Monte Carlo Comparison for Nonparametric Threshold Estimators


Abstract
:1. Introduction
2. Three Nonparametric Threshold Estimators
2.1. Semiparametric M-Estimator
2.2. DKE and IDKE
3. Estimation Difficulties in the Difference Kernel-Type Estimator with Near Boundary
4. Monte Carlo Designs
- DGP 1:
- DGP 2:
- DGP 3:
- DGP 4:
- DGP 5:
- DGP 6:
- DGP 7:
5. Monte Carlo Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Afonso, Antonio, and Joao Tovar Jalles. 2013. Growth and productivity: The role of government debt. International Review of Economics and Finance 25: 384–407. [Google Scholar] [CrossRef]
- Caner, Mehmet, and Bruce Hansen. 2004. Instrumental variable estimation of a threshold model. Econometric Theory 20: 813–43. [Google Scholar] [CrossRef]
- Caner, Mehmet, Thomas J. Grennes, and Friederike N. Koehler-Geib. 2010. Finding the Tipping Point—When Sovereign Debt Turns Bad. Policy Research WP, No. 5391. New Delhi: Policy Research, pp. 1–13. [Google Scholar]
- Cecchetti, Stephen G., Madhusudan Mohanty, and Fabrizio Zampolli. 2011. The Real Effects of Debt. Working paper. Basel, Switzerland: Bank for International Settlements. [Google Scholar]
- Chan, Kung-Sik. 1993. Consistency and Limiting Distribution of the Least Squares Estimator of a Threshold Autoregressive Model. Annals of Statistics 21: 520–33. [Google Scholar] [CrossRef]
- Delgado, Miguel A., and Javier Hidalgo. 2000. Nonparametric inference on structural breaks. Journal of Econometrics 96: 113–44. [Google Scholar] [CrossRef] [Green Version]
- Hansen, Bruce E. 2000. Sample splitting and threshold estimation. Econometrica 68: 575–603. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2011. Threshold Autoregression in Economics. Statistics and Its Interface 4: 123–27. [Google Scholar] [CrossRef]
- Heckman, James J. 1979. Sample Selection Bias as a Specification Error. Econometrica 47: 153–61. [Google Scholar] [CrossRef]
- Henderson, Daniel J., Christopher F. Parmeter, and Liangjun Su. 2017. Nonparametric Threshold Regression: Estimation and Inference. Working paper. Singapore: Research Collection School of Economics. [Google Scholar]
- Kourtellos, Andros, Thanasis Stengos, and Chih Ming Tan. 2016. Structural Threshold Regression. Econometric Theory 32: 827–60. [Google Scholar] [CrossRef]
- Kourtellos, Andros, Thanasis Stengos, and Yiguo Sun. 2017. Endogeneity in Semiparametric Threshold Regression. Working paper. Guelph, ON, Canada: University of Cyprus and University of Guelph. [Google Scholar]
- Potter, Simon M. 1995. A Nonlinear Approach to US GNP. Journal of Applied Econometrics 10: 109–25. [Google Scholar] [CrossRef]
- Seo, Myung Hwan, and Oliver Linton. 2007. A smoothed least squares estimator for threshold regression models. Journal of Econometrics 141: 704–35. [Google Scholar] [CrossRef]
- Seo, Myung Hwan, and Yongcheol Shin. 2016. Dynamic Panels with Threshold Effect and Endogeneity. Journal of Econometrics 195: 169–86. [Google Scholar] [CrossRef]
- Yu, Ping, and Peter C. B. Phillips. 2018. Threshold Regression with Endogeneity. Journal of Econometrics 203: 50–68. [Google Scholar] [CrossRef]
| 1. | With the uniform distribution, the intensity of the Poisson process would not change with the change in the true threshold location. Therefore, the limiting distribution of both the DKE and the IDKE is not affected given is not on the boundary of . |
| 2. | The theoretical density should be the same for all x due to the uniform distribution. The reason we use the data-driven choice of is because we do not know the true density in reality. |
| 3. | All programming is finished in Matlab. |
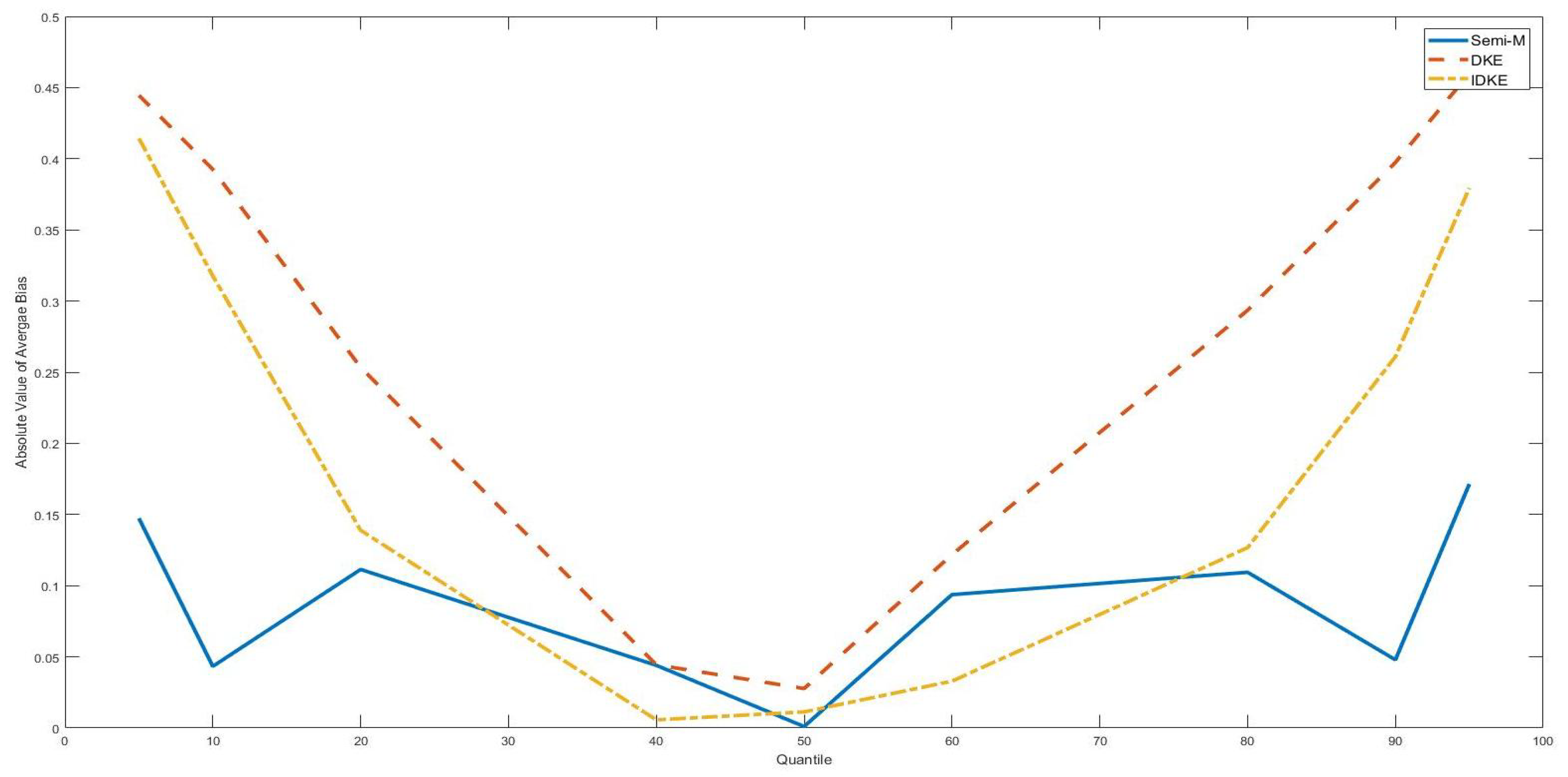
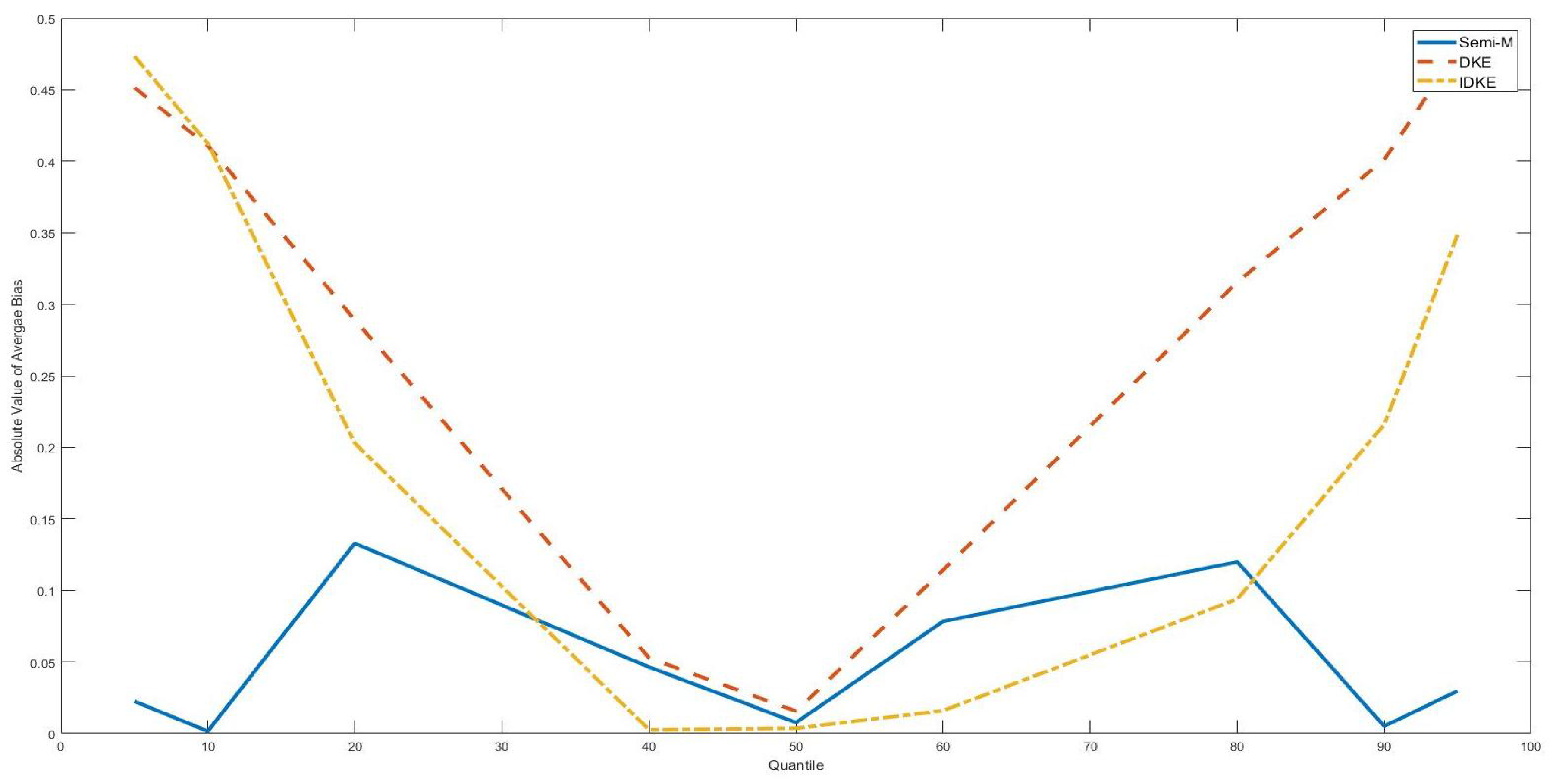
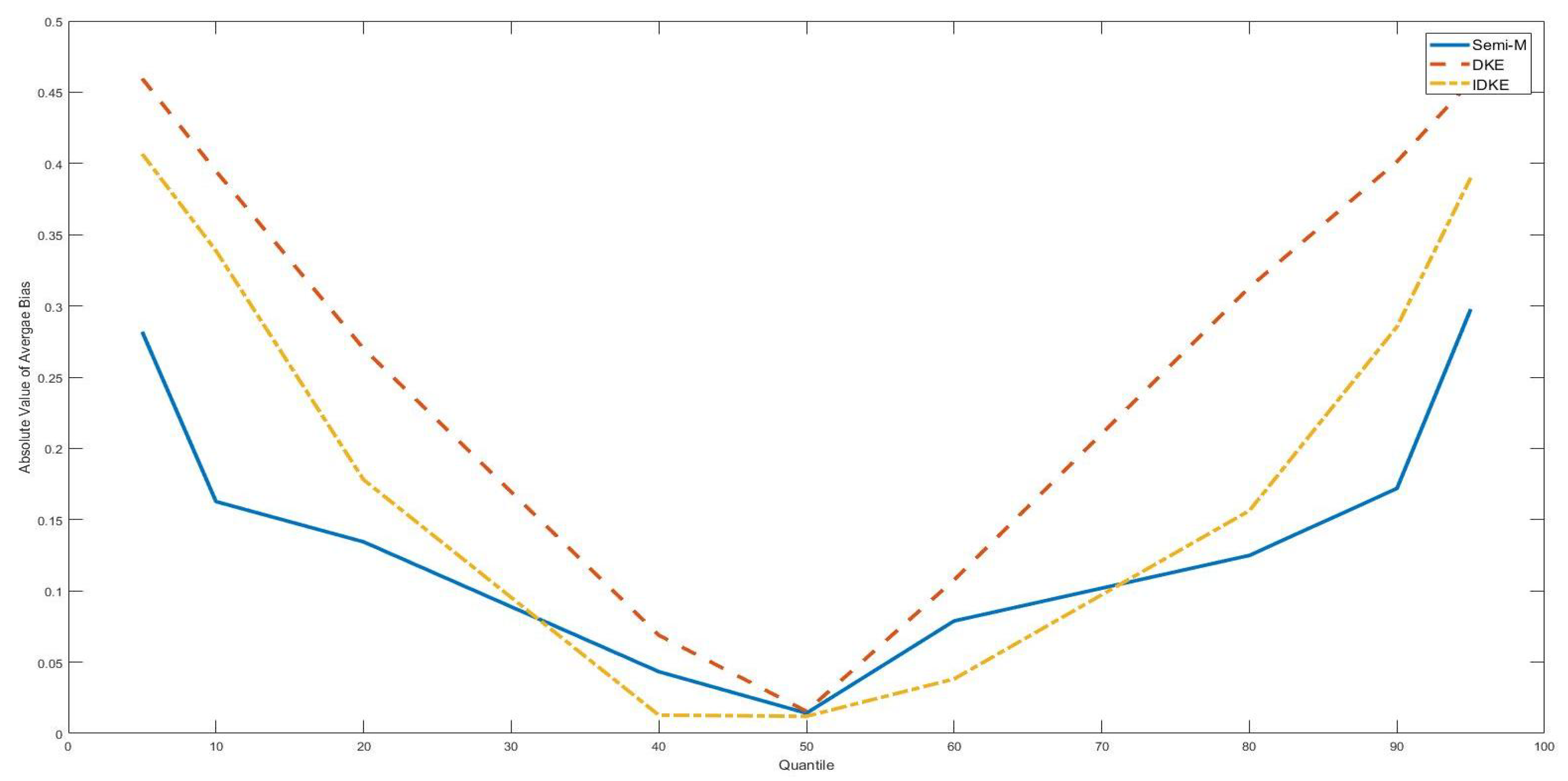
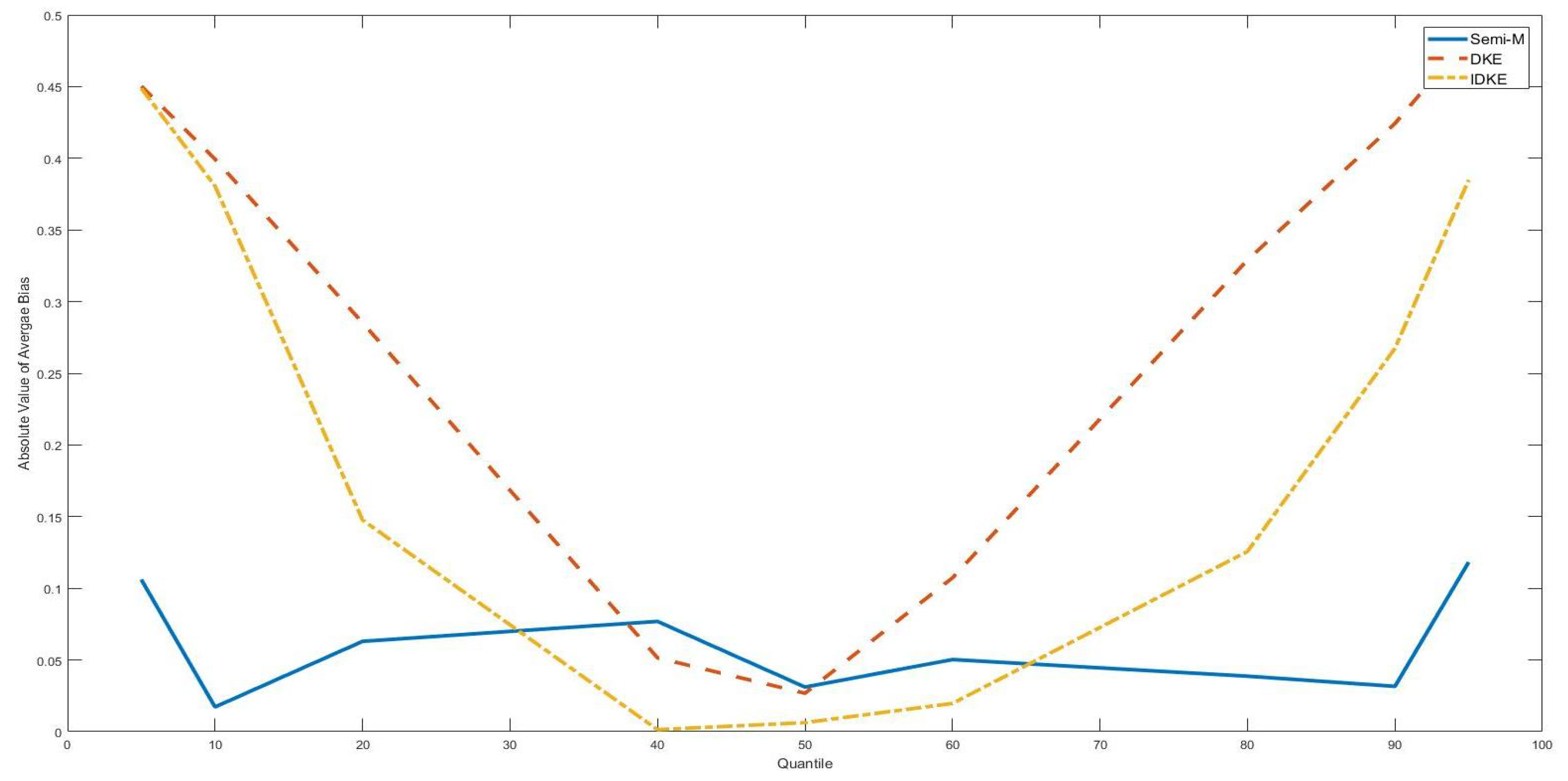
| 4. | With n = 100, the bias, MSE and standard deviation were larger with placed at two tails and placed at the median point. However, with n = 500, there was no apparent difference between tail position estimation and the median position estimation. |
| 5. | For example, in Table 6, the bias monotonically increases with the in sample size. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0336 | 0.2705 | 0.0679 | 0.0144 | 0.0913 | 0.0225 | 0.1152 | 0.1345 | 0.1338 |
| 300 | 0.0015 | 0.2929 | 0.0870 | 0.0006 | 0.0986 | 0.0308 | 0.0241 | 0.1133 | 0.1525 |
| 500 | 0.0002 | 0.2632 | 0.1530 | 0.0001 | 0.0920 | 0.0544 | 0.0097 | 0.1509 | 0.1760 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0056 | −0.0346 | −0.0183 | 0.0084 | 0.0154 | 0.0012 | 0.0916 | 0.1191 | 0.0288 |
| 300 | 0.0007 | −0.0346 | −0.0083 | 0.0009 | 0.0209 | 0.0002 | 0.0302 | 0.1406 | 0.0126 |
| 500 | 0.0008 | −0.0347 | −0.0055 | 0.0003 | 0.0233 | 0.0001 | 0.0166 | 0.1488 | 0.0080 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0397 | −0.2485 | −0.0666 | 0.0163 | 0.1082 | 0.0087 | 0.1215 | 0.2156 | 0.0650 |
| 300 | −0.0028 | −0.2590 | −0.0377 | 0.0009 | 0.1143 | 0.0029 | 0.0299 | 0.2174 | 0.0391 |
| 500 | −0.0004 | −0.2841 | −0.0287 | 0.0001 | 0.1288 | 0.0018 | 0.0118 | 0.2193 | 0.0308 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0359 | 0.2272 | 0.0813 | 0.0154 | 0.0823 | 0.0250 | 0.1190 | 0.1752 | 0.1357 |
| 300 | 0.0053 | 0.2680 | 0.1019 | 0.0020 | 0.0954 | 0.0324 | 0.0442 | 0.1536 | 0.1485 |
| 500 | 0.0002 | 0.2632 | 0.1530 | 0.0001 | 0.0920 | 0.0544 | 0.0097 | 0.1509 | 0.1760 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0008 | −0.0246 | −0.0151 | 0.0082 | 0.0122 | 0.0009 | 0.0907 | 0.1077 | 0.0257 |
| 300 | 0.0002 | −0.0147 | −0.0067 | 0.0009 | 0.0130 | 0.0002 | 0.0306 | 0.1130 | 0.0107 |
| 500 | 0.0002 | −0.0131 | −0.0044 | 0.0000 | 0.0154 | 0.0001 | 0.0068 | 0.1233 | 0.0073 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0307 | −0.2465 | −0.1031 | 0.0119 | 0.1049 | 0.0159 | 0.1048 | 0.2101 | 0.0730 |
| 300 | −0.0059 | −0.2564 | −0.0786 | 0.0023 | 0.1009 | 0.0086 | 0.0477 | 0.1876 | 0.0494 |
| 500 | −0.0008 | −0.2651 | −0.0699 | 0.0003 | 0.1060 | 0.0065 | 0.0177 | 0.1891 | 0.0397 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0303 | 0.2211 | 0.0785 | 0.0128 | 0.0791 | 0.0233 | 0.1092 | 0.1739 | 0.1310 |
| 300 | 0.0022 | 0.2725 | 0.1137 | 0.0014 | 0.0980 | 0.0373 | 0.0376 | 0.1541 | 0.1561 |
| 500 | 0.0005 | 0.2694 | 0.1570 | 0.0002 | 0.0961 | 0.0546 | 0.0131 | 0.1535 | 0.1730 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0017 | −0.0236 | −0.0137 | 0.0073 | 0.0111 | 0.0008 | 0.0852 | 0.1027 | 0.0257 |
| 300 | 0.0002 | −0.0220 | −0.0061 | 0.0004 | 0.0132 | 0.0001 | 0.0196 | 0.1128 | 0.0101 |
| 500 | −0.0003 | −0.0114 | −0.0041 | 0.0001 | 0.0149 | 0.0001 | 0.0112 | 0.1215 | 0.0067 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0358 | −0.2471 | −0.1036 | 0.0160 | 0.1031 | 0.0160 | 0.1212 | 0.2051 | 0.0725 |
| 300 | −0.0027 | −0.2592 | −0.0822 | 0.0013 | 0.1041 | 0.0091 | 0.0360 | 0.1924 | 0.0482 |
| 500 | −0.0007 | −0.2637 | −0.0686 | 0.0004 | 0.1031 | 0.0065 | 0.0203 | 0.1832 | 0.0422 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0371 | 0.2754 | 0.1038 | 0.0168 | 0.0922 | 0.0348 | 0.1242 | 0.1278 | 0.1551 |
| 300 | 0.0065 | 0.2817 | 0.1479 | 0.0030 | 0.0921 | 0.0526 | 0.0545 | 0.1131 | 0.1754 |
| 500 | 0.0010 | 0.2884 | 0.2146 | 0.0005 | 0.0974 | 0.0794 | 0.0221 | 0.1196 | 0.1826 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0050 | −0.0324 | −0.0173 | 0.0086 | 0.0156 | 0.0016 | 0.0930 | 0.1205 | 0.0355 |
| 300 | −0.0010 | −0.0408 | −0.0071 | 0.0012 | 0.0212 | 0.0002 | 0.0341 | 0.1400 | 0.0135 |
| 500 | 0.0000 | −0.0340 | −0.0051 | 0.0000 | 0.0222 | 0.0001 | 0.0038 | 0.1451 | 0.0086 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0378 | −0.2562 | −0.0694 | 0.0157 | 0.1105 | 0.0089 | 0.1196 | 0.2120 | 0.0640 |
| 300 | −0.0025 | −0.2622 | −0.0445 | 0.0007 | 0.1131 | 0.0037 | 0.0266 | 0.2107 | 0.0411 |
| 500 | −0.0007 | −0.2709 | −0.0358 | 0.0004 | 0.1162 | 0.0024 | 0.0203 | 0.2070 | 0.0334 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0141 | 0.2560 | 0.0751 | 0.0060 | 0.1005 | 0.0213 | 0.0762 | 0.1871 | 0.1253 |
| 300 | 0.0005 | 0.2587 | 0.0421 | 0.0006 | 0.0970 | 0.0104 | 0.0253 | 0.1733 | 0.0931 |
| 500 | 0.0000 | 0.2696 | 0.0333 | 0.0000 | 0.0977 | 0.0085 | 0.0038 | 0.1583 | 0.0862 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0035 | −0.0232 | −0.0167 | 0.0050 | 0.0248 | 0.0014 | 0.0710 | 0.1559 | 0.0335 |
| 300 | 0.0000 | −0.0176 | −0.0082 | 0.0001 | 0.0205 | 0.0003 | 0.0118 | 0.1420 | 0.0136 |
| 500 | 0.0001 | −0.0330 | −0.0057 | 0.0000 | 0.0222 | 0.0001 | 0.0041 | 0.1452 | 0.0106 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0203 | −0.2778 | −0.1173 | 0.0085 | 0.1239 | 0.0212 | 0.0900 | 0.2161 | 0.0864 |
| 300 | −0.0007 | −0.2878 | −0.0958 | 0.0002 | 0.1256 | 0.0133 | 0.0154 | 0.2069 | 0.0639 |
| 500 | 0.0000 | −0.2883 | −0.0944 | 0.0000 | 0.1253 | 0.0119 | 0.0035 | 0.2056 | 0.0544 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0197 | 0.2495 | 0.0704 | 0.0082 | 0.0972 | 0.0188 | 0.0882 | 0.1871 | 0.1177 |
| 300 | 0.0002 | 0.2652 | 0.0364 | 0.0001 | 0.0997 | 0.0094 | 0.0114 | 0.1714 | 0.0898 |
| 500 | 0.0000 | 0.2738 | 0.0297 | 0.0000 | 0.1003 | 0.0074 | 0.0032 | 0.1594 | 0.0807 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0019 | −0.0107 | −0.0158 | 0.0051 | 0.0242 | 0.0013 | 0.0711 | 0.1553 | 0.0323 |
| 300 | −0.0004 | −0.0251 | −0.0074 | 0.0002 | 0.0216 | 0.0002 | 0.0138 | 0.1450 | 0.0125 |
| 500 | 0.0001 | −0.0280 | −0.0054 | 0.0000 | 0.0210 | 0.0001 | 0.0036 | 0.1422 | 0.0094 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0184 | −0.2709 | −0.1164 | 0.0082 | 0.1177 | 0.0207 | 0.0886 | 0.2105 | 0.0846 |
| 300 | −0.0007 | −0.2717 | −0.0975 | 0.0004 | 0.1157 | 0.0131 | 0.0194 | 0.2048 | 0.0600 |
| 500 | 0.0002 | −0.2647 | −0.0889 | 0.0000 | 0.1080 | 0.0104 | 0.0042 | 0.1949 | 0.0497 |
| γ0 Is the 25th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | 0.0207 | 0.2936 | 0.1292 | 0.0097 | 0.1086 | 0.0419 | 0.0964 | 0.1498 | 0.1588 |
| 300 | 0.0005 | 0.2915 | 0.1275 | 0.0003 | 0.1031 | 0.0393 | 0.0168 | 0.1347 | 0.1517 |
| 500 | 0.0003 | 0.2947 | 0.1378 | 0.0001 | 0.1048 | 0.0427 | 0.0105 | 0.1341 | 0.1542 |
| γ0 Is the 50th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0034 | 0.0004 | −0.0373 | 0.0051 | 0.0265 | 0.0074 | 0.0716 | 0.1630 | 0.0778 |
| 300 | 0.0013 | 0.0049 | −0.0366 | 0.0003 | 0.0229 | 0.0029 | 0.0178 | 0.1514 | 0.0398 |
| 500 | 0.0003 | 0.0077 | −0.0315 | 0.0001 | 0.0180 | 0.0019 | 0.0081 | 0.1339 | 0.0294 |
| γ0 Is the 75th Quantile of the Threshold Variable | |||||||||
| Bias | MSE | Stdev | |||||||
| n | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE | Semi-M | DKE | IDKE |
| 100 | −0.0244 | −0.2830 | −0.2242 | 0.0106 | 0.1137 | 0.0575 | 0.0998 | 0.1834 | 0.0849 |
| 300 | 0.0000 | −0.2798 | −0.2068 | 0.0001 | 0.1074 | 0.0457 | 0.0084 | 0.1708 | 0.0539 |
| 500 | 0.0000 | −0.2823 | −0.1963 | 0.0000 | 0.1039 | 0.0403 | 0.0036 | 0.1558 | 0.0424 |
| Semiparametric M-Estimator of Henderson et al. (2017) | |||||||
| DGP 1 | DGP 2 | DGP 3 | DGP 4 | DGP 5 | DGP 6 | DGP 7 | |
| p = 25 | −1.235 | −1.202 | −1.209 | −1.280 | −1.224 | −1.347 | −1.307 |
| p = 50 | −1.162 | −1.195 | −1.171 | −1.234 | −1.349 | −1.335 | −1.347 |
| p = 75 | −1.215 | −1.251 | −1.203 | −1.205 | −1.227 | −1.234 | −1.331 |
| IDKE of Yu et al. (2018) | |||||||
| DGP 1 | DGP 2 | DGP 3 | DGP 4 | DGP 5 | DGP 6 | DGP 7 | |
| p = 25 | −2.207 | −2.126 | −2.164 | −2.541 | −1.556 | −1.436 | −2.557 |
| p = 50 | −1.352 | −1.287 | −1.305 | −1.335 | −1.428 | −1.348 | −1.982 |
| p = 75 | −1.758 | −1.949 | −1.966 | −1.757 | −1.876 | −2.115 | −2.626 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Sun, Y. Monte Carlo Comparison for Nonparametric Threshold Estimators. J. Risk Financial Manag. 2018, 11, 49. https://doi.org/10.3390/jrfm11030049
Chen C, Sun Y. Monte Carlo Comparison for Nonparametric Threshold Estimators. Journal of Risk and Financial Management. 2018; 11(3):49. https://doi.org/10.3390/jrfm11030049
Chicago/Turabian StyleChen, Chaoyi, and Yiguo Sun. 2018. "Monte Carlo Comparison for Nonparametric Threshold Estimators" Journal of Risk and Financial Management 11, no. 3: 49. https://doi.org/10.3390/jrfm11030049
APA StyleChen, C., & Sun, Y. (2018). Monte Carlo Comparison for Nonparametric Threshold Estimators. Journal of Risk and Financial Management, 11(3), 49. https://doi.org/10.3390/jrfm11030049