Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
2.2. Logistic Regression
2.3. Decision Tree
2.4. Random Forest
2.5. Artificial Neural Network
2.6. Measures
2.6.1. Explanatory Variables
2.6.2. Outcome Variables
2.7. Data Pre-Processing
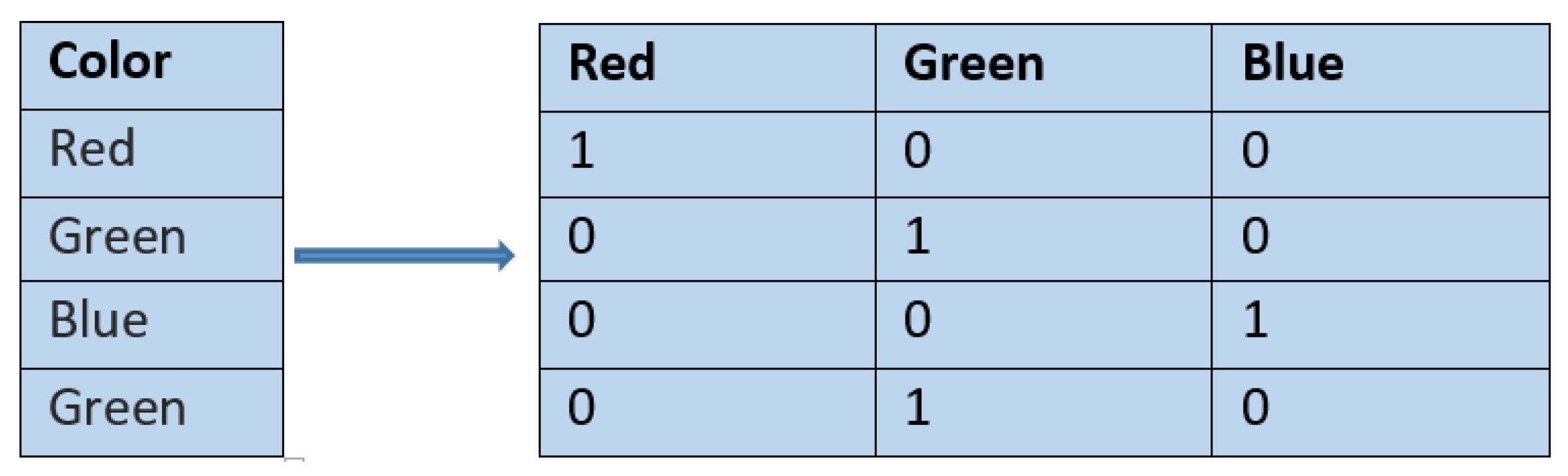
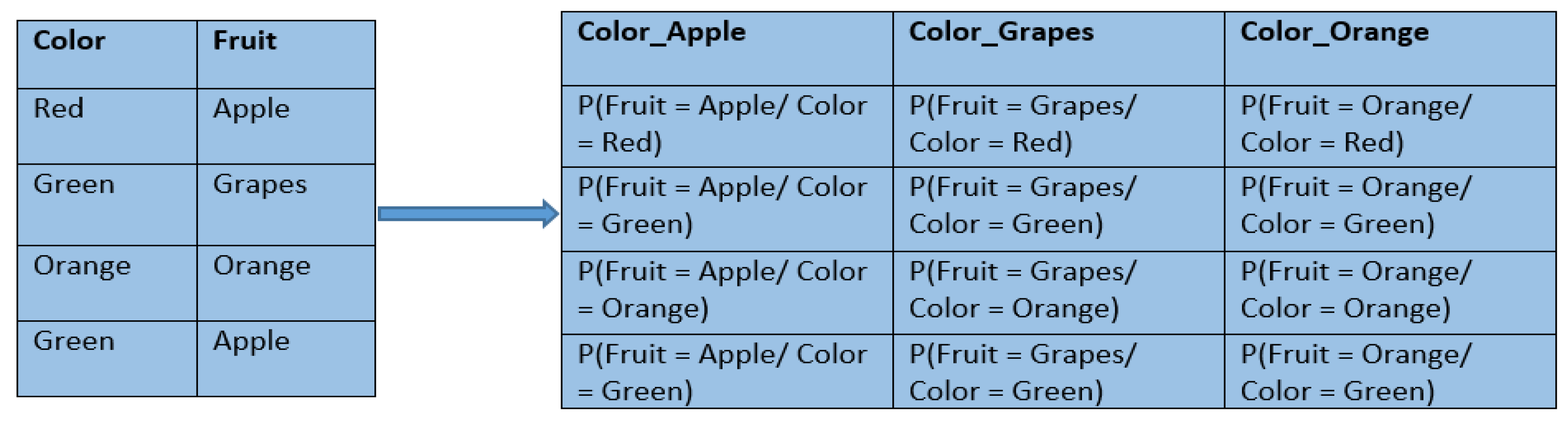
2.7.1. Categorical Encoding Using Target Statistics
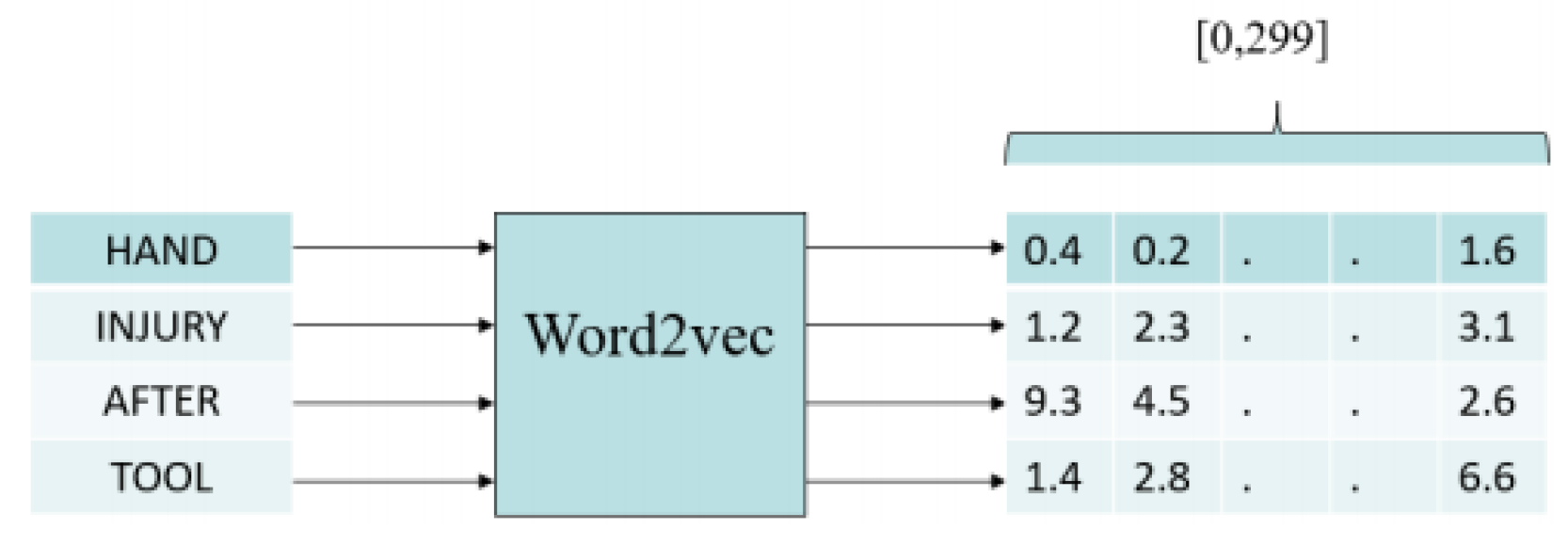
2.7.2. Word Embedding
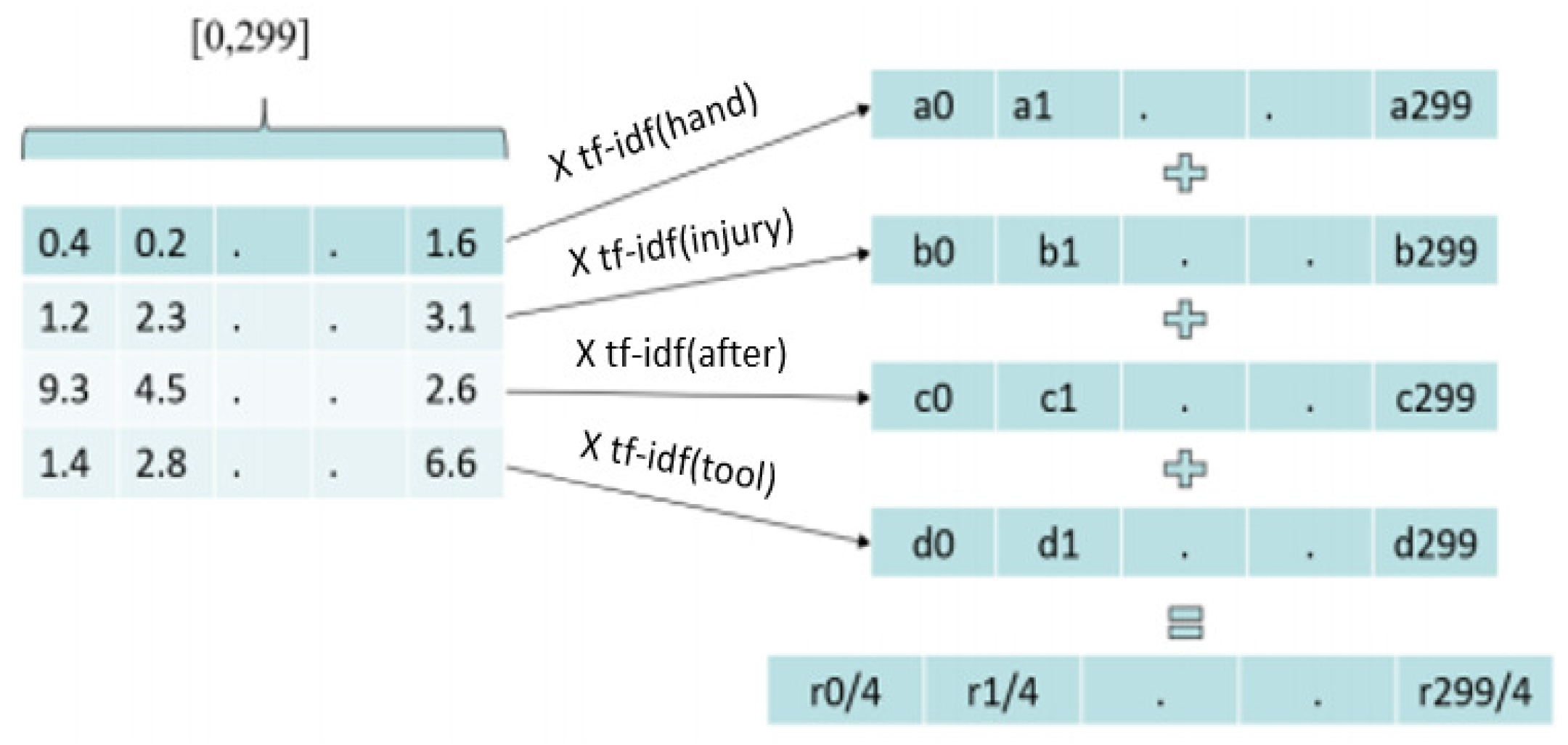
2.8. Representation of Narratives
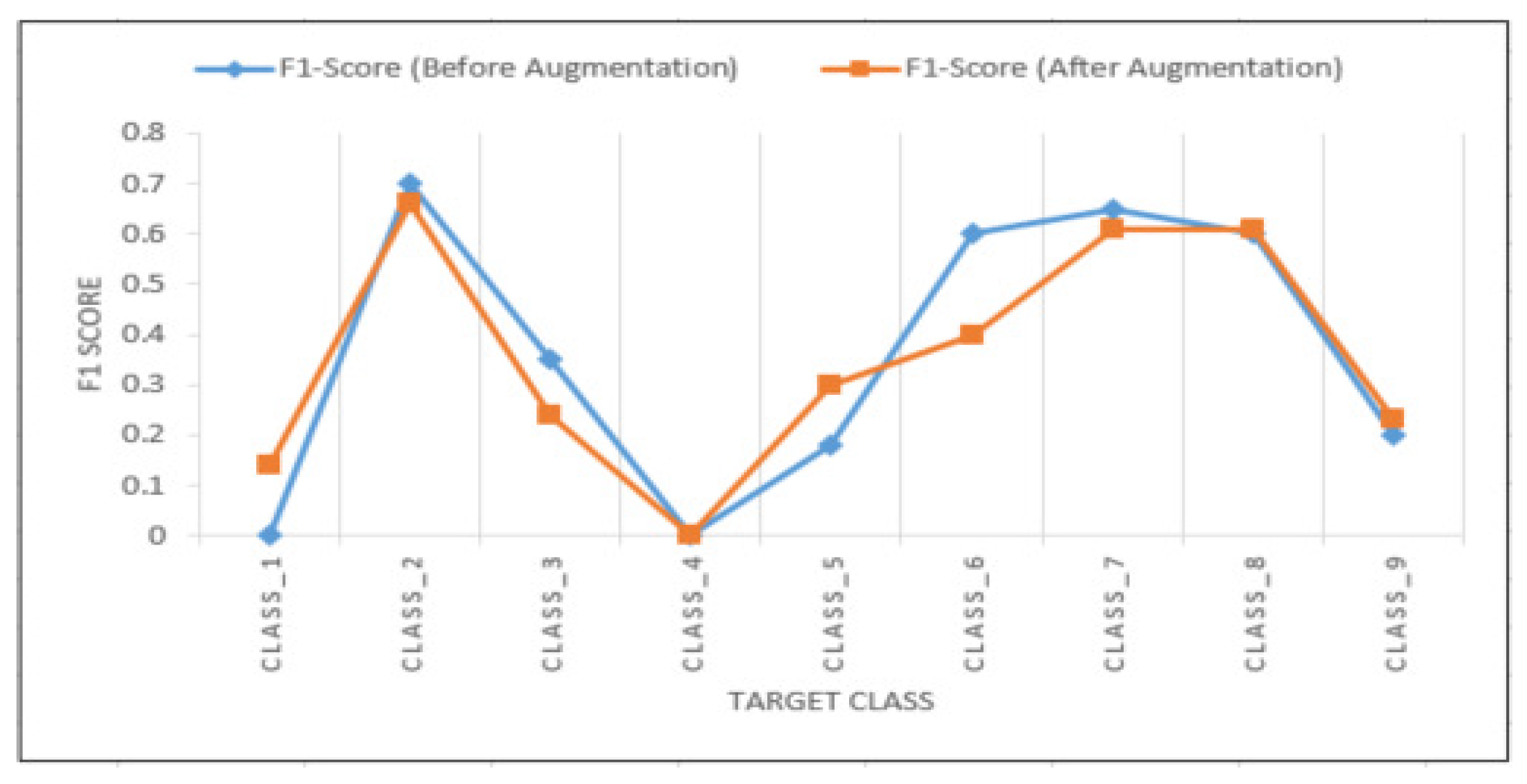
2.9. Data Augmentation
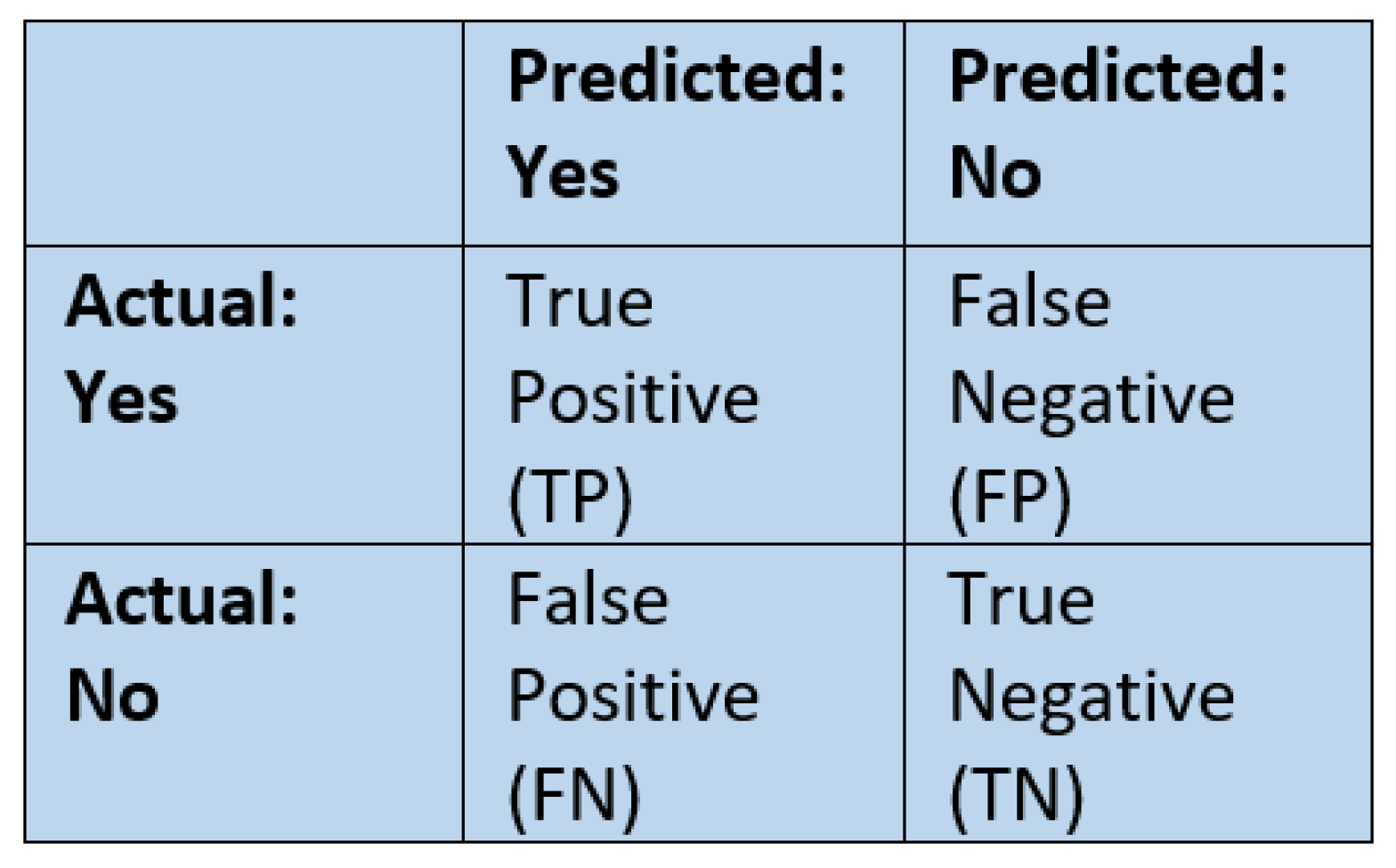
2.10. Performance Metrics
2.10.1. Accuracy
2.10.2. F1 Score
2.11. Mean Squared Error (MSE)
2.12. Root Mean Square Error (RMSE)
2.13. Predicting Outcome of the Injury
2.13.1. Fixed Field Entries
2.13.2. Narratives
2.14. Predicting Days Away from Work
2.14.1. Fixed Field Entries
2.14.2. Narratives
3. Results
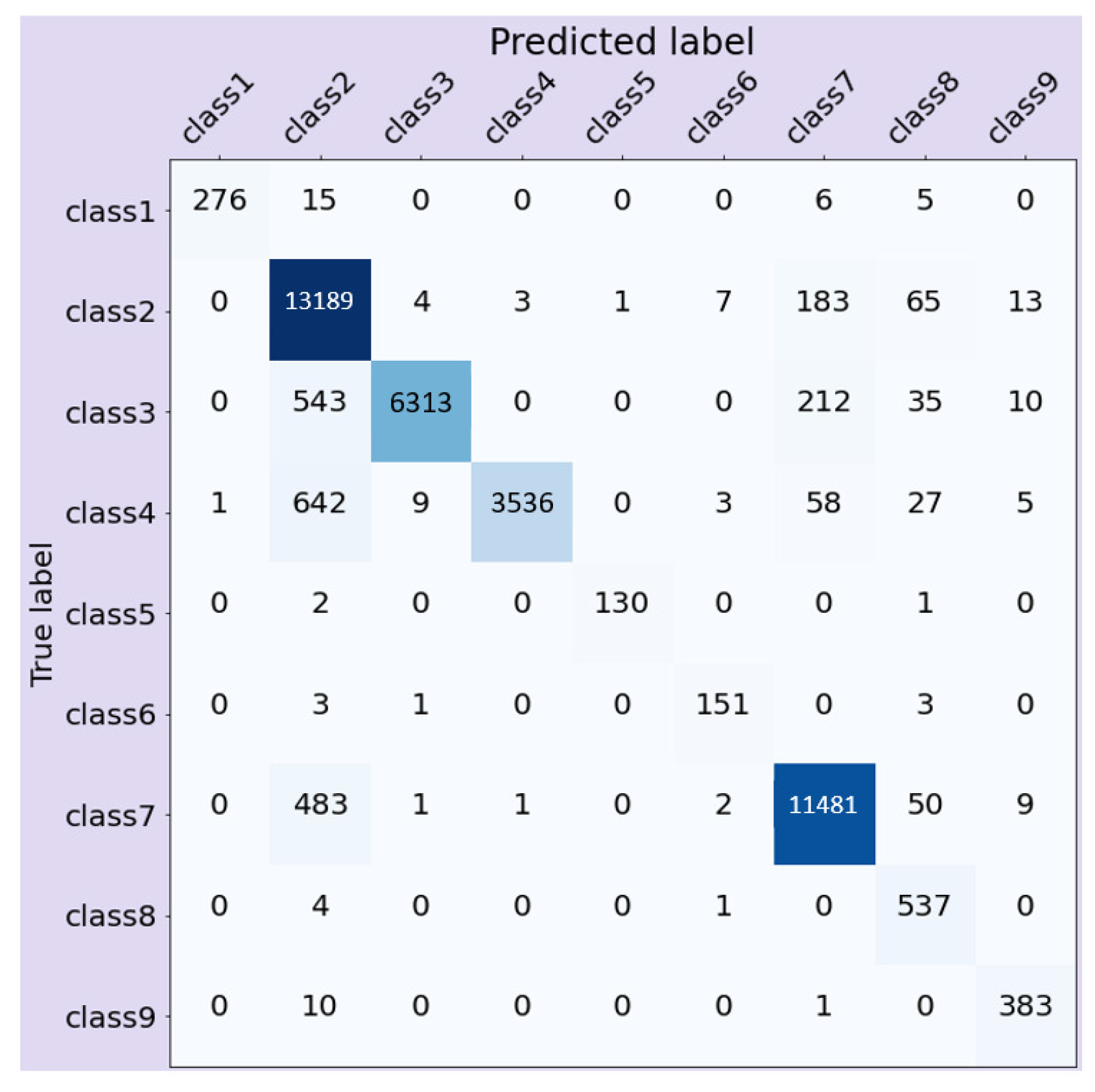
3.1. Injury Outcome
3.2. Days Away from Work
3.3. Feature Importance
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DAFW | Days away from work |
| ANN | Artificial neural network |
| MSHA | Mine safety and health administration |
| GAN | Generative adversarial network |
| NLP | Natural language processing |
| TF-IDF | Term frequency and inverse document frequency |
| MSE | Mean squared error |
| RMSE | Root mean squared error |
| CBOW | Continuous bag of words |
References
- Nowrouzi-Kia, B.; Sharma, B.; Dignard, C.; Kerekes, Z.; Dumond, J.; Li, A.; Larivière, M. Systematic review: Lost-time injuries in the US mining industry. Occup. Med. 2017, 67, 442–447. [Google Scholar] [CrossRef] [Green Version]
- Cdc.gov. NIOSH Mining. 2020. Available online: https://www.cdc.gov/niosh/mining (accessed on 12 July 2020).
- Stemn, E. Analysis of Injuries in the Ghanaian Mining Industry and Priority Areas for Research. Saf. Health Work 2019, 10, 151–165. [Google Scholar] [CrossRef]
- Margolis, K. Underground coal mining injury: A look at how age and experience relate to days lost from work following an injury. Saf. Sci. 2010, 48, 417–421. [Google Scholar] [CrossRef]
- Onder, S. Evaluation of occupational injuries with lost days among opencast coal mine workers through logistic regression models. Saf. Sci. 2013, 59, 86–92. [Google Scholar] [CrossRef]
- Bell, J.; Gardner, L.; Landsittel, D. Slip and fall-related injuries in relation to environmental cold and work location in above-ground coal mining operations. Am. J. Ind. Med. 2000, 38, 40–48. [Google Scholar] [CrossRef]
- Pollard, J.; Heberger, J.; Dempsey, P.G. Maintenance and repair injuries in US mining. J. Qual. Maint. Eng. 2014, 20, 20–31. [Google Scholar] [CrossRef]
- Coleman, P.; Kerkering, J. Measuring mining safety with injury statistics: Lost workdays as indicators of risk. J. Saf. Res. 2007, 38, 523–533. [Google Scholar] [CrossRef]
- Nowrouzi, B.; Rojkova, M.; Casole, J.; Nowrouzi-Kia, B. A bibliometric review of the most cited literature related to mining injuries. Int. J. Min. Reclam. Environ. 2016, 31, 276–285. [Google Scholar] [CrossRef]
- Sarkar, S.; Vinay, S.; Raj, R.; Maiti, J.; Mitra, P. Application of optimized machine learning techniques for prediction of occupational accidents. Comput. Oper. Res. 2019, 106, 210–224. [Google Scholar] [CrossRef]
- Matías, J.; Rivas, T.; Martín, J.; Taboada, J. A machine learning methodology for the analysis of workplace accidents. Int. J. Comput. Math. 2008, 85, 559–578. [Google Scholar] [CrossRef]
- Tixier, A.; Hallowell, M.; Rajagopalan, B.; Bowman, D. Application of machine learning to construction injury prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef] [Green Version]
- Davoudi Kakhki, F.; Freeman, S.; Mosher, G. Evaluating machine learning performance in predicting injury severity in agribusiness industries. Saf. Sci. 2019, 117, 257–262. [Google Scholar] [CrossRef]
- Davoudi Kakhki, F.; Freeman, S.; Mosher, G. Use of logistic regression to identify factors influencing the post-incident state of occupational injuries in agribusiness operations. Appl. Sci. 2019, 9, 3449. [Google Scholar] [CrossRef] [Green Version]
- Rivas, T.; Paz, M.; Martín, J.; Matías, J.; García, J.; Taboada, J. Explaining and predicting workplace accidents using data-mining techniques. Reliab. Eng. Syst. Saf. 2011, 96, 739–747. [Google Scholar] [CrossRef]
- Marucci-Wellman, H.; Corns, H.; Lehto, M. Classifying injury narratives of large administrative databases for surveillance—A practical approach combining machine learning ensembles and human review. Accid. Anal. Prev. 2017, 98, 359–371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davoudi Kakhki, F.; Freeman, S.; Mosher, G. Segmentation of severe occupational incidents in agribusiness industries using latent class clustering. Appl. Sci. 2019, 9, 3641. [Google Scholar] [CrossRef] [Green Version]
- Davoudi Kakhki, F.; Freeman, S.; Mosher, G. Use of neural networks to identify safety prevention priorities in agro-manufacturing operations within commercial grain elevators. Appl. Sci. 2019, 9, 4690. [Google Scholar] [CrossRef] [Green Version]
- Davoudi Kakhki, F.; Freeman, S.; Mosher, G. Applied machine learning in agro-manufacturing occupational Incidents. Procedia Manuf. 2020, 48, 24–30. [Google Scholar] [CrossRef]
- Agarwal, B.; Agarwal, H.; Talib, P. Application of artificial intelligence for successful strategy implementation in indias banking sector. Int. J. Adv. Res. 2019, 7, 157–166. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Yang, S.; Huang, Z.; Huang, T. The Application of Artificial Intelligence in Electronic Commerce. J. Phys. Conf. Ser. 2019, 1302, 032030. [Google Scholar] [CrossRef]
- Riihimaa, P. Impact of machine learning and feature selection on type 2 diabetes risk prediction. J. Med. Artif. Intell. 2020, 3, 10. [Google Scholar] [CrossRef]
- He, X.; Chen, W.; Nie, B.; Zhang, M. Classification technique for danger classes of coal and gas outburst in deep coal mines. Saf. Sci. 2010, 48, 173–178. [Google Scholar] [CrossRef]
- Sanmiquel, L.; Rossell, J.; Vintró, C. Study of Spanish mining accidents using data mining techniques. Saf. Sci. 2015, 75, 49–55. [Google Scholar] [CrossRef]
- Wilson, J.; Lorenz, K. Modeling Binary Correlated Responses Using SAS 2015, SPSS and R; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Peng, C.; Lee, K.; Ingersoll, G. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Bhattacharjee, P.; Dey, V.; Mandal, U. Risk assessment by failure mode and effects analysis (FMEA) using an interval number based logistic regression model. Saf. Sci. 2020, 132, 104967. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M. Data Mining; Elsevier: Haryana, India, 2012. [Google Scholar]
- Patel, B. Efficient Classification of Data Using Decision Tree. Bonfring Int. J. Data Min. 2012, 2, 6–12. [Google Scholar] [CrossRef]
- Patel, N.; Upadhyay, S. Study of Various Decision Tree Pruning Methods with their Empirical Comparison in WEKA. Int. J. Comput. Appl. 2012, 60, 20–25. [Google Scholar] [CrossRef]
- Prajwala, T.R. A Comparative Study on Decision Tree and Random Forest Using R Tool. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 196–199. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Azar, E.; Woon, W.; Kontokosta, C. Evaluation of tree-based ensemble learning algorithms for building energy performance estimation. J. Build. Perform. Simul. 2017, 11, 322–332. [Google Scholar] [CrossRef]
- Kotsiantis, S. Bagging and boosting variants for handling classifications problems: A survey. Knowl. Eng. Rev. 2013, 29, 78–100. [Google Scholar] [CrossRef]
- Chang, L.; Wang, H. Analysis of traffic injury severity: An application of non-parametric classification tree techniques. Accid. Anal. Prev. 2006, 38, 1019–1027. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.; Leu, S.; Cheng, Y.; Wu, T.; Lin, C. Applying data mining techniques to explore factors contributing to occupational injuries in Taiwan’s construction industry. Accid. Anal. Prev. 2012, 48, 214–222. [Google Scholar] [CrossRef] [PubMed]
- Rosenblatt, F. The Perceptron: A Probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lek, S.; Park, Y. Artificial Neural Networks. In Encyclopedia of Ecology; Elsevier: Amsterdam, The Netherlands, 2008; pp. 237–245. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, S.; Teh, Y. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- White, H. Learning in Artificial Neural Networks: A Statistical Perspective. Neural Comput. 1989, 1, 425–464. [Google Scholar] [CrossRef]
- Tu, J. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Zhu, C.; Gao, D. Influence of Data Preprocessing. J. Comput. Sci. Eng. 2016, 10, 51–57. [Google Scholar] [CrossRef]
- Potdar, K.; Pardawala, T.S.; Pai, C.D. A Comparative Study of Categorical Variable Encoding Techniques for Neural Network Classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Micci-Barreca, D. A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems. ACM SIGKDD Explor. Newsl. 2001, 3, 27. [Google Scholar] [CrossRef]
- Khattak, F.; Jeblee, S.; Pou-Prom, C.; Abdalla, M.; Meaney, C.; Rudzicz, F. A survey of word embeddings for clinical text. J. Biomed. Inform. X 2019, 4, 100057. [Google Scholar] [CrossRef]
- Kilimci, Z.; Akyokus, S. Deep Learning-and Word Embedding-Based Heterogeneous Classifier Ensembles for Text Classification. Complexity 2018, 2018, 7130146. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Qi, L.; Li, R.; Wong, J.; Tavanapong, W.; Peterson, D.A.M. Social Media in State Politics: Mining Policy Agendas Topics. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Shields, M.; Teferra, K.; Hapij, A.; Daddazio, R. Refined Stratified Sampling for efficient Monte Carlo based uncertainty quantification. Reliab. Eng. Syst. Saf. 2015, 142, 310–325. [Google Scholar] [CrossRef] [Green Version]
- Groves, W.; Kecojevic, V.; Komljenovic, D. Analysis of fatalities and injuries involving mining equipment. J. Saf. Res. 2007, 38, 461–470. [Google Scholar] [CrossRef]
- Bajpayee, T.; Rehak, T.; Mowrey, G.; Ingram, D. Blasting injuries in surface mining with emphasis on flyrock and blast area security. J. Saf. Res. 2004, 35, 47–57. [Google Scholar] [CrossRef]
- Donoghue, A. Occupational health hazards in mining: An overview. Occup. Med. 2004, 54, 283–289. [Google Scholar] [CrossRef] [Green Version]
- Sanmiquel, L.; Bascompta, M.; Rossell, J.M.; Anticoi, H.F.; Guash, E. Analysis of Occupational Accidents in Underground and Surface Mining in Spain Using Data-Mining Techniques. Int. J. Environ. Res. Public Health 2018, 15, 462. [Google Scholar] [CrossRef] [Green Version]
- Wilson, K.S.; Kootbodien, T.; Naicker, N. Excess Mortality Due to External Causes in Women in the South African Mining Industry: 2013–2015. Int. J. Environ. Res. Public Health 2020, 17, 1875. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.; Kim, Y.; Jung, K. Text Classification via Sentence-level Graph Convolutional Networks. KIISE Trans. Comput. Pract. 2019, 25, 397–401. [Google Scholar] [CrossRef]
- Kim, G.; Jang, J.; Lee, J.; Kim, K.; Yeo, W.; Kim, J. Text Classification Using Parallel Word-level and Character-level Embeddings in Convolutional Neural Networks. Asia Pac. J. Inf. Syst. 2019, 29, 771–788. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Class | Count before Augmentation | Count after Augmentation |
|---|---|---|
| Class1: All Other Cases (Including 1st Aid) | 676 | 7564 |
| Class2: Days Away From Work Only | 31,653 | 31,653 |
| Class3: Days Restricted Activity Only | 16,633 | 16,633 |
| Class4: Days Away From Work & Restricted Activity | 10,025 | 10,025 |
| Class5: Fatality | 336 | 3842 |
| Class6: Injuries due to Natural Causes | 444 | 2785 |
| Class7: No Days Away From Work, No Restricted Activity | 27,627 | 27,627 |
| Class8: Occupational Illness not DEG 1–6 | 1346 | 9676 |
| Class9: Permanent Total or Permanent Partial Disability | 895 | 12,796 |
| Model | F1 Score | Accuracy |
|---|---|---|
| Logistic regression | 0.64 | 67% |
| Decision Tree | 0.58 | 58% |
| Random Forest | 0.66 | 66% |
| Artificial Neural Network | 0.67 | 78% |
| Model | F1 Score | Accuracy |
|---|---|---|
| Random Forest | 0.93 | 93% |
| Artificial Neural Network | 0.60 | 92% |
| Model | Input | MSE | RMSE |
|---|---|---|---|
| Random forest | Fixed Field Entries | 14.65 | 3.82 |
| Injury Narratives | 1502.61 | 38.76 | |
| Artificial neural network | Fixed Field Entries | 0.38 | 0.62 |
| Injury Narratives | 5944.74 | 77.10 |
| Feature | Description |
|---|---|
| Nature of Injury | Identifies the injury in terms of its principal physical characteristics. |
| Injured body part | Identifies the body part affected by an injury. |
| Occupation | Occupation of the accident victim’s regular job title. |
| Coal or Metal | Identifies if the accident occurred at a Coal or Metal/Non-Metal mine. |
| Job Experience | Experience in the job title of the person affected calculated in the decimal year. |
| Hours | Time difference between accident time and shift begin time in hours. |
| Injury Source | Identifies the object, substances, exposure or bodily motion which directly produced or inflicted the injury. |
| Classification | Identifies the circumstances which contributed most directly to the resulting accident. |
| Activity | Specific activity the accident victim was performing at the time of the incident. |
| Accident type | Identifies the event which directly resulted in the injury/accident. |
| Sub-unit | The Sub-unit of the mining site where the accident occurred. |
| Mine experience | Total experience at a specific mine of the person affected calculated in decimal years. |
| Total experience | Total mining experience of the person affected calculated in decimal years. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yedla, A.; Kakhki, F.D.; Jannesari, A. Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations. Int. J. Environ. Res. Public Health 2020, 17, 7054. https://doi.org/10.3390/ijerph17197054
Yedla A, Kakhki FD, Jannesari A. Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations. International Journal of Environmental Research and Public Health. 2020; 17(19):7054. https://doi.org/10.3390/ijerph17197054
Chicago/Turabian StyleYedla, Anurag, Fatemeh Davoudi Kakhki, and Ali Jannesari. 2020. "Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations" International Journal of Environmental Research and Public Health 17, no. 19: 7054. https://doi.org/10.3390/ijerph17197054
APA StyleYedla, A., Kakhki, F. D., & Jannesari, A. (2020). Predictive Modeling for Occupational Safety Outcomes and Days Away from Work Analysis in Mining Operations. International Journal of Environmental Research and Public Health, 17(19), 7054. https://doi.org/10.3390/ijerph17197054