1. Introduction
Wireless sensor networks (WSNs) have been blooming recently, which can probe and collect environmental information, such as temperature, atmospheric pressure, and irradiation to provide ubiquitous sensing, computing, and communication capabilities. A WSN has two important and interesting characteristics that are different from traditional wireless networks. First, after the event occurs, multiple sensors nodes (denoted as
data source nodes) around this event will sense the event, and then send the data back to one sensor node (denoted as
sink node). Hence, communication mode in WSN occurs from multiple data source nodes to one data sink node. This is a type of
multipoint-to-point, rather than the traditional point-to-multipoint (i.e. multicast) communication in wireless networks. For example,
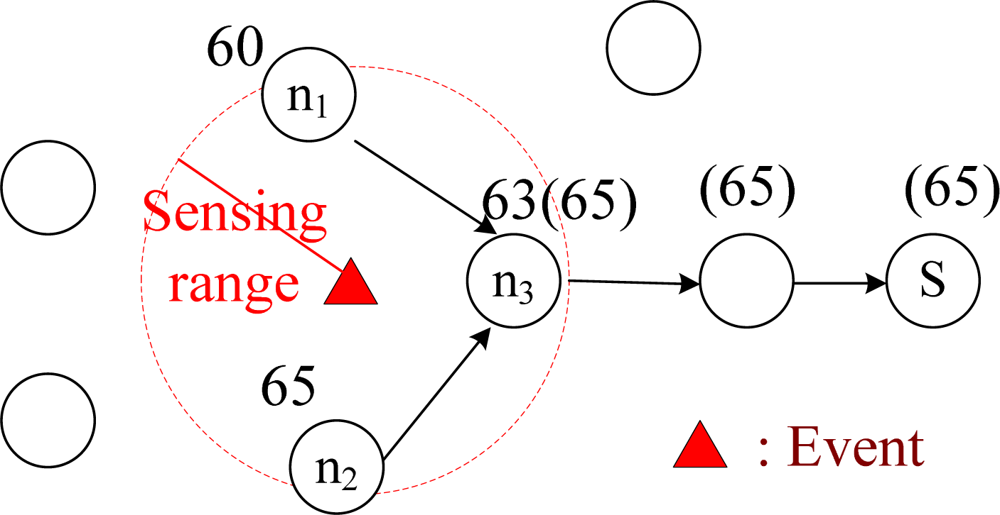
Figure 1 shows a data aggregation tree from three data source nodes to one sink. This data aggregation tree is a type of reverse-multicast tree. Second, energy saving is possible at the nodes on the data aggregation tree because intermediate nodes on the data aggregation tree could receive redundant data from the data source nodes. In order to avoid transmitting useless, redundant data back to the sink, the intermediate nodes could save energy by collecting and processing data before transmission and prevent disconnected networks due to rapid energy depletion of sensors. This type of
data aggregation capability has been put forward as particularly useful for routing, in terms of energy consumption in WSN [
2].
There are several data aggregation schemes, and in addition to reducing redundant transmissions, other aggregation schemes could compute maximum values (MAX), minimum values (MIN), or summations (SUM) of the collected data. For example, in
Figure 1, an event in sensing range of data source nodes
n1,
n2, and
n3 is probed for temperature (60, 65, and 63°F, respectively), and the MAX temperature is then sent back to the sink node
S. If node
n3 could aggregate (i.e. MAX = 65°F) these data before returning it to the sink, the total number of transmission times for node
n3 could be reduced from three to one.
Since it is almost impossible to replace the battery in a sensor node, power efficient communication in WSN plays a crucial role. In data aggregation routing, the key issue is how to construct the reverse multicast tree in such a way to save the total energy consumption. Most existing research literatures construct the tree by only considering the data aggregation aspect [
2,
6]. The basic idea of these data aggregation aspect algorithms is trying to maximize the times of aggregation to reduce the number of transmissions. However, there remains one issue important to the construction of a data aggregation tree, the
MAC layer retransmission issue.
In WSNs, any sensor nodes within another’s transmission range trying to transmit simultaneously would result in collision. In addition, two nodes that are not within each other’s transmission range trying to simultaneously transmit to the same node might also incur collision. This is well known as the hidden-node problem. Because of hidden-node problem, the interference range is larger than the transmission range in wireless communications. In
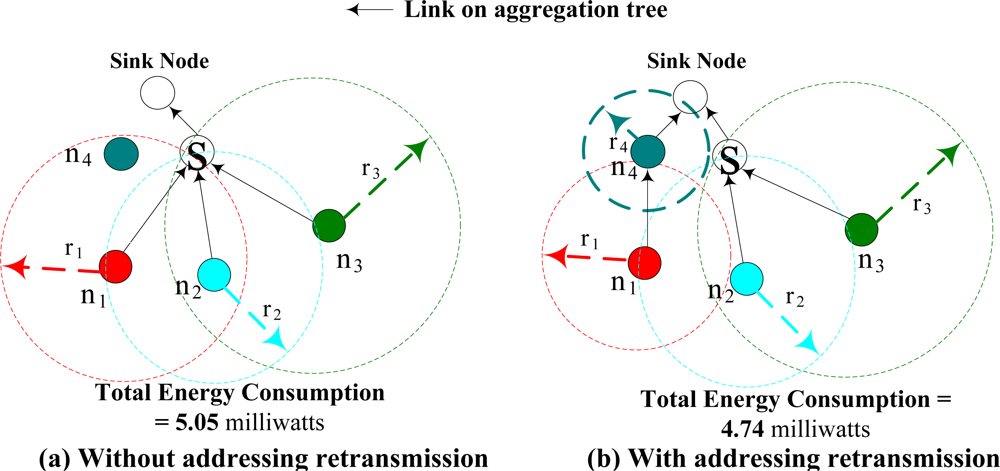
Figure 2(a), shows that even though the transmission radius of nodes
n1 and
n3 do not overlap, collision still occurs at the receiver (node
S) when they transmit at the same time. When collision occurs,
retransmission is required to ensure the data is successfully received. These retransmissions incur additional energy consumption, which will jeopardize the advantages of data aggregation. Data retransmission times are determined by the total number of sensor nodes whose transmission radius covers the receiver (or equivalent to the total number of sensor nodes within each other’s interference range). In other words, the more flows are aggregated, the higher the probability that the senders will incur data retransmission. Hence, there is a tradeoff between data aggregation and retransmission. Good data aggregation tree should address data aggregation and MAC layer retransmission at the same time.
Figure 2 gives an illustrative example to show the tradeoff between the data aggregation and retransmission, where nodes
n1,
n2, and
n3 are the data source nodes. Without considering data collision, the optimal aggregation tree is as shown in
Figure 2(a). Note that when an intermediate node aggregates more data, a greater number of collisions would occur at the intermediate nodes, which results in additional energy consumption. Node
S, the receiver of the three children nodes, will suffer significant collisions that results in more retransmission times. With considered collision effects, a more energy efficient data aggregation tree is as shown in
Figure 2(b). In this figure, by reducing the transmission radius of node
n1, and change its routing assignment to node
n4, the total energy consumption could be reduced. Even though there is extra energy consumption at node
n4, there are only two children nodes at node
S, and thus, the retransmission times caused by collision could be significantly reduced. Hence, the energy consumption associated with retransmission from collisions should be carefully addressed in WSN. This example also shows that a good tradeoff between data aggregation and retransmission is facilitated by intelligent transmission radius and routing assignments. The energy consumption function (including transmission power and retransmission power), as shown in
Figure 2, is calculated by its objective function (IP), as described in Section 3.
This paper discusses the impacts of retransmission on data aggregation, and proposes a MAC aware energy efficient data aggregation algorithm to consider a tradeoff between the benefits of data aggregating and data retransmission costs in WSN. To the best of our knowledge, there is no literature that addresses the cross-layer (layer 2 and layer 3) MAC aware data aggregation routing algorithm in WSNs. This paper proposes an optimization-based heuristic algorithm to solve the MAC aware energy-efficient data aggregation routing problems (MAC-DAR) based on the CSMA/CA protocol in WSNs. The problem is first formulated as a nonlinear programming problem, where the objective function is to minimize total energy consumption from data transmissions and retransmissions. The Lagrangean relaxation scheme in conjunction with the optimization-based heuristic algorithm is proposed to solve this problem. From the computational experiments, the proposed solution approach outperforms the conventional non-MAC aware data aggregation heuristics. In addition, the proposed nonlinear programming formulation for the MAC-DAR problem is based on the existing CSMA/CA protocol, and thus, our algorithm could be deployed in the wireless sensor network, without the necessity of modifying the MAC protocol in WSNs. In summary, besides better solution quality, our proposed approach could be easily deployed in WSNs without changing the existing CSMA/CA protocol.
The remainder of this paper is organized as follows. Section 2, surveys existing related works on data aggregation routing and MAC layer protocols in WSNs. In Section 3, mathematical formulation of the MAC-DAR in WSNs is proposed. In Section 4, solution approaches, as based on Lagrangean relaxation are presented. In Section 5, heuristics are developed for calculating a good primal feasible solution. In Section 6, computational results are reported. Finally, Section 7 concludes this paper.
3. Problem Formulation
A MAC-DAR in WSNs is modeled as a graph, in which sensors are represented as nodes, and the arc connecting the two nodes indicates that one node is within the other’s transmission radius. The definitions of notations adopted in the formulation are listed below.
First, the given parameters are shown as follows:
| N | The set of all sensor nodes |
| Psq | The set of all candidate paths that connect data source node s to sink node q |
| S | The set of all data source nodes |
| h | Longest distance of shortest path to reach the farthest data source node |
| M | An arbitrary large number |
| δp(n,k) | The indicator function, which is 1 if the link from node n to node k is on path p, and 0 otherwise |
| dnk | Euclidean distance between node n and node k |
| tdata | Transmission time for transmitting a data packet |
| RTS | Transmission time for RTS frame |
| SIFS | Short inter-frame space time |
| θ | Maximum propagation delay for transmitting data packet |
| Q | The sink node |
| Rn | The set of all possible transmission radii that node n can adopt, which is a discrete set |
| en (rn) | Energy consumption function of node n per unit time, which is a function of the sensor’s transmission radius |
| T | The largest number of retransmission times |
Then, the decision variables are shown below.
| xsp | 1 if data source node s uses path p to reach sink node q, and 0 otherwise |
| y(n,k) | 1 if the link from node n to node k is on the tree, and 0 otherwise |
| rn | Transmission radius of the node n |
| znk | 1 if node k is covered within transmission radius of node n, and 0 otherwise |
| cnk | Retransmission times of node n to transmit data to node k |
Please note that we do not have to generate all candidate paths that connect data source node
s to sink node
q (i.e.,
Psq). Section 4 will explain by using Lagrangean multipliers as the link arc weight (in
Subproblem 2),
xsp will be associated with the minimum-weight path by using the shortest path algorithm for each data source node
s.
An analysis of retransmission times is conducted as follows. First, it assumes that each sensor node is equipped with a CSMA/CA compatible transceiver, each transmission conforms to a Geometric distribution, and each sensor node generates data packets that follow a Poisson distribution at a certain rate of λ. Successful transmission of data from sender to receiver depends on the number of senders whose transmission radius covers the receiver. By considering receiver side collisions, in terms of communication radii of sensor nodes, the hidden-node problem is implicitly contemplated. In the CSMA/CA protocol, when a sender wants to transmit a packet to a receiver, it will first issue an RTS control frame and wait for a CTS frame from the receiver to ensure that the channel be free [
4]. According to the CSMA/CA protocol, the time interval between RTS and CTS is no larger than a short inter-frame spacing (
SIFS) time. Let the propagation delay from sender to receiver be
θ, and turnaround time be
2θ. The overall contention period is (
RTS +
SIFS + 2θ). Then the average retransmission time from node
n to node
k (i.e.,
cnk) is as follows:
∑j∈N zjk calculates the total number of senders whose transmission radius covers node k. The meaning of (0) is the mean value of the Geometric distribution, where the successful transmission probability, say psuccess, is that no data transmissions are occurring at any node whose transmission radius covers receiver node k within the contention period (RTS+SIFS+2θ).
The MAC-DAR problem in WSNs is then formulated as the following nonlinear optimization problem (IP).
subject to:
The objective function of (IP) is to minimize total energy consumption, where
captures the energy consumption from data transmission; and
captures the energy consumption from retransmission. In conjunction with the objective function, three sets of constraints (data aggregation tree, transmission coverage, and retransmission times) are enforced in Problem (IP) to give the MAC-DAR problem.
A. Data aggregation tree constraint
The basic idea of this set of Constraints, are to ensure that the union of all routing paths, from data source nodes to sink shall be a data aggregation tree. Recall that a data aggregation tree is a reverse-multicast tree, which is a multicast tree rooted at the sink node, but with opposite transmission directions. The data aggregation tree properties are enforced by Constraints (1) to (5). Constraint (1) requires that if path
p is selected for source node
s to reach sink node
q, the path must be on the tree. This constraint also enforces that if links (
n,
k) on path
p are adopted by source node
s to reach the sink node, then
y(n,k) must be 1. Constraints (2) and (11) require that the total number of links on an aggregation tree is at least the maximum of
h and the cardinality of
S. Both
h and |
S| are legitimate lower bounds of the total number of links on an aggregation tree, and they could be calculated in advance [
3]. According to [
3], introducing Constraint (2) will significantly improve solution quality. The left-hand term of Constraint (3) calculates the number of paths that are destined for the sink node, and pass through link (
n, k) on the aggregation tree. The right-hand term of Constraint (3) is at most |
S|. When the union of paths destined for a sink node contains a cycle, and this cycle contains link (
n, k), then Constraint (3) would not be satisfied because there would be too many paths passing through this link. In other words, Constraint (3) enforces the union of paths that do not contain a cycle [
6]. Constraints (4) and (10) require that any data source adopts only one routing path destined for the sink node. Constraint (5) is the outgoing link constraint. All intermediate nodes on the aggregation tree should have only one outgoing link. For example, in
Figure 1, each node on the data aggregation tree has only one outgoing link to the sink node. In summary, Constraints (1)–(5), (10), and (12) enforce that the union of all routing paths shall be a data aggregation tree.
B. Transmission coverage constraint
The basic idea of this set of constraints are to ensure that if a node
k is covered within the transmission radius of node
n, then the distance between node
n and node
k must be smaller than the transmission radius of node
n. Because
M is a very large number, on the left hand side of Constraint (6), if
rn >
dnk (i.e., node
k is within the transmission radius of node
n), then
. This will force
znk to be equal to 1. On the other hand, if
rn >
dnk then
, then,
znk could be equal to 0. Constraint (7) enforces that if node
k is covered within the transmission radius of the node
n, then the transmission radius of node
n must be larger than the distance between nodes
n and
k. Hence, Constraints (6) and (7) specify the transmission coverage constraints for decision variables
rn and
zjk. Then ∑
j∈N zjk, which is used in
Equation (0), calculates the total number of senders whose transmission radius covers the node
k. Constraint (8) relates decision variable
y(n,k) to
znk. When
y(n,k) equals to 1, it will force
znk to be 1.
Constraint (13) restricts that the set of possible transmission radii that node n can adopt is a discrete and finite set. Constraint (14) ensures that each data source node turns on its transmission radius. The transmission radius of each source node cannot be 0.
C. Retransmission time constraints
The basic idea of this set of constraints are to calculate the retransmission times of node
n to transmit data to node
k, where the retransmission times are determined by the total number of nodes on the data aggregation tree, whose transmission radius covers node
k. Constraint (9) calculates the retransmission times of node
n to transmit data to node
k. Since only the sensor nodes on the aggregation tree need to calculate retransmission times, when
y(n,k) = 1, the right side of Constraint (9) is the same as
Equation (0), i.e., to enforce the retransmission times (i.e.,
cnk) and should be at least the average retransmission times. When
y(n,k) = 0, the right side of Constraint (9) is zero, it implies that there is no retransmission time constraint. Constraint (15) is an integer constraint of retransmission times.
In order to make the problem (IP) tractable, a natural logarithm is used on both sides of Constraint (9) for applying the Lagrangean relaxation schemes,
Hence, Constraint (9) becomes
4. Lagrangean Relaxation
The algorithm structure is based upon Lagrangean relaxation. In (IP), by introducing Lagrangean multiplier vectors
u1,
u2,
u3,
u4,
u5, and
u6, Constraints (1), (3), (6), (7), (8), and (9) are dualized to obtain the following Lagrangean relaxation problem (LR).
subject to:
(LR) can be decomposed into four independent subproblems.
Subproblem 1: for
y(n,k)subject to (16), (18) and (20).
Subproblem 2: for
xspsubject to (17) and (19).
Subproblem 3: for
rn and
cnksubject to (22), (23) and (24).
Subproblem 4: for
znksubject to (21).
The proposed algorithm for solving (
SUB1) is described as follows.
Step 1. For each link (n,k) compute the coefficient
for each y(n,k).
Step 2. For all outgoing links of node n, find the smallest coefficient. If the smallest coefficient is negative, then set the corresponding y(n,k) as 1, and the other outgoing links y(n,k) as 0, otherwise set all outgoing links y(n,k) as 0. Repeat step 2 for all nodes.
Step 3. If the total number of y(n,k), whose value is 1 (denoted as τ) are smaller than max{h, |S|}, then first let each y(n,k) whose corresponding coefficient is negative be 1. Second, assign the (max{h, |S|} −τ) number of y(n,k) to be 1 whose corresponding coefficients are the smallest positive values. Third, let the remaining y(n,k) be 0.
The computational complexity of above algorithm is
O(
|N|2).
(
SUB2) can be further decomposed into |
S| independent shortest path problems with nonnegative arc weight whose value is
. For each shortest path problem, it can be effectively solved by Dijkstra’s algorithm. The computational complexity of Dijkstra’s algorithm is
O(
|N|2) for each data source node.
(
SUB3) can be optimally solved by exhaustively searching the combination of radius
rn and
cnk. The computational complexity of (
SUB3) is
O(|
Rn|
T) for each node
n.
In (
SUB4), if the corresponding coefficient
of link (
n,
k) is negative then set
znk to be 1, otherwise 0. The computational complexity of (
SUB4) is
O(1) for each link (
n,
k).
According to the algorithms proposed above, the Lagrangean relaxation problem can be effectively and optimally solved. Based on the weak Lagrangean duality theorem,
ZD(u1,u2,u3,u4,u5,u6) is a lower bound of
ZIP. The tightest lower bound is calculated by using the subgradient method [
1].
5. Obtaining Primal Feasible Solutions
It is noted that solutions to the problem (LR) may not be feasible for the primal problem (IP), because six constraints are relaxed to the objective function. This paper proposes an optimization-based integrated primal feasible algorithm, called LGR-Primal, which jointly address data aggregation and retransmission to obtain primal feasible solutions to the problem (IP). The information in problem (LR) provides useful information to obtain good primal feasible solutions. In LGR-Primal, the information from the Lagrangean relaxation (the solutions to the dual problem and the Lagrangean multipliers) is used to optimize the tradeoff between data aggregation and retransmission.
LGR-Primal is presented in
Algorithm 1; it identifies the routing path (i.e.,
xsp) for each data source node, and then the data aggregation tree is obtained by unifying all the routing paths from each data source node to the sink. In order to obtain an energy efficient data aggregation tree, the link arc weight assignment optimizes the tradeoff between data aggregation and retransmission.
When the routing path xsp of each data source node s, which is returning to the sink node, is determined, then the selected links (i.e., y(n,k)) on the data aggregation tree could also be determined. In addition, the transmission radius (i.e., rn) of each node could also be determined to cover the termination node for all selected links on the data aggregation tree. After the transmission radius of each node is determined, then the coverage decision variable znk could also be determined. Finally, the value of retransmission time cnk could also be determined to satisfy Constraint (9).
In Step 1 of
Algorithm 1, the first term of the arc weight assignment is energy consumption for link (
n,
k),
enk (
dnk), which captures the minimum transmission power to select link (
n,
k) on the data aggregation tree. It is worth noting that, the physical meaning of the Lagrangean multiplier is the violating cost of the associated constraint. The second term,
, captures the penalty cost for violating the tree constraint. The third and forth terms,
and
, capture penalty costs for violating transmission coverage constraints. The fifth and sixth terms,
and
, capture the penalty costs for violating retransmission time constraints. Hence, based on this link arc weight assignment, this paper attempts to identify the minimum transmission power data aggregation tree by considering the extra costs from retransmissions.
The computational complexity of
Algorithm 1 at Step 2 is
O(|
S||
N|
2). At Steps 3 and 4, when computing the retransmission power of the objective function, it requires calculation of the total number of other nodes, whose transmission radius covers node
k (
Equation (0)), in order to determine the retransmission times
cnk from node
n to node
k. Therefore, the computational complexity is
O(|
N|
3). Hence, the computational complexity of the LGR-Primal algorithm should be
O(|
N|
3). However, if each sensor node
k is equipped with GPS, which enables it to know their neighboring sensors nodes, then to determine the retransmission times of
cnk from node
n to node
k would only need to calculate the
k’s neighboring nodes (instead of all the other sensor nodes in the WSN) whose transmission radius covers node
k. In this case, the computational complexity for Steps 3 and 4 would only be
O(|
N|
2). Then the computational complexity of the LGR-Primal algorithm should be
O(|
S||
N|
2). This makes this algorithm scalable to a large scale WSN.
Algorithm 1.
LGR-Primal Algorithm.
Algorithm 1.
LGR-Primal Algorithm.
Step 1) Assign the arc weight of the each link (n, k) as
. Step 2) Perform a Dijkstra’s shortest path algorithm to identify the routing path (i.e., xsp) from each data source node s to the sink node. Step 3) Determine the other decision variables (y(n,k), rn, znk and cnk) without violating the associated constraints. Step 4) Calculate the objective value of the problem (IP).
|
The following section will show a complete algorithm (denoted
LGR), as based on subgradient method [
1] for solving problem (IP). The computational complexity of the LGR is
O(|
S||
N|
2 + |
N||
Rn|
T).
Algorithm 2.
LGR Algorithm.
Algorithm 2.
LGR Algorithm.
| Begin |
| Input: Network topology, data source nodes |
| Output: Data aggregation tree |
| Initialize Lagrangean multiplier vectors ui (0) = 0, ∀i = 1,…,6. |
| UB = ∞ and LB = −∞ (upper and lower bounds, respectively). |
| quiescence_age = 0, and step_size = 2. |
| For iteration = 1 to Max_Iteration, perform the following: |
| Solve subproblem 1, subproblem 2, subproblem 3, subproblem 4. |
| Compute ZD in (LR). |
| If ZD (u) > LB |
| LB = ZD (u) and quiescence_age = 0. |
| Else quiescence_age = quiescence_age + 1. |
| If quiescence_age = Quiescence_Threshold |
| step_size = step_size/2 and quiescence_age = 0. |
| Run Algorithm 1 (LGR-Primal). Compute the new upper bound ub. |
| If ub < UB then UB = ub. |
| Update the step_size. |
| Update the Lagrangean multiplier vectors. |
| End For |
| End |
6. Computational Experiments
The proposed algorithms for MAC-DAR problems are coded in C and run on a PC with PIV-2G. In a LGR algorithm, Max_Iteration and quiescence_age are set to 2000 and 30, respectively. The step size coefficient step_size, is initialized as 2, and is halved when the objective function value of the dual problem is not improved by iterations reaching quiescence_age. The computational times for the following experiments are all within five minutes.
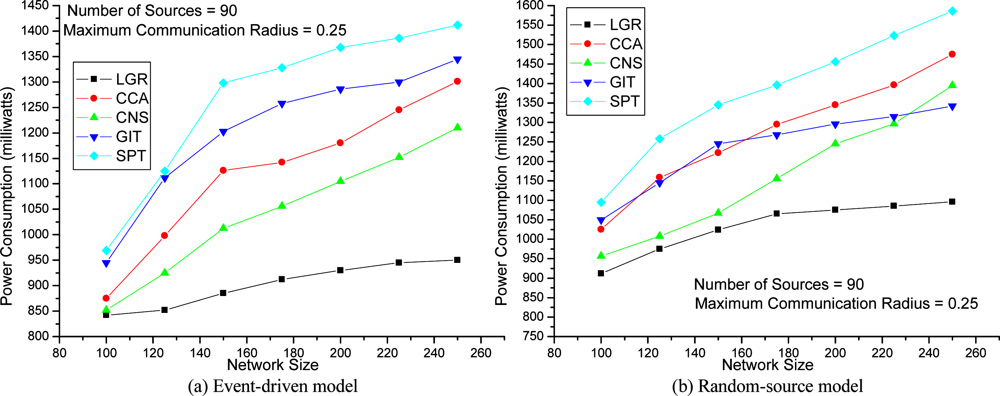
The network topology comprises |
N| (= 150 in
Figure 3 and
4, up-to 250 in
Figure 5) sensor nodes randomly placed within a 1×1 square unit area. The cost of the energy consumption function (in milliwatts),
en (
rn), is defined as the square of 100×Euclidean distance multiplied by the energy consumption per millisecond when the sensor node is transmitting data. The set of all possible transmission radii of sensor node
n (i.e.,
Rn) are configured to begin from 0 to the
maximum communication radius (e.g. 0.25 in
Figure 3) with step size 0.01. The CSMA/CA related parameters (
RTS,
SIFS,
θ) are the same settings as in [
4]. To evaluate the solution quality of our proposed algorithm, four existing algorithms are implemented for comparison. The SPT, GIT, and CNS algorithms are proposed in [
2], and the forth algorithm CCA, is described in [
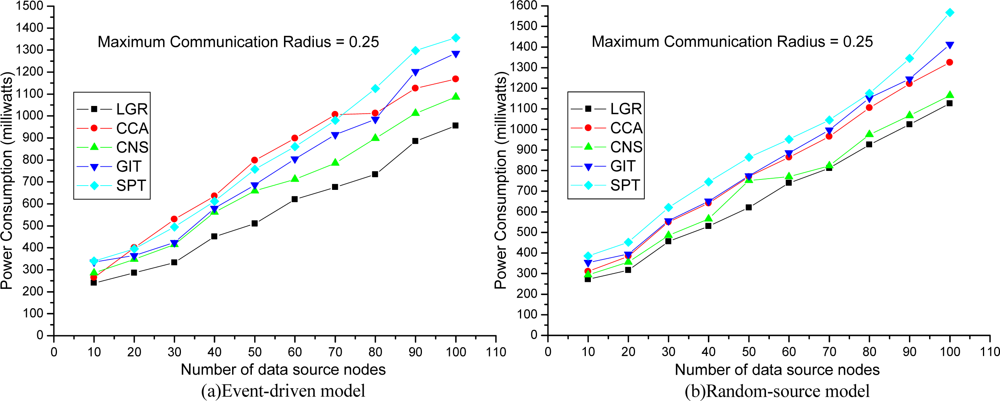
5]. It is worth noting that, all four heuristic constructs data aggregation trees without considering MAC layer collision effects. Each plotted point in
Figures 3–
5 is a mean value over 10 simulation results.
Two different models in WSN are simulated. The first is an event-driven, where neighboring sensor nodes of the event will become the data source nodes. The second is a random-source, where data source nodes are determined in random. Hence, the data source nodes in an event-driven model will be closer to each other than in a random-source model.
Figure 3 shows the total energy consumption with increasing numbers of data source nodes. When the number of source nodes is large, the aggregation tree is larger. It is shown that the LGR algorithm can obtain the best solution quality, as compared to other heuristics in both event-driven and random-source models. In addition, in an event-driven model, the solution quality of LGR algorithm is even more significant than other heuristics. This is because in an event-driven model, the data source nodes are clustered to increase probability of collisions. Hence, heuristic algorithms that do not address the MAC collision suffer from severe retransmission occurrences.
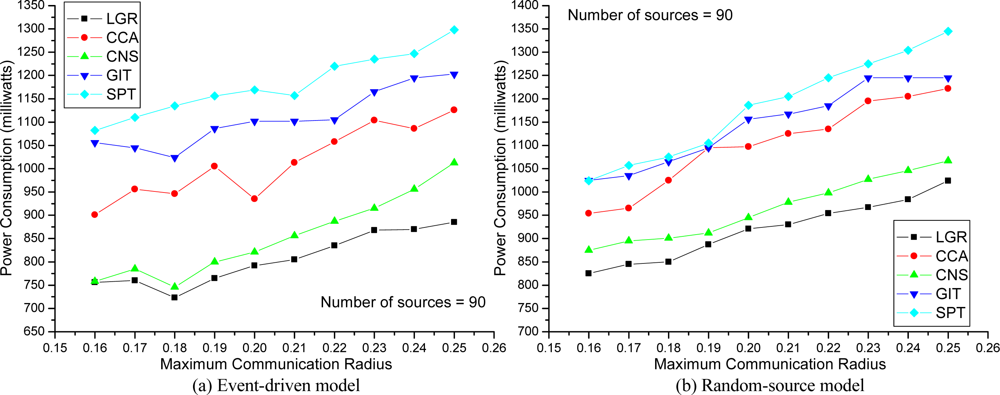
In
Figure 4, the effects of communication radii on energy consumption are examined with 90 data source nodes. As shown, the LGR algorithm can still obtain best solution quality, as compared to the other heuristics on both models. Interestingly, even though a large maximum communication radius could increase the probability of data aggregation, it is shown that a large maximum communication radius did not offer any advantage for MAC aware energy efficient data aggregation trees, because a large communication radius leads to severe collisions that could jeopardize the advantages of data aggregation. In addition, in an event-driven model, the best solution for the LGR algorithm is at 0.18, instead of at 0.16 communication radius. This reveals that; for too small communication radii, even though the collision probability is low, it will not provide data aggregation advantages that save total transmission power. Hence, best communication radii setting should consider the tradeoff between collision and data aggregation.
Figure 5 depicts the experiments evaluating the solution quality under different network sizes (i.e., network density). The LGR algorithm outperforms the other heuristics for all the network sizes. In large network size (i.e., a high density of sensor nodes within a fixed deployment area), the solution quality of LGR over the other heuristics is more significant. Recall that in the first term (i.e.,
) of the objective function in problem (IP), which favors communication links of shorter distances, thus, the data aggregation tree will be composed of more relay nodes for data aggregation. However, in this case, as too many relay nodes on the data aggregation tree will introduce higher probability of collision, we will have larger retransmission cost (i.e., the second term of the objective function in problem (IP)). It is expected that the second term will play a more important role in a dense network topology. According to
Figure 5, the solution for LGR increase more mildly than the other heuristics in a dense network topology, which reveals that LGR will not select a large number of hops for data aggregation, in order to avoid extra energy loss from retransmissions in a dense network topology.
The improvement ratio is defined as (other approach — LGR)/(LGR)×100% to show the solution quality. In
Table 1, the improvement ratio of LGR over SPT, GIT, CNS, and CCA is 57%, 42%, 29%, and 59%, respectively.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




