
Variable Slope Forecasting Methods and COVID-19 Risk


Abstract
:1. Introduction
2. Materials and Methods
2.1. Modeling the Omitted Variables Problem
2.2. Solutions to the Omitted Variables Problem
3. Results
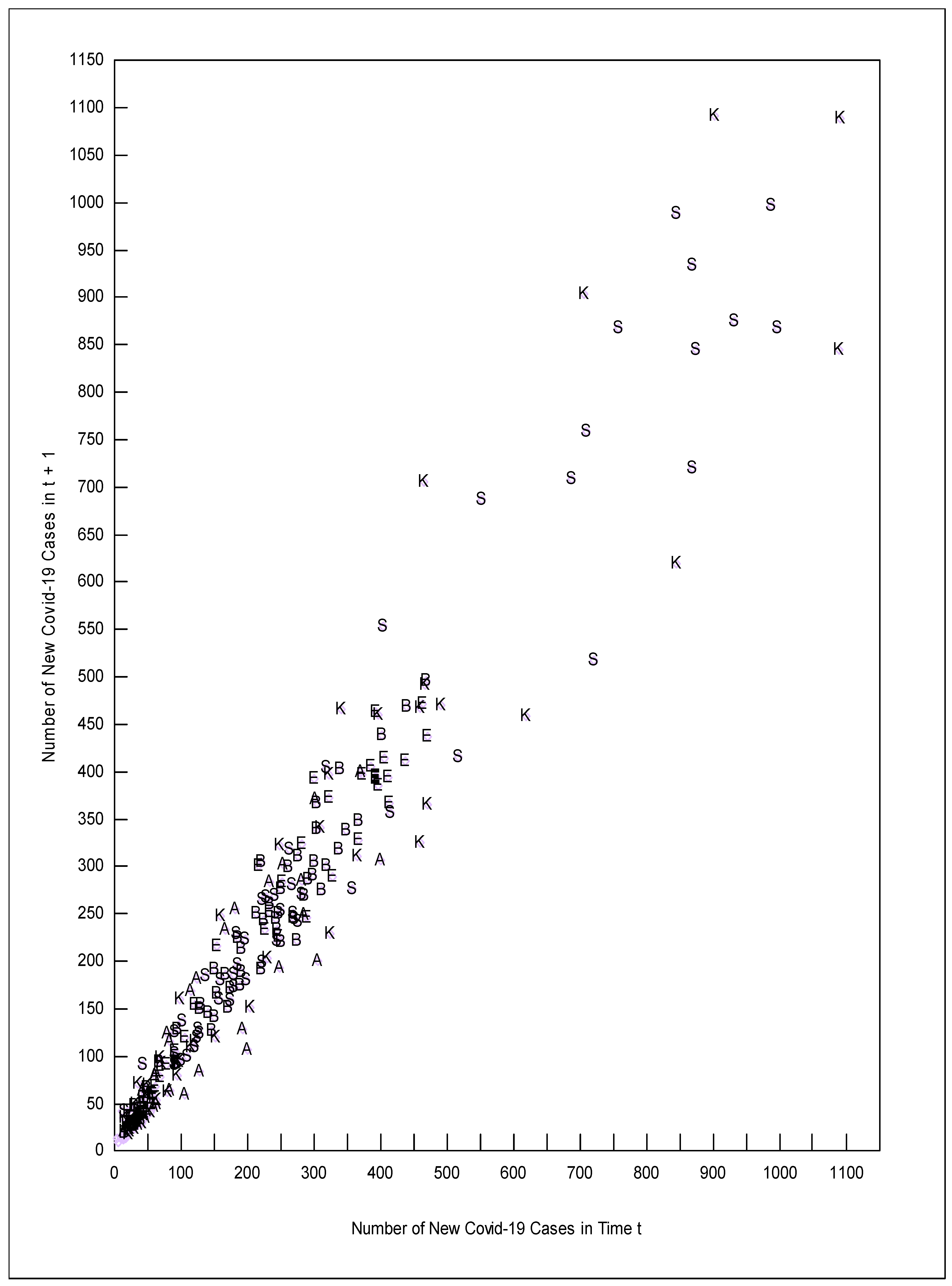
4. An Example—The Spread Rate of COVID-19
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
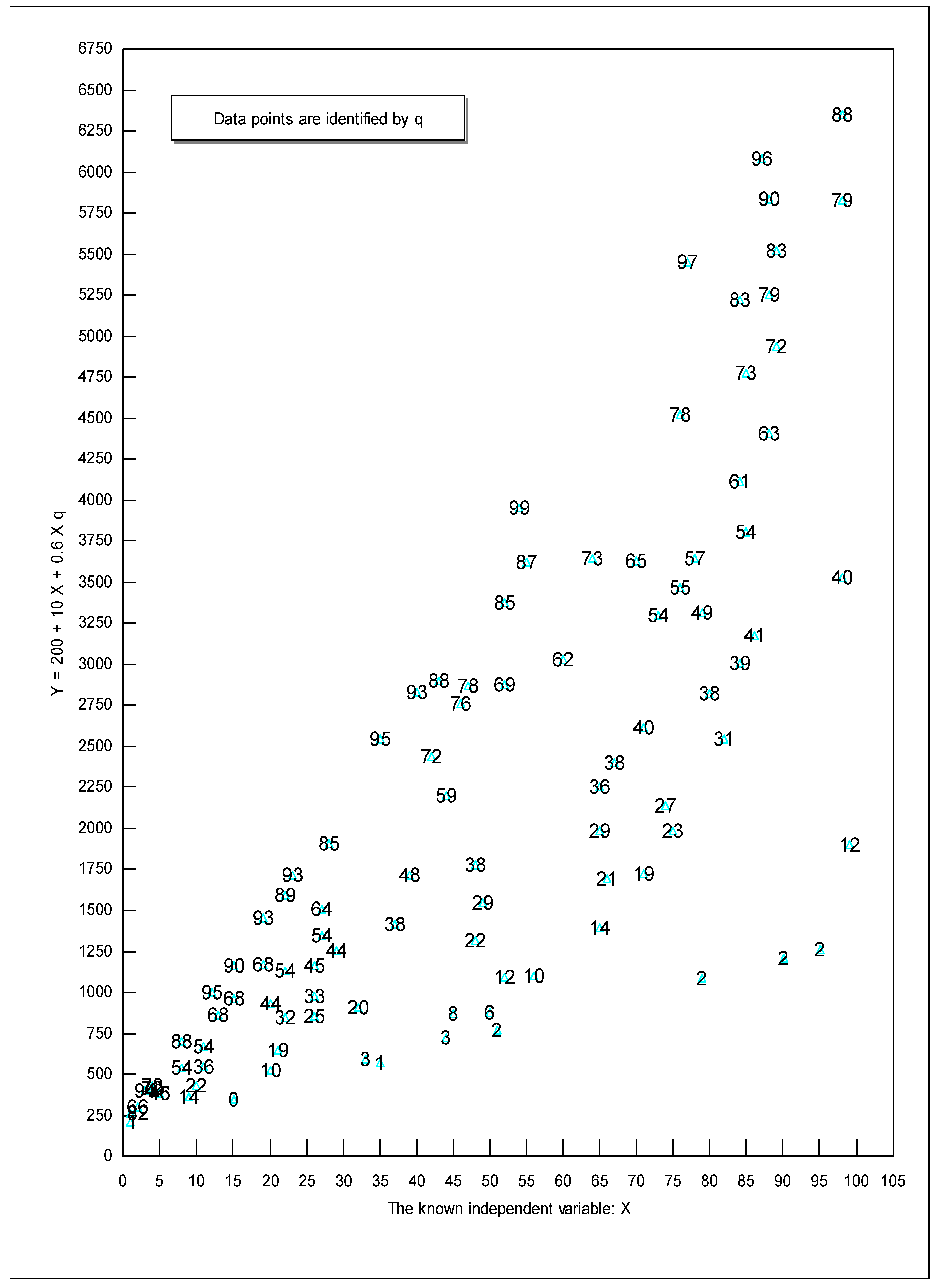
| 1 | Some researchers might see a dY/dX = (β1 + β2ȣ1) as a problem since the coefficient on X in Equation (1) is just β1. However, we disagree because a one-unit increase in X would cause Y to increase by exactly β1 + β2ȣ1 even if ȣ2 Xq is not included in Equation (2). In contrast, if ȣ2 Xq is included in Equation (2), then a one-unit increase in X will not cause Y to increase by an amount equal to just β1, as shown by Equation (7) below (Leightner 2015). |
| 2 | Assuming that u is independent of q and u ~ N(0,σu2). If this assumption does not hold, our conclusions are not changed; however, the math is more complex. |
| 3 | However, Panel N reveals that the standard error of |e| is always much less for VSGLS than it is for RTPLS no matter what the sample size, the importance of the omitted variable, or the amount of measurement and round off error. |
| 4 | |
| 5 | If (as is the case when running simulations where all qs are randomly generated) the actual qs fluctuate randomly from observation to observation, then the resulting confidence interval will be huge indicating that predictions based on the RTPLS estimates are not reliable. However, we have only seen this happen once when using real-world time series data. |
References
- Aitken, Alexander Craig. 1935. On Least Squares and Linear Combinations of Observations. Proceedings of the Royal Society of Edinburgh 55: 42–48. [Google Scholar] [CrossRef]
- Arcidiacono, Peter, and Robert Miller. 2011. Conditional Choice Probability Estimation of Dynamic Discrete Choice Models with Unobserved Heterogeneity. Econometrica 79: 1823–67. [Google Scholar]
- Blevins, Jason. 2016. Sequential Monte Carlo Methods for Estimating Dynamic Microeconomic Models. Journal of Applied Econometrics 31: 773–804. [Google Scholar] [CrossRef] [Green Version]
- Bound, John, David A. Jaeger, and Regina M. Baker. 1995. Problems with Instrumental Variables Estimation when the Correlation between the Instruments and the Endogenous Explanatory Variable is Weak. Journal of the American Statistical Association 90: 443–50. [Google Scholar] [CrossRef]
- Branson, Johannah, and Charles Albert (Knox) Lovell. 2000. Taxation and Economic Growth in New Zealand. In Taxation and the Limits of Government. Edited by Gerald W. Scully and Patrick James Caragata. Boston: Kluwer Academic, pp. 37–88. [Google Scholar]
- Center for Disease Control and Prevention. 2021. Science Brief: Emerging SARS-CoV2 Variants. Available online: https://www.cdc.gov/coronavirus/2019-ncov/science/science-briefs/scientific-brief-emerging-variants.html?CDC_AA_refVal=https%3A%2F%2Fwww.cdc.gov%2Fcoronavirus%2F2019-ncov%2Fmore%2Fscience-and-research%2Fscientific-brief-emerging-variants.html (accessed on 15 April 2021).
- Dulaney, Chelsey. 2017. Dollar Kicks off the New Year on a High Note. The Wall Street Journal, January 4, B16. [Google Scholar]
- European Centre for Disease Prevention and Control. 2021. COVID-19 Update Situation, Worldwide. Available online: https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases (accessed on 18 September 2021).
- Hu, Yingyao, Matthew Shum, Wei Tan, and Ruli Xiao. 2017. A Simple Estimator for Dynamic Models with Serially Correlated Unobservables. Journal of Econometric Methods, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Imai, Susumu, Neelam Jain, and Andrew Ching. 2009. Bayesian Estimation of Dynamic Discrete Choice Models. Econometrica 77: 1865–99. [Google Scholar]
- Leightner, Jonathan E. 2015. The Limits of Fiscal, Monetary, and Trade Policies: International Comparisons and Solutions. Singapore: World Scientific. [Google Scholar]
- Leightner, Jonathan E. 2020. Estimates of the Inflation versus Unemployment Tradeoff that are not Model Dependent. Journal of Central Banking Theory and Practice 2020: 5–21. [Google Scholar] [CrossRef] [Green Version]
- Leightner, Jonathan E., and Tomoo Inoue. 2007. Tackling the Omitted Variables Problem without the Strong Assumptions of Proxies. European Journal of Operational Research 178: 819–40. [Google Scholar] [CrossRef]
- Leightner, Jonathan E., and Tomoo Inoue. 2008. Capturing Climate’s Effect on Pollution Abatement with an Improved Solution to the Omitted Variables Problem. European Journal of Operational Research 191: 539–56. [Google Scholar] [CrossRef]
- Leightner, Jonathan E., and Tomoo Inoue. 2012. Solving the Omitted Variables Problem of Regression Analysis using the Relative Vertical Position of Observations. Advances in Decision Sciences. Available online: http://www.hindawi.com/journals/ads/2012/728980/ (accessed on 1 October 2021).
- Li, Ming-Wei, Yu-Tain Wang, Jing Geng, and Wei-Chiang Hong. 2021. Chaos cloud quantum bat hybrid optimization algorithm. Nonlinear Dynamics 103: 1167–93. [Google Scholar] [CrossRef]
- Murray, Michael P. 2017. Linear Model IV Estimation when Instruments are Many or Weak. Journal of Econometric Methods De Gruyter 6: 1–22. [Google Scholar] [CrossRef]
- Nishiura, Hiroshi, Natalie Linton, and Andrei Akhmetzhanov. 2020. Serial interval of novel coronavirus (COVID-19) infections. International Journal of Infectious Diseases 93: 284–86. [Google Scholar] [CrossRef] [PubMed]
- Nizalova, Olena Y., and Irina Murtazashvili. 2016. Exogenous Treatment and Endogenous Factors: Vanishing of Omitted Variable Bias on the Interaction Term. Journal of Econometric Methods De Gruyter 5: 71–78. [Google Scholar] [CrossRef]
- Norets, Andriy. 2009. Inference in dynamic discrete choice models with serially correlated unobserved state variables. Econometrica 77: 1665–82. [Google Scholar]
- Ramsey, James Benard. 1969. Tests for Specification Errors in Classical Linear Least-Squares Regression Analysis. Journal of the Royal Statistical Society, Series B (Methodology) 31: 350–71. [Google Scholar] [CrossRef]
- Sharma, Sunil Kumar, Aashima Bangia, Mohammed Alshehri, and Rashmi Bhardwaj. 2021. Nonlinear Dynamics for the spread of Pathogenesis of COVID-19 Pandemic. Journal of Infection and Public Health 14: 817–31. [Google Scholar] [CrossRef] [PubMed]
- Shaw, Philip, Michael Andrew Cohen, and Tao Chen. 2016. Nonparametric Instrumental Variable Estimation in Practice. Journal of Econometric Methods 5: 153–78. [Google Scholar] [CrossRef] [Green Version]
- Soy, Anne. 2020. Coronavirus in Africa: Five Reasons Why COVID-19 Has Been Less Deadly than Elsewhere. BBC News. October 8. Available online: https://www.bbc.com/news/world-africa-54418613 (accessed on 21 April 2021).
- Zhang, Zichen, and Wei-Chiang Hong. 2021. Application of variational mode decomposition and chaotic grey wolf optimizer with support vector regression for forecasting electric loads. Knowledge-Based Systems 228: 107297. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Column | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| q’s affect | 1000% | 100% | 10% | 1000% | 100% | 10% | 1000% | 100% | 10% | |
| size of u | 0% | 0% | 0% | 1% | 1% | 1% | 10% | 10% | 10% | |
| Panel A | mean |e| | |||||||||
| %OLS e | n = 100 | 0.70887 | 0.17753 | 0.02399 | 0.70887 | 0.17753 | 0.02400 | 0.70886 | 0.17759 | 0.02499 |
| n = 250 | 0.71172 | 0.17706 | 0.02389 | 0.71172 | 0.17706 | 0.02389 | 0.71170 | 0.17707 | 0.02428 | |
| n = 500 | 0.71129 | 0.17682 | 0.02386 | 0.71130 | 0.17682 | 0.02386 | 0.71131 | 0.17685 | 0.02405 | |
| Panel B | ||||||||||
| %VSOLS e | n = 100 | 0.57849 | 0.18976 | 0.02738 | 0.57733 | 0.18552 | 0.03312 | 0.57076 | 0.23972 | 0.32891 |
| n = 250 | 0.42280 | 0.11473 | 0.01564 | 0.42276 | 0.11507 | 0.03476 | 0.42899 | 0.25026 | 0.32705 | |
| n = 500 | 0.31742 | 0.08605 | 0.01141 | 0.32090 | 0.09775 | 0.04337 | 0.36785 | 0.33497 | 0.40862 | |
| Panel C | ||||||||||
| %VSGLS e | n = 100 | 0.02311 | 0.00651 | 0.00089 | 0.02394 | 0.01364 | 0.01499 | 0.04773 | 0.10913 | 0.14922 |
| n = 250 | 0.01017 | 0.00287 | 0.00039 | 0.01179 | 0.01329 | 0.01746 | 0.04600 | 0.12690 | 0.17446 | |
| n = 500 | 0.00544 | 0.00154 | 0.00021 | 0.00790 | 0.01410 | 0.01914 | 0.04884 | 0.13923 | 0.19137 | |
| Panel D | ||||||||||
| %RTPLS e | n = 100 | 0.04071 | 0.00795 | 0.00101 | 0.04150 | 0.01476 | 0.01489 | 0.06231 | 0.10851 | 0.14787 |
| n = 250 | 0.01871 | 0.00335 | 0.00043 | 0.02015 | 0.01349 | 0.01736 | 0.05073 | 0.12618 | 0.17339 | |
| n = 500 | 0.01911 | 0.00290 | 0.00023 | 0.02076 | 0.01450 | 0.01907 | 0.05463 | 0.13874 | 0.19060 | |
| Panel E | standard e of |e| | |||||||||
| %OLS error | n = 100 | 1.0836 | 0.2092 | 0.0275 | 1.0836 | 0.2092 | 0.0275 | 1.0836 | 0.2092 | 0.0275 |
| n = 250 | 1.0941 | 0.2096 | 0.0275 | 1.0941 | 0.2096 | 0.0275 | 1.0941 | 0.2096 | 0.0275 | |
| n = 500 | 1.0947 | 0.2096 | 0.0275 | 1.0947 | 0.2096 | 0.0275 | 1.0947 | 0.2096 | 0.0275 | |
| Panel F | ||||||||||
| %VSOLS error | n = 100 | 3.9096 | 1.3301 | 0.1954 | 3.8981 | 1.2862 | 0.2085 | 3.8267 | 1.5087 | 2.3137 |
| n = 250 | 4.4421 | 1.1361 | 0.1535 | 4.4417 | 1.1332 | 0.3429 | 4.5118 | 2.4587 | 3.2971 | |
| n = 500 | 4.6436 | 1.1903 | 0.1540 | 4.7211 | 1.4233 | 0.6534 | 5.6769 | 5.1948 | 6.1352 | |
| Panel G | ||||||||||
| %VSGLS error | n = 100 | 0.0714 | 0.0170 | 0.0023 | 0.0747 | 0.0378 | 0.0413 | 0.1530 | 0.3052 | 0.4118 |
| n = 250 | 0.0439 | 0.0107 | 0.0014 | 0.0517 | 0.0508 | 0.0657 | 0.1988 | 0.4833 | 0.6567 | |
| n = 500 | 0.0310 | 0.0075 | 0.0010 | 0.0455 | 0.0694 | 0.0930 | 0.2709 | 0.6847 | 0.9298 | |
| Panel H | ||||||||||
| %RTPLS error | n = 100 | 0.1193 | 0.0203 | 0.0025 | 0.1224 | 0.0404 | 0.0414 | 0.1932 | 0.3065 | 0.4126 |
| n = 250 | 0.0749 | 0.0121 | 0.0015 | 0.0818 | 0.0516 | 0.0657 | 0.2178 | 0.4838 | 0.6571 | |
| n = 500 | 0.0922 | 0.0127 | 0.0011 | 0.1030 | 0.0715 | 0.0930 | 0.3012 | 0.6853 | 0.9300 | |
| Panel I | mean |e| ratio | |||||||||
| OLS/RTPLS | n = 100 | 2138.12 | 840.87 | 1062.57 | 117.43 | 31.28 | 3.87 | 28.50 | 3.87 | 0.40 |
| n = 250 | 1696.36 | 2496.56 | 4470.49 | 178.66 | 35.83 | 3.79 | 33.67 | 3.80 | 0.38 | |
| n = 500 | 2729.59 | 3042.64 | 9531.99 | 174.76 | 36.27 | 3.79 | 33.80 | 3.79 | 0.38 | |
| Panel J | ||||||||||
| VSOLS/RTPLS | n = 100 | 660.69 | 236.98 | 247.60 | 29.90 | 7.55 | 1.14 | 7.09 | 1.14 | 0.88 |
| n = 250 | 256.71 | 426.66 | 560.03 | 28.55 | 5.49 | 0.96 | 5.17 | 0.96 | 0.86 | |
| n = 500 | 316.74 | 319.14 | 862.57 | 19.22 | 3.77 | 0.90 | 3.51 | 0.90 | 0.86 | |
| Panel K | ||||||||||
| VSGLS/RTPLS | n = 100 | 34.11 | 2.76 | 2.63 | 1.57 | 1.00 | 1.02 | 0.95 | 1.02 | 1.02 |
| n = 250 | 2.82 | 3.04 | 2.11 | 1.15 | 1.00 | 1.01 | 0.95 | 1.01 | 1.01 | |
| n = 500 | 1.63 | 3.18 | 2.15 | 0.68 | 0.98 | 1.01 | 0.92 | 1.01 | 1.01 | |
| Panel L | standard e of |e| ratio | |||||||||
| OLS/RTPLS | n = 100 | 1.4025 | 1.4025 | 1.4025 | 1.5070 | 1.6937 | 1.7326 | 1.6721 | 1.7344 | 1.7446 |
| n = 250 | 1.4092 | 1.4092 | 1.4092 | 1.5833 | 1.7506 | 1.7563 | 1.7366 | 1.7564 | 1.7613 | |
| n = 500 | 1.4115 | 1.4115 | 1.4115 | 1.5802 | 1.7638 | 1.7671 | 1.7484 | 1.7673 | 1.7699 | |
| Panel M | ||||||||||
| VSOLS/RTPLS | n = 100 | 1.3 × 10−12 | 1.5 × 10−12 | 1.5 × 10−11 | 0.4467 | 1.0568 | 1.2409 | 1.0201 | 1.2446 | 1.1031 |
| n = 250 | 9.5× 10−13 | 4.1× 10−12 | 6.3 × 10−11 | 0.6565 | 1.1906 | 1.2066 | 1.1681 | 1.2065 | 1.1056 | |
| n = 500 | 1.6 × 10−12 | 5.0 × 10−12 | 1.3 × 10−10 | 0.6585 | 1.2508 | 1.1745 | 1.2307 | 1.1743 | 1.1181 | |
| Panel N | ||||||||||
| VSGLS/RTPLS | n = 100 | 1.5 × 10−12 | 1.9 × 10−12 | 1.8 × 10−11 | 0.5163 | 0.6732 | 0.3243 | 0.8881 | 0.3648 | 0.2952 |
| n = 250 | 2.4 × 10−12 | 8.1 × 10−12 | 9.0 × 10−11 | 0.7402 | 0.4993 | 0.2268 | 0.7798 | 0.2504 | 0.2189 | |
| n = 500 | 4.3 × 10−12 | 1.3 × 10−11 | 1.8 × 10−10 | 0.9451 | 0.6504 | 0.1783 | 0.8432 | 0.2486 | 0.1758 | |
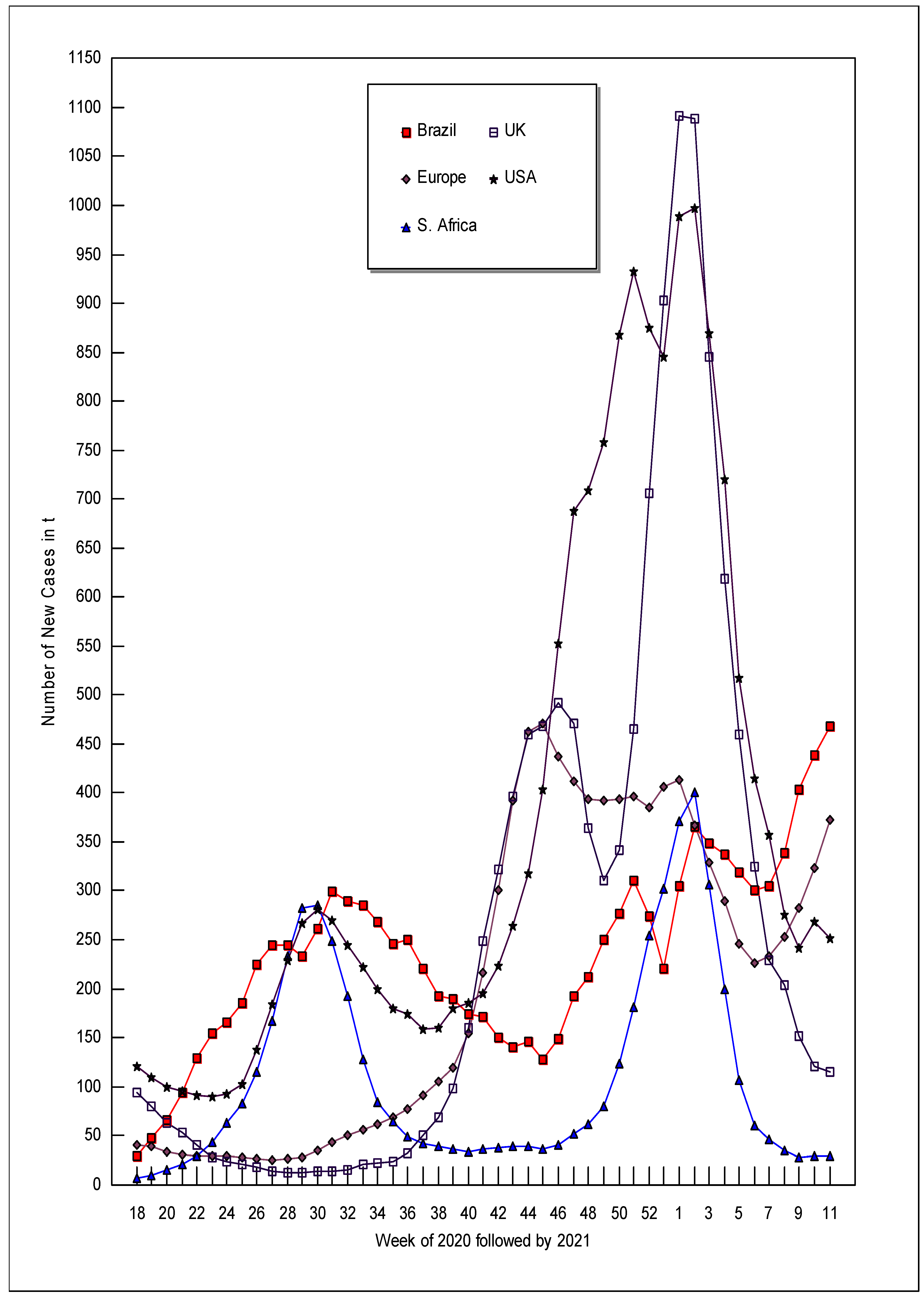
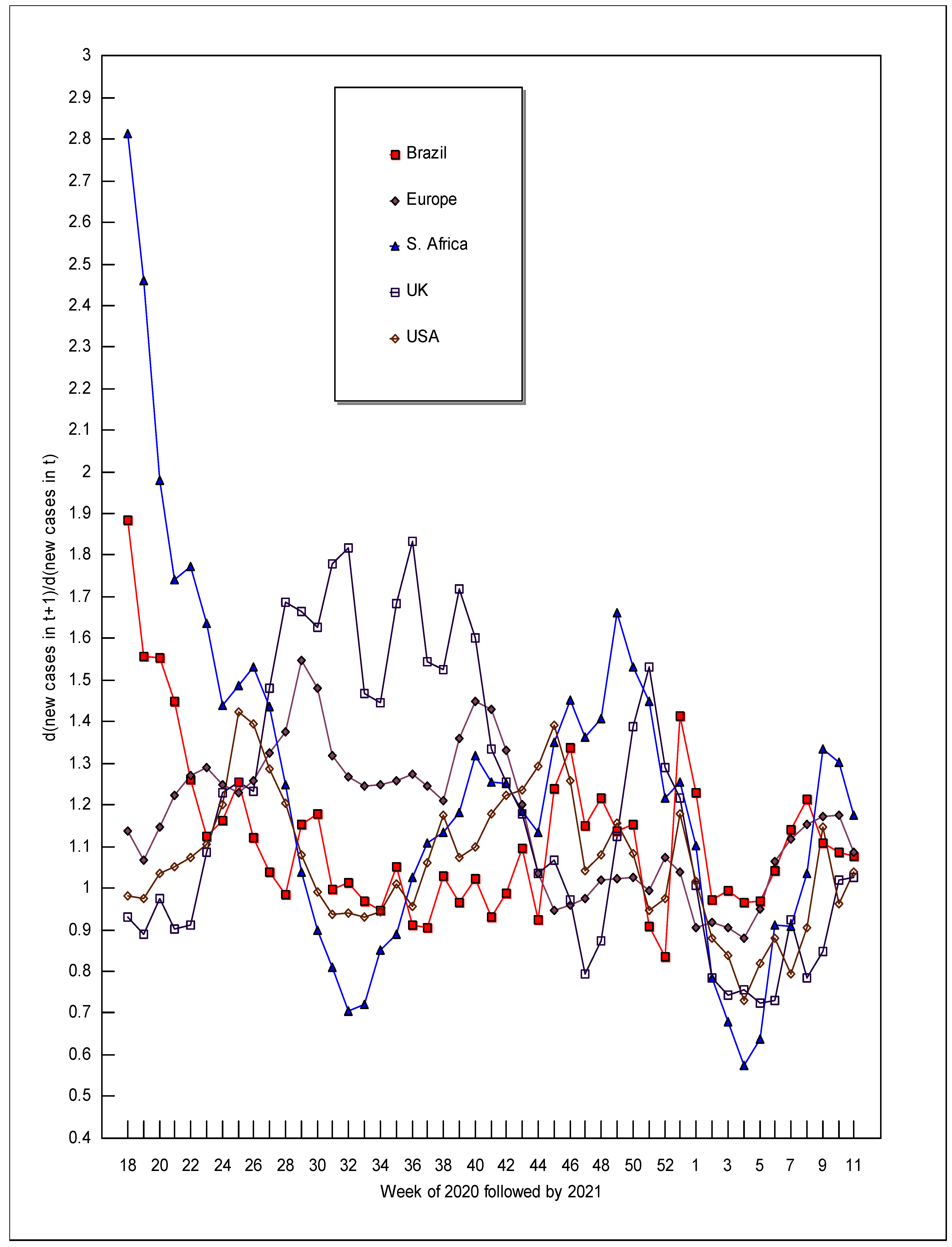
| Year | Week | New Cases in t | dcases in t + 1/dcases in t | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Brazil | Europe | S. Africa | UK | USA | Brazil | Europe | S. Africa | UK | USA | ||
| 2020 | 11 | 20.6 | 3.8 | 2.42 | 5.45 | ||||||
| 2020 | 12 | 41.8 | 12.5 | 10.5 | 1.55 | 3.48 | 4.78 | ||||
| 2020 | 13 | 56.8 | 35.6 | 42.1 | 1.18 | 2.22 | 2.36 | ||||
| 2020 | 14 | 4.5 | 58.9 | 70.9 | 91.4 | 3.64 | 1.07 | 1.41 | 1.46 | ||
| 2020 | 15 | 8.4 | 54.9 | 91.9 | 125.2 | 2.48 | 1.05 | 1.11 | 1.08 | ||
| 2020 | 16 | 12.9 | 49.7 | 94.4 | 127.5 | 2.06 | 1.04 | 1.09 | 1.03 | ||
| 2020 | 17 | 18.7 | 44.0 | 95.3 | 123.4 | 2.00 | 1.11 | 1.07 | 1.04 | ||
| 2020 | 18 | 29.4 | 40.9 | 6.1 | 94.2 | 120.3 | 1.88 | 1.14 | 2.81 | 0.93 | 0.98 |
| 2020 | 19 | 47.4 | 38.6 | 9.2 | 79.6 | 109.9 | 1.56 | 1.07 | 2.46 | 0.89 | 0.98 |
| 2020 | 20 | 65.8 | 33.2 | 14.7 | 62.8 | 99.3 | 1.55 | 1.15 | 1.98 | 0.97 | 1.03 |
| 2020 | 21 | 94.3 | 30.1 | 21.2 | 53.2 | 94.7 | 1.45 | 1.22 | 1.74 | 0.90 | 1.05 |
| 2020 | 22 | 128.8 | 28.9 | 28.9 | 40.1 | 91.7 | 1.26 | 1.27 | 1.77 | 0.91 | 1.07 |
| 2020 | 23 | 154.6 | 28.7 | 43.3 | 28.5 | 90.4 | 1.13 | 1.29 | 1.64 | 1.09 | 1.10 |
| 2020 | 24 | 166.0 | 29.0 | 63.0 | 23.0 | 91.8 | 1.16 | 1.25 | 1.44 | 1.23 | 1.20 |
| 2020 | 25 | 185.0 | 28.2 | 82.6 | 20.3 | 102.3 | 1.25 | 1.23 | 1.49 | 1.26 | 1.42 |
| 2020 | 26 | 224.2 | 26.8 | 114.8 | 17.5 | 137.4 | 1.12 | 1.26 | 1.53 | 1.23 | 1.39 |
| 2020 | 27 | 243.7 | 25.7 | 167.7 | 13.6 | 183.6 | 1.04 | 1.32 | 1.44 | 1.48 | 1.29 |
| 2020 | 28 | 244.9 | 26.0 | 232.9 | 12.2 | 228.4 | 0.98 | 1.38 | 1.25 | 1.69 | 1.21 |
| 2020 | 29 | 233.0 | 27.8 | 282.6 | 12.6 | 267.3 | 1.15 | 1.55 | 1.04 | 1.66 | 1.08 |
| 2020 | 30 | 260.8 | 35.1 | 285.3 | 13.0 | 280.7 | 1.18 | 1.48 | 0.90 | 1.63 | 0.99 |
| 2020 | 31 | 298.9 | 43.9 | 248.1 | 13.2 | 270.3 | 1.00 | 1.32 | 0.81 | 1.78 | 0.94 |
| 2020 | 32 | 290.0 | 49.9 | 192.9 | 15.5 | 245.0 | 1.01 | 1.27 | 0.70 | 1.82 | 0.94 |
| 2020 | 33 | 285.3 | 55.3 | 127.9 | 20.3 | 222.1 | 0.97 | 1.25 | 0.72 | 1.47 | 0.93 |
| 2020 | 34 | 268.3 | 60.9 | 84.2 | 21.8 | 198.7 | 0.95 | 1.25 | 0.85 | 1.44 | 0.94 |
| 2020 | 35 | 245.6 | 68.0 | 63.6 | 23.5 | 179.4 | 1.05 | 1.26 | 0.89 | 1.69 | 1.01 |
| 2020 | 36 | 250.2 | 77.5 | 48.5 | 31.6 | 173.4 | 0.91 | 1.27 | 1.02 | 1.83 | 0.96 |
| 2020 | 37 | 220.2 | 90.8 | 41.7 | 50.0 | 157.9 | 0.91 | 1.25 | 1.11 | 1.54 | 1.06 |
| 2020 | 38 | 191.5 | 105.2 | 38.3 | 69.2 | 159.6 | 1.03 | 1.21 | 1.13 | 1.53 | 1.18 |
| 2020 | 39 | 189.1 | 119.5 | 35.4 | 97.7 | 179.8 | 0.96 | 1.36 | 1.18 | 1.72 | 1.07 |
| 2020 | 40 | 174.4 | 154.6 | 33.9 | 159.7 | 185.2 | 1.02 | 1.45 | 1.32 | 1.60 | 1.10 |
| 2020 | 41 | 170.6 | 216.0 | 36.6 | 247.9 | 195.6 | 0.93 | 1.43 | 1.25 | 1.33 | 1.18 |
| 2020 | 42 | 150.6 | 300.7 | 37.9 | 322.4 | 222.6 | 0.99 | 1.33 | 1.25 | 1.26 | 1.22 |
| 2020 | 43 | 140.7 | 392.4 | 39.4 | 396.8 | 263.9 | 1.09 | 1.20 | 1.19 | 1.18 | 1.24 |
| 2020 | 44 | 146.0 | 462.6 | 38.8 | 459.2 | 318.1 | 0.92 | 1.04 | 1.13 | 1.04 | 1.29 |
| 2020 | 45 | 127.0 | 471.0 | 36.1 | 467.5 | 403.5 | 1.24 | 0.94 | 1.35 | 1.07 | 1.39 |
| 2020 | 46 | 149.3 | 437.1 | 40.8 | 491.3 | 552.8 | 1.34 | 0.96 | 1.45 | 0.97 | 1.26 |
| 2020 | 47 | 191.6 | 411.6 | 51.3 | 470.2 | 687.4 | 1.15 | 0.98 | 1.36 | 0.79 | 1.04 |
| 2020 | 48 | 212.5 | 393.4 | 61.8 | 364.4 | 708.8 | 1.22 | 1.02 | 1.41 | 0.87 | 1.08 |
| 2020 | 49 | 250.3 | 392.6 | 79.1 | 310.3 | 758.3 | 1.14 | 1.02 | 1.66 | 1.12 | 1.16 |
| 2020 | 50 | 276.3 | 393.6 | 123.5 | 341.0 | 868.1 | 1.15 | 1.03 | 1.53 | 1.39 | 1.08 |
| 2020 | 51 | 310.5 | 395.9 | 181.0 | 465.6 | 932.9 | 0.91 | 0.99 | 1.45 | 1.53 | 0.95 |
| 2020 | 52 | 274.0 | 385.4 | 254.4 | 705.7 | 874.6 | 0.84 | 1.07 | 1.22 | 1.29 | 0.97 |
| 2020 | 53 | 221.2 | 405.6 | 301.5 | 903.1 | 844.5 | 1.41 | 1.04 | 1.26 | 1.22 | 1.18 |
| 2021 | 1 | 304.5 | 413.7 | 370.5 | 1091.1 | 988.3 | 1.23 | 0.90 | 1.10 | 1.01 | 1.02 |
| 2021 | 2 | 366.0 | 366.3 | 399.9 | 1089.0 | 996.4 | 0.97 | 0.92 | 0.78 | 0.78 | 0.88 |
| 2021 | 3 | 348.0 | 328.2 | 305.8 | 845.0 | 868.3 | 0.99 | 0.90 | 0.68 | 0.74 | 0.84 |
| 2021 | 4 | 337.6 | 289.0 | 199.6 | 618.9 | 719.9 | 0.97 | 0.88 | 0.57 | 0.75 | 0.73 |
| 2021 | 5 | 318.4 | 246.5 | 106.5 | 458.9 | 517.1 | 0.97 | 0.95 | 0.64 | 0.72 | 0.82 |
| 2021 | 6 | 299.9 | 226.2 | 59.9 | 324.6 | 414.8 | 1.04 | 1.06 | 0.91 | 0.73 | 0.88 |
| 2021 | 7 | 304.4 | 232.8 | 46.6 | 228.8 | 357.0 | 1.14 | 1.12 | 0.91 | 0.92 | 0.79 |
| 2021 | 8 | 338.9 | 252.2 | 34.4 | 203.5 | 275.4 | 1.21 | 1.15 | 1.04 | 0.78 | 0.91 |
| 2021 | 9 | 402.9 | 282.5 | 27.7 | 151.4 | 241.3 | 1.11 | 1.17 | 1.34 | 0.85 | 1.15 |
| 2021 | 10 | 438.8 | 323.1 | 29.0 | 120.3 | 268.8 | 1.09 | 1.18 | 1.30 | 1.02 | 0.96 |
| 2021 | 11 | 468.5 | 372.2 | 29.8 | 114.7 | 250.9 | 1.08 | 1.09 | 1.18 | 1.03 | 1.04 |
| 2021 | 12 | 495.9 | 396.6 | 27.0 | 109.6 | 252.7 | |||||
| Year | Week | Brazil | Europe | S. Africa | UK | USA | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | ||
| 2020 | 15 | 0.02 | 2.88 | −1.67 | 7.14 | ||||||
| 2020 | 16 | 0.64 | 1.71 | −0.65 | 4.37 | −1.75 | 6.04 | ||||
| 2020 | 17 | 0.95 | 1.23 | 0.17 | 2.59 | −0.02 | 2.81 | ||||
| 2020 | 18 | 0.62 | 4.20 | 0.98 | 1.18 | 0.69 | 1.56 | 0.64 | 1.60 | ||
| 2020 | 19 | 1.17 | 2.83 | 0.98 | 1.18 | 0.76 | 1.27 | 0.91 | 1.13 | ||
| 2020 | 20 | 1.21 | 2.41 | 0.99 | 1.21 | 0.77 | 1.21 | 0.93 | 1.09 | ||
| 2020 | 21 | 1.10 | 2.28 | 1.00 | 1.28 | 0.77 | 1.14 | 0.93 | 1.11 | ||
| 2020 | 22 | 0.98 | 2.10 | 0.97 | 1.36 | 0.99 | 3.31 | 0.84 | 1.00 | 0.92 | 1.13 |
| 2020 | 23 | 0.92 | 1.86 | 0.97 | 1.43 | 1.11 | 2.73 | 0.75 | 1.15 | 0.93 | 1.17 |
| 2020 | 24 | 0.85 | 1.77 | 1.10 | 1.37 | 1.22 | 2.21 | 0.68 | 1.36 | 0.93 | 1.26 |
| 2020 | 25 | 0.94 | 1.56 | 1.18 | 1.32 | 1.24 | 1.99 | 0.66 | 1.49 | 0.79 | 1.55 |
| 2020 | 26 | 1.02 | 1.36 | 1.20 | 1.32 | 1.24 | 1.90 | 0.78 | 1.50 | 0.84 | 1.64 |
| 2020 | 27 | 0.95 | 1.34 | 1.18 | 1.36 | 1.30 | 1.71 | 0.90 | 1.61 | 0.95 | 1.61 |
| 2020 | 28 | 0.85 | 1.38 | 1.13 | 1.44 | 1.16 | 1.70 | 0.87 | 1.88 | 1.05 | 1.56 |
| 2020 | 29 | 0.85 | 1.37 | 1.03 | 1.66 | 0.84 | 1.85 | 0.93 | 2.00 | 0.93 | 1.63 |
| 2020 | 30 | 0.89 | 1.30 | 1.10 | 1.69 | 0.57 | 1.89 | 1.07 | 2.01 | 0.79 | 1.59 |
| 2020 | 31 | 0.85 | 1.29 | 1.16 | 1.66 | 0.45 | 1.72 | 1.38 | 1.92 | 0.74 | 1.46 |
| 2020 | 32 | 0.83 | 1.29 | 1.11 | 1.68 | 0.41 | 1.46 | 1.52 | 1.91 | 0.75 | 1.31 |
| 2020 | 33 | 0.82 | 1.30 | 1.04 | 1.71 | 0.49 | 1.18 | 1.33 | 2.01 | 0.82 | 1.13 |
| 2020 | 34 | 0.79 | 1.25 | 1.07 | 1.56 | 0.59 | 1.00 | 1.20 | 2.05 | 0.89 | 1.01 |
| 2020 | 35 | 0.89 | 1.10 | 1.19 | 1.34 | 0.60 | 0.99 | 1.21 | 2.07 | 0.87 | 1.03 |
| 2020 | 36 | 0.84 | 1.11 | 1.23 | 1.29 | 0.51 | 1.16 | 1.19 | 2.11 | 0.88 | 1.04 |
| 2020 | 37 | 0.81 | 1.10 | 1.22 | 1.28 | 0.54 | 1.30 | 1.19 | 2.00 | 0.85 | 1.12 |
| 2020 | 38 | 0.80 | 1.14 | 1.19 | 1.30 | 0.68 | 1.32 | 1.22 | 1.99 | 0.80 | 1.26 |
| 2020 | 39 | 0.81 | 1.14 | 1.13 | 1.41 | 0.78 | 1.35 | 1.34 | 1.98 | 0.85 | 1.26 |
| 2020 | 40 | 0.82 | 1.11 | 1.07 | 1.55 | 0.89 | 1.42 | 1.32 | 1.97 | 0.88 | 1.27 |
| 2020 | 41 | 0.83 | 1.11 | 1.07 | 1.60 | 0.98 | 1.41 | 1.20 | 1.89 | 0.98 | 1.26 |
| 2020 | 42 | 0.88 | 1.09 | 1.12 | 1.59 | 1.05 | 1.40 | 1.01 | 1.96 | 1.00 | 1.30 |
| 2020 | 43 | 0.84 | 1.16 | 1.11 | 1.60 | 1.10 | 1.38 | 0.84 | 1.99 | 0.98 | 1.34 |
| 2020 | 44 | 0.82 | 1.17 | 0.86 | 1.72 | 1.06 | 1.40 | 0.76 | 1.80 | 1.03 | 1.39 |
| 2020 | 45 | 0.71 | 1.36 | 0.69 | 1.69 | 1.03 | 1.44 | 0.86 | 1.48 | 1.06 | 1.47 |
| 2020 | 46 | 0.69 | 1.54 | 0.68 | 1.51 | 0.96 | 1.59 | 0.82 | 1.38 | 1.11 | 1.45 |
| 2020 | 47 | 0.76 | 1.53 | 0.76 | 1.28 | 0.97 | 1.62 | 0.66 | 1.36 | 0.93 | 1.56 |
| 2020 | 48 | 0.79 | 1.56 | 0.89 | 1.08 | 1.04 | 1.64 | 0.66 | 1.23 | 0.85 | 1.58 |
| 2020 | 49 | 1.02 | 1.41 | 0.90 | 1.07 | 1.13 | 1.76 | 0.63 | 1.30 | 0.84 | 1.53 |
| 2020 | 50 | 0.99 | 1.40 | 0.92 | 1.08 | 1.19 | 1.78 | 0.45 | 1.62 | 0.91 | 1.34 |
| 2020 | 51 | 0.82 | 1.41 | 0.95 | 1.06 | 1.19 | 1.78 | 0.35 | 1.94 | 0.87 | 1.25 |
| 2020 | 52 | 0.64 | 1.46 | 0.95 | 1.10 | 1.04 | 1.86 | 0.61 | 1.87 | 0.83 | 1.26 |
| 2020 | 53 | 0.52 | 1.65 | 0.96 | 1.10 | 0.96 | 1.89 | 0.92 | 1.70 | 0.81 | 1.33 |
| 2021 | 1 | 0.52 | 1.69 | 0.85 | 1.17 | 0.87 | 1.75 | 0.80 | 1.78 | 0.81 | 1.27 |
| 2021 | 2 | 0.47 | 1.67 | 0.80 | 1.17 | 0.55 | 1.77 | 0.46 | 1.87 | 0.72 | 1.28 |
| 2021 | 3 | 0.52 | 1.66 | 0.77 | 1.17 | 0.36 | 1.65 | 0.39 | 1.62 | 0.65 | 1.31 |
| 2021 | 4 | 0.62 | 1.61 | 0.77 | 1.09 | 0.16 | 1.60 | 0.39 | 1.41 | 0.50 | 1.36 |
| 2021 | 5 | 0.74 | 1.31 | 0.85 | 0.97 | 0.24 | 1.27 | 0.51 | 1.09 | 0.60 | 1.12 |
| 2021 | 6 | 0.91 | 1.07 | 0.76 | 1.12 | 0.39 | 1.05 | 0.69 | 0.80 | 0.68 | 0.98 |
| 2021 | 7 | 0.84 | 1.20 | 0.73 | 1.24 | 0.35 | 1.14 | 0.57 | 0.98 | 0.67 | 0.95 |
| 2021 | 8 | 0.80 | 1.34 | 0.75 | 1.32 | 0.32 | 1.31 | 0.58 | 0.99 | 0.65 | 1.00 |
| 2021 | 9 | 0.86 | 1.33 | 0.87 | 1.31 | 0.34 | 1.59 | 0.59 | 1.01 | 0.56 | 1.26 |
| 2021 | 10 | 0.96 | 1.28 | 1.02 | 1.25 | 0.58 | 1.61 | 0.58 | 1.15 | 0.61 | 1.27 |
| 2021 | 11 | 0.99 | 1.26 | 1.05 | 1.24 | 0.70 | 1.60 | 0.66 | 1.18 | 0.64 | 1.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leightner, J.; Inoue, T.; Micheaux, P.L.d. Variable Slope Forecasting Methods and COVID-19 Risk. J. Risk Financial Manag. 2021, 14, 467. https://doi.org/10.3390/jrfm14100467
Leightner J, Inoue T, Micheaux PLd. Variable Slope Forecasting Methods and COVID-19 Risk. Journal of Risk and Financial Management. 2021; 14(10):467. https://doi.org/10.3390/jrfm14100467
Chicago/Turabian StyleLeightner, Jonathan, Tomoo Inoue, and Pierre Lafaye de Micheaux. 2021. "Variable Slope Forecasting Methods and COVID-19 Risk" Journal of Risk and Financial Management 14, no. 10: 467. https://doi.org/10.3390/jrfm14100467
APA StyleLeightner, J., Inoue, T., & Micheaux, P. L. d. (2021). Variable Slope Forecasting Methods and COVID-19 Risk. Journal of Risk and Financial Management, 14(10), 467. https://doi.org/10.3390/jrfm14100467