1. Introduction
It is necessary to achieve high-quality voice communication in environments that have high temperatures, high pressure, strong radiation and strong electromagnetic effects. These environments create difficulties for conventional electroacoustic sensors and cause them not to work properly [
1]. External Fabry–Perot interferometric (EFPI) acoustic sensors are widely used in special fields such as national defense and security [
2], marine acoustic monitoring and positioning [
3] and fuel pipeline leakage and positioning [
4] because of their passive detection end, anti-electromagnetic interference, low loss, corrosion resistance and long-distance capabilities [
5,
6,
7]. However, since the noise present in these environments can significantly degrade the perceptual quality and clarity of voice communication, voice enhancement is a much-needed task.
Speech enhancement is one of the most important and challenging tasks in speech applications, in which the goal is to suppress and reduce noise interference to extract useful speech signals in noisy backgrounds [
8,
9]. With the successful application of deep learning in the field of images [
10,
11,
12,
13,
14], many scholars have begun to apply deep learning technology to speech enhancement. The existing speech enhancement methods can be divided into two categories: machine learning and deep learning. Regarding machine learning, early algorithms were generally implemented on shallow models and small datasets due to the limitations of computer hardware. Kim et al. developed a Gaussian mixture model (GMM)-based method for time–frequency (T-F) units according to the frequency band characteristics of input signals to determine the probability of speech and noise. However, this method models each frequency band separately, ignoring the correlation between frequency bands [
15]. Han et al. used the support vector machine (SVM) method to identify speech-dominated and noise-dominated T-F units. Compared with the GMM, the SVM shows a better generalization ability, but it still loses some target speech when the noise speech energy is too high [
16]. Chung et al. designed a training and compensation algorithm of class-conditioned basis vectors in a nonnegative matrix factorization (NMF) model for single-channel speech enhancement. The NMF algorithm is trained separately on clean speech and noise to reduce residual noise components that have similar characteristics to clean speech. However, when encountering speech or noise that does not appear in training, the performance of the algorithm will drop [
17].
Regarding deep learning, neural networks can enhance noisy speech in the time–frequency (TF) domain or directly in the time domain. In the time-domain method, the neural network directly learns the mapping relationship of the time-domain waveform level, and the processing flow is relatively simple. A one-dimensional convolutional neural network is usually used. Between feature extraction and waveform restoration, a neural network with a temporal modeling ability, such as a recurrent neural network (RNN) [
18] and a temporal convolutional network (TCN) [
19], is used to enhance the effect of speech enhancement. However, a shared limitation of RNNs and TCNs is their inability to effectively capture long-term dependencies in speech signals that extend across multiple time frames. On the other hand, TF domain methods, which are also popular, perform speech enhancement by learning the masking relationship from the spectrogram of noises to the spectrogram of clean speech. It is believed that speech and noise are more separated after passing through the short-time Fourier transform (STFT), which usually uses a convolutional encoder–decoder (CED) or U-Net framework [
20]. After the STFT was performed, TF domain methods can take the complex-valued spectrogram as input and then decompose the magnitude and phase into real and imaginary parts in Cartesian coordinates. These methods solve the long-standing problem of the phase being difficult to estimate. Recently, Choi et al. proposed deep complex U-Net (DCUnet), which utilizes deep complex-valued convolutional layers for the near-perfect enhancement of speech [
21]. Cao et al. proposed a generative adversarial network to model temporal and frequency correlations and achieved extremely high performance [
22]. Park et al. proposed a multi-view attention network to improve the accuracy of feature extraction [
23].
The EFPI acoustic sensor is a special microphone that converts sound waves into an optical signal. The speech signal needs to be received by the EFPI acoustic sensor and demodulated by the demodulation system to restore the sound signal. Unlike conventional microphones, some optical parameters (such as the light intensity, phase and polarization state) will also affect the acoustic characteristics of the EFPI acoustic sensor and cause frequency responses and noise [
24,
25]. Although deep learning has achieved extremely high performance in speech enhancement, most speech enhancement models are designed for conventional microphones and may not work perfectly on EFPI acoustic sensors.
In this paper, we propose a hybrid deep learning architecture that combines a complex-valued convolutional neural network and a long short-term memory (CV-CNN-LSTM) for speech enhancement of fiber-optic EFPI acoustic sensors. The CV-CNN and LSTM are set as the primary framework for the neural network, and the TF domain features of the signal are extracted through the STFT, completing the purpose of speech enhancement. Compared with a simple CV-CNN and LSTM, CV-CNN-LSTM is the best with regard to the speech enhancement performance test.
3. Neural Networks
3.1. Complex-Valued Convolution
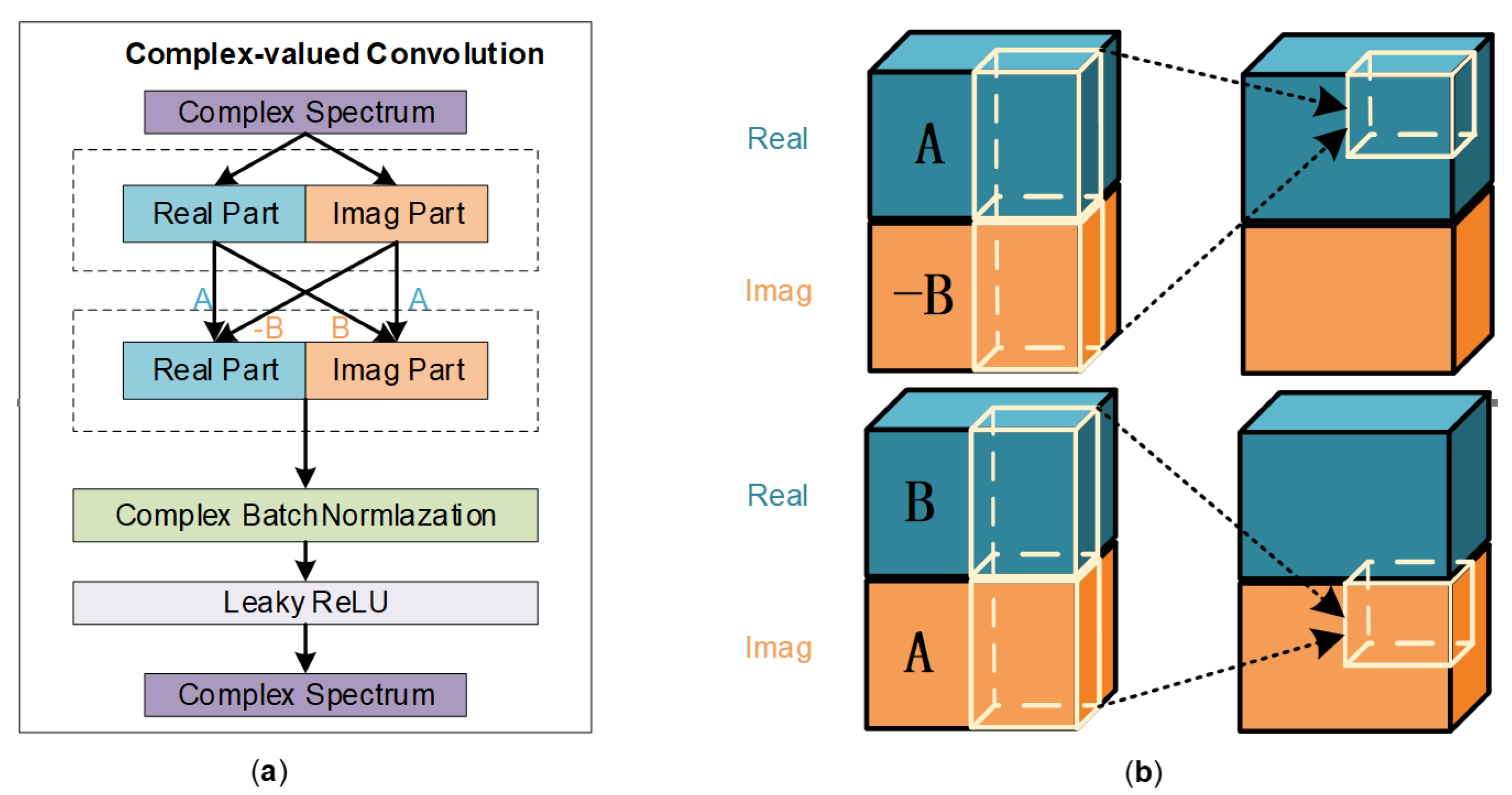
Complex-valued convolution is an operation in mathematics and signal processing in which two complex-valued functions are convolved with each other. A complex-valued spectrogram obtained by the STFT of a speech signal can be decomposed into real and imaginary parts in Cartesian coordinates. The CV-CNN convolves the real part and imaginary part, respectively, with two complex-valued functions. The complex-valued convolution filter, also known as kernels, is defined as
, where both
and
are real-valued matrices. The input complex matrix
is defined as
, and the complex-valued convolution operation on
with
is done by
. The operation process of complex-valued convolution is shown in
Figure 2.
The complex-valued convolutional layers constitute the main structural elements of a CV-CNN and extract features from the complex-valued input data. A complex-valued convolution can be implemented as a set of four convolutions with real-valued functions. The two complex-valued functions are separated into their real and imaginary components, and each component is convolved separately with the corresponding component of the other function. Thus four real-valued convolutions can be combined to form the final complex-valued convolution. These convolution kernels are two-dimensional (2D) since the one-dimensional (1D) speech time waveforms have been transformed into a complex-valued spectrogram with the application of the STFT. Since the spectrogram is complex-valued, the dot product is computed separately for the real and imaginary parts of the filter and the spectrogram, resulting in a complex-valued output at each position.
Multiple hidden layers are included in a typical complex-valued convolutional structure, which can extract features of high-dimensional data and learn nonlinear relationships adaptively. We add a batch normalization (BN) layer and a Leaky ReLu (LR) layer after each convolutional layer. The BN layer can improve the training stability and convergence speed of the network by normalizing the activations of the previous layer. When used after each convolutional layer, the BN layers can help to stabilize the training process by maintaining the variance and mean of the activations close to zero and one, respectively. The LR activation functions are a variant of the ReLu that allows a small gradient when the input is negative. The LR layer can help to introduce nonlinearity and improve the ability of the network to learn complex representations of the input data. A complete complex-valued convolutional network structure is shown in
Figure 3.
3.2. Long Short-Term Memory
When deep learning is applied to sequential data such as music, video and speech, it is important to model the long-term dependencies in the time series. RNNs are designed to process sequential data using the mechanism of recurrent feedback. However, RNNs are notoriously difficult to train due to the vanishing and exploding gradient issues. To overcome these problems, the LSTM was proposed as a special type of RNN. There are three important components inside the LSTM, including the input gate, forgetting gates and output gates. These gates allow the network to selectively retain or discard information from previous time steps, ensuring that relevant features of the sequential data are accurately captured. By selectively controlling the flow of information through the network, LSTMs can effectively model long-term dependencies and have become a widely used approach in various applications of sequential data analysis.
CV-CNN excels at learning time–frequency domain features in speech signals, but its ability to capture time dependence and long-term context information is limited. In contrast, LSTMs are adept at capturing long-term dependencies in speech signals, which may span across multiple time frames. This makes them well-suited for modeling the temporal structure of speech and reducing the impact of noise interference. By integrating LSTM with CV-CNN, we can build a model that effectively handles speech signals of different lengths without requiring extensive preprocessing. In order to be able to handle complex-valued features extracted by the CV-CNN, we use the CV-LSTM in the proposed model. Similar to CV-CNN, considering the real and imaginary components of the complex input
and
, the output of the CV-LSTM,
, can be defined as
where
and
represent two traditional LSTMs of the real part and the imaginary part.
3.3. Target and Loss Function
The target of model training is a complex ratio mask (CRM). CRM is a technique used in speech enhancement. It is a complex-valued function that estimates the ratio between the desired speech signal and the interfering noise signal. The CRM is computed by taking the complex ratio of the time–frequency representations of the desired speech and the noisy signal. The resulting CRM is then applied to the noisy signal to suppress the noise and enhance the desired speech signal. The CRM is able to capture the phase information of the signal, which is useful when the noise around the EFPI acoustic sensor is unstable, and its phase changes over time;
can be defined as
wre
and
denote the real and imaginary parts of the noisy complex-valued spectrogram obtained by the STFT, respectively. The real and imaginary parts of the clean speech complex-valued spectrogram obtained by the STFT are represented by
and
.
The loss function measures the discrepancy between the predicted output of the model and the true output, and the goal of the model is to minimize this discrepancy. In the present study, the scale-invariant signal-to-noise ratio (SI-SNR) is utilized. The SI-SNR is a metric commonly used to evaluate the performance of speech separation or source separation algorithms. It measures the ratio of the energy of the target speech signal to the energy of the interference or noise signal while being insensitive to the amplitude scaling of the separated signals. The SI-SNR can be defined as
where s is the reference signal and y is the estimated signal; the ||.|| operator denotes the L2 norm.
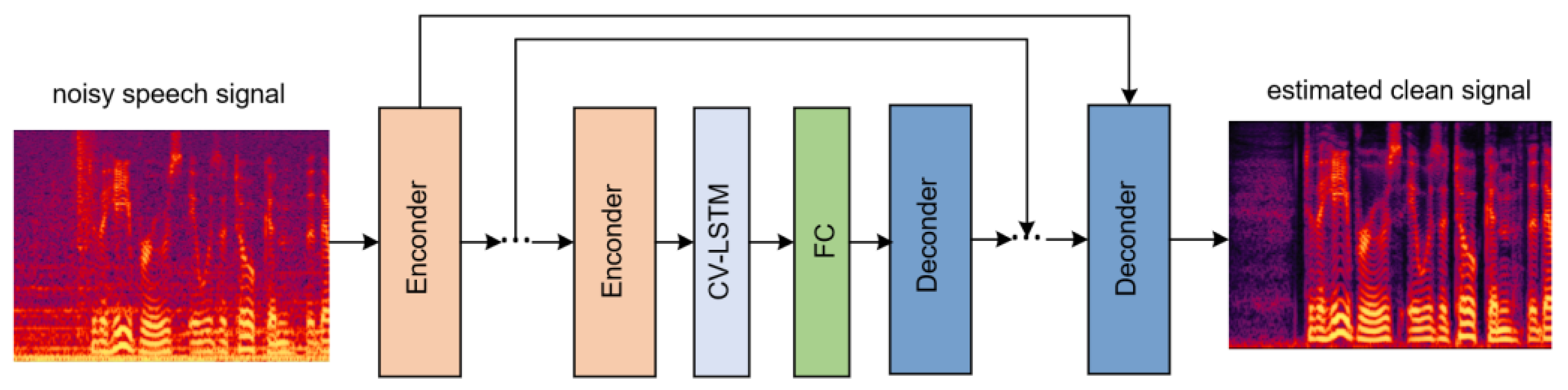
3.4. The CV-CNN-LSTM Model
In the present study, the CV-CNN-LSTM model mainly adopts the encoder–decoder structure. The encoder receives input and compresses it into a reduced representation, which is subsequently forwarded to a decoder. The decoder then generates an output based on this compressed representation. The encoder–decoder framework is commonly used in applications such as natural language processing, speech and audio processing and image and video processing.
In the CV-CNN-LSTM model, the encoder is the complete complex-valued convolution network structure mentioned in
Section 3.1. This encoder is composed of a complex-valued convolution layer, batch normalization layer and LeakyReLu layer. The decoder is similar in structure to the encoder, except that all 2D convolution functions are replaced by 2D transposed functions. The structure of the CV-CNN-LSTM model is shown in
Figure 4. This model consists of six encoder blocks, six decoder blocks and one CV-LSTM) layer. Moreover, the FC is a fully connected layer. The fully connected layers in the model are used to learn nonlinear combinations of features at a higher level of abstraction.
To improve the performance and training efficiency of the encoder–decoder architecture, we use skip connections between the encoder and decoder. Skip connections enable the network to reuse learned features from earlier layers in later layers, which can help to preserve important information and prevent that information from being lost during training. Additionally, with skip connections, the network can converge faster because it is easier to learn identity maps than to learn complex maps from scratch.
4. Results and Discussion
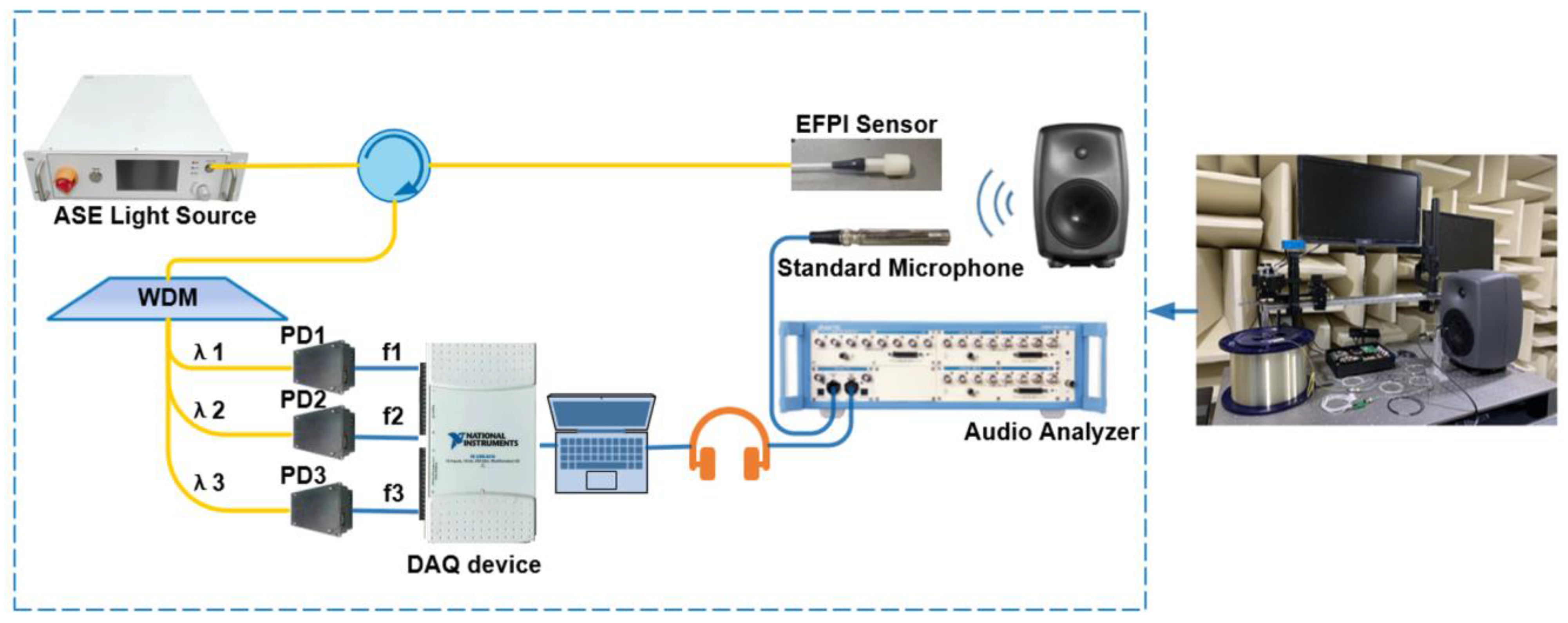
To ensure the normal demodulation of the optimized 3 × 3 algorithm, we first conducted a performance test in an anechoic chamber in which the three wavelengths are selected according to Equation (2): 1546.92 nm (
), 1550.92 nm (
) and 1554.94 nm (
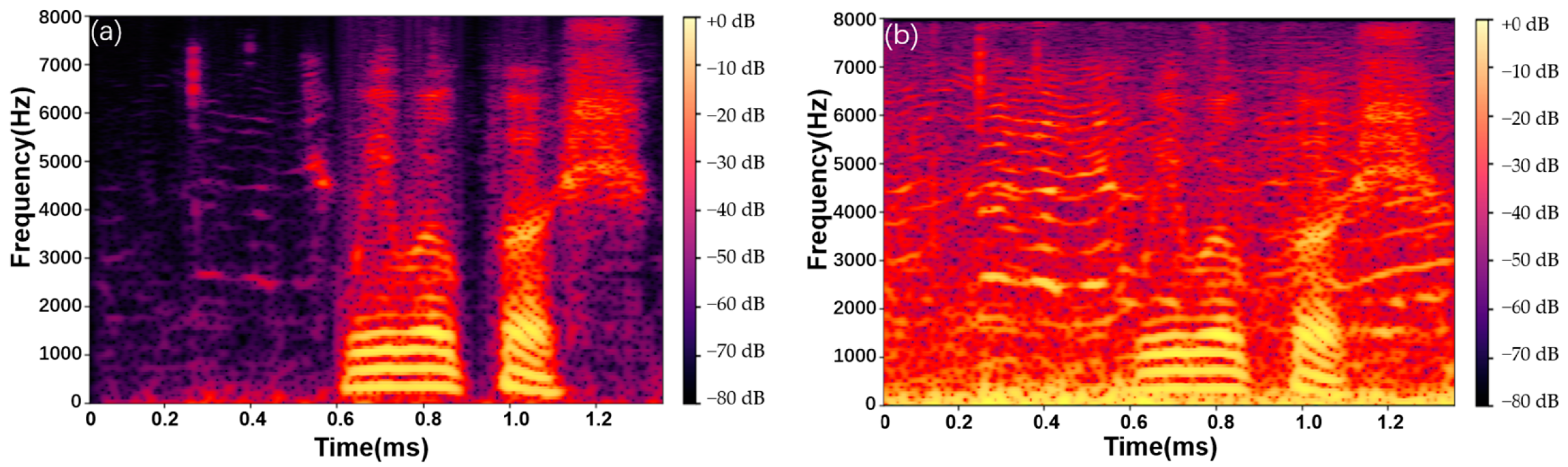
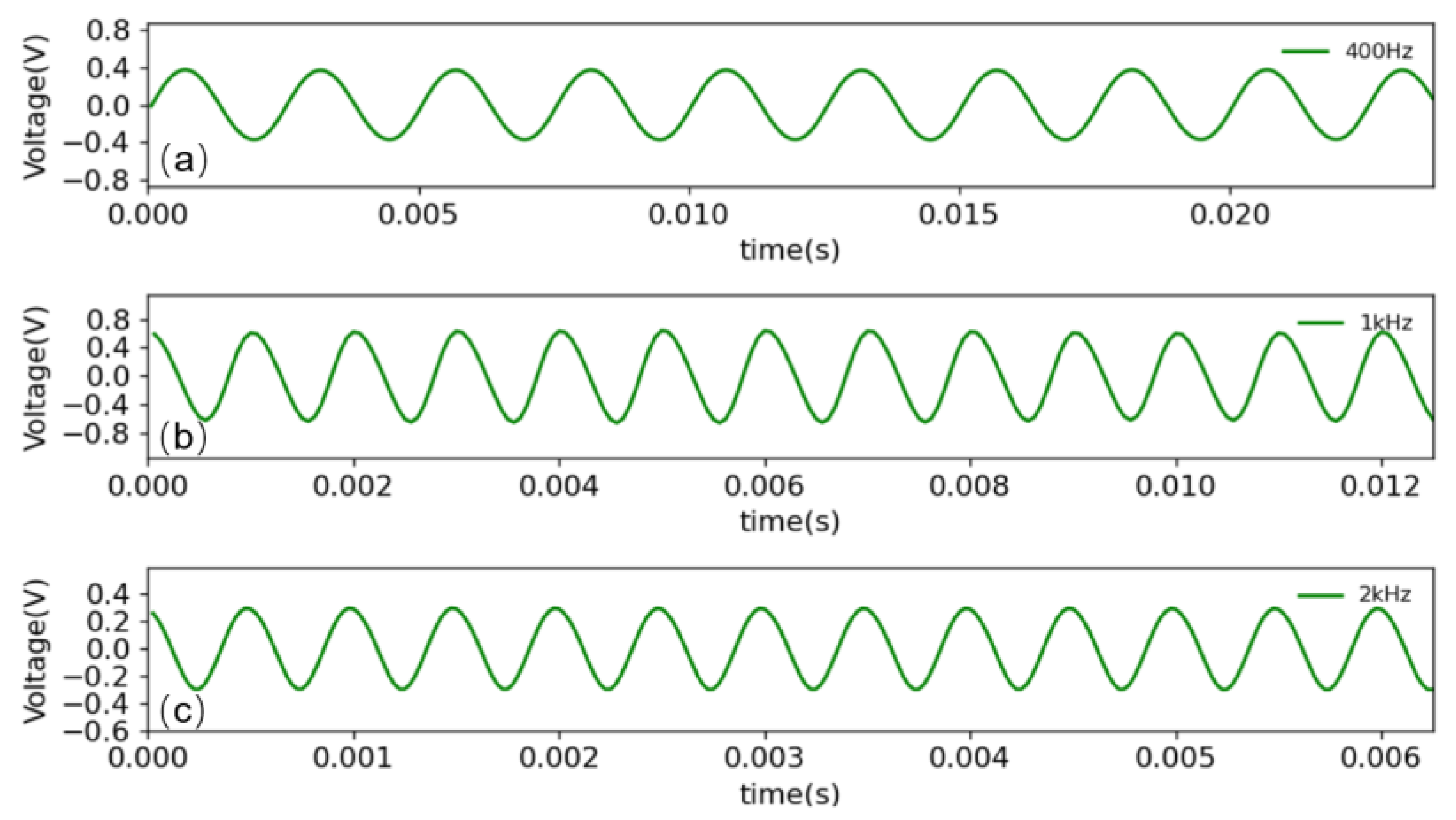
). The NI-USB6210 is used to collect and process the signals of the three PDs. The demodulated signals are connected to the audio analyzer through the earphones for testing. The demodulation effects of the different frequency signals are shown in
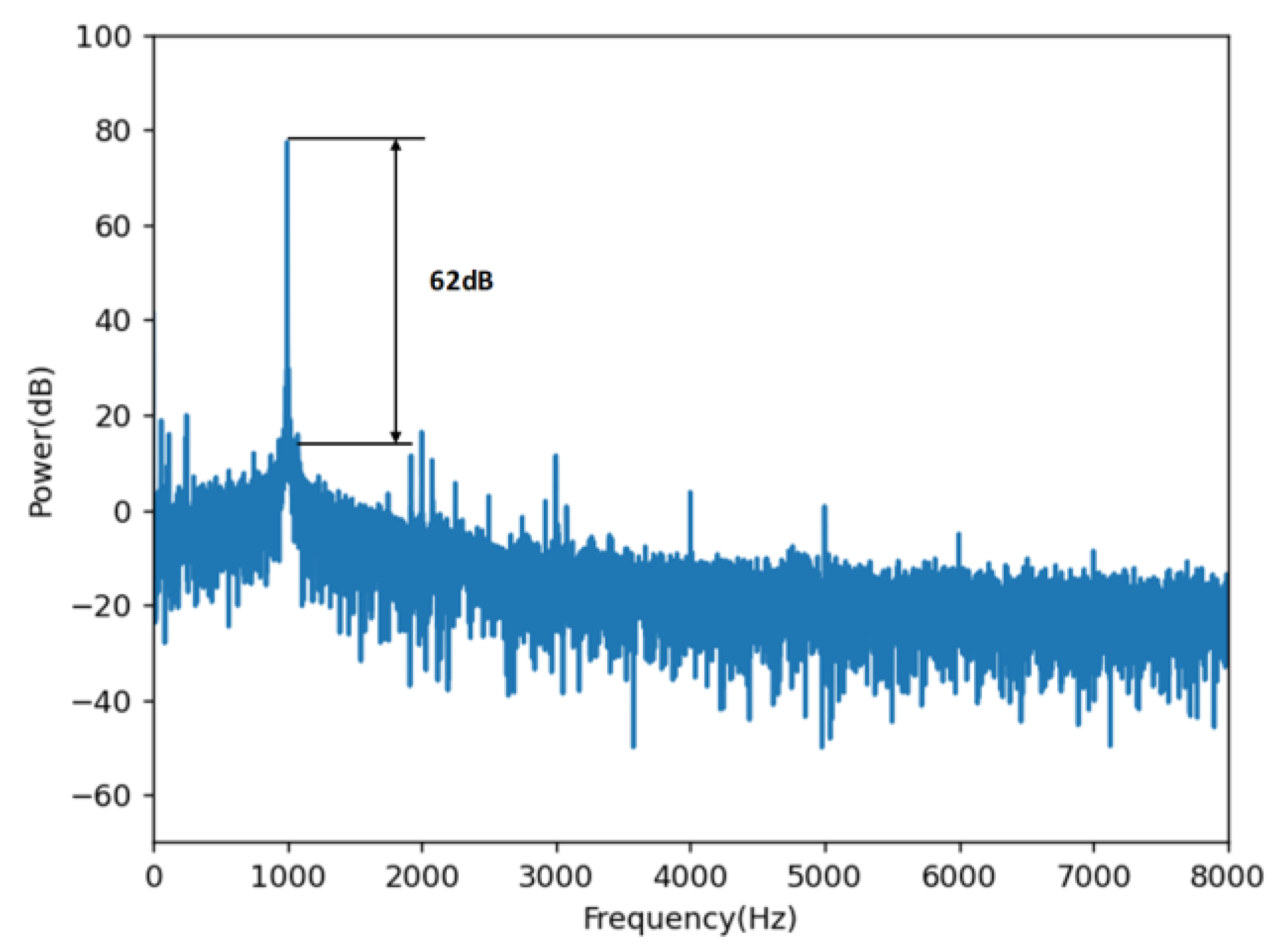
Figure 5. To obtain more detailed indicators, we used the audio analyzer test to evaluate the signal-to-noise ratio. The results, which reach a signal-to-noise ratio of 62 DB, are shown in
Figure 6.
In this study, our dataset is constructed from the 28 speakers dataset (28spk) [
27], which contains speech clips from 28 people. We randomly selected 6000 utterances from the 28spk corpus and divided them into three parts. There were 4800 utterances in the training set, 660 utterances in the validation set and 540 utterances in the test set. All utterances were played in the anechoic chamber through a high-quality speaker, and EFPI acoustic sensors were used to capture the speech signals. In the end, the audio was clipped to ten seconds, and we obtained approximately 16 h of paired clean and noisy utterances. The evaluation set is generated by randomly selecting utterances from the speech set and the noise set and mixing them at three signal-to-noise ratios (SNRs) (5 DB, 10 DB and 15 DB). According to the frequency range of the voice call, all the speech signals were sampled at 16 kHz. The design and implementation of the deep learning model for the speech enhancement of the EFPI acoustic sensor were held in a Python 3.8.3 environment using the deep learning tool Torch. Pytorch 1.7 was used as the backend of the Torch library. All experiments were performed on a desktop computer featuring an Intel Core i7-10700 2.90 GHz CPU, 32 GB RAM memory and a 10 GB NVIDIA GeForce RTX 3080 GPU.
Regarding the CV-CNN-LSTM model, the complex-valued spectrogram was extracted by using a Hamming window. The window length and hop size are 25 ms and 6.25 ms, respectively, and the FFT length is 512. The number of channels for the CV-CNN-LSTM is {32, 64, 128, 256, 256, 256}. The kernel size and stride are set to (5, 2) and (2, 1), respectively. The CV-LSTM layer uses a two-layer structure, the parameters of the two layers are the same, and each layer contains 128 hidden units. We chose Adam as the optimizer, set the initial learning rate to 0.001 and used ExponentialLR to control the change in the learning rate. We compare several models, including CNN, LSTM, CV-CNN and CV-LSTM, on the same dataset. The CNN model is structured with six 2D convolutional layers, each accompanied by a batch normalization layer and succeeded by a max-pooling layer. Channel counts for the CNN model are specified as {16, 32, 64, 64, 128, 128}, while kernel sizes and strides are consistently set to (3, 3) and (1, 1). The LSTM model contains two LSTM layers; each layer has 256 units, and the output layer is a fully-connected layer. Comprising six CV-CNN layers, the CV-CNN model boasts channel numbers of {16, 32, 64, 64, 128, 128} and identical kernel size and stride settings as its CNN counterpart. Lastly, the CV-LSTM model is composed of two CV-LSTM layers, and each LSTM layer has 256 units and utilizes two separate fully-connected layers to deliver the real and imaginary components of the results, respectively.
The evaluation of speech enhancement model performance is conducted using two widely-accepted and complementary metrics: Perceptual Evaluation of Speech Quality (PESQ) [
28] and Short-Time Objective Intelligibility (STOI) [
29]. PESQ scores generally range from −0.5 to 4.5, with higher values indicating superior speech quality. The STOI metric provides a normalized score between 0 and 1, where higher values correspond to greater speech intelligibility.
Table 1 and
Table 2 show the comparison of PESQ and STOI scores between the proposed model and other models. It can be seen that the proposed model has the best test results on data with different SNRs.
Furthermore, additional experiments were conducted to optimize the proposed model. In particular, the performance of the proposed model was evaluated while changing some of its parameters, namely, the window length of the STFT and the number of complex-valued convolutional layers. The window length is a key parameter in the STFT for the feature extraction of speech signals. Using a window length that is too long can result in poor time resolution. This results in a loss of important spectral information and increased spectral leakage. Conversely, if the window length is too short, it will result in a poor frequency resolution. This can lead to poor separation of the speech and noise components in the frequency domain, resulting in a low quality of enhanced speech. The experimental results of the window length comparison are shown in
Table 3 and
Table 4. It can be seen that the optimal window length is approximately 25 ms. The enhancement effect of the CV-CNN-LSTM model that uses different window lengths is shown in
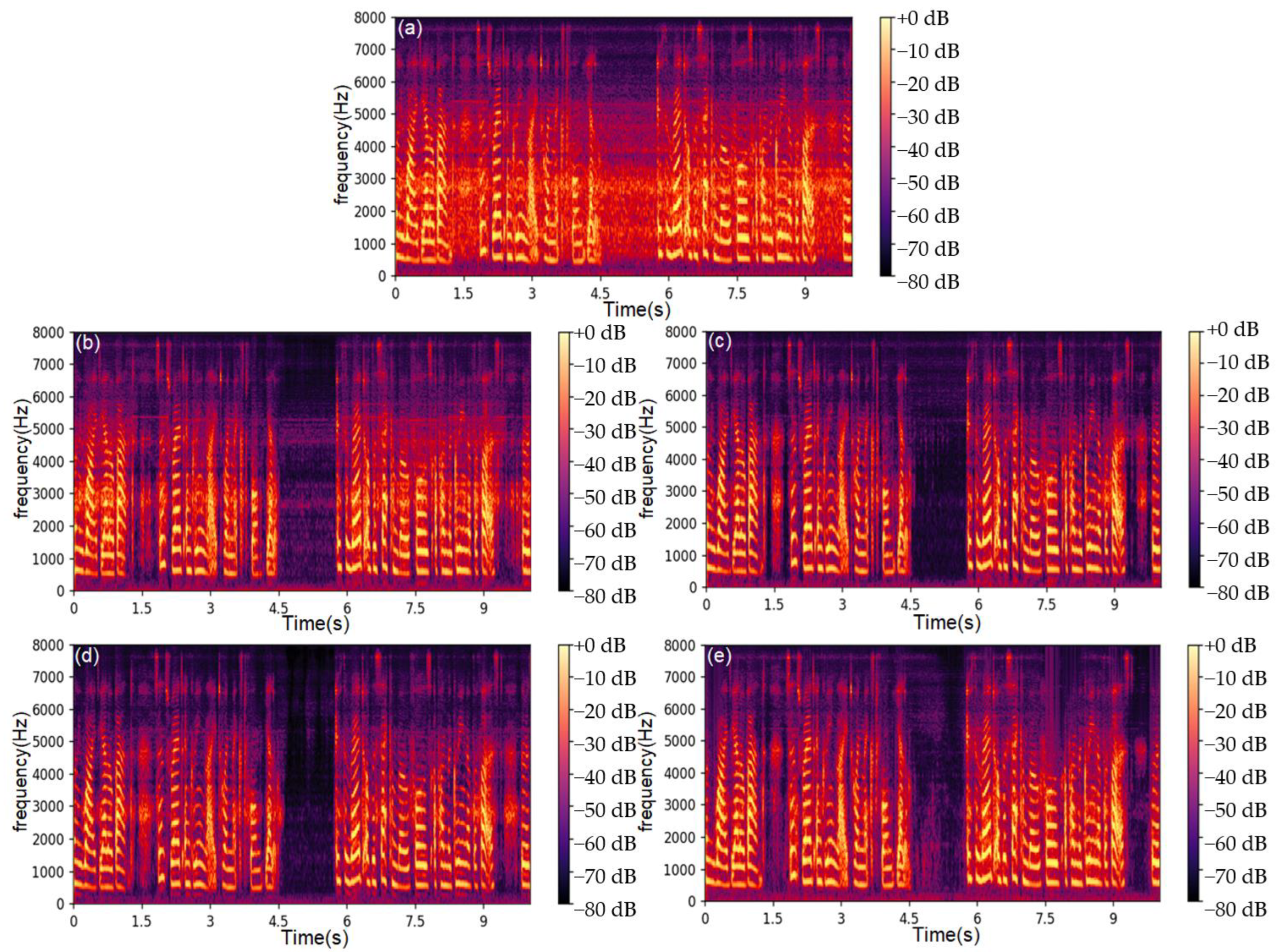
Figure 7. The noise signal used in
Figure 6 is a speech recording at an SNR of 10 dB.
The number of complex-valued convolutional layers also plays a significant role in the model’s performance. If the number is too low, the model may fail to capture crucial input data features effectively. On the other hand, excessive layers may lead to overfitting, resulting in good training set scores but poor performance on the test set.
Table 5 and
Table 6 show the performance of the proposed model for different numbers of complex-valued convolutional layers. The model was trained and tested using four to eight complex-valued convolutional layers in a structure similar to the one displayed in
Figure 4. As can be observed, both PESQ and STOI scores are highest when using six complex-valued convolutional layers in the CV-CNN-LSTM model.
5. Conclusions
In this paper, speech enhancement techniques based on fiber-optic EFPI acoustic sensors are studied. First, the speaker’s speech signal is demodulated by the fiber-optic EFPI acoustic sensor demodulated based on the 3 × 3 coupling algorithm, and then the speech signal is edited, and the edited speech signal is subjected to STFT to extract spectral features. The overall structure of the CV-CNN-LSTM model is implemented by combining CV-CNN and CV-LSTM. Among them, CV-CNN is suitable for processing complex-valued spectrogram data, while CV-LSTM is good at capturing the characteristics of sequential data related to time series. Experimental results show that the CV-CNN-LSTM model can achieve better performance than other models in terms of PESQ score and STOI score.
The speech enhancement technology in this paper is expected to be applied to the fields where traditional methods cannot be applied, such as high magnetic field environments, flammable and explosive environments and high electric field environments. Of course, the fiber-optic EFPI acoustic sensor process in this paper is more complex than electrical-based acoustic sensors. With the reduction of the cost of optoelectronic devices, the technology is expected to be used in fields such as deserts and polar regions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}