
Estimation of Health-Related Physical Fitness (HRPF) Levels of the General Public Using Artificial Neural Network with the National Fitness Award (NFA) Datasets


 ,
,  , , and
, , and 
Abstract
:1. Introduction
- This paper proposes the ANN-based estimation model to predict the HRPF level of the general public using NFA datasets. The proposed model aims to improve the estimation accuracy of the previous MLR-based estimation model by additionally adopting a non-linear feature in the estimation model. ANN structures including layer and node configurations, non-linear activation function, and training/validation methods for the estimation model are presented.
- This paper derives the optimal ANN model that maximizes the estimation accuracy through in-depth analysis on effects of four techniques including input-output correlation, hidden layer structures, input data standardization, and outlier removal to the estimation accuracy. Contributions of each technique to the final accuracy results are quantitatively evaluated in terms of R2 and SEE values and the optimal ANN model is proposed based on the results of the analysis.
- Finally, this paper proves the superior performance of the ANN model by comparing the estimation accuracy of the ANN model with not only that of the previous MLR model but also that of the representative machine learning models including K-NN, random forest, and support vector machine (SVM). It demonstrates practical usefulness of the proposed model in smart fitness applications.
2. Materials and Methods
2.1. Dataset
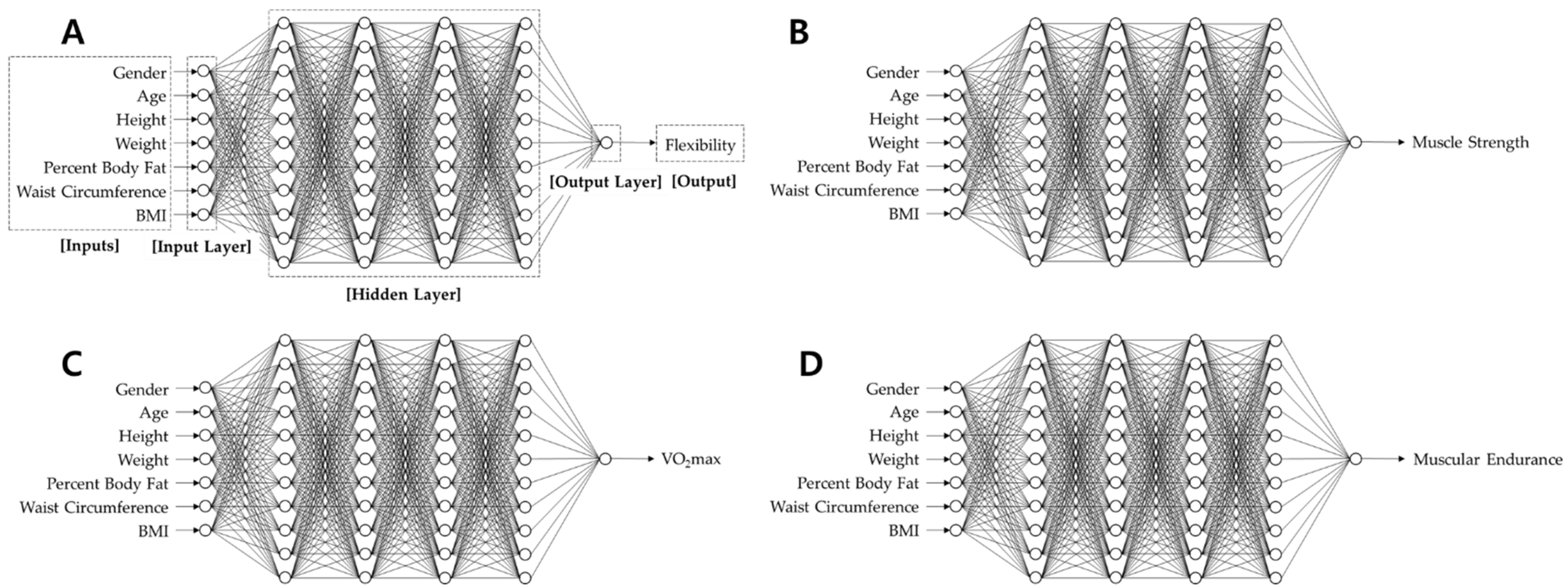
2.2. ANN-Based HRPF Level Estimation Model
2.3. Optimizations for Enhancing Estimation Accuracy of ANN Model
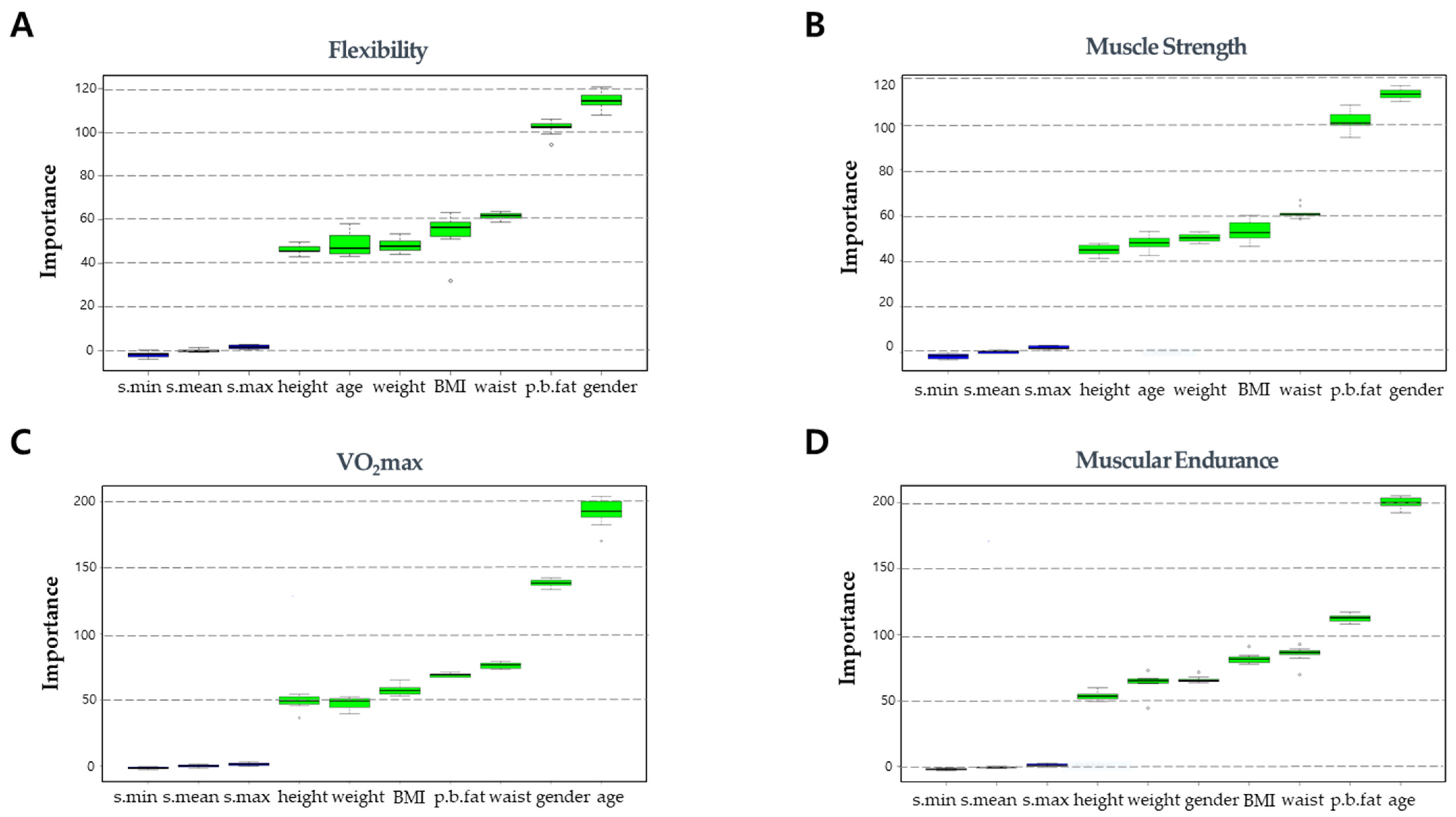
2.3.1. Correlation Analysis between Input and Output Variables
2.3.2. Comparison of Hidden Layer Structures
2.3.3. Standardization of Input Data
2.3.4. Outlier Removal
3. Results
3.1. Input/Output Correlation Analysis
3.2. Effect of Hidden Layer Structure
3.3. Effect of Input Data Standardization
3.4. Effect of Outlier Removal
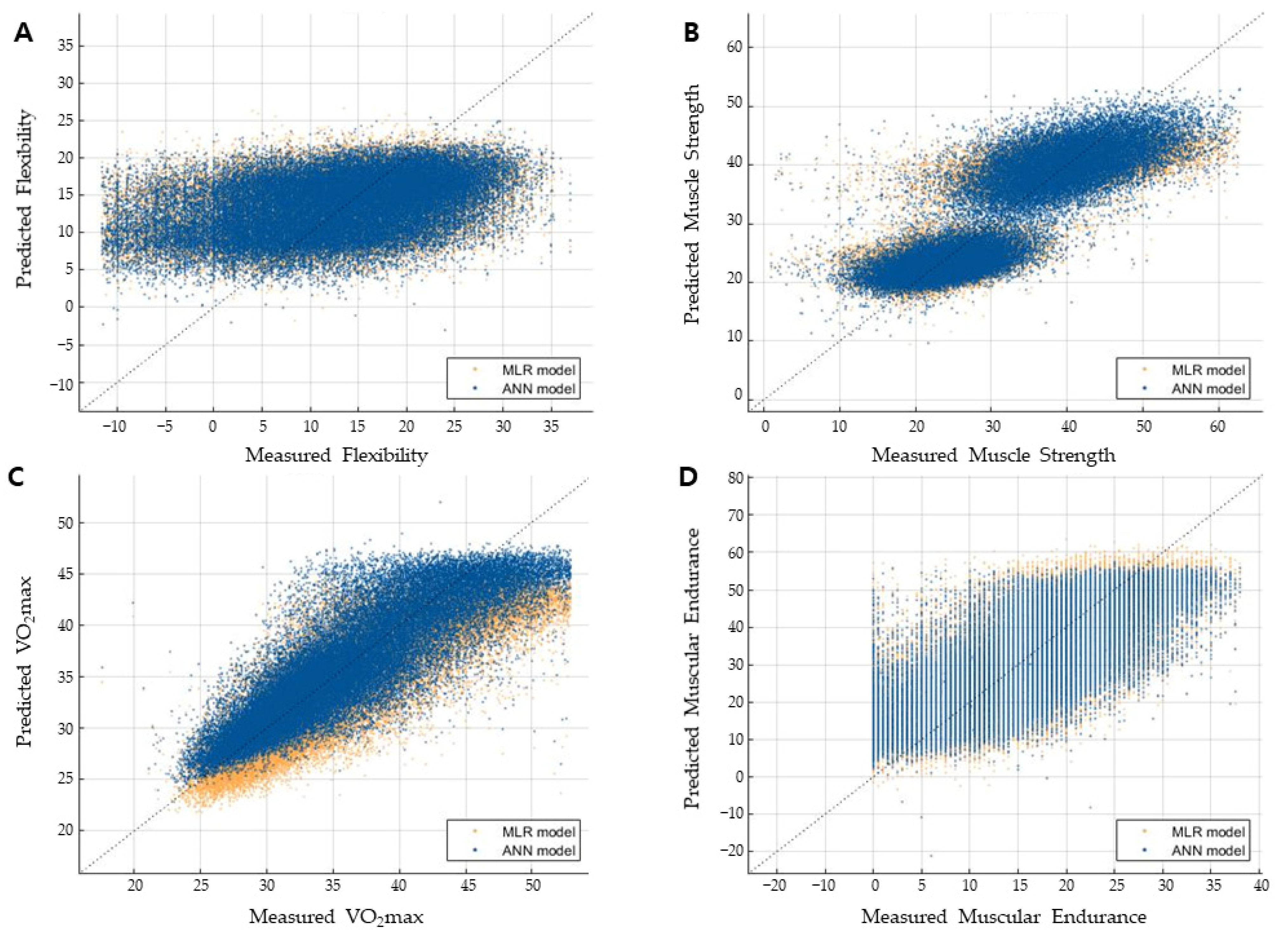
3.5. Performance Comparison with the MLR Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gupta, P.; Agrawal, D.; Chhabra, J.; Dhir, P.K. IoT based smart healthcare kit. In Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies, ICCTICT 2016—Proceedings, New Delhi, India, 11–13 March 2016; pp. 237–242. [Google Scholar]
- Thompson, W.R. Worldwide Survey of Fitness Trends for 2021 Apply It. ACSM’s Health Fit. J. 2020, 25, 10–19. [Google Scholar] [CrossRef]
- Murdoch, T.B.; Detsky, A.S. The inevitable application of big data to health care. JAMA J. Am. Med. Assoc. 2013, 309, 1351–1352. [Google Scholar] [CrossRef]
- Noorbakhsh-Sabet, N.; Zand, R.; Zhang, Y.; Abedi, V. Artificial Intelligence Transforms the Future of Health Care. Am. J. Med. 2019, 132, 795–801. [Google Scholar] [CrossRef]
- Storer, T.W.; Davis, J.A.; Caiozzo, V.J. Accurate prediction of VO2max in cycle ergometry. Med. Sci. Sports Exerc. 1990, 22, 704–712. [Google Scholar] [CrossRef]
- Harvey, D. Assessment of the flexibility of elite athletes using the modified Thomas test. Br. J. Sports Med. 1998, 32, 68–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strand, S.L.; Hjelm, J.; Shoepe, T.C.; Fajardo, M.A. Norms for an isometric muscle endurance test. J. Hum. Kinet. 2014, 40, 93–102. [Google Scholar] [CrossRef] [Green Version]
- Batrakoulis, A. European Survey of Fitness Trends for 2020. ACSM’s Health Fit. J. 2019, 23, 28–35. [Google Scholar] [CrossRef]
- Higgins, J.P. Smartphone Applications for Patients’ Health and Fitness. Am. J. Med. 2016, 129, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, J.J.P.C.; De Rezende Segundo, D.B.; Junqueira, H.A.; Sabino, M.H.; Prince, R.M.I.; Al-Muhtadi, J.; De Albuquerque, V.H.C. Enabling Technologies for the Internet of Health Things. IEEE Access 2018, 6, 13129–13141. [Google Scholar] [CrossRef]
- La Delfa, N.J.; Potvin, J.R. Predicting manual arm strength: A direct comparison between artificial neural network and multiple regression approaches. J. Biomech. 2016, 49, 602–605. [Google Scholar] [CrossRef]
- Aklan, R.; Robergs, R.; Kravitz, L. Prediction of VO2max from an Individualized Submaximal Cycle Ergometer Protocol. J. Exerc. Physiol. Online 2018, 11, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Mahajan, U.; Krishnan, A.; Malhotra, V.; Sharma, D.; Gore, S. Predicting Fitness and Performance of Diving using Machine Learning Algorithms. In Proceedings of the 2019 IEEE Pune Section International Conference (PuneCon), Pune, India, 19–20 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Akay, M.F.; Abut, F.; Çetin, E.; Yarim, I.; Sow, B. Support vector machines for predicting the hamstring and quadriceps muscle strength of college-aged athletes. Turk. J. Electr. Eng. Comput. Sci. 2017, 25, 2567–2582. [Google Scholar] [CrossRef] [Green Version]
- Taha, Z.; Musa, R.M.; Majeed, A.P.A.; Alim, M.M.; Abdullah, M.R. The identification of high potential archers based on fitness and motor ability variables: A Support Vector Machine approach. Hum. Mov. Sci. 2018, 57, 184–193. [Google Scholar] [CrossRef] [PubMed]
- Musa, R.M.; Abdul Majeed, A.P.P.; Taha, Z.; Chang, S.W.; Nasir, A.F.A.; Abdullah, M.R. A machine learning approach of predicting high potential archers by means of physical fitness indicators. PLoS ONE 2019, 14, e020963. [Google Scholar] [CrossRef] [PubMed]
- Ruiz, J.R.; Ramirez-Lechuga, J.; Ortega, F.B.; Castro-Piñero, J.; Benitez, J.M.; Arauzo-Azofra, A.; Sanchez, C.; Sjöström, M.; Castillo, M.J.; Gutierrez, A.; et al. Artificial neural network-based equation for estimating VO2max from the 20 m shuttle run test in adolescents. Artif. Intell. Med. 2008, 44, 233–245. [Google Scholar] [CrossRef]
- Kupusinac, A.; Stokić, E.; Doroslovački, R. Predicting body fat percentage based on gender, age and BMI by using artificial neural networks. Comput. Methods Programs Biomed. 2014, 113, 610–619. [Google Scholar] [CrossRef] [PubMed]
- Mauger, A.R.; Sculthorpe, N. A new VO 2max protocol allowing self-pacing in maximal incremental exercise. Br. J. Sports Med. 2012, 46, 59–63. [Google Scholar] [CrossRef]
- Big Data Market C. Available online: https://www.bigdata-culture.kr/bigdata/user/data_market/detail.do?id=c99df919-f2c9-4ceb-999d-82688c028031 (accessed on 21 July 2020).
- Kim, S.W.; Park, H.Y.; Jung, H.; Lee, J.; Lim, K. Estimation of Health-Related Physical Fitness Using Multiple Linear Regression in Korean Adults: National Fitness Award 2015–2019. Front Physiol. 2021, 12, 668055. [Google Scholar] [CrossRef]
- Korea Institute of Sports Science (KISS). Available online: https://www.sports.re.kr/front/research/project/orginView.do?menu_seq=594&pageno=1&artctrlno=CR_301710&bibctrlno=CR_301710&lib_seq= (accessed on 1 November 2014).
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Schilling, F. The Effect of Batch Normalization on Deep Convolutional Neural Networks; KTH Royal Institute of Technology: Stockholm, Sweden, 2016. [Google Scholar]
- Kaur, H.; Kumari, V. Predictive modelling and analytics for diabetes using a machine learning approach. Appl. Comput. Inform. 2019. ahead of print. [Google Scholar] [CrossRef]
- Rahman, M.; Islam, D.; Mukti, R.J.; Saha, I. A deep learning approach based on convolutional LSTM for detecting diabetes. Comput. Biol. Chem. 2020, 88. [Google Scholar] [CrossRef]
- Mollalo, A.; Rivera, K.M.; Vahedi, B. Artificial Neural Network Modeling of Novel Coronavirus (COVID-19) Incidence Rates across the Continental United States. Int. J. Environ. Res. Public Health 2020, 17, 4204. [Google Scholar] [CrossRef] [PubMed]
- Ali, Z.; Hussain, I.; Faisal, M.; Elashkar, E.E.; Gani, S.; Shehzad, M.A. Selection of appropriate time scale with Boruta algorithm for regional drought monitoring using multi-scaler drought index. Tellus Ser. A Dyn. Meteorol. Oceanogr. 2019, 71, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Data Type | Index | Max | Min | Mean (SD) | |||
|---|---|---|---|---|---|---|---|
| Male | Female | Male | Female | Male | Female | ||
| Physical Information | Age (year) | 64.0 | 64.0 | 19.0 | 19.0 | 34.6 (14.6) | 42.1 (14.7) |
| Height (cm) | 205.5 | 196.3 | 132.9 | 119.5 | 172.8 (6.3) | 159.2 (5.7) | |
| Weight (kg) | 160.0 | 143.5 | 30.4 | 30.2 | 73.3 (10.9) | 58.2 (8.6) | |
| Percent Body Fat (%) | 63.0 | 58.6 | 3.0 | 2.0 | 21.0 (6.7) | 31.0 (6.5) | |
| Waist Circumference (cm) | 149.0 | 150.0 | 50.0 | 50.2 | 81.5 (9.4) | 81.5 (9.3) | |
| BMI (kg/m2) | 48.4 | 47.1 | 11.3 | 11.5 | 24.5 (3.2) | 23.0 (3.3) | |
| Physical Fitness Index | Flexibility (cm) | 52.0 | 40 | −30.0 | −30.0 | 9.2 (9.4) | 15.0 (8.3) |
| Muscule Strength (kg) | 78.0 | 82.2 | 1.0 | 1.0 | 39.8 (7.6) | 23.4 (4.7) | |
| VO2max (mL/kg/min) | 67.0 | 73.8 | 10.0 | 13.5 | 40.5 (5.8) | 31.7 (3.9) | |
| Muscular endurance | 100.0 | 100.0 | 0.0 | 0.0 | 40.3 (14.0) | 22.4 (12.8) | |
| # of Layers | # of Nodes | Flexibility | Muscle Strength | VO2max | Muscular Endurance | ||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | SEE | R2 | SEE | R2 | SEE | R2 | SEE | ||
| 1 | 7 | 0.1795 | 8.3789 | 0.7400 | 5.2151 | 0.7394 | 3.3305 | 0.5083 | 11.2255 |
| 14 | 0.1798 | 8.3773 | 0.7429 | 5.1855 | 0.7332 | 3.3699 | 0.5483 | 10.7598 | |
| 21 | 0.1763 | 8.3954 | 0.7436 | 5.1790 | 0.7280 | 3.4026 | 0.5591 | 10.6302 | |
| 28 | 0.1661 | 8.4471 | 0.7404 | 5.2107 | 0.7280 | 3.4027 | 0.5541 | 10.6897 | |
| 2 | 7 | 0.1775 | 8.3892 | 0.7429 | 5.1863 | 0.7373 | 3.3438 | 0.5523 | 10.7116 |
| 14 | 0.1840 | 8.3563 | 0.7425 | 5.1895 | 0.7238 | 3.4288 | 0.5508 | 10.7298 | |
| 21 | 0.1838 | 8.3570 | 0.7408 | 5.2070 | 0.7237 | 3.4295 | 0.5553 | 10.6761 | |
| 28 | 0.1651 | 8.4522 | 0.7387 | 5.2283 | 0.7140 | 3.4886 | 0.5532 | 10.7010 | |
| 3 | 7 | 0.1731 | 8.4115 | 0.7224 | 5.3888 | 0.7133 | 3.4933 | 0.5493 | 10.7475 |
| 14 | 0.1618 | 8.4688 | 0.7441 | 5.1733 | 0.7315 | 3.3804 | 0.5446 | 10.8032 | |
| 21 | 0.1721 | 8.4170 | 0.7443 | 5.1713 | 0.7237 | 3.4294 | 0.5451 | 10.7977 | |
| 28 | 0.1844 | 8.3540 | 0.7462 | 5.1523 | 0.7387 | 3.3350 | 0.5611 | 10.6060 | |
| 4 | 7 | 0.1764 | 8.3949 | 0.7261 | 5.3522 | 0.7264 | 3.4127 | 0.5441 | 10.8099 |
| 14 | 0.1730 | 8.4122 | 0.7476 | 5.1381 | 0.7275 | 3.4058 | 0.5547 | 10.6826 | |
| 21 | 0.1751 | 8.4016 | 0.7403 | 5.2118 | 0.7224 | 3.4372 | 0.5624 | 10.5903 | |
| 28 | 0.1727 | 8.4139 | 0.7394 | 5.2207 | 0.6889 | 3.6387 | 0.5517 | 10.7189 | |
| Average () | 0.1750 () | 8.4017 () | 0.7401 () | 5.2131 () | 0.7250 () | 3.4206 () | 0.5497 () | 10.7425 () | |
| Model | Flexibility | Muscle Strength | VO2max | Muscular Endurance | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | SEE | R2 | SEE | R2 | SEE | R2 | SEE | |
| Without standardization | 0.1844 | 8.3540 | 0.7476 | 5.1381 | 0.7394 | 3.3305 | 0.5624 | 10.5903 |
| With standardization | 0.1832 | 8.3877 | 0.7462 | 5.1527 | 0.7577 | 3.2136 | 0.5735 | 10.4631 |
| Model | # of Data Removed (%) | Flexibility | Muscle Strength | VO2max | Muscular Endurance | ||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | SEE | R2 | SEE | R2 | SEE | R2 | SEE | ||
| Without | 0 | 0.1832 | 8.3877 | 0.7462 | 5.1527 | 0.7577 | 3.2136 | 0.5735 | 10.4631 |
| IQR | 12,250 (6.19%) | 0.1700 | 7.8868 | 0.7554 | 4.9853 | 0.7630 | 3.0031 | 0.5707 | 10.3421 |
| 3σ | 6532 (3.30%) | 0.1722 | 8.1054 | 0.7529 | 4.9935 | 3.1083 | 0.7578 | 0.5724 | 10.3508 |
| Model | Flexibility | Muscle Strength | VO2max | Muscular Endurance | ||||
|---|---|---|---|---|---|---|---|---|
| R2 | SEE | R2 | SEE | R2 | SEE | R2 | SEE | |
| MLR model | 0.1529 | 8.7200 | 0.7073 | 5.6100 | 0.7191 | 3.9200 | 0.5565 | 10.6500 |
| SVM model | 0.1635 | 8.4604 | 0.7426 | 5.1890 | 0.7494 | 3.2659 | 0.5626 | 10.5879 |
| K-NN model | 0.1764 | 8.3950 | 0.7449 | 5.1653 | 0.7539 | 3.2363 | 0.5735 | 10.4547 |
| Random forest model | 0.1784 | 8.4181 | 0.7445 | 5.1696 | 0.7523 | 3.2472 | 0.5730 | 10.4607 |
| Proposed ANN model | 0.1700 | 7.8868 | 0.7554 | 4.9853 | 0.7630 | 3.0031 | 0.5707 | 10.3421 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-H.; Ju, H.-S.; Lee, S.-H.; Kim, S.-W.; Park, H.-Y.; Kang, S.-W.; Song, Y.-E.; Lim, K.; Jung, H. Estimation of Health-Related Physical Fitness (HRPF) Levels of the General Public Using Artificial Neural Network with the National Fitness Award (NFA) Datasets. Int. J. Environ. Res. Public Health 2021, 18, 10391. https://doi.org/10.3390/ijerph181910391
Lee S-H, Ju H-S, Lee S-H, Kim S-W, Park H-Y, Kang S-W, Song Y-E, Lim K, Jung H. Estimation of Health-Related Physical Fitness (HRPF) Levels of the General Public Using Artificial Neural Network with the National Fitness Award (NFA) Datasets. International Journal of Environmental Research and Public Health. 2021; 18(19):10391. https://doi.org/10.3390/ijerph181910391
Chicago/Turabian StyleLee, Seung-Hun, Hyeon-Seong Ju, Sang-Hun Lee, Sung-Woo Kim, Hun-Young Park, Seung-Wan Kang, Young-Eun Song, Kiwon Lim, and Hoeryong Jung. 2021. "Estimation of Health-Related Physical Fitness (HRPF) Levels of the General Public Using Artificial Neural Network with the National Fitness Award (NFA) Datasets" International Journal of Environmental Research and Public Health 18, no. 19: 10391. https://doi.org/10.3390/ijerph181910391
APA StyleLee, S. -H., Ju, H. -S., Lee, S. -H., Kim, S. -W., Park, H. -Y., Kang, S. -W., Song, Y. -E., Lim, K., & Jung, H. (2021). Estimation of Health-Related Physical Fitness (HRPF) Levels of the General Public Using Artificial Neural Network with the National Fitness Award (NFA) Datasets. International Journal of Environmental Research and Public Health, 18(19), 10391. https://doi.org/10.3390/ijerph181910391