
A Clinical Decision Web to Predict ICU Admission or Death for Patients Hospitalised with COVID-19 Using Machine Learning Algorithms

 ,
,  , and
, and
Abstract
:1. Introduction
1.1. Context
1.2. Related Work and Limitations
1.3. Contributions of Our Work
2. Materials and Methods
2.1. Patient Information Recruitment
2.2. Statistical Analysis
2.3. Training and Validation
2.4. External Validation
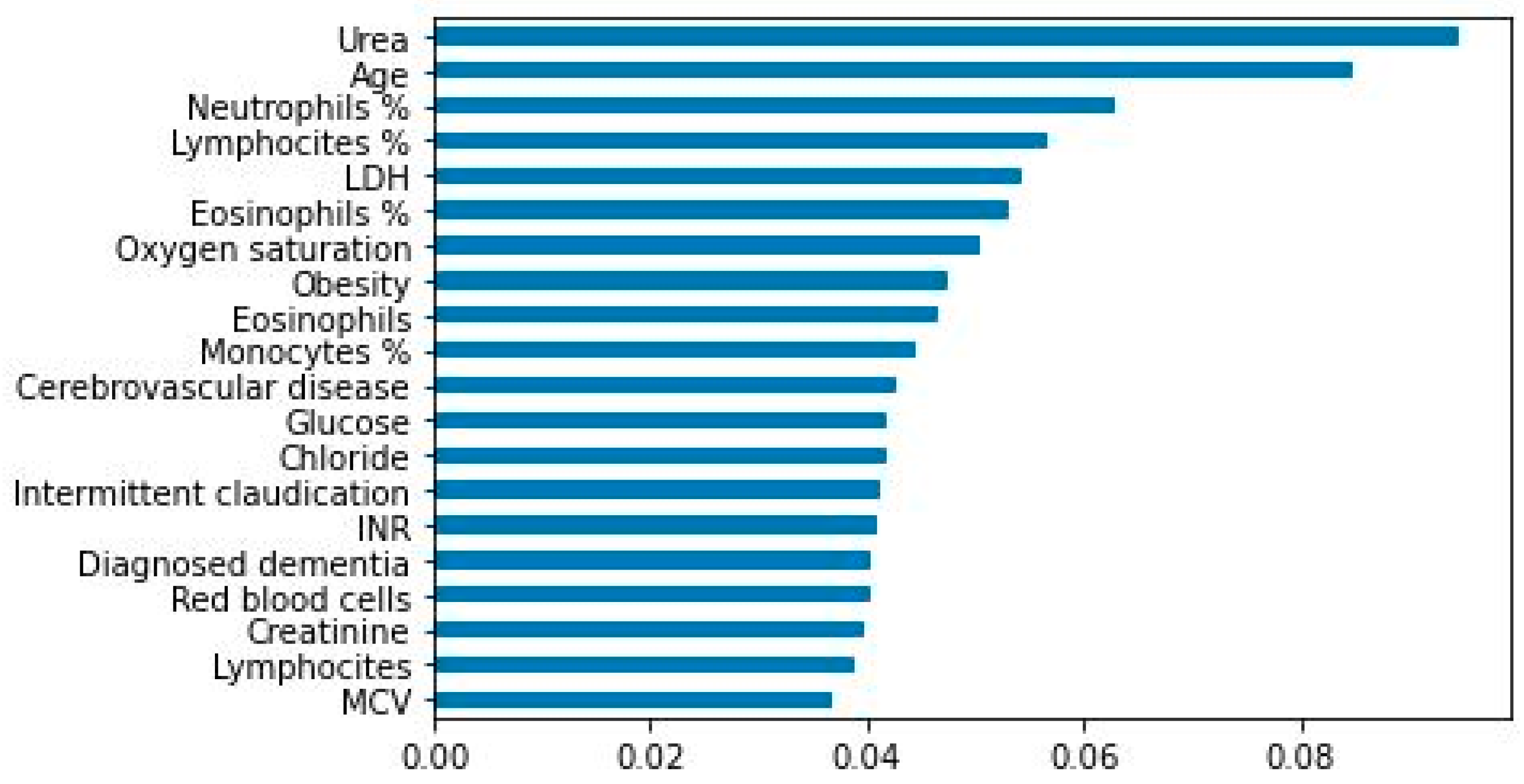
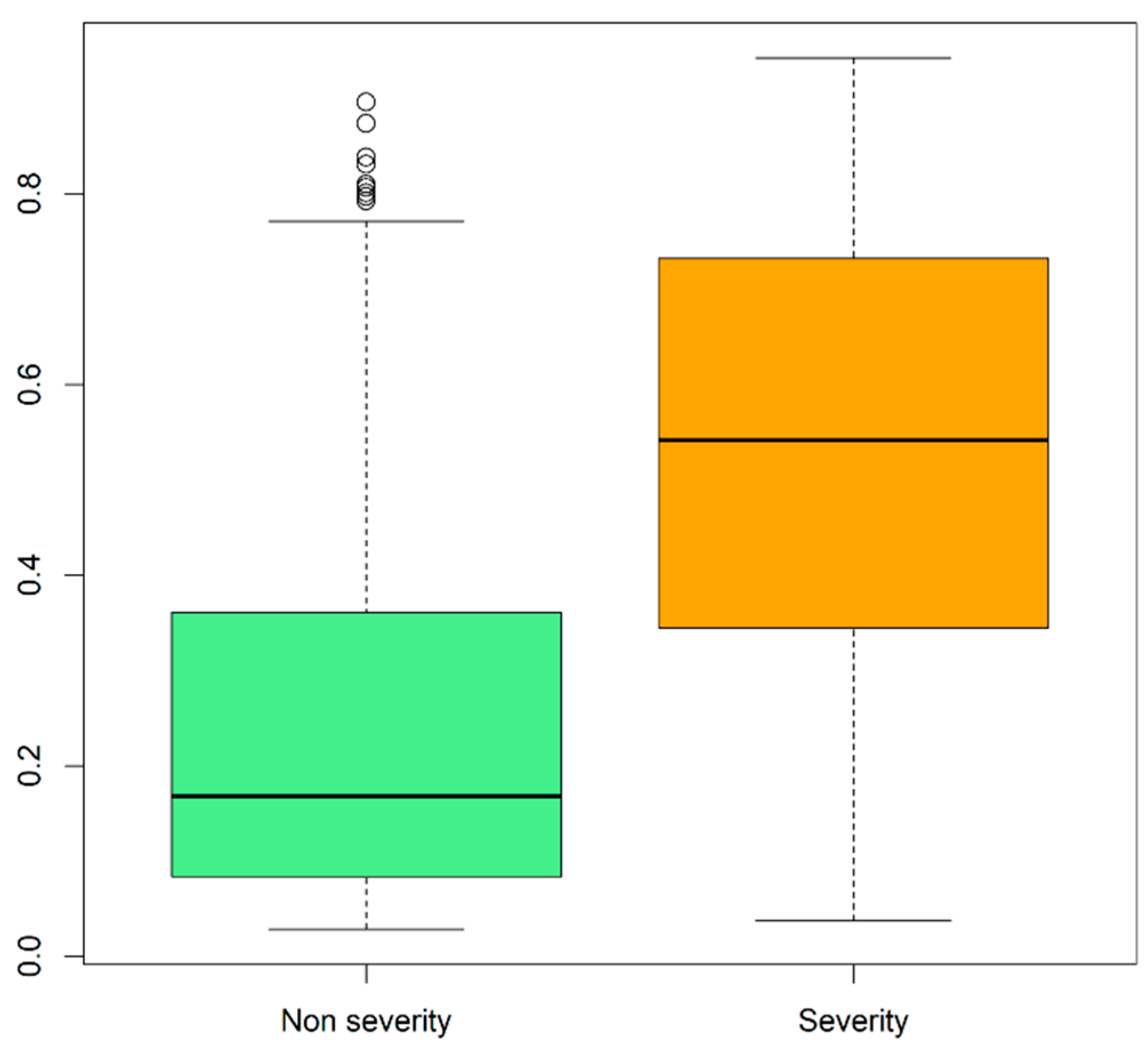
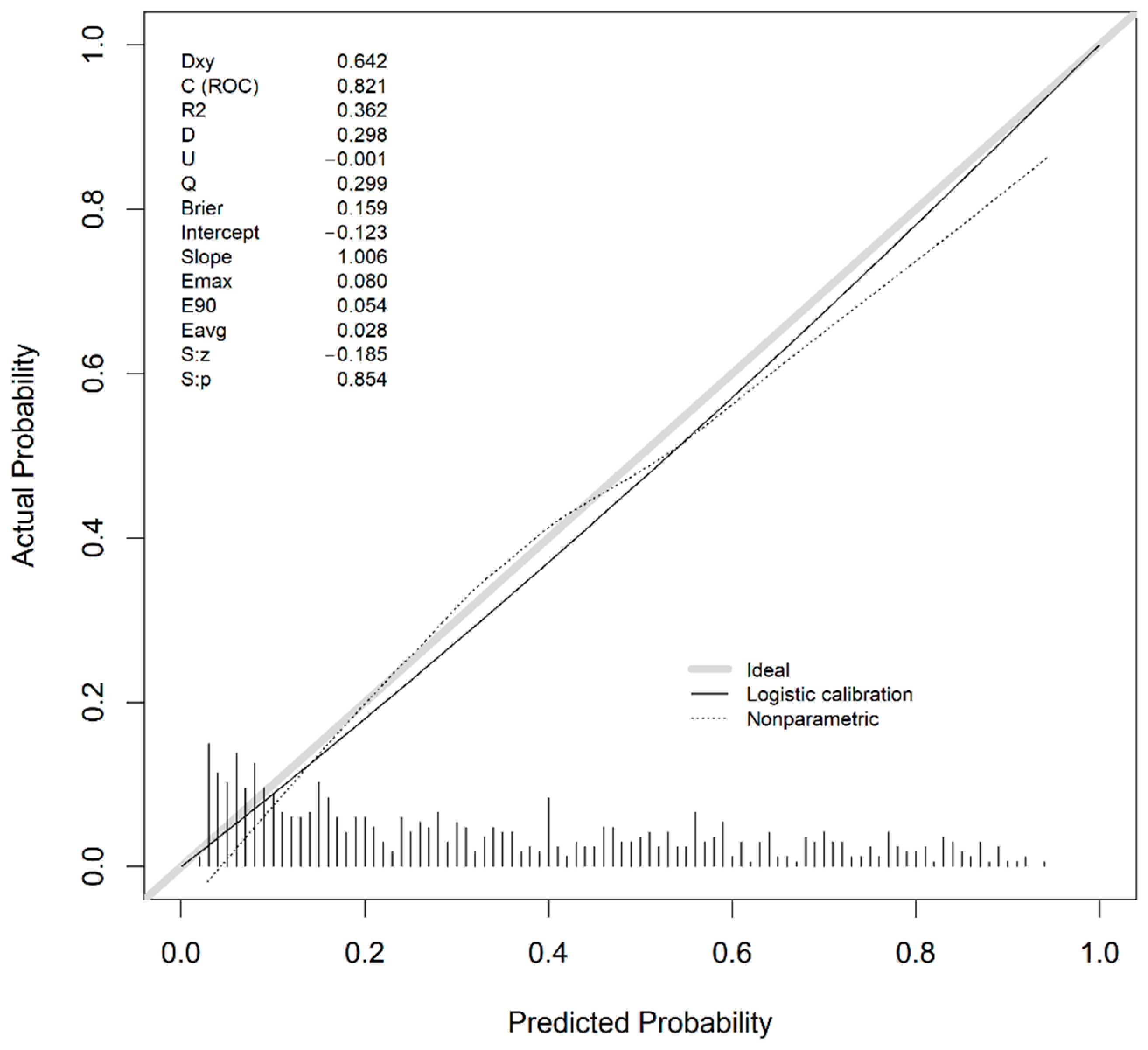
3. Results
3.1. External Validation Analysis
3.2. Clinically Useful Tool
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUC | Area Under ROC Curve |
| CI | Confidence Interval |
| COVID-19 | Coronavirus disease 2019 |
| ICU | Intensive Care Unit |
| INR | International Normalized Ratio |
| INR-PT | International Normalized Ratio-Prothrombin Time |
| LDH | Lactate Dehydrogenase |
| MCV | Mean Corpuscular Volume |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| NPV | Negative Predicted Value |
| PCR | Polymerase Chain Reaction |
| PPV | Positive Predictive Value |
| ROC | Receiver Operating Characteristic |
| RT-PCR | Reverse Transcription Polymerase Chain Reaction |
| SARS-CoV-2 | Severe Acute Respiratory Syndrome Coronavirus 2 |
| SVM | Support Vector Machine |
| TPE | Tree-structured Parzen Estimator |
| XGBoost | Extreme Gradient Boosting |
References
- DeLancey, E.R.; Simms, J.F.; Mahdianpari, M.; Brisco, B.; Mahoney, C.; Kariyeva, J. Comparing deep learning and shallow learning for large-scale wetland classification in Alberta, Canada. Remote Sens. 2020, 12, 2. [Google Scholar] [CrossRef] [Green Version]
- Thanh, H.V.; Sugai, Y.; Sasaki, K. Application of artificial neural network for predicting the performance of CO2 enhanced oil recovery and storage in residual oil zones. Sci. Rep. 2020, 10, 18204. [Google Scholar] [CrossRef]
- Lacueva-Pérez, F.J.; Ilarri, S.; Vargas, J.J.B.; Lezaun, G.L.; Alonso, R.D.H. Multifactorial Evolutionary Prediction of Phenology and Pests: Can Machine Learning Help? In Proceedings of the WEBIST 2020—16th International Conference on Web Information Systems and Technologies, Online, 3–5 November 2020; Science and Technology Publications, Lda: Setúbal, Portugal, 2020; pp. 75–82. [Google Scholar]
- Han, T.; Li, Y.F.; Qian, M. A hybrid generalization network for intelligent fault diagnosis of rotating machinery under unseen working conditions. IEEE Instrum. Meas. 2021, 70, 3520011. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal. Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Jiang, L.; Wu, Z.; Xu, X.; Zhan, Y.; Jin, X.; Wang, L.; Qiu, Y. Opportunities and challenges of artificial intelligence in the medical field: Current application, emerging problems, and problem-solving strategies. J. Int. Med. Res. 2021, 49, 03000605211000157. [Google Scholar] [CrossRef] [PubMed]
- Secinaro, S.; Calandra, D.; Secinaro, A.; Muthurangu, V.; Biancone, B. The role of artificial intelligence in healthcare: A structured literature review. BMC Med. Inform. Decis. Mak. 2021, 21, 125. [Google Scholar] [CrossRef]
- Musulin, J.; Baressi Šegota, S.; Štifanić, D.; Lorencin, I.; Anđelić, N.; Šušteršič, T.; Blagojević, A.; Filipović, A.; Ćabov, T.; Markova-Car, E. Application of Artificial Intelligence-Based Regression Methods in the Problem of COVID-19 Spread Prediction: A Systematic Review. Int. J. Environ. Res. Public Health 2021, 18, 4287. [Google Scholar] [CrossRef]
- Aznar-Gimeno, R.; Labata-Lezaun, G.; Adell-Lamora, A.; Abadía-Gallego, D.; del-Hoyo-Alonso, R.; González-Muñoz, C. Deep Learning for Walking Behaviour Detection in Elderly People Using Smart Footwear. Entropy 2021, 23, 777. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.B.; Jung, K.H.; Lee, Y.; Kim, H.-J.; Kim, N.; Jun, S.; Seo, J.B.; Lynch, D.A. Comparison of shallow and deep learning methods on classifying the regional pattern of diffuse lung disease. J. Digit. Imaging 2018, 31, 415–424. [Google Scholar] [CrossRef]
- Chauhan, S.; Vig, L.; De Filippo De Grazia, M.; Corbetta, M.; Ahmad, S.; Zorzi, M. A comparison of shallow and deep learning methods for predicting cognitive performance of stroke patients from MRI lesion images. Front. Neuroinform. 2019, 13, 53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Del CarmenRodríguez-Hernández, M.; del-Hoyo-Alonso, R.; Ilarri, S.; Montafñés-Salas, R.M.; Sabroso-Lasa, S. An Experimental Evaluation of Content-based Recommendation Systems: Can Linked Data and BERT Help? In Proceedings of the 2020 IEEE/ACS 17th International Conference on Computer Systems and Applications (AICCSA), Antalya, Turkey, 2–5 November 2020; IEEE: Antalya, Turkey, 2020; pp. 1–8. [Google Scholar]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, D. An introductory review of deep learning for prediction models with big data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [Green Version]
- Playe, B.; Stoven, V. Evaluation of deep and shallow learning methods in chemogenomics for the prediction of drugs specificity. J. Cheminform. 2020, 12, 1–18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; See, K.C. Artificial Intelligence for COVID-19: Rapid Review. J. Med. Internet Res. 2020, 22, e21476. [Google Scholar] [CrossRef]
- Global Data: Coronavirus Pandemic COVID-19. Available online: https://www.worldometers.info/coronavirus/ (accessed on 9 June 2021).
- Wu, Z.; McGoogan, J.M. Characteristics of and important lessons from the coronavirus disease 2019 (COVID-19) outbreak in China: Summary of a report of 72,314 cases from the Chinese Center for Disease Control and Prevention. JAMA 2020, 323, 1239–1242. [Google Scholar] [CrossRef]
- Karadag, E. Increase in COVID-19 cases and case-fatality and case-recovery rates in Europe: A cross-temporal meta-analysis. J. Med. Virol. 2020, 92, 1511–1517. [Google Scholar] [CrossRef]
- Izcovich, A.; Ragusa, M.A.; Tortosa, F.; Lavena Marzio, M.A.; Agnoletti, C.; Bengolea, A.; Ceirano, A.; Espinosa, F.; Saavedra, E.; Sanguine, V. Prognostic factors for severity and mortality in patients infected with COVID-19: A systematic review. PLoS ONE 2020, 15, e0241955. [Google Scholar]
- Knight, S.R.; Ho, A.; Pius, R.; Buchan, I.; Carson, G.; Drake, T.M.; Dunning, J.; Fairfield, C.J.; Gamble, C.; Green, C.A. Risk stratification of patients admitted to hospital with COVID-19 using the ISARIC WHO Clinical Characterisation Protocol: Development and validation of the 4C Mortality Score. BMJ 2020, 370, m3339. [Google Scholar] [CrossRef]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.J.; Dahly, D.L.; Damen, J.A.; Debray, T.P.A. Prediction models for diagnosis and prognosis of COVID-19 infection: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aznar-Gimeno, R.; Paño-Pardo, J.R.; Esteban, L.M.; Labata-Lezaun, G.; Esquillor-Rodrigo, M.J.; Lanas, A.; Abadía-Gallego, D.; Diez-Fuertes, F.; Tellería-Orriols, C.; del-Hoyo-Alonso, R.; et al. Changes and Evolution among SARS-COV-2 Hospitalised Patients in Terms of Severity, Mortality and Virus Genome in a Spanish Cohort. Research Square [Preprint] (2021). Available online: https://www.researchsquare.com/article/rs-199395/v1 (accessed on 9 June 2021).
- Cai, W.; Liu, T.; Xue, X.; Luo, G.; Wang, X.; Shen, Y.; Fang, Q.; Sheng, J.; Dhen, F.; Liang, T. CT Quantification and Machine-learning Models for Assessment of Disease Severity and Prognosis of COVID-19 Patients. Acad. Radiol. 2020, 27, 1665–1678. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Yang, P.; Xie, Y.; Woodruff, H.C.; Rao, X.; Guiot, J.; Frix, A.N.; Louis, R.; Moutschen, M.; Li, J.; et al. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: An international multicentre study. Eur. Respir. J. 2020, 56, 2001104. [Google Scholar] [CrossRef]
- Yao, H.; Zhang, N.; Zhang, R.; Duan, M.; Xie, T.; Pan, J.; Peng, E.; Huang, J.; Zhang, Y.; Xu, X.; et al. Severity detection for the coronavirus disease 2019 (COVID-19) patients using a machine learning model based on the blood and urine tests. Front. Cell Dev. Biol. 2020, 8, 683. [Google Scholar] [CrossRef]
- Marcos, M.; Belhassen-Garcia, M.; Sanchez-Puente, A.; Sampedro-Gomez, J.; Azibeiro, R.; Dorado-Díaz, P.I.; Marcano-Millar, E.; García-Vidal, C.; Moreiro-Barroso, M.T.; Cubino-Bóveda, N.; et al. Development of a severity of disease score and classification model by machine learning for hospitalized COVID-19 patients. PLoS ONE 2020, 16, e0240200. [Google Scholar]
- Jiang, X.; Coffee, M.; Bari, A.; Wang, J.; Jiang, X.; Huang, J.; Shi, J.; Dai, J.; Cai, J.; Zhang, T.; et al. Towards an artificial intelligence framework for data-driven prediction of coronavirus clinical severity. CMC Comput. Mater. Con. 2020, 63, 537–551. [Google Scholar] [CrossRef]
- Patel, D.; Kher, V.; Desai, B.; Lei, X.; Cen, S.; Nanda, N.; Gholamrezanezhad, A.; Duddalwar, V.; Varghese, B.; Oberai, A.A. Machine learning based predictors for COVID-19 disease severity. Sci. Rep. 2021, 11, 4673. [Google Scholar] [CrossRef]
- Štifanić, D.; Musulin, J.; Jurilj, Z.; Šegota, S.B.; Lorencin, I.; Anđelić, N.; Vlahinić, S.; Šušteršič, T.; Blagojević, A.; Filipović, N.; et al. Semantic segmentation of chest X-ray images based on the severity of COVID-19 infected patients. EAI Endorsed Trans. Bioeng. Bioinform. 2021, 1, e3. [Google Scholar]
- Riley, R.D.; Ensor, J.; Snell, K.I.; Harrell, F.E.; Martin, G.P.; Reitsma, J.B.; Moons, K.G.M.; Collins, G.; van Smeden, M. Calculating the sample size required for developing a clinical prediction model. BMJ 2020, 368, m441. [Google Scholar] [CrossRef] [Green Version]
- Caramelo, F.; Ferreira, N.; Oliveiros, B. Estimation of risk factors for COVID-19 mortality-preliminary results. medRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Yan, L.; Zhang, H.T.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Li, S.; Zhang, M.; et al. Prediction of criticality in patients with severe COVID-19 infection using three clinical features: A machine learning-based prognostic model with clinical data in Wuhan. medRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Yuan, M.; Yin, W.; Tao, Z. Association of radiologic findings with mortality of patients infected with 2019 novel coronavirus in Wuhan, China. PLoS ONE 2020, 15, e0230548. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.; Yu, X.; Zhao, H. Host susceptibility to severe COVID-19 and establishment of a host risk score: Findings of 487 cases outside Wuhan. Crit. Care 2020, 24, 108. [Google Scholar] [CrossRef] [Green Version]
- Yue, H.; Yu, Q.; Liu, C.; Huang, Y.; Jiang, Z.; Shao, C.; Zhang, H.; Ma, B.; Wang, Y.; Xie, G.; et al. Machine learning-based CT radiomics model for predicting hospital stay in patients with pneumonia associated with SARS-CoV-2 infection: A multicenter study. Ann. Transl. Med. 2020, 8, 859. [Google Scholar] [CrossRef] [PubMed]
- Gong, J.; Ou, J.; Qiu, X.; Jie, Y.; Chen, Y.; Yuan, L.; Cao, J.; Tan, M.; Xu, W.; Zheng, F.; et al. A tool to early predict severe 2019-novel coronavirus pneumonia (COVID-19): A multicenter study using the risk nomogram in Wuhan and Guangdong, China. Clin. Infect. Dis. 2020, 71, 833–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, J.; Hungerford, D.; Chen, H.; Abrams, S.T.; Li, S.; Wang, G.; Wang, Y.; Kang, H.; Bonnett, L.; Zheng, R.; et al. Development and External Validation of a Prognostic Multivariable Model on Admission for Hospitalized Patients with COVID-19. 2020. Available online: https://www.medrxiv.org/content/medrxiv/early/2020/03/30/2020.03.28.20045997.full.pdf (accessed on 14 July 2021).
- Koller, D.; Sahami, M. Toward optimal feature selection. In Proceedings of the ICML’96 Proceedings of the 13th International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- Pepe, M.S.; Longton, G.; Janes, H. Estimation and comparison of receiver operating characteristic curves. Stata J. 2009, 9, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: New York, NY, USA, 2013; Volume 398. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD’19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2623–2631. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kég, B. Algorithms for hyper-parameter optimization. In Proceedings of the 25th Annual Conference on neural Information Processing Systems (NIPS) 2011, Granada, Spain, 12–14 December 2011; pp. 2546–2554. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 14 May 2021).
- The Python Tutorial. Available online: https://docs.python.org/3/tutorial/ (accessed on 14 May 2021).
- Strumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2015, 41, 647–665. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- Berenguer, J.; Ryan, P.; Rodríguez-Baño, J.; Jarrín, I.; Carratalà, J.; Pachón, J.; Yllescas, M.; Arriba, J.R.; COVID-19@Spain Study Group. Characteristics and predictors of death among 4035 consecutively hospitalized patients with COVID-19 in Spain. Clin. Microbiol. Infect. 2020, 26, 1525–1536. [Google Scholar] [CrossRef]
- Grasselli, G.; Greco, M.; Zanella, A.; Albano, G.; Antonelli, M.; Bellani, G.; Bonanomi, E.; Cabrini, L.; Carlesso, E.; Castelli, G.; et al. Risk Factors Associated with Mortality among Patients with COVID-19 in Intensive Care Units in Lombardy, Italy. JAMA Intern. Med. 2020, 180, 1345–1355. [Google Scholar] [CrossRef]
- Steyerberg, E.W. Clinical Prediction Models; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non Severity (n = 1548) | Severity (n = 699) | p-Value | |
|---|---|---|---|
| Age (years) | 66 (51–81) | 83 (71–89) | <0.001 |
| Oxygen saturation (%) | 96 (94–97) | 94 (91–96) | <0.001 |
| Intermittent claudication (yes) | 41 (2.65%) | 42 (6.01%) | <0.001 |
| Cerebrovascular disease (yes) | 104 (6.72%) | 104 (14.88%) | <0.001 |
| Dementia (yes) | 124 (8.01%) | 141 (20.17%) | <0.001 |
| Obesity (yes) | 218 (14.08%) | 123 (17.6%) | 0.03701 |
| Chloride (mmol/L) | 101.5 (98.4–104) | 102.3 (99–106) | <0.001 |
| Creatinine (mg/dL) | 0.86 (0.68–1.1) | 1.1 (0.81–1.58) | <0.001 |
| Eosinophils (%) | 0.17 (0–0.7) | 0 (0–0.2) | <0.001 |
| Eosinophils (mil/mm3) | 0.0102 (0–0.04385) | 0 (0–0.01702) | <0.001 |
| Glucose (mg/dL) | 110 (96–133) | 128 (104–170) | <0.001 |
| International normalized ratio-prothrombin time (INR-PT) | 1.1 (1.02–1.17) | 1.16 (1.06–1.305) | <0.001 |
| Lactate dehydrogenase (U/L) | 275 (219–350) | 336.5 (246.8–470) | <0.001 |
| Lymphocytes (%) | 17.9 (11.65–25.98) | 10.74 (6.275–18) | <0.001 |
| Lymphocytes (mil/mm3) | 1.0875 (0.7561–1.4941) | 0.8055 (0.5605–1.1458) | <0.001 |
| Monocytes (%) | 8.07 (6–10.438) | 6.2 (4–8.9) | <0.001 |
| Neutrophils (%) | 72 (63.28–80.41) | 81.4 (72.75–88.5) | <0.001 |
| Red blood cells (mil/mm3) | 4.6 (4.19–4.95) | 4.32 (3.87–4.72) | <0.001 |
| Urea (g/l) | 0.3595 (0.27–0.5258) | 0.609 (0.42–0.91) | <0.001 |
| Mean corpuscular volume (fl) | 89.7 (86.1–93) | 91.5 (87.7–95) | <0.001 |
| Non Severity (n = 425) | Severity (n = 201) | p-Value | |
|---|---|---|---|
| Age (years) | 71 (58–83) | 84 (74–89) | <0.001 |
| Oxygen saturation (%) | 95 (94–97) | 95 (92–97) | 0.03714 |
| Intermittent claudication (yes) | 24 (5.65%) | 17 (8.46%) | 0.2484 |
| Cerebrovascular disease (yes) | 44 (10.35%) | 37 (18.41%) | 0.007451 |
| Dementia (yes) | 43 (10.12%) | 32 (15.92%) | 0.05051 |
| Obesity (yes) | 75 (17.65%) | 27 (13.43%) | 0.2236 |
| Chloride (mmol/L) | 101.7 (98.9–104.1) | 102.1 (98.3–105.7) | 0.1273 |
| Creatinine (mg/dL) | 0.85 (0.68–1.06) | 1.14 (0.8–1.64) | <0.001 |
| Eosinophils (%) | 0.1 (0–0.4) | 0.01 (0–0.24) | <0.001 |
| Eosinophils (mil/mm3) | 0.00715 (0–0.02808) | 0.00026 (0–0.0162) | <0.001 |
| Glucose (mg/dL) | 116 (100–145) | 130 (106–174) | <0.001 |
| International normalized ratio-prothrombin time (INR-PT) | 1.08 (1.02–1.17) | 1.15 (1.06–1.32) | <0.001 |
| Lactate dehydrogenase (U/L) | 266 (213–336) | 322 (245–414) | <0.001 |
| Lymphocytes (%) | 16 (10.5–24.4) | 9.2 (5.5–14.8) | <0.001 |
| Lymphocytes (mil/mm3) | 0.9432 (0.6696–1.362) | 0.6987 (0.4611–1.0577) | <0.001 |
| Monocytes (%) | 7.9 (5.6–10.59) | 5.7 (3.6–8.29) | <0.001 |
| Neutrophils (%) | 74.7 (64.66–82.4) | 84.5 (75.1–88.7) | <0.001 |
| Red blood cells (mil/mm3) | 4.46 (4.01–4.81) | 4.17 (3.66–4.62) | <0.001 |
| Urea (g/L) | 0.396 (0.306–0.553) | 0.672 (0.446–1.1) | <0.001 |
| Mean corpuscular volume (fl) | 90.1 (87.1–93) | 90.7 (87–94.9) | 0.07457 |
| Model | Parameters | Search Space | Best Model | AUC |
|---|---|---|---|---|
| Number of hidden layers | [2, 10] | 7 | ||
| Number of neurons | [16, 512] | [96, 176, 240, 240, 352, 352, 384] | ||
| MLP | Activation layer | [selu, linear, tanh, softmax] | [softmax, selu, softmax, selu, selu, selu, selu] | 0.8015 |
| Learning rate | {0.001,0.01,0.1} | 0.001 | ||
| Optimizer | {sgd, adam, rmsprop} | rmsprop | ||
| Batch size | [1, 64] | 54 | ||
| Number of estimators | [30, 1300] | 820 | ||
| Max. depth | [3, 20] | 15 | ||
| Random Forest | Min. samples split | [2, 30] | 10 | 0.8297 |
| Criterion | {gini, entropy} | gini | ||
| Min. impurity decrease | {5 × 10−5, 1 × 10−4, 2 × 10−4, 5 × 10−4, 1 × 10−3, 1.5 × 10−3, 2 × 10−3, 5 × 10−3, 0.01} | 2 × 10−4 | ||
| Number of estimators | [30, 1300] | 330 | ||
| Scale pos. weight | [1, 10] | 1 | ||
| Column subsample size per tree | [0.3, 1] | 0.85 | ||
| Subsample size per tree | [0.3, 1] | 0.64 | ||
| XGBoost | Max. depth | [3, 20] | 15 | 0.8307 |
| Learning rate | {10−4, 10−3, 10−2,0.1, 0.15, 0.2, 0.3, 0.4} | 0.01 | ||
| Reg. alpha | {10−4, 10−3, 10−2,0.1, 0.15, 0.2, 0.3, 0.4} | 0.4 | ||
| Gamma | [0.05, 1] | 0.6 |
| Parameter | All-Variable Model | 50-Variable Model | 20-Variable Model |
|---|---|---|---|
| Number of estimators | 330 | 690 | 340 |
| Scale pos. weight | 1 | 5 | 1 |
| Column subsample size per tree | 0.85 | 0.41 | 0.84 |
| Subsample size per tree | 0.64 | 0.94 | 0.68 |
| Max. depth | 15 | 14 | 13 |
| Learning rate | 0.01 | 0.2 | 0.01 |
| Reg. alpha | 0.4 | 0.3 | 0.15 |
| Gamma | 0.6 | 0.1 | 0.45 |
| Thr | tp | tn | fp | fn | Sens | Spec | PPV | NPV | Accuracy | Youden |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.05 | 199 | 44 | 381 | 2 | 0.99 | 0.1 | 0.34 | 0.96 | 0.39 | 0.09 |
| 0.1 | 199 | 137 | 288 | 2 | 0.99 | 0.32 | 0.41 | 0.99 | 0.54 | 0.31 |
| 0.15 | 192 | 187 | 238 | 9 | 0.96 | 0.44 | 0.45 | 0.95 | 0.61 | 0.4 |
| 0.2 | 184 | 237 | 188 | 17 | 0.92 | 0.56 | 0.49 | 0.93 | 0.67 | 0.47 |
| 0.22 | 179 | 250 | 175 | 22 | 0.89 | 0.59 | 0.51 | 0.92 | 0.69 | 0.48 |
| 0.24 | 178 | 257 | 168 | 23 | 0.89 | 0.6 | 0.51 | 0.92 | 0.69 | 0.49 |
| 0.26 | 171 | 267 | 158 | 30 | 0.85 | 0.63 | 0.52 | 0.9 | 0.7 | 0.48 |
| 0.28 | 164 | 277 | 148 | 37 | 0.82 | 0.65 | 0.53 | 0.88 | 0.7 | 0.47 |
| 0.3 | 159 | 288 | 137 | 42 | 0.79 | 0.68 | 0.54 | 0.87 | 0.71 | 0.47 |
| 0.32 | 154 | 300 | 125 | 47 | 0.77 | 0.71 | 0.55 | 0.86 | 0.73 | 0.47 |
| 0.34 | 152 | 307 | 118 | 49 | 0.76 | 0.72 | 0.56 | 0.86 | 0.73 | 0.48 |
| 0.36 | 148 | 318 | 107 | 53 | 0.74 | 0.75 | 0.58 | 0.86 | 0.74 | 0.48 |
| 0.38 | 146 | 326 | 99 | 55 | 0.73 | 0.77 | 0.6 | 0.86 | 0.75 | 0.49 |
| 0.4 | 143 | 330 | 95 | 58 | 0.71 | 0.78 | 0.6 | 0.85 | 0.76 | 0.49 |
| 0.42 | 134 | 339 | 86 | 67 | 0.67 | 0.8 | 0.61 | 0.83 | 0.76 | 0.46 |
| 0.44 | 131 | 343 | 82 | 70 | 0.65 | 0.81 | 0.62 | 0.83 | 0.76 | 0.46 |
| 0.46 | 125 | 345 | 80 | 76 | 0.62 | 0.81 | 0.61 | 0.82 | 0.75 | 0.43 |
| 0.48 | 117 | 353 | 72 | 84 | 0.58 | 0.83 | 0.62 | 0.81 | 0.75 | 0.41 |
| 0.5 | 113 | 359 | 66 | 88 | 0.56 | 0.84 | 0.63 | 0.8 | 0.75 | 0.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aznar-Gimeno, R.; Esteban, L.M.; Labata-Lezaun, G.; del-Hoyo-Alonso, R.; Abadia-Gallego, D.; Paño-Pardo, J.R.; Esquillor-Rodrigo, M.J.; Lanas, Á.; Serrano, M.T. A Clinical Decision Web to Predict ICU Admission or Death for Patients Hospitalised with COVID-19 Using Machine Learning Algorithms. Int. J. Environ. Res. Public Health 2021, 18, 8677. https://doi.org/10.3390/ijerph18168677
Aznar-Gimeno R, Esteban LM, Labata-Lezaun G, del-Hoyo-Alonso R, Abadia-Gallego D, Paño-Pardo JR, Esquillor-Rodrigo MJ, Lanas Á, Serrano MT. A Clinical Decision Web to Predict ICU Admission or Death for Patients Hospitalised with COVID-19 Using Machine Learning Algorithms. International Journal of Environmental Research and Public Health. 2021; 18(16):8677. https://doi.org/10.3390/ijerph18168677
Chicago/Turabian StyleAznar-Gimeno, Rocío, Luis M. Esteban, Gorka Labata-Lezaun, Rafael del-Hoyo-Alonso, David Abadia-Gallego, J. Ramón Paño-Pardo, M. José Esquillor-Rodrigo, Ángel Lanas, and M. Trinidad Serrano. 2021. "A Clinical Decision Web to Predict ICU Admission or Death for Patients Hospitalised with COVID-19 Using Machine Learning Algorithms" International Journal of Environmental Research and Public Health 18, no. 16: 8677. https://doi.org/10.3390/ijerph18168677
APA StyleAznar-Gimeno, R., Esteban, L. M., Labata-Lezaun, G., del-Hoyo-Alonso, R., Abadia-Gallego, D., Paño-Pardo, J. R., Esquillor-Rodrigo, M. J., Lanas, Á., & Serrano, M. T. (2021). A Clinical Decision Web to Predict ICU Admission or Death for Patients Hospitalised with COVID-19 Using Machine Learning Algorithms. International Journal of Environmental Research and Public Health, 18(16), 8677. https://doi.org/10.3390/ijerph18168677