Coronary Artery Disease Diagnosis; Ranking the Significant Features Using a Random Trees Model

 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
2. Data Mining Classification Methods
2.1. Decision Tree of CHAID
- Reading predictors: the first step is to make classified predictors or features out of any consecutive predictors by partitioning the concerned consecutive disseminations into a number of classifiers with almost equal numbers of observations. For classified predictors, the classifiers or target classes are determined.
- Consolidating classifiers: the second step is to round through the features to estimate for each feature the pair of feature classifiers that is least significantly different with regard to the dependent variable. In this process, the CHIAD model includes two types of statistical tests. One, for the classification dataset, it will gain a Chi-square test or Pearson Chi-square. The assumptions for Chi-square test are as follows:
- 3.
- Selecting the partition variable: the third step is to select the partition of the predictor variable with the smallest adapted p-value, i.e., the predictor variable that will gain the most significant partition. The p-value is formulated in a . If the smallest (Bonferroni) adopted p-value for any predictor feature is greater than some alpha-to-partition value, then no further partitions will be done, and the concerned node is a final node. This process is continued until no further partitions can be done, i.e., given the alpha-to-consolidate and alpha-to-partition values). Eventually, according to step 2, the p-value is obtained as follows:
2.2. Decision Tree of C5.0
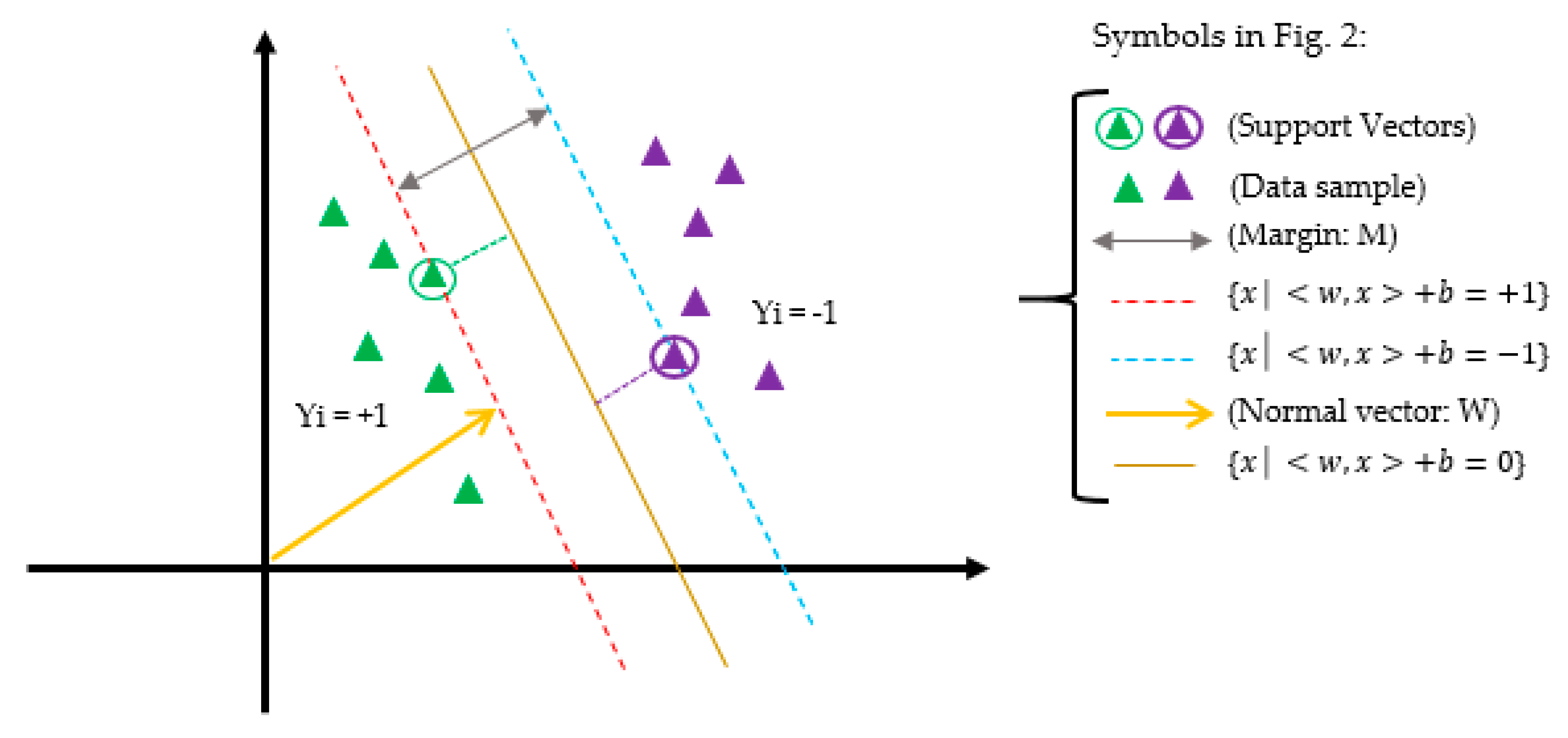
2.3. Support Vector Machine
2.4. Random Trees
- Using the N data sample randomly, in the training dataset to develop the tree.
- Each node as a predictive feature grasps a random data sample selected so that m < M (m represents the selected feature and M represents the full of features in the corresponding dataset. Given that during the growth of trees, m is kept constant.)
- Using the m features selected for generating the partition in the previous step, the P node is computed using the best partition path from points. P represents the next node.
- For aggregating, the prediction dataset uses the tree classification voting from the trained trees with n trees.
- For generating the terminal RTs, the model uses the biggest voted features.
- The RTs process continues until the tree is complete and reaches only one leaf node.
3. Related Works
4. Proposed Methodology
4.1. Description of the Dataset
4.2. Classifying the Dataset
4.3. Preprocessing the Dataset
4.4. Classifying the Models Using the 10-Fold Cross-Validation Method
5. Evaluating the Results
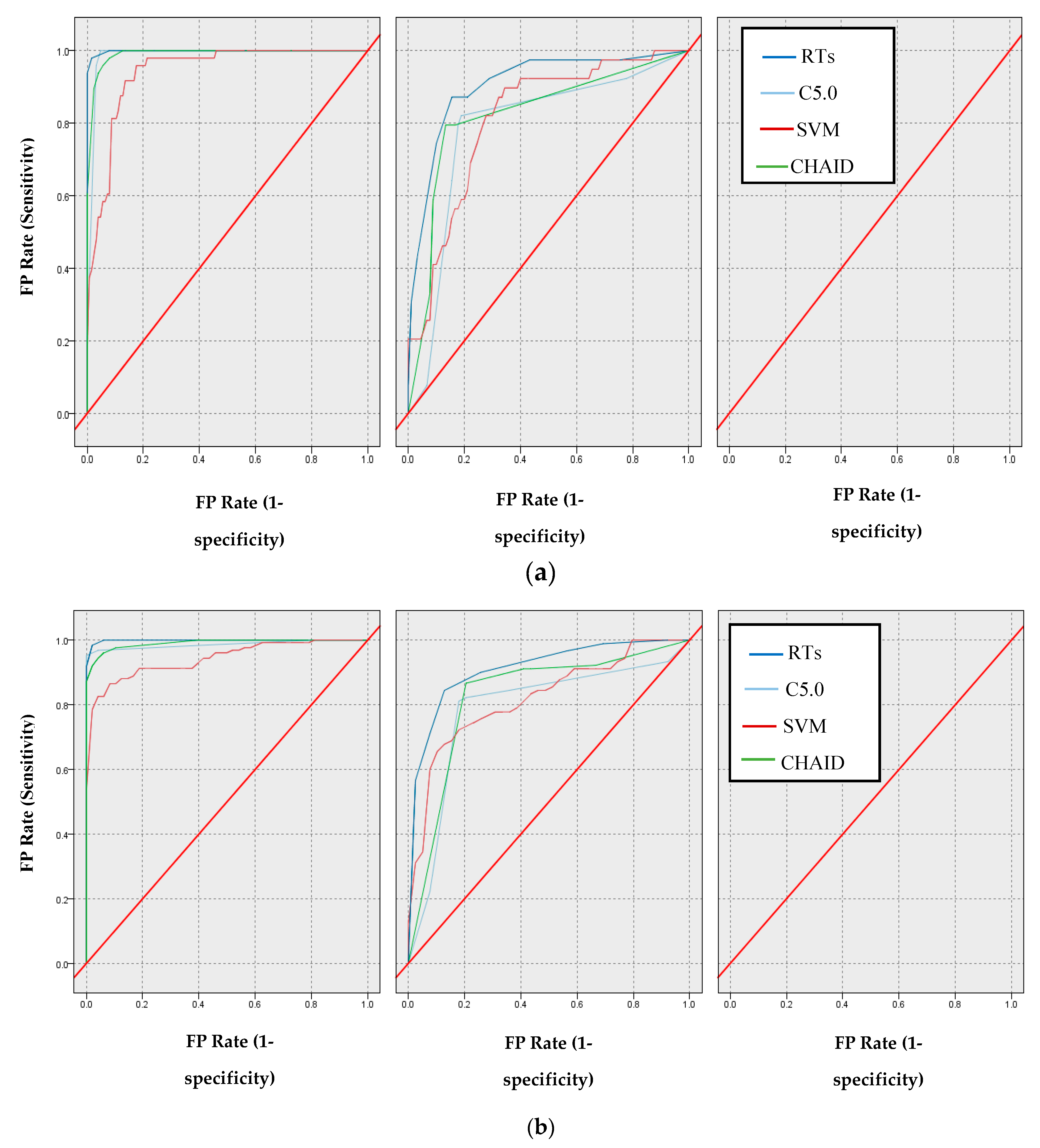
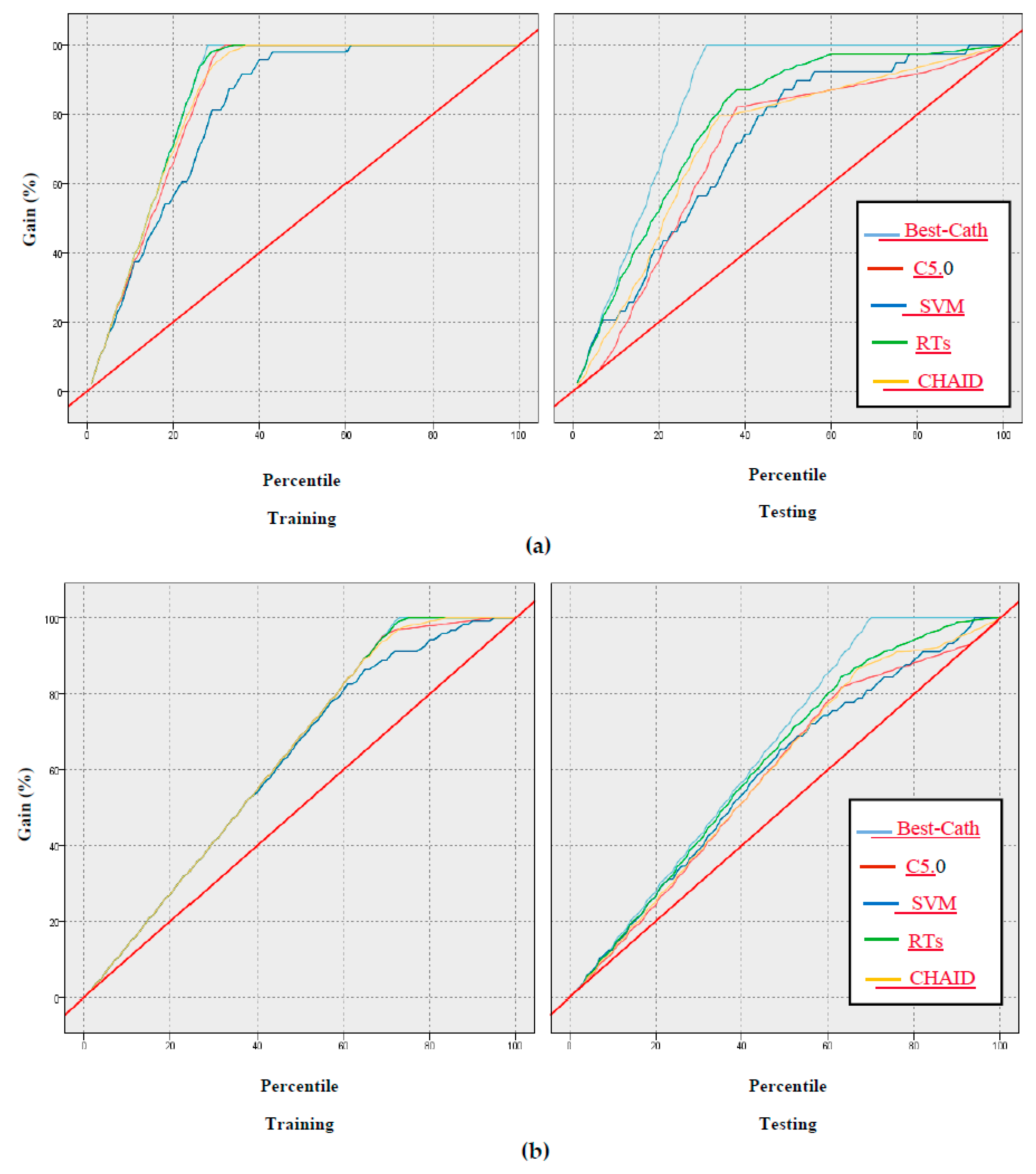
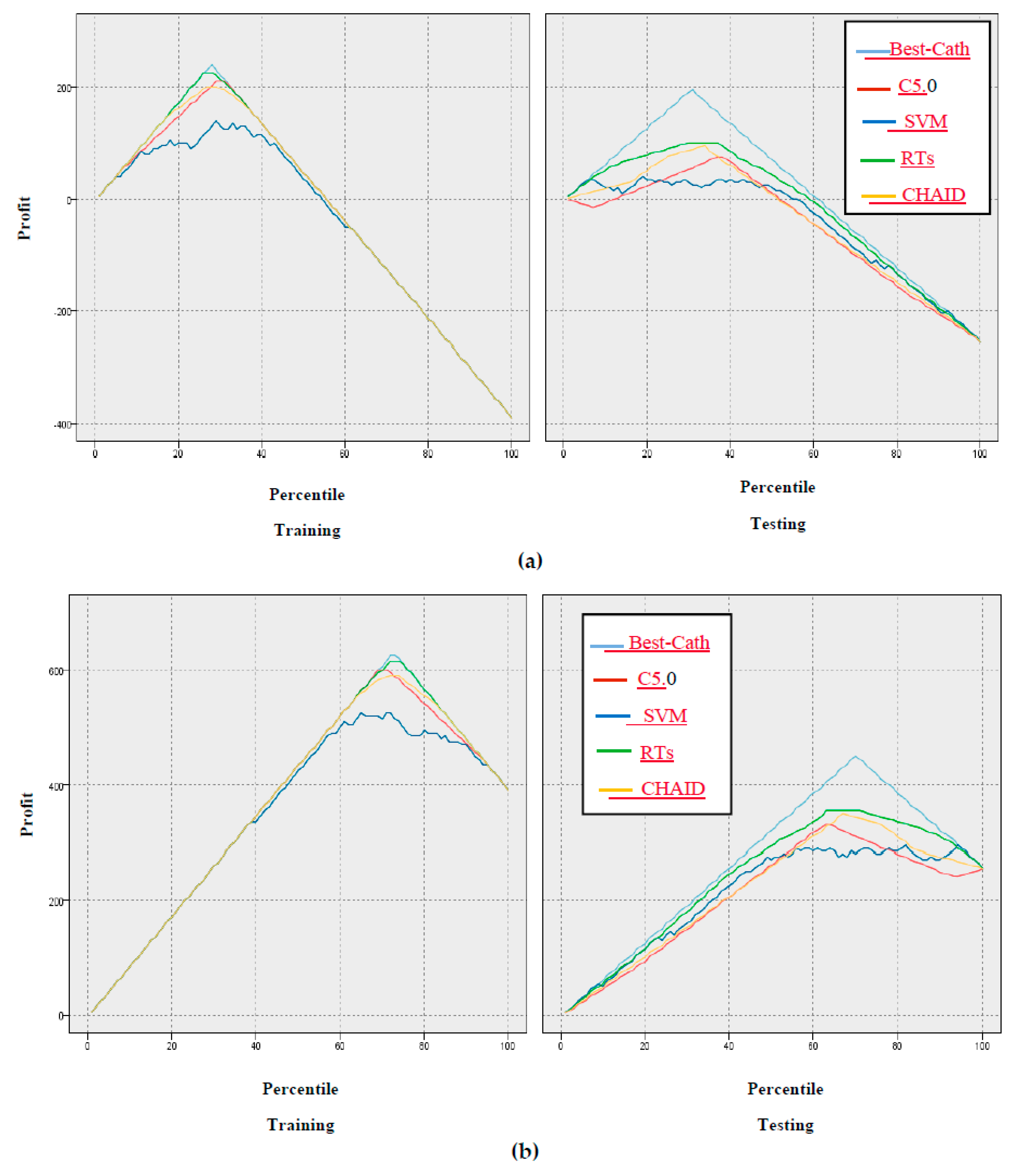
5.1. Evaluation Based on Classification Criteria
5.2. Evaluation Based on Significant Predictive Features
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Joloudari, J.H.; Saadatfar, H.; Dehzangi, A.; Shamshirband, S. Computer-aided decision-making for predicting liver disease using PSO-based optimized SVM with feature selection. Inform. Med. Unlocked 2019, 17, 100255. [Google Scholar] [CrossRef]
- Ahmad, G.; Khan, M.A.; Abbas, S.; Athar, A.; Khan, B.S.; Aslam, M.S. Automated Diagnosis of Hepatitis B Using Multilayer Mamdani Fuzzy Inference System. J. Healthc. Eng. 2019, 2019, 6361318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Kung, L.; Gupta, S.; Ozdemir, S. Leveraging big data analytics to improve quality of care in healthcare organizations: A configurational perspective. Br. J. Manag. 2019, 30, 362–388. [Google Scholar] [CrossRef]
- Amin, M.S.; Chiam, Y.K.; Varathan, K.D. Identification of significant features and data mining techniques in predicting heart disease. Telemat. Inform. 2019, 36, 82–93. [Google Scholar] [CrossRef]
- Zipes, D.P.; Libby, P.; Bonow, R.O.; Mann, D.L.; Tomaselli, G.F. Braunwal’s Heart Disease E-Book: A Textbook of Cardiovascular Medicine; Elsevier Health Sciences Wiley: San Francisco, CA, USA, 2018. [Google Scholar]
- Alizadehsani, R.; Abdar, M.; Roshanzamir, M.; Khosravi, A.; Kebria, P.M.; Khozeimeh, F.; Nahavandi, S.; Sarrafzadegan, N.; Acharya, U.R. Machine learning-based coronary artery disease diagnosis: A comprehensive review. Comput. Biol. Med. 2019, 111, 103346. [Google Scholar] [CrossRef]
- Pace, P.; Aloi, G.; Gravina, R.; Caliciuri, G.; Fortino, G.; Liotta, A. An edge-based architecture to support efficient applications for healthcare industry 4.0. IEEE Trans. Ind. Inform. 2018, 15, 481–489. [Google Scholar] [CrossRef] [Green Version]
- Wah, T.Y.; Gopal Raj, R.; Iqbal, U. Automated diagnosis of coronary artery disease: A review and workflow. Cardiol. Res. Pract. 2018, 2018, 2016282. [Google Scholar]
- World Health Organization (WHO). Cardiovascular diseases (CVD). 2019. Available online: http://www.who.int/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds) (accessed on 8 April 2019).
- Centers for Disease Control and Prevention, National Center for Health Statistics. Multiple Cause of Death 1999–2015 on CDC WONDER Online Database, Released December 2016. Data Are from the Multiple Cause of Death Files, 1999–2015, as Compiled from Data Provided by the 57 Vital Statistics Jurisdictions through the Vital Statistics Cooperative Program. Available online: http://wonder.cdc.gov/mcd-icd10.html (accessed on 8 April 2019).
- Benjamin, E.J.; Virani, S.S.; Callaway, C.W.; Chang, A.R.; Cheng, S.; Chiuve, S.E.; Cushman, M.; Delling, F.N.; Deo, R.; de Ferranti, S.D. Heart disease and stroke statistics-2018 update: A report from the American Heart Association. Circulation 2018, 137, e67–e492. [Google Scholar] [CrossRef]
- Alizadehsani, R.; Habibi, J.; Hosseini, M.J.; Mashayekhi, H.; Boghrati, R.; Ghandeharioun, A.; Bahadorian, B.; Sani, Z.A. A data mining approach for diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2013, 111, 52–61. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Mojrian, S.; Pinter, G.; Hassannataj Joloudari, J.; Felde, I.; Nabipour, N.; Nadai, L.; Mosavi, A. Hybrid Machine Learning Model of Extreme Learning Machine Radial Basis Function for Breast Cancer Detection and Diagnosis: A Multilayer Fuzzy Expert System. Preprints 2019, 2019100349. [Google Scholar] [CrossRef]
- Liu, S.; Motani, M. Feature Selection Based on Unique Relevant Information for Health Data. arXiv 2018, arXiv:1812.00415. [Google Scholar]
- Kass, G.V. An exploratory technique for investigating large quantities of categorical data. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1980, 29, 119–127. [Google Scholar] [CrossRef]
- Abdar, M.; Zomorodi-Moghadam, M.; Das, R.; Ting, I.H. Performance analysis of classification algorithms on early detection of liver disease. Expert Syst. Appl. 2017, 67, 239–251. [Google Scholar] [CrossRef]
- Chaid-analysis. Available online: http://www.statsoft.com/textbook/chaid-analysis/ (accessed on 8 April 2019).
- Available online: http://www.public.iastate.edu/~kkoehler/stat557/tree14p.pdf (accessed on 8 April 2019).
- Althuwaynee, O.F.; Pradhan, B.; Lee, S. A novel integrated model for assessing landslide susceptibility mapping using CHAID and AHP pair-wise comparison. Int. J. Remote Sens. 2016, 37, 1190–1209. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Pramanik, S.; Chowdhury, U.N.; Pramanik, B.K.; Huda, N. A comparative study of bagging, boosting and C4. 5: The recent improvements in decision tree learning algorithm. Asian J. Inf. Technol. 2010, 9, 300–306. [Google Scholar]
- Quinlan, J.R. Bagging, Boosting, and C4. 5; in AAAI/IAAI; Wiley: San Fransisco, CA, USA, 1996. [Google Scholar]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Schapire, R.E. A Brief Introduction to Boosting; Springer: Amsterdam, The Netherland, 1999. (In Ijcai) [Google Scholar]
- Pang, S.-L.; Gong, J.-Z. C5. 0 classification algorithm and application on individual credit evaluation of banks. Syst. Eng.-Theory Pract. 2009, 29, 94–104. [Google Scholar] [CrossRef]
- Pandya, R.; Pandya, J. C5. 0 algorithm to improved decision tree with feature selection and reduced error pruning. Int. J. Comput. Appl. 2015, 117, 18–21. [Google Scholar] [CrossRef]
- Siknun, G.P.; Sitanggang, I.S. Web-based classification application for forest fire data using the shiny framework and the C5. 0 algorithm. Procedia Environ. Sci. 2016, 33, 332–339. [Google Scholar] [CrossRef] [Green Version]
- Tseng, C.J.; Lu, C.J.; Chang, C.C.; Chen, G.D. Application of machine learning to predict the recurrence-proneness for cervical cancer. Neural Comput. Appl. 2014, 24, 1311–1316. [Google Scholar] [CrossRef]
- Vladimir, V.N.; Vapnik, V. The Nature of Statistical Learning Theory; Springer: Heidelberg, Germany, 1995. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Navia-Vázquez, A.; Gutierrez-Gonzalez, D.; Parrado-Hernández, E.; Navarro-Abellan, J.J. Distributed support vector machines. IEEE Trans. Neural Netw. 2006, 17, 1091. [Google Scholar] [CrossRef] [PubMed]
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random forests and decision trees. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 272–278. [Google Scholar]
- Abdoh, S.F.; Rizka, M.A.; Maghraby, F.A. Cervical cancer diagnosis using random forest classifier with SMOTE and feature reduction techniques. IEEE Access 2018, 6, 59475–59485. [Google Scholar] [CrossRef]
- Set, Z.-A.S.D. UCI Machine Learning Repository, Center for Machine Learning and Intelligent Systems. 2017. Available online: https://archive.ics.uci.edu/ml/machine-learning-databases/00412/ (accessed on 8 April 2019).
- Alizadehsani, R.; Hosseini, M.J.; Khosravi, A.; Khozeimeh, F.; Roshanzamir, M.; Sarrafzadegan, N.; Nahavandi, S. Non-invasive detection of coronary artery disease in high-risk patients based on the stenosis prediction of separate coronary arteries. Comput. Methods Programs Biomed. 2018, 162, 119–127. [Google Scholar] [CrossRef]
- Alizadehsani, R.; Habibi, J.; Hosseini, M.J.; Boghrati, R.; Ghandeharioun, A.; Bahadorian, B.; Sani, Z.A. Diagnosis of coronary artery disease using data mining techniques based on symptoms and ecg features. Eur. J. Sci. Res. 2012, 82, 542–553. [Google Scholar]
- Alizadehsani, R.; Zangooei, M.H.; Hosseini, M.J.; Habibi, J.; Khosravi, A.; Roshanzamir, M.; Khozeimeh, F.; Sarrafzadegan, N.; Nahavandi, S. Coronary artery disease detection using computational intelligence methods. Knowl.-Based Syst. 2016, 109, 187–197. [Google Scholar] [CrossRef]
- Arabasadi, Z.; Alizadehsani, R.; Roshanzamir, M.; Moosaei, H.; Yarifard, A.A. Computer aided decision making for heart disease detection using hybrid neural network-Genetic algorithm. Comput. Methods Programs Biomed. 2017, 141, 19–26. [Google Scholar] [CrossRef]
- Abdar, M.; Książek, W.; Acharya, U.R.; Tan, R.S.; Makarenkov, V.; Pławiak, P. A new machine learning technique for an accurate diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2019, 179, 104992. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. Int. Jt. Conf. Artif. Intell. 1995, 14, 1137–1145. [Google Scholar]
- Haq, A.U.; Li, J.P.; Memon, M.H.; Nazir, S.; Sun, R. A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob. Inf. Syst. 2018, 2018, 3860146. [Google Scholar] [CrossRef]
- Weng, C.-H.; Huang, T.C.-K.; Han, R.-P. Disease prediction with different types of neural network classifiers. Telemat. Inform. 2016, 33, 277–292. [Google Scholar] [CrossRef]
- Dousthagh, M.; Nazari, M.; Mosavi, A.; Shamshirband, S.; Chronopoulos, A.T. Feature weighting using a clustering approach. Int. J. Model. Optim. 2019, 9, 67–71. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2005, 27, 861–874. [Google Scholar] [CrossRef]
- Tan, P.N. Introduction to Data Mining; Pearson Education: New Delhi, India, 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Feature Name | Range | Measurement | |||
|---|---|---|---|---|---|---|
| Mean | Std. Error of Mean | Std. Deviation | Variance | |||
| Demographic | Age | (30–80) | 58.90 | 0.6 | 10.39 | 108 |
| Demographic | Weight | (48–120) | 73.83 | 0.69 | 11.99 | 143.7 |
| Demographic | Length | (140–188) | 164.72 | 0.54 | 9.33 | 87.01 |
| Demographic | Sex | Male, Female | --- | --- | --- | --- |
| Demographic | BMI (body mass index Kb/m2) | (18–41) | 27.25 | 0.24 | 4.1 | 16.8 |
| Demographic | DM (diabetes mellitus) | (0, 1) | 0.3 | 0.03 | 0.46 | 0.21 |
| Demographic | HTN (hypertension) | (0, 1) | 0.6 | 0.03 | 0.49 | 0.24 |
| Demographic | Current smoker | (0, 1) | 0.21 | 0.02 | 0.41 | 0.17 |
| Demographic | Ex-smoker | (0, 1) | 0.03 | 0.01 | 0.18 | 0.03 |
| Demographic | FH (family history) | (0, 1) | 0.16 | 0.02 | 0.37 | 0.13 |
| Demographic | Obesity | Yes if MBI > 25, No otherwise | --- | --- | --- | --- |
| Demographic | CRF (chronic renal failure) | Yes, No | --- | --- | --- | --- |
| Demographic | CVA (cerebrovascular accident) | Yes, No | --- | --- | --- | --- |
| Demographic | Airway disease | Yes, No | --- | --- | --- | --- |
| Demographic | Thyroid disease | Yes, No | --- | --- | --- | --- |
| Demographic | CHF (congestive heart failure) | Yes, No | --- | --- | --- | --- |
| Demographic | DPL (dyslipidemia) | Yes, No | --- | --- | --- | --- |
| Symptom and examination | BP (blood pressure mm Hg) | (90–190) | 129.55 | 1.09 | 18.94 | 358.65 |
| Symptom and examination | PR (pulse rate ppm) | (50–110) | 75.14 | 0.51 | 8.91 | 79.42 |
| Symptom and examination | Edema | (0, 1) | 0.04 | 0.01 | 0.2 | 0.04 |
| Symptom and examination | Weak peripheral pulse | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Lung rates | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Systolic murmur | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Diastolic murmur | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Typical chest pain | (0, 1) | 0.54 | 0.03 | 0.5 | 0.25 |
| Symptom and examination | Dyspnea | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Function class | 1, 2, 3, 4 | 0.66 | 0.06 | 1.03 | 1.07 |
| Symptom and examination | Atypical | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Nonanginal chest pain | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Exertional chest pain | Yes, No | --- | --- | --- | --- |
| Symptom and examination | Low TH Ang (low-threshold angina) | Yes, No | --- | --- | --- | --- |
| ECG | Rhythm | Sin, AF | --- | --- | --- | --- |
| ECG | Q wave | (0, 1) | 0.05 | 0.01 | 0.22 | 0.05 |
| ECG | ST elevation | (0, 1) | 0.05 | 0.01 | 0.21 | 0.04 |
| ECG | ST depression | (0, 1) | 0.23 | 0.02 | 0.42 | 0.18 |
| ECG | T inversion | (0, 1) | 0.3 | 0.03 | 0.46 | 0.21 |
| ECG | LVH (left ventricular hypertrophy) | Yes, No | --- | --- | --- | --- |
| ECG | Poor R-wave progression | Yes, No | --- | --- | --- | --- |
| Laboratory and echo | FBS (fasting blood sugar mg/dL) | (62–400) | 119.18 | 2.99 | 52.08 | 2712.29 |
| Laboratory and echo | Cr (creatine mg/dL) | (0.5–2.2) | 1.06 | 0.02 | 0.26 | 0.07 |
| Laboratory and echo | TG (triglyceride mg/dL) | (37–1050) | 150.34 | 5.63 | 97.96 | 9596.05 |
| Laboratory and echo | LDL (low-density lipoprotein mg/dL) | (18–232) | 104.64 | 2.03 | 35.4 | 1252.93 |
| Laboratory and echo | HDL (high-density lipoprotein mg/dL) | (15–111) | 40.23 | 0.61 | 10.56 | 111.49 |
| Laboratory and echo | BUN (blood urea nitrogen mg/dL) | (6–52) | 17.5 | 0.4 | 6.96 | 48.4 |
| Laboratory and echo | ESR (erythrocyte sedimentation rate mm/h) | (1–90) | 19.46 | 0.92 | 15.94 | 253.97 |
| Laboratory and echo | HB (hemoglobin g/dL) | (8.9–17.6) | 13.15 | 0.09 | 1.61 | 2.59 |
| Laboratory and echo | K (potassium mEq/lit) | (3.0–6.6) | 4.23 | 0.03 | 0.46 | 0.21 |
| Laboratory and echo | Na (sodium mEq/lit) | (128–156) | 141 | 0.22 | 3.81 | 14.5 |
| Laboratory and echo | WBC (white blood cell cells/mL) | (3700–18.000) | 7562.05 | 138.67 | 2413.74 | 5,826,137.52 |
| Laboratory and echo | Lymph (lymphocyte %) | (7–60) | 32.4 | 0.57 | 9.97 | 99.45 |
| Laboratory and echo | Neut (neutrophil %) | (32–89) | 60.15 | 0.59 | 10.18 | 103.68 |
| Laboratory and echo | PLT (platelet 1000/mL) | (25–742) | 221.49 | 3.49 | 60.8 | 3696.18 |
| Laboratory and echo | EF (ejection fraction %) | (15–60) | 47.23 | 0.51 | 8.93 | 79.7 |
| Laboratory and echo | Region with RWMA | (0–4) | 0.62 | 0.07 | 1.13 | 1.28 |
| Laboratory and echo | VHD (valvular heart disease) | Normal, Mild, Moderate, Severe | --- | --- | --- | --- |
| Categorical | Target class: Cath | CAD, Normal | --- | --- | --- | --- |
| The Actual Class | The Predicted Class | |
|---|---|---|
| Disease (CAD) | Healthy (Normal) | |
| Positive | True Positive | False Positive |
| Negative | False Negative | True Negative |
| No. | Feature | Predictor Significance |
|---|---|---|
| 1 | Typical chest pain | 0.98 |
| 2 | TG | 0.66 |
| 3 | BMI | 0.63 |
| 4 | Age | 0.58 |
| 5 | Weight | 0.54 |
| 6 | BP | 0.51 |
| 7 | K | 0.48 |
| 8 | FBS | 0.43 |
| 9 | Length | 0.37 |
| 10 | BUN | 0.3 |
| 11 | PR | 0.29 |
| 12 | HB | 0.26 |
| 13 | Function class | 0.25 |
| 14 | Neut | 0.25 |
| 15 | EF-TTE | 0.25 |
| 16 | WBC | 0.24 |
| 17 | DM | 0.23 |
| 18 | PLT | 0.2 |
| 19 | Atypical | 0.19 |
| 20 | FH | 0.18 |
| 21 | HDL | 0.16 |
| 22 | ESR | 0.16 |
| 23 | CR | 0.14 |
| 24 | LDL | 0.14 |
| 25 | T inversion | 0.13 |
| 26 | DLP | 0.13 |
| 27 | Region RWMA | 0.12 |
| 28 | HTN | 0.11 |
| 29 | Obesity | 0.1 |
| 30 | Systolic murmur | 0.09 |
| 31 | Sex | 0.09 |
| 32 | Dyspnea | 0.08 |
| 33 | Current smoker | 0.06 |
| 34 | BBB | 0.05 |
| 35 | LVH | 0.03 |
| 36 | Edema | 0.02 |
| 37 | Ex-smoker | 0.02 |
| 38 | VHD | 0.01 |
| 39 | St depression | 0.01 |
| 40 | Lymph | 0.0 |
| No. | Feature | Predictor Significance |
|---|---|---|
| 1 | Typical chest pain | 0.04 |
| 2 | Atypical | 0.03 |
| 3 | Sex | 0.02 |
| 4 | Obesity | 0.02 |
| 5 | FH | 0.02 |
| 6 | Age | 0.02 |
| 7 | DM | 0.02 |
| 8 | Dyspnea | 0.02 |
| 9 | Systolic murmur | 0.02 |
| 10 | St depression | 0.02 |
| 11 | HTN | 0.02 |
| 12 | LDL | 0.02 |
| 13 | Current smoker | 0.02 |
| 14 | DLP | 0.02 |
| 15 | BP | 0.02 |
| 16 | LVH | 0.02 |
| 17 | Nonanginal | 0.02 |
| 18 | Tin version | 0.02 |
| 19 | Length | 0.02 |
| 20 | Function class | 0.02 |
| 21 | BBB | 0.02 |
| 22 | VHD | 0.02 |
| 23 | CHF | 0.02 |
| 24 | PR | 0.02 |
| 25 | WBC | 0.02 |
| 26 | BUN | 0.02 |
| 27 | FBS | 0.02 |
| 28 | ESR | 0.02 |
| 29 | CVA | 0.02 |
| 30 | Thyroid disease | 0.02 |
| 31 | Lymph | 0.02 |
| 32 | Weight | 0.02 |
| 33 | CR | 0.02 |
| 34 | Airway disease | 0.02 |
| 35 | TG | 0.02 |
| 36 | CRF | 0.02 |
| 37 | Diastolic murmur | 0.02 |
| 38 | Low TH ang | 0.02 |
| 39 | Exertional CP | 0.02 |
| 40 | Weak peripheral pulse | 0.02 |
| 41 | Neut | 0.02 |
| 42 | PLT | 0.02 |
| 43 | St elevation | 0.02 |
| 44 | EF-TTE | 0.02 |
| 45 | K | 0.02 |
| 46 | BMI | 0.02 |
| 47 | Ex-smoker | 0.02 |
| 48 | Lung rates | 0.02 |
| 49 | HDL | 0.02 |
| 50 | Na | 0.01 |
| 51 | Edema | 0.01 |
| 52 | Q wave | 0.01 |
| 53 | HB | 0.01 |
| 54 | Poor R progression | 0.01 |
| 55 | Region RWMA | 0.01 |
| No. | Feature | Predictor Significance |
|---|---|---|
| 1 | Typical chest pain | 0.28 |
| 2 | CR | 0.14 |
| 3 | ESR | 0.13 |
| 4 | T inversion | 0.1 |
| 5 | Edema | 0.09 |
| 6 | Region RWMA | 0.08 |
| 7 | Poor R progression | 0.04 |
| 8 | Sex | 0.03 |
| 9 | DM | 0.03 |
| 10 | BMI | 0.02 |
| 11 | WBC | 0.02 |
| 12 | DLP | 0.02 |
| 13 | Length | 0.01 |
| 14 | Dyspnea | 0.0 |
| 15 | EF-TTE | 0.0 |
| No. | Feature | Predictor Significance |
|---|---|---|
| 1 | Typical chest pain | 0.33 |
| 2 | Age | 0.15 |
| 3 | T inversion | 0.11 |
| 4 | VHD | 0.1 |
| 5 | DM | 0.09 |
| 6 | HTN | 0.04 |
| 7 | Nonanginal | 0.03 |
| 8 | BP | 0.02 |
| 9 | Region RWMA | 0.02 |
| 10 | HDL | 0.02 |
| Decision Rule | Most Frequent Category | Rule Accuracy | Forest Accuracy | Interestingness Index |
|---|---|---|---|---|
| (BP > 110.0), (FH > 0.0), (Neut > 51.0) and (Typical Chest Pain > 0.0) | CAD | 1.000 | 1.000 | 1.000 |
| (BMI ≤ 29.02), (EF-TTE > 50.0), (CR ≤ 0.9), (Typical Chest Pain > 0.0) and (Atypical = {N}) | CAD | 1.000 | 1.000 | 1.000 |
| (Weight > 8.0), (CR > 0.9), (Typical Chest Pain > 0.0) and (Atypical = {N}) | CAD | 1.000 | 1.000 | 1.000 |
| (K ≤ 4.9), (WBC > 5700.0), (CR < 0.9), | CAD | 1.000 | 1.000 | 1.000 |
| (DM > 0.0) and (Typical Chest Pain > 0.0) | CAD | 1.000 | 1.000 | 1.000 |
| Referense | Methods | No. Features Subset Selection | Accuracy (%) | Auc % | Gini % |
|---|---|---|---|---|---|
| [37] | Naïve Bayes-SMO | 16 | 88.52 | Not reported | Not reported |
| [12] | SMO along with information Gain | 34 | 94.08 | Not reported | Not reported |
| [38] | SVM along with average information gain and also information gain | 24 | 86.14 for LAD 83.17 for LCX 83.50 for RCA | Not reported | Not reported |
| [39] | Neural network-genetic algorithm-weight by SVM | 22 | 93.85 | Not reported | Not reported |
| [36] | SVM along with feature engineering | 32 | 96.40 | 92 | Not reported |
| [40] | N2Genetic-nuSVM | 29 | 93.08 | Not reported | Not reported |
| In our study | Random trees | 40 | 91.47 | 96.70 | 93.40 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joloudari, J.H.; Hassannataj Joloudari, E.; Saadatfar, H.; Ghasemigol, M.; Razavi, S.M.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Nadai, L. Coronary Artery Disease Diagnosis; Ranking the Significant Features Using a Random Trees Model. Int. J. Environ. Res. Public Health 2020, 17, 731. https://doi.org/10.3390/ijerph17030731
Joloudari JH, Hassannataj Joloudari E, Saadatfar H, Ghasemigol M, Razavi SM, Mosavi A, Nabipour N, Shamshirband S, Nadai L. Coronary Artery Disease Diagnosis; Ranking the Significant Features Using a Random Trees Model. International Journal of Environmental Research and Public Health. 2020; 17(3):731. https://doi.org/10.3390/ijerph17030731
Chicago/Turabian StyleJoloudari, Javad Hassannataj, Edris Hassannataj Joloudari, Hamid Saadatfar, Mohammad Ghasemigol, Seyyed Mohammad Razavi, Amir Mosavi, Narjes Nabipour, Shahaboddin Shamshirband, and Laszlo Nadai. 2020. "Coronary Artery Disease Diagnosis; Ranking the Significant Features Using a Random Trees Model" International Journal of Environmental Research and Public Health 17, no. 3: 731. https://doi.org/10.3390/ijerph17030731
APA StyleJoloudari, J. H., Hassannataj Joloudari, E., Saadatfar, H., Ghasemigol, M., Razavi, S. M., Mosavi, A., Nabipour, N., Shamshirband, S., & Nadai, L. (2020). Coronary Artery Disease Diagnosis; Ranking the Significant Features Using a Random Trees Model. International Journal of Environmental Research and Public Health, 17(3), 731. https://doi.org/10.3390/ijerph17030731