
Optimization of Sample Construction Based on NDVI for Cultivated Land Quality Prediction


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Collection and Processing
2.3. Machine Learning Models
- (1)
- Backpropagation neural network model
- (2)
- Decision Tree model
- (3)
- Random Forest model
- (4)
- Support Vector Machine model
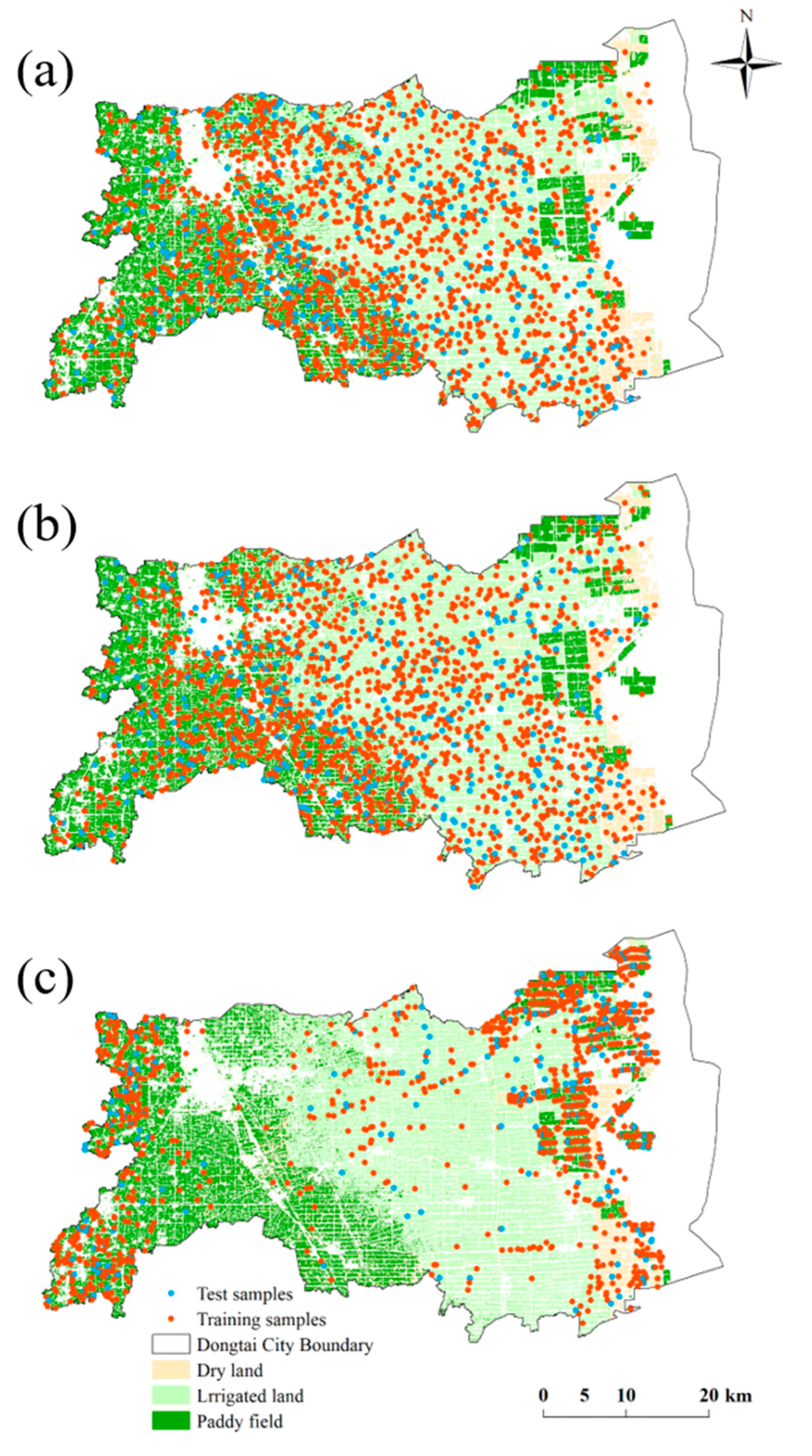
2.4. Sample Construction
- (1)
- Random point sampling
- (2)
- Random patch sampling
- (3)
- Area sequence patch sampling
2.5. Model Validation and Evaluation
2.5.1. Training Set and Test Set
2.5.2. Model Evaluation Index
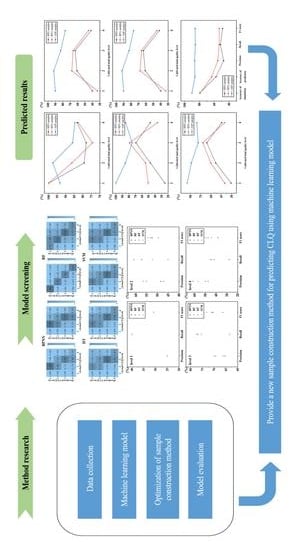
2.6. Establishment of Research Program
- (1)
- Four machine learning models (BPNN, DT, RF, SVM) commonly used in cultivated land quality evaluation were selected.
- (2)
- The training set of RPO samples was used to train the model. Training the model was stopped when the simulation accuracy of the model training set was no longer improved, and the optimal model was formed. The test set of RPO samples was used to verify the model.
- (3)
- The accuracy, precision, recall and F1-score of different models were calculated, and the model with the best classification effect was selected.
- (4)
- RPA samples and ASP samples were applied to the machine learning model with the best performance and compared with RPO samples.
- (5)
- The model was trained with the training set of RPA samples and ASP samples, respectively. Then, the model was validated using the test sets of RPA samples and ASP samples, respectively.
- (6)
- The accuracy, precision, recall and F1-score of the model under different sample construction methods were calculated, and the sample construction method with the highest prediction accuracy was selected.
3. Results
3.1. Model Screening Based on the RPO Samples
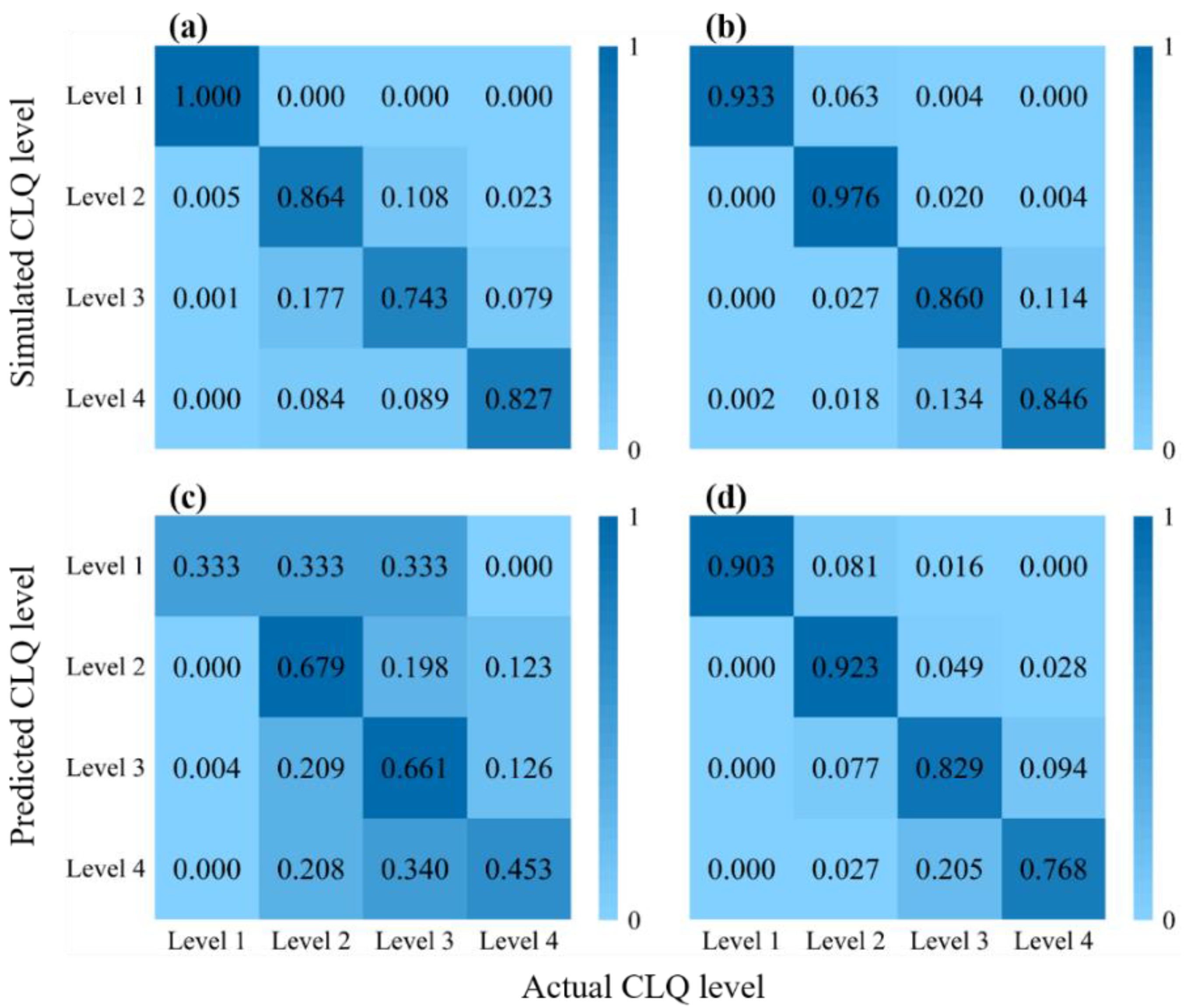
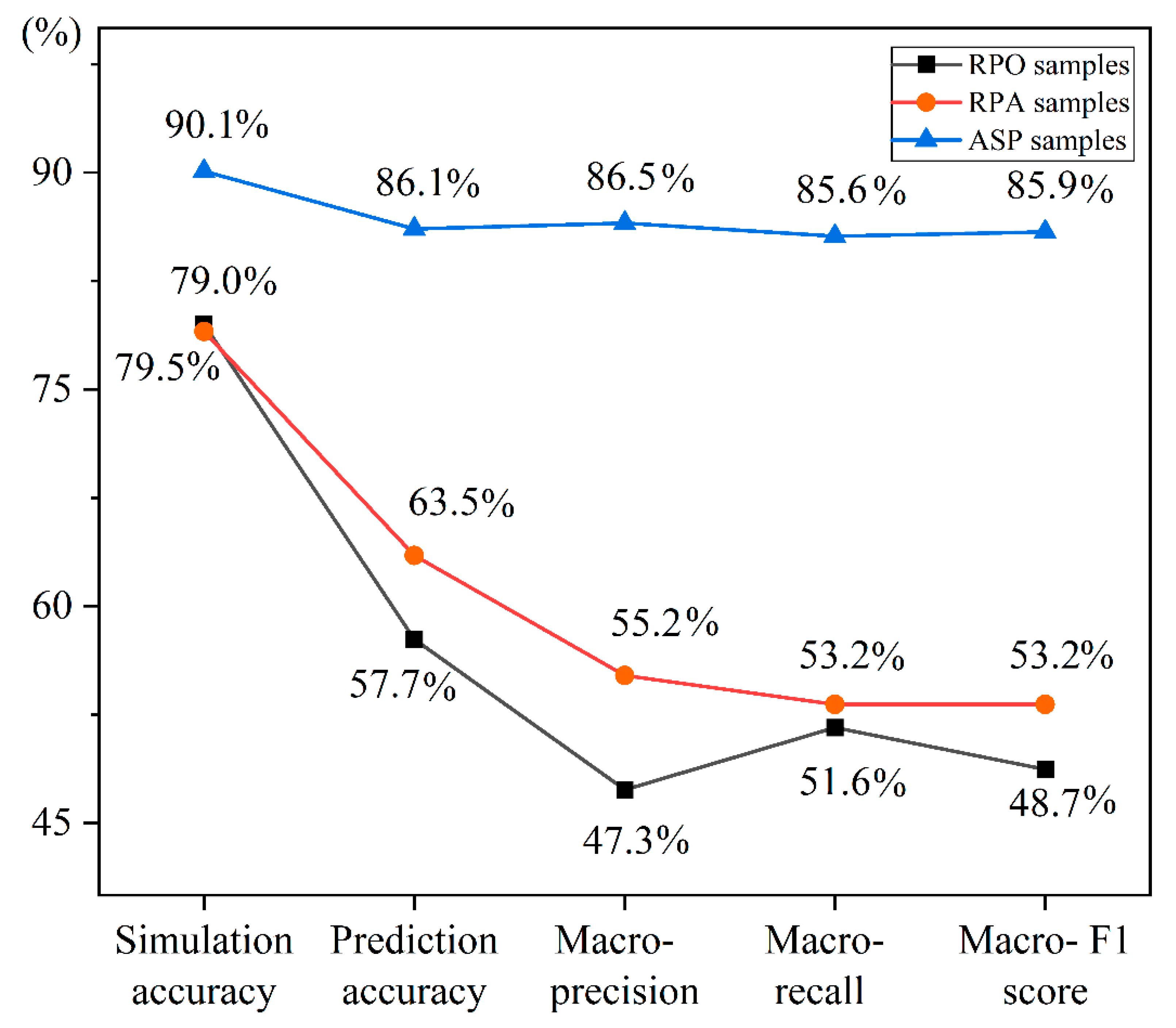
3.2. Optimization of the Sample Construction
3.3. Optimal Sample Construction
4. Discussion
4.1. Selection of CLQ Evaluation Methods
4.2. Effect of the Sample Construction Method on the Model Prediction Accuracy
4.3. Implications for Policy and Decision Making
4.4. Research Limitations and Prospects
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tan, Y.; Chen, H.; Lian, K.; Yu, Z. Comprehensive Evaluation of Cultivated Land Quality at County Scale: A Case Study of Shengzhou, Zhejiang Province, China. Int. J. Environ. Res. Public Health 2020, 17, 1169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Yao, M.; Zhao, Q.; Chen, Z.; Jiang, P.; Li, M.; Chen, D. Delineation of a basic farmland protection zone based on spatial connectivity and comprehensive quality evaluation: A case study of Changsha City, China. Land Use Policy 2021, 101, 105145. [Google Scholar] [CrossRef]
- Foley, J.A.; Ramankutty, N.; Brauman, K.A.; Cassidy, E.S.; Gerber, J.S.; Johnston, M.; Mueller, N.D.; O’Connell, C.; Ray, D.K.; West, P.C.; et al. Solutions for a cultivated planet. Nature 2011, 478, 337–342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, Y.; Duan, W.; Fleskens, L.; Li, M.; Hao, J. Study on evaluation of regional cultivated land quality based on resource-asset-capital attributes and its spatial mechanism. Appl. Geogr. 2020, 125, 102284. [Google Scholar] [CrossRef]
- Fu, G.; Bai, W. Advances and prospects of evaluating cultivated land quality. Resour. Sci. 2015, 37, 226–236. [Google Scholar]
- Wang, Y.; Li, X.; He, H.; Xin, L.; Tan, M. How reliable are cultivated land assets as social security for Chinese farmers? Land Use Policy 2020, 90, 104318. [Google Scholar] [CrossRef]
- Su, S.; Zhang, Q.; Zhang, Z.; Zhi, J.; Wu, J. Rural settlement expansion and paddy soil loss across an ex-urbanizing watershed in eastern coastal China during market transition. Reg. Environ. Chang. 2011, 11, 651–662. [Google Scholar] [CrossRef]
- Kong, X. China must protect high-quality arable land. Nature 2014, 506, 7. [Google Scholar] [CrossRef]
- Zhao, R.; Wu, K.; Li, X.; Gao, N.; Yu, M. Discussion on the Unified Survey and Evaluation of Cultivated Land Quality at County Scale for China’s 3rd National Land Survey: A Case Study of Wen County, Henan Province. Sustainability 2021, 13, 2513. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Guo, L. Towards realistic assessment of cultivated land quality in an ecologically fragile environment: A satellite imagery-based approach. Appl. Geogr. 2010, 30, 271–281. [Google Scholar] [CrossRef]
- Zhu, Q.; Liao, K.; Xu, Y.; Yang, G.; Wu, S.; Zhou, S. Monitoring and prediction of soil moisture spatial-temporal variations from a hydropedological perspective: A review. Soil Res. 2012, 50, 625–637. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, Z.; Yang, Y.; Guo, Y. Status and Prospect of Agricultural Remote Sensing. Trans. Chin. Soc. Agric. Mach. 2015, 46, 247–260. [Google Scholar]
- Linna, F.; Jinping, S. Cultivated Land Quality Assessment Based on SPOT Multispectral Remote Sensing Image: A Case Study in Jimo City of Shandong Province. Prog. Geogr. 2008, 27, 71–78. [Google Scholar]
- Wang, Z.; Wang, L.; Xu, R.; Huang, H.; Wu, F. GIS and RS based Assessment of Cultivated Land Quality of Shandong Province. Procedia Environ. Sci. 2012, 12, 823–830. [Google Scholar] [CrossRef] [Green Version]
- Xia, Z.; Peng, Y.; Liu, S.; Liu, Z.; Wang, G.; Zhu, A.X.; Hu, Y. The Optimal Image Date Selection for Evaluating Cultivated Land Quality Based on Gaofen-1 Images. Sensors 2019, 19, 4937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guan, Y.; Zou, Z.; Zhang, X.; Min, C. Research on the Inversion Model of Cultivated Land Quality Based on Normalized Difference Vegetation Index. Chin. J. Soil Sci. 2018, 49, 779–787. [Google Scholar]
- Zakarya, Y.M.; Metwaly, M.M.; AbdelRahman, M.A.E.; Metwalli, M.R.; Koubouris, G. Optimized Land Use through Integrated Land Suitability and GIS Approach in West El-Minia Governorate, Upper Egypt. Sustainability 2021, 13, 12236. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Hegde, R.; Singh, S.K. Spatial prediction of major soil properties using Random Forest techniques A case study in semi-arid tropics of South India. Geoderma Reg. 2017, 10, 154–162. [Google Scholar] [CrossRef]
- Magidi, J.; Nhamo, L.; Mpandeli, S.; Mabhaudhi, T. Application of the Random Forest Classifier to Map Irrigated Areas Using Google Earth Engine. Remote Sens. 2021, 13, 876. [Google Scholar] [CrossRef]
- Zhu, M.; Liu, S.; Xia, Z.; Wang, G.; Hu, Y.; Liu, Z. Crop Growth Stage GPP-Driven Spectral Model for Evaluation of Cultivated Land Quality Using GA-BPNN. Agriculture 2020, 10, 318. [Google Scholar] [CrossRef]
- Lin, C.; Hu, Y.; Liu, Z.; Peng, Y.; Wang, L.; Peng, D. Estimation of Cultivated Land Quality Based on Soil Hyperspectral Data. Agriculture 2022, 12, 93. [Google Scholar] [CrossRef]
- Samasse, K.; Hanan, N.P.; Tappan, G.; Diallo, Y. Assessing Cropland Area in West Africa for Agricultural Yield Analysis. Remote Sens. 2018, 10, 1785. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Liu, J.; Zhang, J. Evaluation method and model analysis for productivity of cultivated land. Trans. Chin. Soc. Agric. Eng. 2014, 30, 204–210. [Google Scholar]
- Duo, L.; Hu, Z. Soil Quality Change after Reclaiming Subsidence Land with Yellow River Sediments. Sustainability 2018, 10, 4310. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, H.; Zhang, H.; Liber, K. A comprehensive support vector machine-based classification model for soil quality assessment. Soil Tillage Res. 2016, 155, 19–26. [Google Scholar] [CrossRef]
- Fan, S.; Qiu, L.; Ru, K.; Chen, Q.; Hu, Y. Classification method of agricultural land quality based on back-propagation neural network and support vector machine. J. China Agric. Univ. 2018, 23, 138–148. [Google Scholar]
- Li, Y.; Zhang, Y.; Zhao, G.; Li, T.; Li, J.; Dou, J.; Fan, R. Remote sensing inversion and application for soil fertility of cultivated land in the hilly areas of central-south Shandong of China. Trans. Chin. Soc. Agric. Eng. 2020, 36, 269–278. [Google Scholar]
- Liu, S.; Peng, Y.; Xia, Z.; Hu, Y.; Wang, G.; Zhu, A.X.; Liu, Z. The GA-BPNN-Based Evaluation of Cultivated Land Quality in the PSR Framework Using Gaofen-1 Satellite Data. Sensors 2019, 19, 5127. [Google Scholar] [CrossRef] [Green Version]
- Du, F.; Zhu, A.X.; Liu, J.; Yang, L. Predictive mapping with small field sample data using semi-supervised machine learning. Trans. GIS 2020, 24, 315–331. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, L.; Ma, T.; Shen, F.; Cai, Y.; Zhou, C. A self-training semi-supervised machine learning method for predictive mapping of soil classes with limited sample data. Geoderma 2021, 384, 114809. [Google Scholar] [CrossRef]
- Sheng, Y.; Liu, W.; Xu, H.; Gao, X. The Spatial Distribution Characteristics of the Cultivated Land Quality in the Diluvial Fan Terrain of the Arid Region: A Case Study of Jimsar County, Xinjiang, China. Land 2021, 10, 896. [Google Scholar] [CrossRef]
- Qiu, L.; Zhu, J.; Pan, Y.; Wu, S.; Dang, Y.; Xu, B.; Yang, H. The positive impacts of landscape fragmentation on the diversification of agricultural production in Zhejiang Province, China. J. Clean. Prod. 2020, 251, 119722. [Google Scholar] [CrossRef]
- Zhou, X. Quality Grades of Newly Cultivated Land and Factors Influencing Grain Productivity in Loess Tableland Area. Bull. Soil Water Conserv. 2020, 40, 237–243. [Google Scholar]
- Li, X.; Yu, M.; Ma, J.; Luo, Z.; Chen, F.; Yang, Y. Identifying the Relationship between Soil Properties and Rice Growth for Improving Consolidated Land in the Yangtze River Delta, China. Sustainability 2018, 10, 3072. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Wu, K.; Zhao, H.; Zhao, R.; Li, T. Arrangement of High-Standard Basic Farmland Construction Based on Village-region Cultivated Land Quality Uniformity. Chin. Geogr. Sci. 2019, 29, 325–340. [Google Scholar] [CrossRef] [Green Version]
- Zeng, R.; Zhao, R.; Liang, Y. Cultivated land quality assessment based on AHP-grey correlation analysis method taking Xiangyang city of Hubei province as an example. Sci. Surv. Mapp. 2018, 43, 90–96. [Google Scholar]
- Peng, Y.; Zhao, L.; Hu, Y.; Wang, G.; Wang, L.; Liu, Z. Prediction of Soil Nutrient Contents Using Visible and Near-Infrared Reflectance Spectroscopy. Isprs Int. J. Geo-Inf. 2019, 8, 437. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.W.; Ding, Y.; Wan, H.P. Machine learning approaches for wind speed forecasting using long-term monitoring data: A comparative study. Smart Struct. Syst. 2019, 24, 733–744. [Google Scholar]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Heil, J.; Michaelis, X.; Marschner, B.; Stumpe, B. The power of Random Forest for the identification and quantification of technogenic substrates in urban soils on the basis of DRIFT spectra. Environ. Pollut. 2017, 230, 574–583. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Mishra, A.K.; Yu, Z. Evaluating uncertainties in multi-layer soil moisture estimation with support vector machines and ensemble Kalman filtering. J. Hydrol. 2016, 538, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Estevez, V.; Beucher, A.; Mattback, S.; Boman, A.; Auri, J.; Bjork, K.-M.; Osterholm, P. Machine learning techniques for acid sulfate soil mapping in southeastern Finland. Geoderma 2022, 406, 115446. [Google Scholar] [CrossRef]
- Wang, F.; Yang, S.; Yang, W.; Yang, X.; Ding, J. Comparison of machine learning algorithms for soil salinity predictions in three dryland oases located in Xinjiang Uyghur Autonomous Region (XJUAR) of China. Eur. J. Remote Sens. 2019, 52, 256–276. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Chang, C.; Wang, Z.; Qi, G.; Dong, C.; Zhao, G. Upscaling Remote Sensing Inversion Model of Wheat Field Cultivated Land Quality in the Huang-Huai-Hai Agricultural Region, China. Remote Sens. 2021, 13, 5095. [Google Scholar] [CrossRef]
- Ge, G.; Shi, Z.; Zhu, Y.; Yang, X.; Hao, Y. Land use/cover classification in an arid desert-oasis mosaic landscape of China using remote sensed imagery: Performance assessment of four machine learning algorithms. Glob. Ecol. Conserv. 2020, 22, e00971. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Statnikov, A.; Wang, L.; Aliferis, C.F. A comprehensive comparison of random forests and support vector machines for microarray-based cancer classification. BMC Bioinform. 2008, 9, 319. [Google Scholar] [CrossRef] [Green Version]
- Zeraatpisheh, M.; Ayoubi, S.; Jafari, A.; Tajik, S.; Finke, P. Digital mapping of soil properties using multiple machine learning in a semi-arid region, central Iran. Geoderma 2019, 338, 445–452. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Liu, L.; Zhai, M. Prediction for short-term traffic flow based on modified PSO optimized BP neural network. Syst. Eng.-Theory Pract. 2012, 32, 2045–2049. [Google Scholar]
- Lim, C.S.; Mohamad, E.T.; Motahari, M.R.; Armaghani, D.J.; Saad, R. Machine Learning Classifiers for Modeling Soil Characteristics by Geophysics Investigations: A Comparative Study. Appl. Sci. 2020, 10, 5734. [Google Scholar] [CrossRef]
- Tang, Z.; Zhou, W.; Yang, H.; Xie, X.; Hu, Y. Evaluation of Cultivated Land Quality Based on Interactive Logistic Regression Model. Ecol. Environ. Sci. 2020, 29, 2394–2403. [Google Scholar]
- Lin, Z.; Ren, X.; Zhu, A.; Zhao, X.; Hu, Y. Research on the index system of cultivated land quality grading based on random forest algorithm. J. South China Agric. Univ. 2020, 41, 38–48. [Google Scholar]
- Chagas, C.D.S.; Koenow Pinheiro, H.S.; de Carvalho Junior, W.; Cunha dos Anjos, L.H.; Pereira, N.R.; Bhering, S.B. Data mining methods applied to map soil units on tropical hillslopes in Rio de Janeiro, Brazil. Geoderma Reg. 2017, 9, 47–55. [Google Scholar] [CrossRef]
- Meier, M.; de Souza, E.; Francelino, M.R.; Fernandes Filho, E.I.; Goncalves Reynaud Schaefer, C.E. Digital Soil Mapping Using Machine Learning Algorithms in a Tropical Mountainous Area. Rev. Bras. Cienc. Do Solo 2018, 42, e0170421. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Ouyang, Z.; Li, Y.; Li, F. Cultivated land use change in China, 1999–2007: Policy development perspectives. J. Geogr. Sci. 2012, 22, 1061–1078. [Google Scholar] [CrossRef]
- Liu, L.; Zhou, D.; Chang, X.; Lin, Z. A new grading system for evaluating China’s cultivated land quality. Land Degrad. Dev. 2020, 31, 1482–1501. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted | Positive | True Positive (TP) | False Positive (FP) |
| Negative | False Negative (FN) | True Negative (TN) | |
| Machine Learning Model | The Accuracy of Training Dataset | The Accuracy of Test Dataset |
|---|---|---|
| BPNN | 66.4% | 60.6% |
| RF | 79.5% | 57.7% |
| DT | 64.4% | 60.9% |
| SVM | 65.0% | 63.0% |
| Samples | The Accuracy of Training Dataset | The Accuracy of Test Dataset |
|---|---|---|
| RPA-RF | 79.0% | 63.5% |
| ASP-RF | 90.1% | 86.1% |
| CLQ Level | Sample Construction Method | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Level 1 | RPA-RF | 50.5% | 33.3% | 40.0% |
| ASP-RF | 100% | 90.3% | 94.9% | |
| Level 2 | RPA-RF | 54.5% | 67.9% | 60.5% |
| ASP-RF | 85.6% | 92.2% | 88.8% | |
| Level 3 | RPA-RF | 79.2% | 66.1% | 72.0% |
| ASP-RF | 75.2% | 82.9% | 78.9% | |
| Level 4 | RPA-RF | 36.4% | 45.3% | 40.3% |
| ASP-RF | 85.1% | 76.8% | 80.8% | |
| Macro Average | RPA-RF | 55.2% | 53.2% | 53.2% |
| ASP-RF | 86.5% | 85.6% | 85.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Wang, J.; Ge, L.; Zhou, Y.; Zhou, S. Optimization of Sample Construction Based on NDVI for Cultivated Land Quality Prediction. Int. J. Environ. Res. Public Health 2022, 19, 7781. https://doi.org/10.3390/ijerph19137781
Li C, Wang J, Ge L, Zhou Y, Zhou S. Optimization of Sample Construction Based on NDVI for Cultivated Land Quality Prediction. International Journal of Environmental Research and Public Health. 2022; 19(13):7781. https://doi.org/10.3390/ijerph19137781
Chicago/Turabian StyleLi, Chengqiang, Junxiao Wang, Liang Ge, Yujie Zhou, and Shenglu Zhou. 2022. "Optimization of Sample Construction Based on NDVI for Cultivated Land Quality Prediction" International Journal of Environmental Research and Public Health 19, no. 13: 7781. https://doi.org/10.3390/ijerph19137781
APA StyleLi, C., Wang, J., Ge, L., Zhou, Y., & Zhou, S. (2022). Optimization of Sample Construction Based on NDVI for Cultivated Land Quality Prediction. International Journal of Environmental Research and Public Health, 19(13), 7781. https://doi.org/10.3390/ijerph19137781