Machine Learning for Mortality Analysis in Patients with COVID-19

 ,
, 
 ,
, 
Abstract
:1. Introduction
2. Data and Methods
2.1. Data
- Patient ID
- Age and gender
- COVID diagnostic (confirmed/pending confirmation)
- ER date in
- ER specialty, ER diagnostic, and destination after ER
- First and last constant measurements in the ER (heart rate, temperature, minimum and maximum arterial pressure, O2 saturation in blood)
- Admission date to the hospital
- ICU date in, ICU date out, and number of days in the ICU (if applicable)
- Discharge date and destination (home/deceased/transferred to other hospital/voluntary discharge/transferred to a socio-sanitary center)
2.2. Data Analysis Methods
2.2.1. Survival Data Analysis
2.2.2. Logistic Regression
2.2.3. Bayesian Network
- A set of variables (continuous or discrete) forming the network nodes.
- A set of directed links that connect a pair of nodes. If there is a relationship with direction , it is said that X is the parent of Y.
- Each node is associated with a conditional probability function that takes as the input a particular set of values for the node’s parent variables and gives the probability of the variable represented by the node .
- The graph has no directed cycles.
2.2.4. Decision Tree
- A decision tree is a non-parametric model; it does not assume any parametric form for class densities, and the structure of the tree is not fixed a priori. Rather, the tree grows during learning depending on the complexity of the problem.
- They are explanatory models as opposed to other more powerful models, such as neural networks, in which extracting knowledge from them is extremely complex.
2.2.5. Random Forest
2.2.6. Biclustering
2.3. Software
3. Results
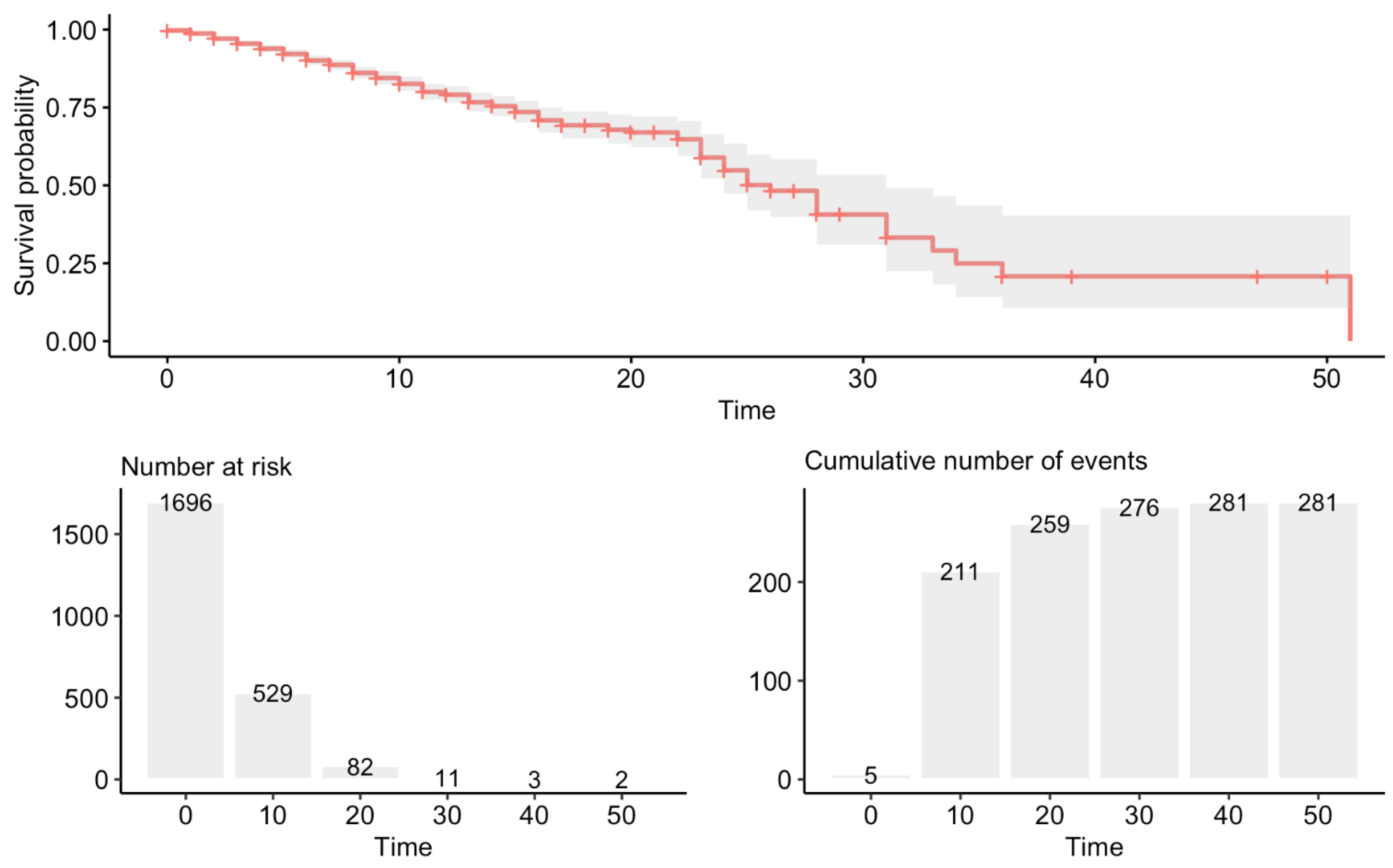
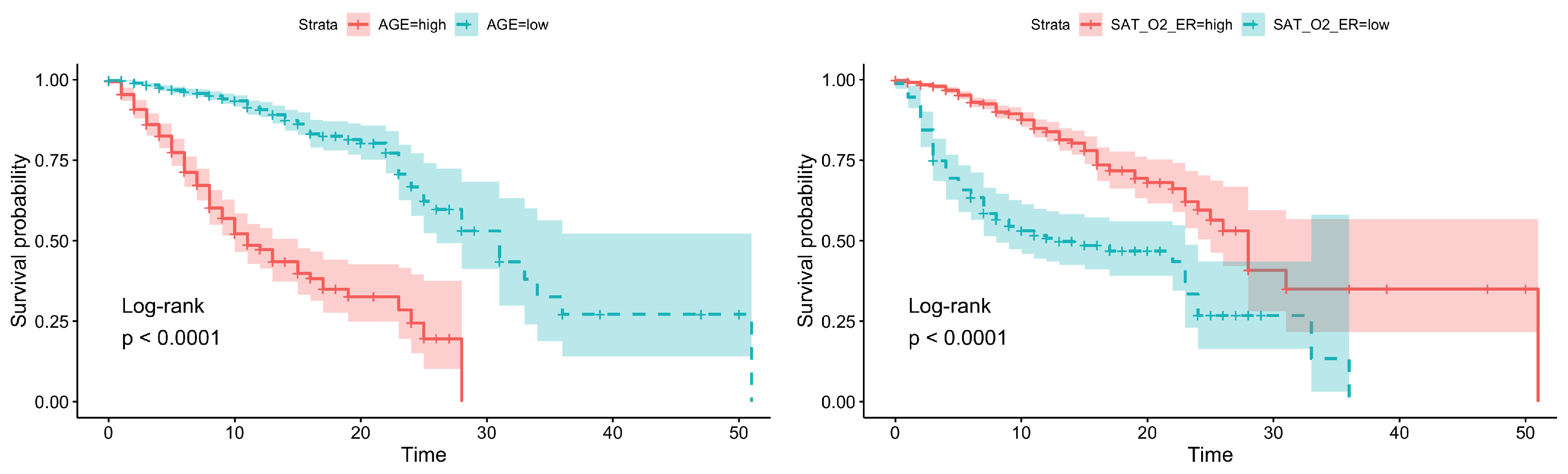
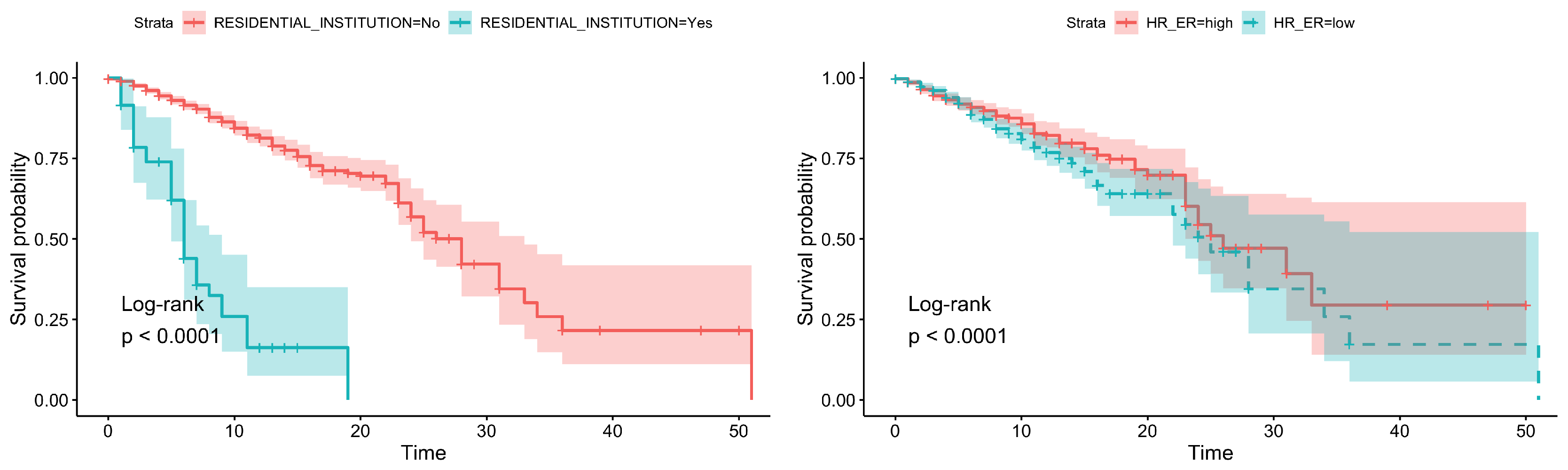
3.1. Survival Analysis
3.2. Supervised Learning Analysis
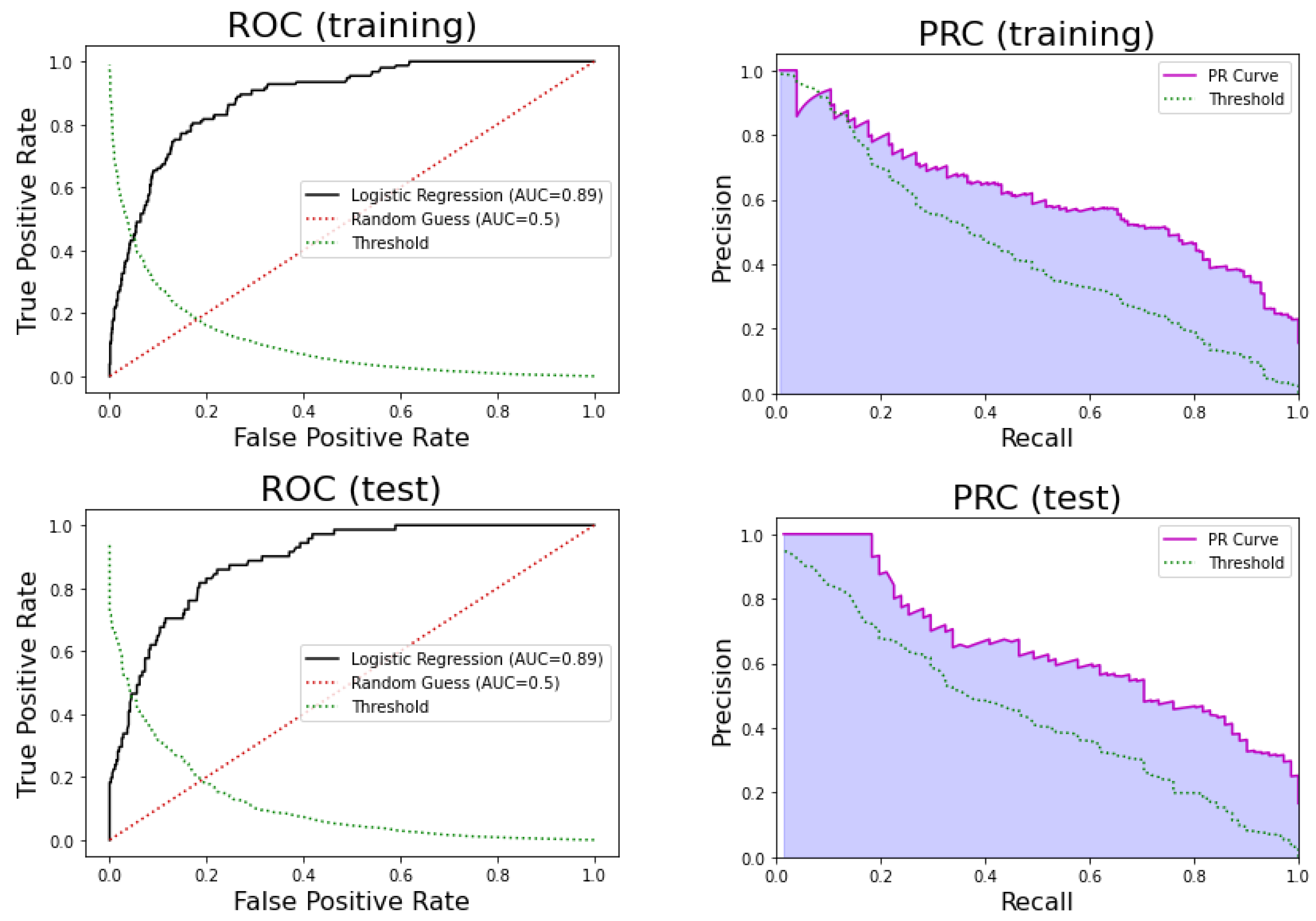
3.2.1. Logistic Regression
3.2.2. Decision Tree
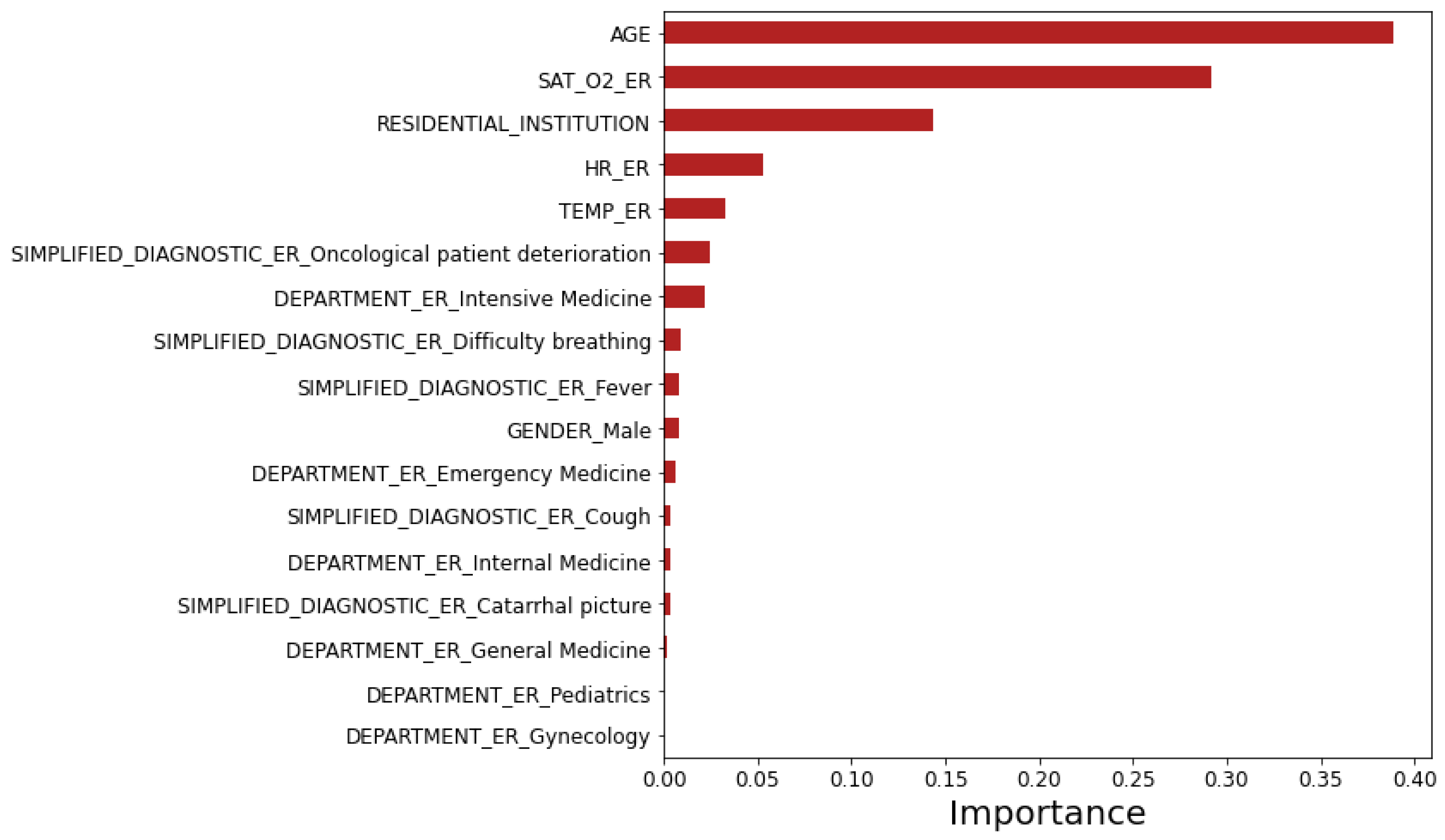
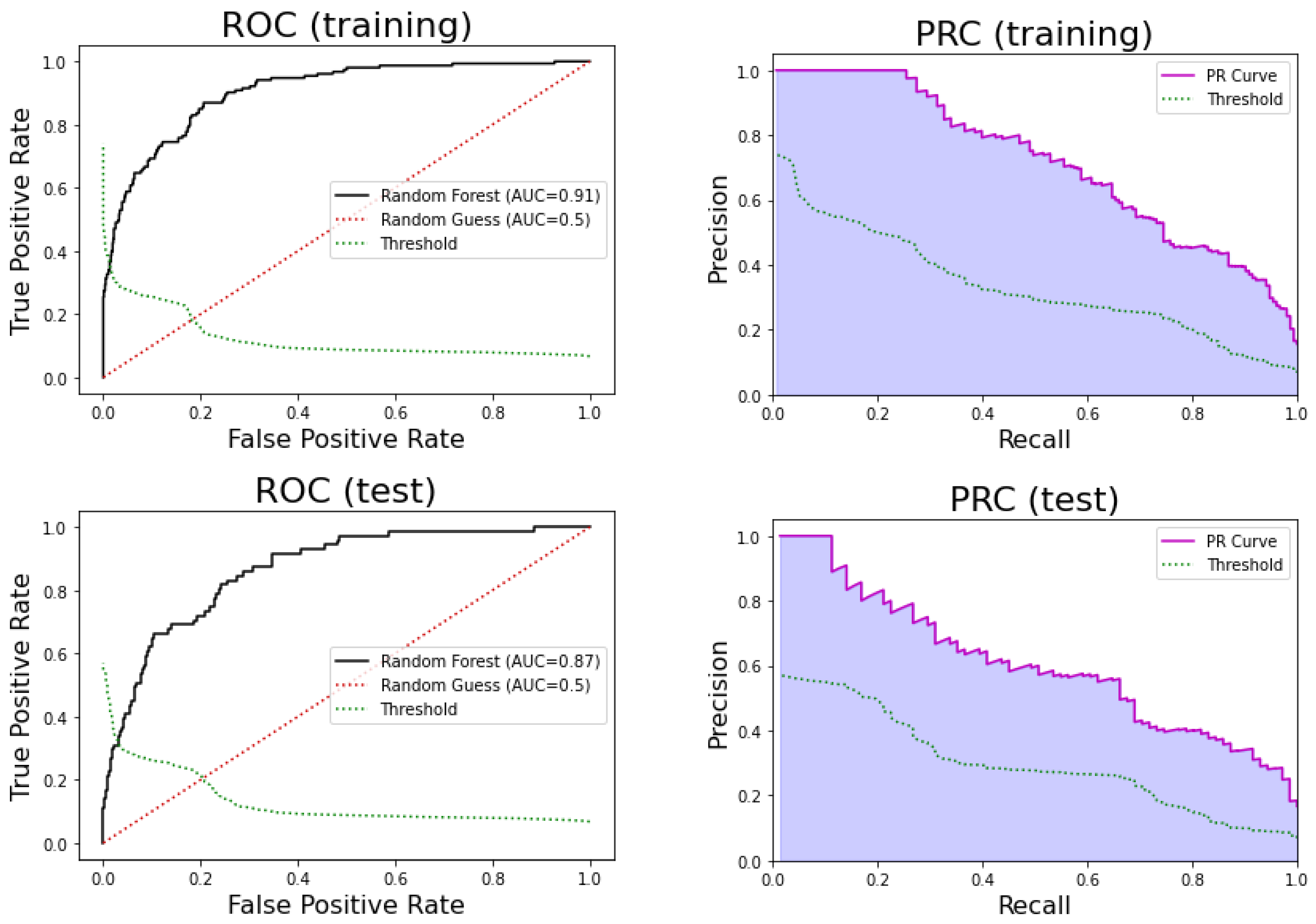
3.2.3. Random Forests
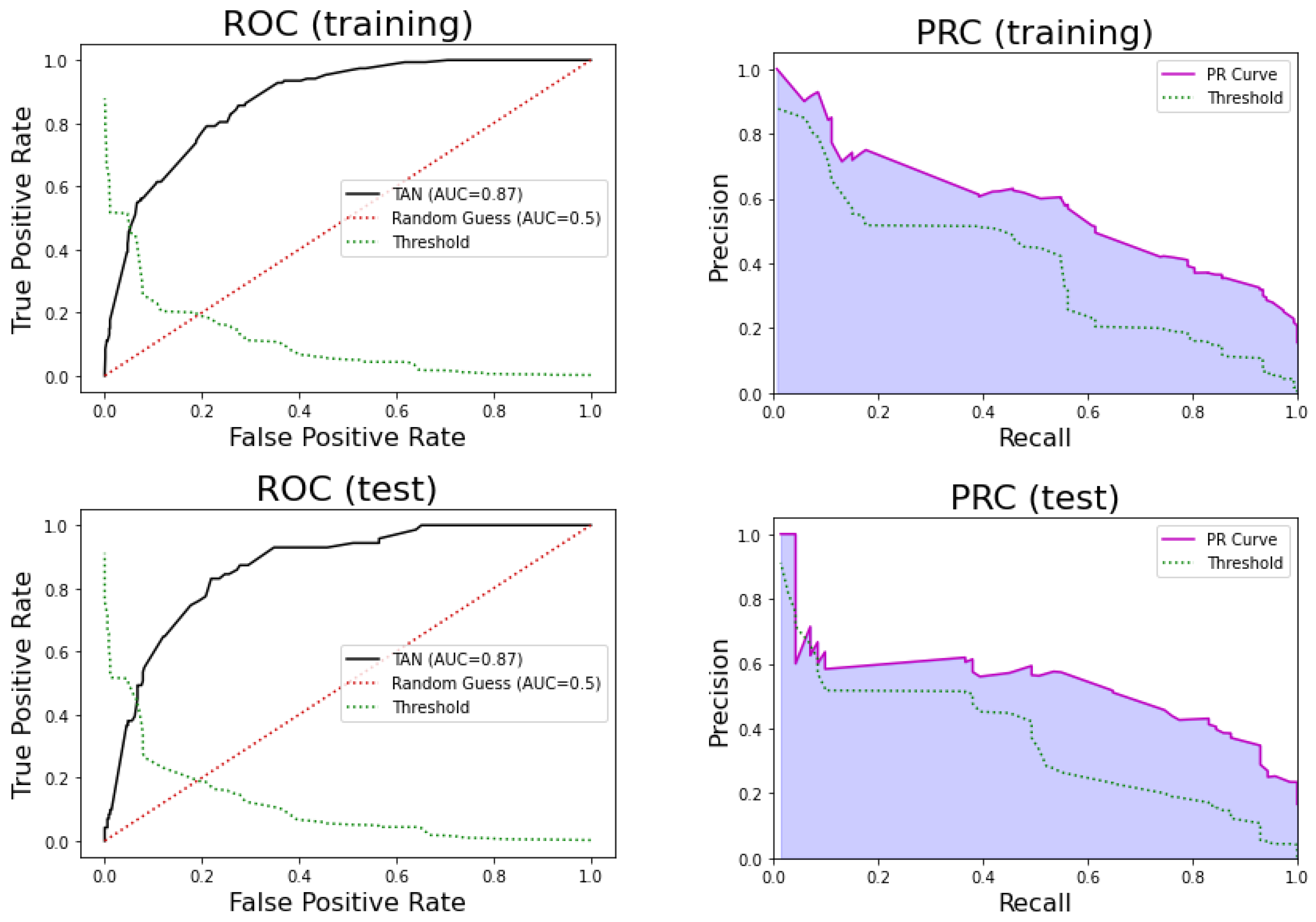
3.2.4. Bayesian Models
3.2.5. Models’ Comparison
3.3. Unsupervised Learning Analysis
Biclustering
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AIC | Akaike’s Information Criterion |
| AUC | Area Under the Curve |
| PRC | Precision Recall Curve |
| BN | Bayesian Network |
| ER | Emergency Room |
| ML | Machine Learning |
| NPV | Negative Predictive Value |
| PPV | Positive Predictive Value |
| RF | Random Forest |
| ROC | Receiver Operating Curve |
| TAN | Tree Augmented naive Bayes Network |
| WHO | World Health Organization |
References
- Coronavirus Disease (COVID-19) Weekly Epidemiological Update and Weekly Operational Update. 2020. Available online: https://www.who.int/docs/default-source/coronaviruse/situation-reports/20200824-weekly-epi-update.pdf (accessed on 31 August 2020).
- Condes, E.; Arribas, J.R. Impact of COVID-19 on Madrid hospital system. Enferm. Infecc. Microbiol. Clin. 2020, 11–21. [Google Scholar] [CrossRef]
- Wendel García, P.D.; Fumeaux, T.; Guercy, P.; Heuberger, D.M.; Montomoli, J.; Roche-Campo, F.; Schuepbach, R.A.; Hilty, M.P.; RISC-19-ICU Investigators. Prognostic factors associated with mortality risk and disease progression in 639 critically ill patients with COVID-19 in Europe: Initial report of the international RISC-19-ICU prospective observational cohort. EClinicalMedicine 2020, 25, 100449. [Google Scholar] [CrossRef]
- Berenguer, J.; Ryan, P.; Rodríguez-Baño, J.; Jarrín, I.; Carratalà, J.; Pachón, J.; Yllescas, M.; Arribas, J. Characteristics and predictors of death among 4035 consecutively hospitalized patients with COVID-19 in Spain. Clin. Microbiol. Infect. 2020, 29, 82–97. [Google Scholar] [CrossRef]
- Rodríguez-Baño, J.; Pachón, J.; Carratalà, J.; Ryan, P.; Jarrín, I.; Yllescas, M.; Arribas, J.R.; Berenguer, J. Treatment with tocilizumab or corticosteroids for COVID-19 patients with hyperinflammatory state: A multicentre cohort study (SAM-COVID-19). Clin. Microbiol. Infect. 2020. [Google Scholar] [CrossRef]
- Fiolet, T.; Guihur, A.; Rebeaud, M.; Mulot, M.; Peiffer-Smadja, N.; Mahamat-Saleh, Y. Effect of hydroxychloroquine with or without azithromycin on the mortality of COVID-19 patients: A systematic review and meta-analysis. Clin. Microbiol. Infect. 2020. [Google Scholar] [CrossRef]
- Tiwari, N.; Upadhyay, J.; Nazam Ansari, M.; Joshi, R. Novel Beta-Coronavirus (SARS-CoV-2): Current and Future Aspects of Pharmacological Treatments. Saudi Pharm. J. 2020, 28, 1243–1252. [Google Scholar] [CrossRef]
- Lima, M.A.; Silva, M.T.T.; Oliveira, R.V.; Soares, C.N.; Takano, C.L.; Azevedo, A.E.; Moraes, R.L.; Rezende, R.B.; Chagas, I.T.; Espíndola, O.; et al. Smell dysfunction in COVID-19 patients: More than a yes-no question. J. Neurol. Sci. 2020, 418, 117107. [Google Scholar] [CrossRef]
- Barabas, J.; Zalman, R.; Kochlan, M. Automated evaluation of COVID-19 risk factors coupled with real-time, indoor, personal localization data for potential disease identification, prevention and smart quarantining. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; pp. 645–648. [Google Scholar]
- Islam, M.N.; Islam, I.; Munim, K.M.; Islam, A.K.M.N. A Review on the Mobile Applications Developed for COVID-19: An Exploratory Analysis. IEEE Access 2020, 8, 145601–145610. [Google Scholar] [CrossRef]
- Cecilia, J.M.; Cano, J.; Hernández-Orallo, E.; Calafate, C.T.; Manzoni, P. Mobile crowdsensing approaches to address the COVID-19 pandemic in Spain. IET Smart Cities 2020, 2, 58–63. [Google Scholar] [CrossRef]
- Mbunge, E. Integrating emerging technologies into COVID-19 contact tracing: Opportunities, challenges and pitfalls. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 1631–1636. [Google Scholar] [CrossRef]
- Fields, B.K.; Demirjian, N.L.; Gholamrezanezhad, A. Coronavirus Disease 2019 (COVID-19) diagnostic technologies: A country-based retrospective on screening and containment procedures during the first wave of the pandemic. Clin. Imaging 2020. [Google Scholar] [CrossRef]
- Escobedo, A.A.; Rodríguez-Morales, A.J.; Almirall, P.; Almanza, C.; Rumbaut, R. SARS-CoV-2/COVID-19: Evolution in the Caribbean islands. Travel Med. Infect. Dis. 2020, 101854. [Google Scholar] [CrossRef]
- Guirao, A. The Covid-19 outbreak in Spain. A simple dynamics model, some lessons, and a theoretical framework for control response. Infect. Dis. Model. 2020, 5, 652–669. [Google Scholar] [CrossRef]
- Yeşilkanat, C.M. Spatio-temporal estimation of the daily cases of COVID-19 in worldwide using random forest machine learning algorithm. Chaos Solitons Fractals 2020, 140, 110210. [Google Scholar] [CrossRef]
- Al-Rakhami, M.S.; Al-Amri, A.M. Lies Kill, Facts Save: Detecting COVID-19 Misinformation in Twitter. IEEE Access 2020, 8, 155961–155970. [Google Scholar] [CrossRef]
- Shrivastava, G.; Kumar, P.; Ojha, R.P.; Srivastava, P.K.; Mohan, S.; Srivastava, G. Defensive Modeling of Fake News Through Online Social Networks. IEEE Trans. Comput. Soc. Syst. 2020, 1–9. [Google Scholar] [CrossRef]
- Yang, C.; Delcher, C.; Shenkman, E.; Ranka, S. Data Driven Approaches for Healthcare: Machine Learning for Identifying High Utilizers; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Topol, E. Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again; Basic Books: New York, NY, USA, 2019. [Google Scholar]
- Chang, A.C. Intelligence-Based Medicine: Artificial Intelligence and Human Cognition in Clinical Medicine and Healthcare; Academic Press: New York, NY, USA, 2020. [Google Scholar]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable Deep Learning for Pulmonary Disease and Coronavirus COVID-19 Detection from X-rays. Comput. Methods Programs Biomed. 2020, 196, 105608. [Google Scholar] [CrossRef]
- Mertz, L. AI-Driven COVID-19 Tools to Interpret, Quantify Lung Images. IEEE Pulse 2020, 11, 2–7. [Google Scholar] [CrossRef]
- Horry, M.J.; Chakraborty, S.; Paul, M.; Ulhaq, A.; Pradhan, B.; Saha, M.; Shukla, N. COVID-19 Detection Through Transfer Learning Using Multimodal Imaging Data. IEEE Access 2020, 8, 149808–149824. [Google Scholar] [CrossRef]
- Wang, N.; Liu, H.; Xu, C. Deep Learning for The Detection of COVID-19 Using Transfer Learning and Model Integration. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 281–284. [Google Scholar]
- Cheng, F.Y.; Joshi, H.; Tandon, P.; Freeman, R.; Reich, D.L.; Mazumdar, M.; Kohli-Seth, R.; Levin, M.A.; Timsina, P.; Kia, A. Using Machine Learning to Predict ICU Transfer in Hospitalized COVID-19 Patients. J. Clin. Med. 2020, 9, 1668. [Google Scholar] [CrossRef]
- Izquierdo, J.L.; Ancochea, J.; Soriano, J.B. Clinical Characteristics and Prognostic Factors for ICU Admission of Patients with Covid-19: A Retrospective Study Using Machine Learning and Natural Language Processing. J. Med. Internet Res. 2020. [Google Scholar] [CrossRef] [PubMed]
- Burian, E.; Jungmann, F.; Kaissis, G.A.; Lohöfer, F.K.; Spinner, C.D.; Lahmer, T.; Treiber, M.; Dommasch, M.; Schneider, G.; Huber, W. Intensive Care Risk Estimation in COVID-19 Pneumonia Based on Clinical and Imaging Parameters: Experiences from the Munich Cohort. J. Clin. Med. 2020, 9, 1514. [Google Scholar] [CrossRef] [PubMed]
- Shen, B.; Yi, X.; Sun, Y.; Bi, X.; Du, J.; Zhang, C.; Quan, S.; Zhang, F.; Sun, R.; Ge, W. Proteomic and Metabolomic Characterization of COVID-19 Patient Sera. Cell 2020, 182, 59–72. [Google Scholar] [CrossRef] [PubMed]
- Randhawa, G.S.; Soltysiak, M.P.; El Roz, H.; de Souza, C.P.; Hill, K.A.; Kari, L. Machine learning using intrinsic genomic signatures for rapid classification of novel pathogens: COVID-19 case study. PLoS ONE 2020, 15, e0232391. [Google Scholar] [CrossRef] [Green Version]
- Naseem, M.; Akhund, R.; Arshad, H.; Ibrahim, M.T. Exploring the Potential of Artificial Intelligence and Machine Learning to Combat COVID-19 and Existing Opportunities for LMIC: A Scoping Review. J. Prim. Care Community Health 2020. [Google Scholar] [CrossRef]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of machine learning and artificial intelligence for Covid-19 (SARS-CoV-2) pandemic: A review. Chaos Solitons Fractals 2020. [Google Scholar] [CrossRef]
- Albahri, A.S.; Hamid, R.A. Role of biological Data Mining and Machine Learning Techniques in Detecting and Diagnosing the Novel Coronavirus (COVID-19): A Systematic Review. J. Med Syst. 2020, 44. [Google Scholar] [CrossRef]
- Covid Data Save Lives. 2020. Available online: https://www.hmhospitales.com/coronavirus/covid-data-save-lives/english-version (accessed on 31 August 2020).
- Bernaola, N.; Mena, R.; Bernaola, A.; Lara, A.; Carballo, C.; Larranaga, P.; Bielza, C. Observational Study of the Efficiency of Treatments in Patients Hospitalized with Covid-19 in Madrid. medRxiv 2020. Available online: https://www.medrxiv.org/content/early/2020/07/21/2020.07.17.20155960.full.pdf (accessed on 31 August 2020). [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Russell, S.J.; Norvig, P.; Russell, S.J. Artificial Intelligence: A Modern Approach (Prentice Hall Series in Artificial Intelligence); Prentice Hall: New York, NY, USA, 2003. [Google Scholar]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1956, 53, 457–481. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Klein, M. Survival Analysis: A Self-Learning Text; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Weisberg, S. Applied Linear Regression; Wiley: Weinheim, Germany, 2005. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; Adaptive computation and machine learning; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Kursa, M.; Rudnicki, W. Feature Selection with Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A. Direct Clustering of a Data Matrix. J. Am. Stat. Assoc. 1972, 67, 123–129. [Google Scholar] [CrossRef]
- Scikit-Learn: Machine Learning in Python. 2020. Available online: https://scikit-learn.org/stable/ (accessed on 31 August 2020).
- Pandas. 2020. Available online: https://pandas.pydata.org/ (accessed on 31 August 2020).
- Numpy. 2020. Available online: https://numpy.org/ (accessed on 31 August 2020).
- Matplotlib: Visualization with Python. 2020. Available online: https://matplotlib.org/ (accessed on 31 August 2020).
- Kuhn, M. CARET: Classification and Regression Training, R Package Version 6.0-86; Available online: https://CRAN.R-project.org/package=caret (accessed on 31 August 2020).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien, R Package Version 1.7-3; Available online: https://CRAN.R-project.org/package=e1071 (accessed on 31 August 2020).
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- WHO Discontinues Hydroxychloroquine and Lopinavir/ritonavir Treatment Arms for COVID-19. 2020. Available online: https://www.who.int/news-room/detail/04-07-2020-who-discontinues-hydroxychloroquine-and-lopinavir-ritonavir-treatment-arms-for-covid-19 (accessed on 31 August 2020).
- García, A. Covid-19: The precarious position of Spain’s nursing homes. BMJ 2020, 369, 1–3. [Google Scholar]
- FDA Cautions against Use of Hydroxychloroquine or Chloroquine for COVID-19 Outside of the Hospital Setting or a Clinical Trial Due to Risk of Heart Rhythm Problems. 2020. Available online: https://www.fda.gov/drugs/drug-safety-and-availability/fda-cautions-against-use-hydroxychloroquine-or-chloroquine-covid-19-outside-hospital-setting-or (accessed on 31 August 2020).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Sig. | Optimal Cutpoint | Mean Time ± StdError |
|---|---|---|---|
| Age | <0.0001 | 79.0 | high = 14.12 ± 0.70, low = 31.53 ± 1.95 |
| Residential Institution | <0.0001 | yes = 7.74 ± 0.91, no = 27.79 ± 1.61 | |
| Temperature | 0.72 | 35.9 | high = 27.88 ± 1.79, low = 20.09 ± 1.50 |
| Heart Rate | <0.0001 | 89.0 | high = 29.34 ± 2.48, low = 25.81 ± 2.21 |
| O2 saturation | <0.0001 | 86.0 | high = 30.44 ± 2.14, low = 16.65 ± 1.26 |
| Gender | 0.42 | female = 31.99 ± 3.01, male = 25.36 ± 1.70 | |
| Department | 0.36 | Emergency Medicine 26.71 ± 1.59 General Medicine 40.48 ± 4.01 Gynecology 51.00 ± 0.00 Intensive Medicine 24.50 ± 9.03 Internal Medicine 30.76 ± 6.93 Pediatrics 51.00 ± 0.00 Traumatology 12.50 ± 1.06 | |
| Simplified Diagnostic | 0.019 | Catarrhal Picture 25.29 ± 1.83 Cough 30.22 ± 6.27 Difficulty Breathing 25.35 ± 2.26 Fever 39.92 ± 2.71 Oncological Patient Deterioration 23.34 ± 3.85 Other 27.02 ± 3.56 |
| Variables | Estimate | Std Error | p-Value |
|---|---|---|---|
| Age | 1.738 | 0.174 | <0.001 |
| Gender | 0.207 | 0.111 | 0.061 |
| Saturation | 0.102 | 1.277 | <0.001 |
| Residential Institution | 0.082 | 1.329 | <0.001 |
| Oncological Patient Deterioration | 0.078 | 1.277 | <0.001 |
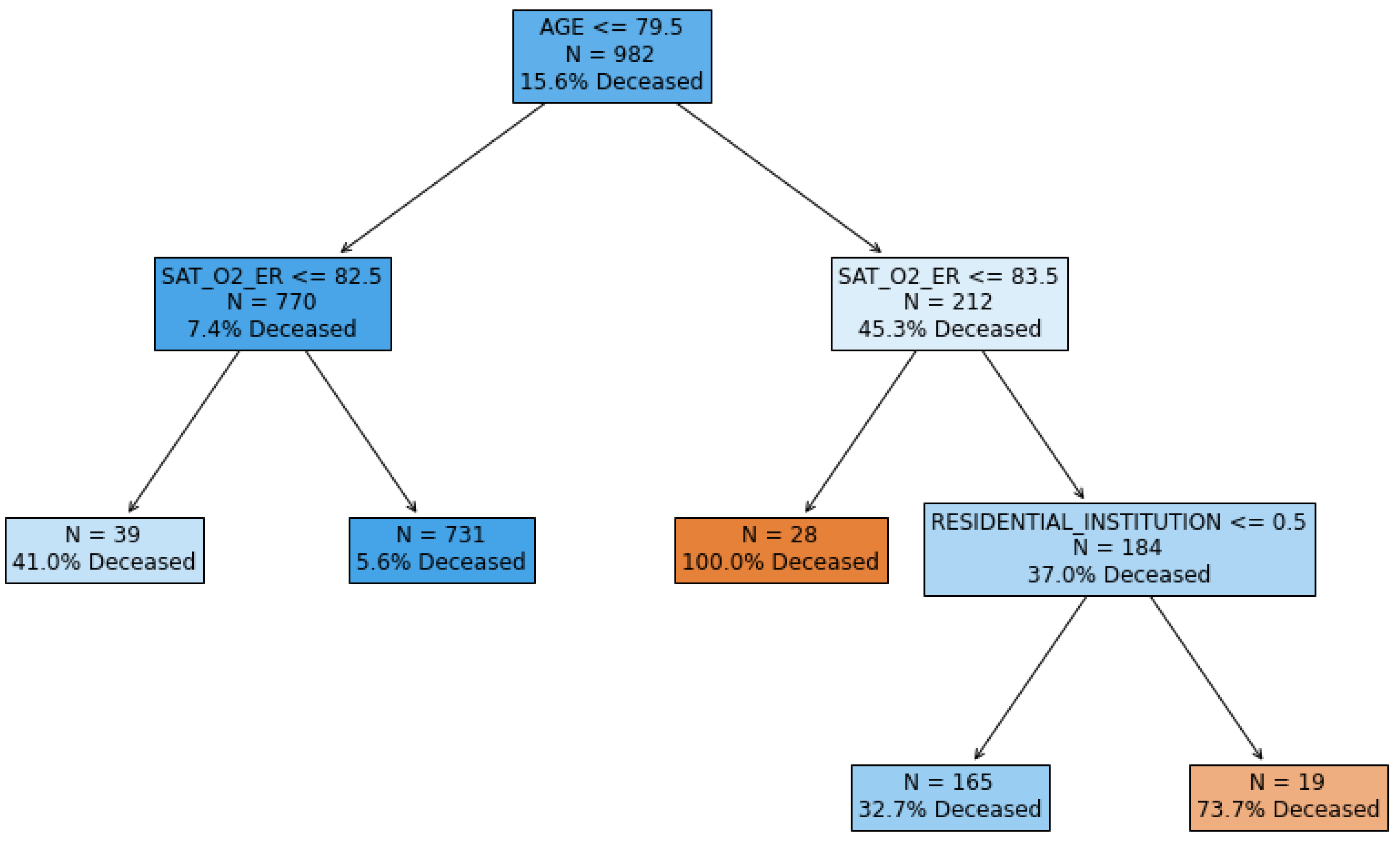
| Rule | Support (Training) | Deceased (Training) | Support (Test) | Deceased (Test) |
|---|---|---|---|---|
| and | 4.0% (N = 39) | 41.0% | 3.5% (N = 15) | 40.0% |
| and | 74.4% (N = 731) | 5.6% | 72.4% (N = 309) | 7.1% |
| and | 2.9% (N = 28) | 100% | 3.5% (N = 15) | 80.0% |
| and and | 16.8% (N = 165) | 32.7% | 19.0% (N = 81) | 32.1% |
| and and | 1.9% (N = 19) | 73.7% | 1.6% (N = 7) | 71.4% |
| Model | AUC | Sensitivity | Specificity | PPV | NPV |
|---|---|---|---|---|---|
| Logistic Regression | 0.89 | 0.80 | 0.83 | 0.46 | 0.96 |
| Decision Tree | 0.81 | 0.73 | 0.83 | 0.45 | 0.94 |
| Random Forest | 0.90 | 0.87 | 0.79 | 0.44 | 0.97 |
| Tree Augmented Naive Bayes | 0.87 | 0.79 | 0.79 | 0.41 | 0.95 |
| Model | AUC | Sensitivity | Specificity | PPV | NPV |
|---|---|---|---|---|---|
| Logistic Regression | 0.89 | 0.82 | 0.81 | 0.47 | 0.96 |
| Decision Tree | 0.77 | 0.69 | 0.81 | 0.42 | 0.93 |
| Random Forest | 0.87 | 0.82 | 0.76 | 0.40 | 0.95 |
| Tree Augmented Naive Bayes | 0.87 | 0.77 | 0.79 | 0.43 | 0.95 |
| Decision Tree | Random Forest | Tree Augmented Naive Bayes | |
|---|---|---|---|
| Logistic Regression | <0.0001 | <0.01 | 0.07 |
| Decision Tree | - | <0.0001 | <0.001 |
| Random Forest | - | - | 0.92 |
| Bicluster | N | Age | First Saturation | % ICU | % Deceased |
|---|---|---|---|---|---|
| 1 | 845 | 62 ± 15 [0–98] | 94 ± 4 | 0.7 | 1.5 |
| 2 | 555 | 69 ± 16 [26–105] | 91 ± 8 | 2.3 | 14.2 |
| 3 | 223 | 78 ± 15 [0–106] | 89 ± 9 | 4.5 | 63.2 |
| 4 | 72 | 68 ± 12 [34–98] | 85 ± 13 | 70.8 | 66.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Montañés, M.; Rodríguez-Belenguer, P.; Serrano-López, A.J.; Soria-Olivas, E.; Alakhdar-Mohmara, Y. Machine Learning for Mortality Analysis in Patients with COVID-19. Int. J. Environ. Res. Public Health 2020, 17, 8386. https://doi.org/10.3390/ijerph17228386
Sánchez-Montañés M, Rodríguez-Belenguer P, Serrano-López AJ, Soria-Olivas E, Alakhdar-Mohmara Y. Machine Learning for Mortality Analysis in Patients with COVID-19. International Journal of Environmental Research and Public Health. 2020; 17(22):8386. https://doi.org/10.3390/ijerph17228386
Chicago/Turabian StyleSánchez-Montañés, Manuel, Pablo Rodríguez-Belenguer, Antonio J. Serrano-López, Emilio Soria-Olivas, and Yasser Alakhdar-Mohmara. 2020. "Machine Learning for Mortality Analysis in Patients with COVID-19" International Journal of Environmental Research and Public Health 17, no. 22: 8386. https://doi.org/10.3390/ijerph17228386
APA StyleSánchez-Montañés, M., Rodríguez-Belenguer, P., Serrano-López, A. J., Soria-Olivas, E., & Alakhdar-Mohmara, Y. (2020). Machine Learning for Mortality Analysis in Patients with COVID-19. International Journal of Environmental Research and Public Health, 17(22), 8386. https://doi.org/10.3390/ijerph17228386