


HPnet: Hybrid Parallel Network for Human Pose Estimation


Abstract
:1. Introduction
- We propose a novel Hybrid Parallel network (HPnet) to localize the keypoints. The HPnet leverages the capabilities of the self-attention-based model and CNN-based model.
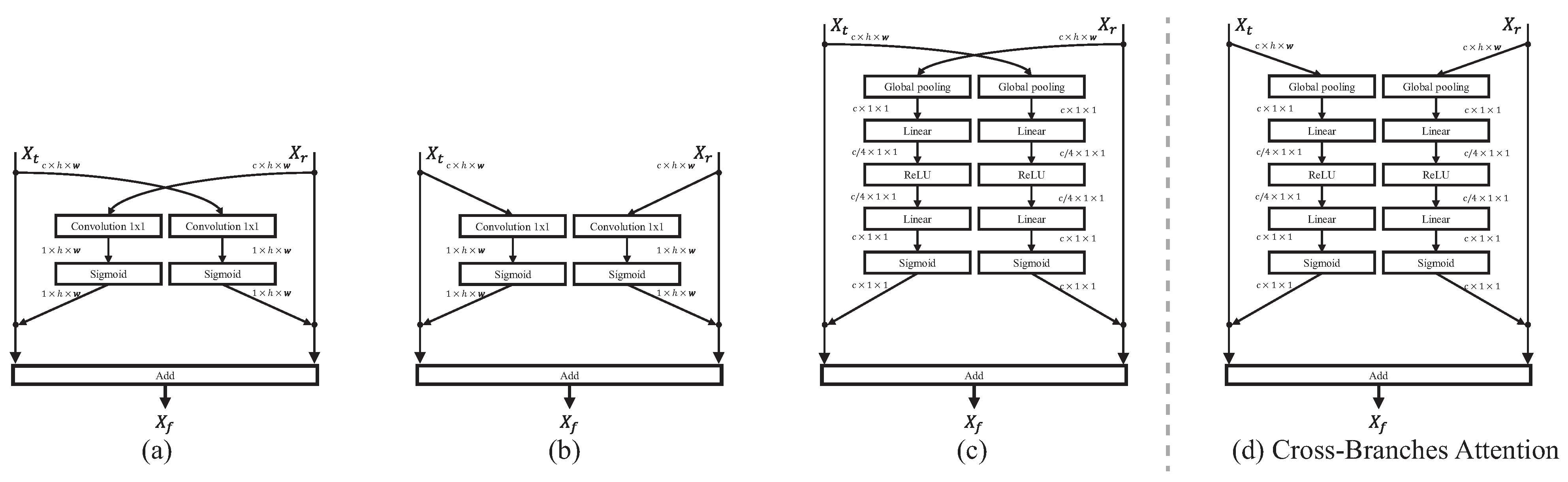
- We develop a cross-branches attention block(CBA) to fusion the parallel features generated by both branches. The cross-branches attention mitigates the semantic conflict.
- We evaluate our model on the COCO keypoints dataset, and the performance is comparable to the state-of-the-art methods.
2. Related Works
2.1. Human Pose Estimation
2.2. Hybrid Models
2.3. Attention Mechanism
3. Method
3.1. Overall Framework
3.2. The Parallel Branches
3.3. The Convolutional Branch
3.4. The Cross-Branches Attention
3.5. Loss
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implement Detail
4.2. Results on Coco Keypoint Detection Task
4.3. Results on MPII Dataset
4.4. Ablation Study
4.4.1. Effectiveness of the Self-Attention Branch
4.4.2. Effectiveness of the Cross-Branches Attention
4.4.3. Hyperpramameter Tuning
5. Discussion
5.1. Performance at Each Type of Joint
5.2. Location Errors Analysis
5.3. Failure Cases Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards Accurate Multi-person Pose Estimation in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 3711–3719. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Zhu, Z.; Huang, T.; Xu, M.; Shi, B.; Cheng, W.; Bai, X. Progressive and aligned pose attention transfer for person image generation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4306–4320. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.Y.; Yang, X.; Liu, M.Y.; Wang, T.C.; Lu, Y.D.; Yang, M.H.; Kautz, J. Dancing to Music. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 3581–3591. [Google Scholar]
- Hou, Y.; Yao, H.; Sun, X.; Li, H. Soul Dancer: Emotion-Based Human Action Generation. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 15, 99:1–99:19. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VI. pp. 472–487. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Jiang, W.; Jin, S.; Liu, W.; Qian, C.; Luo, P.; Liu, S. PoseTrans: A Simple Yet Effective Pose Transformation Augmentation for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V. pp. 643–659. [Google Scholar]
- Wang, D.; Xie, W.; Cai, Y.; Liu, X. A Fast and Effective Transformer for Human Pose Estimation. IEEE Signal Process. Lett. 2022, 29, 992–996. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar] [CrossRef]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context Attention for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5669–5678. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII. pp. 483–499. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11025–11034. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-Trained Image Processing Transformer. arXiv 2020, arXiv:2012.00364. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-End Human Pose and Mesh Reconstruction with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 1954–1963. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 11636–11645. [Google Scholar]
- Stoffl, L.; Vidal, M.; Mathis, A. End-to-End Trainable Multi-Instance Pose Estimation with Transformers. In Proceedings of the 5th IEEE International Conference on Multimedia Information Processing and Retrieval, MIPR 2022, Virtual Event, 2–4 August 2022; pp. 228–233. [Google Scholar]
- Xiong, Z.; Wang, C.; Li, Y.; Luo, Y.; Cao, Y. Swin-Pose: Swin Transformer Based Human Pose Estimation. arXiv 2022, arXiv:2201.07384. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11313–11322. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Mao, W.; Ge, Y.; Shen, C.; Tian, Z.; Wang, X.; Wang, Z.; den Hengel, A.v. Poseur: Direct Human Pose Regression with Transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 72–88. [Google Scholar]
- Chen, H.; Jiang, X.; Dai, Y. Shift Pose: A Lightweight Transformer-like Neural Network for Human Pose Estimation. Sensors 2022, 22, 7264. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yan, C.; Tu, Y.; Wang, X.; Zhang, Y.; Hao, X.; Zhang, Y.; Dai, Q. STAT: Spatial-Temporal Attention Mechanism for Video Captioning. IEEE Trans. Multimed. 2020, 22, 229–241. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 14821–14831. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 4467–4475. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.D. Dual-path convolutional image-text embeddings with instance loss. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, J.; Liu, Q.; Liu, B.; Guo, G. Dual-Path Attention Network for Compressed Sensing Image Reconstruction. IEEE Trans. Image Process. 2020, 29, 9482–9495. [Google Scholar] [CrossRef] [PubMed]
- Jiang, K.; Wang, Z.; Yi, P.; Lu, T.; Jiang, J.; Xiong, Z. Dual-Path Deep Fusion Network for Face Image Hallucination. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 378–391. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated Human Detection with Flexible Mixtures of Parts. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2878–2890. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Progressive search space reduction for human pose estimation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Contributors, M. OpenMMLab Pose Estimation Toolbox and Benchmark. Available online: https://github.com/open-mmlab/mmpose (accessed on 14 August 2020).
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-Person Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Ronchi, M.R.; Perona, P. Benchmarking and Error Diagnosis in Multi-instance Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 369–378. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Res | Backbone | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|---|---|
| SBL [8] | 256 × 192 | Res50 | 70.4 | 88.6 | 78.3 | 67.1 | 77.2 |
| SBL [8] | 384 × 288 | Res50 | 72.2 | 89.3 | 78.9 | 68.1 | 79.7 |
| SBL [8] | 256 × 192 | Res101 | 71.4 | 89.3 | 79.3 | 68.1 | 78.1 |
| SBL [8] | 384 × 288 | Res101 | 73.6 | 89.6 | 80.3 | 69.9 | 81.1 |
| SBL [8] | 256 × 192 | Res152 | 72.0 | 89.3 | 79.8 | 68.7 | 78.9 |
| SBL [8] | 384 × 288 | Res152 | 74.3 | 89.6 | 81.1 | 70.5 | 81.6 |
| TransPose-R-A3 [12] | 256 × 192 | ResNet-S | 71.7 | 88.9 | 78.8 | 68.0 | 78.6 |
| TransPose-R-A4 [12] | 256 × 192 | ResNet-S | 72.6 | 89.1 | 79.9 | 68.8 | 79.8 |
| TransPose-H-A3 [12] | 256 × 192 | HRNet-S-W32 | 74.2 | 89.6 | 80.8 | 70.6 | 81.0 |
| TransPose-H-A4 [12] | 256 × 192 | HRNet-S-W48 | 75.3 | 90.0 | 81.8 | 71.7 | 82.1 |
| HPnet | 256 × 192 | Res50 | 72.8 | 90.0 | 80.9 | 65.7 | 75.2 |
| HPnet | 384 × 288 | Res50 | 74.8 | 90.4 | 82.0 | 67.7 | 77.9 |
| HPnet | 256 × 192 | Res101 | 73.3 | 90.4 | 81.4 | 66.3 | 75.7 |
| HPnet | 384 × 288 | Res101 | 75.1 | 90.4 | 82.0 | 67.9 | 78.0 |
| HPnet | 256 × 192 | Res152 | 73.7 | 90.4 | 81.7 | 66.6 | 76.3 |
| HPnet | 384 × 288 | Res152 | 75.6 | 90.5 | 82.7 | 68.4 | 78.6 |
| Method | Res | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|---|
| G-RMI [2] | 353 × 257 | 64.9 | 85.5 | 71.3 | 62.3 | 70 |
| Integral [48] | 256 × 256 | 67.8 | 88.2 | 74.8 | 63.9 | 74 |
| CPN [7] | 384 × 288 | 72.1 | 91.4 | 80 | 68.7 | 77.2 |
| RMPE [49] | 320 × 256 | 72.3 | 89.2 | 79.1 | 68 | 78.6 |
| HRNet-W32 [9] | 384 × 288 | 74.9 | 92.5 | 82.8 | 71.3 | 80.9 |
| HRNet-W48 [9] | 384 × 288 | 75.5 | 92.5 | 83.3 | 71.9 | 81.5 |
| TokenPose-L/D24 [26] | 256 × 192 | 75.1 | 92.1 | 82.5 | 71.7 | 81.1 |
| TokenPose-L/D24 [26] | 384 × 288 | 75.9 | 92.3 | 83.4 | 72.2 | 82.1 |
| SBL [8] | 384 × 288 | 73.7 | 91.9 | 81.1 | 70.3 | 80 |
| TransPose-H-A6 [12] | 256 × 192 | 75.0 | 92.2 | 82.3 | 71.3 | 81.1 |
| HPnet | 384 × 288 | 75.4 | 92.6 | 83.2 | 71.8 | 81.2 |
| Method | Res | Head | Shoulders | Elbows | Wrists | Hips | Knees | Ankles | PCKh |
|---|---|---|---|---|---|---|---|---|---|
| Hourglass [16] | 256 × 256 | 96.6 | 95.6 | 89.5 | 84.7 | 88.5 | 85.3 | 81.9 | 89.4 |
| CPM [1] | 368 × 368 | 96.1 | 94.8 | 87.5 | 82.2 | 87.6 | 82.8 | 78.0 | 87.6 |
| SBL [8] | 256 × 256 | 96.9 | 95.4 | 89.4 | 84.0 | 88.0 | 84.6 | 81.1 | 89.0 |
| HRNet-W48 [9] | 256 × 256 | 97.2 | 95.7 | 90.6 | 85.6 | 89.1 | 86.9 | 82.3 | 90.1 |
| RLE [17] | 256 × 256 | 95.8 | 94.6 | 86.9 | 78.3 | 87.5 | 80.4 | 73.5 | 86.0 |
| TokenPose-L/D24 [26] | 256 × 256 | 97.1 | 95.9 | 90.4 | 86 | 89.3 | 87.1 | 82.5 | 90.2 |
| HPnet | 256 × 256 | 97.0 | 96.7 | 92.2 | 88.0 | 91.5 | 88.7 | 85.3 | 91.8 |
| AP | AP50 | AP75 | AP(M) | AP(L) | |
|---|---|---|---|---|---|
| - | 71.6 | 89.7 | 79.8 | 64.6 | 74.2 |
| 001 | 71.9 | 89.9 | 79.7 | 64.9 | 74.6 |
| 010 | 72.2 | 90.0 | 80.1 | 65.0 | 74.8 |
| 100 | 72.5 | 90.1 | 80.6 | 65.4 | 75.0 |
| 111 | 72.5 | 90.0 | 80.2 | 65.4 | 75.1 |
| Method | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|
| concat | 72.3 | 89.8 | 79.9 | 65.3 | 74.8 |
| m-spatial | 72.5 | 90.0 | 80.0 | 65.5 | 74.9 |
| m-channel | 72.6 | 89.9 | 80.1 | 65.5 | 75.1 |
| self-spatial | 72.4 | 89.8 | 80.2 | 65.2 | 75.2 |
| CBA | 72.8 | 90.0 | 80.9 | 65.7 | 75.2 |
| Backbone | CBA | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|---|
| res101 | 73.2 | 89.8 | 80.0 | 65.8 | 76.2 | |
| - | √ | 75.1 | 90.4 | 82.0 | 67.9 | 78.0 |
| res152 | 74.6 | 90.1 | 81.7 | 67.4 | 77.6 | |
| - | √ | 75.5 | 90.5 | 82.7 | 68.4 | 78.6 |
| Res | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|
| - | 72.54 | 89.97 | 80.24 | 65.40 | 75.07 |
| w/pos | 72.17 | 89.85 | 79.81 | 65.11 | 74.65 |
| Config | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|
| 111 | 72.54 | 89.97 | 80.24 | 65.40 | 75.07 |
| 121 | 72.46 | 89.94 | 80.12 | 65.32 | 74.92 |
| Post | AP | AP50 | AP75 | AP(M) | AP(L) |
|---|---|---|---|---|---|
| - | 75.6 | 90.5 | 82.7 | 68.4 | 78.6 |
| Dark | 76.25 | 90.93 | 83.20 | 69.19 | 79.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yao, H.; Hou, Y. HPnet: Hybrid Parallel Network for Human Pose Estimation. Sensors 2023, 23, 4425. https://doi.org/10.3390/s23094425
Li H, Yao H, Hou Y. HPnet: Hybrid Parallel Network for Human Pose Estimation. Sensors. 2023; 23(9):4425. https://doi.org/10.3390/s23094425
Chicago/Turabian StyleLi, Haoran, Hongxun Yao, and Yuxin Hou. 2023. "HPnet: Hybrid Parallel Network for Human Pose Estimation" Sensors 23, no. 9: 4425. https://doi.org/10.3390/s23094425
APA StyleLi, H., Yao, H., & Hou, Y. (2023). HPnet: Hybrid Parallel Network for Human Pose Estimation. Sensors, 23(9), 4425. https://doi.org/10.3390/s23094425