Environment-Aware Production Scheduling for Paint Shops in Automobile Manufacturing: A Multi-Objective Optimization Approach

Abstract
:1. Introduction
2. Literature Review
2.1. The Color-Batching Problem
2.2. The Car Sequencing Problem
3. Problem Formulation
3.1. The Production Setting
3.2. The Resequencing Buffer System
3.3. The MILP Model
3.4. Further Discussion
4. The Assembly Shop Sequencing Subproblem
- The paced production mode in assembly shop means that each job has identical processing time (). In addition, the position-based due date assignment scheme suggests that the situation can be further simplified as .
- Each lane of the selectivity bank is actually imposing a set of precedence constraints (in the chain form) on the relevant cars traveling through the lane. These precedence constraints must be respected when scheduling the assembly shop.
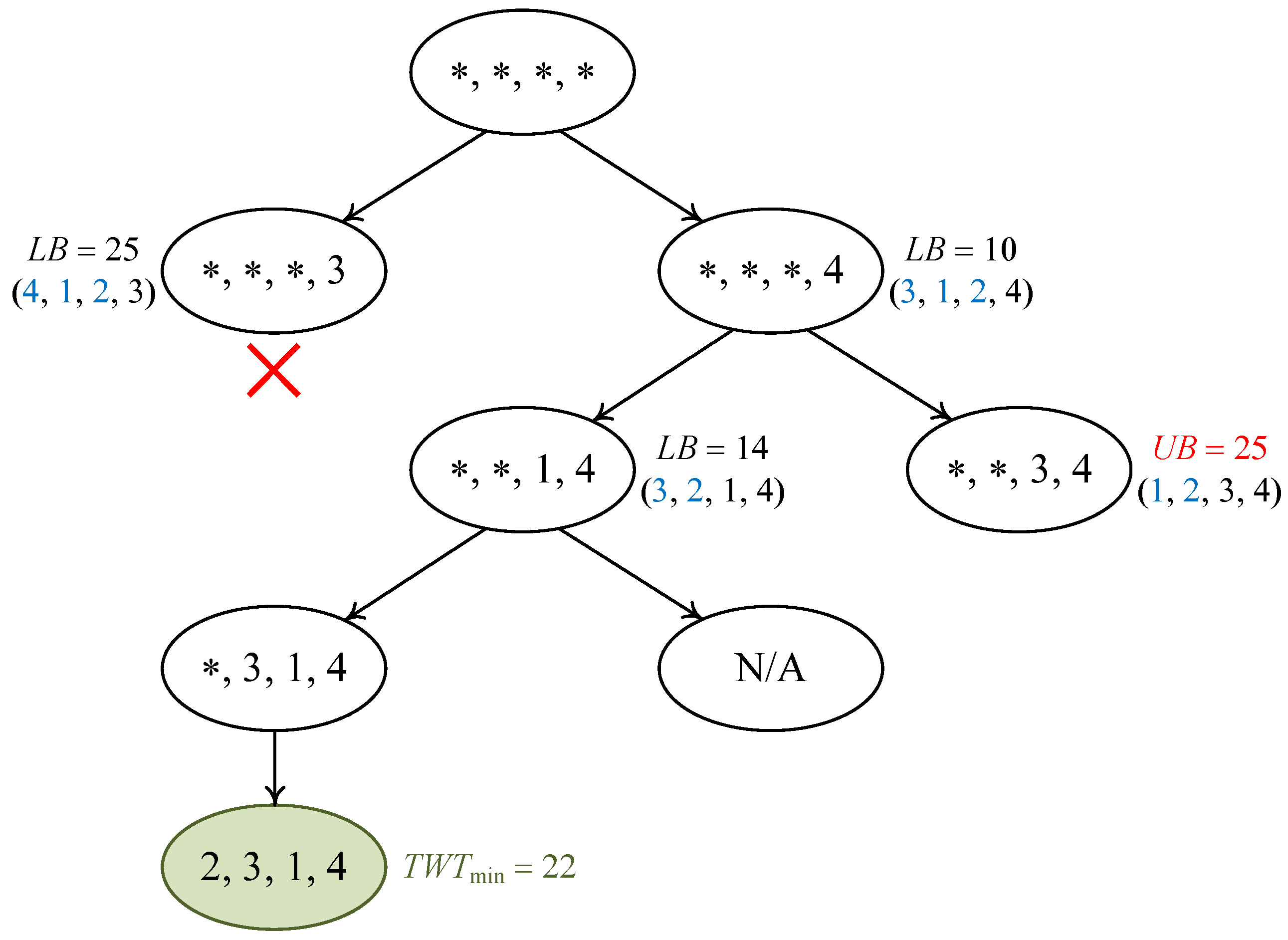
4.1. A Branch-and-Bound Algorithm
- The algorithm always selects the node with the smallest lower bound from for further exploration (Line 3). The motivation is to focus on the promising subregion of the search space so that it is likely to discover a feasible solution with lower objective value, leading to more opportunities of pruning the search tree.
- If the selected node has a lower bound below the current best objective value (upper bound), the algorithm has to further explore the node by creating branches on it. This is implemented in Line 6. In particular, the algorithm is attempting to insert jobs into the last vacant position of the current partial solution corresponding to . Constrained by the precedence relations given in the form of , only the last unscheduled job in each precedence chain () is applicable for this purpose. Hence, at most L descendant nodes will be created.
- For each descendant node , the lower bound is first obtained by employing a Hungarian algorithm to solve the relaxed scheduling problem (neglecting precedence constraints) which consists of the unscheduled jobs with respect to the partial solution of (Line 8). Then, three cases are identified and handled separately.
- If the schedule obtained after solving the relaxed problem () turns out to be a feasible solution for the original problem (which means respecting all the precedence relations), then the algorithm further investigates whether this solution defines a new upper bound and updates the relevant variables when necessary (Lines 11–14).
- If the obtained schedule is not feasible for the original problem but its objective value (i.e., the lower bound ) turns out to be larger than or equal to the current upper bound (i.e., ), the node can be discarded or fathomed (Line 16) because there is no hope of finding better solutions by branching on .
- Finally, if the lower bound value is below the upper bound, the node should be explored in the subsequent search process, and therefore, it is added to the node set (Line 18).
| Algorithm 1 B&B for |
Input: The weight () and due date () of each job , and L chains of jobs indicating their precedence relations ()
|
4.2. An Illustrative Example
5. The Main Algorithm: MOPSO
5.1. Fundamentals of PSO
5.2. Encoding and Decoding of Solutions
5.3. Evaluation of Solutions
5.4. Initialization of Solutions
- Step 1:
- Sort all the n cars in a non-decreasing order of their due dates. In the case of identical due dates, the cars with larger weights are prioritized. The sorted car sequence is denoted by S.
- Step 2:
- Select a car randomly from the first positions of S, recorded as car c. Let , where F stands for the car sequence to be determined for the paint shop. Remove car c from S.
- Step 3:
- Scan the first cars in the current S. Identify the car that leads to the minimum setup cost, i.e., such that , where represents the color index of car c and denotes the subsequence which consists of the first cars in S.
- Step 4:
- Append car to the end of sequence F. Remove car from S.
- Step 5:
- If , let and go back to Step 3. Otherwise, exit the procedure and output F.
- Input:
- The processing sequence for paint shop, .
- Step 1:
- Solve the single machine scheduling problem for the n cars. The optimal car sequence is recorded as .
- Step 2:
- For each car , find its position in and denote the position index by .
- Step 3:
- Let . Define for each lane .
- Step 4:
- For car , if there exists l such that , then let ; otherwise, let .
- Step 5:
- Push car to lane . Let .
- Step 6:
- Let . If , go back to Step 4. Otherwise, terminate the procedure.
5.5. Time-Variant Parameters
5.6. Sorting of Solutions
- Step 1:
- Evaluate the distance between each pair of solutions as , where represents the normalized distance between and with respect to the z-th objective function, i.e., , with (resp. ) denoting the maximum (resp. minimum) value of the z-th objective in . refers to the number of objectives in our problem.
- Step 2:
- For each solution , find the solutions that are situated most closely to in the objective space:
- (2.1)
- Let , .
- (2.2)
- For , let , .
- Step 3:
- For each solution , calculate the crowding distance value as .
5.7. Handling of Personal Best and Global Best Solutions
- Step 1:
- Incorporate all solutions from into B.
- Step 2:
- Identify the first two Pareto ranks in B by performing a Pareto-based sorting of the solutions. Remove the solutions that belong to the other Pareto ranks from B.
- Step 3:
- Evaluate each solution in B using the exact approach (i.e., getting the objective value by the B&B method detailed in Section 4).
- Step 4:
- Identify the first Pareto rank (i.e., the non-dominated solutions) in B. Remove the other solutions (those which are dominated) from B.
- Step 5:
- Sort the solutions in B according to the crowding distance measure (c.f. Section 5.6).
- Step 6:
- If , remove from B the solutions that are ranked beyond the first places.
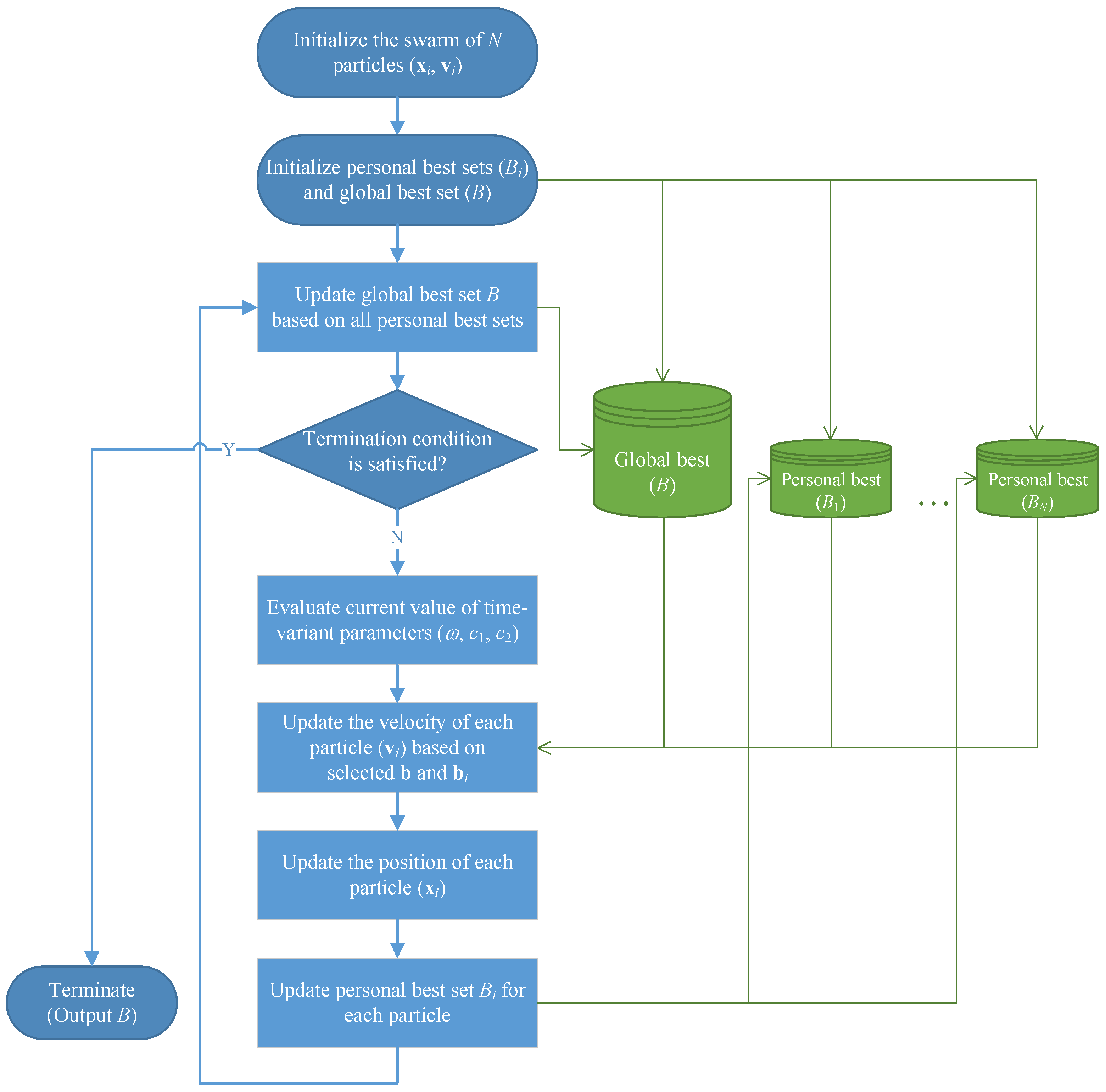
5.8. Summary of the MOPSO Algorithm
- Step 1:
- [Initialization] Apply the procedures given in Section 5.4 to generate the initial positions for a total of N particles, i.e., . Initialize the particles’ velocities by generating each component of randomly from . Let (for ) and . Define the iteration index .
- Step 2:
- [Global best] Update the global best solution set B based on the currently available personal best solution sets by applying the procedure given in Section 5.7 (part (2)).
- Step 3:
- [Termination test] If the termination condition is satisfied, terminate the algorithm with B as the output solutions. Otherwise, continue with the following steps.
- Step 4:
- Step 5:
- [Velocity update] Determine by randomly selecting a solution from . Determine by applying the roulette wheel method to select a solution from B. Based on the selected and , update the velocity for each particle i according to Equation (24), thus yielding .
- Step 6:
- [Position update] Update the position for each particle i according to Equation (25), yielding . If any component of the new position vector falls below , it is reassigned with ; if any component value exceeds , it is reassigned with ( represents a very small constant, say, 0.001).
- Step 7:
- [Personal best] Update the personal best solution set for each particle i with the newly obtained solution by following the rules stated in Section 5.7 (part (1)).
- Step 8:
- [Loop] Let , and then return to Step 2.
6. Computational Experiments and Results
6.1. Experimental Setup
- The number of cars (n) and the number of color options (E) are considered in a coordinated way at eight different levels, i.e., .
- The number of lanes in the selectivity bank is considered at three levels, i.e., . We do not consider limitations on the capacity of each lane because it is assumed that the cars pass through the lanes dynamically.
- The required color for each car i is randomly determined from the set with equal probability. The position-based due date of car i is set as , where follows the binomial distribution . The weight of car i is generated from the discrete uniform distribution .
- The emission cost coefficient is determined by for , where is generated from the uniform distribution . Meanwhile, it is assumed that .
- The ONVG (overall non-dominated vector generation) indicator [37] measures the number of solutions in the non-dominated solution set, i.e., . Higher values suggest that the corresponding algorithm is able to provide a wider range of choices for the ultimate decision-making.
- The CM (coverage metric) indicator [38] is defined on the basis of another non-dominated solution set () for comparison with . Formally, it is defined aswhere indicates the case that either dominates or (i.e., having equal objective vectors). It is clear that reflects the proportion of solutions in that are dominated by (or equal to) some solution in . Therefore, a higher value of suggests better performance of the algorithm which produces .
- The and indicators [39] describe the distance between the solutions in and a reference solution set (ideally, the exact Pareto frontier of the problem) in the objective space. Formally, the distance metrics are defined aswhere the reference set is usually composed of all non-dominated solutions obtained by the compared algorithms as an approximation to the real Pareto frontier if the latter is unknown. In the above equations, where is the value interval for the z-th objective function. Clearly, smaller values of and suggest that the solutions in are closer to the estimated Pareto frontier.
- The TS (Tan’s Spacing) indicator [40] reflects how evenly the solutions in are distributed. It is defined aswhere with denoting the Euclidean distance between and its closest neighbor solution in (with regard to the objective space). Smaller values of indicate that the solutions are distributed more evenly and thus are more preferable for decision-making.
- Number of particles in the swarm: ;
- Beginning and ending values of inertia weight: , ;
- Beginning and ending values of acceleration coefficients: , , , ;
- Size limit on personal best solution sets: ;
- Size limit on global best solution set: .
6.2. Evaluation of Optimality
6.3. Comparison with Typical MOEAs
- Focusing on the ONVG indicator, we can see from the “Avg.” row that the proposed MOPSO has obtained more non-dominated solutions than the compared algorithms in the average sense (except in the comparison with MOEA/D-ACO on the group of 200-car instances). The statistical results also suggest that the differences are significant in most cases. The MOPSO outperforms the pccsAMOPSO consistently on all groups of instances, whereas the advantage over MOEA/D-ACO diminishes as the problem size grows. The relatively higher performance of MOEA/D-ACO on larger instances reveals the benefit of the decomposition-based optimization approach which promotes diversification and thereby handles huge solution spaces effectively. Overall, the number of obtained solutions increases with the problem size, which is not surprising because increased number of cars and buffer lanes will create more opportunities of making compromises between the emission objective and the tardiness objective.
- By taking a look at the and indicators, we find that the MOPSO has clearly outperformed both compared algorithms in terms of the average and maximum distances to the approximated Pareto frontier. In particular, the MOPSO has achieved the smallest average value of among the three algorithms on 89 out of the 120 instances, and has achieved the smallest average value of on 94 out of the 120 instances. The superior performance can be attributed to the enhanced search ability represented by the redesigned personal/global best handling mechanisms and some other problem-specific components of the algorithm. It is worthwhile to point out that the reference set (used for calculating and in Equations (32) and ()), which represents the approximated Pareto frontier, is constructed by executing the two compared algorithms with sufficiently long iterations. This suggests that a bias has been created in favor of the MOEA/D-ACO and pccsAMOPSO. The remarkable performance of the proposed algorithm despite such an adverse condition is therefore quite convincing.
- By observing the TS indicator, we notice that the MOPSO has achieved the smallest average value among the three algorithms on 90 out of the 120 instances. The superior performance can be attributed to the improved solution sorting mechanism in the MOPSO which relies on a precisely defined crowding distance measure. In particular, our distance measure is based on the concept of Euclidean distances, which complies with the definition of the TS indicator. By contrast, the MOEA/D-ACO does not incorporate an explicit sorting mechanism based on crowdedness and therefore it results in the poorest performance in terms of the TS indicator. The pccsAMOPSO algorithm utilizes a novel distance measure called the parallel cell distance to estimate the density of solutions, which turns out to be effective in the process of solving our problem, especially for relatively smaller-sized instances. Overall, our distance measure has been proved to work more effectively under the TS indicator because of its accuracy for characterizing the distribution of solutions in the objective space. Finally, a noticeable trend is that the TS values generally increase with the size of instances. The degradation reflects the exponential explosion of solution spaces which adds to the difficulty of obtaining evenly-spaced non-dominated solutions.
- According to the CM indicator, it can be found that the average value of stays above 0.90 and the average value of stays above 0.94 across all the instances, which apparently means that a large portion of the solutions obtained by MOEA/D-ACO () and pccsAMOPSO () are dominated by or equal to (in terms of the objective vector) certain solutions output by the proposed algorithm (). Meanwhile, the average values of and stay below 0.08 across all the instances, which indicates that the solution quality of the compared algorithms cannot match that of the proposed algorithm. To reveal the relative strengths of MOEA/D-ACO and pccsAMOPSO, we also report the average values of and . The comparative results show that the MOEA/D-ACO maintains an advantage over the pccsAMOPSO, and the superiority becomes more apparent as the size of instances grows (noting that increases from 0.58 for to 0.71 for and decreases from 0.37 for to 0.25 for ), which validates high flexibility of the decomposition-based approach.
- As suggested by the statistical results given in Table 12 and Table 13 (one-tailed p-values), 29 of the 32 paired samples tested are significantly different in the statistical sense (under the significance level of 0.01). The 3 insignificant cases occur when we perform the test on the ONVG values. The underlying fact is that the number of non-dominated solutions obtained in each run of an algorithm is not very stable (it is more prone to random perturbations than other indicators). In general, the statistical results verify that the proposed MOPSO significantly outperforms the compared approaches for solving the bi-objective scheduling problem considered in this paper.
7. Conclusions
- A random key-based encoding scheme which facilitates PSO implementation;
- A dedicated procedure for initialization of particles by exploiting problem-specific information;
- A set of time-variant parameters which help to achieve a better balance of extensive exploration and intensive exploitation by means of adjusting the search patterns dynamically;
- Some novel mechanisms to deal with multi-objective optimization (e.g., strategies for sorting solutions based on an accurately defined crowding distance measure and techniques for maintaining personal/global best solutions considering both Pareto dominance and diversity).
Acknowledgments
Conflicts of Interest
Notations
| n | number of cars |
| E | number of color options |
| L | number of lanes in the buffer |
| position-based due date of car i | |
| priority weight of car i | |
| tardiness of car i in the assembly shop | |
| amount of emission incurred when switching from color to color | |
| a 0−1 constant which equals 1 iff car i requires color e | |
| total pollutant emissions in the paint shop | |
| total weighted tardiness in the assembly shop | |
| lower bound of used by the branch-and-bound algorithm | |
| position of particle i in the MOPSO | |
| velocity of particle i in the MOPSO | |
| t | iteration index in the MOPSO |
| time-variant inertia weight in the MOPSO | |
| , | time-variant acceleration coefficients in the MOPSO |
| personal best solution (associated with particle i) selected for position update | |
| global best solution selected for position update | |
| personal best solution set maintained for particle i | |
| B | global best solution set |
| maximum size of personal best solution sets | |
| maximum size of global best solution set | |
| N | number of particles in the MOPSO |
| crowding distance value for solution i in a non-dominated set | |
| truncation parameter in the calculation of | |
| number of non-dominated solutions in the obtained solution set | |
| coverage metric which reflects the dominance relation between two solution sets | |
| , | distance metrics which depict how far the solutions are situated from the true Pareto frontier |
| spacing metric which describes how evenly the solutions in a set are distributed |
References
- He, L.Y.; Ou, J.J. Pollution Emissions, Environmental Policy, and Marginal Abatement Costs. Int. J. Environ. Res. Public Health 2017, 14, 1509. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Chiong, R.; Michalewicz, Z.; Chang, P.C. Sustainable scheduling of manufacturing and transportation systems. Eur. J. Oper. Res. 2016, 3, 741–743. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, F.; Fang, K.; Sutherland, J.W. Energy-conscious flow shop scheduling under time-of-use electricity tariffs. CIRP Ann. Manuf. Technol. 2014, 63, 37–40. [Google Scholar] [CrossRef]
- Liu, C.H.; Huang, D.H. Reduction of power consumption and carbon footprints by applying multi-objective optimisation via genetic algorithms. Int. J. Prod. Res. 2014, 52, 337–352. [Google Scholar] [CrossRef]
- Zhou, L.; Xu, K.; Cheng, X.; Xu, Y.; Jia, Q. Study on optimizing production scheduling for water-saving in textile dyeing industry. J. Clean. Prod. 2017, 141, 721–727. [Google Scholar] [CrossRef]
- Spieckermann, S.; Gutenschwager, K.; Voß, S. A sequential ordering problem in automotive paint shops. Int. J. Prod. Res. 2004, 42, 1865–1878. [Google Scholar] [CrossRef]
- Moon, D.H.; Kim, H.S.; Song, C. A simulation study for implementing color rescheduling storage in an automotive factory. Simulation 2005, 81, 625–635. [Google Scholar] [CrossRef]
- Hartmann, S.A.; Runkler, T.A. Online optimization of a color sorting assembly buffer using ant colony optimization. In Proceedings of the 2007, Selected Papers of the Annual International Conference of the German Operations Research Society (GOR), Saarbrücken, 5–7 September 2007; Kalcsics, J., Nickel, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 415–420. [Google Scholar]
- Sun, H.; Fan, S.; Shao, X.; Zhou, J. A colour-batching problem using selectivity banks in automobile paint shops. Int. J. Prod. Res. 2015, 53, 1124–1142. [Google Scholar] [CrossRef]
- Ko, S.S.; Han, Y.H.; Choi, J.Y. Paint batching problem on M-to-1 conveyor systems. Comput. Oper. Res. 2016, 74, 118–126. [Google Scholar] [CrossRef]
- Epping, T.; Hochstättler, W.; Oertel, P. Complexity results on a paint shop problem. Discret. Appl. Math. 2004, 136, 217–226. [Google Scholar] [CrossRef]
- Xu, Y.; Zhou, J.G. A virtual resequencing problem in automobile paint shops. In Proceedings of the 22nd International Conference on Industrial Engineering and Engineering Management 2015: Core Theory and Applications of Industrial Engineering (Volume 1); Qi, E., Shen, J., Dou, R., Eds.; Atlantis Press: Paris, France, 2016; pp. 71–80. [Google Scholar]
- Amini, H.; Meunier, F.; Michel, H.; Mohajeri, A. Greedy colorings for the binary paintshop problem. J. Discret. Algorithms 2010, 8, 8–14. [Google Scholar] [CrossRef]
- Andres, S.D.; Hochstättler, W. Some heuristics for the binary paint shop problem and their expected number of colour changes. J. Discret. Algorithms 2011, 9, 203–211. [Google Scholar] [CrossRef]
- Sun, H.; Han, J. A study on implementing color-batching with selectivity banks in automotive paint shops. J. Manuf. Syst. 2017, 44, 42–52. [Google Scholar] [CrossRef]
- Parrello, B.D.; Kabat, W.C.; Wos, L. Job-shop scheduling using automated reasoning: A case study of the car-sequencing problem. J. Autom. Reason. 1986, 2, 1–42. [Google Scholar] [CrossRef]
- Kis, T. On the complexity of the car sequencing problem. Oper. Res. Lett. 2004, 32, 331–335. [Google Scholar] [CrossRef]
- Estellon, B.; Gardi, F. Car sequencing is NP-hard: A short proof. J. Oper. Res. Soc. 2013, 64, 1503–1504. [Google Scholar] [CrossRef]
- Golle, U.; Rothlauf, F.; Boysen, N. Iterative beam search for car sequencing. Ann. Oper. Res. 2015, 226, 239–254. [Google Scholar] [CrossRef]
- Zinflou, A.; Gagné, C.; Gravel, M. Genetic algorithm with hybrid integer linear programming crossover operators for the car-sequencing problem. INFOR Inform. Syst. Oper. Res. 2010, 48, 23–37. [Google Scholar] [CrossRef]
- Thiruvady, D.; Ernst, A.; Wallace, M. A Lagrangian-ACO matheuristic for car sequencing. EURO J. Comput. Optim. 2014, 2, 279–296. [Google Scholar] [CrossRef]
- Solnon, C.; Cung, V.D.; Nguyen, A.; Artigues, C. The car sequencing problem: Overview of state-of-the-art methods and industrial case-study of the ROADEF’2005 challenge problem. Eur. J. Oper. Res. 2008, 191, 912–927. [Google Scholar] [CrossRef]
- Estellon, B.; Gardi, F.; Nouioua, K. Two local search approaches for solving real-life car sequencing problems. Eur. J. Oper. Res. 2008, 191, 928–944. [Google Scholar] [CrossRef]
- Ribeiro, C.C.; Aloise, D.; Noronha, T.F.; Rocha, C.; Urrutia, S. A hybrid heuristic for a multi-objective real-life car sequencing problem with painting and assembly line constraints. Eur. J. Oper. Res. 2008, 191, 981–992. [Google Scholar] [CrossRef]
- Briant, O.; Naddef, D.; Mounié, G. Greedy approach and multi-criteria simulated annealing for the car sequencing problem. Eur. J. Oper. Res. 2008, 191, 993–1003. [Google Scholar] [CrossRef]
- Gavranović, H. Local search and suffix tree for car-sequencing problem with colors. Eur. J. Oper. Res. 2008, 191, 972–980. [Google Scholar] [CrossRef]
- Jahren, E.; Achá, R.A. A column generation approach and new bounds for the car sequencing problem. Ann. Oper. Res. 2017, in press. [Google Scholar] [CrossRef]
- Zhang, S.; Yu, D.; Shao, X.; Wang, S.; Zhang, C.; Lin, W. A novel artificial ecological niche optimization algorithm for car sequencing problem considering energy consumption. Proc. Inst. Mech. Eng. Part B 2015, 229, 546–562. [Google Scholar] [CrossRef]
- Yavuz, M. Iterated beam search for the combined car sequencing and level scheduling problem. Int. J. Prod. Res. 2013, 51, 3698–3718. [Google Scholar] [CrossRef]
- Chutima, P.; Olarnviwatchai, S. A multi-objective car sequencing problem on two-sided assembly lines. J. Intell. Manuf. 2017, in press. [Google Scholar] [CrossRef]
- Boysen, N.; Zenker, M. A decomposition approach for the car resequencing problem with selectivity banks. Comput. Oper. Res. 2013, 40, 98–108. [Google Scholar] [CrossRef]
- Pinedo, M.L. Scheduling: Theory, Algorithms, and Systems, 5th ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Leung, J.Y.T.; Young, G.H. Minimizing total tardiness on a single machine with precedence constraints. ORSA J. Comput. 1990, 2, 346–352. [Google Scholar] [CrossRef]
- Banks, A.; Vincent, J.; Anyakoha, C. A review of particle swarm optimization. Part I: Background and development. Nat. Comput. 2007, 6, 467–484. [Google Scholar] [CrossRef]
- Vepsalainen, A.P.; Morton, T.E. Priority rules for job shops with weighted tardiness costs. Manag. Sci. 1987, 33, 1035–1047. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Van Veldhuizen, D.A.; Lamont, G.B. On measuring multiobjective evolutionary algorithm performance. In Proceedings of the IEEE Congress on Evolutionary Computation, La Jolla, CA, USA, 16–19 July 2000; Volume 1, pp. 204–211. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Ulungu, E.L.; Teghem, J.; Ost, C. Efficiency of interactive multi-objective simulated annealing through a case study. J. Oper. Res. Soc. 1998, 49, 1044–1050. [Google Scholar] [CrossRef]
- Tan, K.C.; Goh, C.K.; Yang, Y.J.; Lee, T.H. Evolving better population distribution and exploration in evolutionary multi-objective optimization. Eur. J. Oper. Res. 2006, 171, 463–495. [Google Scholar] [CrossRef]
- Ratnaweera, A.; Halgamuge, S.K.; Watson, H.C. Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients. IEEE Trans. Evol. Comput. 2004, 8, 240–255. [Google Scholar] [CrossRef]
- Ke, L.; Zhang, Q.; Battiti, R. MOEA/D-ACO: A multiobjective evolutionary algorithm using decomposition and ant colony. IEEE Trans. Cybern. 2013, 43, 1845–1859. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Yen, G.G. Adaptive multiobjective particle swarm optimization based on parallel cell coordinate system. IEEE Trans. Evol. Comput. 2015, 19, 1–18. [Google Scholar]
- Horng, S.C.; Lin, S.S. An ordinal optimization theory-based algorithm for a class of simulation optimization problems and application. Expert Syst. Appl. 2009, 36, 9340–9349. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job Index (j) | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Weight () | 5 | 1 | 8 | 3 |
| Due date () | 2 | 2 | 1 | 1 |
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1.80 | 2.19 | 0.21 | 1.32 | 0.95 | 2.05 | 1.54 | 0.82 | |
| No. | ONVG | TS | CM | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MOPSO | CPLEX | MOPSO | CPLEX | MOPSO | CPLEX | MOPSO | CPLEX | |||
| 1 | 9.86 | 12.00 | 0.009 | 0.000 | 0.018 | 0.000 | 1.44 | 1.33 | 0.40 | 1.00 |
| 2 | 12.73 | 14.00 | 0.011 | 0.002 | 0.028 | 0.012 | 1.32 | 1.37 | 0.43 | 0.98 |
| 3 | 10.46 | 12.00 | 0.013 | 0.000 | 0.030 | 0.000 | 1.30 | 1.44 | 0.47 | 1.00 |
| 4 | 10.91 | 13.00 | 0.008 | 0.000 | 0.024 | 0.000 | 1.42 | 1.40 | 0.39 | 1.00 |
| 5 | 12.68 | 14.00 | 0.016 | 0.004 | 0.034 | 0.010 | 1.49 | 1.30 | 0.54 | 0.98 |
| Avg. | 11.33 | 13.00 | 0.011 | 0.001 | 0.027 | 0.004 | 1.39 | 1.37 | 0.45 | 0.99 |
| No. | Size | MOPSO | MOEA/D-ACO | pccsAMOPSO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ONVG | TS | ONVG | TS | ONVG | TS | ||||||||
| 1 | 9.86 | 0.009 | 0.022 | 1.44 | 10.97 | 0.060 | 0.151 | 1.96 | 10.48 | 0.070 | 0.172 | 1.50 | |
| 2 | * | 12.73 | 0.020 | 0.047 | 1.32 | 9.49 | 0.043 | 0.074 | 1.69 | 9.47 | 0.054 | 0.142 | 2.15 |
| 3 | * | 10.46 | 0.021 | 0.045 | 1.30 | 12.01 | 0.063 | 0.188 | 1.37 | 11.11 | 0.040 | 0.103 | 1.30 |
| 4 | * | 10.91 | 0.013 | 0.029 | 1.42 | 10.23 | 0.032 | 0.065 | 1.77 | 10.97 | 0.093 | 0.199 | 1.79 |
| 5 | * | 12.68 | 0.017 | 0.037 | 1.49 | 9.51 | 0.061 | 0.179 | 1.63 | 9.30 | 0.040 | 0.083 | 1.69 |
| 6 | 10.20 | 0.026 | 0.059 | 1.48 | 11.01 | 0.032 | 0.090 | 1.40 | 10.56 | 0.070 | 0.135 | 2.48 | |
| 7 | * | 10.79 | 0.018 | 0.042 | 1.43 | 10.70 | 0.022 | 0.047 | 2.26 | 11.27 | 0.036 | 0.069 | 2.26 |
| 8 | * | 11.99 | 0.032 | 0.073 | 1.34 | 11.69 | 0.018 | 0.044 | 2.14 | 11.87 | 0.022 | 0.047 | 1.87 |
| 9 | * | 10.60 | 0.016 | 0.036 | 1.26 | 10.59 | 0.053 | 0.096 | 1.76 | 10.12 | 0.058 | 0.146 | 1.92 |
| 10 | * | 12.75 | 0.024 | 0.044 | 1.48 | 13.00 | 0.027 | 0.069 | 1.41 | 13.05 | 0.089 | 0.163 | 1.81 |
| 11 | 12.20 | 0.020 | 0.031 | 1.18 | 11.34 | 0.016 | 0.032 | 1.18 | 11.70 | 0.094 | 0.271 | 1.94 | |
| 12 | * | 12.42 | 0.018 | 0.040 | 1.45 | 12.68 | 0.043 | 0.088 | 2.29 | 12.90 | 0.085 | 0.146 | 1.32 |
| 13 | * | 12.26 | 0.020 | 0.041 | 1.26 | 11.97 | 0.013 | 0.036 | 1.49 | 12.20 | 0.041 | 0.113 | 2.10 |
| 14 | * | 10.79 | 0.020 | 0.031 | 1.37 | 10.63 | 0.048 | 0.129 | 1.35 | 11.06 | 0.057 | 0.129 | 1.71 |
| 15 | * | 13.88 | 0.030 | 0.051 | 1.37 | 12.53 | 0.053 | 0.137 | 1.65 | 13.66 | 0.065 | 0.119 | 1.87 |
| 16 | 11.79 | 0.028 | 0.061 | 1.34 | 11.55 | 0.060 | 0.149 | 1.51 | 12.07 | 0.024 | 0.067 | 1.30 | |
| 17 | * | 12.94 | 0.028 | 0.065 | 1.48 | 11.51 | 0.020 | 0.049 | 1.76 | 13.20 | 0.053 | 0.120 | 1.52 |
| 18 | * | 11.13 | 0.022 | 0.049 | 1.49 | 10.20 | 0.059 | 0.123 | 1.67 | 11.52 | 0.065 | 0.148 | 1.47 |
| 19 | * | 12.36 | 0.014 | 0.022 | 1.40 | 12.02 | 0.065 | 0.105 | 1.51 | 11.41 | 0.026 | 0.046 | 1.40 |
| 20 | * | 12.46 | 0.030 | 0.061 | 1.36 | 13.35 | 0.043 | 0.123 | 1.62 | 12.20 | 0.053 | 0.118 | 1.25 |
| 21 | 15.32 | 0.030 | 0.059 | 1.27 | 16.20 | 0.014 | 0.024 | 1.76 | 15.21 | 0.030 | 0.074 | 1.79 | |
| 22 | * | 12.84 | 0.019 | 0.047 | 1.28 | 11.53 | 0.059 | 0.158 | 1.53 | 12.35 | 0.044 | 0.081 | 1.83 |
| 23 | * | 13.55 | 0.010 | 0.022 | 1.48 | 13.88 | 0.017 | 0.029 | 1.71 | 13.70 | 0.085 | 0.250 | 1.97 |
| 24 | * | 13.88 | 0.020 | 0.033 | 1.19 | 13.84 | 0.058 | 0.123 | 1.88 | 12.77 | 0.039 | 0.094 | 1.75 |
| 25 | * | 12.37 | 0.011 | 0.027 | 1.47 | 12.29 | 0.035 | 0.094 | 1.57 | 11.37 | 0.091 | 0.177 | 1.52 |
| 26 | 13.22 | 0.010 | 0.018 | 1.26 | 12.31 | 0.043 | 0.123 | 1.65 | 13.14 | 0.069 | 0.130 | 2.07 | |
| 27 | * | 14.58 | 0.028 | 0.068 | 1.35 | 12.82 | 0.065 | 0.148 | 1.55 | 14.21 | 0.059 | 0.163 | 1.28 |
| 28 | * | 12.17 | 0.032 | 0.060 | 1.39 | 10.98 | 0.025 | 0.076 | 2.22 | 12.13 | 0.077 | 0.135 | 1.85 |
| 29 | * | 10.60 | 0.028 | 0.064 | 1.28 | 10.58 | 0.063 | 0.120 | 1.73 | 9.74 | 0.060 | 0.176 | 1.97 |
| 30 | * | 13.90 | 0.014 | 0.022 | 1.21 | 15.06 | 0.014 | 0.031 | 1.32 | 14.35 | 0.063 | 0.170 | 1.48 |
| Avg. | 12.26 | 0.021 | 0.044 | 1.36 | 11.88 | 0.041 | 0.097 | 1.68 | 11.97 | 0.058 | 0.133 | 1.74 | |
| No. | Size | MOPSO | MOEA/D-ACO | pccsAMOPSO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ONVG | TS | ONVG | TS | ONVG | TS | ||||||||
| 31 | 16.75 | 0.037 | 0.075 | 1.43 | 15.48 | 0.062 | 0.169 | 1.64 | 16.01 | 0.131 | 0.265 | 1.52 | |
| 32 | * | 16.72 | 0.048 | 0.107 | 1.42 | 17.62 | 0.034 | 0.057 | 1.81 | 13.85 | 0.023 | 0.044 | 1.87 |
| 33 | * | 15.38 | 0.038 | 0.093 | 1.35 | 15.62 | 0.044 | 0.085 | 1.63 | 14.01 | 0.123 | 0.328 | 1.60 |
| 34 | * | 16.53 | 0.044 | 0.085 | 1.36 | 14.98 | 0.026 | 0.046 | 1.34 | 15.20 | 0.095 | 0.183 | 1.34 |
| 35 | * | 15.66 | 0.026 | 0.056 | 1.36 | 14.57 | 0.073 | 0.169 | 1.54 | 15.28 | 0.033 | 0.095 | 1.49 |
| 36 | 15.97 | 0.047 | 0.098 | 1.49 | 15.59 | 0.067 | 0.109 | 2.19 | 12.91 | 0.076 | 0.203 | 1.90 | |
| 37 | * | 17.02 | 0.027 | 0.061 | 1.26 | 18.50 | 0.083 | 0.171 | 1.25 | 16.19 | 0.044 | 0.080 | 1.34 |
| 38 | * | 16.25 | 0.035 | 0.079 | 1.30 | 14.65 | 0.079 | 0.210 | 1.21 | 14.68 | 0.094 | 0.240 | 1.29 |
| 39 | * | 14.86 | 0.037 | 0.065 | 1.69 | 14.54 | 0.074 | 0.215 | 2.51 | 12.06 | 0.057 | 0.136 | 1.72 |
| 40 | * | 17.60 | 0.036 | 0.078 | 1.55 | 16.61 | 0.059 | 0.166 | 1.45 | 15.23 | 0.061 | 0.151 | 1.49 |
| 41 | 17.48 | 0.049 | 0.109 | 1.52 | 15.81 | 0.053 | 0.123 | 1.65 | 16.49 | 0.023 | 0.059 | 1.57 | |
| 42 | * | 18.98 | 0.045 | 0.076 | 1.37 | 17.82 | 0.067 | 0.147 | 2.04 | 17.86 | 0.115 | 0.292 | 1.37 |
| 43 | * | 17.14 | 0.041 | 0.076 | 1.66 | 16.01 | 0.052 | 0.102 | 1.52 | 16.64 | 0.062 | 0.126 | 1.92 |
| 44 | * | 17.06 | 0.027 | 0.064 | 1.53 | 17.88 | 0.079 | 0.196 | 1.50 | 14.32 | 0.129 | 0.228 | 1.59 |
| 45 | * | 15.76 | 0.033 | 0.053 | 1.44 | 14.29 | 0.073 | 0.151 | 1.68 | 13.92 | 0.071 | 0.181 | 1.62 |
| 46 | 16.82 | 0.036 | 0.088 | 1.35 | 16.77 | 0.030 | 0.085 | 1.56 | 14.41 | 0.144 | 0.368 | 1.65 | |
| 47 | * | 16.63 | 0.029 | 0.045 | 1.70 | 17.42 | 0.067 | 0.123 | 1.83 | 13.33 | 0.085 | 0.159 | 1.92 |
| 48 | * | 17.70 | 0.023 | 0.037 | 1.30 | 17.55 | 0.027 | 0.080 | 1.46 | 16.12 | 0.089 | 0.234 | 1.45 |
| 49 | * | 18.59 | 0.035 | 0.087 | 1.42 | 19.18 | 0.047 | 0.090 | 1.97 | 16.79 | 0.030 | 0.081 | 1.47 |
| 50 | * | 20.80 | 0.039 | 0.083 | 1.56 | 21.43 | 0.030 | 0.056 | 2.24 | 16.99 | 0.061 | 0.175 | 1.75 |
| 51 | 19.05 | 0.035 | 0.055 | 1.40 | 19.00 | 0.063 | 0.170 | 1.31 | 18.37 | 0.076 | 0.163 | 1.87 | |
| 52 | * | 18.39 | 0.041 | 0.071 | 1.72 | 16.96 | 0.042 | 0.086 | 1.97 | 17.77 | 0.099 | 0.200 | 1.97 |
| 53 | * | 17.86 | 0.041 | 0.074 | 1.59 | 17.49 | 0.072 | 0.141 | 1.73 | 16.61 | 0.140 | 0.317 | 1.58 |
| 54 | * | 17.44 | 0.026 | 0.052 | 1.53 | 15.79 | 0.050 | 0.130 | 1.58 | 15.82 | 0.024 | 0.066 | 1.80 |
| 55 | * | 16.38 | 0.039 | 0.062 | 1.70 | 14.61 | 0.024 | 0.068 | 2.08 | 14.97 | 0.110 | 0.200 | 1.86 |
| 56 | 15.76 | 0.020 | 0.031 | 1.36 | 17.05 | 0.068 | 0.117 | 1.34 | 13.99 | 0.034 | 0.080 | 1.52 | |
| 57 | * | 21.07 | 0.021 | 0.033 | 1.39 | 22.25 | 0.061 | 0.131 | 1.92 | 19.70 | 0.118 | 0.213 | 1.50 |
| 58 | * | 20.31 | 0.050 | 0.116 | 1.27 | 21.47 | 0.084 | 0.190 | 1.32 | 16.37 | 0.055 | 0.131 | 1.52 |
| 59 | * | 16.49 | 0.046 | 0.099 | 1.72 | 15.38 | 0.078 | 0.173 | 1.71 | 14.12 | 0.115 | 0.310 | 1.84 |
| 60 | * | 22.24 | 0.043 | 0.090 | 1.64 | 23.25 | 0.049 | 0.132 | 2.34 | 18.44 | 0.124 | 0.224 | 1.83 |
| Avg. | 17.49 | 0.036 | 0.073 | 1.48 | 17.19 | 0.057 | 0.130 | 1.71 | 15.61 | 0.081 | 0.184 | 1.64 | |
| No. | Size | MOPSO | MOEA/D-ACO | pccsAMOPSO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ONVG | TS | ONVG | TS | ONVG | TS | ||||||||
| 61 | 18.04 | 0.061 | 0.150 | 1.41 | 16.51 | 0.060 | 0.156 | 1.72 | 15.54 | 0.118 | 0.216 | 1.47 | |
| 62 | * | 18.42 | 0.056 | 0.086 | 1.42 | 18.79 | 0.095 | 0.259 | 1.46 | 16.62 | 0.118 | 0.260 | 1.59 |
| 63 | * | 19.80 | 0.048 | 0.094 | 1.67 | 17.93 | 0.118 | 0.305 | 2.21 | 16.49 | 0.065 | 0.182 | 1.67 |
| 64 | * | 17.39 | 0.023 | 0.046 | 1.49 | 18.01 | 0.033 | 0.087 | 1.56 | 14.70 | 0.029 | 0.079 | 1.61 |
| 65 | * | 17.15 | 0.066 | 0.118 | 1.58 | 16.63 | 0.093 | 0.186 | 1.84 | 14.80 | 0.125 | 0.232 | 1.68 |
| 66 | 21.60 | 0.036 | 0.087 | 1.37 | 22.49 | 0.037 | 0.072 | 1.93 | 19.87 | 0.044 | 0.102 | 1.96 | |
| 67 | * | 20.53 | 0.023 | 0.039 | 1.42 | 21.35 | 0.130 | 0.377 | 1.66 | 17.88 | 0.173 | 0.404 | 1.54 |
| 68 | * | 17.23 | 0.064 | 0.154 | 1.51 | 16.10 | 0.141 | 0.269 | 2.26 | 14.39 | 0.107 | 0.298 | 1.55 |
| 69 | * | 21.43 | 0.048 | 0.080 | 1.59 | 19.34 | 0.136 | 0.225 | 2.58 | 19.69 | 0.107 | 0.254 | 2.06 |
| 70 | * | 19.09 | 0.053 | 0.100 | 1.63 | 19.85 | 0.078 | 0.172 | 2.37 | 17.32 | 0.062 | 0.114 | 1.81 |
| 71 | 21.41 | 0.020 | 0.041 | 1.44 | 21.22 | 0.121 | 0.292 | 1.57 | 19.13 | 0.078 | 0.136 | 2.14 | |
| 72 | * | 23.23 | 0.055 | 0.132 | 1.42 | 21.64 | 0.065 | 0.195 | 1.94 | 20.67 | 0.069 | 0.131 | 2.12 |
| 73 | * | 18.09 | 0.028 | 0.050 | 1.50 | 17.24 | 0.075 | 0.182 | 2.17 | 16.11 | 0.170 | 0.400 | 1.65 |
| 74 | * | 23.27 | 0.044 | 0.085 | 1.59 | 23.70 | 0.046 | 0.095 | 2.00 | 19.93 | 0.151 | 0.326 | 2.07 |
| 75 | * | 19.21 | 0.028 | 0.049 | 1.65 | 18.97 | 0.135 | 0.248 | 2.47 | 17.13 | 0.140 | 0.251 | 2.43 |
| 76 | 19.57 | 0.055 | 0.111 | 1.57 | 18.54 | 0.042 | 0.087 | 1.78 | 16.72 | 0.138 | 0.246 | 1.50 | |
| 77 | * | 22.06 | 0.028 | 0.051 | 1.64 | 21.79 | 0.054 | 0.106 | 2.56 | 17.95 | 0.051 | 0.129 | 1.77 |
| 78 | * | 22.10 | 0.045 | 0.078 | 1.55 | 20.80 | 0.053 | 0.147 | 1.96 | 19.87 | 0.035 | 0.081 | 1.92 |
| 79 | * | 23.50 | 0.019 | 0.040 | 1.35 | 22.75 | 0.159 | 0.465 | 1.61 | 21.01 | 0.112 | 0.193 | 1.92 |
| 80 | * | 18.64 | 0.019 | 0.043 | 1.49 | 19.26 | 0.033 | 0.098 | 1.81 | 16.95 | 0.151 | 0.314 | 2.26 |
| 81 | 20.83 | 0.061 | 0.093 | 1.60 | 19.48 | 0.034 | 0.094 | 1.76 | 18.61 | 0.105 | 0.295 | 1.60 | |
| 82 | * | 20.19 | 0.040 | 0.097 | 1.66 | 20.78 | 0.085 | 0.211 | 2.63 | 18.12 | 0.080 | 0.171 | 2.34 |
| 83 | * | 21.87 | 0.049 | 0.113 | 1.50 | 22.24 | 0.044 | 0.086 | 1.85 | 18.74 | 0.102 | 0.257 | 1.87 |
| 84 | * | 22.71 | 0.044 | 0.072 | 1.53 | 21.92 | 0.123 | 0.260 | 2.22 | 20.51 | 0.105 | 0.226 | 2.04 |
| 85 | * | 22.78 | 0.032 | 0.073 | 1.38 | 22.67 | 0.092 | 0.227 | 2.20 | 20.03 | 0.065 | 0.138 | 1.54 |
| 86 | 26.75 | 0.040 | 0.092 | 1.40 | 26.98 | 0.119 | 0.303 | 1.38 | 22.77 | 0.086 | 0.211 | 1.66 | |
| 87 | * | 21.40 | 0.065 | 0.147 | 1.50 | 21.74 | 0.098 | 0.219 | 2.20 | 19.36 | 0.160 | 0.434 | 1.79 |
| 88 | * | 21.60 | 0.025 | 0.046 | 1.67 | 20.85 | 0.119 | 0.265 | 2.07 | 17.76 | 0.103 | 0.193 | 1.87 |
| 89 | * | 21.15 | 0.060 | 0.104 | 1.38 | 20.21 | 0.033 | 0.086 | 1.65 | 18.92 | 0.051 | 0.126 | 1.71 |
| 90 | * | 23.54 | 0.041 | 0.099 | 1.70 | 22.74 | 0.161 | 0.424 | 2.25 | 21.61 | 0.111 | 0.286 | 2.22 |
| Avg. | 20.82 | 0.043 | 0.086 | 1.52 | 20.42 | 0.087 | 0.207 | 1.99 | 18.31 | 0.100 | 0.223 | 1.85 | |
| No. | Size | MOPSO | MOEA/D-ACO | pccsAMOPSO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ONVG | TS | ONVG | TS | ONVG | TS | ||||||||
| 91 | 22.75 | 0.044 | 0.100 | 1.52 | 23.92 | 0.028 | 0.067 | 1.57 | 20.82 | 0.117 | 0.237 | 1.71 | |
| 92 | * | 18.64 | 0.091 | 0.213 | 1.44 | 18.88 | 0.044 | 0.127 | 1.61 | 17.44 | 0.124 | 0.219 | 1.64 |
| 93 | * | 19.81 | 0.058 | 0.125 | 1.44 | 20.16 | 0.161 | 0.436 | 1.75 | 17.97 | 0.188 | 0.549 | 1.56 |
| 94 | * | 19.02 | 0.085 | 0.155 | 1.68 | 18.80 | 0.149 | 0.380 | 1.83 | 17.44 | 0.227 | 0.396 | 1.81 |
| 95 | * | 18.64 | 0.025 | 0.043 | 1.67 | 19.60 | 0.088 | 0.228 | 2.27 | 16.64 | 0.161 | 0.296 | 2.03 |
| 96 | 19.24 | 0.024 | 0.043 | 1.60 | 20.35 | 0.055 | 0.116 | 2.50 | 18.31 | 0.032 | 0.090 | 2.01 | |
| 97 | * | 21.94 | 0.078 | 0.142 | 1.39 | 23.15 | 0.039 | 0.102 | 1.85 | 20.54 | 0.103 | 0.218 | 1.67 |
| 98 | * | 21.33 | 0.074 | 0.116 | 1.53 | 20.28 | 0.092 | 0.159 | 2.05 | 20.56 | 0.070 | 0.152 | 1.69 |
| 99 | * | 22.71 | 0.094 | 0.167 | 1.70 | 21.36 | 0.037 | 0.089 | 1.92 | 21.36 | 0.121 | 0.264 | 2.32 |
| 100 | * | 21.79 | 0.079 | 0.124 | 1.78 | 22.28 | 0.114 | 0.325 | 2.55 | 19.48 | 0.023 | 0.068 | 1.71 |
| 101 | 21.58 | 0.054 | 0.087 | 1.67 | 21.54 | 0.058 | 0.145 | 2.11 | 18.75 | 0.056 | 0.133 | 1.91 | |
| 102 | * | 24.34 | 0.051 | 0.111 | 1.49 | 26.85 | 0.159 | 0.436 | 2.36 | 20.58 | 0.133 | 0.385 | 1.65 |
| 103 | * | 22.38 | 0.090 | 0.177 | 1.78 | 22.15 | 0.219 | 0.365 | 2.07 | 20.92 | 0.211 | 0.491 | 2.36 |
| 104 | * | 20.74 | 0.065 | 0.160 | 1.68 | 22.11 | 0.163 | 0.340 | 1.88 | 20.05 | 0.157 | 0.303 | 1.82 |
| 105 | * | 22.51 | 0.038 | 0.065 | 1.87 | 21.06 | 0.142 | 0.322 | 2.13 | 20.51 | 0.131 | 0.288 | 1.92 |
| 106 | 27.13 | 0.087 | 0.172 | 1.65 | 26.58 | 0.103 | 0.205 | 2.59 | 23.34 | 0.141 | 0.249 | 1.73 | |
| 107 | * | 26.67 | 0.066 | 0.120 | 1.66 | 28.61 | 0.052 | 0.091 | 2.69 | 24.31 | 0.207 | 0.421 | 1.67 |
| 108 | * | 22.95 | 0.037 | 0.089 | 1.70 | 24.09 | 0.183 | 0.516 | 1.92 | 19.77 | 0.041 | 0.108 | 2.20 |
| 109 | * | 21.41 | 0.025 | 0.062 | 1.50 | 19.99 | 0.209 | 0.606 | 1.78 | 18.56 | 0.162 | 0.351 | 2.10 |
| 110 | * | 24.86 | 0.095 | 0.210 | 1.72 | 23.40 | 0.190 | 0.520 | 2.46 | 24.05 | 0.121 | 0.244 | 1.61 |
| 111 | 21.15 | 0.094 | 0.230 | 1.84 | 21.81 | 0.110 | 0.310 | 2.65 | 17.86 | 0.097 | 0.254 | 1.82 | |
| 112 | * | 22.02 | 0.062 | 0.101 | 1.91 | 22.34 | 0.083 | 0.244 | 2.34 | 20.89 | 0.222 | 0.513 | 1.88 |
| 113 | * | 28.67 | 0.078 | 0.158 | 1.41 | 30.25 | 0.088 | 0.145 | 1.88 | 25.61 | 0.114 | 0.316 | 1.43 |
| 114 | * | 20.17 | 0.082 | 0.170 | 1.40 | 21.50 | 0.145 | 0.421 | 1.52 | 17.83 | 0.203 | 0.515 | 1.39 |
| 115 | * | 24.16 | 0.055 | 0.097 | 1.77 | 25.85 | 0.097 | 0.172 | 2.17 | 20.58 | 0.164 | 0.476 | 2.00 |
| 116 | 26.08 | 0.062 | 0.148 | 1.56 | 27.06 | 0.043 | 0.115 | 2.34 | 24.23 | 0.128 | 0.348 | 1.95 | |
| 117 | * | 23.03 | 0.085 | 0.185 | 1.72 | 23.67 | 0.082 | 0.164 | 2.33 | 22.10 | 0.056 | 0.112 | 1.69 |
| 118 | * | 23.17 | 0.075 | 0.122 | 1.40 | 23.46 | 0.218 | 0.545 | 1.72 | 20.24 | 0.174 | 0.422 | 1.84 |
| 119 | * | 27.55 | 0.032 | 0.060 | 1.51 | 29.95 | 0.131 | 0.362 | 1.99 | 26.51 | 0.112 | 0.321 | 1.86 |
| 120 | * | 24.76 | 0.089 | 0.172 | 1.84 | 25.14 | 0.170 | 0.460 | 2.84 | 21.97 | 0.095 | 0.166 | 1.97 |
| Avg. | 22.71 | 0.066 | 0.131 | 1.63 | 23.21 | 0.115 | 0.284 | 2.12 | 20.64 | 0.130 | 0.297 | 1.83 | |
| No. | Size | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 1.00 | 0.00 | 0.88 | 0.10 | 0.93 | 0.01 | |
| 2 | * | 0.91 | 0.09 | 0.95 | 0.04 | 0.52 | 0.43 |
| 3 | * | 0.86 | 0.12 | 0.98 | 0.00 | 0.41 | 0.59 |
| 4 | * | 0.93 | 0.05 | 0.88 | 0.10 | 0.44 | 0.55 |
| 5 | * | 0.87 | 0.10 | 0.87 | 0.11 | 0.37 | 0.57 |
| 6 | 0.87 | 0.11 | 1.00 | 0.00 | 0.68 | 0.26 | |
| 7 | * | 0.99 | 0.00 | 0.94 | 0.04 | 0.86 | 0.11 |
| 8 | * | 0.93 | 0.04 | 0.87 | 0.11 | 0.62 | 0.36 |
| 9 | * | 0.85 | 0.14 | 1.00 | 0.00 | 0.62 | 0.33 |
| 10 | * | 0.87 | 0.09 | 0.96 | 0.01 | 0.42 | 0.54 |
| 11 | 0.88 | 0.06 | 0.88 | 0.10 | 0.39 | 0.53 | |
| 12 | * | 0.85 | 0.13 | 0.88 | 0.09 | 0.71 | 0.21 |
| 13 | * | 0.93 | 0.03 | 1.00 | 0.00 | 0.39 | 0.58 |
| 14 | * | 0.97 | 0.02 | 0.89 | 0.07 | 0.41 | 0.57 |
| 15 | * | 0.98 | 0.01 | 0.95 | 0.02 | 0.40 | 0.59 |
| 16 | 0.97 | 0.00 | 0.93 | 0.07 | 0.59 | 0.36 | |
| 17 | * | 1.00 | 0.00 | 1.00 | 0.00 | 0.89 | 0.05 |
| 18 | * | 0.91 | 0.09 | 0.91 | 0.06 | 0.56 | 0.42 |
| 19 | * | 0.87 | 0.09 | 0.85 | 0.15 | 0.43 | 0.50 |
| 20 | * | 1.00 | 0.00 | 0.89 | 0.06 | 1.00 | 0.00 |
| 21 | 0.97 | 0.01 | 0.89 | 0.08 | 0.60 | 0.38 | |
| 22 | * | 0.86 | 0.12 | 1.00 | 0.00 | 0.49 | 0.46 |
| 23 | * | 0.90 | 0.06 | 0.84 | 0.15 | 0.55 | 0.38 |
| 24 | * | 0.91 | 0.06 | 0.99 | 0.00 | 0.61 | 0.33 |
| 25 | * | 0.91 | 0.02 | 1.00 | 0.00 | 0.41 | 0.51 |
| 26 | 0.86 | 0.11 | 0.91 | 0.04 | 0.97 | 0.00 | |
| 27 | * | 0.82 | 0.18 | 0.98 | 0.00 | 0.69 | 0.24 |
| 28 | * | 0.94 | 0.04 | 0.98 | 0.00 | 0.60 | 0.32 |
| 29 | * | 0.81 | 0.15 | 0.85 | 0.13 | 0.54 | 0.38 |
| 30 | * | 0.88 | 0.11 | 0.95 | 0.00 | 0.42 | 0.56 |
| Avg. | 0.91 | 0.07 | 0.93 | 0.05 | 0.58 | 0.37 |
| No. | Size | ||||||
|---|---|---|---|---|---|---|---|
| 31 | 0.87 | 0.12 | 0.92 | 0.03 | 0.70 | 0.23 | |
| 32 | * | 0.81 | 0.14 | 1.00 | 0.00 | 0.65 | 0.34 |
| 33 | * | 0.82 | 0.15 | 1.00 | 0.00 | 0.53 | 0.46 |
| 34 | * | 0.85 | 0.10 | 0.94 | 0.04 | 0.76 | 0.21 |
| 35 | * | 0.99 | 0.00 | 1.00 | 0.00 | 0.78 | 0.16 |
| 36 | 0.98 | 0.00 | 0.89 | 0.10 | 0.78 | 0.21 | |
| 37 | * | 0.90 | 0.08 | 1.00 | 0.00 | 0.93 | 0.00 |
| 38 | * | 0.99 | 0.00 | 0.84 | 0.11 | 0.44 | 0.49 |
| 39 | * | 0.96 | 0.00 | 0.96 | 0.01 | 0.78 | 0.15 |
| 40 | * | 0.98 | 0.00 | 0.92 | 0.08 | 0.44 | 0.48 |
| 41 | 0.90 | 0.09 | 1.00 | 0.00 | 0.39 | 0.58 | |
| 42 | * | 0.82 | 0.13 | 0.86 | 0.09 | 0.78 | 0.16 |
| 43 | * | 0.82 | 0.13 | 0.87 | 0.09 | 0.38 | 0.54 |
| 44 | * | 0.92 | 0.06 | 0.92 | 0.03 | 0.57 | 0.43 |
| 45 | * | 0.98 | 0.01 | 0.87 | 0.09 | 0.65 | 0.31 |
| 46 | 1.00 | 0.00 | 0.86 | 0.11 | 0.81 | 0.15 | |
| 47 | * | 0.99 | 0.00 | 0.91 | 0.04 | 0.41 | 0.54 |
| 48 | * | 0.84 | 0.15 | 0.90 | 0.05 | 0.42 | 0.52 |
| 49 | * | 0.98 | 0.01 | 0.95 | 0.01 | 0.60 | 0.32 |
| 50 | * | 0.88 | 0.07 | 0.90 | 0.07 | 0.73 | 0.21 |
| 51 | 0.93 | 0.04 | 0.96 | 0.00 | 0.90 | 0.05 | |
| 52 | * | 0.88 | 0.10 | 1.00 | 0.00 | 0.92 | 0.05 |
| 53 | * | 0.95 | 0.00 | 1.00 | 0.00 | 0.52 | 0.42 |
| 54 | * | 1.00 | 0.00 | 0.88 | 0.12 | 0.97 | 0.03 |
| 55 | * | 0.91 | 0.02 | 0.95 | 0.04 | 0.94 | 0.02 |
| 56 | 1.00 | 0.00 | 0.93 | 0.04 | 0.47 | 0.46 | |
| 57 | * | 0.83 | 0.13 | 0.98 | 0.00 | 0.69 | 0.26 |
| 58 | * | 0.88 | 0.11 | 0.96 | 0.02 | 0.43 | 0.50 |
| 59 | * | 1.00 | 0.00 | 0.99 | 0.01 | 0.61 | 0.35 |
| 60 | * | 0.98 | 0.01 | 1.00 | 0.00 | 0.60 | 0.39 |
| Avg. | 0.92 | 0.05 | 0.94 | 0.04 | 0.65 | 0.30 |
| No. | Size | ||||||
|---|---|---|---|---|---|---|---|
| 61 | 0.83 | 0.12 | 1.00 | 0.00 | 0.55 | 0.37 | |
| 62 | * | 0.97 | 0.00 | 1.00 | 0.00 | 0.91 | 0.08 |
| 63 | * | 0.92 | 0.04 | 1.00 | 0.00 | 0.94 | 0.02 |
| 64 | * | 0.97 | 0.02 | 0.95 | 0.01 | 0.37 | 0.61 |
| 65 | * | 1.00 | 0.00 | 0.88 | 0.08 | 0.81 | 0.13 |
| 66 | 0.83 | 0.14 | 0.93 | 0.04 | 0.74 | 0.19 | |
| 67 | * | 0.88 | 0.11 | 1.00 | 0.00 | 0.37 | 0.61 |
| 68 | * | 0.95 | 0.04 | 1.00 | 0.00 | 0.81 | 0.18 |
| 69 | * | 0.86 | 0.12 | 0.88 | 0.07 | 0.57 | 0.42 |
| 70 | * | 0.94 | 0.01 | 1.00 | 0.00 | 0.55 | 0.38 |
| 71 | 0.84 | 0.16 | 0.92 | 0.05 | 0.65 | 0.29 | |
| 72 | * | 0.90 | 0.08 | 0.93 | 0.05 | 0.39 | 0.61 |
| 73 | * | 0.84 | 0.11 | 0.90 | 0.10 | 0.47 | 0.49 |
| 74 | * | 1.00 | 0.00 | 0.92 | 0.03 | 0.96 | 0.00 |
| 75 | * | 0.96 | 0.01 | 0.86 | 0.12 | 0.74 | 0.20 |
| 76 | 0.99 | 0.00 | 0.95 | 0.00 | 0.41 | 0.56 | |
| 77 | * | 1.00 | 0.00 | 0.98 | 0.00 | 0.61 | 0.31 |
| 78 | * | 0.96 | 0.00 | 1.00 | 0.00 | 0.57 | 0.43 |
| 79 | * | 0.82 | 0.16 | 0.93 | 0.06 | 0.79 | 0.14 |
| 80 | * | 0.91 | 0.07 | 0.96 | 0.02 | 1.00 | 0.00 |
| 81 | 0.81 | 0.18 | 0.85 | 0.12 | 0.93 | 0.00 | |
| 82 | * | 0.87 | 0.12 | 1.00 | 0.00 | 0.39 | 0.52 |
| 83 | * | 0.83 | 0.14 | 0.88 | 0.09 | 0.62 | 0.37 |
| 84 | * | 0.91 | 0.08 | 0.93 | 0.02 | 0.73 | 0.22 |
| 85 | * | 0.82 | 0.16 | 0.96 | 0.01 | 0.73 | 0.22 |
| 86 | 0.89 | 0.10 | 0.89 | 0.05 | 0.78 | 0.15 | |
| 87 | * | 0.91 | 0.05 | 0.90 | 0.06 | 0.40 | 0.52 |
| 88 | * | 0.86 | 0.10 | 0.92 | 0.03 | 0.44 | 0.53 |
| 89 | * | 0.87 | 0.08 | 1.00 | 0.00 | 0.79 | 0.17 |
| 90 | * | 0.86 | 0.08 | 0.96 | 0.01 | 0.83 | 0.15 |
| Avg. | 0.90 | 0.08 | 0.94 | 0.03 | 0.66 | 0.30 |
| No. | Size | ||||||
|---|---|---|---|---|---|---|---|
| 91 | 0.85 | 0.11 | 1.00 | 0.00 | 0.68 | 0.29 | |
| 92 | * | 0.96 | 0.01 | 0.93 | 0.03 | 0.85 | 0.14 |
| 93 | * | 0.81 | 0.17 | 1.00 | 0.00 | 0.65 | 0.35 |
| 94 | * | 0.84 | 0.15 | 1.00 | 0.00 | 0.89 | 0.11 |
| 95 | * | 0.96 | 0.00 | 0.93 | 0.03 | 0.73 | 0.21 |
| 96 | 0.88 | 0.11 | 1.00 | 0.00 | 0.72 | 0.23 | |
| 97 | * | 0.96 | 0.00 | 0.87 | 0.12 | 0.89 | 0.04 |
| 98 | * | 0.82 | 0.15 | 0.94 | 0.02 | 0.41 | 0.51 |
| 99 | * | 0.81 | 0.15 | 1.00 | 0.00 | 0.67 | 0.29 |
| 100 | * | 0.85 | 0.11 | 0.89 | 0.06 | 0.84 | 0.13 |
| 101 | 0.86 | 0.13 | 0.92 | 0.07 | 0.96 | 0.00 | |
| 102 | * | 0.98 | 0.00 | 1.00 | 0.00 | 0.55 | 0.42 |
| 103 | * | 1.00 | 0.00 | 1.00 | 0.00 | 0.99 | 0.00 |
| 104 | * | 0.93 | 0.05 | 0.92 | 0.04 | 0.86 | 0.06 |
| 105 | * | 0.98 | 0.01 | 0.86 | 0.09 | 0.91 | 0.02 |
| 106 | 0.94 | 0.03 | 1.00 | 0.00 | 0.39 | 0.56 | |
| 107 | * | 0.96 | 0.00 | 1.00 | 0.00 | 0.98 | 0.00 |
| 108 | * | 0.97 | 0.00 | 0.87 | 0.12 | 0.88 | 0.07 |
| 109 | * | 0.95 | 0.02 | 1.00 | 0.00 | 0.39 | 0.59 |
| 110 | * | 0.86 | 0.12 | 0.95 | 0.02 | 0.80 | 0.12 |
| 111 | 0.91 | 0.06 | 1.00 | 0.00 | 0.49 | 0.49 | |
| 112 | * | 0.82 | 0.15 | 0.85 | 0.13 | 0.40 | 0.54 |
| 113 | * | 0.92 | 0.02 | 0.87 | 0.13 | 0.98 | 0.00 |
| 114 | * | 0.97 | 0.00 | 0.99 | 0.00 | 0.64 | 0.28 |
| 115 | * | 0.84 | 0.12 | 1.00 | 0.00 | 0.92 | 0.06 |
| 116 | 0.84 | 0.11 | 0.92 | 0.04 | 0.42 | 0.55 | |
| 117 | * | 0.86 | 0.12 | 0.97 | 0.00 | 0.90 | 0.07 |
| 118 | * | 0.81 | 0.15 | 0.89 | 0.11 | 0.45 | 0.48 |
| 119 | * | 0.87 | 0.13 | 1.00 | 0.00 | 0.53 | 0.42 |
| 120 | * | 0.81 | 0.13 | 0.90 | 0.06 | 0.56 | 0.38 |
| Avg. | 0.89 | 0.08 | 0.95 | 0.04 | 0.71 | 0.25 |
| n | ONVG | TS | ||
|---|---|---|---|---|
| 50 | ||||
| 100 | ||||
| 150 | ||||
| 200 |
| n | ONVG | TS | ||
|---|---|---|---|---|
| 50 | ||||
| 100 | ||||
| 150 | ||||
| 200 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R. Environment-Aware Production Scheduling for Paint Shops in Automobile Manufacturing: A Multi-Objective Optimization Approach. Int. J. Environ. Res. Public Health 2018, 15, 32. https://doi.org/10.3390/ijerph15010032
Zhang R. Environment-Aware Production Scheduling for Paint Shops in Automobile Manufacturing: A Multi-Objective Optimization Approach. International Journal of Environmental Research and Public Health. 2018; 15(1):32. https://doi.org/10.3390/ijerph15010032
Chicago/Turabian StyleZhang, Rui. 2018. "Environment-Aware Production Scheduling for Paint Shops in Automobile Manufacturing: A Multi-Objective Optimization Approach" International Journal of Environmental Research and Public Health 15, no. 1: 32. https://doi.org/10.3390/ijerph15010032
APA StyleZhang, R. (2018). Environment-Aware Production Scheduling for Paint Shops in Automobile Manufacturing: A Multi-Objective Optimization Approach. International Journal of Environmental Research and Public Health, 15(1), 32. https://doi.org/10.3390/ijerph15010032