
Predicting Fitness Centre Dropout

 ,
,  and
and
Abstract
:1. Introduction
2. Methods
2.1. Dataset
2.2. Machine Learning Classification Models
2.3. Model Performance
- Sensitivity (SN): True positive rate = TP/(TP + FN);
- Specificity (SP): True negative rate = TN/(TN + FP);
- Precision: True predicted ‘no dropouts’ against all predicted ‘no dropouts’ true or not TP/(TP + FP);
- F1-Score: Combines precision and sensitivity representing their harmonic mean 2 × TP/(2 × TP + FP + FN);
- Receiver Operating Characteristic (ROC) Curve: Representing the model capability to distinguish dropout and non-dropout. Higher AUC (Area Under the Curve) better model prediction 0 and 1.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- IHRSA. European Health Club Report: The Size and Scope of Leading Markets; International Health, Racquet & Sports Club Association (IHRSA): Boston, MA, USA, 2010. [Google Scholar]
- Grantham, W.C.; Patton, R.W.; York, T.D.; Winick, M.L. Health Fitness Management: A Comprehensive Resource for Managing and Operating Programs and Facilities; Human Kinetics: Leeds, UK, 1998; ISBN 978-0-7360-6205-3. [Google Scholar]
- Tharret, S.J.; Peterson, J.A. Fitness Management: A Comprehensive Resource for Developing, Leading, Managing, and Operating a Successful Health, Fitness Club; Healthy Learning: Monterey, CA, USA, 2006. [Google Scholar]
- Avourdiadou, S.; Theodorakis, N. The development of loyalty among novice and experienced customers of sport and fitness centres. Sport Manag. Rev. 2014, 17, 419–431. [Google Scholar] [CrossRef]
- Pedragosa, V.; Cardadeiro, E. Barómetro do Fitness em Portugal 2018; Edições AGAP: Lisbon, Portugal, 2018. [Google Scholar]
- Emeterio, I.C.S.; García-Unanue, J.; Iglesias-Soler, E.; Felipe, J.L.; Gallardo, L. Prediction of abandonment in Spanish fitness centres. Eur. J. Sport Sci. 2018, 19, 217–224. [Google Scholar] [CrossRef] [PubMed]
- Sperandei, S.; Vieira, M.C.; Reis, A. Adherence to physical activity in an unsupervised setting: Explanatory variables for high attrition rates among fitness center members. J. Sci. Med. Sport 2016, 19, 916–920. [Google Scholar] [CrossRef] [PubMed]
- Cooil, B.; Keiningham, T.L.; Aksoy, L.; Hsu, M. A Longitudinal analysis of customer satisfaction and share of wallet: Investigating the moderating effect of customer characteristics. J. Mark. 2007, 71, 67–83. [Google Scholar] [CrossRef] [Green Version]
- Pridgeon, L.; Grogan, S. Understanding exercise adherence and dropout: An interpretative phenomenological analysis of men and women’s accounts of gym attendance and non-attendance. Qual. Res. Sport Exerc. Health 2012, 4, 382–399. [Google Scholar] [CrossRef]
- Pawlowski, T.; Breuer, C.; Wicker, P.; Poupaux, S. Travel time spending behaviour in recreational sports: An econometric approach with management implications. Eur. Sport Manag. Q. 2009, 9, 215–242. [Google Scholar] [CrossRef]
- Ferrand, A.; Robinson, L.; Valette-Florence, P. The intention-to-repurchase paradox: A case of the health and fitness industry. J. Sport Manag. 2010, 24, 83–105. [Google Scholar] [CrossRef]
- Hurley, T. Managing customer retention in the health and fitness industry: A case of neglect. Ir. Mark. Rev. 2004, 17, 23–29. [Google Scholar]
- MacIntosh, E.; Law, B. Should I stay or should I go? Exploring the decision to join, maintain, or cancel a fitness membership. Manag. Sport Leis. 2015, 20, 191–210. [Google Scholar] [CrossRef]
- Bodet, G. Loyalty in sport participation services: An examination of the mediating role of psychological commitment. J. Sport Manag. 2012, 26, 30–42. [Google Scholar] [CrossRef]
- Edward, M.; Sahadev, S. Role of switching costs in the service quality, perceived value, customer satisfaction and customer retention linkage. Asia Pac. J. Mark. Logist. 2011, 23, 327–345. [Google Scholar] [CrossRef]
- Kelleher, J.D.; Namee, B.M.; D’Arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies, 1st ed.; The MIT Press: Cambridge, MA, USA, 2015; ISBN 978-0-262-02944-5. [Google Scholar]
- Verbeke, W.; Martens, D.; Mues, C.; Baesens, B. Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Syst. Appl. 2011, 38, 2354–2364. [Google Scholar] [CrossRef]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Kim, J.W.; Lee, B.H.; Shaw, M.J.; Chang, H.-L.; Nelson, M. Application of decision-tree induction techniques to personalized advertisements on internet storefronts. Int. J. Electron. Commer. 2001, 5, 45–62. [Google Scholar] [CrossRef]
- Yang, Q.; Yin, J.; Ling, C.; Pan, R. Extracting actionable knowledge from decision trees. IEEE Trans. Knowl. Data Eng. 2006, 19, 43–56. [Google Scholar] [CrossRef]
- Emeterio, I.C.S.; Iglesias-Soler, E.; Gallardo, L.; Rodriguez-Cañamero, S.; Unanue, J.F.G. A prediction model of retention in a Spanish fitness centre. Manag. Sport Leis. 2016, 21, 300–318. [Google Scholar] [CrossRef]
- Pinheiro, P.; Cavique, L. Models for increasing retention in regular sports services: Predictive analysis and loyalty actions. In Proceedings of the IEEE 2018 13th Iberian Conference on Information Systems and Technologies (CISTI), Cáceres, Spain, 13–16 June 2018; pp. 1–6. [Google Scholar]
- Pedragosa, V.; Cardadeiro, E. Barómetro do Fitness em Portugal 2020; Edições AGAP: Lisbon, Portugal, 2021. [Google Scholar]
- Continuum Analytics Anaconda Software Distribution. Available online: https://www.anaconda.com/download/ (accessed on 20 July 2017).
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Berry, M.J.A.; Linoff, G. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management, 2nd ed.; Wiley Pub.: Indianapolis, IN, USA, 2004; ISBN 978-0-471-47064-9. [Google Scholar]
- Stoltzfus, J.C. Logistic regression: A brief primer. Acad. Emerg. Med. 2011, 18, 1099–1104. [Google Scholar] [CrossRef]
- Lee, S.J.; Siau, K. A review of data mining techniques. Ind. Manag. Data Syst. 2001, 101, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Loh, W. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Da Gama, J.M.P.; Ferreira, A.C.P.D.L.; Carvalho, D.; Faceli, K.; Lorena, A.C.; Oliveira, M. Extração do Conhecimento de Dados Data Mining; Edições Sílabo: Lisbon, Portugal, 2017; ISBN 978-972-618-914-5. [Google Scholar]
- Coussement, K.; Poel, D.V.D. Churn prediction in subscription services: An application of support vector machines while comparing two parameter-selection techniques. Expert Syst. Appl. 2008, 34, 313–327. [Google Scholar] [CrossRef]
- Milošević, M.; Živić, N.; Andjelković, I. Early churn prediction with personalized targeting in mobile social games. Expert Syst. Appl. 2017, 83, 326–332. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; ISBN 9780387848570. [Google Scholar]
- Buntine, W.; Niblett, T. A further comparison of splitting rules for decision-tree induction. Mach. Learn. 1992, 8, 75–85. [Google Scholar] [CrossRef] [Green Version]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Cervello, E.; Escartí, A.; Guzmán, J.F. Youth sport dropout from the achievement goal theory. Psicothema 2007, 19, 65–71. [Google Scholar]
- Annesi, J.J. Effects of a computer feedback treatment and behavioral support protocol on drop out from a newly initiated exercise program. Percept. Mot. Skills 2007, 105, 55–66. [Google Scholar] [CrossRef]
- Annesi, J.J.; Unruh, J.L. Effects of the Coach Approach® intervention on drop-out rates among adults initiating exercise programs at nine ymcas over three years. Percept. Mot. Skills 2007, 104, 459–466. [Google Scholar] [CrossRef] [PubMed]
- Talley, M. Customer retention: A managers perspective. In The Sport and Fitness Sector; Oakley, B., Rhys, M., Eds.; Routledge: London, UK, 2008; ISBN 978-0-415-45405-6. [Google Scholar]
- García-Fernández, J.; Gálvez Ruíz, P.; Fernández Gavira, J.; Vélez Colón, L. A loyalty model according to membership longevity of low-cost fitness center: Quality, value, satisfaction, and behavioral intention. Rev. Psicol. Deporte 2016, 25, 0107–0110. [Google Scholar]
- Surujlal, J.; Dhurup, M. Establishing and maintaining customer relationships in commercial health and fitness centers in South Africa. Int. J. Trade Econ. Finance 2012, 14–18. [Google Scholar] [CrossRef]



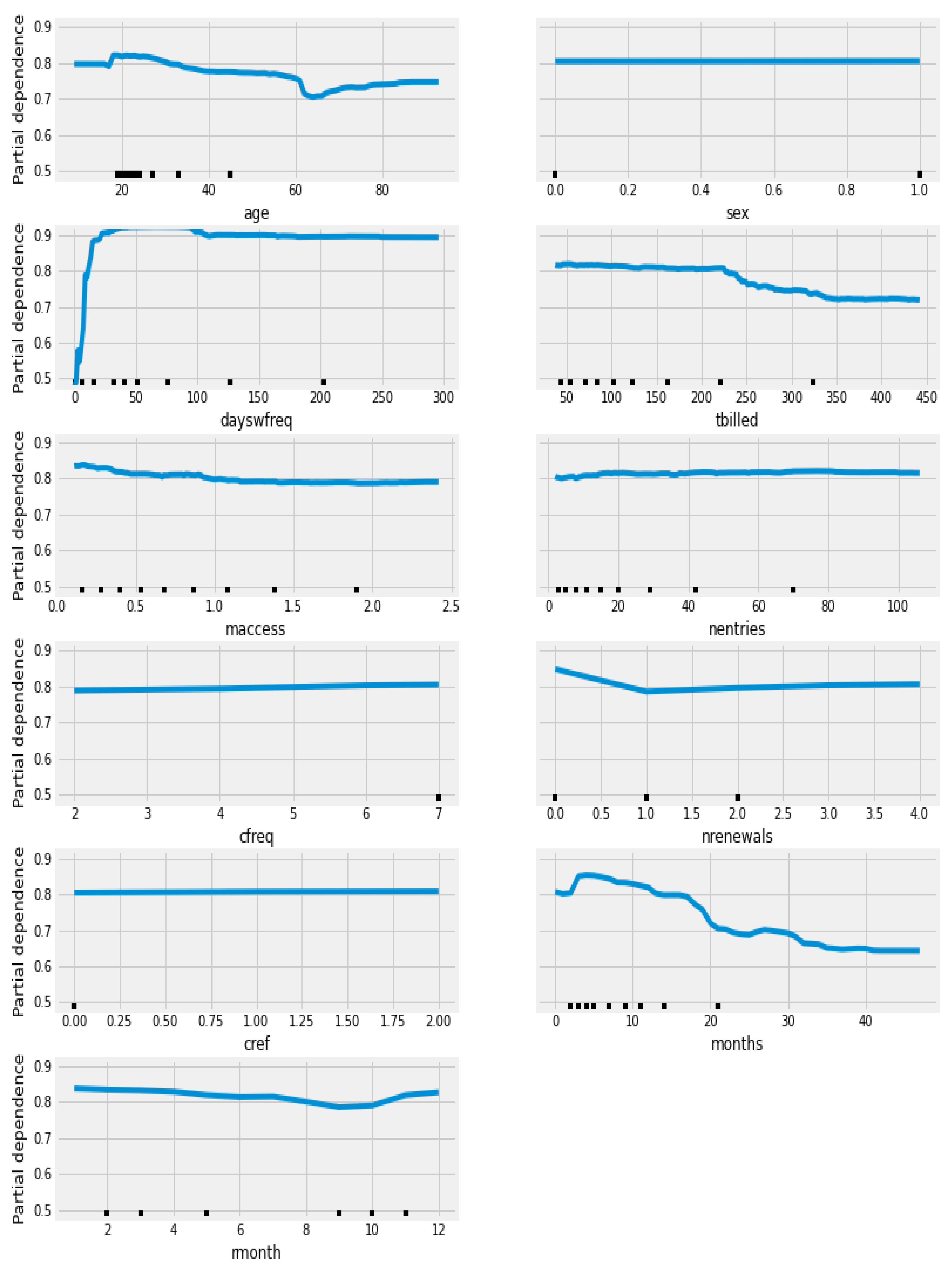{kind=link}
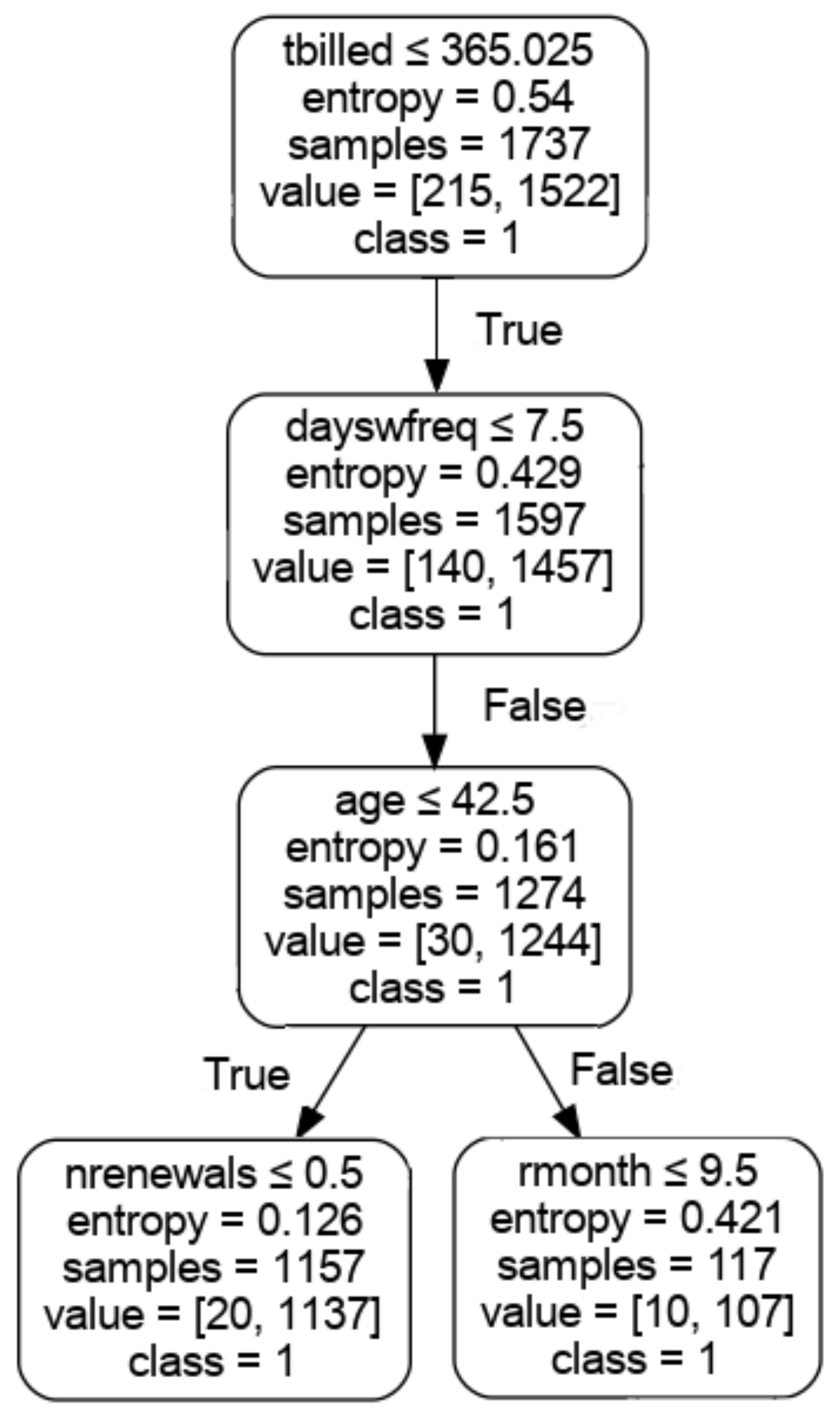{kind=link}
| Variable | Description | Min | Max | Mean (SD *) |
|---|---|---|---|---|
| age | Age of the participants in years | 9 | 93 | 27.87 (11.80) |
| sex | Sex (0—female; 1—male) | 0 | 1 | 0.35 (0.48) |
| dayswfreq | Non-attendance days before dropout | 0 | 991 | 76.40 (101.80) |
| tbilled | Total amount billed during the registration period (values in euros) | 3.60 | 3747.20 | 155.32 (162.45) |
| maccess | Average number of visits per week | 0.01 | 10.33 | 0.89 (0.76) |
| nentries | Total number of visits to the fitness centre that the member made during the registration period | 1 | 585 | 29.06 (41.15) |
| cfreq | Weekly contracted accesses | 2 | 7 | 6.86 (0.72) |
| nrenewals | Number of registration renewals | 0 | 4 | 0.78 (0.90) |
| cref | Number of member referrals | 0 | 2 | 0.01 (0.08) |
| rmonth | Registration month | 1 | 12 | 6.72 (3.53) |
| months | Member enrolment (total time in months) | 0 | 47 | 9.35 (8.22) |
| dropout | Measurement of members’ commitment (0 = active, 1 = dropout) | 0 | 1 | 0.88 (0.33) |
| Performance | LR | DTC | RFC | GBC |
|---|---|---|---|---|
| Accuracy | 0.785 | 0.839 | 0.920 | 0.955 |
| Sensitivity | 0.785 | 0.842 | 0.938 | 0.986 |
| Specificity | 0.786 | 0.819 | 0.790 | 0.735 |
| Precision | 0.963 | 0.970 | 0.969 | 0.963 |
| F1 Score | 0.865 | 0.901 | 0.953 | 0.975 |
| AUC | 0.786 | 0.830 | 0.865 | 0.860 |
| CI * (Lower, Upper) | (0.759, 0.812) | (0.807, 0.853) | (0.845, 0.884) | (0.840, 0.881) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sobreiro, P.; Guedes-Carvalho, P.; Santos, A.; Pinheiro, P.; Gonçalves, C. Predicting Fitness Centre Dropout. Int. J. Environ. Res. Public Health 2021, 18, 10465. https://doi.org/10.3390/ijerph181910465
Sobreiro P, Guedes-Carvalho P, Santos A, Pinheiro P, Gonçalves C. Predicting Fitness Centre Dropout. International Journal of Environmental Research and Public Health. 2021; 18(19):10465. https://doi.org/10.3390/ijerph181910465
Chicago/Turabian StyleSobreiro, Pedro, Pedro Guedes-Carvalho, Abel Santos, Paulo Pinheiro, and Celina Gonçalves. 2021. "Predicting Fitness Centre Dropout" International Journal of Environmental Research and Public Health 18, no. 19: 10465. https://doi.org/10.3390/ijerph181910465
APA StyleSobreiro, P., Guedes-Carvalho, P., Santos, A., Pinheiro, P., & Gonçalves, C. (2021). Predicting Fitness Centre Dropout. International Journal of Environmental Research and Public Health, 18(19), 10465. https://doi.org/10.3390/ijerph181910465