

Automatic Detection of Microaneurysms in Fundus Images Using an Ensemble-Based Segmentation Method
 , , ,
, , ,
Abstract
:1. Introduction
2. Background
3. Methods and Materials
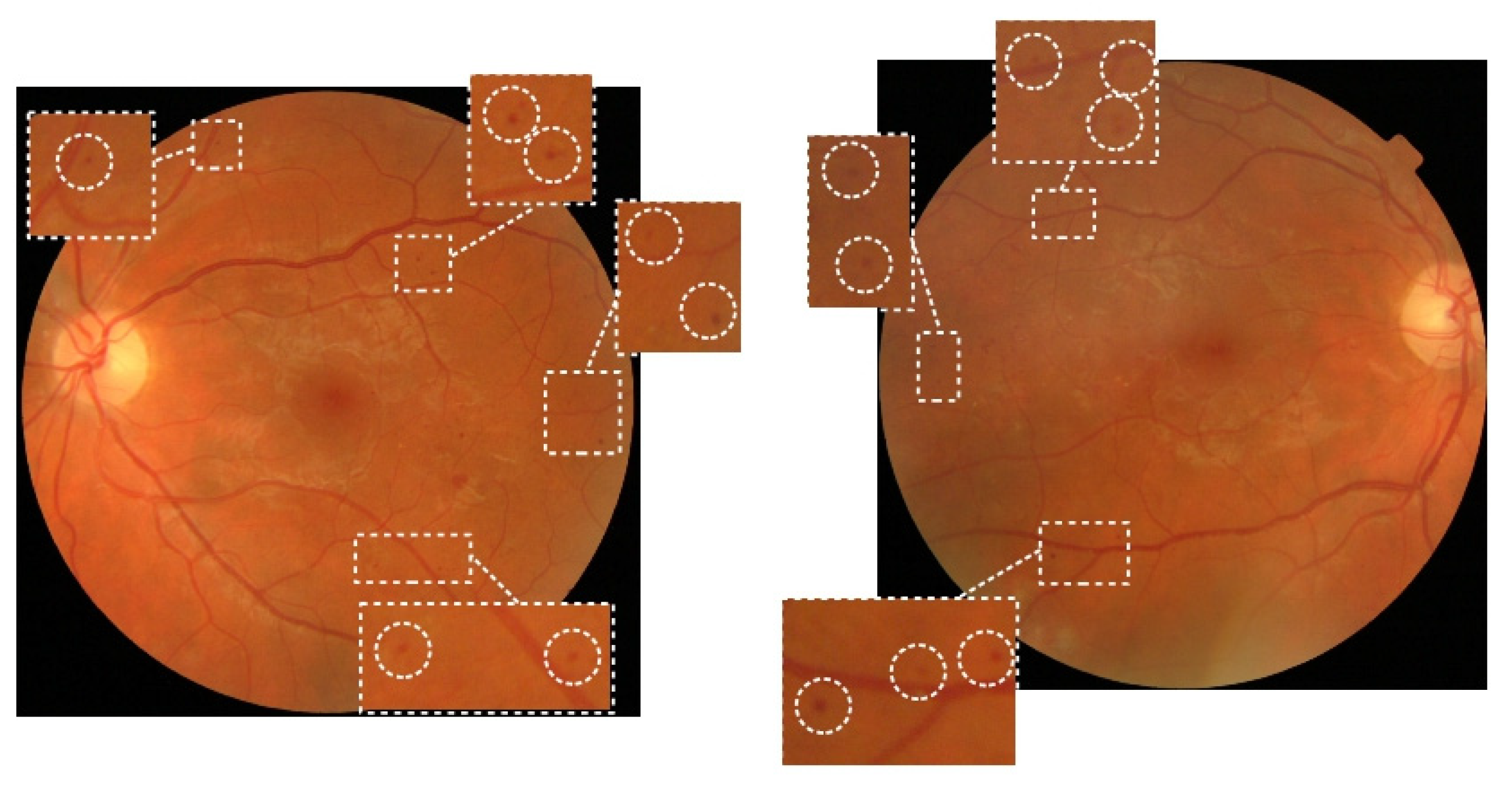
3.1. Dataset
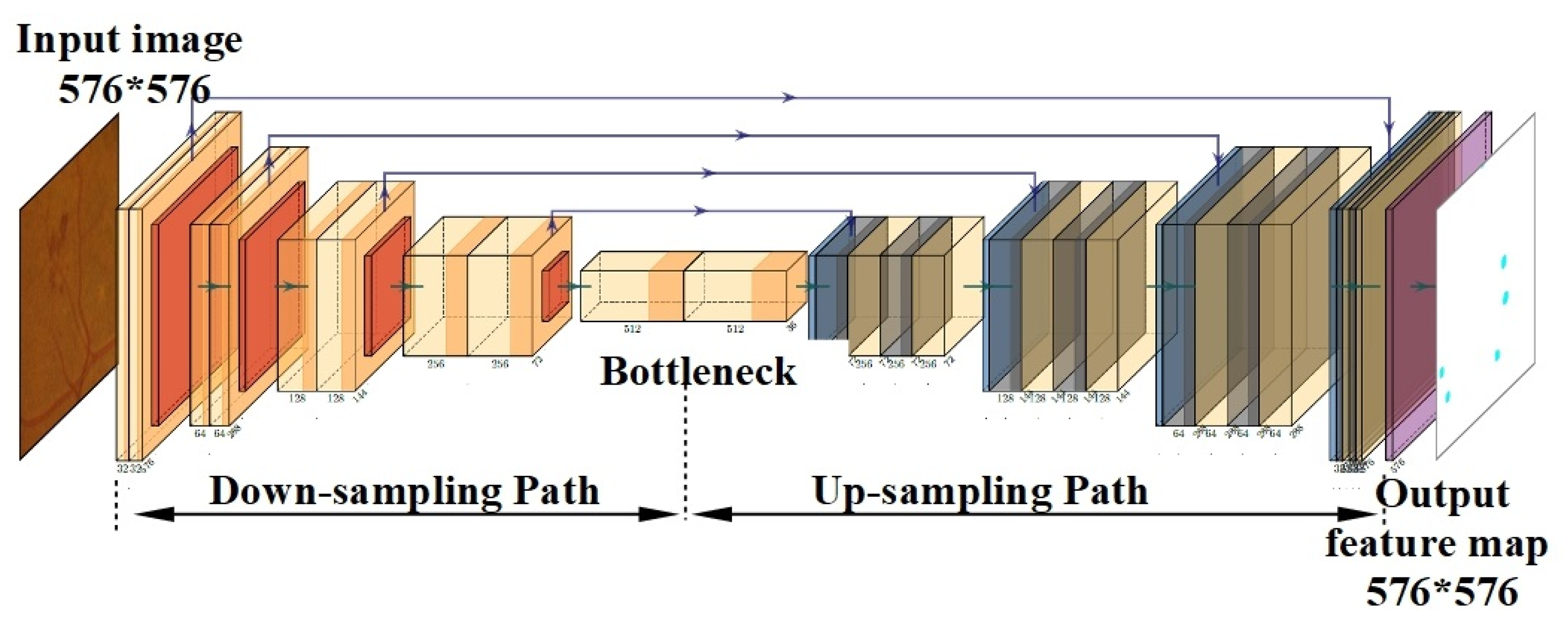
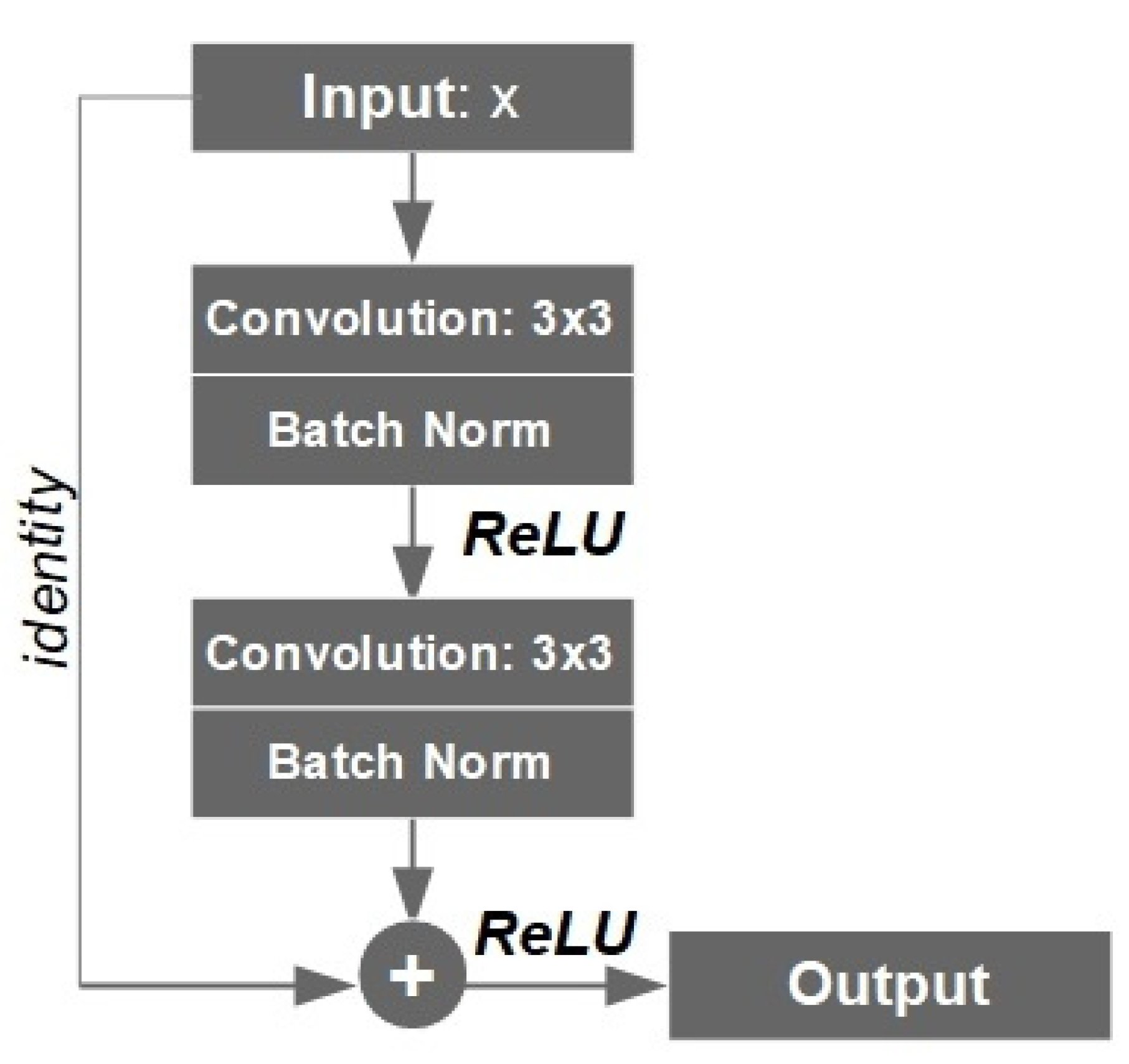
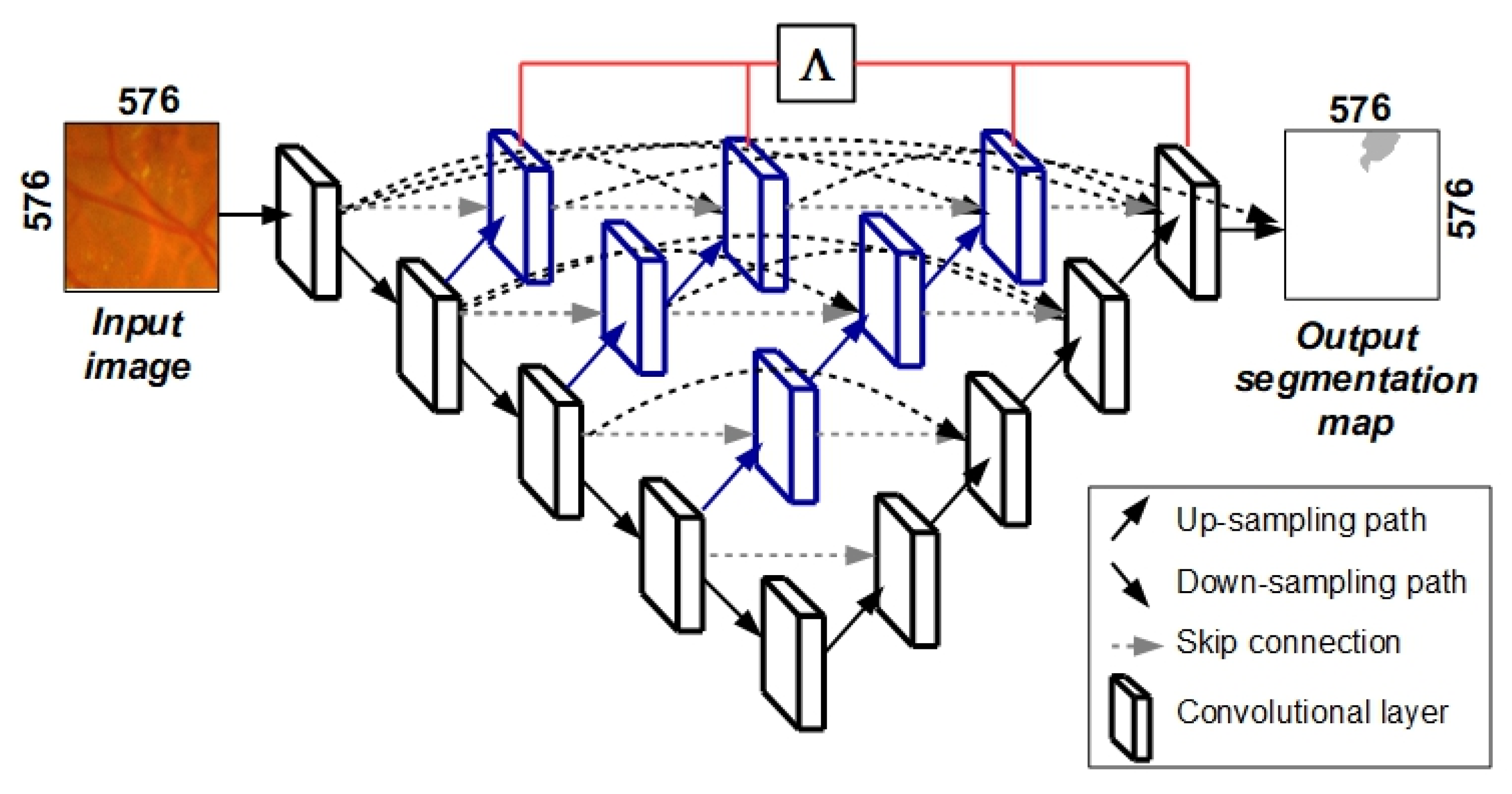
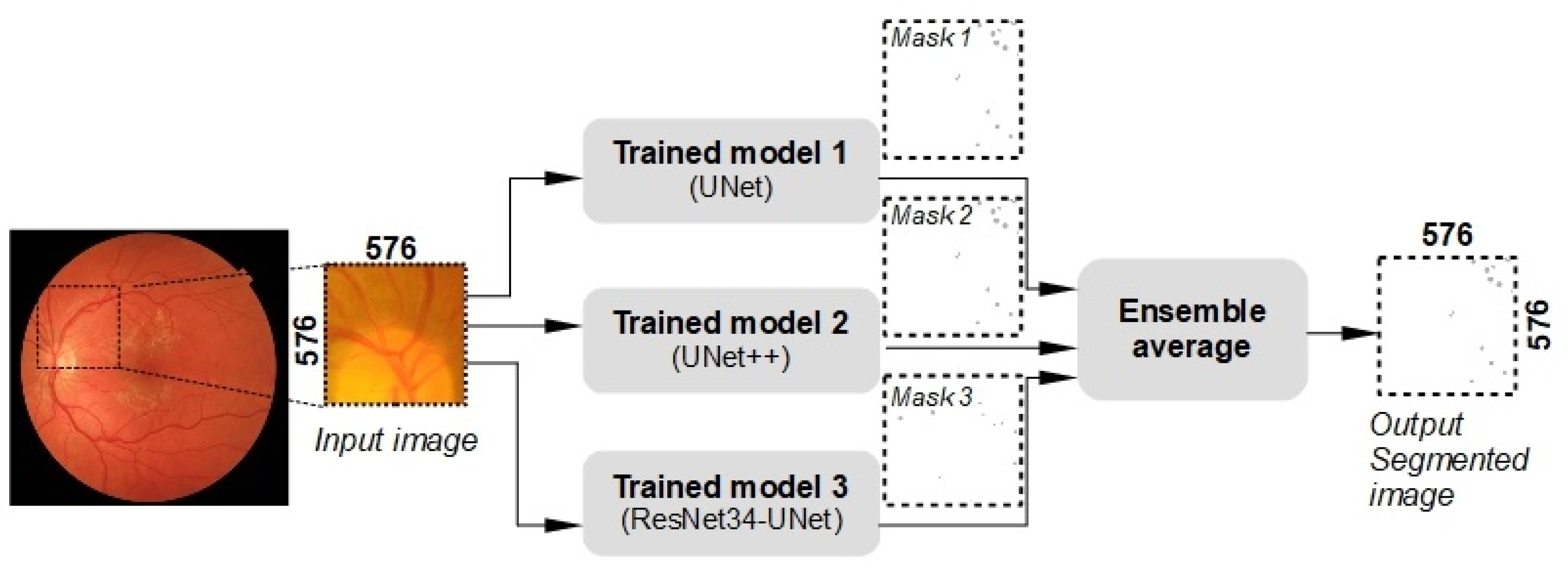
3.2. Proposed Segmentation Model
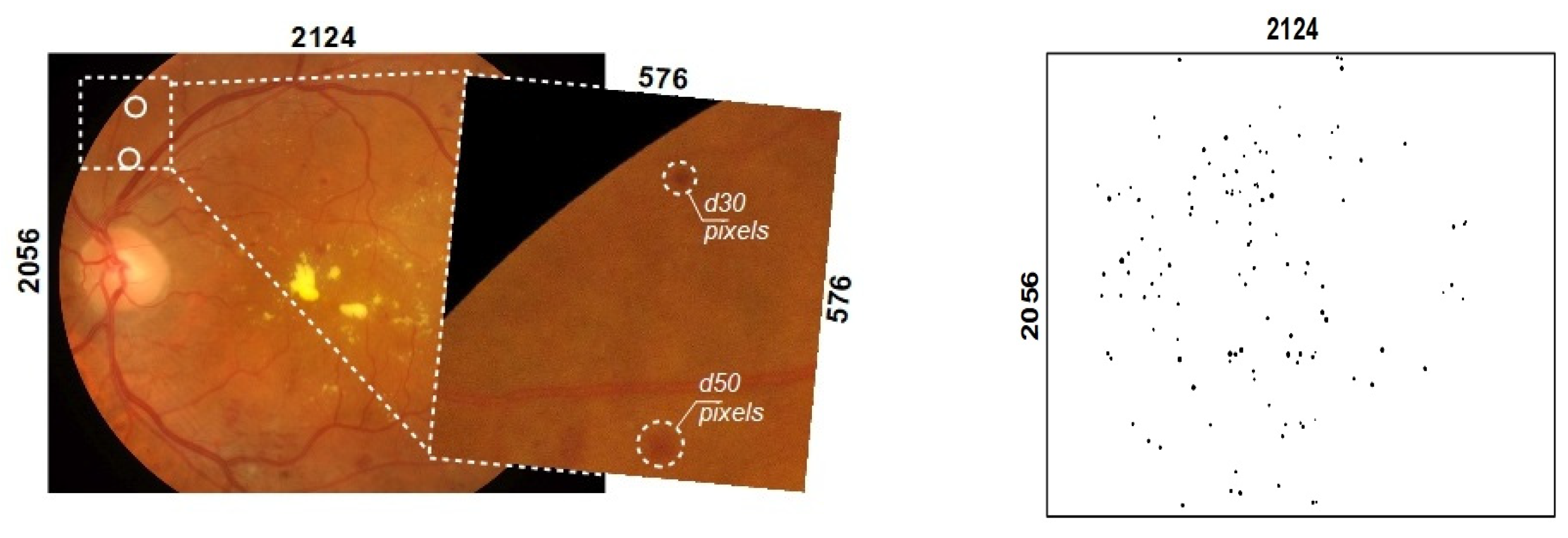
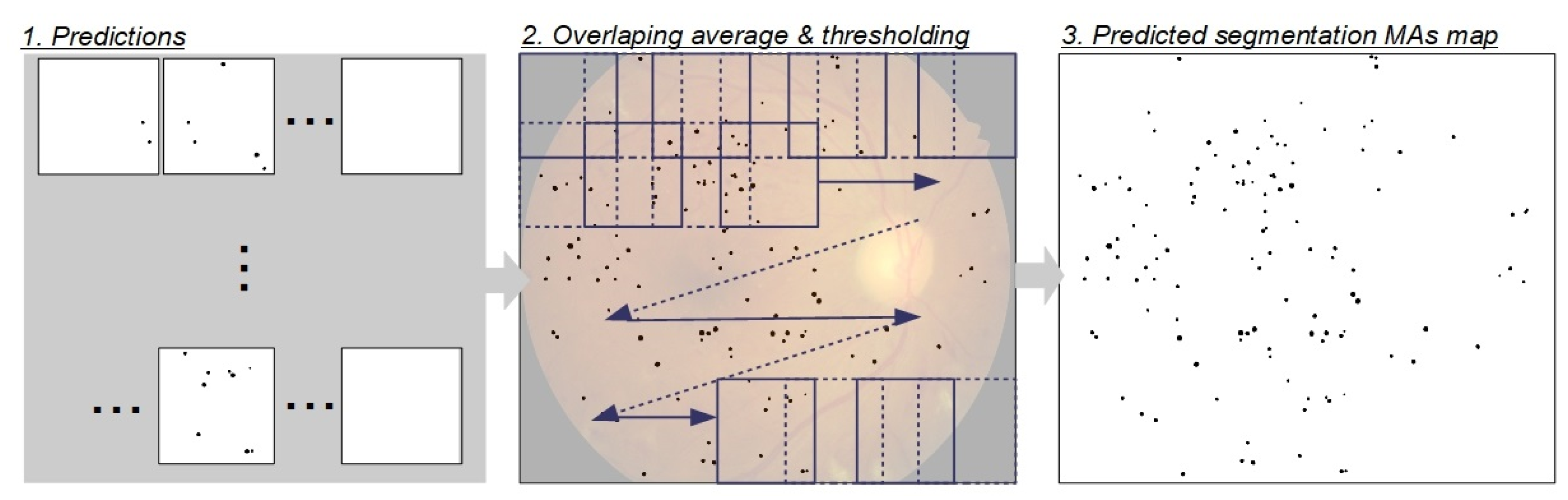
3.3. Reconstruction of the Predicted Segmentation Map from RoIs
3.4. Semantic Segmentation Performance Measures
4. Results
4.1. Experimental Setup
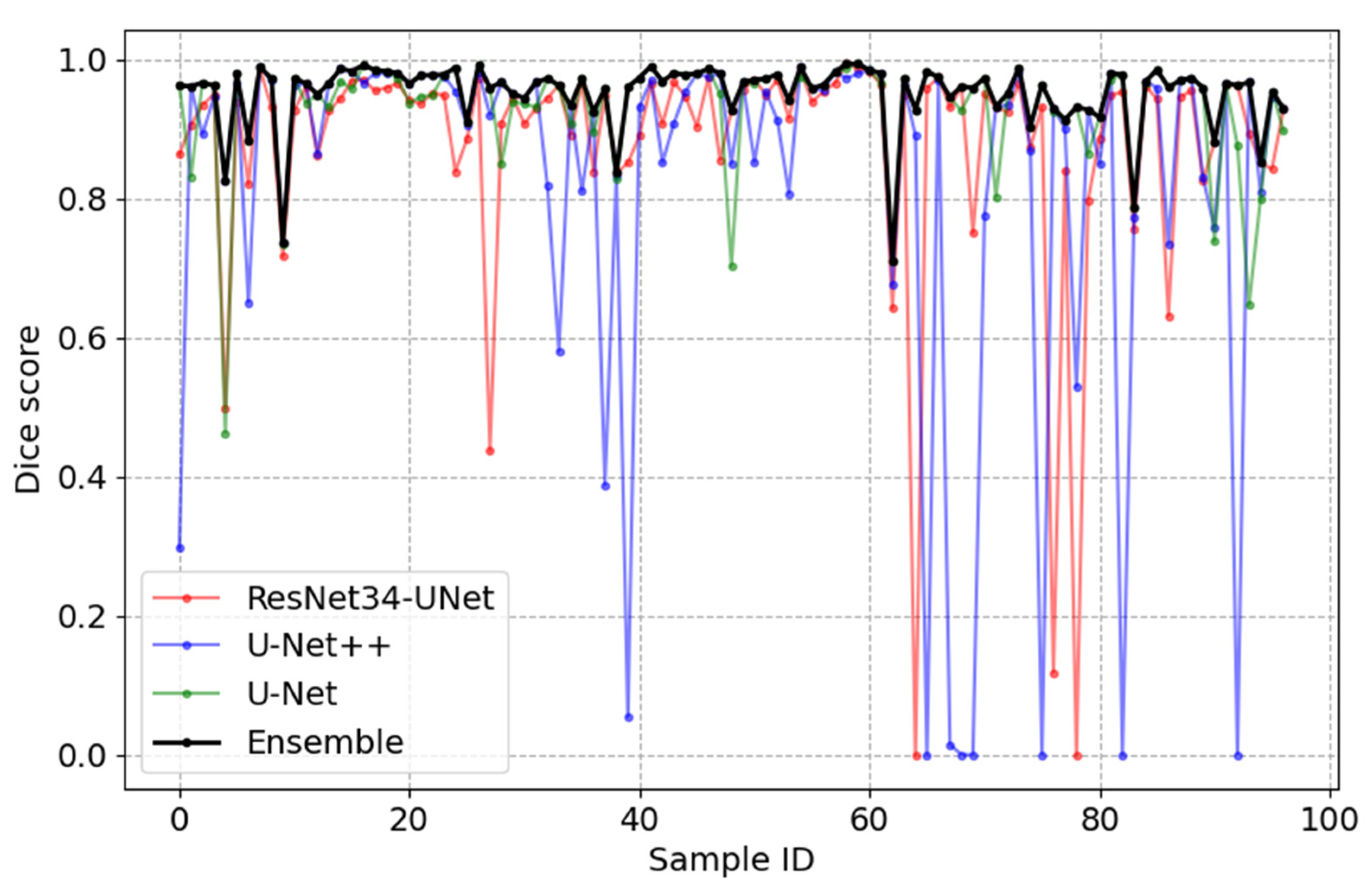
4.2. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Ethics
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- International Diabetes Federation. IDF Diabetes Atlas, 10th ed.; International Diabetes Federation: Brussels, Belgium, 2021. [Google Scholar]
- GBD 2019 Blindness and Vision Impairment Collaborators, Vision Loss Expert Group of the Global Burden of Disease Study. Causes of blindness and vision impairment in 2020 and trends over 30 years, and prevalence of avoidable blindness in relation to VISION 2020: The Right to Sight: An analysis for the Global Burden of Disease Study. Lancet Glob. Health 2021, 9, e144–e160, Erratum in Lancet Glob. Health 2021, 9, e408. [Google Scholar] [CrossRef] [PubMed]
- Ehlers, J.P.; Jiang, A.C.; Boss, J.D.; Hu, M.; Figueiredo, N.; Babiuch, A.; Talcott, K.; Sharma, S.; Hach, J.; Le, T.; et al. Quantitative ultra-widefield angiography and diabetic retinopathy severity: An assessment of panretinal leakage index, ischemic index and microaneurysm count. Ophthalmology 2019, 126, 1527–1532. [Google Scholar] [CrossRef] [PubMed]
- Nadeem, M.W.; Goh, H.G.; Hussain, M.; Liew, S.-Y.; Andonovic, I.; Khan, M.A. Deep Learning for Diabetic Retinopathy Analysis: A Review, Research Challenges, and Future Directions. Sensors 2022, 22, 6780. [Google Scholar] [CrossRef] [PubMed]
- Palani, D.; Venkatalakshmi, K.; Jabeen, A.R.; Ram, V.M.A.B. Effective Detection of Diabetic Retinopathy from Human Retinal Fundus Images Using Modified FCM and IWPSO. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Carrillo, J.; Bautista, L.; Villamizar, J.; Rueda, J.; Sanchez, M.; Rueda, D. Glaucoma Detection Using Fundus Images of the Eye. In Proceedings of the 2019 XXII Symposium on Image, Signal Processing and Artificial Vision (STSIVA), Bucaramanga, Colombia, 24–26 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Noyel, G.; Vartin, C.; Boyle, P.; Kodjikian, L. Retinal Vessel Segmentation by Probing Adaptive to Lighting Variations. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1246–1249. [Google Scholar] [CrossRef]
- Raj, P.K.; Manjunath, A.; Kumar, J.R.H.; Seelamantula, C.S. Automatic Classification of Artery/Vein from Single Wavelength Fundus Images. In Proceedings of the 17th IEEE International Symposium on Biomedical Imaging, ISBI 2020, Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1262–1265. [Google Scholar] [CrossRef]
- Raja, P.M.S.; Sumithra, R.P.; Thanusha, G. Automatic Glaucoma Diagnosis Based on Photo Segmentation with Fundus Images. In Proceedings of the 2021 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 17–18 March 2021; pp. 102–105. [Google Scholar] [CrossRef]
- Dharmawan, D.A.; Li, D.; Ng, B.P.; Rahardja, S. A New Hybrid Algorithm for Retinal Vessels Segmentation on Fundus Images. IEEE Access 2019, 7, 41885–41896. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Chen, D. Blood Vessel Segmentation in Fundus Images Based on Improved Loss Function. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 4017–4021. [Google Scholar] [CrossRef]
- Yan, S.; Huang, J.; Tang, X.; Chi, X. Fundus Image Segmentation Using Step Time Signal Polynomial Fitting. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2021; pp. 985–992. [Google Scholar] [CrossRef]
- Nasery, V.; Soundararajan, K.B.; Galeotti, J. Learning to Segment Vessels from Poorly Illuminated Fundus Images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1232–1236. [Google Scholar] [CrossRef]
- Yin, P.; Yuan, R.; Cheng, Y.; Wu, Q. Deep Guidance Network for Biomedical Image Segmentation. IEEE Access 2020, 8, 116106–116116. [Google Scholar] [CrossRef]
- Wang, Y.; Li, S.; Cao, G.; Cao, C.; Li, M.; Zhu, X. Improved U-net fundus image segmentation method. In Proceedings of the 2019 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Shanghai, China, 21–24 November 2019; pp. 110–113. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, R.; Zhou, X.; Liu, Y.; Wang, L.; Lv, C.; Lv, B.; Xie, G. Lesion-Aware Segmentation Network for Atrophy and Detachment of Pathological Myopia on Fundus Images. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1242–1245. [Google Scholar] [CrossRef]
- Hervella, A.S.; Ramos, L.; Rouco, J.; Novo, J.; Ortega, M. Multi-Modal Self-Supervised Pre-Training for Joint Optic Disc and Cup Segmentation in Eye Fundus Images. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 961–965. [Google Scholar] [CrossRef]
- Tang, M.C.S.; Teoh, S.S.; Ibrahim, H. Retinal Vessel Segmentation from Fundus Images Using DeepLabv3+. In Proceedings of the 2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), Selangor, Malaysia, 12 May 2022; pp. 377–381. [Google Scholar] [CrossRef]
- Wu, Q.; Cheddad, A. Segmentation-based Deep Learning Fundus Image Analysis. In Proceedings of the 2019 Ninth International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Santos, C.; Aguiar, M.; Welfer, D.; Belloni, B. A New Approach for Detecting Fundus Lesions Using Image Processing and Deep Neural Network Architecture Based on YOLO Model. Sensors 2022, 22, 6441. [Google Scholar] [CrossRef] [PubMed]
- Nawaz, F.; Ramzan, M.; Mehmood, K.; Khan, H.U.; Khan, S.H.; Bhutta, M.R. Early Detection of Diabetic Retinopathy Using Machine Intelligence through Deep Transfer and Representational Learning. Comput. Mater. Contin. 2021, 66, 1631–1645. [Google Scholar] [CrossRef]
- Tavakoli, M.; Mehdizadeh, A.; Aghayan, A.; Shahri, R.P.; Ellis, T.; Dehmeshki, J. Automated Microaneurysms Detection in Retinal Images Using Radon Transform and Supervised Learning: Application to Mass Screening of Diabetic Retinopathy. IEEE Access 2021, 9, 67302–67314. [Google Scholar] [CrossRef]
- Valizadeh, A.; Ghoushchi, S.J.; Ranjbarzadeh, R.; Pourasad, Y. Presentation of a Segmentation Method for a Diabetic Retinopathy Patient’s Fundus Region Detection Using a Convolutional Neural Network. Comput. Intell. Neurosci. 2021, 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Metric | U-Net | RestNet34-UNet | U-Net++ | Ensemble |
|---|---|---|---|---|
| 0.88 | 0.81 | 0.76 | 0.91 | |
| Dice Score | 0.93 | 0.88 | 0.82 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raudonis, V.; Kairys, A.; Verkauskiene, R.; Sokolovska, J.; Petrovski, G.; Balciuniene, V.J.; Volke, V. Automatic Detection of Microaneurysms in Fundus Images Using an Ensemble-Based Segmentation Method. Sensors 2023, 23, 3431. https://doi.org/10.3390/s23073431
Raudonis V, Kairys A, Verkauskiene R, Sokolovska J, Petrovski G, Balciuniene VJ, Volke V. Automatic Detection of Microaneurysms in Fundus Images Using an Ensemble-Based Segmentation Method. Sensors. 2023; 23(7):3431. https://doi.org/10.3390/s23073431
Chicago/Turabian StyleRaudonis, Vidas, Arturas Kairys, Rasa Verkauskiene, Jelizaveta Sokolovska, Goran Petrovski, Vilma Jurate Balciuniene, and Vallo Volke. 2023. "Automatic Detection of Microaneurysms in Fundus Images Using an Ensemble-Based Segmentation Method" Sensors 23, no. 7: 3431. https://doi.org/10.3390/s23073431
APA StyleRaudonis, V., Kairys, A., Verkauskiene, R., Sokolovska, J., Petrovski, G., Balciuniene, V. J., & Volke, V. (2023). Automatic Detection of Microaneurysms in Fundus Images Using an Ensemble-Based Segmentation Method. Sensors, 23(7), 3431. https://doi.org/10.3390/s23073431