3.2. FSUs Assignment Algorithms for WSW1(4, n, r) Switching Fabrics
The objective of this section is to describe how FSUs should be assigned to the connections in the switching fabrics. In a space-division switching fabric, a connection path, i.e., a set of resources used by a given connection, is composed of swithching elements (SEs) and interstage links (ILs) used by the connection. When two connections must use the same IL at the same time, one of these connections is blocked. In an EON switching fabric there is another dimension, wavelength. In this case, the connection path is determined not only by a set of SEs and ILs, but also by a set of FSUs on a given IL. To find two blocking connections, it is necessary to determine not only whether the connection paths of these two connections use the same IL(ILs), but also whether they use at least one common FSU.
The process of assigning FSUs to connection paths so that they do not block each other can be implemented in a way similar to that proposed in [
15]. However, in the considered
switching fabric, the problem is much more complex, due to the larger number of inputs and outputs, resulting in a larger number of possible permutations. We propose six distinct FSUs assignment algorithms, denoted as
,
,
,
,
, and
. Then, we try to find the best one, or a group of them, for which the number
k of required FSUs in ILs will be the lowest, yet allowing the realization of all possible sets of compatible connections [
33].
The main idea of all proposed algorithms is to divide all FSUs in ILs into two subsets, in which we will establish connections corresponding to different
. Of course, the wavelength intervals of FSUs used for the connections represented by
at the input port may be different from those assigned to these connections in ILs. The wavelength shift is the task of BV-WBCSs, from which the outermost sections are constructed. To determine the conditions under which all possible
can be realized in
(that is, it is RNB, as shown in [
33]), we have to find the required value of
k in each IL as the maximum value of the sum of the number of FSUs in both subsets.
To proceed with the description of the assignment algorithms, we have to add an important assumption about
. Each set of compatible connections in
is represented by a different state of the matrix
. We can reduce the number of states considered, assuming that
is equal to or greater than the rest of the elements in
. Similarly,
is equal to or greater than the other elements, except for those in row 1 and column 1 [
34]. Finally,
is equal to or greater than all the remaining elements in
from rows 1 and 2 and elements from column 1 and 2. This property can be written as
This assumption does not change the FSUs assignment process or the final result, but simplifies the explanation of the algorithms, their structure, and operation. If the criteria in (
5) are not satisfied, the input and/or output stages, represented as rows and/or columns in the matrix
, should be modified by rearranging. For example, if the element
is greater than
,
is replaced with
and
with
, which makes
become
.
To make it possible for each algorithm to assign FSUs to connections, we introduce the concept of subregions and critical pairs. The rows and columns of the matrix represent the inputs and outputs of , respectively. Two elements located in the same row/column represent connections from/to the same input/output, and cannot occupy the same FSUs in ILs. Otherwise, the connections represented by one of these elements are blocked. For example, the connections represented by and may use the same set of FSUs since they come from and go to different outer stage switches. We call such elements “matched”. On the other hand, the connections represented by and have to use different FSUs, as they are directed to the same output switch, and we call them “mismatched”. Let us divide the elements of each row and each column into two pairs of elements, creating four groups of four elements each.
Definition 1. Let represent in switching fabric working under algorithm , where . Each algorithm divides into four disjoint subsets called quarters (denoted as , where ). Each consists of four elements , which form two pairs of matched elements.
The way each algorithm assigns elements
to quarters is shown in
Figure 2. In each assignment, we can find pairs of
’s that are not in the same columns or rows. We surround these pairs with the same type of line and the same color, and the corresponding connections can occupy the same set of FSUs in ILs (elements matched). In contrast,
’s surrounded by different line types always share the same rows or columns, i.e., they are mismatched (having to occupy disjoint sets of FSUs in ILs). For instance, in
the quarters
and
contain
,
,
,
and
,
,
, and
, respectively; these quarters are matched. In
, elements
and
, as well as
and
, are matched, while
and
, as well as
and
, or
and
, as well as
and
, are mismatched. When assigning slots, there will be no conflict between connections when mismatched quarters use disjoint sets of FSUs. Such mismatched quarters will be called “subregions”.
Definition 2. Two mismatched quarters obtained in by the algorithm are called subregions. The subregions are denoted as ADx.j, where and .
The divisions of
elements into subregions for algorithms
,
, and
are shown in
Figure 3. Each of the four rectangles surrounding the matrix
consists of a quarter surrounded by a solid line and a quarter surrounded by a dashed line (see
Figure 3). When we have subregions determined by
, we have to divide the set of FSUs in ILs into two subsets,
and
; slots in each subset will be used for connections represented in different quarters in subregions. As a result, the total number of FSUs in ILs for algorithm
, denoted by
is determined by the sum of slots needed in
and
, that is,
Any
can be realized by using
when we maximize (
6) through all
s, that is, when
The connections shown in
Figure 1 are set by using
, and the set of FSUs in each IL is divided into subsets
and
by bold vertical lines.
As we have
divided into subregions, we will now show how the algorithms assign FSUs to connections. We discuss here only
to limit the length of the paper; the assignment procedure for the other algorithms can be easily derived by analogy. First, we consider the connections represented by elements in
and
, and the FSUs assigned to these connections will form the set
. The connections in
and
are matched, so they can use the same set of FSUs in ILs from
and
numbered from 1 to
;
. Similarly, the connections in
and
are matched, so they can use the same set of FSUs in ILs from
and
and are numbered from 1 to
;
. The connections in
and
are also matched, but are mismatched with connections in
and
; therefore, they can use FSUs from
to
+
and from
to
+
. The same approach can be used for the connections in
and
—that is, they can use FSUs from
to
+
and from
to
+
. As a result, we have already assigned
a FSUs and
;
;
; from property (
3)
and
. Next, we have to consider the connections represented by elements in
and
, and the FSUs assigned to these connections will form the set
. By analogy, this set will contain FSUs numbered from
to
; where
;
} and
;
}.
The
is listed as Algorithm 1, and the detailed assignment of FSUs is shown in
Table 1. Similar procedures and tables can be obtained for algorithms from
to
by comparing
presented in
Figure 2b–f with that obtained for
(
Figure 2a), and by comparing how FSUs are assigned to elements of
in
Table 1.
| Algorithm 1: () |
Data: Result: FSUs assigned to connections in - 1
Create matrix - 2
Assign FSUs to the connections according to Table 1
|
3.3. The Maximum Number of FSUs in the Algorithms
We now determine the maximum number of FSUsto be occupied by each pair of mismatched quarters; that is, we derive the maximum values for (
7) for each algorithm. The number of FSUs required by each
and each
depends on the elements of
surrounded by solid and dashed lines, respectively. Similarly, as in the description of the algorithms, we provide a detailed analysis for
and present the final equations for the remaining algorithms. From
Table 1, we obtain
and
In general, each element of each pair in (
8) and (
9) can be greater. Therefore, we must consider all the cases to determine the maximum needed value of
k. When the first sums in (
8) and (
9) are greater, we choose the maximum between pairs (
;
), (
;
), (
;
), and (
;
). The elements in these pairs form the subregion AD1.1 (see
Figure 3a). In the subregions ADx.1 and ADx.4, quarters are placed horizontally (H), while in ADx.2 and ADx.3, quarters are placed vertically (V). The elements with maximum values in the subregions can be located in four scenarios: HH, HV, VH, and VV (see
Figure 4), while in each scenario we have four cases denoted by (a), (b), (c), and (d). These cases for scenario HH in AD1.1 are presented in
Figure 5.
In the equations listed in
Appendix A, we provide the results for the possible maximum values of Equation (
7) for all the scenarios and cases for
. When creating these formulas, we take into account the properties (
3) and (
5). Here we explain two cases. In the AD1.1 scenario HH and case (a)
,
,
, and
are the maximum values. This means that
, and this sum is equal to
n (
3). In the same scenario, but in case (c), we have
and
. The maximum value of
can be
n. However, since
we get
and
Since
, the maximum value of
+
=
n −
, i.e.,
. As the result,
=
.
The listed equations give the maximum values of
k for a given subregion, scenario, and case. Now, we have to find for which of these equations
k reaches the highest value through all possible
s, that is
When we look at
Table 2, where we included the results of all subregions, scenarios, and cases for algorithms
,
, and
, we can conclude that
n ≤
≤
. This means that there are
s for which we can realize all connections in less than
slots, but there are also cases where
requires
slots. However, when we need
slots for
in the algorithm
, we may need less than
slots when using another algorithm, for example
or
. The results of these algorithms are also included in
Table 2. We omit
and
, because the arrangement of elements in
is similar to the transpose of
, and the arrangement of elements in
is similar to the transpose of
; moreover, the results for these algorithms are exactly the same as for
and
, respectively. The problem of finding the best value of
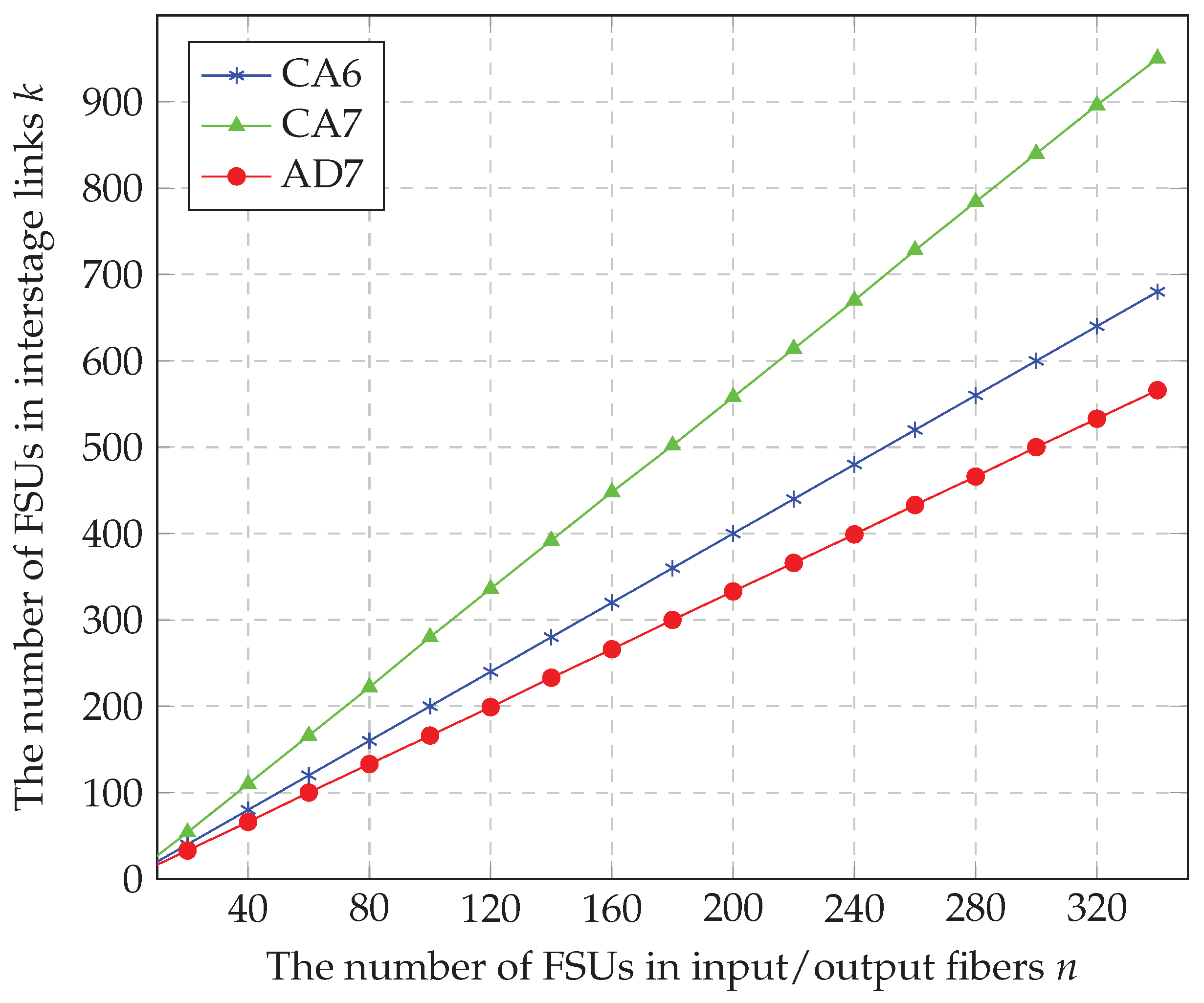
k when all the algorithms are used is the subject of the next section.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}