Figure 1.
Indicative vision setup for obtaining point clouds from different views. Two RealSense depth cameras are used, with a rotation option of the cameras around z-axis. In the simplest scenario, two pointclouds, one from each camera, are collected and merged into a single point cloud of the scene.
Figure 1.
Indicative vision setup for obtaining point clouds from different views. Two RealSense depth cameras are used, with a rotation option of the cameras around z-axis. In the simplest scenario, two pointclouds, one from each camera, are collected and merged into a single point cloud of the scene.
Figure 2.
Three different settings of collected validation data: merged point cloud from 3 views using 3D printed mushrooms (left), merged point cloud from 2 views using real mushrooms (center) and merged point cloud from multiple views (18) using 3D printed mushrooms (right).
Figure 2.
Three different settings of collected validation data: merged point cloud from 3 views using 3D printed mushrooms (left), merged point cloud from 2 views using real mushrooms (center) and merged point cloud from multiple views (18) using 3D printed mushrooms (right).
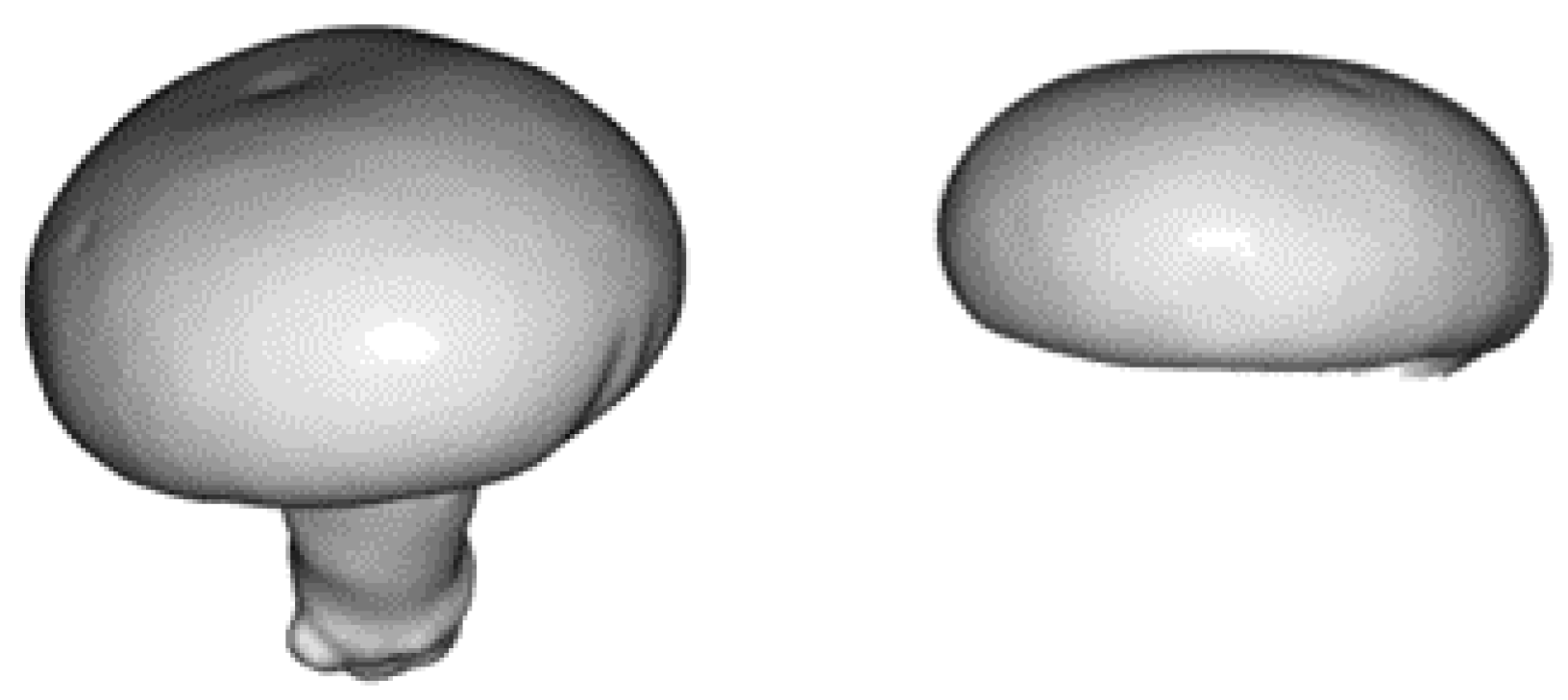
Figure 3.
The 3D mesh of the mushroom template. In practice, we used only the 3D model of the mushroom cap (right), instead of the whole mushroom mesh (left).
Figure 3.
The 3D mesh of the mushroom template. In practice, we used only the 3D model of the mushroom cap (right), instead of the whole mushroom mesh (left).
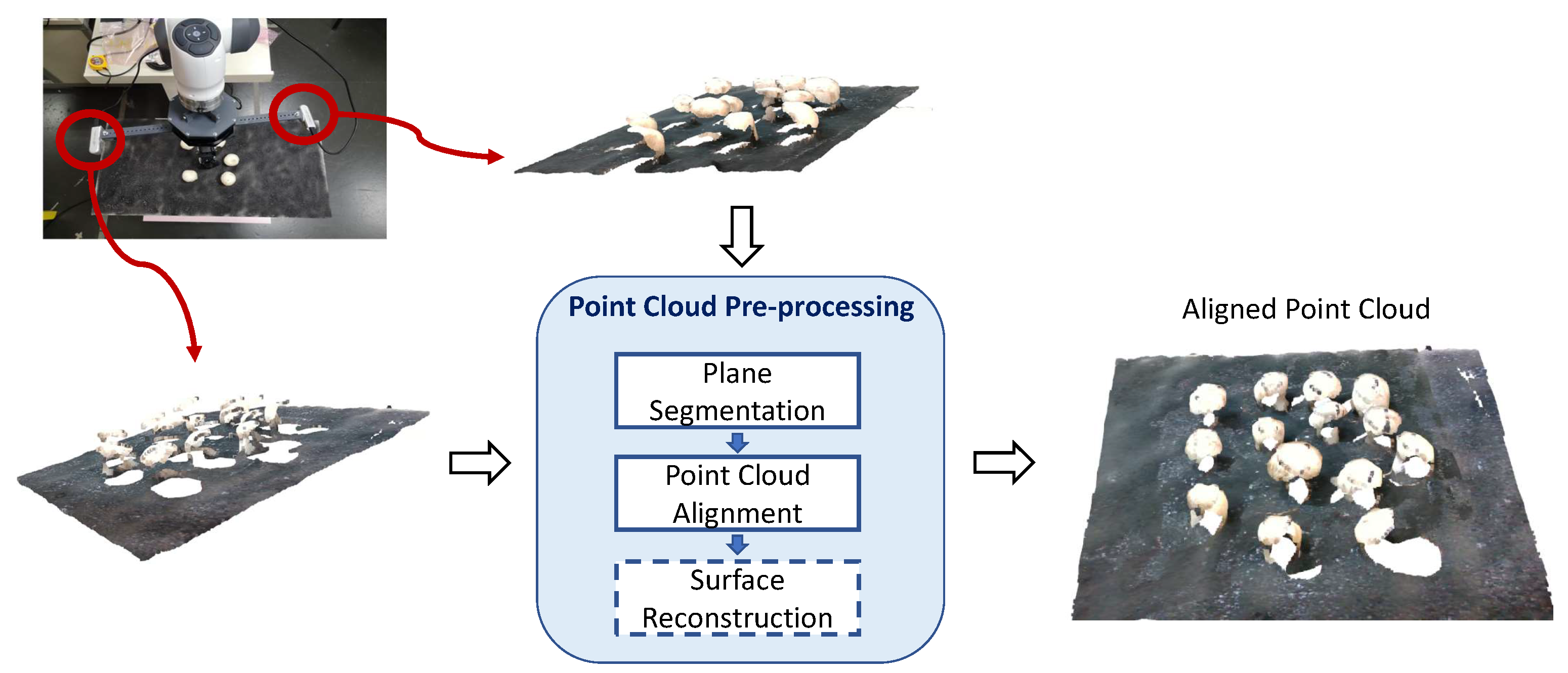
Figure 4.
Overview of the preprocessing steps. The input is a set of point clouds from different views. The surface reconstruction step is optional.
Figure 4.
Overview of the preprocessing steps. The input is a set of point clouds from different views. The surface reconstruction step is optional.
Figure 5.
Plane segmentation; points belonging to the detected ground plane are visualized with red color.
Figure 5.
Plane segmentation; points belonging to the detected ground plane are visualized with red color.
Figure 6.
Upper row: Examples of the initial alignment using the camera parameters, bottom row: Examples of the finer alignment of the developed method. Red boxes point out misalignments.
Figure 6.
Upper row: Examples of the initial alignment using the camera parameters, bottom row: Examples of the finer alignment of the developed method. Red boxes point out misalignments.
Figure 7.
Reconstructed mesh overlaid by the initial point cloud.
Figure 7.
Reconstructed mesh overlaid by the initial point cloud.
Figure 8.
Visualization of the reconstructed mesh for different viewpoints.
Figure 8.
Visualization of the reconstructed mesh for different viewpoints.
Figure 9.
Visualization of the RANSAC-based estimation results for FPFH (first column) and FCGF (second column) features.
Figure 9.
Visualization of the RANSAC-based estimation results for FPFH (first column) and FCGF (second column) features.
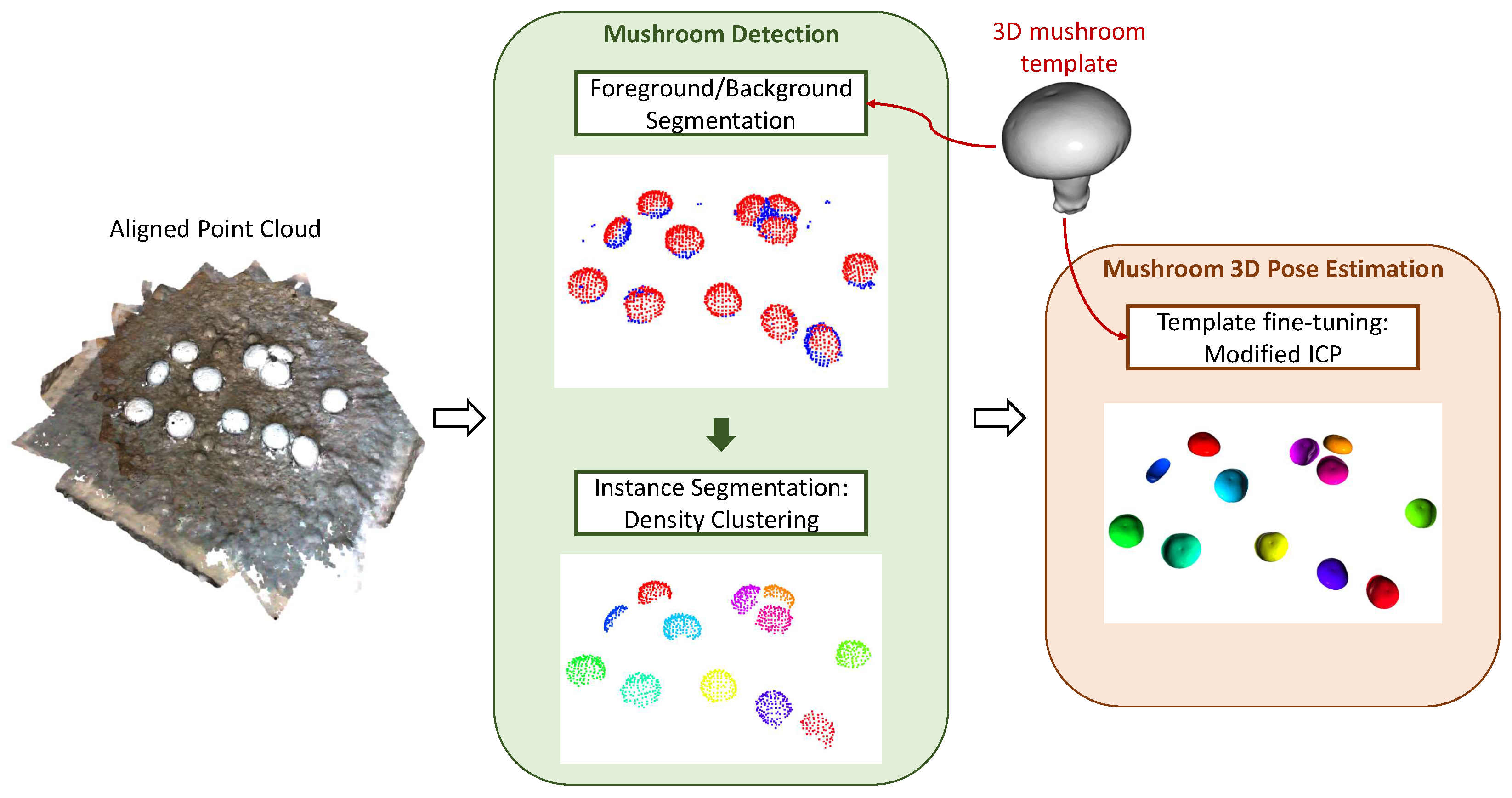
Figure 10.
Overview of the proposed pipeline. The two main functionalities are mushroom detection and mushroom pose estimation. Visualization examples of each step/sub-step are provided.
Figure 10.
Overview of the proposed pipeline. The two main functionalities are mushroom detection and mushroom pose estimation. Visualization examples of each step/sub-step are provided.
Figure 11.
Examples of mushroom segmentation; points belonging to a mushroom are depicted with red color, while background points with blue. Two variants are depicted: (a) only one template point cloud is considered and (b) a set of augmented template point clouds are considered.
Figure 11.
Examples of mushroom segmentation; points belonging to a mushroom are depicted with red color, while background points with blue. Two variants are depicted: (a) only one template point cloud is considered and (b) a set of augmented template point clouds are considered.
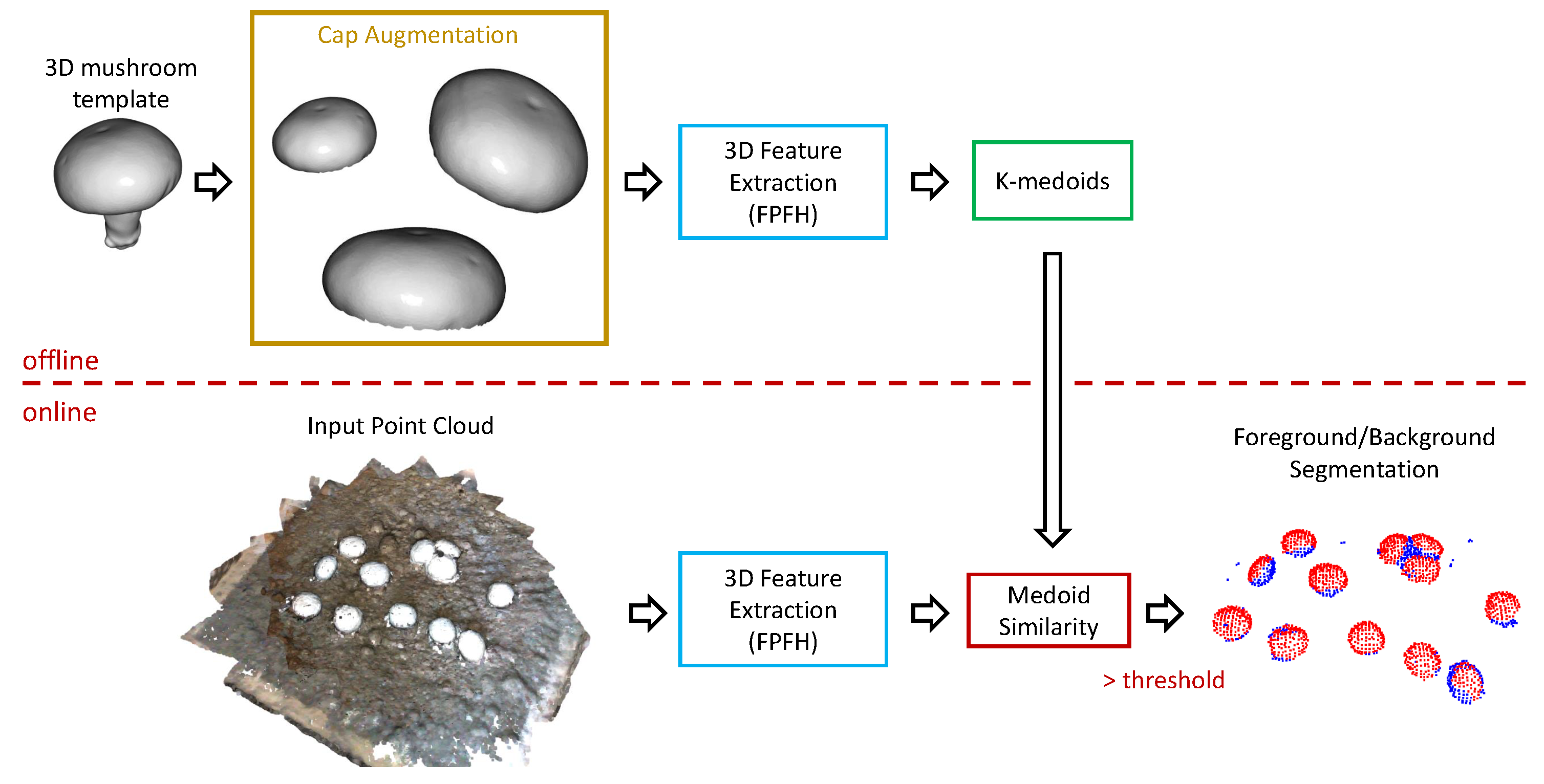
Figure 12.
Overview of foreground/background separation. Augmentation of the template (only the cap), and clustering of the 3D features of the augmented set with a k-medoids algorithm, was applied offline. For the “online” processing of a new point cloud we simply compared the 3D feature of each point with the already computed medoids. If cosine similarity was above a user-defined threshold, the point was considered a mushroom point (i.e., foreground point).
Figure 12.
Overview of foreground/background separation. Augmentation of the template (only the cap), and clustering of the 3D features of the augmented set with a k-medoids algorithm, was applied offline. For the “online” processing of a new point cloud we simply compared the 3D feature of each point with the already computed medoids. If cosine similarity was above a user-defined threshold, the point was considered a mushroom point (i.e., foreground point).
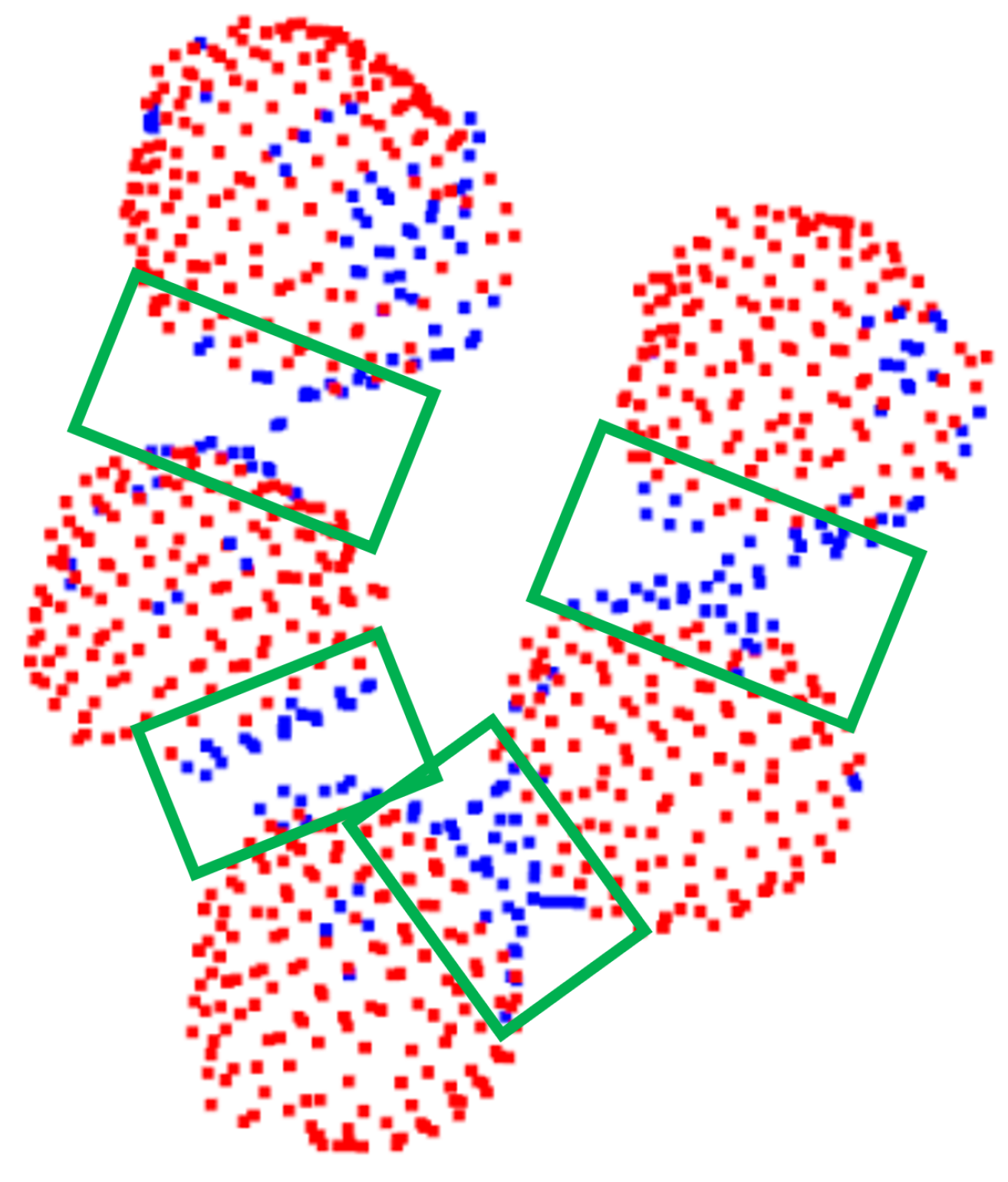
Figure 13.
Example of foreground/background separation of neighboring mushrooms. Note that regions of “contact”, denoted with green boxes, were not recognized as mushrooms. Red points are classified as mushroom points (foreground) while blue points are not relevant points (background).
Figure 13.
Example of foreground/background separation of neighboring mushrooms. Note that regions of “contact”, denoted with green boxes, were not recognized as mushrooms. Red points are classified as mushroom points (foreground) while blue points are not relevant points (background).
Figure 14.
Visualization of the density clustering step over the foreground/background separation results. Different colors denote different clusters.
Figure 14.
Visualization of the density clustering step over the foreground/background separation results. Different colors denote different clusters.
Figure 15.
Visualization of three distinct (starting, intermediate and ending) steps of the developed ICP variant.
Figure 15.
Visualization of three distinct (starting, intermediate and ending) steps of the developed ICP variant.
Figure 16.
Detected mushrooms as template meshes of different colors.
Figure 16.
Detected mushrooms as template meshes of different colors.
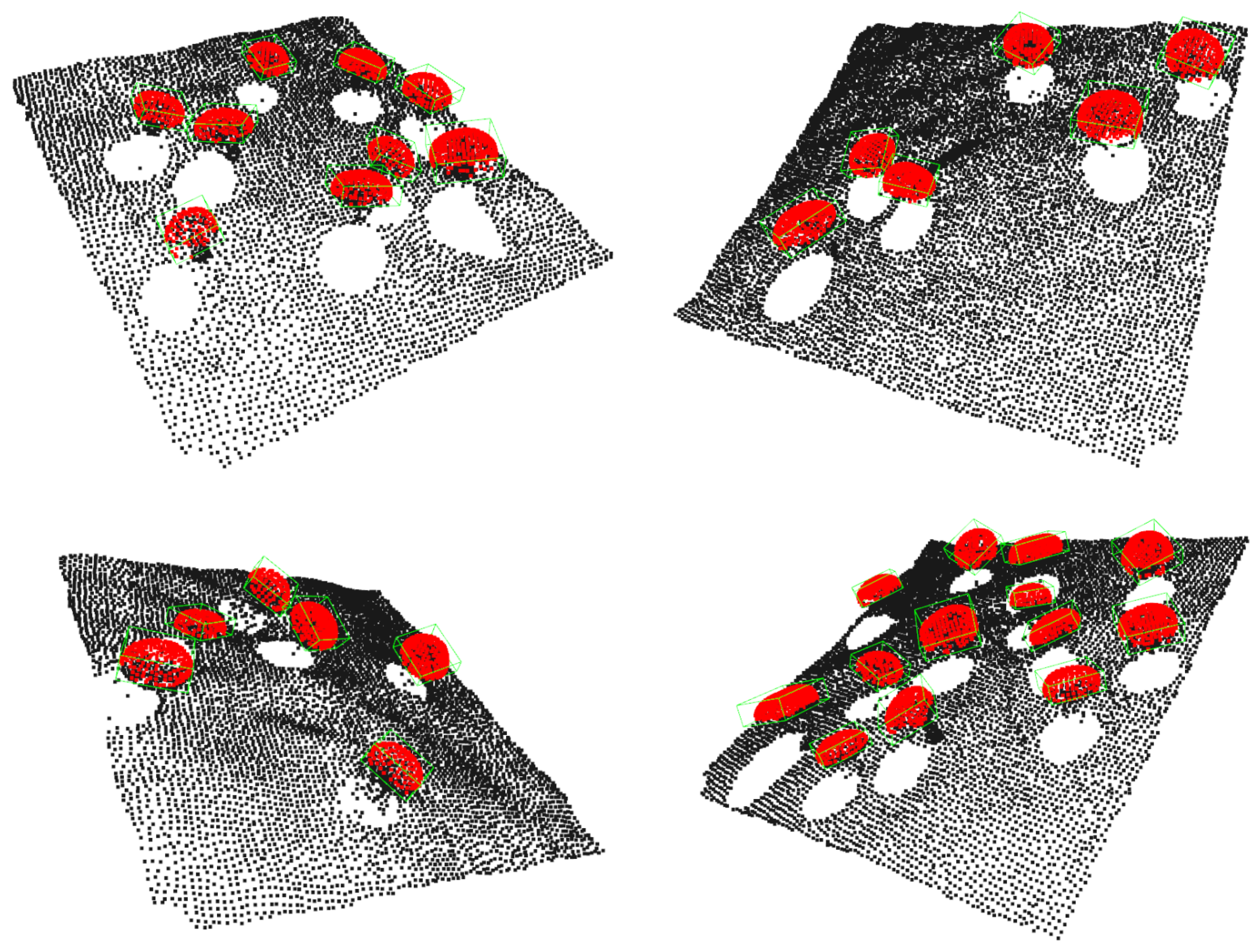
Figure 17.
Mushroom pose estimation results in the form of oriented bounding boxes.
Figure 17.
Mushroom pose estimation results in the form of oriented bounding boxes.
Figure 18.
Examples of (a) successful and (b) erroneous ellipsoid fitting.
Figure 18.
Examples of (a) successful and (b) erroneous ellipsoid fitting.
Figure 19.
Examples of synthetic mushroom scenes. Mushroom caps are highlighted with red color.
Figure 19.
Examples of synthetic mushroom scenes. Mushroom caps are highlighted with red color.
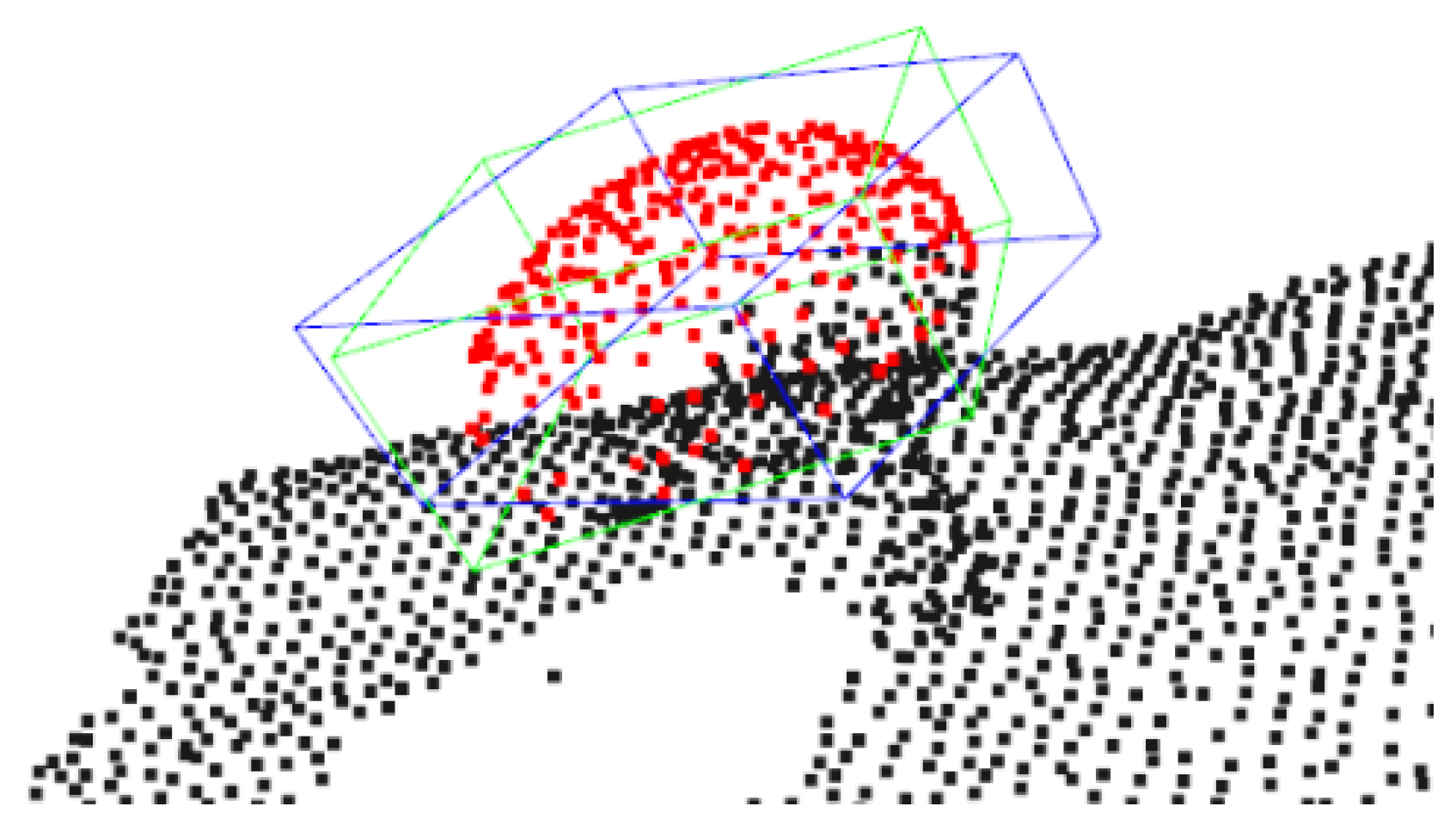
Figure 20.
Two bounding boxes of very similar pose that report an overlap IoU value of 60%. The green box denotes the ground truth box, while the blue box denotes the predicted bounding box.
Figure 20.
Two bounding boxes of very similar pose that report an overlap IoU value of 60%. The green box denotes the ground truth box, while the blue box denotes the predicted bounding box.
Figure 21.
Visualization of the proposed steps when real data were considered. From left to right: (1) initial point cloud, (2) foreground/background separation, (3) instance segmentation, (4) template matching, (5) fitted templates overlaid over the initial pointcloud. The first three rows correspond to point cloud from multiple viewpoints of a rotating vision system, while the last two correspond to point clouds of two opposite views.
Figure 21.
Visualization of the proposed steps when real data were considered. From left to right: (1) initial point cloud, (2) foreground/background separation, (3) instance segmentation, (4) template matching, (5) fitted templates overlaid over the initial pointcloud. The first three rows correspond to point cloud from multiple viewpoints of a rotating vision system, while the last two correspond to point clouds of two opposite views.
Table 1.
Comparison of the RANSAC-based approach and the proposed pipeline.
Table 1.
Comparison of the RANSAC-based approach and the proposed pipeline.
| Method | MAP @ 25% IoU | MAP @ 50% IoU |
|---|
| RANSAC-based Approach | 90.89% | 53.62% |
| Proposed Approach | 99.80% | 96.31% |
Table 2.
Impact of different 3D features. FPFH [
27] and FCGF [
28] were considered.
Table 2.
Impact of different 3D features. FPFH [
27] and FCGF [
28] were considered.
| 3D Features | MAP @ 25% IoU | MAP @ 50% IoU |
|---|
| FCGF | 99.63% | 24.75% |
| FPFH | 99.80% | 96.31% |
Table 3.
Impact of the ICP template fine-tuning step. Typical ICP and the proposed modification are compared.
Table 3.
Impact of the ICP template fine-tuning step. Typical ICP and the proposed modification are compared.
| Template Alignment | MAP @ 25% IoU | MAP @ 50% IoU |
|---|
| basic ICP | 98.33% | 45.92% |
| modified ICP | 99.80% | 96.31% |
Table 4.
Impact of the optional mesh reconstruction preprocessing step.
Table 4.
Impact of the optional mesh reconstruction preprocessing step.
| | w/Surface Reconstruction | w/o Surface Reconstruction |
|---|
| MAP @ 50% IoU: | 96.36 ± 2.02% | 96.31 ± 0.92% |
Table 5.
Comparison between the ellipsoid-based pose estimation and the proposed template matching ICP variant.
Table 5.
Comparison between the ellipsoid-based pose estimation and the proposed template matching ICP variant.
| | Ellipsoid Variant | Modified ICP |
|---|
| MAP @ 50% IoU: | 89.09% | 96.31% |
Table 6.
Pose Estimation in terms of cosine similarity between rotation vectors. Mean and median cosine metrics were computed for detection over a specified IoU threshold.
Table 6.
Pose Estimation in terms of cosine similarity between rotation vectors. Mean and median cosine metrics were computed for detection over a specified IoU threshold.
| | 25% IoU | 50% IoU |
|---|
| mean cos. similarity: | 0.9885 | 0.9920 |
| mean angle error: | 8.70 | 7.27 |
| median cos. similarity: | 0.9927 | 0.9948 |
| median angle error: | 6.93 | 5.85 |
Table 7.
Detection and pose estimation results for a standard registration pipeline (RANSAC+ICP) applied on segmented mushrooms regions. We report both MAP and angle error for detections over 25% IoU.
Table 7.
Detection and pose estimation results for a standard registration pipeline (RANSAC+ICP) applied on segmented mushrooms regions. We report both MAP and angle error for detections over 25% IoU.
| | MAP | (Mean) Angle Error |
|---|
| segmented RANSAC+ICP | 91.78% | 13.77 |
| proposed | 99.80% | 8.70 |

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}