1. Introduction
Cardiovascular disease (CVD) has become the second major cause of death of non-communicable diseases (NCDs) for several years. Although the trend of NCD mortality was decreased over the last 20 years, the COVID-19 pandemic has aggravated that trend by increasing the risk of illness and death for the existing NCD patient [
1].
An electrocardiogram (ECG) signal, consisting of the P, T, and U waves and the QRS complex, represents the electrical activity of the heart [
2]. For the diagnosis and treatment of CVD, monitoring and recording of the ECG signals are required. The ECG signal can represent electrical activities, heart rate variability (HRV), and abnormalities of the heart. One approach to the ECG application is telemedicine, which is the implementation of the internet of things (IoT), wireless sensor networks, and embedded systems in the medical system. Also, multi-lead ECG acquisition, long-term monitoring and recording, higher resolution, and frequency of the signal are required for better ECG monitoring and diagnosis. To improve the performance and efficiency of the data transmission, data storage, and clinical application, the data compression process for the ECG signal is important, especially for those requirements mentioned before.
The compression method for the ECG signal is approached in two directions, i.e., lossy and lossless compression. Lossy compression significantly has a higher compression ratio than lossless compression, where the compression ratio is the ratio of the original data size to the compressed data size. However, the lossy compression generally has some reconstruction error which means the reconstructed signal value is different from the original one. While the lossless term for the ECG signal compression implies no error from the reconstructed signal.
The ECG compression method can also be categorized into three techniques, i.e., direct-time domain, transform domain, and parameter extraction [
3]. The direct-time technique compresses the data in the time domain directly by extracting the significant samples and removing redundancies. The transform domain technique compresses the data by transforming the data to another domain, for example, Fourier transform, wavelet transform, discrete cosine transform, etc. The parameter extraction technique compresses the data by extracting the characteristics of features of the signal, for example, linear prediction, complex or peak extraction, neural network approach, etc. In recent years, most of the compression methods have been based on two main approaches, i.e., the linear prediction technique and the transform domain technique. In addition, the coding and data packaging techniques are also implemented to maximize the compression performance.
Tsai and Kuo [
3] proposed the adaptive linear prediction with content-adaptive Golomb–Rice coding. Tsai and Tsai [
4] proposed the multi-channel adaptive linear prediction with a modified Golomb–Rice coding method, and Tsai et al. [
5] also implemented the method in [
4] on Very Large-Scale Integration (VLSI). This work compressed the 12-lead ECG signal by using four reference leads to calculate the other eight leads of the signals. The fuzzy theory and exponential weighting technique were applied to the adaptive linear prediction. Deepu et al. [
6] introduced sign-sign least mean square (SSLMS) adaptive linear prediction with the Savitzky-Golay filter. Deepu et al. [
7] proposed linear prediction and fixed-length data packaging and also introduced the 1st to 4th order of the linear prediction function for the ECG signal. Arnavut [
8] introduced the Burrow-Wheeler transform with the autoregressive (AR) model, the Move-to-front coder, and the Inversion ranks coder with the linear prediction compression method. Luo et al. [
9] proposed the adaptive linear prediction based on a fuzzy decision with 2-stage Huffman coding implemented on VLSI. Jia et al. [
10] proposed the dual-mode linear prediction compression method with context-based error modeling and modified Golomb–Rice coding. Tseng et al. [
11] introduced the compression method using Takagi-Sugeno fuzzy neural network with predictive coding. Miaou and Chao [
12] proposed wavelet-based vector quantization for lossless compression with a unified vector quantization framework. Koski [
13] introduced an example of ECG compression with various encoding methods, including 1st and 2nd-order linear prediction, Gamma coding, Huffman coding, LZ-77 method, and complex extraction. Giuseppe et al. [
14] proposed an ECG lossless compression method using the RAKE algorithm with simple prediction. Zhou [
15] introduced the K-means clustering for lossless ECG compression by applying the K-means clustering with the QRS complex and the 1st-order differential for non-QRS region. Li et al. [
16] proposed the differential linear prediction method with modified variable-length coding.
This paper is organized as follows. The proposed method and the related techniques, including the prediction error-based linear prediction, the modified Golomb–Rice coding, the data reconstruction process, and the linear prediction coefficient determination, are described in
Section 2.
Section 3 describes the 3 ECG data sets used in this research. The experimental results are presented and discussed in
Section 4 and
Section 5, respectively.
Section 6 then concludes the paper.
2. Materials and Methods
The proposed compression method aims to increase the compression ratio, which is the ratio of the original data size to the compressed data size while maintaining the lossless feature. In addition, the compression method was designed to be operable in real time without determining any parameters or thresholds. The method proposed in this work is based on the lossless compression concept. The adaptive linear prediction was introduced in recent works where the linear prediction function was changed according to the trend of the ECG signal. However, this concept does not bring the lowest linear prediction error, especially in regions between intervals, abnormal beats, and noisy regions. In addition, the thresholds of some parameters for determining the linear prediction functions may be changed when the data sets or the acquisition setups of the ECG signals are different. The encoding process in [
5] is applied in this work since the process can adaptively adjust the parameters according to the input signal. The overall scheme of the proposed ECG compression method comprising the compression stage and reconstruction stage is shown in
Figure 1.
The compression stage for ECG signal in this work includes 2 processes, i.e., the prediction error-based adaptive linear prediction and the Golomb–Rice coding. The concept of this compression stage is to minimize the ECG signal level into the prediction error for each sample by using linear prediction and to encode the prediction error to the binary format by using length-variable coding. Meanwhile, the reconstruction of the compressed signal data can be done by reversing the compression processes. The related techniques are described in more detail next.
2.1. Prediction Error-Based Adaptive Linear Prediction
The linear prediction has been implemented in many related works for ECG compression since it has the benefit of low complexity for implementation in hardware such as Silicon-on-Chip (SoC) and Field Programmable Gate Array (FPGA). In this research, we exploited the modified forward linear prediction for the linear prediction process. The predicted value
for the linear prediction order p of the signal
can be predicted from the linear combination of the past signal value
with the linear prediction function in Equation (1) where
are the linear prediction coefficients,
and the prediction error
of the prediction order p can be defined with Equation (2), i.e.,
Therefore, the main factor that affects the compression ratio in this approach is the prediction error. The compression ratio can be maximized by minimizing the prediction error. This means the linear prediction order and the linear prediction coefficients must be determined or selected appropriately for each ECG signal. One of the methods to determine the linear prediction coefficients is by using the autocorrelation method, which can be solved by using the Yule–Walker equations with the Levinson–Durbin algorithm [
17]. In terms of adaptive linear prediction (ALP), the order of the linear prediction function can be changed following the trends or the region of the ECG signal to give the lowest prediction error. We initially proposed a compression method and tested it on small data in [
18]. The algorithm of the prediction error-based adaptive linear prediction consists of 2 steps.
The first step is to calculate the prediction value and the prediction error of each linear prediction function from the 1st to 4th order. These coefficients of the linear prediction were used in many related works using the triangle of binomial transform coefficients like Pascal’s triangle. All 4 linear prediction functions are shown in Equations (3)–(6), respectively.
The second step is to compare the absolute value of each prediction error from the first step. The smallest absolute prediction error is chosen to be the determined absolute prediction error as shown in Equation (7),
The block diagram that summarizes the prediction error-based adaptive linear prediction method is shown in
Figure 2.
Figure 3 illustrates an ECG signal from the MIT Arrhythmia database record number “100” along with its prediction errors from the 1st to 4th linear prediction orders and the determined prediction error from Equation (7). We can see that the lower order of linear prediction function yields a better prediction error in the flat region, whereas the higher order yields a better prediction error in the high slope region.
2.2. Modified Golomb–Rice Coding
The concept of entropy coding is to encode the data in length-variable code format. Many related works introduced Huffman coding and Golomb–Rice coding for data compression since they are lossless compression methods. Golomb–Rice coding was introduced by Solomon W. Golomb [
19] and was modified by Robert F. Rice [
20,
21]. The idea of this method is to convert the data value to the quotient and remainder by using the power of 2, which is suitable for storing the compressed data in binary format.
The modified Golomb–Rice coding process converts the prediction error to a non-negative integer value since the prediction error from the linear prediction process is the signed integer value, while the encoding input must be a non-negative value [
5]. For the non-negative value
, the prediction error
can be converted by Equation (8).
The non-negative prediction error is then encoded into the quotient and remainder by using the power
of 2 in Equations (9) and (10),
where
is the base-2 logarithm of the mean absolute error (MAE) of the 3 latest samples, defined as Equations (11) and (12),
The compressed data
includes the quotient
which is encoded in unary format, one of the ‘0′ bit for the quotient and the remainder separation, and the remainder
, which is encoded in binary format, i.e.,
The length of the compressed data depends upon the absolute prediction error and the parameter
. The block diagram of the Golomb–Rice coding can be shown in
Figure 4.
The flowchart of the proposed ECG lossless compression method is shown in
Figure 5.
2.3. Data Reconstruction Process
The ECG signal can be reconstructed back by reversing the compression process. The compressed data is encoded with the modified Golomb–Rice coding as described earlier. Then the reconstructed ECG signal value
can be computed with Equation (2) since
can be computed with the 4 recently reconstructed signals, and
is received as the compressed data. The reconstructed signal
will be the same as the original ECG data
. Hence, this is a lossless compression method since there is no reconstruction error. Note that the first 4 samples of the ECG signal data must be encoded and stored directly to compute the 1st to 4th order of the linear prediction at the compression and reconstruction process. The data packet of the compressed data is shown in
Figure 6.
Figure 7 illustrates the proof of the lossless compression method. The first plot is an example of ECG signal data from the record number “100” with 2 s in time duration. The second plot is the prediction error that is determined before the encoding process. Then the third plot is the decoded prediction error from the compressed data, whereas the fourth plot is the reconstructed ECG signal data. The last plot shows the difference between the original data and the reconstructed data to confirm that there is no reconstruction error in the proposed method. The compression ratio achieved from this example is 3.63.
2.4. Linear Prediction Coefficient Determination
As for a linear prediction-based ECG compression method, the prediction order and coefficients are very crucial. Some questions still remain to answer, for example, which of Equations (1)–(4) is the best for ECG signal prediction? Are the coefficients in those equations good enough? Hence, they deserve a close investigation of how or how well we could come up with them. Consider a function that predicts the current sample by using the linear combination of the past samples as in Equation (1); the linear prediction coefficients are a set of coefficients that minimize the prediction error
One of the approaches to determine the coefficients
, k = 1, 2, …, p, is by using the autocorrelation method [
17]. Yule–Walker equations were used to solve the coefficients with the autocorrelation of the signal
, i.e., solve the following equation:
where
is the autocorrelation of
for time lag
. This equation can be solved by using the well-known Levinson–Durbin recursive procedure [
22].
3. ECG Data Sets
For the performance evaluation for data compression in this research, we used three public data sets of ECG signals, i.e., the PTB Diagnostic ECG database (PTBDB), the European ST-T database (EDB), and the MIT-BIH Arrhythmia database (MITDB). As mentioned earlier, we initially tried to compress a part of MITDB in [
18]. However, more experiments needed to be done, and some issues needed to be investigated. Hence, in this research, extensive experiments were performed on these three ECG data sets. It is worthwhile noting that these three data sets have totally different characteristics [
23] as follows:
- 1.
PTB Diagnostic ECG database (PTBDB) [
24]:
- 2.
European ST-T database (EDB) [
25]:
- 3.
MIT-BIH Arrhythmia database (MITDB) [
26]:
As we can see, these three data sets are different in all of these features, i.e., number of records, time duration per record, sampling frequency, and resolution. Hence, they will be very good candidates to be used in the evaluation of lossless ECG compression across different data sets or different setups.
5. Discussion
From the compression results compared to the state-of-the-art works in
Table 1,
Table 2 and
Table 3 in
Section 4.1, the proposed compression method achieved compression ratios close to or better than that of the others. The results demonstrate that the proposed lossless ECG signal compression method is very robust. It can be applied even in different ECG signal acquisition setups, i.e., different numbers of records, different time duration per record, different sampling frequencies, or different resolutions (number of bits per sample). For the PTBDB data set, the result in [
4,
5] showed CR of 3.98 and 4.07, which is higher than the 3.16 achieved by the proposed method. However, we cannot really compare them because, in [
4], data from other channels were required to reconstruct the data in the channel of interest. It was not a single-lead ECG signal reconstruction like what we have here. For the EDB and MITDB data sets, it is interesting that the results in [
8] yielded very high CRs compared to other existing methods. In [
8], however, it was mentioned that not all data were used; there was data selection to make it comparable to a previous method. Meanwhile, we applied the proposed method for the entire data in each data set. Hence, the results may not be comparable. To make a fair comparison, we need to make sure that all methods take the exact same ECG signals as the inputs.
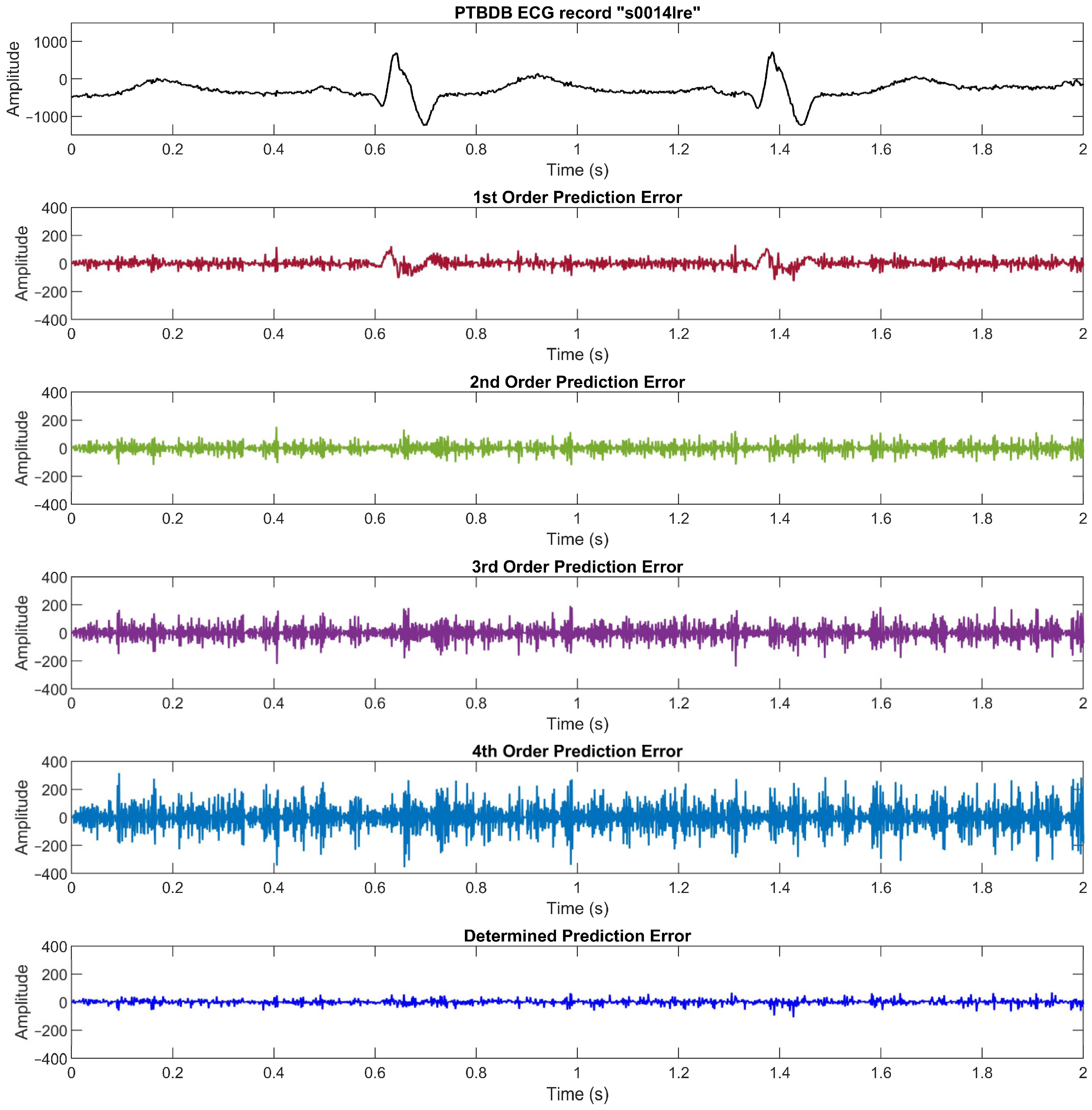
We compare the prediction error for each order and the determined absolute prediction error from the MITDB data set in
Figure 2 (see
Section 2.1), the PTBDB data set in
Figure 9, and the EDB data set in
Figure 10. The results in these figures show that the higher resolution and sampling frequency of the ECG signal will cause a higher prediction error which in turn decreases the compression ratio. In the PTBDB data set, the high frequency and resolution of the original signals also significantly increases the low-order prediction errors in the flat regions, whereas it is lower for the MITDB and EDB data sets. This is the reason that the average CR for the PTBDB data set is lower than that for the MITDB and EDB data sets.
From the results shown in
Table 4,
Table 5 and
Table 6 in
Section 4.2, the proposed and algorithm-determined linear prediction coefficients were compared. Each order of the proposed coefficient was chosen to minimize the prediction error for the different signal regions. Meanwhile, the determined coefficient was calculated to fit the entire length of the signal. Therefore, the results show that the 2nd order of the linear prediction function is sufficient to predict the ECG signal with an acceptable prediction error. The corresponding coefficients are
and
. It is very interesting that although all three data sets are different in signal acquisition setups, especially the sampling frequency, which dictates the temporal information, they still produce the same rounded prediction coefficients. This is in agreement with the results in [
7] in that, using the mean absolute prediction error and root-mean-square prediction error, the 2nd order of the linear prediction function yielded the best prediction performance.
6. Conclusions
In this research, a lossless ECG signal compression method was proposed. The method exploited the prediction error-based adaptive linear prediction and the modified Golomb–Rice coding. The evaluation results of the proposed method on the PTB Diagnostic database, the European ST-T database, and the MIT-BIH Arrhythmia database achieved an average compression ratio (CR) of 3.16, 3.75, and 3.52, respectively. These average CRs on these three data sets are comparable to or better than most of the other related works. The results also suggested that the proposed lossless ECG signal compression method was very robust and could be applied in different ECG signal acquisition setups, i.e., numbers of records, time duration per record, sampling frequencies, or resolution. In addition, the proposed linear prediction coefficients were compared to the coefficients determined by the autocorrelation method with Yule–Walker equations and the Levinson–Durbin method. The results demonstrated the agreement with previous work, i.e., the 2nd order of the linear prediction function is suitable to apply to ECG signal compression with the corresponding prediction coefficients and . Even though the proposed method is robust to different ECG signal acquisition setups, its obvious limitation is that it is specifically designed for ECG signals only. The ongoing and future trends of this work include how to further increase the compression ratio in this lossless ECG signal compression and how to implement the proposed method to other signals in which lossless compression is required. We can anticipate that the determination of the prediction coefficients of each particular signal will be crucial. If the proper prediction coefficients are determined, efficient lossless compression will be achieved by the proposed method.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}