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Shape context: A new descriptor for shape matching and object recognition. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 7 November–2 December 2000; Volume 13. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferrari, R.J.; Zhang, H.; Kube, C.R. Real-time detection of steam in video images. Pattern Recognit. 2007, 40, 1148–1159. [Google Scholar] [CrossRef]
- Calderara, S.; Piccinini, P.; Cucchiara, R. Vision based smoke detection system using image energy and color information. Mach. Vis. Appl. 2011, 22, 705–719. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.H.; Huang, J.; Han, S.Z.; Long, C.J.; Yuan, Z.Y.; Zhang, D.Y. Contourlet transform based texture analysis for smoke and fog classification. In Applied Mechanics and Materials; Trans Tech Publications, Ltd.: Baech, Switzerland, 2011; Volume 88, pp. 537–542. [Google Scholar]
- Ye, W.; Zhao, J.; Wang, S.; Wang, Y.; Zhang, D.; Yuan, Z. Dynamic texture based smoke detection using Surfacelet transform and HMT model. Fire Saf. J. 2015, 73, 91–101. [Google Scholar] [CrossRef]
- Yuan, F. Video-based smoke detection with histogram sequence of LBP and LBPV pyramids. Fire Saf. J. 2011, 46, 132–139. [Google Scholar] [CrossRef]
- Zhao, Y.; Lu, W.; Zheng, Y.; Wang, J. An early smoke detection system based on increment of optical flow residual. In Proceedings of the 2012 International Conference on Machine Learning and Cybernetics, Xian, China, 15–17 July 2012; Volume 4, pp. 1474–1479. [Google Scholar]
- Ho, C.C.; Kuo, T.H. Real-time video-based fire smoke detection system. In Proceedings of the 2009 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Singapore, 14–17 July 2009; pp. 1845–1850. [Google Scholar]
- Gubbi, J.; Marusic, S.; Palaniswami, M. Smoke detection in video using wavelets and support vector machines. Fire Saf. J. 2009, 44, 1110–1115. [Google Scholar] [CrossRef]
- Li, J.; Zou, X.; Lu, W. The design and implementation of fire smoke detection system based on FPGA. In Proceedings of the 2012 24th Chinese Control and Decision Conference (CCDC), Taiyuan, China, 23–25 May 2012; pp. 3919–3922. [Google Scholar]
- Bianconi, F.; Fernández, A. Evaluation of the effects of Gabor filter parameters on texture classification. Pattern Recognit. 2007, 40, 3325–3335. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Dong, H.; Zhou, E. An early fire detection method based on smoke texture analysis and discrimination. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 3, pp. 95–99. [Google Scholar]
- Hannan, M.; Arebey, M.; Begum, R.A.; Mustafa, A.; Basri, H. An automated solid waste bin level detection system using Gabor wavelet filters and multi-layer perception. Resour. Conserv. Recycl. 2013, 72, 33–42. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2020; pp. 9759–9768. [Google Scholar]
- He, L.; Gong, X.; Zhang, S.; Wang, L.; Li, F. Efficient attention based deep fusion CNN for smoke detection in fog environment. Neurocomputing 2021, 434, 224–238. [Google Scholar] [CrossRef]
- Lin, G.; Zhang, Y.; Xu, G.; Zhang, Q. Smoke detection on video sequences using 3D convolutional neural networks. Fire Technol. 2019, 55, 1827–1847. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J.-Real-Time Image Process. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Cao, Y.; Yang, F.; Tang, Q.; Lu, X. An attention enhanced bidirectional LSTM for early forest fire smoke recognition. IEEE Access 2019, 7, 154732–154742. [Google Scholar] [CrossRef]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl.-Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J.; Peters, S.; Li, J.; Oliver, S.; Mueller, N. Investigating the Impact of Using IR Bands on Early Fire Smoke Detection from Landsat Imagery with a Lightweight CNN Model. Remote Sens. 2022, 14, 3047. [Google Scholar] [CrossRef]
- Zhao, N.; Wang, X.W.; Yin, S.L. Research of fire smoke detection algorithm based on video. Int. J. Electron. Inf. Eng. 2021, 13, 1–9. [Google Scholar]
- Gao, Y.; Cheng, P. Forest fire smoke detection based on visual smoke root and diffusion model. Fire Technol. 2019, 55, 1801–1826. [Google Scholar] [CrossRef]
- Jadon, A.; Omama, M.; Varshney, A.; Ansari, M.S.; Sharma, R. FireNet: A specialized lightweight fire & smoke detection model for real-time IoT applications. arXiv 2019, arXiv:1905.11922. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2874–2883. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Shrivastava, A.; Sukthankar, R.; Malik, J.; Gupta, A. Beyond skip connections: Top-down modulation for object detection. arXiv 2016, arXiv:1612.06851. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 5936–5944. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Standvoss, K.; Quax, S.C.; van Gerven, M.A. Visual attention through uncertainty minimization in recurrent generative models. bioRxiv 2020. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germant, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. A 2-nets: Double attention networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–14 December 2018; Volume 31. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2018; Volume 30. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 28 October 2019. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lu, F.; Xie, F.; Shen, S.; Yang, J.; Zhao, J.; Sun, R.; Huang, L. The One-Stage Detector Algorithm Based on Background Prediction and Group Normalization for Vehicle Detection. Appl. Sci. 2020, 10, 5883. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Authors, P. PaddleDetection, Object Detection and Instance Segmentation Toolkit Based on PaddlePaddle. 2019. Available online: https://github.com/PaddlePaddle/PaddleDetection (accessed on 19 March 2023).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| epoch | 300 |
| batch size | 32 |
| learning rate | 0.001 |
| weight decay | 0.0005 |
| optimizer | SGD |
| momentum | 0.937 |
| warmup | 3 |
| random seed | 42 |
| image size | 640 |
| num workers | 12 |
| Method | Year | # Param. (M) | FLOPs (G) | FPS (V100) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| One-Stage Detectors | |||||||||||
| SSD | 2016 | 30.8 | 65.9 | 24.6 | 10.6 | 25.6 | 40.8 | 43.5 | 24.5 | 87.9 | 24.5 |
| PPYOLO-R50 | 2020 | 33.8 | 68.6 | 29.2 | 28.2 | 35.0 | 37.3 | 54.3 | 46.6 | 106.6 | 155.6 |
| RetinaNet-R101-FPN | 2017 | 35.1 | 71.2 | 31.6 | 6.9 | 36.5 | 41.6 | 44.9 | 55.1 | 112.3 | 175.9 |
| YOLOv3-SPP | 2018 | 35.1 | 76.8 | 28.1 | 33.1 | 36.2 | 38.0 | 44.8 | 62.0 | 78.2 | 200.6 |
| FCOS-R101-FPN | 2019 | 37.7 | 70.1 | 37,3 | 19.3 | 40.5 | 42.1 | 48.4 | 50.8 | 109.1 | 171.1 |
| RetinaNet-FreeAnchor | 2017 | 40.4 | 75.7 | 39.7 | 36.7 | 40.1 | 44.9 | 49.4 | 56.7 | 126.1 | 177.3 |
| ATSS-R101-FPN | 2020 | 41.8 | 71.7 | 45.0 | 32.4 | 43.0 | 45.9 | 51.5 | 50.9 | 111.0 | 172.1 |
| VarifocalNet-R101-FPN | 2021 | 42.1 | 73.1 | 44.3 | 35.5 | 43.0 | 47.1 | 51.5 | 51.5 | 106.0 | 164.7 |
| PPYOLOE-X | 2022 | 42.9 | 76.1 | 44.4 | 38.7 | 45.0 | 47.4 | 58.6 | 95.3 | 204.9 | 95.2 |
| PPYOLOv2-R101 | 2021 | 44.5 | 78.8 | 46.2 | 53.4 | 47.8 | 46.4 | 61.8 | 73.2 | 187.4 | 87.0 |
| PicoDet-L | 2021 | 47.9 | 82.1 | 50.2 | 39.9 | 49.2 | 51.3 | 58.0 | 5.8 | 16.8 | 223.0 |
| RTMDet-X | 2022 | 48.1 | 84.2 | 50.7 | 27.3 | 45.1 | 54.3 | 57.3 | 94.9 | 141.7 | 136.1 |
| PPYOLOE+-X | 2022 | 49.6 | 82.3 | 54.3 | 37.1 | 49.8 | 54.7 | 62.6 | 98.4 | 206.6 | 95.2 |
| TOOD-R101-FPN | 2021 | 52.1 | 82.3 | 57.8 | 36.3 | 53.9 | 56.2 | 60.3 | 53.4 | 73.3 | 175.5 |
| ATSS-FPN-DyHead | 2019 | 52.4 | 84.3 | 58.1 | 28.7 | 52.5 | 58.5 | 61.4 | 210.4 | 322.2 | 50.1 |
| YOLOv5-L6 | 2020 | 56.5 | 89.0 | 61.4 | 38.4 | 52.6 | 61.9 | 64.3 | 76.2 | 110.5 | 79.4 |
| YOLOv4-P5 | 2020 | 57.0 | 90.0 | 65.5 | 46.0 | 55.9 | 64.7 | 67.2 | 70.3 | 166.0 | 105.3 |
| YOLOX-X | 2021 | 57.4 | 86.8 | 65.8 | 55.6 | 56.1 | 60.5 | 63.3 | 99.0 | 282.0 | 38.6 |
| YOLOv7-X | 2022 | 59.4 | 89.3 | 67.8 | 56.1 | 56.8 | 64.7 | 66.8 | 70.8 | 188.9 | 108.7 |
| YOLOv6-L | 2022 | 59.6 | 88.8 | 68.1 | 49.4 | 57.8 | 64.8 | 67.5 | 58.5 | 143.8 | 94.3 |
| YOLOR-CSP-X | 2021 | 61.3 | 91.0 | 70.2 | 49.9 | 58.1 | 66.6 | 68.4 | 99.8 | 223.0 | 83.3 |
| Two-Stage Detectors | |||||||||||
| Faster-R50-PAFPN | 2018 | 29.1 | 63.0 | 22.1 | 19.0 | 28.9 | 34.3 | 37.5 | 44.7 | 100.9 | 175.7 |
| Sparse-R101-FPN | 2020 | 34.8 | 69.7 | 26.3 | 20.5 | 33.4 | 41.1 | 60.8 | 124.9 | 95.1 | 174.0 |
| CenterNet-R18-DCN | 2019 | 34.8 | 71.3 | 30.1 | 15.9 | 34.8 | 39.7 | 46.7 | 14.4 | 19.3 | 71.3 |
| Mask-R101-FPN | 2017 | 35.7 | 69.0 | 33.4 | 35.7 | 37.7 | 40.4 | 43.3 | 63.2 | 174.9 | 13.5 |
| Faster-R101-FPN | 2017 | 37.2 | 73.8 | 32.5 | 27.0 | 38.3 | 42.5 | 44.7 | 60.1 | 121.4 | 177.2 |
| DDOD-R50-FPN | 2021 | 37.8 | 69.8 | 37.6 | 27.5 | 37.4 | 43.2 | 47.0 | 32.2 | 72.7 | 172.3 |
| Cascade-R101-FPN | 2018 | 38.5 | 72.2 | 36.7 | 20.8 | 38.3 | 45.0 | 45.6 | 87.9 | 149.2 | 176.0 |
| Cascade-X101-DCN-FPN | 2019 | 42.0 | 73.2 | 43.8 | 19.5 | 43.1 | 48.7 | 49.0 | 95.4 | 305.2 | 177.6 |
| RepPoints-R101-FPN | 2019 | 45.3 | 77.6 | 47.6 | 22.5 | 45.0 | 52.6 | 53.6 | 56.9 | 81.2 | 170.7 |
| Libra Faster-X101-FPN | 2019 | 47.2 | 75.7 | 53.4 | 30.6 | 47.8 | 52.1 | 54.1 | 99.1 | 184.8 | 178.5 |
| DetectoRS-HTC-R101 | 2020 | 47.8 | 78.9 | 52.1 | 25.5 | 46.1 | 54.5 | 56.1 | 196.5 | 279.1 | 49.6 |
| HTC-Res2Net-R101-FPN | 2019 | 48.9 | 78.5 | 54.6 | 33.8 | 48.4 | 54.6 | 55.3 | 89.2 | 156.7 | 4.4 |
| RetinaNet-R50-FPG | 2020 | 48.9 | 81.7 | 53.4 | 16.3 | 51.4 | 55.1 | 57.4 | 70.9 | 122.2 | 205.9 |
| Cascade-Mask-ConvNeXt-S | 2021 | 49.7 | 82.3 | 50.2 | 30.1 | 53.2 | 55.7 | 57.7 | 120.4 | 133.3 | 78.5 |
| Mask-ConvNeXt-T | 2021 | 51.1 | 83.8 | 56.4 | 36.6 | 54.1 | 56.2 | 57.9 | 99.2 | 150.8 | 89.5 |
| Faster-R50-FPG | 2020 | 53.7 | 85.0 | 60.4 | 45.2 | 54.4 | 57.2 | 59.5 | 79.4 | 253.7 | 214.5 |
| Mask-R50-FPG | 2020 | 55.2 | 85.4 | 62.9 | 48.7 | 55.4 | 59.3 | 60.6 | 82.0 | 305.2 | 44.7 |
| Cascacde-Mask-S101-FPN | 2020 | 56.1 | 86.4 | 64.6 | 48.5 | 57.6 | 62.1 | 62.4 | 103.2 | 211.5 | 56.8 |
| Cascade-Mask-ConvNeXt-T | 2021 | 57.6 | 86.8 | 66.1 | 49.8 | 57.9 | 63.5 | 64.3 | 124.7 | 234.8 | 48.9 |
| Transformer-Based Detectors | |||||||||||
| Detr-R50 | 2020 | 35.6 | 72.3 | 30.7 | 20.9 | 32.8 | 43.0 | 50.7 | 41.3 | 37.1 | 55.6 |
| Deformable-Detr-R50 | 2020 | 37.8 | 75.1 | 36.7 | 23.7 | 33.5 | 45.6 | 55.4 | 55.8 | 45.9 | 57.4 |
| ViTDet-Base | 2020 | 47.8 | 76.5 | 47.3 | 34.5 | 41.2 | 50.1 | 57.8 | 106.3 | 210.5 | 66.2 |
| Mask-R50-Swin-S | 2021 | 48.9 | 77.7 | 49.6 | 37.9 | 43.1 | 51.7 | 58.8 | 67.5 | 230.6 | 68.9 |
| ViTDet-Faster-R50 | 2020 | 50.2 | 80.3 | 52.7 | 37.4 | 45.8 | 53.8 | 59.2 | 77.4 | 284.7 | 74.8 |
| RepPoints-Swin-T | 2021 | 52.1 | 82.6 | 54.0 | 41.3 | 46.8 | 56.1 | 62.3 | 88.5 | 189.5 | 77.4 |
| ViTDet-Large | 2020 | 53.3 | 83.2 | 55.7 | 42.0 | 48.8 | 58.9 | 62.4 | 156.7 | 238.5 | 44.0 |
| Mask-RepPoints-Swin-T | 2021 | 53.8 | 84.7 | 57.4 | 45.1 | 52.1 | 57.5 | 64.3 | 101.6 | 200.3 | 68.4 |
| Ours | 62.5 | 87.9 | 71.4 | 58.5 | 60.7 | 68.1 | 68.1 | 45.4 | 143.6 | 113.6 |
| Method | TTA | Size | |
|---|---|---|---|
| YOLOv5-L6 | − | 640 | 56.5 |
| ✓ | 640 | 58.7 | |
| YOLOv4-P5 | − | 640 | 57.0 |
| ✓ | 640 | 58.6 | |
| YOLOv7-X | − | 640 | 59.4 |
| ✓ | 640 | 59.7 | |
| YOLOv6-L | − | 640 | 59.6 |
| ✓ | 640 | 60.3 | |
| YOLOR-CSP-X | − | 640 | 61.3 |
| ✓ | 640 | 63.9 | |
| Ours | − | 640 | 62.5 |
| ✓ | 640 | 65.1 |
| Method | Precision | IoU Threshould | |
|---|---|---|---|
| Ours | FP16 (default) | 0.65 (default) | 62.5 |
| FP32 | 0.65 | 62.5 | |
| FP16 | 0.70 | 62.5 | |
| FP32 | 0.70 | 62.7 | |
| Improvement | +0.2 |
| Method | Fire | Smoke | |
|---|---|---|---|
| One-Stage Detectors | |||
| YOLOv5-L5 | 56.5 | 56.1 | 56.9 |
| YOLOv4-P5 | 57.0 | 57.3 | 56.7 |
| YOLOX-X | 57.4 | 61.9 | 53.0 |
| YOLOv7-X | 59.4 | 62.0 | 56.7 |
| YOLOv6-L | 59.6 | 60.6 | 58.7 |
| YOLOR-CSP-X | 61.3 | 61.9 | 60.6 |
| Two-Stage Detectors | |||
| Faster-R50-FPG | 53.7 | 56.1 | 51.2 |
| Mask-R50-FPG | 55.2 | 57.5 | 53.0 |
| Cascade-Mask-S101-FPN | 56.1 | 58.1 | 54.1 |
| Cascade-Mask-ConvNeXt-T | 57.6 | 58.8 | 55.4 |
| Transformer-Based Detectors | |||
| RepPoints-Swin-T | 52.1 | 55.7 | 48.5 |
| ViTDet-Large | 53.3 | 55.4 | 51.2 |
| Mask-RepPoints-Swin-T | 53.8 | 55.8 | 51.8 |
| Ours | 62.5 | 63.9 | 61.1 |
| Method | Size | #Param.(M) | FLOPs(G) | |
|---|---|---|---|---|
| YOLOv7 | 640 | 57.7 | 36.9 | 104.7 |
| YOLOv7+ | 640 | 60.7 | 21.6 | 35.7 |
| YOLOv7-X | 640 | 59.4 | 71.3 | 189.9 |
| YOLOv7-X+ | 640 | 62.5 | 37.1 | 70.2 |
| YOLOv7-W6 | 1280 | 59.9 | 81.0 | 360.0 |
| YOLOv7-W6+ | 1280 | 63.0 | 39.9 | 100.3 |
| YOLOv7-E6 | 1280 | 60.7 | 97.2 | 515.2 |
| YOLOv7-E6+ | 1280 | 63.5 | 45.4 | 144.5 |
| YOLOv7-D6 | 1280 | 61.5 | 154.7 | 806.8 |
| YOLOv7-D6+ | 1280 | 63.9 | 78.8 | 187.9 |
| YOLOv7-E6E | 1280 | 61.8 | 151.7 | 843.2 |
| YOLOv7-E6E+ | 1280 | 64.3 | 77.7 | 206.8 |
| Rank | CDPB | PSA | RC FPN-PAN | |
|---|---|---|---|---|
| 1 | − | − | − | 59.4 |
| 2 | ✓ | − | − | 59.7 |
| 3 | − | ✓ | − | 60.5 |
| 4 | − | − | ✓ | 61.1 |
| 5 | ✓ | ✓ | − | 61.7 |
| 6 | − | ✓ | ✓ | 62.0 |
| 7 | ✓ | − | ✓ | 62.1 |
| 8 | ✓ | ✓ | ✓ | 62.3 |
| Improvement | +2.9 |
| Rank | Match Strategy | Weight Decay | |
|---|---|---|---|
| 1 | − | − | 59.4 |
| 2 | − | ✓ | 60.6 |
| 3 | ✓ | − | 61.2 |
| 4 | ✓ | ✓ | 62.0 |
| Improvement | +2.6 |
| Rank | Structure | Strategy | |
|---|---|---|---|
| 1 | − | − | 59.4 |
| 2 | − | ✓ | 62.0 |
| 3 | ✓ | − | 62.3 |
| 4 | ✓ | ✓ | 62.5 |
| Improvement | +3.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, C.; Zheng, A.; Wu, Z.; Tong, C. Real-Time Fire Smoke Detection Method Combining a Self-Attention Mechanism and Radial Multi-Scale Feature Connection. Sensors 2023, 23, 3358. https://doi.org/10.3390/s23063358
Jin C, Zheng A, Wu Z, Tong C. Real-Time Fire Smoke Detection Method Combining a Self-Attention Mechanism and Radial Multi-Scale Feature Connection. Sensors. 2023; 23(6):3358. https://doi.org/10.3390/s23063358
Chicago/Turabian StyleJin, Chuan, Anqi Zheng, Zhaoying Wu, and Changqing Tong. 2023. "Real-Time Fire Smoke Detection Method Combining a Self-Attention Mechanism and Radial Multi-Scale Feature Connection" Sensors 23, no. 6: 3358. https://doi.org/10.3390/s23063358
APA StyleJin, C., Zheng, A., Wu, Z., & Tong, C. (2023). Real-Time Fire Smoke Detection Method Combining a Self-Attention Mechanism and Radial Multi-Scale Feature Connection. Sensors, 23(6), 3358. https://doi.org/10.3390/s23063358