1. Introduction
Parametric discrete-time duration models are used extensively within econometrics and the other statistical sciences. Since misspecification of these models can lead to invalid inferences, a variety of semiparametric alternatives have been proposed. However, even these alternative semiparametric estimators exploit certain smoothness and moment conditions, which may be untenable in some circumstances. To address these shortcomings, we propose a new estimator, based on
Horowitz (
1992)’s smoothed maximum score estimator of single-period binary choice models, which relaxes these assumptions. To motivate and contextualize this estimator, we use this Introduction to review the relevant literature on discrete duration and binary choice models and indicate how our proposed estimator fills a gap in the literature.
In econometrics, discrete-time duration models are typically framed as a sequence of binary choices. The probability of remaining in a state at time
s (the continuation probability) is denoted
, and the hazard rate is simply
. Many parametric forms have been employed for the hazard rate in these models including extreme value, logistic, normal and other parsimonious specifications. Examples using a logistic specification include:
Huff-Stevens (
1999),
Finnie and Gray (
2002),
Bover et al. (
2002) and
D’Addio and Rosholm (
2005); normal distribution:
Meghir and Whitehouse (
1997) and
Chan and Huff-Stevens (
2001); extreme value (also known as the complementary log-log model):
Baker and Rea (
1998),
Cooper et al. (
1999),
Holmas (
2002),
Fennema et al. (
2006) and
Gullstrand and Tezic (
2008). These and others were reviewed in
Allison (
1982) and
Sueyoshi (
1995).
Hess (
2009) has suggested using the generalized Pareto distribution, which nests the extreme value and logistic distributions. These specifications lead naturally to maximum likelihood estimation of
, although it is useful to note that there are alternative ways to estimate
including nonlinear regression, treating
as a conditional mean. As with any parametric approach, misspecification of the hazard rate can lead to invalid inferences. In this regard, we consider various relevant semiparametric alternatives, which relax the parametric assumptions.
We note first that semiparametric estimation of continuous-time models has been the focus of substantial research in the discipline. Numerous authors have developed distribution theory for semiparametric estimation of various continuous-time duration models including
Horowitz (
1999),
Nielsen et al. (
1998),
Van der Vaart (
1996) and
Bearse et al. (
2007). While these and other semiparametric estimators allow for the relaxation of some parametric assumptions associated with continuous-time duration models, they are not generally appropriate when the duration random variable has a discrete distribution.
We adopt the standard approach in econometrics of constructing the continuation probability from an underlying latent regression structure. In a standard single-period basic binary choice model, we would observe with where is the usual indicator function, Z is an index function of observable random variables and unknown parameters and U has a distribution function F. With discrete-time duration models, the observed duration is the sum of a sequence of indicators so that , where with , and the distribution function of is denoted by .
There is a large literature on semiparametric estimation of single-period binary choice models. We briefly review this, highlighting how it has been adapted for certain multivariate discrete choice and/or discrete-duration models and finally how our proposed estimator fills a gap in this research. Since in some cases, the conditional mean of
Y in the single-period case can be written as
, the parameter of interest,
, can be estimated from a semi-parametric regression. This was suggested by
Ichimura (
1993) to obtain a
-consistent estimator of
. With respect to duration models and exploiting the fact that
can also be written as the conditional mean of the choice variable,
Reza and Rilstone (
2014) minimized a sum of squared semiparametric residuals to estimate the parameters of interest. In a similar vein,
Klein and Spady (
1993) developed a semi-parametric maximum likelihood estimator of
with the single observation likelihood function written as
.
Klein and Spady’s (
1993) estimator essentially consists of replacing
F with a nonparametric conditional mean function.
Reza and Rilstone (
2016) adapted
Klein and Spady’s (
1993) estimator to the discrete duration case. They also derived the efficiency bounds and showed that their estimator obtained these bounds. We note that the approaches in
Ichimura (
1993) and
Klein and Spady (
1993) require continuity of
F in the underlying covariates and are limited with respect to the forms of allowable heteroskedasticity (for example, heteroskedasticity from time-varying parameters is precluded). Another problem is simply that identification may not be possible under the mean-independence restriction that
.
1 By extension, the estimators of
Reza and Rilstone (
2014,
2016) suffer the same shortcomings as applied to duration models.
With respect to single-period binary choice models,
Manski’s (
1975,
1985) Maximum Score (MS) estimator circumvents these limitations using simply the median-independence restriction that
. The MS estimator can be written as the maximizer of:
where
is an index function of the observable covariates. As is usually the case, a normalization of
is necessary. For the estimator to be consistent, a few restrictions need to be imposed, in particular with respect to the distribution of
U. The shortcomings of the estimator are that it is only
-consistent, and its asymptotic distribution, a form of Brownian motion, is not amenable for use in the applied work.
From one perspective, the shortcomings of the MS estimator derive from its use of the non-differentiable indicator function.
Horowitz (
1992) largely circumvented its limitations in this regard by replacing the indicator function with a smoothed indicator function,
. The objective function for the Smoothed Maximum Score (SMS) estimator is:
The SMS is typically better than
-consistent, but slower than
, the speed of convergence depending on the smoothness of
and the distribution of the random components of the model. Note that the
-convergence of the estimators such as
Klein and Spady’s (
1993) is linked to the manner in which they use kernels. These estimators are a form of double averages. However, the objective functions for MS and SMS are nonparametric point estimators, which are single averages. With some caveats, the SMS estimator reflects the fact that the only exploitable information is at or close to the median of the
U’s. The
estimators effectively use all the data points.
The main objective of this paper is to show how to extend SMS to estimate discrete duration models. The MS and SMS estimators have been used in other situations such as
Lee (
1992) and
Melenberg and Van Soest (
1996), who extended the MS and SMS, respectively, to ordered-response models.
De Jong and Woutersen (
2011) have extended the SMS estimator to binary choices with dynamic time series data.
Fox (
2007) adapted the MS estimator to multinomial choices.
Charlier et al. (
1995) extended the SMS to panel data. Other researchers have modified the MS and SMS estimators to improve their sampling properties.
Kotlyarova and Zinde-Walsh (
2010) suggested using a weighted average of different SMS estimators to reduce mean squared error.
Iglesias (
2010) derived the second-order bias, which can be used to reduce the bias of the SMS estimator.
Jun et al. (
2015) proposed a Laplace estimator alternative to improve on the
-consistency of the MS estimator. To our knowledge, neither the MS nor SMS estimators have been extended to duration models.
Section 2 and
Section 3 discuss the class of models considered and present the basic estimator along with its main asymptotic properties.
Section 4 provides some simulation results concerning the sampling distribution of the estimator, and
Section 5 concludes.
2. Modelling
As mentioned, a standard approach for modelling a discrete duration process is to construct it as a sequence of binary choice models, with observed and unobserved heterogeneity. The standard binary choice model is adapted such that in each time period,
s, a choice is made by individual
i to continue in a state if the latent variable:
is greater than zero. Here,
2 is an index where
is a scalar random variable and
is a
vector, which may include a function of
s, while
is a
vector of constants.
We assume the
’s and
’s are jointly i.i.d. We observe
and
,
. A natural adaptation of Manski’s setup is the additional assumption that
,
. We estimate the parameters by effectively estimating the density of
at zero by nonparametric methods. For notational convenience, we often suppress the
i subscripts. Another way to view the modelling is that in any given period
s with
, this is a standard binary choice variable with the key difference being that the index
Z is a function of some covariates and the number of completed periods,
s. The duration variable for period
s is simply
with
,
.
3 The evolution of the
’s, conditional on the covariates and duration, is given by:
Note that this representation is such that is zero if the subject left the state prior to period s and becomes a standard binary choice model in period s if the subject elected to continue in the state in period .
We put an upper limit,
S, on the length of spells. This is common in empirical work.
4 Allowing for unbounded
S introduces technical difficulties that are not readily resolved. Put
. It is useful to note that by iterated expectations:
so that, tautologically,
, the continuation probability function, is:
3. The Estimator
Adapting the SMS estimator to the discrete duration model as outlined in
Section 2, the objective function is:
, a smoothed indicator function, is the anti-derivative of and has the properties: , , . In most kernel density estimation, K is a density function and is its associated cumulative distribution function. The technical requirements here sometimes require use of a higher order kernel.
Note that the objective function is of the same form as the usual SMS estimator with the modifications that there is a double summand over individuals and time periods and each of the summands at period s is multiplied by , so that after exit, there is no further contribution to the objective function by that individual.
Implicitly, we impose the identification condition that the coefficient on
is unity
5 (e.g.,
Li and Racine 2007).
Horowitz (
1992) discussed the identification issue.
is assumed to have a continuous distribution, conditional on
and
. Let:
The estimator solves the first-order conditions
, which are given by:
Concerning notation, when a function’s argument
is suppressed, it is evaluated at
, e.g.,
.
, a
matrix. Thus,
and
denote the cumulative distribution and density functions of
conditional on
, and
denotes the density functions of
conditional on
. The superscript
indicates the
derivative of a function with respect to
, and in particular, we have
.
is a generic constant. Put:
Let denote the probability distribution of given . The distributional assumptions we make are as follows.
Assumption 1. is a random sample where . . . for all i.
Assumption 2. For , (a) the support of the distribution of is not contained in any proper linear subspace of , (b) for almost every and (c) for almost every , the distribution of conditional on has everywhere positive density with respect to the Lebesgue measure.
Assumption 3. for almost every , .
Assumption 4. , a compact subset of .
Assumption 5. The elements of have finite fourth moments, .
Assumption 6. as
Assumption 7. (a) is twice differentiable everywhere; K and are uniformly bounded; and each of the following integrals over is finite: , , . (b) For some integer and each integer j, , , . (c) For , , any , ,
Assumption 8. is m-times continuously differentiable with respect to z in a neighbourhood of zero, almost every , and , .
Assumption 9. is m-times continuously differentiable with respect to in a neighbourhood of zero, almost every and , , .
Assumption 10. is an interior point of .
Assumption 11. Q is negative definite.
These assumptions adapt those in
Horowitz (
1992) to allow for the dependency structure. They also embed
Manski’s (
1985) assumptions with
. Notice that the random sampling assumption refers to
N random draws within each being the potentially
S observations.
Identification (see Proof of Proposition 1 in
Appendix A) follows by adapting
Manski’s (
1985) proof for the MS estimator. Of interest here is that we wish to allow for time dependence. Note that for the MS/SMS case, nothing precludes the inclusion of a constant in the index so long as, say,
is not co-linear
6 (in fact, simulation and empirical results such as in
Horowitz (
1998) indicate good results for intercept estimates). For the
m-multinomial choice model,
Lee (
1992) included
m non-stochastic threshold parameters (including a constant). In our case, the same applies for including certain non-stochastic functions of
s in
, such as including indicators for each
s or a polynomial in
s. For parsimony in our numerical/empirical work, we have included quadratics to allow for increasing, decreasing and non-monotonic time dependency. This allows for straight-forward testing. In this regard, we note that the semiparametric information matrix derived in
Reza and Rilstone (
2016) was singular for this class of models. There is no contradiction here, since the singularity indicates that those parameters are not estimable at the
-rate; it does not imply that they cannot be identified or estimated at a less than
-rate, which we do here.
We have the following lemma, which permits simple derivation of the asymptotic properties of the estimator.
Lemma 1. Let Assumptions 1–11 hold. Then, (a) , (b) and (c) .
The asymptotic distribution of the estimator can be summarized easily using the following result.
Proposition 1. Let Assumptions 1–11 hold. Then, (a) is consistent and (b) .
The proofs are in
Appendix A. In the statement of the proposition, note the presence of the first-order bias,
, for which it may be advisable to adjust the raw estimator. One of the benefits of this estimator is that one can effectively ignore the dependence of the observations, pool all the observations across individuals for whose
and use standard SMS optimization procedures. This is what we have done in the simulations.
Reza and Rilstone’s (
2016) setup (extension of
Klein and Spady 1993) allows for estimation of the hazard rate,
, with a natural estimate of time dependence from the semiparametric estimates of
. Note that
Reza and Rilstone’s (
2016) estimator of
only has a
-rate of convergence.
As for the SMS estimator, we can consider the optimal choice of window width. As with
Horowitz (
1992), we consider choices that minimize an MSE criterion. Therefore, if we consider that the asymptotic results correspond to the distribution of a random variable, say
W, with mean
and variance
, we can consider minimizing, say, the inner product MSE of
, where
is a positive definite weighting matrix, i.e., minimize
with respect to
. This results in:
For inferences it is necessary to obtain consistent estimates of the components of the first-order bias and variance. These cannot be directly estimated as they depend on the distribution of the unobservable
U’s. However, by extension of the arguments in
Horowitz (
1992), they may be obtained through various derivatives of the objective function. Specifically, put:
By the uniform law of large numbers, , and .
It is well known that the first-order asymptotic results may provide a poor approximation to the sampling distribution of the SMS estimator. Thus, it may be preferable to use some higher order method to approximate the distribution. Apart from
Iglesias (
2010) who applied the results in
Rilstone et al. (
1996) to derive the second-order bias of
, little is known (explicitly) about the second-order properties of the SMS estimator. Estimates can be bootstrapped. In this regard, we note that one should resample individuals. That is, bootstrap estimates should be based on resamples:
, where the *’s indicate random draws from the original data.
Horowitz (
2002) documents some of the issues associated with bootstrapping the distribution of
. In particular, the corresponding re-estimates:
, say, and corresponding standard errors should be calculated using an under-smoothing window-width such as
.
4. Simulation Exercise
To examine the estimator’s performance in finite samples, we conducted Monte Carlo simulations with several Data Generating Processes (DGPs). We adapted simulations in
Horowitz (
1992) by augmenting the models with duration dependence, and a variety of error distributions. The latent processes we considered included those with homoskedastic errors:
and those with heteroskedastic errors:
We conducted the simulations for two sample sizes,
and
. The
X’s were drawn as i.i.d.
. For the DGP with homoskedastic normal errors, this resulted in duration times with averages of 5.7 (
) and standard deviations also 5.7 (
). With heteroskedastic errors, the average duration times were 8.7 (
) with standard deviations of 9.6 (
) and 9.5 (
). For identification purposes, the coefficient on
was normalized to one, and our key parameter of interest was the coefficient on
, with a true value of one. We conducted 500 replications for each specification. We followed
Horowitz (
1992) to estimate the parameters in two steps: first using simulated annealing to find the approximate maximizer of
followed by gradient methods for greater precision. We then used the bias correction described in the previous section to bias-adjust the parameter estimates. We used a Gaussian kernel with a window-width
.
7 Standard errors and the bias correction were based on the consistent estimators
,
and
from Equation (
14).
Table 1,
Table 2 and
Table 3 report the summary statistics of the simulations for the estimates of the coefficients on
,
and
, respectively. We also conducted corresponding probit estimates as benchmarks. Note that, with normal errors, the probit estimates were fully efficient. The summary statistics indicated that the semiparametrically-estimated coefficients on
were very close to the true parameter. The bias and standard deviation both decreased with sample size. This is particularly true compared to the (misspecified) probit estimator when the errors were heteroskedastic. As for the coefficient on the linear duration dependence term (
), there appeared to be some bias, particularly in the presence of heteroskedasticity. However, the bias and RMSE of the SMS estimators diminished with sample size. This was not the case with the probit estimators. As indicated earlier, estimating duration dependence term at the
-rate was not possible. The estimates of the coefficient on the quadratic term of the duration dependence were somewhat biased, although the bias decreased with the sample as did the RMSE. Larger sample sizes than used here may be required to estimate, with precision, more nuanced forms of duration dependence using the proposed SMS in these contexts.
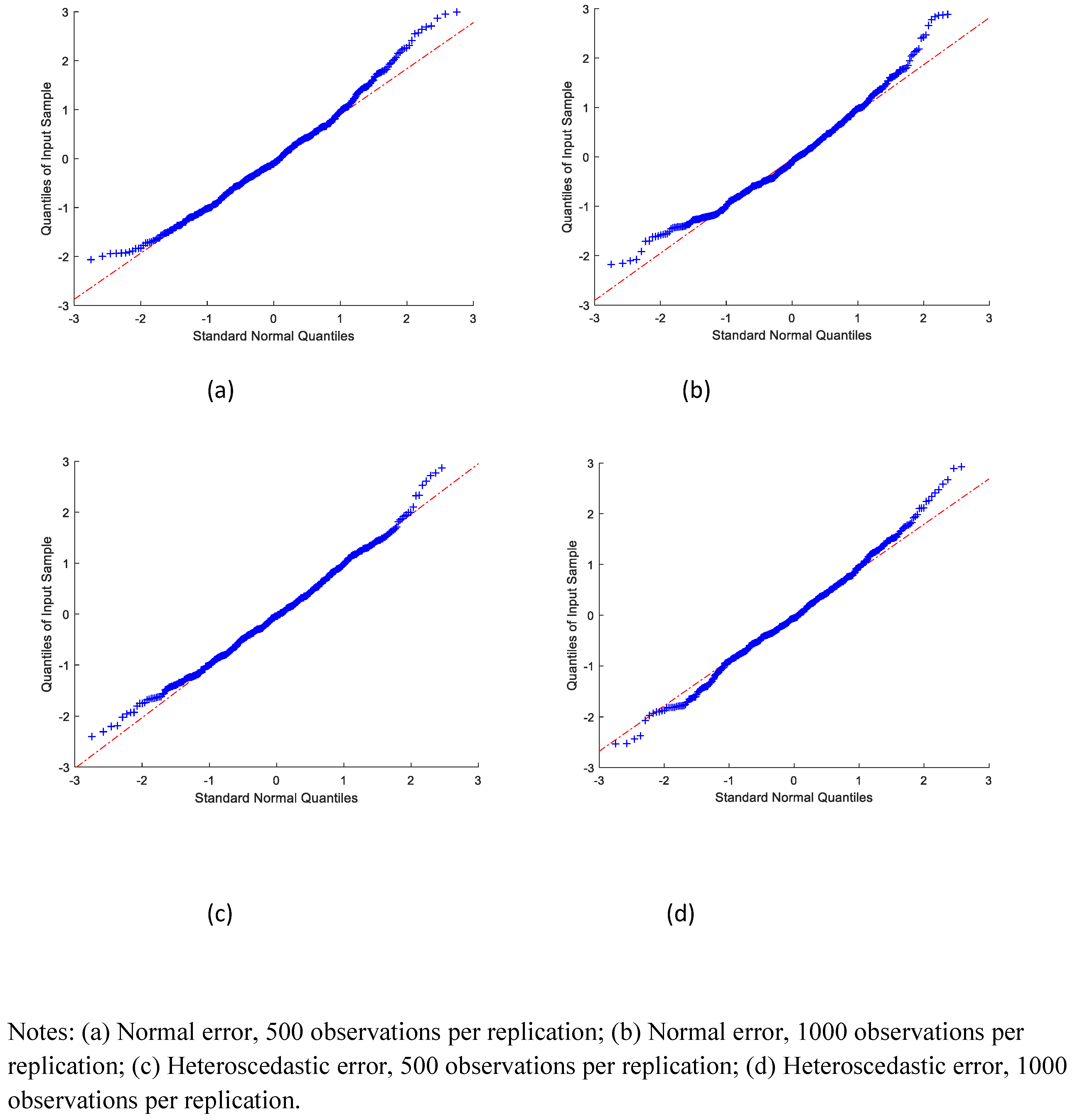
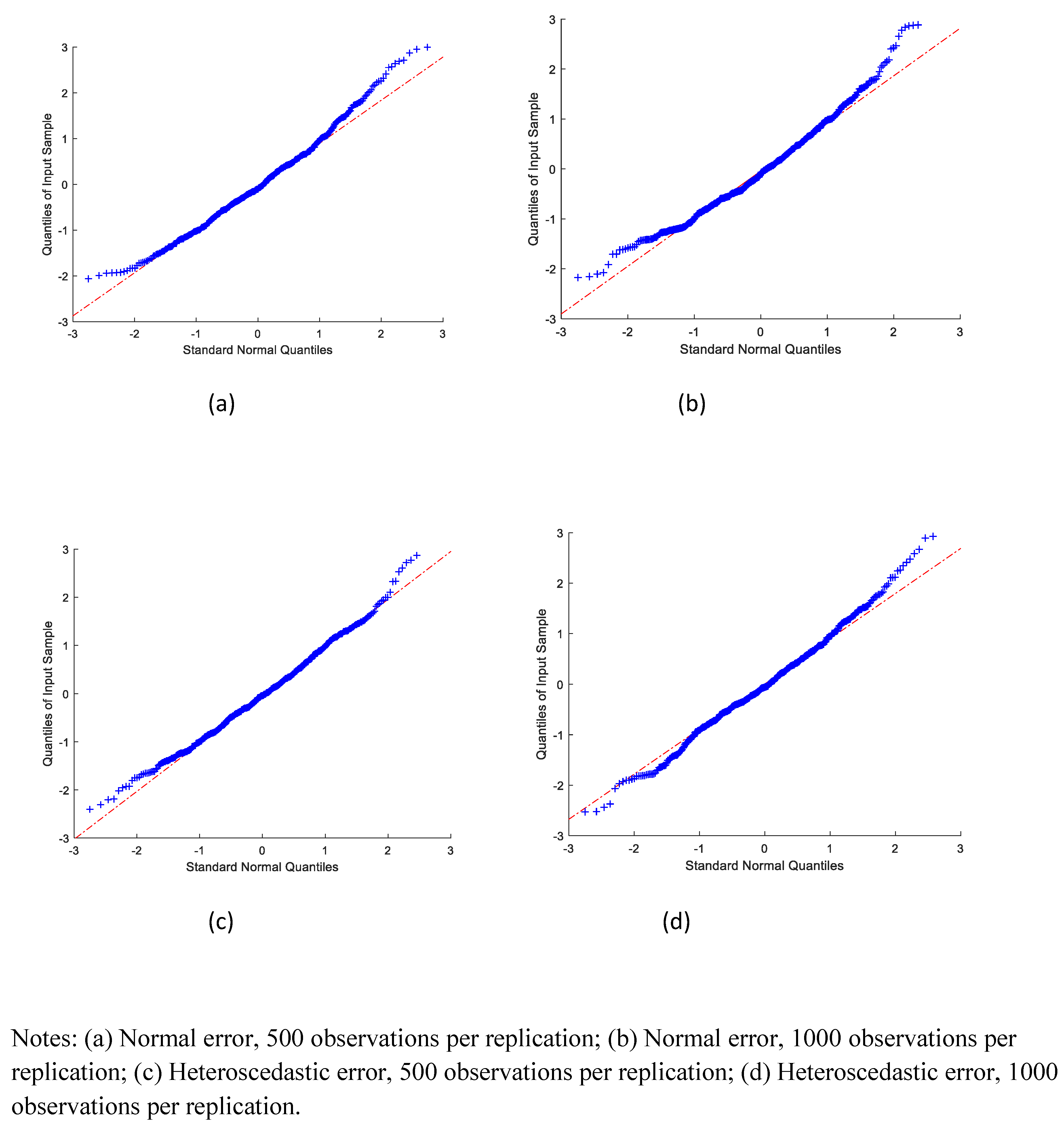
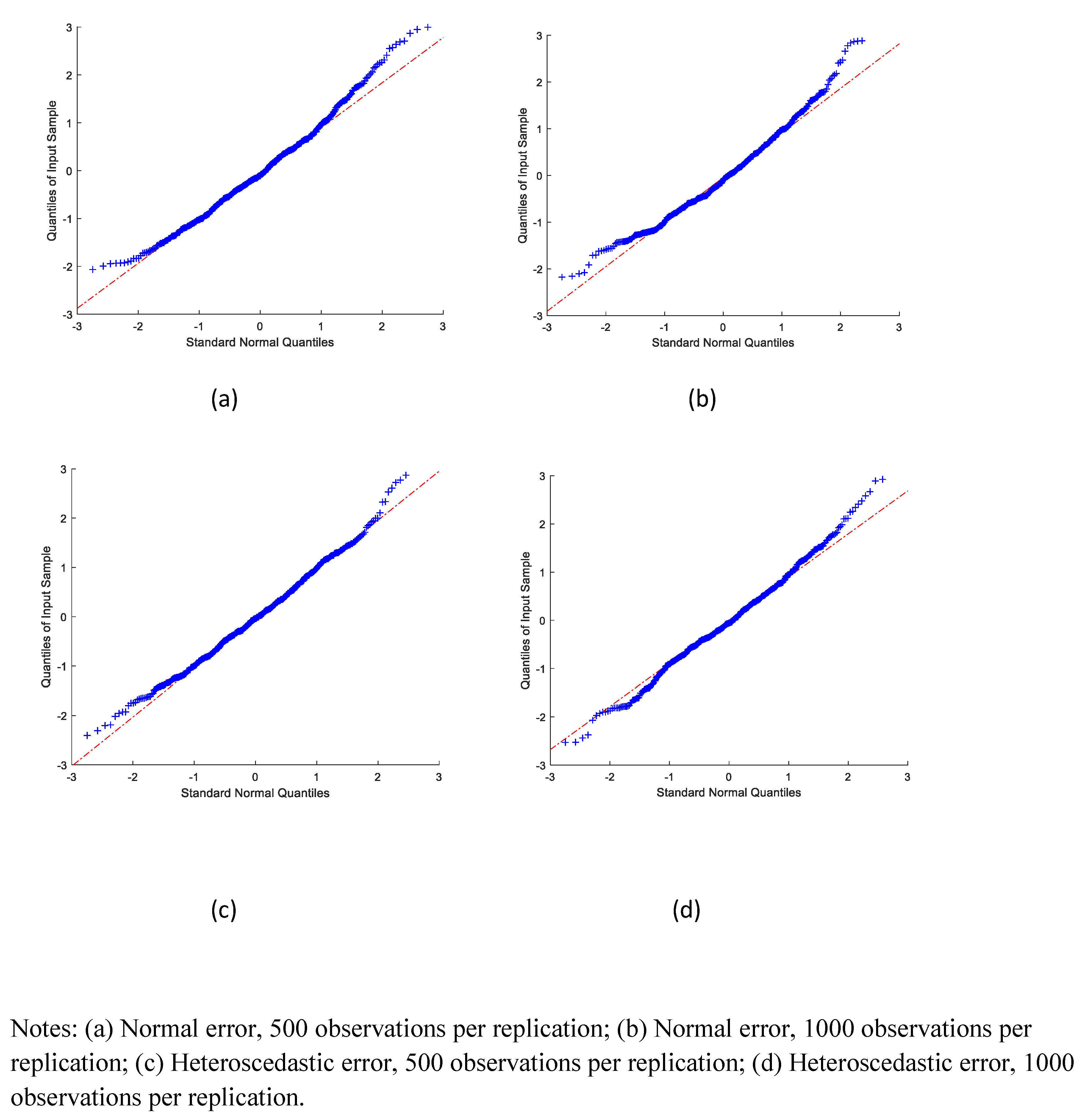
We also examined the distribution of the estimates.
Figure 1,
Figure 2 and
Figure 3 graph the QQ-plots of the standardized SMS estimates of the coefficients on
,
and
, respectively. Most of the standardized estimates appeared to be close to the standard normal quantiles, except for a few extreme values. The extreme values are potentially due to difficulties with numerical optimization. This would seem to indicate that the sampling distributions of the estimators in our simulation exercise were reasonably well approximated by a normal distribution.





{kind=link}
{kind=link}
{kind=link}