
Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining

 ,
,  ,
, 
 and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Scientometrics and Text Mining
2.2. Software
2.3. Indicators
2.3.1. Production and Chronology
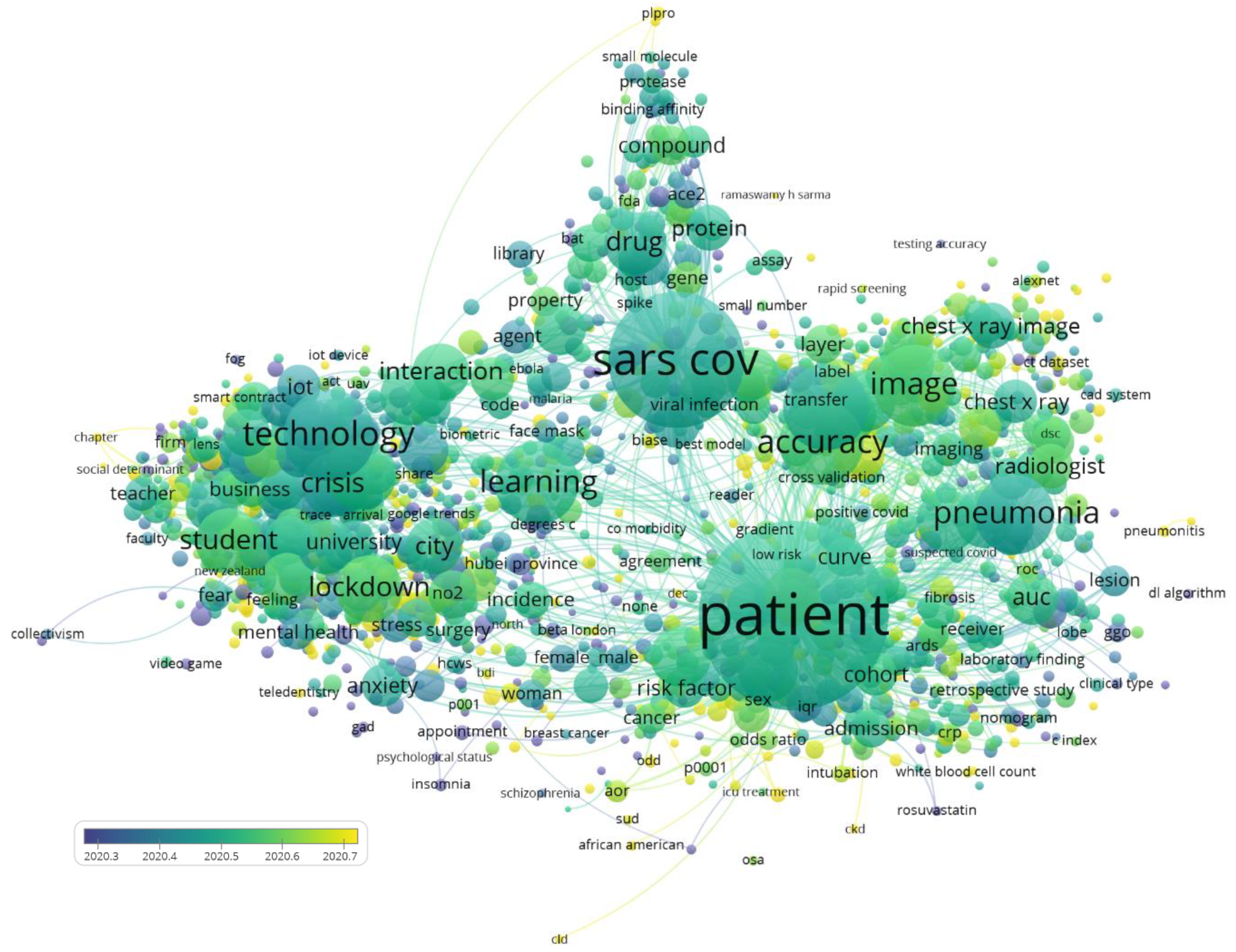
2.3.2. Topics Analysis
2.3.3. Citation and High Cited Elements
2.3.4. Co-Citation Analysis
2.3.5. Overlay Visualization
2.4. Data Acquisition
2.4.1. Sources of Data
2.4.2. Collected Data
3. Results and Discussion
3.1. Production and Chronology Analysis
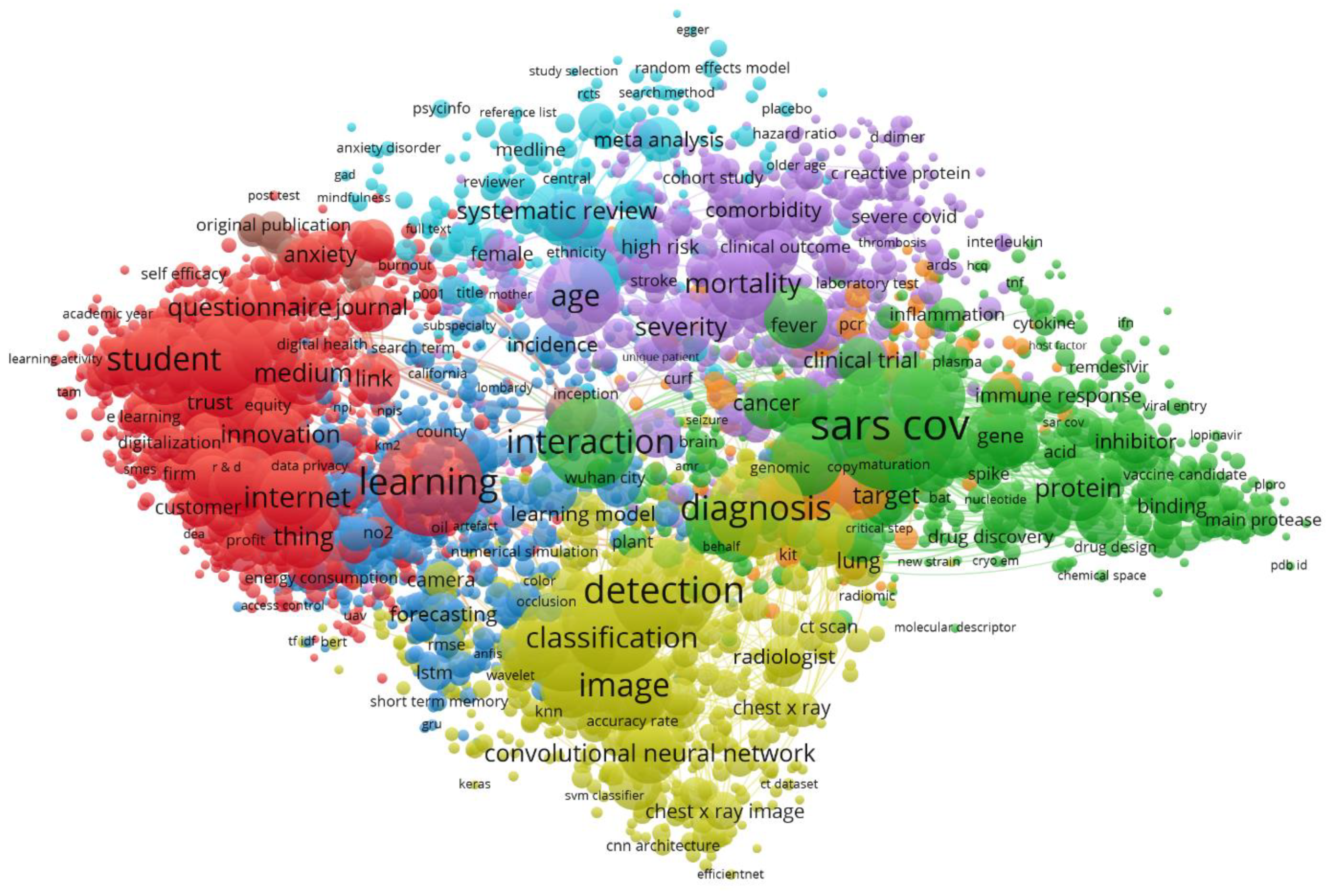
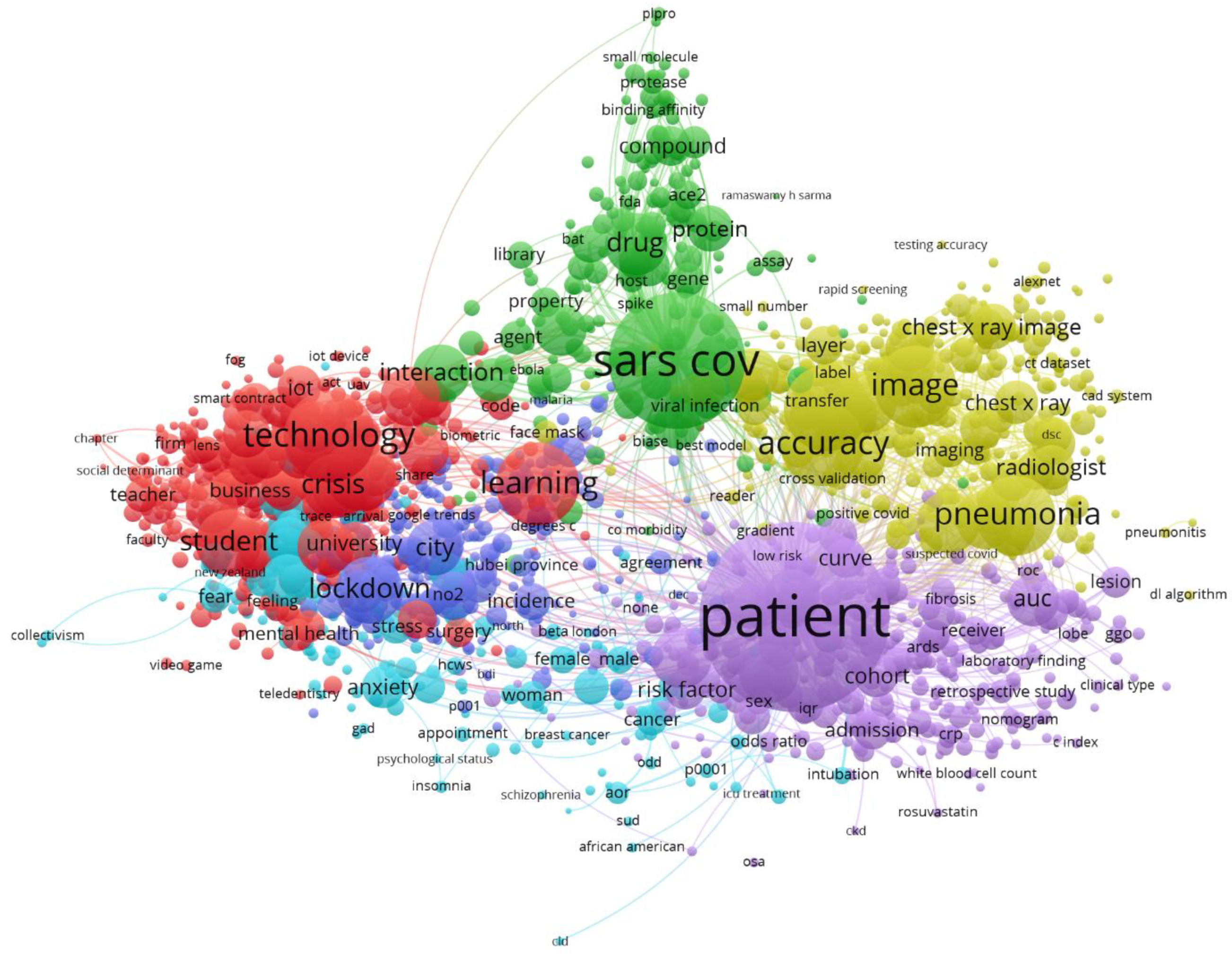
3.2. Topic Analysis
3.2.1. Technology Applied to Adaptations of Different Sectors of Activity of Society to the Pandemic (Red Cluster)
3.2.2. Artificial Intelligence Applied to Large-Scale COVID-19 Management Public Policies (Dark Blue Cluster)
3.2.3. Data Analysis Applied to Psychosocial Issues and COVID-19 Pandemic (Light Blue Cluster)
3.2.4. Drug Repurposing and Vaccines (Green Cluster)
3.2.5. Diagnosis and AI-Aided Tests (Yellow Cluster)
3.2.6. Disease Progression (Violet Cluster)
3.2.7. Equivalences with WoS Source
3.3. Topics Variation along Time
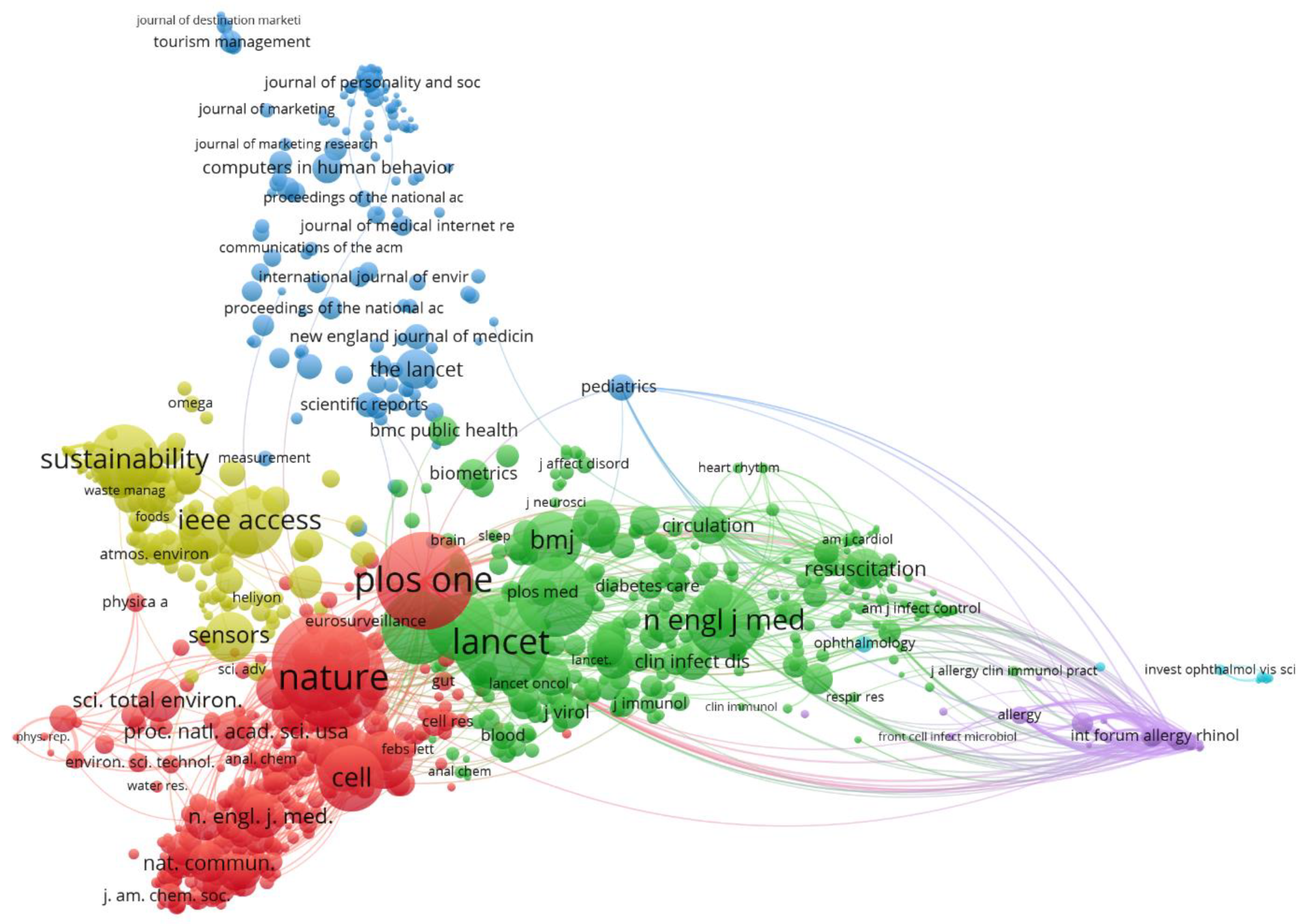
3.4. Citations and Highly Cited Elements
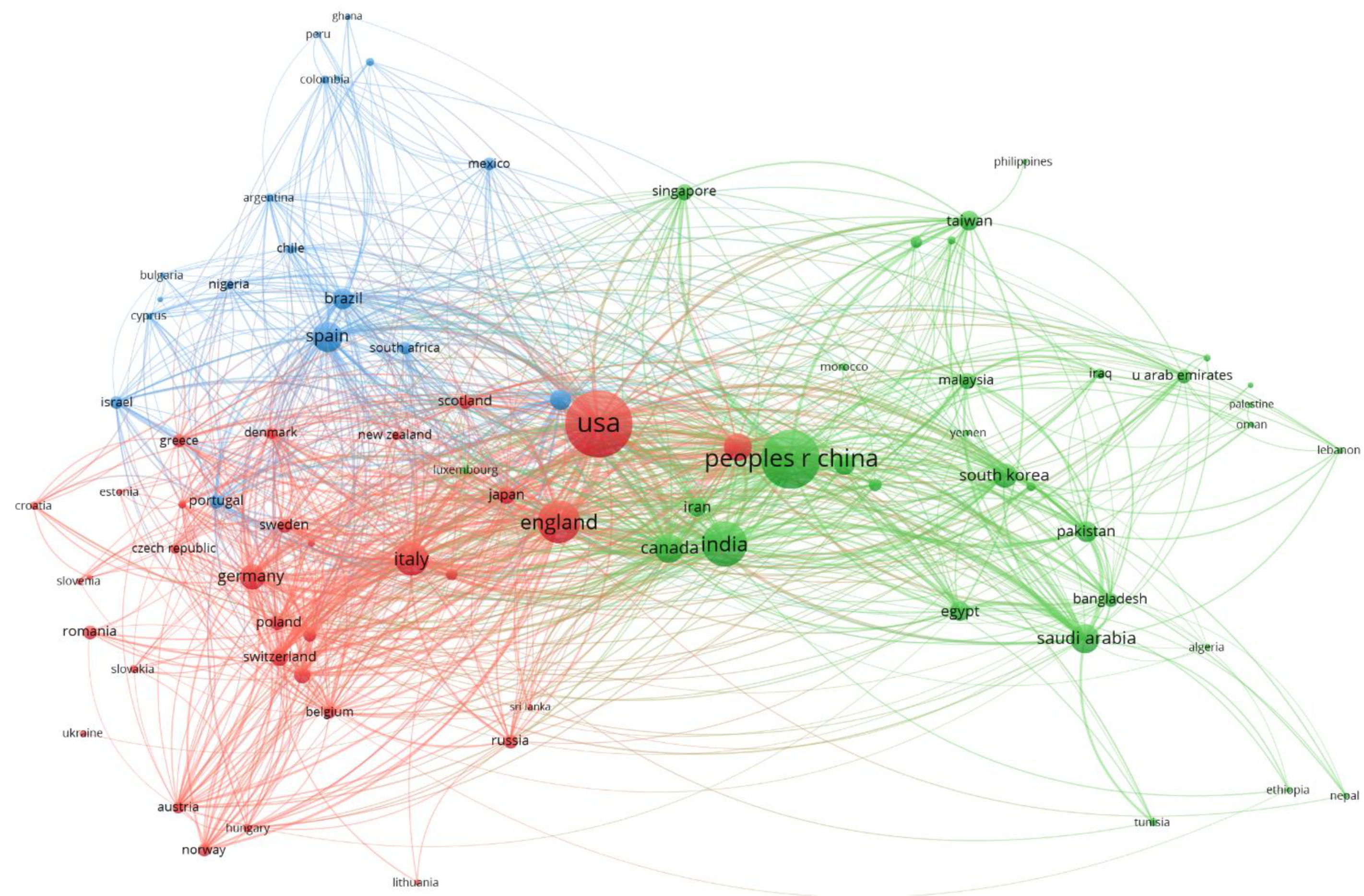
3.4.1. Citation by Source
3.4.2. Citation by Number of Papers
3.5. Co-Citation Analysis
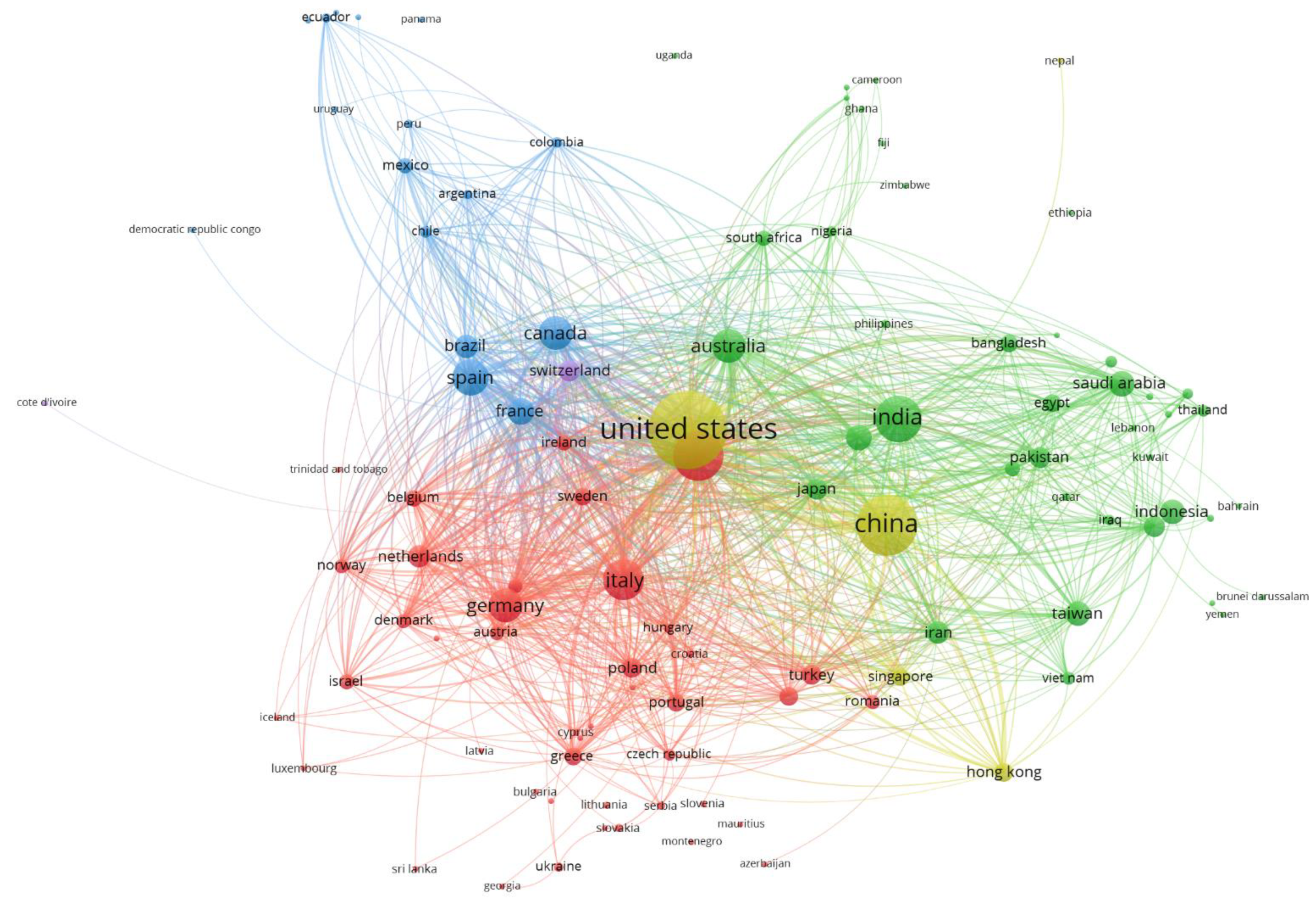
3.5.1. Co-Citation by Source
3.5.2. Co-Citations by Author
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgemnts
Conflicts of Interest
References
- Ting, D.S.W.; Carin, L.; Dzau, V.; Wong, T.Y. Digital technology and COVID-19. Nat. Med. 2020, 26, 459–461. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Rodríguez, I.; Zamora-Izquierdo, M.Á.; Rodríguez, J.V. Towards an ICT-based platform for type 1 diabetes mellitus management. Appl. Sci. 2018, 8, 511. [Google Scholar] [CrossRef] [Green Version]
- Calton, B.; Abedini, N.; Fratkin, M. Telemedicine in the time of coronavirus. J. Pain Symptom Manag. 2020, 60, e12–e14. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Zamora-Izquierdo, M.Á. Variables to be monitored via biomedical sensors for complete type 1 diabetes mellitus management: An extension of the “on-board” concept. J. Diabetes Res. 2018, 2018, 4826984. [Google Scholar] [CrossRef]
- Alladi, T.; Chamola, V.; Rodrigues, J.J.; Kozlov, S.A. Blockchain in smart grids: A review on different use cases. Sensors 2019, 19, 4862. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernández-Ramos, J.L.; Karopoulos, G.; Geneiatakis, D.; Martin, T.; Kambourakis, G.; Fovino, I.N. Sharing pandemic vaccination certificates through blockchain: Case study and performance evaluation. arXiv 2021, arXiv:2101.04575. [Google Scholar]
- Fusco, A.; Dicuonzo, G.; Dell’Atti, V.; Tatullo, M. Blockchain in healthcare: Insights on COVID-19. Int. J. Environ. Res. Public Health 2020, 17, 7167. [Google Scholar] [CrossRef]
- Martin, T.; Karopoulos, G.; Hernández-Ramos, J.L.; Kambourakis, G.; Nai Fovino, I. Demystifying COVID-19 digital contact tracing: A survey on frameworks and mobile apps. Wirel. Commun. Mob. Comput. 2020, 2020, 8851429. [Google Scholar] [CrossRef]
- Ahmed, N.; Michelin, R.A.; Xue, W.; Ruj, S.; Malaney, R.; Kanhere, S.S.; Jha, S.K. A survey of COVID-19 contact tracing apps. IEEE Access 2020, 8, 134577–134601. [Google Scholar] [CrossRef]
- Chamola, V.; Hassija, V.; Gupta, V.; Guizani, M. A comprehensive review of the COVID-19 pandemic and the role of IoT, drones, AI, blockchain, and 5G in managing its impact. IEEE Access 2020, 8, 90225–90265. [Google Scholar] [CrossRef]
- Pham, Q.V.; Fang, F.; Ha, V.N.; Piran, M.J.; Le, M.; Le, L.B.; Ding, Z. A survey of multi-access edge computing in 5G and beyond: Fundamentals, technology integration, and state-of-the-art. IEEE Access 2020, 8, 116974–117017. [Google Scholar] [CrossRef]
- Siriwardhana, Y.; Gür, G.; Ylianttila, M.; Liyanage, M. The role of 5G for digital healthcare against COVID-19 pandemic: Opportunities and challenges. ICT Express 2021, 7, 244–252. [Google Scholar] [CrossRef]
- Latif, S.; Usman, M.; Manzoor, S.; Iqbal, W.; Qadir, J.; Tyson, G.; Crowcroft, J. Leveraging data science to combat covid-19: A comprehensive review. IEEE Trans. Artif. Intell. 2020, 1, 85–103. [Google Scholar] [CrossRef]
- Colavizza, G.; Costas, R.; Traag, V.A.; van Eck, N.J.; van Leeuwen, T.; Waltman, L. A scientometric overview of CORD-19. PLoS ONE 2021, 16, e0244839. [Google Scholar] [CrossRef] [PubMed]
- Duan, D.; Xia, Q. Evolution of Scientific Collaboration on COVID-19: A Bibliometric Analysis; Learned Publishing: Hoboken, NJ, USA, 2021; pp. 429–441. [Google Scholar]
- Haghani, M.; Varamini, P. Temporal evolution, most influential studies and sleeping beauties of the coronavirus literature. Scientometrics 2021, 126, 1–46. [Google Scholar] [CrossRef]
- Hossain, M.M. Current status of global research on novel coronavirus disease (Covid-19): A bibliometric analysis and knowledge mapping. F1000Research 2020, 9, 374. [Google Scholar] [CrossRef]
- Pal, J.K. Visualizing the knowledge outburst in global research on COVID-19. Scientometrics 2021, 126, 4173–4193. [Google Scholar] [CrossRef]
- Chellappandi, P.; Vijayakumar, C.S. Bibliometrics, Scientometrics, Webometrics/Cybermetrics, Informetrics and Altmetrics–An Emerging Field in Library and Information Science Research. Shanlax Int. J. Educ. 2018, 7, 5–8. [Google Scholar]
- Broadus, R.N. Toward a definition of “bibliometrics”. Scientometrics 1987, 12, 373–379. [Google Scholar] [CrossRef]
- Thongpapanl, N.T. The changing landscape of technology and innovation management: An updated ranking of journals in the field. Technovation 2012, 32, 257–271. [Google Scholar] [CrossRef]
- Song, M.; Ding, Y. Topic modeling: Measuring scholarly impact using a topical lens. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 235–257. [Google Scholar]
- Podsakoff, P.M.; MacKenzie, S.B.; Podsakoff, N.P.; Bachrach, D.G. Scholarly influence in the field of management: A bibliometric analysis of the determinants of university and author impact in the management literature in the past quarter century. J. Manag. 2008, 34, 641–720. [Google Scholar] [CrossRef] [Green Version]
- Van Eck, N.J.; Waltman, L. Visualizing bibliometric networks. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 285–320. [Google Scholar]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Kessler, M.M. Bibliographic coupling between scientific papers. Am. Doc. 1963, 14, 10–25. [Google Scholar] [CrossRef]
- Small, H. Co-citation in the scientific literature: A new measure of the relationship between two documents. J. Am. Soc. Inf. Sci. 1973, 24, 265–269. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. VOS: A new method for visualizing similarities between objects. In Advances in Data Analysis; Springer: Berlin/Heidelberg, Germany, 2007; pp. 299–306. [Google Scholar]
- Yan, E.; Ding, Y.; Jacob, E.K. Overlaying communities and topics: An analysis on publication networks. Scientometrics 2012, 90, 499–513. [Google Scholar] [CrossRef] [Green Version]
- Van Eck, N.; Waltman, L.; Noyons, E.; Buter, R. Automatic term identification for bibliometric mapping. Scientometrics 2010, 82, 581–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, X.; Lai, W. Clustering graphs for visualization via node similarities. J. Vis. Lang. Comput. 2006, 17, 225–253. [Google Scholar] [CrossRef]
- Boyack, K.W.; Klavans, R. Co-citation analysis, bibliographic coupling, and direct citation: Which citation approach represents the research front most accurately? J. Am. Soc. Inf. Sci. Technol. 2010, 61, 2389–2404. [Google Scholar] [CrossRef]
- Waltman, L.; Van Eck, N.J. A new methodology for constructing a publication-level classification system of science. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 2378–2392. [Google Scholar] [CrossRef] [Green Version]
- Leydesdorff, L.; Bornmann, L. Mapping (USPTO) patent data using overlays to Google Maps. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1442–1458. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Liu, W. A Tale of Two Databases: The Use of Web of Science and Scopus in Academic Papers. Scientometrics 2020, 123, 321–335. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Rollins, J.; Yan, E. Web of Science use in published research and review papers 1997–2017: A selective, dynamic, cross-domain, content-based analysis. Scientometrics 2018, 115, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Harzing, A.W.; Alakangas, S. Google Scholar, Scopus and the Web of Science: A longitudinal and cross-disciplinary comparison. Scientometrics 2016, 106, 787–804. [Google Scholar] [CrossRef]
- Ahmad, M.; Batcha, M.S. Mapping of Publications Productivity on Journal of Documentation 1989–2018: A Study Based on Clarivate Analytics–Web of Science Database. Libr. Philos. Pract. 2019, 2213, 1–14. [Google Scholar]
- Baas, J.; Schotten, M.; Plume, A.; Côté, G.; Karimi, R. Scopus as a curated, high-quality bibliometric data source for academic research in quantitative science studies. Quant. Sci. Stud. 2020, 1, 377–386. [Google Scholar] [CrossRef]
- Valderrama-Zurián, J.C.; Aguilar-Moya, R.; Melero-Fuentes, D.; Aleixandre-Benavent, R. A systematic analysis of duplicate records in Scopus. J. Informetr. 2015, 9, 570–576. [Google Scholar] [CrossRef] [Green Version]
- Halevi, G.; Moed, H.; Bar-Ilan, J. Suitability of Google Scholar as a source of scientific information and as a source of data for scientific evaluation—Review of the literature. J. Informetr. 2017, 11, 823–834. [Google Scholar] [CrossRef]
- Orduña Malea, E.; Martín-Martín, A.; Delgado-López-Cózar, E. Google Scholar as a source for scholarly evaluation: A bibliographic review of database errors. Rev. Esp. Doc. Cient. 2017, 40, 1–33. [Google Scholar]
- Visser, M.; van Eck, N.J.; Waltman, L. Large-scale comparison of bibliographic data sources: Scopus, Web of Science, Dimensions, Crossref, and Microsoft Academic. Quant. Sci. Stud. 2021, 2, 20–41. [Google Scholar] [CrossRef]
- Wouters, P.; Thelwall, M.; Kousha, K.; Waltman, L.; de Rijcke, S.; Rushforth, A.; Wouters, P. The Metric Tide: Literature Review, Supplementary Report I to the Independent Review of the Role of Metrics in Research Assessment and Management; HEFCE: London, UK, 2015. [Google Scholar]
- Mongeon, P.; Paul-Hus, A. The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics 2016, 106, 213–228. [Google Scholar] [CrossRef]
- Aksnes, D.W.; Sivertsen, G. A criteria-based assessment of the coverage of Scopus and Web of Science. J. Data Inf. Sci. 2019, 4, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Shnurenko, I.; Murovana, T.; Kushchu, I. Artificial Intelligence; UNESCO Institute for Information Technologies: Paris, France, 2020. [Google Scholar]
- Vafea, M.T.; Atalla, E.; Georgakas, J.; Shehadeh, F.; Mylona, E.K.; Kalligeros, M.; Mylonakis, E. Emerging technologies for use in the study, diagnosis, and treatment of patients with COVID-19. Cell. Mol. Bioeng. 2020, 13, 249–257. [Google Scholar] [CrossRef]
- Qadri, Y.A.; Nauman, A.; Zikria, Y.B.; Vasilakos, A.V.; Kim, S.W. The future of healthcare internet of things: A survey of emerging technologies. IEEE Commun. Surv. Tutor. 2020, 22, 1121–1167. [Google Scholar] [CrossRef]
- Bonaccorso, G. Machine Learning Algorithms: Popular Algorithms for Data Science and Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- WorldBank. World Bank Group. Gross Domestic Product 2021. Available online: www.worldbank.org/indicator/NY.GDP.MKTP.CD (accessed on 15 June 2021).
- WorldBank. World Bank Group. Country Income Classifications. Available online: https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups/ (accessed on 15 June 2021).
- Van Eck, N.J.; Waltman, L. Text mining and visualization using VOSviewer. arXiv 2011, arXiv:1109.2058. [Google Scholar]
- Gallacher, G.; Hossain, I. Remote work and employment dynamics under COVID-19: Evidence from Canada. Can. Public Policy 2020, 46, S44–S54. [Google Scholar] [CrossRef]
- Leonardi, P.M. COVID-19 and the new technologies of organizing: Digital exhaust, digital footprints, and artificial intelligence in the wake of remote work. J. Manag. Stud. 2020, 12648, Epub ahead of print. [Google Scholar] [CrossRef]
- Dannenberg, P.; Fuchs, M.; Riedler, T.; Wiedemann, C. Digital transition by COVID-19 pandemic? The German food online retail. Tijdschr. Voor Econ. En Soc. Geogr. 2020, 111, 543–560. [Google Scholar] [CrossRef]
- Håkansson, A. Impact of COVID-19 on online gambling–a general population survey during the pandemic. Front. Psychol. 2020, 11, 2588. [Google Scholar] [CrossRef]
- Hoekstra, J.C.; Leeflang, P.S. Marketing in the era of COVID-19. Ital. J. Mark. 2020, 2020, 249–260. [Google Scholar] [CrossRef]
- Arechar, A.A.; Rand, D.G. Turking in the time of COVID. Behav. Res. Methods 2021, 1–5. [Google Scholar] [CrossRef]
- Raza, K. Artificial intelligence against COVID-19: A meta-analysis of current research. In Big Data Analytics and Artificial Intelligence Against COVID-19: Innovation Vision and Approach; Springer: Berlin/Heidelberg, Germany, 2020; pp. 165–176. [Google Scholar]
- Wang, M.; Zeng, Q.; Chen, W.; Pan, J.; Wu, H.; Sudlow, C.; Robertson, D. Building the Knowledge Graph for UK Health Data Science. 2021. Available online: https://era.ed.ac.uk/handle/1842/36684 (accessed on 25 June 2021).
- Sawyer, J. Wearable Internet of Medical Things Sensor Devices 2020, Artificial Intelligence-driven Smart Healthcare Services, and Personalized Clinical Care in COVID-19 Telemedicine. Am. J. Med. Res. 2020, 7, 71–77. [Google Scholar]
- Rizk-Allah, R.M.; Hassanien, A.E. COVID-19 forecasting based on an improved interior search algorithm and multi-layer feed forward neural network. arXiv 2020, arXiv:2004.05960. [Google Scholar]
- Huang, C.J.; Chen, Y.H.; Ma, Y.; Kuo, P.H. Multiple-input deep convolutional neural network model for covid-19 forecasting in china. MedRxiv 2020. [Google Scholar] [CrossRef]
- Gupta, R.; Pal, S.K. Trend Analysis and Forecasting of COVID-19 outbreak in India. MedRxiv 2020. medRxiv:2020.03.26.20044511. [Google Scholar] [CrossRef] [Green Version]
- Singh, V.; Poonia, R.C.; Kumar, S.; Dass, P.; Agarwal, P.; Bhatnagar, V.; Raja, L. Prediction of COVID-19 corona virus pandemic based on time series data using Support Vector Machine. J. Discret. Math. Sci. Cryptogr. 2020, 23, 1583–1597. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, I.; Chatzigiannakis, I.; Rodríguez, J.V.; Maranghi, M.; Gentili, M.; Zamora-Izquierdo, M.Á. Utility of big data in predicting short-term blood glucose levels in type 1 diabetes mellitus through machine learning techniques. Sensors 2019, 19, 4482. [Google Scholar] [CrossRef] [Green Version]
- Saba, T.; Abunadi, I.; Shahzad, M.N.; Khan, A.R. Machine learning techniques to detect and forecast the daily total COVID-19 infected and deaths cases under different lockdown types. Microsc. Res. Tech. 2021, 84, 1462–1474. [Google Scholar] [CrossRef]
- Wadhwa, P.; Tripathi, A.; Singh, P.; Diwakar, M.; Kumar, N. Predicting the time period of extension of lockdown due to increase in rate of COVID-19 cases in India using machine learning. Mater. Today Proc. 2021, 37, 2617–2622. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Pardo-Quiles, D.J.; Heras-González, P.; Chatzigiannakis, I. Modeling and Forecasting Gender-Based Violence through Machine Learning Techniques. Appl. Sci. 2020, 10, 8244. [Google Scholar] [CrossRef]
- Zhou, C.; Su, F.; Pei, T.; Zhang, A.; Du, Y.; Luo, B.; Xiao, H. COVID-19: Challenges to GIS with big data. Geogr. Sustain. 2020, 1, 77–87. [Google Scholar] [CrossRef]
- Jung, Y.; Agulto, R. A Public Platform for Virtual IoT-Based Monitoring and Tracking of COVID-19. Electronics 2021, 10, 12. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Molina-García-Pardo, J.M.; Zamora-Izquierdo, M.Á.; Martínez-Inglés, M.T.M.I.I. A Comparison of Different Models of Glycemia Dynamics for Improved Type 1 Diabetes Mellitus Management with Advanced Intelligent Analysis in an Internet of Things Context. Appl. Sci. 2020, 10, 4381. [Google Scholar] [CrossRef]
- Lee, I.K.; Wang, C.C.; Lin, M.C.; Kung, C.T.; Lan, K.C.; Lee, C.T. Effective strategies to prevent coronavirus disease-2019 (COVID-19) outbreak in hospital. J. Hosp. Infect. 2020, 105, 102. [Google Scholar] [CrossRef] [Green Version]
- Albahli, S.; Algsham, A.; Aeraj, S.; Alsaeed, M.; Alrashed, M.; Rauf, H.T.; Mohammed, M.A. COVID-19 Public Sentiment Insights: A Text Mining Approach to the Gulf Countries. Comput. Mater. Contin. 2021, 67, 014265. [Google Scholar]
- Choi, H.K.; Lee, S.H. Trends and Effectiveness of ICT Interventions for the Elderly to Reduce Loneliness: A Systematic Review. Healthcare 2021, 9, 293. [Google Scholar] [CrossRef]
- Koh, J.X.; Liew, T.M. How loneliness is talked about in social media during COVID-19 pandemic: Text mining of 4,492 Twitter feeds. J. Psychiatr. Res. 2020. [Google Scholar] [CrossRef] [PubMed]
- Ćosić, K.; Popović, S.; Šarlija, M.; Kesedžić, I.; Jovanovic, T. Artificial intelligence in prediction of mental health disorders induced by the covid-19 pandemic among health care workers. Croat. Med. J. 2020, 61, 279. [Google Scholar] [CrossRef]
- WHO. Infodemic Management Infodemiology. 2020. Available online: www.who.int/teams/riskcommunication/infodemic-management (accessed on 24 June 2021).
- Paka, W.S.; Bansal, R.; Kaushik, A.; Sengupta, S.; Chakraborty, T. Cross-SEAN: A cross-stitch semi-supervised neural attention model for COVID-19 fake news detection. Appl. Soft Comput. 2021, 107, 107393. [Google Scholar] [CrossRef]
- Bullock, J.; Luccioni, A.; Pham, K.H.; Lam, C.S.N.; Luengo-Oroz, M. Mapping the landscape of artificial intelligence applications against COVID-19. J. Artif. Intell. Res. 2020, 69, 807–845. [Google Scholar] [CrossRef]
- Wang, C.S.; Lin, P.J.; Cheng, C.L.; Tai, S.H.; Yang, Y.H.K.; Chiang, J.H. Detecting potential adverse drug reactions using a deep neural network model. J. Med. Internet Res. 2019, 21, e11016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ho, D. Addressing COVID-19 drug development with artificial intelligence. Adv. Intell. Syst. 2020, 2, 2000070. [Google Scholar] [CrossRef] [Green Version]
- Ke, Y.Y.; Peng, T.T.; Yeh, T.K.; Huang, W.Z.; Chang, S.E.; Wu, S.H.; Chen, C.T. Artificial intelligence approach fighting COVID-19 with repurposing drugs. Biomed. J. 2020, 43, 355–362. [Google Scholar] [CrossRef]
- Funk, B.; Sadeh-Sharvit, S.; Fitzsimmons-Craft, E.E.; Trockel, M.T.; Monterubio, G.E.; Goel, N.J.; Taylor, C.B. A framework for applying natural language processing in digital health interventions. J. Med. Internet Res. 2020, 22, e13855. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Engkvist, O.; Wang, Y.; Olivecrona, M.; Blaschke, T. The rise of deep learning in drug discovery. Drug Discov. Today 2018, 23, 1241–1250. [Google Scholar] [CrossRef] [PubMed]
- Hughes, J.P.; Rees, S.; Kalindjian, S.B.; Philpott, K.L. Principles of early drug discovery. Br. J. Pharmacol. 2011, 162, 1239–1249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andoni, A. Artificial Intelligence Can’t Help with the COVID Pandemic. Or Can It? NODE Health 2020. Available online: https://nodehealth.org/2020/07/08/artificial-intelligence-cant-help-with-the-covid-pandemic-or-can-it/ (accessed on 20 June 2021).
- Etzioni, O.; Decario, N. AI Can Help Scientists Find a Covid-19 Vaccine. 2020. Available online: www.wired.com/story/opinion-ai-can-help-find-scientists-find-a-covid-19-vaccine/ (accessed on 2 May 2020).
- Rojas, A. Artificial Intelligence in the COVID-19 era. Artif. Intell. 2020, 27, 8. [Google Scholar]
- Marian, A.J. Current state of vaccine development and targeted therapies for COVID-19: Impact of basic science discoveries. Cardiovasc. Pathol. 2020, 50, 107278. [Google Scholar] [CrossRef]
- Mahomed, N.; van Ginneken, B.; Philipsen, R.H.; Melendez, J.; Moore, D.P.; Moodley, H.; Madhi, S.A. Computer-aided diagnosis for World Health Organization-defined chest radiograph primary-endpoint pneumonia in children. Pediatric Radiol. 2020, 50, 482–491. [Google Scholar] [CrossRef]
- Wang, L.; Lin, Z.Q.; Wong, A. Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Maghded, H.S.; Ghafoor, K.Z.; Sadiq, A.S.; Curran, K.; Rawat, D.B.; Rabie, K. A novel AI-enabled framework to diagnose coronavirus COVID-19 using smartphone embedded sensors: Design study. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 180–187. [Google Scholar]
- Sun, L.; Song, F.; Shi, N.; Liu, F.; Li, S.; Li, P.; Shi, Y. Combination of four clinical indicators predicts the severe/critical symptom of patients infected COVID-19. J. Clin. Virol. 2020, 128, 104431. [Google Scholar] [CrossRef] [PubMed]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Cao, B. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- Rahmatizadeh, S.; Valizadeh-Haghi, S.; Dabbagh, A. The role of artificial intelligence in management of critical COVID-19 patients. J. Cell. Mol. Anesth. 2020, 5, 16–22. [Google Scholar]
- Shamout, F.E.; Shen, Y.; Wu, N.; Kaku, A.; Park, J.; Makino, T.; Geras, K.J. An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department. NPJ Digit. Med. 2021, 4, 1–11. [Google Scholar] [CrossRef]
- Ebrahimian, S.; Homayounieh, F.; Rockenbach, M.A.; Putha, P.; Raj, T.; Dayan, I.; Kalra, M.K. Artificial intelligence matches subjective severity assessment of pneumonia for prediction of patient outcome and need for mechanical ventilation: A cohort study. Sci. Rep. 2021, 11, 1–10. [Google Scholar] [CrossRef]
- Agbehadji, I.E.; Awuzie, B.O.; Ngowi, A.B.; Millham, R.C. Review of big data analytics, artificial intelligence and nature-inspired computing models towards accurate detection of COVID-19 pandemic cases and contact tracing. Int. J. Environ. Res. Public Health 2020, 17, 5330. [Google Scholar] [CrossRef]
- Khan, R.; Shrivastava, P.; Kapoor, A.; Tiwari, A.; Mittal, A. Social media analysis with AI: Sentiment analysis techniques for the analysis of twitter covid-19 data. J. Critical Rev. 2020, 7, 2761–2774. [Google Scholar]
- Shenoy, V.; Mahendra, S.; Vijay, N. COVID 19—Lockdown technology adaption, teaching, learning, students engagement and faculty experience. Mukt Shabd J. 2020, 9, 698–702. [Google Scholar]
- Zhou, Y.; Wang, F.; Tang, J.; Nussinov, R.; Cheng, F. Artificial intelligence in COVID-19 drug repurposing. Lancet Digit. Health 2020, 2, e667–e676. [Google Scholar] [CrossRef]
- Lu, R.; Zhao, X.; Li, J.; Niu, P.; Yang, B.; Wu, H.; Tan, W. Genomic characterisation and epidemiology of 2019 novel coronavirus: Implications for virus origins and receptor binding. Lancet 2020, 395, 565–574. [Google Scholar] [CrossRef] [Green Version]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Xia, L. Correlation of chest CT and RT-PCR testing for coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Ye, F.; Zhang, M.; Cui, C.; Huang, B.; Niu, P.; Liu, D. In vitro antiviral activity and projection of optimized dosing design of hydroxychloroquine for the treatment of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Clin. Infect. Dis. 2020, 71, 732–739. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, D.; Du, G.; Du, R.; Zhao, J.; Jin, Y.; Wang, C. Remdesivir in adults with severe COVID-19: A randomised, double-blind, placebo-controlled, multicentre trial. Lancet 2020, 395, 1569–1578. [Google Scholar] [CrossRef]
- Anderson, R.M.; Heesterbeek, H.; Klinkenberg, D.; Hollingsworth, T.D. How will country-based mitigation measures influence the course of the COVID-19 epidemic? Lancet 2020, 395, 931–934. [Google Scholar] [CrossRef]
- Gordon, D.E.; Jang, G.M.; Bouhaddou, M.; Xu, J.; Obernier, K.; White, K.M.; Krogan, N.J. A SARS-CoV-2 protein interaction map reveals targets for drug repurposing. Nature 2020, 583, 459–468. [Google Scholar] [CrossRef]
- Ziegler, C.G.; Allon, S.J.; Nyquist, S.K.; Mbano, I.M.; Miao, V.N.; Tzouanas, C.N.; Zhang, K. SARS-CoV-2 receptor ACE2 is an interferon-stimulated gene in human airway epithelial cells and is detected in specific cell subsets across tissues. Cell 2020, 181, 1016–1035. [Google Scholar] [CrossRef]
- Ferretti, L.; Wymant, C.; Kendall, M.; Zhao, L.; Nurtay, A.; Abeler-Dörner, L.; Fraser, C. Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science 2020, 368, eabb6936. [Google Scholar] [CrossRef] [Green Version]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; van Smeden, M. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. Br. Med. J. 2020, 369, m1328. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Yang, L.; Zhang, C.; Xiang, Y.T.; Liu, Z.; Hu, S.; Zhang, B. Online mental health services in China during the COVID-19 outbreak. Lancet Psychiatry 2020, 7, e17–e18. [Google Scholar] [CrossRef]
- Ruano, F.J.; Álvarez, M.L.S.; Haroun-Díaz, E.; de la Torre, M.V.; González, P.L.; Prieto-Moreno, A.; Díez, G.C. Impact of the COVID-19 pandemic in children with allergic asthma. J. Allergy Clin. Immunol. Pract. 2020, 8, 3172–3174. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Cao, B. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [Green Version]
- Harzing, A.W.K.; Van der Wal, R. Google Scholar as a new source for citation analysis. Ethics Sci. Environ. Politics 2008, 8, 61–73. [Google Scholar] [CrossRef]
- Apostolopoulos, I.D.; Mpesiana, T.A. Covid-19: Automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Xu, B. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). Eur. Radiol. 2021, 31, 6096–6104. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Xia, J. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 2020, 296, E65–E71. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Searching Criteria | ||
|---|---|---|
| machine learning OR | ||
| artificial intelligence OR | ||
| deep learning OR | ||
| neural network OR | ||
| big data OR | ||
| internet of things OR | ||
| cloud computing OR | ||
| edge computing OR | ||
| quantum computing OR | ||
| virtual reality OR | ||
| Covid * OR | augmented reality OR | |
| sars-cov-2 OR | cyber security OR | |
| 2019-ncov OR | AND | biometrics OR |
| Severe acute | 5G OR | |
| respiratory syndrome) | natural language processing OR | |
| feature selection OR | ||
| random forest OR | ||
| support vector machines OR | ||
| decision trees OR | ||
| blockchain OR | ||
| cloud computing OR | ||
| genetic algorithm OR | ||
| gradient boosting OR | ||
| k nearest neighbors OR | ||
| naïve bayes | ||
| Citations | Journal | Documents | Ratio (cit/doc) | Categories |
|---|---|---|---|---|
| 9047 | Lancet | 26 | 347.96 | Medicine, General and Internal |
| 2722 | Radiology | 20 | 136.10 | Radiology, Nuclear Medicine and Medical Imaging |
| 2310 | International Journal of Environmental Research and Public Health (*) | 426 | 5.42 | Public, Environmental and Occupational Health-Environmental Sciences |
| 2156 | Nature | 30 | 71.87 | Multidisciplinary |
| 2142 | Chaos Solitons and Fractals | 120 | 17.85 | Physics, Multidisciplinary-Mathematics, Interdisciplinary Applications-Physics, Mathematical |
| 2103 | Science of the Total Environment | 70 | 30.04 | Environmental Sciences |
| 1695 | Journal of Medical Internet Research (*) | 294 | 5.77 | Health Care Sciences and Services-Medical Informatics |
| 1660 | Cell | 21 | 79.05 | Cell Biology, Biochemistry and Molecular Biology |
| 1621 | Clinical Infectious Diseases | 9 | 180.11 | Microbiology, Infectious Diseases and Immunology |
| 1517 | Plos One (*) | 355 | 4.27 | Biology, Multidisciplinary Sciences |
| Document Title | Authors | Year | Source | Cited by |
|---|---|---|---|---|
| Genomic characterization and epidemiology of 2019 novel coronavirus: implications for virus origins and receptor binding [105] | Lu, R., Zhao, X., Li, J., (...), Shi, W., Tan, W. | 2020 | The Lancet, 395 (10,224), pp. 565–574 | 4444 |
| Correlation of Chest CT and RT-PCR Testing for Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases [106] | Ai, T., Yang, Z., Hou, H., (...), Sun, Z., Xia, L. | 2020 | Radiology, 296 (2), pp. E32–E40 | 2074 |
| In vitro antiviral activity and projection of optimized dosing design of hydroxychloroquine for the treatment of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [107] | Yao, X., Ye, F., Zhang, M., (...), Tan, W., Liu, D. | 2020 | Clinical Infectious Diseases, 71 (15), pp. 732–739 | 1292 |
| Remdesivir in adults with severe COVID-19: a randomized, double-blind, placebo-controlled, multicenter trial [108] | Wang, Y., Zhang, D., Du, G., (...), Cao, B., Wang, C. | 2020 | The Lancet, 395 (10,236), pp. 1569–1578 | 1290 |
| How will country-based mitigation measures influence the course of the COVID-19 epidemic? [109] | Anderson, R.M., Heesterbeek, H., Klinkenberg, D., Hollingsworth, T.D. | 2020 | The Lancet, 395 (10,228), pp. 931–934 | 1159 |
| A SARS-CoV-2 protein interaction map reveals targets for drug repurposing [110] | Gordon, D.E., Jang, G.M., Bouhaddou, M., (...), Shoichet, B.K., Krogan, N.J. | 2020 | Nature, 583 (7816), pp. 459–468 | 1068 |
| SARS-CoV-2 Receptor ACE2 Is an Interferon-Stimulated Gene in Human Airway Epithelial Cells and Is Detected in Specific Cell Subsets across Tissues [111] | Ziegler, C.G.K., Allon, S.J., Nyquist, S.K., (...), Xu, Y., Zhang, K. | 2020 | Cell, 181 (5), pp. 1016–1035.e19 | 741 |
| Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing [112] | Ferretti, L., Wymant, C., Kendall, M., (...), Bonsall, D., Fraser, C. | 2020 | Science, 368 (6491) | 706 |
| Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal [113] | Wynants, L., Van Calster, B., Collins, G.S., (...), Moons, K.G.M., Van Smeden, M. | 2020 | The BMJ, 369, m1328 | 651 |
| Online mental health services in China during the COVID-19 outbreak [114] | Liu, S., Yang, L., Zhang, C., (...), Hu, S., Zhang, B. | 2020 | The Lancet Psychiatry, 7 (4), pp. e17–e18 | 623 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Rodríguez, I.; Rodríguez, J.-V.; Shirvanizadeh, N.; Ortiz, A.; Pardo-Quiles, D.-J. Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining. Int. J. Environ. Res. Public Health 2021, 18, 8578. https://doi.org/10.3390/ijerph18168578
Rodríguez-Rodríguez I, Rodríguez J-V, Shirvanizadeh N, Ortiz A, Pardo-Quiles D-J. Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining. International Journal of Environmental Research and Public Health. 2021; 18(16):8578. https://doi.org/10.3390/ijerph18168578
Chicago/Turabian StyleRodríguez-Rodríguez, Ignacio, José-Víctor Rodríguez, Niloofar Shirvanizadeh, Andrés Ortiz, and Domingo-Javier Pardo-Quiles. 2021. "Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining" International Journal of Environmental Research and Public Health 18, no. 16: 8578. https://doi.org/10.3390/ijerph18168578
APA StyleRodríguez-Rodríguez, I., Rodríguez, J. -V., Shirvanizadeh, N., Ortiz, A., & Pardo-Quiles, D. -J. (2021). Applications of Artificial Intelligence, Machine Learning, Big Data and the Internet of Things to the COVID-19 Pandemic: A Scientometric Review Using Text Mining. International Journal of Environmental Research and Public Health, 18(16), 8578. https://doi.org/10.3390/ijerph18168578