1. Introduction
Assessing and managing risk is a core element of public health practice, although explicit and detailed documentation of these processes varies among various public health programs. Use of a qualitative (semi-quantitative) risk assessment matrix is a growing practice. The comparative simplicity and apparent ease of use of this approach likely contributes to widespread adoption including a generic international standard for risk assessment techniques in support of risk management [
1]. Major public institutions have adopted the risk assessment matrix in fields ranging from assessing highway construction risk, financial risk, preventing terrorist attacks, to agency-wide enterprise risk management across all of government [
2,
3]. The World Health Organization has adopted this approach for risk assessment of acute public health events [
4] and for assuring safe drinking water [
5]. Risk matrices have also been adopted nationally in Australia for assuring safe drinking water and for drinking water safety plan implementation in Alberta, Canada [
6,
7].
Although the various applications of this technique differ in specific details, they all involve the common structural features of a matrix with one axis representing categories of probability (likelihood or frequency) of possible hazardous events and the other axis representing categories of severity (impact or consequences) of those events. Each intersecting cell of the matrix (i.e., row-column pair) is pre-assigned a risk such as low, medium, or high risk. This basic structure is consistent with a widely adopted, if somewhat simplified, concept of risk as being primarily a function of two variables, one representing probability and the other consequences.
The UK National Health Service (NHS) has developed detailed guidance for applying the risk assessment matrix technique, which specified the following properties as being essential for such a risk assessment matrix, “
it should:- •
be simple to use;
- •
provide consistent results when used by staff from a variety of roles or professions;
- •
should be capable of assessing a broad range of risks including clinical, health and safety, financial risks, and reputation; and
- •
should be simple for NHS trusts to adapt to meet their specific needs.” [
8]
The ISO standard characterized this technique as offering [
1]:
“
Strengths:- •
relatively easy to use;
- •
provides a rapid ranking of risks into different significance levels.
Limitations:- •
a matrix should be designed to be appropriate for the circumstances so it may be difficult to have a common system applying across a range of circumstances relevant to an organization;
- •
it is difficult to define the scales unambiguously;
- •
use is very subjective and there tends to be significant variation between raters;
- •
risks cannot be aggregated (i.e., one cannot define that a particular number of low risks or a low risk identified a particular number of times is equivalent to a medium risk);
- •
it is difficult to combine or compare the level of risk for different categories of consequences.”
Cox outlined a number of serious deficiencies with the risk assessment matrix approach for assessing risk, including: Poor resolution, ambiguous inputs and outputs, sub-optimal allocation of resources based on inaccurate risk estimation and outright errors in assigning higher rankings to quantitatively lower risks [
9]. In particular, for the last concern, Cox demonstrated that the prediction of risk arising from the risk assessment matrix could be worse than a random guess by using a mathematical function for which frequency and severity are negatively correlated and using the commonly adopted formulation (with frequency as a measure of probability and severity as a measure of consequence):
Specifically Cox proposed the following theoretical but plausible deterministic negative relationship between frequency and severity values [
9]:
He designed a simplified 2 × 2 risk assessment matrix with two categories of frequency (Low, High) and two categories of severity (Low, High), then assigned medium risk to the pairs (frequency, severity) of (Low, High) and (High, Low), high risk to the pair (High, High), and low risk to the pair (Low, Low). He demonstrated that in this risk assessment matrix, most points in the medium risk categories actually have smaller risk values from Equation (1) than any points in the low risk cells. This theoretical example demonstrates that the risk category assignment by the matrix is different from the risk calculation that is intended to accurately estimate the risk and, as such, the risk matrix predictions can be, according to Cox [
9], worse than useless (
i.e., worse than random).
The prospect of risk predictions being worse than random for risks having a negative correlation between frequency and severity is gravely troubling because such a negative correlation is to be expected in many, if not most, of the circumstances that risk assessment matrix is used to characterize. The wide-spread practice of risk management has reduced the occurrence of hazards causing serious consequences, making their frequency lower. Certainly, for risks being able to accurately distinguish low frequency-high consequence risks from high frequency-low consequence risks is crucial. Despite a growing number of citations, this grave concern of the risk assessment matrix method has received little traction in applied fields such as public health since first proposed by Cox in 2008.
Given our focus on health risk, we sought a practical public health example for which we could find experiential data on risk to assess the practical implications of this concern about risk assessment matrices. Cases, such as drinking water safety, where risk assessment matrices are being widely adopted were not pursued for our analysis because, while there is no shortage of monitoring data, little of this can be readily used for assessing tangible public health risk [
10]. The connection between available monitoring data and risk is complex and drinking water disease outbreaks in affluent countries are comparatively rare [
11].
The tangible health risks associated with tainted blood transfusions, by comparison, offers a circumstance where, after the major tragedies associated with HIV and hepatitis C transmission through transfusion of tainted blood and blood products, there has been a concerted effort to estimate the frequency of blood contamination for a range of pathogens capable of causing a wide range of disease outcomes of variable severity. Quintela
et al. produced a generic risk assessment matrix addressing production processes in blood banks, but this analysis did not provide the kind of risk data needed to evaluate the Cox concerns [
12].
The objective of our study is to explore the validity of risk matrices for health risk assessment by using a public health risk scenario, tainted blood transfusion infection risk because it provides experiential frequency data estimates for which the frequency of a risk is expected to be negatively correlated with the severity of consequences. That negative correlation is a requirement for allowing risk assessment matrix predictions to be worse than random and potentially harmful according to the analysis of Cox [
9].
2. Methods
To illustrate the behavior of the risk assessment matrix tool, first we constructed a risk assessment matrix for the hazards associated with infection risk from tainted-blood transfusion using only frequency and severity values. Second, we identified the relationship between frequency and severity values and estimated the risk using Equation (1). Then we compare the estimated risk values (quantitative values) with the risk levels in the risk assessment matrix to verify their compatibility.
Risk ranking for decision makers in the risk assessment matrix is commonly visualized by assigning colors to risk categories, which are the cells in the matrix. The assignment of risk categories to the risk assessment matrix (
Figure 1) must be done initially by the risk assessor, with an application of judgment, before any specific risks are placed in the matrix. Misunderstanding that this color-coding approach must be restricted to risk has appeared where color-coding was also pre-assigned for both the severity and frequency categories [
8]. The color-coding in a risk assessment matrix must only apply to the risk categories that are a product of the severity and frequency ratings that determine the location of any specific risk in the matrix. The magnitude assignment (provided by the color coding) for any risk thus results from its placement in the matrix according to its estimated severity and frequency.
We adapted the NHS criteria for assigning the severity and frequency rankings as listed in
Table 1 [
8]. To obtain estimates of frequency for our purposes, we collected the prevalence estimates of different blood infectious diseases in blood donors and the population of Canada from the reports of the Public Health Agency of Canada from 1987 to 1996 (
Table 2) [
13]. For these data we found a very wide range (6 orders of magnitude) of frequency values (0.0000008 to 0.4;
Table 2). Because of the wide range of values involved, we adopted a logarithmic scale for both the frequency and severity categories.
Because we located no reports on the prevalence of Creutzfeldt Jakob Disease/variant Creutzfeldt Jakob Disease (CJD/vCJD) in blood donors we used the prevalence in the entire population instead. We acknowledge that this will likely over-estimate the frequency and consequently the risk among blood donors for transmitting CJD/vCJD.
We evaluated the disease severity by assigning severity ranging from very low to very high for each blood infectious disease according to expected complications, mortality, morbidity and available treatment for the infection. While the severity ranking is clearly a judgmental input to the risk assessment matrix based on NHS criteria ranging from very low to very high, frequency is assigned a ranking (extremely low to very high) based on where the frequency evidence dictates (
i.e., according to
Table 1).
Figure 1.
Generic risk assessment matrix.
Figure 1.
Generic risk assessment matrix.
Table 1.
National health service criteria for severity and frequency levels, adapted from [
8].
Table 1.
National health service criteria for severity and frequency levels, adapted from [8].
| Criteria for Severity Levels |
| Very Low Severity | |
| Low Severity | |
| Medium Severity | Moderate injury requiring professional intervention Increase in length of hospital stay by 4–15 days Impacts on a small number of patients
|
| High Severity | |
| Very High Severity | Incidence leading to death Multiple permanent injuries or irreversible health effects Impacts on a large number of patients
|
| Criteria for Frequency Levels |
| Extremely Low Frequency | |
| Very Low Frequency | |
| Low Frequency | |
| Medium Frequency | |
| High Frequency | |
| Very High Frequency | |
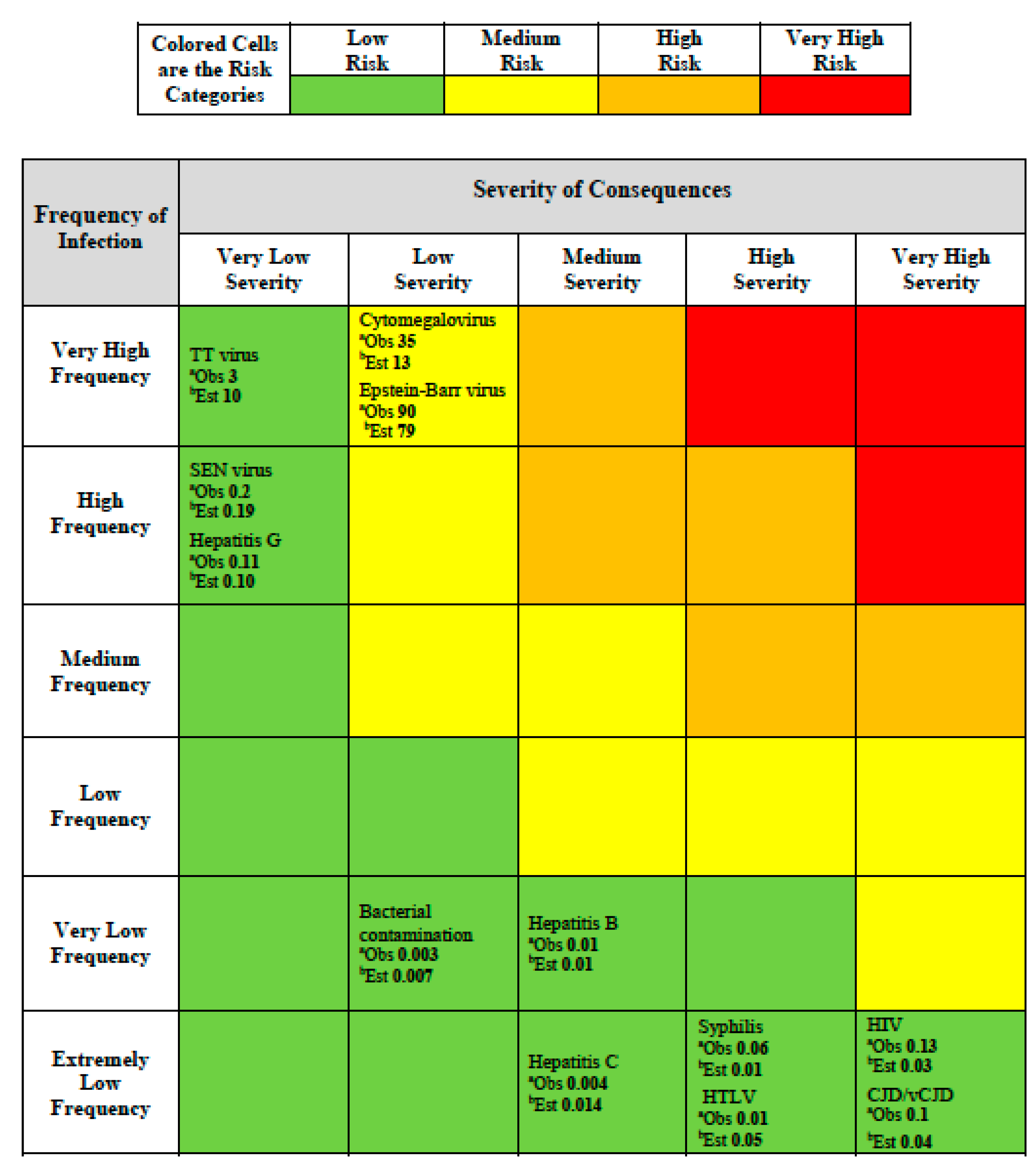
For the matrix scheme we adopted an additional color was added to deal with the wide range of values in frequency and consequences. In our scheme (
Figure 2) red indicates very high risk that requires immediate actions and priority in decision-making, orange indicates high risk that requires attention and a control process, yellow indicates moderate risk that requires a specific monitoring program, and green indicates low risk that can be managed according to current standard controls and regulation. The expectation for a risk assessment matrix is that the semi-quantitative ranking provided will be consistent with an underlying quantitative risk ranking which could, at least in theory, be defined by a risk function.
For each infectious hazard in
Table 2, we were able to place it in the risk assessment matrix (
Figure 2) by considering the frequency and severity category according to the assignments we made in
Table 2 according to the NHS scheme (
Table 1). In addition, because we have the experience-based estimates of frequency for each hazard and we could use a mid-point of the assigned judgmental severity category from
Table 2, we were able to calculate a risk value, using Equation (1). This value is shown for each infectious hazard in
Table 2 as the number labeled “
Obs.” meaning “observed” for each hazard placed in the risk assessment matrix (
Figure 2).
Table 2.
Severity and frequency of blood infectious diseases in Canada, 1987–1996, adapted from [
13].
Table 2.
Severity and frequency of blood infectious diseases in Canada, 1987–1996, adapted from [13].
| Infectious Diseases | Severity | Severity Category a | Frequency | Frequency Category b | Source |
|---|
| HIV | 105 | Very High | 0.000001 | Extremely Low | Blood Donors |
| HTLV | 104 | High | 0.0000008 | Extremely Low | Blood Donors |
| Hepatitis B | 103 | Medium | 0.00001 | Very Low | Blood Donors |
| Hepatitis C | 103 | Medium | 0.000004 | Extremely Low | Blood Donors |
| Hepatitis G | 10 | Very Low | 0.01 | High | Blood Donors |
| Bacterial Contamination | 102 | Low | 0.000026 | Very Low | Blood Donors |
| Cytomegalovirus | 102 | Low | 0.4 | Very High | Blood Donors |
| Epstein-Barr virus | 102 | Low | 0.9 | Very High | Blood Donors |
| TT virus | 10 | Very Low | 0.3 | Very High | Blood Donors |
| SEN virus | 10 | Very Low | 0.02 | High | Blood Donors |
| CJD/vCJD | 105 | Very High | 0.000001 | Extremely Low | Population |
| Syphilis | 104 | High | 0.000006 | Extremely Low | Blood Donors |
To allow us to evaluate the concern expressed by Cox, we calculated Spearman’s correlation of frequency and severity in this risk assessment matrix in logarithmic scales to confirm whether the data we were using satisfied the Cox requirement for a negative correlation between severity and frequency [
9].
Furthermore, we determined an empirical relationship for log-severity as a function of log-frequency for these infectious disease data, as:
Applying the basic relationship for risk in terms of severity and frequency (Equation (1)) to Equation (3), an empirical equation for risk as a function of frequency can be determined as:
Figure 2.
Risk assessment matrix providing colored risk categories plus observed and estimated risk.
a Observed (
Obs) risk numbers shown are based on the generic risk function (Risk = Frequency × Severity; Equation (1)) and using
Table 1 entries for frequency and severity based on
Table 2 data;
b Estimated (
Est) risk numbers shown are based on the fitted risk function Equation (4).
Figure 2.
Risk assessment matrix providing colored risk categories plus observed and estimated risk.
a Observed (
Obs) risk numbers shown are based on the generic risk function (Risk = Frequency × Severity; Equation (1)) and using
Table 1 entries for frequency and severity based on
Table 2 data;
b Estimated (
Est) risk numbers shown are based on the fitted risk function Equation (4).
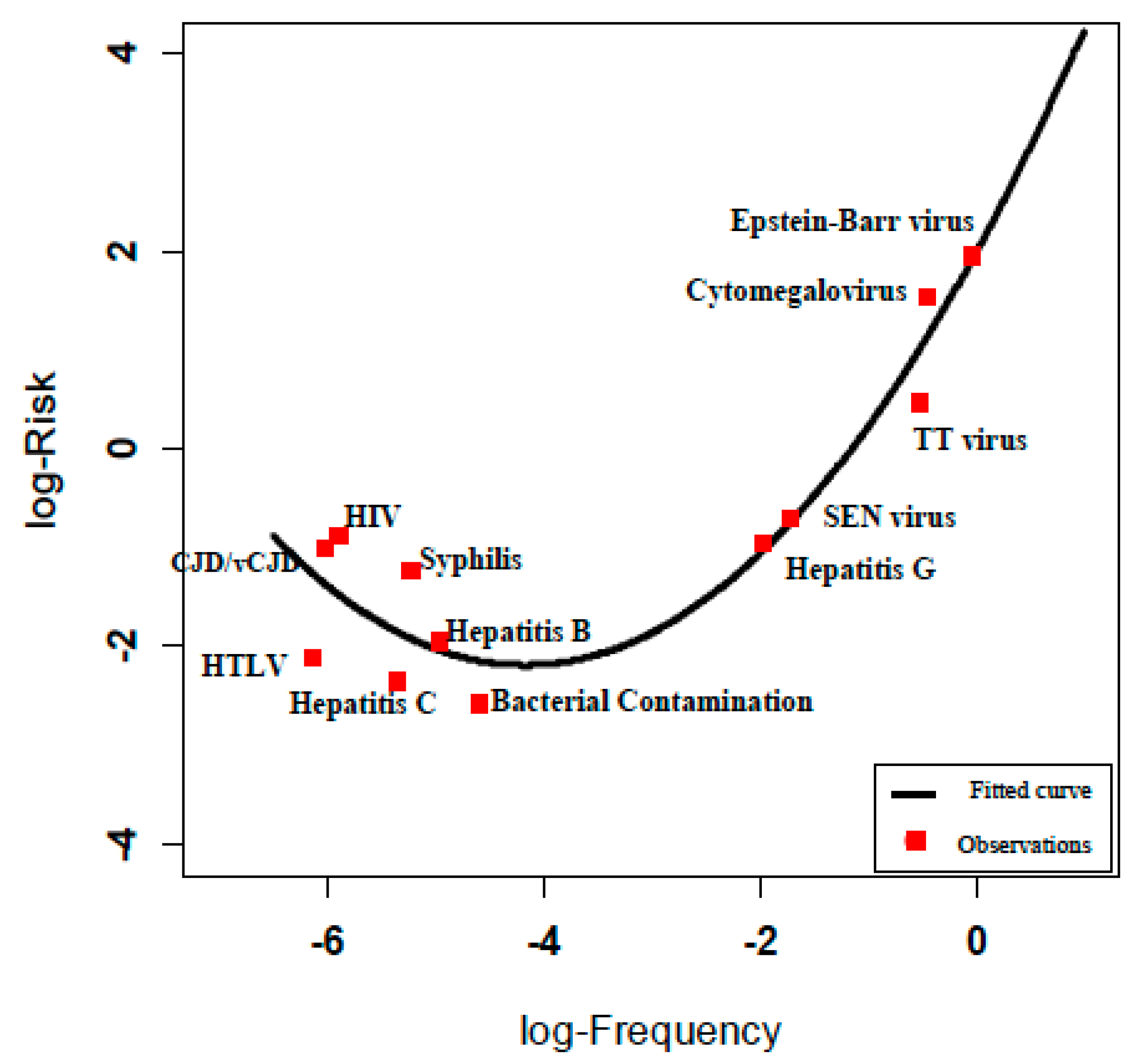
The relationship between this empirical function and the observed estimates of risk derived from
Table 2 is shown in
Figure 3.
The calculated risk values for each infection hazard are shown in the risk assessment matrix (
Figure 2) for each hazard as “
Est.” meaning “estimated”. The evidence in
Figure 2 does not show any medium, high or very high risks most likely because risk management of blood transfusions has been focused on lowering such extreme risks. However, this lack of higher risk observations challenged our ability to fully assess the concern that Cox raised about the value of predictions raised by risk assessment matrices. Consequently, we attempted to explore this matter further by using the empirical relationship (Equation (4)) we found based on the observed data (
Table 2).
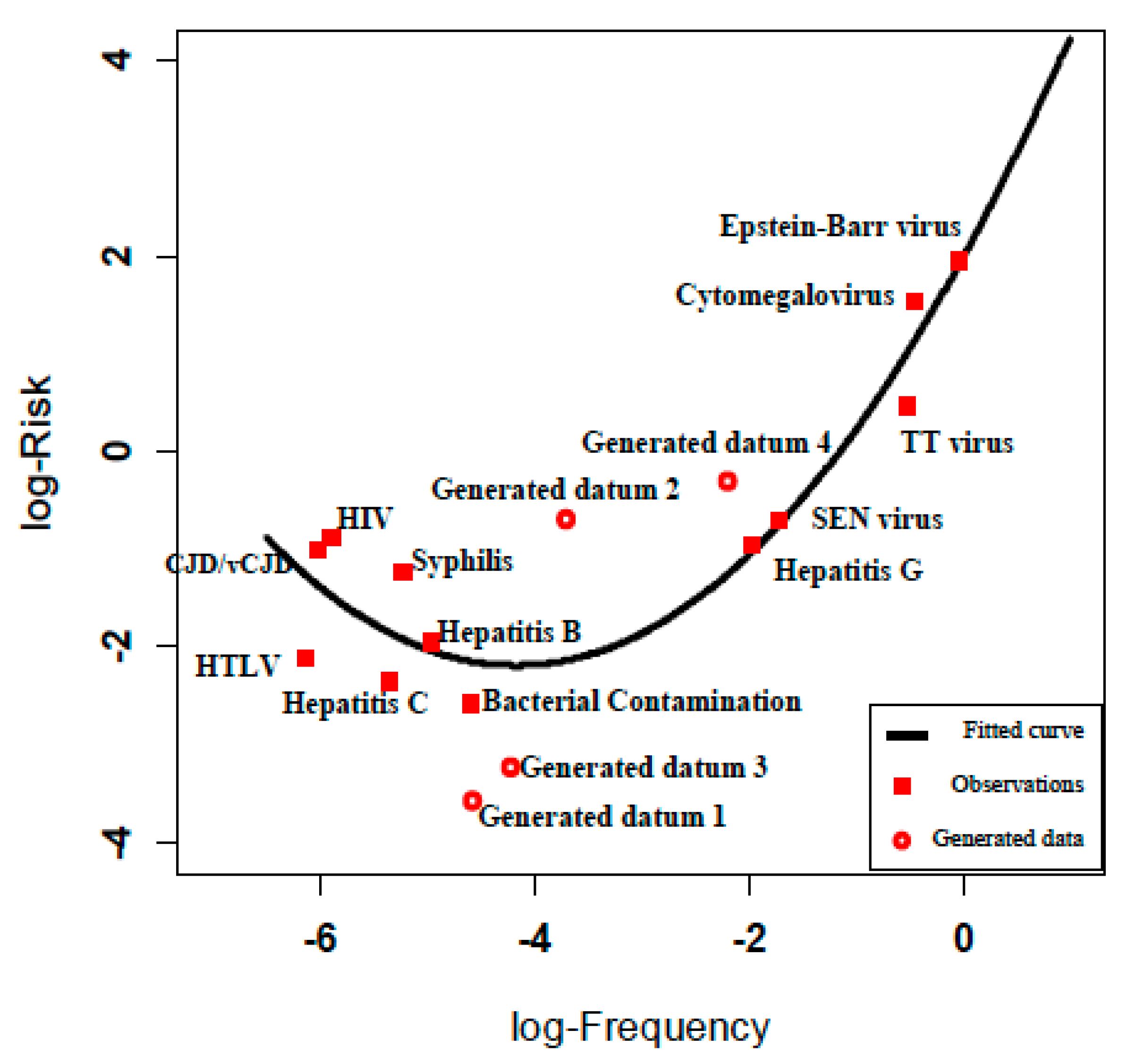
We sought to populate the risk assessment matrix with some generated risk values that were not found in
Table 2, but which were consistent with the empirical risk relationship (Equation (4)). For this purpose, we generated four scenarios with frequencies from the prediction interval limits for the new risk estimation in the middle parts (log-frequency between −4.5 and −2), where there are no experiential frequency estimates for blood transfusion infections hazards and calculated their severities accordingly to populate the risk assessment matrix (
Figure 4).
Figure 3.
Risk estimation according to log-Risk = log-Frequency + log-Severity.
Figure 3.
Risk estimation according to log-Risk = log-Frequency + log-Severity.
Figure 4.
Observed and estimated risk for observations and generated data.
Figure 4.
Observed and estimated risk for observations and generated data.
We divided the log-frequency gap (−4.5, −2) into three equal parts and selected the two cut points −2.83 and −3.67. The risk estimation for these points using Equation (4) is −1.76 (95% PI: (−3.22, −0.3)) and −2.13 (95% PI: (−3.57, −0.69)), respectively. We generated four data points according to the 95% prediction interval limits of fitted risks. We calculated the corresponding severities from Equation (3) and rounded the values to the nearest severity value (
Table 3).
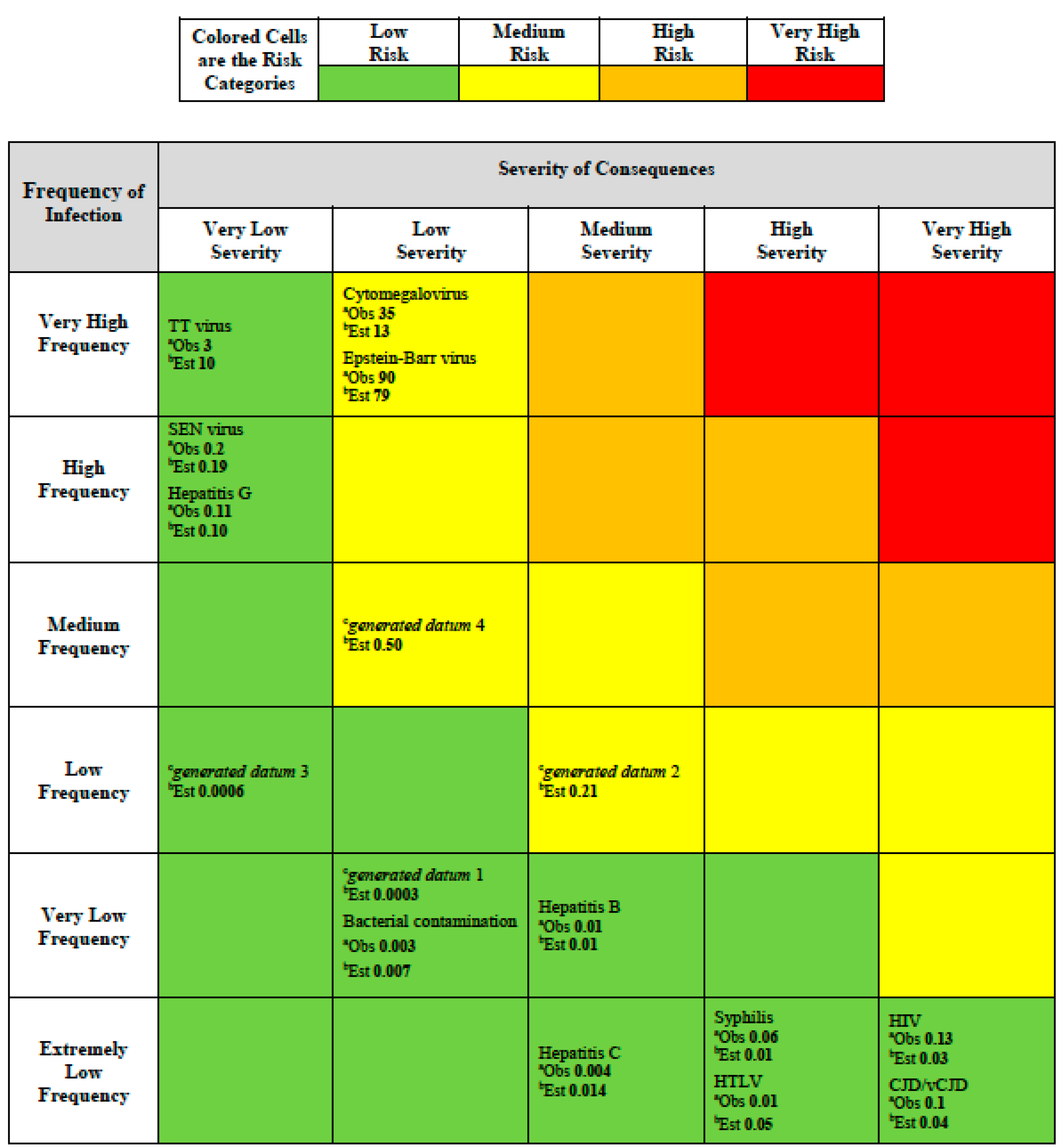
We illustrated the fitted risk curve defined by product of severity and frequency of the diseases (
Figure 4). Risks calculated from Equation (4) (reported to 1 significant figure to acknowledge the large uncertainty in these data) are shown on the risk assessment matrix in
Figure 5.
Figure 5.
Risk assessment matrix providing colored risk categories plus observed and estimated risk and generated data.
a Observed (
Obs) risk numbers shown are based on the generic risk function (Risk = Frequency × Severity; Equation (1)) and using
Table 1 entries frequency and severity using
Table 2 data;
b Estimated (
Est) risk numbers shown are based on the fitted risk function Equation (4);
c Generated data.
Figure 5.
Risk assessment matrix providing colored risk categories plus observed and estimated risk and generated data.
a Observed (
Obs) risk numbers shown are based on the generic risk function (Risk = Frequency × Severity; Equation (1)) and using
Table 1 entries frequency and severity using
Table 2 data;
b Estimated (
Est) risk numbers shown are based on the fitted risk function Equation (4);
c Generated data.
Table 3.
Frequency and severity of generated data.
Table 3.
Frequency and severity of generated data.
| Generated Data | Frequency | Risk | Severity |
|---|
| Datum 1 | 0.00003 | 0.0003 | 10 |
| Datum 2 | 0.00021 | 0.21 | 1000 |
| Datum 3 | 0.00006 | 0.0006 | 10 |
| Datum 4 | 0.005 | 0.5 | 100 |
4. Conclusions
Our limited validation of the Cox concern, using a tangible public health risk example, suggests a need for careful reconsideration of uses of the risk assessment matrix in risk management. There is no straightforward solution to address the concerns raised about risk assessment matrices. We do not propose a viable alternative to the risk assessment matrix tool for mapping risks that lack prior knowledge on harm frequency and its severity. However, risk analysts in all fields using the risk assessment matrix should be aware of this limitation. At least, they should investigate or contemplate the plausible correlation between frequency and severity for the hazards to be evaluated in the risk assessment matrix according to their prior knowledge in the field. When some data are available (generally not the case), they could look at data in the manner we did and try to fit a risk function and eventually compare the results with the risk assessment matrix results to identify anomalies.
We do not advocate a wholesale abandonment of risk assessment matrices for guiding risk management, particularly when applied, as they commonly are, to diverse hazards across a broad organizational portfolio. Of course, application of the risk matrix to a diverse range of hazards brings its own complications and challenges that must be acknowledged. The construction and evaluation of a risk assessment matrix can, if used wisely, stimulate a valuable discussion among operational personnel to reflect on what can go wrong and how well prepared the organization is equipped to manage various risks. Provided that the results of a risk assessment matrix exercise are treated with appropriate and healthy scepticism, they can serve a useful purpose for initiating and focusing a discussion about risk priorities within an organization. Achieving healthy scepticism may be difficult as long as risk matrix users see this technique as a simple tool and ignore the embedded complexity involved.
The primary danger revealed in this analysis, owing largely to the pioneering insight offered by Cox [
9], is to avoid allowing such over-simplified risk analyses to become the risk management decision rather than properly being only an operational input that can guide, challenge and inform decision-making to be based on a comprehensive understanding of risk. Risk assessment matrix outputs should not be allowed primarily to drive or, in the worst case, to become the risk management decision.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



