Currently popular scientific terms include “big data” and “big spatial data.” Especially when dealing with medical and public health data, one big (spatial) data feature meriting more attention is (geographic) resolution. This feature interfaces with the Law of Large Numbers (LLN), a statistical principle that may be summarized as follows:
Given random sampling, as a sample size, n, goes to infinity, the empirical probability of an event approaches its theoretical probability (given by its probability mass or density function): the distribution of a random sample tends to resemble the distribution for its parent population more closely as n increases.
In other words, certain statistics computed from a sample tend toward their corresponding parameter values as
n increases, which relates the LLN to the Central Limit Theorem (CLT), another fundamental principle of statistics (see [
1]). These two statistical concepts interface with interplay between the notions of big data and of resolution, with the latter sometimes moderating the former. This theme constitutes the topic of this paper.
The phrase big (spatial) data refers to extremely large datasets, with the meaning of “big” remaining ambiguous, and not necessarily referring to amount. Rather, the following selected data properties constitute the differentiating features: volume (i.e., quantity), velocity (i.e., availability speed), variety (i.e., diversity of types), variability (i.e., information content meaning constantly changing), veracity (i.e., degree of reliability/accuracy), and complexity (i.e., structured, semi-structured, quasi-structured, and unstructured). Big data are burdened with the following requisites, which need to be performed efficiently and effectively: analyzing, capturing, privacy preserving, querying, sharing, storing, transferring, updating, and visualizing [
2]. These are the same handling requirements that distinguish between geographic information system datasets and many other types of data [
3] (p. 1), furnishing a strong link between the notions of “big data” and “big spatial data.” Cressie et al. [
4] (p. 115) note that “… the sheer size of a massive [dataset] may challenge and, ultimately, defeat a statistical methodology that was designed for smaller [datasets] …” One such failure is statistical significance testing: with a large enough dataset, virtually all results are statistically significant. Conversely, with a small enough dataset, virtually no results are statistically significant (i.e., small sample sizes undercut the trustworthiness of statistical inferences, with a sample size of one, in and of itself, unable to furnish any information about the precision of its sample statistic; see [
5]). Another stems from such data almost always being non-random, such that without adequate data analytic precautions, resulting correlations can be spurious, predictions can be erroneous, and results can be unsatisfactory.
With these aforementioned caveats in mind, the purpose of this paper is to establish some deeper insights into big spatial data, with special reference to public health data, in terms of their uncertainty through one of the hallmarks of georeferenced data, namely spatial autocorrelation (SA), coupled with small geographic areas (re. resolution). A focal point is the intersection of SA with the issue of instability of estimates in small sample sizes, and/or over small geographic areas in the presence of what appears to be big spatial data. Impacts of interest concern the nature, degree, and mixture of SA. Big data analyses focus on hypothesis generation rather than hypothesis testing [
6], and hence one important theme for big spatial data is relationship stability, especially with regard to heterogeneity, across geography (as well as time). Accordingly, this paper studies six Florida metropolitan statistical areas (MSAs) to address this geographic stability aspect. Meanwhile, big healthcare data (increasingly acquired from electronic health records) are not only complex, but also have unique characteristics, beyond their large size (which often is relative to the usually unavoidable extremely small clinical trial sample sizes; [
7]), that both facilitate and complicate the uncovering of insights about an observable public health phenomenon. To this end, this paper studies selected cancer cases for the period 2001–2010. Its aim is to identify and assess geographical patterns within the context of SA to establish a better understanding of small geographic area data uncertainty [i.e., the instability of small sample size (à la the CLT) and/or small geographic area estimates].
1.1. A Motivating Example: The Role of Resolution
Geocoding of individuals allows for their post-stratification by areal units such as ZIP codes and census blocks, block groups, and tracts, these latter three polygon types being devised by the United States (US) Census Bureau [
8]. These units constitute small areas. Aggregated socio-economic/demographic attribute data often are available for these geographic polygons, enabling data merging for observational studies involving ecological correlation analysis. This data analytic framework often suffers from post-stratification defects, especially when it yields small geographic area sample sizes. Spielman et al. [
9], after studying US census data uncertainty causes, show that these data tend to have higher margins of error for smaller geographic areal units. In other words, resolution matters.
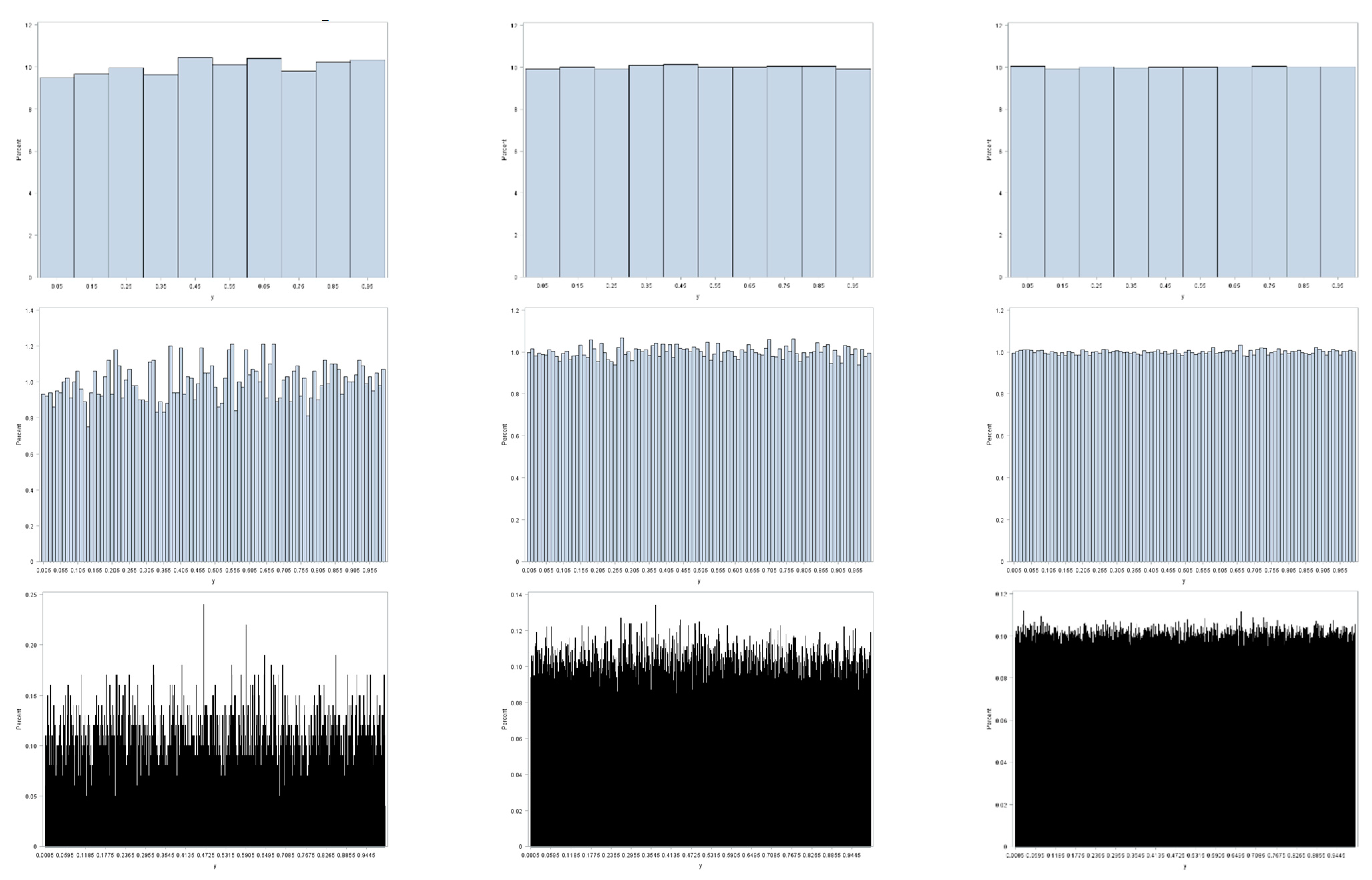
Figure 1 illustrates this preceding contention, furnishing an appropriate example here, because binning of observed values to construct histograms parallels the geographic aggregation of geocoded points into areal unit polygons. This illustration employs three random sample sizes: 10
4, 10
5, and 10
6. It also employs three resolutions (i.e., bin sizes): 0.1, 0.01, and 0.001. Sampling is from a uniform distribution; the LLN implies that as
n increases these histograms should converge on their parent theoretical uniform frequency distribution for the interval [0, 1]. All three coarser resolutions display little deviation from a uniform distribution, with this deviation decreasing with increasing sample size. As resolution becomes finer, the
n = 10
4 sample size fails to display a close correspondence with its parent uniform distribution: the moderate resolution has noticeable variation, and the fine resolution has conspicuous variation in bin frequencies. These deviations dampen out as
n increases to 10
5, and then to 10
6. However, if the bin size were decreased to 0.0001 for the
n = 10
6 sample size, then it, too, would exhibit obvious deviations from a uniform distribution. One principal implication is that small area resolution, both geographic and non-geographic, plays a critical role in determining the meaning of the notion of big data, particularly with regard to its volume and variability properties.
1.2. Effective Geographic Sample Size: A Complicating Factor
One of the complexities of spatial data arises from their being correlated data containing redundant or duplicate information (i.e., they are spatially autocorrelated; [
10]). The SA latent in most geographically distributed socio-economic/demographic data is positive, and roughly ranges from 0.4 to 0.6 for provincial/state, county, and census tract resolutions across national and regional geographic landscapes studied to date. The SA latent in most remotely sensed images also is positive, and roughly ranges from 0.9 to 0.99, certainly for a 30 m-by-30 m pixel size (e.g., Landsat images). The effective geographic sample size for
n areal units is the number,
n*, of equivalent independent and identically distributed observations based upon the nonredundant information content in a given dataset [
11,
12,
13,
14,
15];
n*, like degrees of freedom, may not be an integer.
Table 1 furnishes examples of
n and
n* that have been gleaned from the literature. The calculation of
n* is somewhat sensitive to the assumed spatial statistical model. Nevertheless, even with moderate positive SA (PSA), substantial reductions in effective sample size occur. Reductions for remotely sensed images potentially could decrease from an extremely large
n to an
n* < 30.
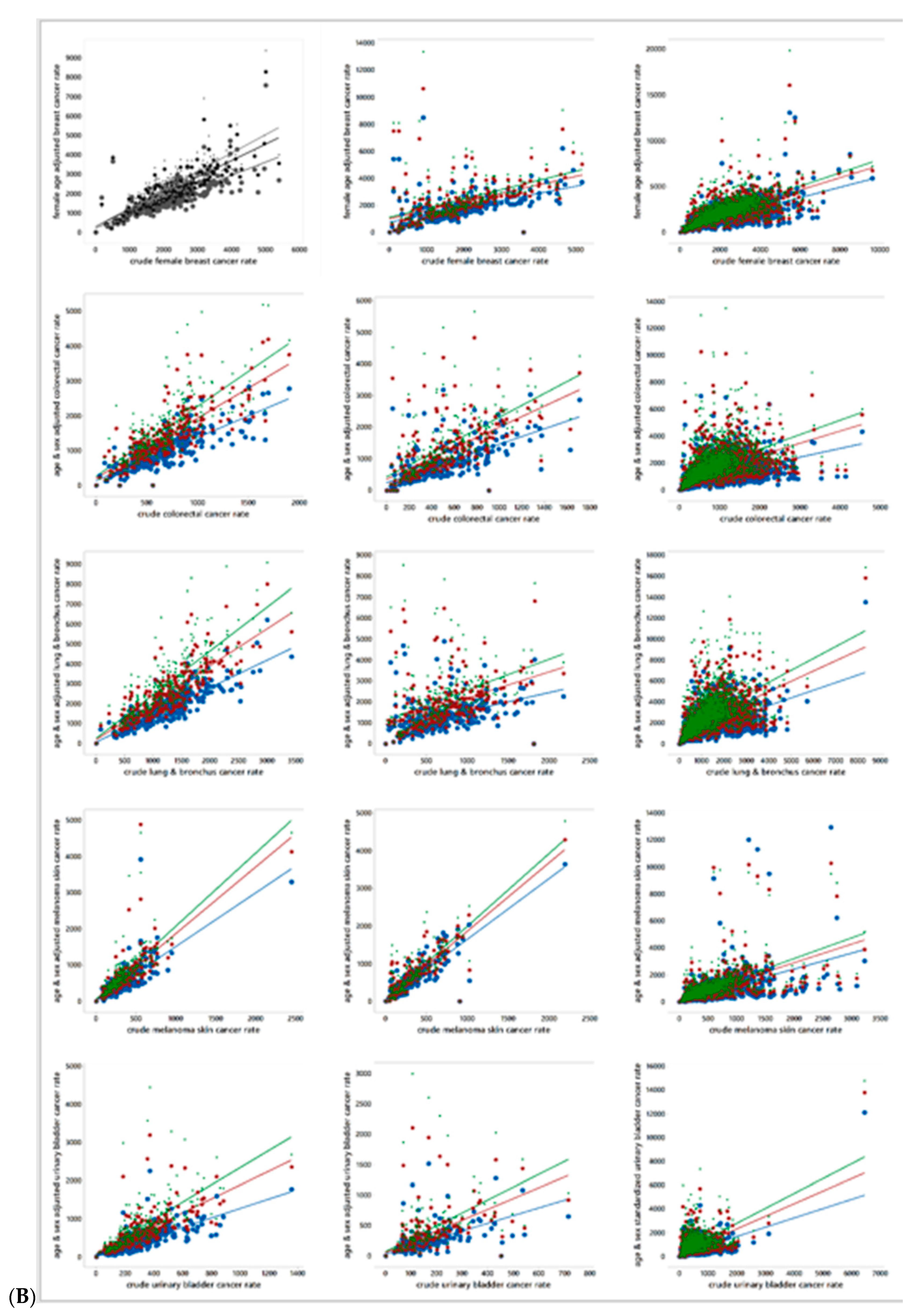
1.3. The Florida Cancer Dataset
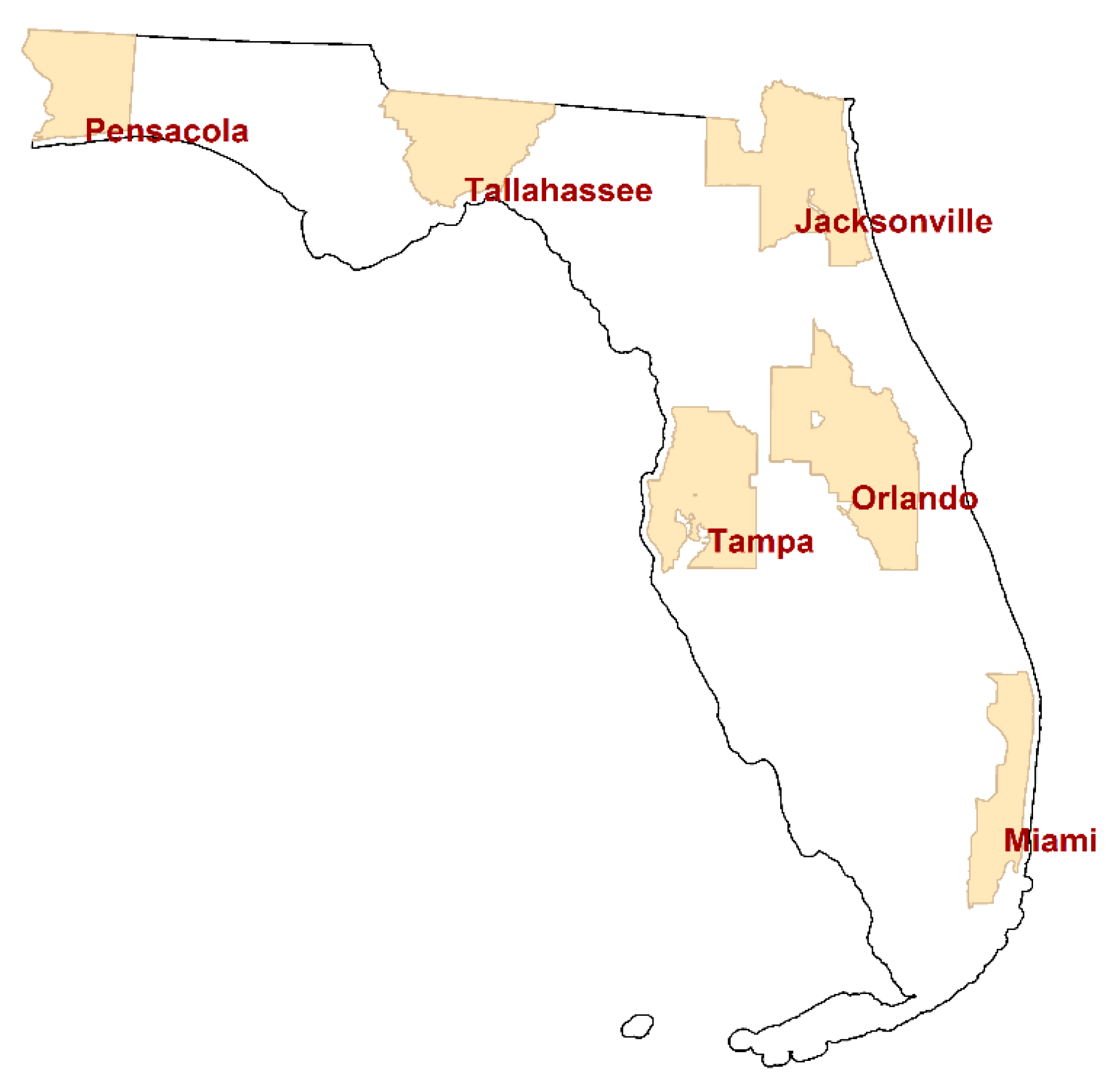
This paper summarizes analyses of individual cancer cases located in the following six Florida MSAs: Jacksonville, Miami, Orlando, Pensacola, Tallahassee, and Tampa.
Figure 2 portrays the location of these MSAs, which furnish a wide geographic coverage of the state. This study utilizes six different cancer types that have a relatively large number of cases: breast, female breast, colorectal, lung & bronchus, melanoma skin, and urinary bladder. The other counties have relatively small numbers of cancer cases, so that a considerable number of small areal units in the counties (e.g., census block groups) have zero cases even for these more common cancer types. Hence, this study focuses on the six counties.
Individual cancer patient data in Florida from 2001 to 2010 were obtained from the Florida Cancer Registry of the Florida Department of Health and then analyzed (with rigorous University of Texas at Dallas and Florida Department of Health Institutional Review Board monitoring and approval). This dataset contains limited individual patient demographic characteristics, such as age and gender, as well as residential locations in the form of geocoded x, y coordinates. These data includ no information that can reveal patient identities. Cancer patient points that were inadequately geocoded using home address matching were removed from the dataset as part of its data cleaning (The Florida Department of Health contracts address matched to a private vendor that uses proprietary geocoding software. Authors’ data cleaning resulted in a dataset with a geocoding success rate of roughly 90%). These points were geocoded either to a ZIP code centroid with a partial address (i.e., ZIP code only), or were assigned to areal units that have zero population in both the 2000 and 2010 US decennial census reports. Duplicate registry entries were also removed. After this data cleaning exercise, 9,444,852 records remained for use in this study.
Table 2 presents the number of cancer cases from this reduced set of records for the six cancer types in the individual MSAs.
Geographically aggregated cancer cases were converted to rates per 100,000 population, in part, to adjust for the varying sizes of the areal units (i.e., census block groups). Other analyses of these data include articles by Hu et al. [
17,
18] and Lee et al. [
19,
20], which furnish additional details about these data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}