1. Introduction
The greatest challenge to the widespread adoption of machine learning methods in credit underwriting is the risk of violating the
Fair Credit Reporting Act (
FCRA) (
2012) by providing recommendations that are adversely correlated with protected class status such as race, gender, religion, zipcode, etc. The challenge arises from the ability of machine learning methods to leverage superficially unrelated data to infer structure that is highly correlated with protected class status, even though the input data did not explicitly include any such factors. Past FCRA rulings indicate that a model’s forecasts cannot be adjusted after development to remove bias. Rather, the model must be developed initially to lack any prohibited correlations.
Our work creates a two-step modeling process to prevent the final model from having any structures, linear correlation, or nonlinear dependence related to protected class status. This is accomplished by first creating a model that predicts loan output using only prohibited information. This is used as a fixed input to a second model that only uses seemingly appropriate information but that could otherwise exhibit correlations to protected class status. When the model is used for loan underwriting, the first model on restricted information is replaced with a single average loss rate, which serves as what would have been the intercept term of the model using appropriate inputs.
This seemingly simple procedure has some subtle consequences and benefits and is ideally suited to unconstrained or uncontrollable machine learning models. Other groups have developed bias measurement toolkits intended to help researchers measure potential bias and adjust their models appropriately (
Bellamy et al. 2019;
Saleiro et al. 2018). Our goal is to develop a modeling procedure that cannot be biased as a consequence of its construction, guaranteeing that it would pass such tests.
The article begins with a discussion of bias in machine learning and unique challenges in lending.
Section 3 describes the test data, including census data and performance of subprime credit cards.
Section 4 describes the modeling methods used for this test.
Section 5 and
Section 6 provide the model estimation details and test results.
2. Definitions of Bias
Concerns about bias in machine learning are widespread. Examples of failures in the criminal justice system (
Završnik 2019), hiring at Amazon (
Dastin 2018), suggestions of problems with the Apple Card (
Knight 2019), and facial recognition (
Herlitz and Lovén 2013) are just a few (
O’neil 2016). Notably, the defense of Apple Card against gender bias in the assignment of credit lines was that none of the inputs included gender. However, gender blindness does not guarantee gender neutrality, which is the essence of the problem in applying machine learning to credit risk modeling.
Mehrabi et al. (
2021) put all the potential sources of bias into two broad categories: bias in the data or bias in the algorithm. Within these they define 23 kinds of bias. Among the problems that can occur in machine learning, overfitting is the most pervasive and probably the most studied (
Gençay and Qi 2001). Furthermore, neural networks can be susceptible to a “recency” bias, wherein the model’s parameters are more heavily tuned to the most recent training data (
Gradojevic et al. 2009). Furthermore, data snooping bias (
Sermpinis et al. 2016) occurs when models are trained multiple times on the same data set, eventually making the test data part of the training data or simply causing researchers to misjudge the significance of their results.
However, the bias problem in lending is actually different from all 23 identified by Mahrabi. Our data may faithfully represent what is in society and have no knowledge of protected class status, and yet correlate to such status in violation of FCRA. This is an unintended ethical bias (
Shadowen 2019). So how do we remove an ethical bias with no knowledge of the ethical conflict? The truth is that we cannot. Judging a model on ethical bias after it was created without knowledge of protected class status is a doomed approach, and yet is how regulators appear to be approaching the problem. To prevent ethical bias, we must know that we are biased or at least where we have risk of bias. Having color-blind data does not protect us from creating models that are color-biased.
With linear methods, we generally feel safe in saying that no information on protected class status was given to the model, so the results are unbiased. The same cannot be said of machine learning (
Feldman et al. 2015;
Prince and Schwarcz 2019), especially when given alternate inputs. Big data and sophisticated modeling approaches create significant risks of unfair treatment (
O’neil 2016). Unfortunately, a linear mindset underlies US regulations.
One such example showed that the digital footprint of an online borrower was as predictive as FICO score, yet all of those digital footprint data elements probably correlate to protected class status (
Berg et al. 2018). Excluding protected data is insufficient to assert that the final model’s forecasts do not correlate to protected status. Simple linear correlation is the standard for finding discrimination.
We refer to this as an unintended bias, because the model developer may take no actions specifically intended to create such bias and may themselves be unaware of the presence of bias. The unawareness of bias can easily occur, because except for mortgage reporting requirements, lenders are actually prohibited from collecting data on protected class status in a way that would allow a credit risk model developer to conclusively test the models. The best that can be done today is to guess ethnicity from last names, as regulators have been attempting, and yet that process is prone to being unfair as well.
The task then becomes creating a model that is ethically unbiased, even though the data set provides no information against which to test for bias. To be blunt, that is practically impossible for the most well-meaning human agent. For an automated algorithm, failure is assured, eventually. The solutions will be legal as much as statistical (
Lehr and Ohm 2017).
For the present research, we imagine a world where protected class status is included in the data set, so that we can intentionally prevent bias and test for success. This is often true in applications outside lending, such as Amazon’s hiring data or criminal justice data, on which we hope this approach might be tested. In order to test the approach on lending data, we will use US Census data by 5-digit zip code as a proxy for who the borrowers might have been.
3. Data
Data were obtained from a Near Prime to Subprime credit card portfolio, defined as less than 700 FICO. The data sample contained 146,500 accounts originated between 2005 and 2019, which were split half for testing and half for training. Averaged across the observed period from 2007 through 2019, the default rate was 6.2%. We specifically avoided data from the SARS-CoV-2 (COVID-19) pandemic. Performance data during this period was strongly affected by job losses but also government support programs and lender forbearance programs that are not well-captured in the data. In addition, these programs are not yet closed at the time of this research, so the ultimate default outcomes are not yet known (
Breeden et al. 2021).
The later analysis will create models using only that information available at origination to predict later defaults. The portfolio data included the following metrics:
Original score
Original interest rate
Subcategory
Credit limit
Balance transfer
Total loan balance
Total deposits
5-digit Zipcode
Total loan balance and total deposits refer to the complete relationship of the borrower with the lender across all products.
The US Census data was obtained from the 2010 census, which had the best overlap to the available loan data. The following fields were extracted, specifically because they would not be FCRA compliant.
Median age
Male to female ratio
Persons per household
Asian fraction
Black fraction
Native American fraction
Native Hawaiian fraction
Hispanic fraction
The origination data from the loan portfolio was matched by 5-digit zipcode to incorporate the census data. We cannot know the actual age, gender, or ethnicity of the borrower, but simply assigned the probability or average of these values from the census data for the area where they reside.
Table 1 shows the correlations between the assigned census values and the loan data. In almost all cases, statistically significant correlations are found, even though those correlations are slight. Correlations to interest rate and credit limit are excusable when the same data correlates to the original credit bureau score used for underwriting.
This table is not evidence of bias. At most, it is evidence of a cultural problem that non-white ethnic groups in the US are poorer than corresponding white borrowers. Notably, in almost every case, when the percentage of an ethnic group rises and bureau scores decline, interest rates rise and credit limits decline. The movement of interest rates and credit limits relative to bureau scores is financially reasonable. The correlation between ethnicity and bureau score is where the cultural problem lies.
The challenge faced by lenders is proving a lack of bias. The portfolio analyzed here used underwriting methods that passed regulatory review on the basis that they did not have any protected class status inputs; the models were linear, and the sensitive factors in the model were to the borrowers’ past financial performance, as measured at the credit bureaus. In a world of alternate data and machine learning, even when everything is undertaken properly, residual correlations to protected class are almost certain unless explicit preventative measures can be taken.
4. Model Development
Among the research into how to modify the input data,
Feldman et al. (
2015) identify the specific input factors causing the problem and adjust them the least amount possible so as to prevent an assessment of bias.
Kamiran and Calders (
2010) create a preferential sampling of the input data to eliminate the risk of creating biased models.
Zliobaite et al. (
2011) seek to modify the dependent variable in the input training data to remove historic bias prior to model training.
Zemel et al. (
2013) formulate fairness as a problem of finding an optimal representation of the data file, simultaneously obfuscating information about protected class status.
For research into how to modify the model training or use,
Luo et al. (
2015) create a discrimination-aware association rule classifier incorporating a discrimination adjustment during classifier training.
Fish et al. (
2015) modified the hypothesis output of the AdaBoost classification algorithm by shifting the decision boundary for the protected class.
Kozodoi et al. (
2021) review methods in credit scoring for incorporating fairness criteria into the machine learning development process.
Kamishima et al. (
2012) create a regularization approach applicable to any model that removes prediction bias.
Zafar et al. (
2015) explain a mechanism to design fair classifiers via tunable decision boundaries to apply varying degrees of fairness.
Correlation is a simple linear measure. A simple, even-ordered polynomial relationship between the default outcome and a restricted input could discriminate against borrowers and yet slip past a linear correlation test. To comply with the spirit of the law and the ethics behind the law, our approach seeks to make sure that nonlinear methods such as the many machine learning approaches do not find pockets of predictability relative to restricted inputs.
To achieve nonlinear independence between credit risk modeling and restricted inputs, we propose the following analysis steps:
Perform age–period–cohort analysis to quantify lifecycle and environment.
Create a scoring model via regression or machine learning using only restricted inputs and APC functions as a fixed offset.
Create a second scoring model via regression or machine learning using only apparently acceptable inputs with the restricted scoring model and APC functions as a fixed offset.
Create the forecasts from the second scoring model with the restricted scoring model inputs set to zero.
The first step, using age–period–cohort analysis, allows us to normalize the default performance for changing macroeconomic environments, seasonality, and the lifecycle versus age of the account. This is optional as part of creating a score, but it serves both to stabilize the score estimation through different phases of the economic environment and to allow the model to predict calibrated probability of default using macroeconomic scenarios (
Breeden and Thomas 2008).
The second step of building an APC Score using only restricted inputs and with the APC lifecycle and environment as fixed inputs is designed to provide a worst-case model. What is the most structure that can be explained statistically due to restricted inputs, even though we know that these inputs are correlated with financially reasonable inputs such as bureau scores, as seen in
Table 1? To be clear, this model will never be used in underwriting. It is created only so that the next model can be unbiased.
The third step creates another APC Score, this time with the restricted model and APC lifecycle and environment all as fixed inputs. The traditional credit risk factors considered in this step will therefore be explaining only that structure not previously captured by product lifecycle, economic environment, seasonality, and protected class status.
Forecasts from this model would be unacceptable, because the model includes the restricted model. However, the restricted model is a separable component of the model that will be mean-zero from the estimation process. Simply setting the restricted model input to 0 at the time the model is run would eliminate any influence in the forecast from those restricted inputs. The model will be age-, gender-, and ethnicity-blind to the extent that the restricted model captured those sensitivities. The better the restricted model, the more unbiased will be the final forecasts in step 4.
For comparison, in the results section, we also created a credit risk model without the restricted model inputs in order to represent how models are created today. We will compare the traditional approach to the use of a restricted model to see how much forecasting accuracy degrades from this process.
4.1. Age–Period–Cohort Analysis
Age–period–cohort models (
Breeden 2014;
Glenn 2005;
Mason and Fienberg 1985;
Ryder 1965) are a kind of vintage analysis and are closely related to panel survival models. The advantage of APC in modeling lending data comes from the ability to explicitly set constraints on the linear trend ambiguity between age, vintage, and time functions. We know from the work by
Holford (
1983) that, once the constant and linear terms are appropriately incorporated, the nonlinear structure for
F,
G, and
H is uniquely estimable.
The target variable for this study is the probability of default (
PD), where default is measured as being ≥90 days past due.
PD is measured relative to the previous months’ active accounts. Attrition is not explicitly modeled, because consumer credit cards are more likely to go dormant than be closed by request of the cardholder. Account closure is most often initiated by the lender in moments when they seek to reduce their risk from those dormant credit cards becoming unexpectedly active or stolen.
Loan performance can be described in an APC model as
, referred to as the lifecycle, measures the loan’s default risk as a function of age of the loan, a. captures the unique credit risk of each vintage as a function of origination date, v. measures variation in default rates by calendar date t to capture environmental risks such as macroeconomic impacts and seasonality.
In the present context, these functions were estimated nonparametrically via Bayesian APC (
Schmid and Held 2007). Nonparametric estimation is appealing for capturing details in the vintage and environmental functions. Because the lifecycle, credit risk, and environment functions are summed, only one overall intercept term may be estimated. By convention, the estimates are constrained so that the mean of the vintage function
and mean of the environment function
both equal 0. The relationship
also requires that an assumption be made about how to remove the linear specification error. Consistent with earlier work (
Breeden and Canals-Cerdá 2018), this is accomplished using an orthogonal projection onto the space of functions that are orthogonal to all linear functions. The coefficients obtained are then transformed back to the original specification.
4.2. APC Scoring
Previous work (
Breeden 2016) has shown that the vintage function
may be replaced with an account level credit score. A panel logistic regression model may be created with
as fixed inputs. “Fixed” means that the coefficient for those inputs is unchanged during the model estimation. This has the effect of letting
specify the mean of the distribution at each forecast month, and the logistic regression model estimates the distribution of account risk centered about that mean.
where
are the available attributes
at origination for account
i. The
are the coefficients to be estimated. Vintage dummies are included with coefficients
. To avoid colinearity problems between the APC and scoring components, the lifecycle and environment functions from the APC analysis,
are taken as fixed inputs when creating the logistic regression model in Equation (
3).
4.3. Stochastic Gradient Boosted Trees
For the present study, any machine learning method might be employed. Neural networks of various forms have many proponents within credit risk modeling, partly because they can be structured to improve credit decision explainability (
Yang et al. 2020). For this demonstration project, we have chosen to use stochastic gradient boosting due to its popularity among credit risk modelers and broad success in data science.
The credit score is built as a decision tree with each split optimized according to fitness function that is controlled by the stochastic gradient boosting algorithm. Conceptually, one could describe boosting as a process of building subsequent models on the residuals of previous models, though for model types that have no explicit measure of residuals (
Schapire 2003;
Schapire and Freund 2013). Gradient boosting (
Friedman 2001) computes the gradient of a fitness function in order to provide weights to each model trained. Stochastic gradient boosting (
Friedman 2002) combines bagging with gradient boosting, building an ensemble of ensembles of trees, where different gradient boosted ensembles are built for each data sample.
4.4. APC + SGB Trees
To maintain parity with the APC scoring approach, the stochastic gradient-boosted trees were also created with a fixed input using the lifecycle and environment from APC (
Breeden and Leonova 2019). This approach combines the discrimination power of SGB trees with the adaptation through time of vintage analysis and is proving highly effective as a method to combine scoring and long-range forecasting.
In the study of unintended bias, the APC + SGB trees also provides a natural approach to include the structure of the restricted model as a separable component to be dropped out later.
5. Model Estimation
All the models created for this study begin with an age–period–cohort analysis of the data to normalize for trends due to product lifecycles and macroeconomic trends.
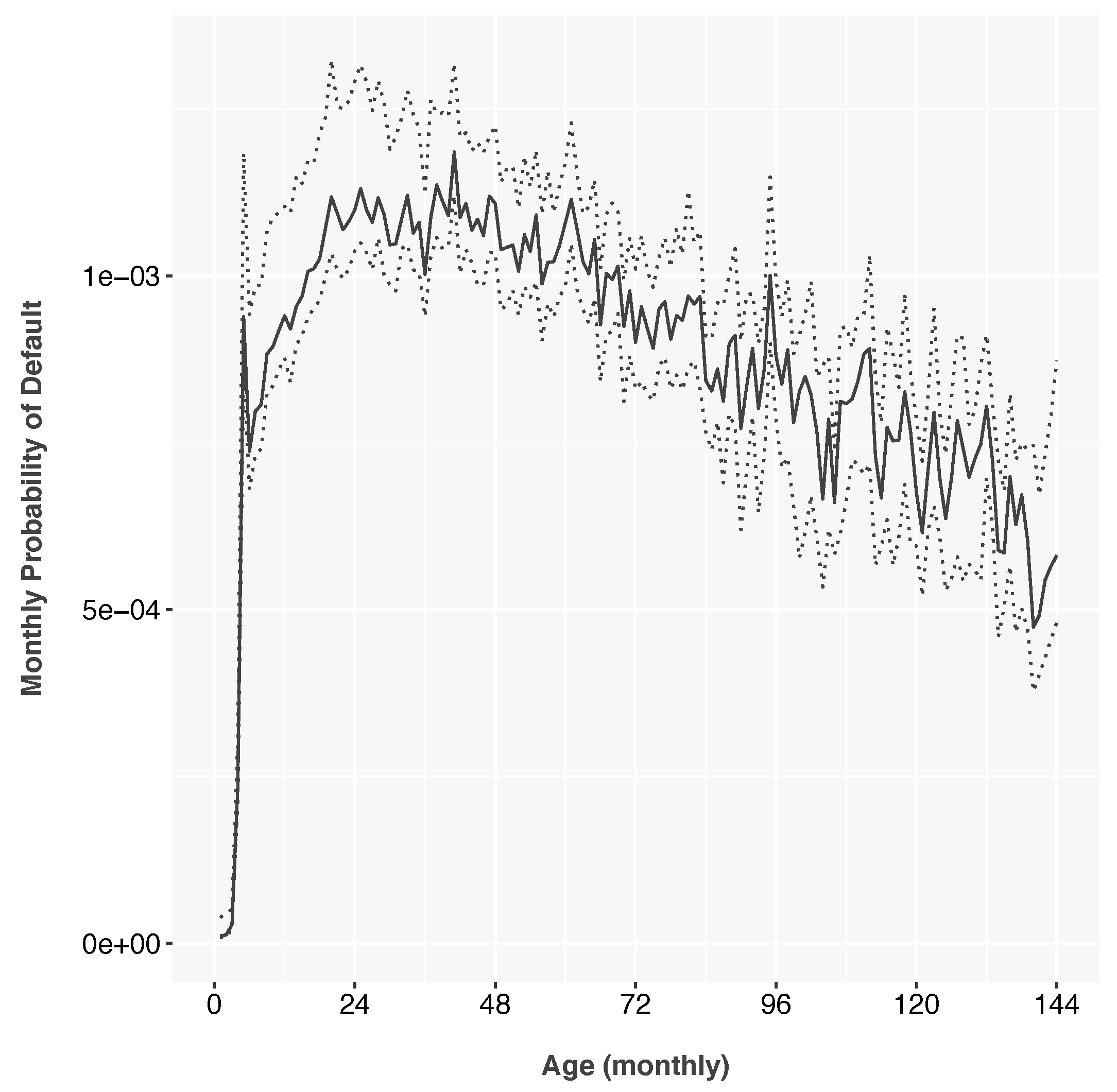
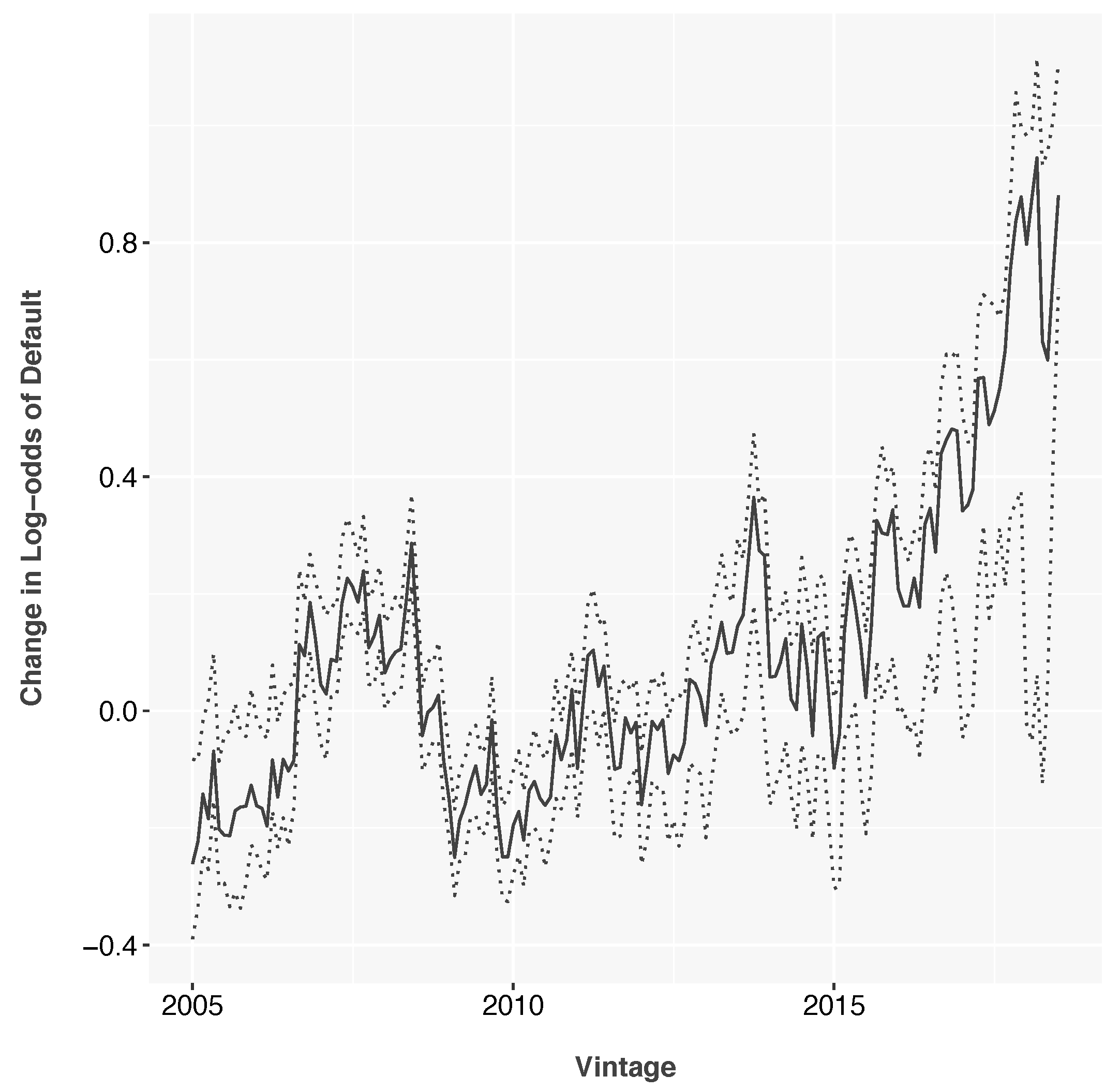
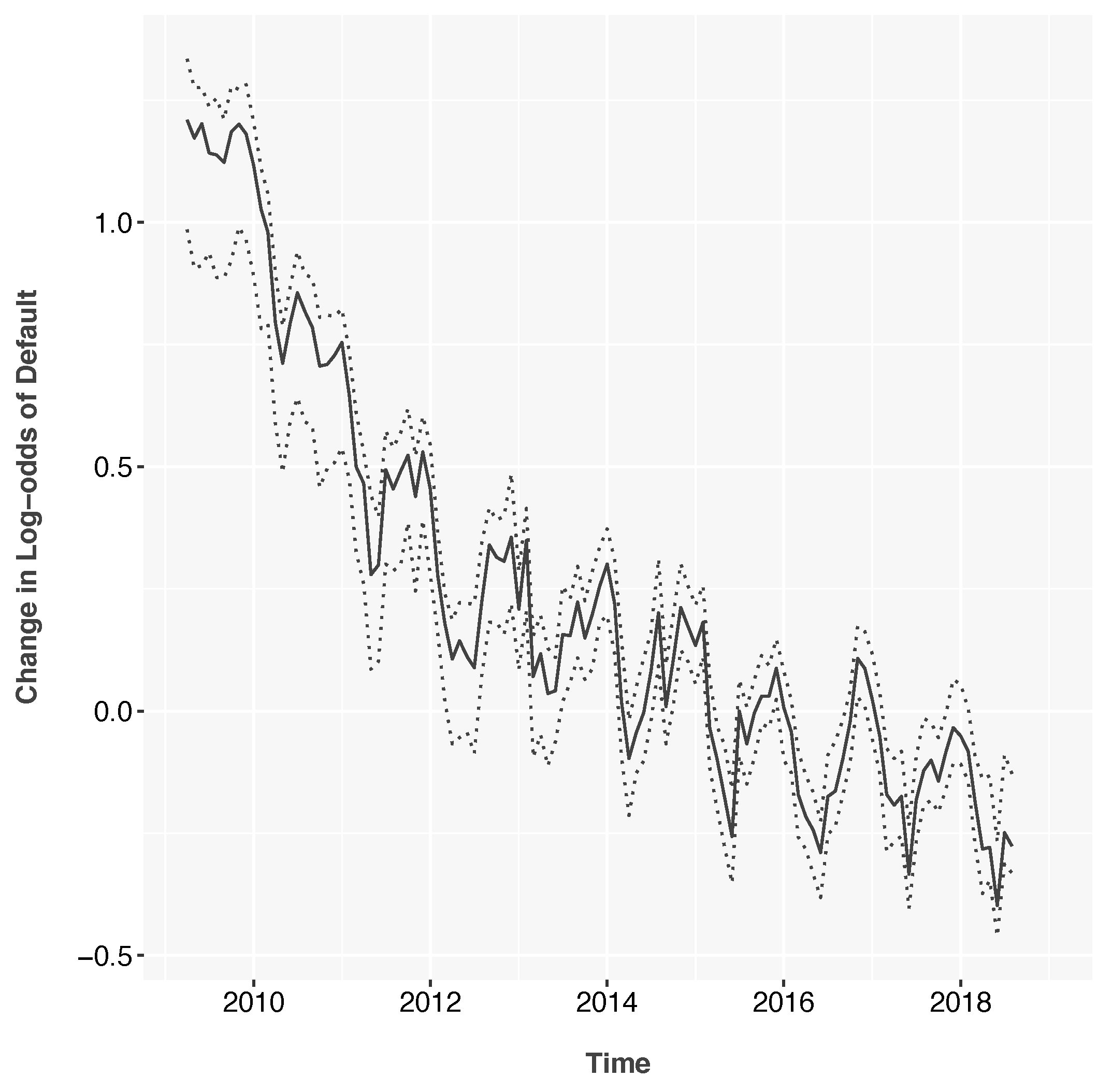
Figure 1 and
Figure 2 show the functions estimated on subprime credit card data.
The lifecycle function was estimated as log-odds of monthly default and then transformed to monthly probability of default for display purposes. It shows a peak risk around 36 months from origination and decreasing risk thereafter as the riskiest accounts have previously defaulted. The initial default spike represents fraud or other underwriting failures.
The vintage function shows the risk of each monthly vintage relative to the average lifecycle and is therefore centered about 0. This shows a risk peak in 2007–2008, as was common in the industry. The portfolio also shows rising risk in the most recent years, again, as has been seen in other portfolios. Both peaks could be a combination of macroeconomic adverse selection (
Breeden and Canals-Cerdá 2018) and increased risk appetite by the lender.
The environment function,
Figure 3 begins with the peak of the 2009 recession and shows steady macroeconomic improvement throughout history. Defaults also show a distinct seasonal pattern throughout history. Again, the environment function is measured relative to the lifecycle and is, therefore, mean zero.
The first scoring model estimated used the APC Scoring approach for logistic panel regression with standard credit risk inputs,
Table 2. In a business application, credit limit would not be included as an input factor, because the score would be intended to advise the assignment of credit limits. In this retrospective analysis, credit limit highlights that some information was used in underwriting that was not otherwise available at the time of this retrospective.
Table 3 and
Table 4 show the coefficients for the model built on restricted inputs. The coefficients of this model are marginally significant, but it is not subject to regulatory scrutiny, so we left everything in to maximize possible sensitivity.
The rest of the models were built using the same framework and variable sets as described previously.
Table 5 describes all of the models built and tested here.
6. Results
All the models were tested by creating 36-month forecasts from the origination date and using the actual lifecycle and environment as input. In a real-world test, the environment would be replaced with a macroeconomic model using macroeconomic scenarios as inputs. In the current context, macroeconomic models and scenarios are not germane to the topic of unintended bias.
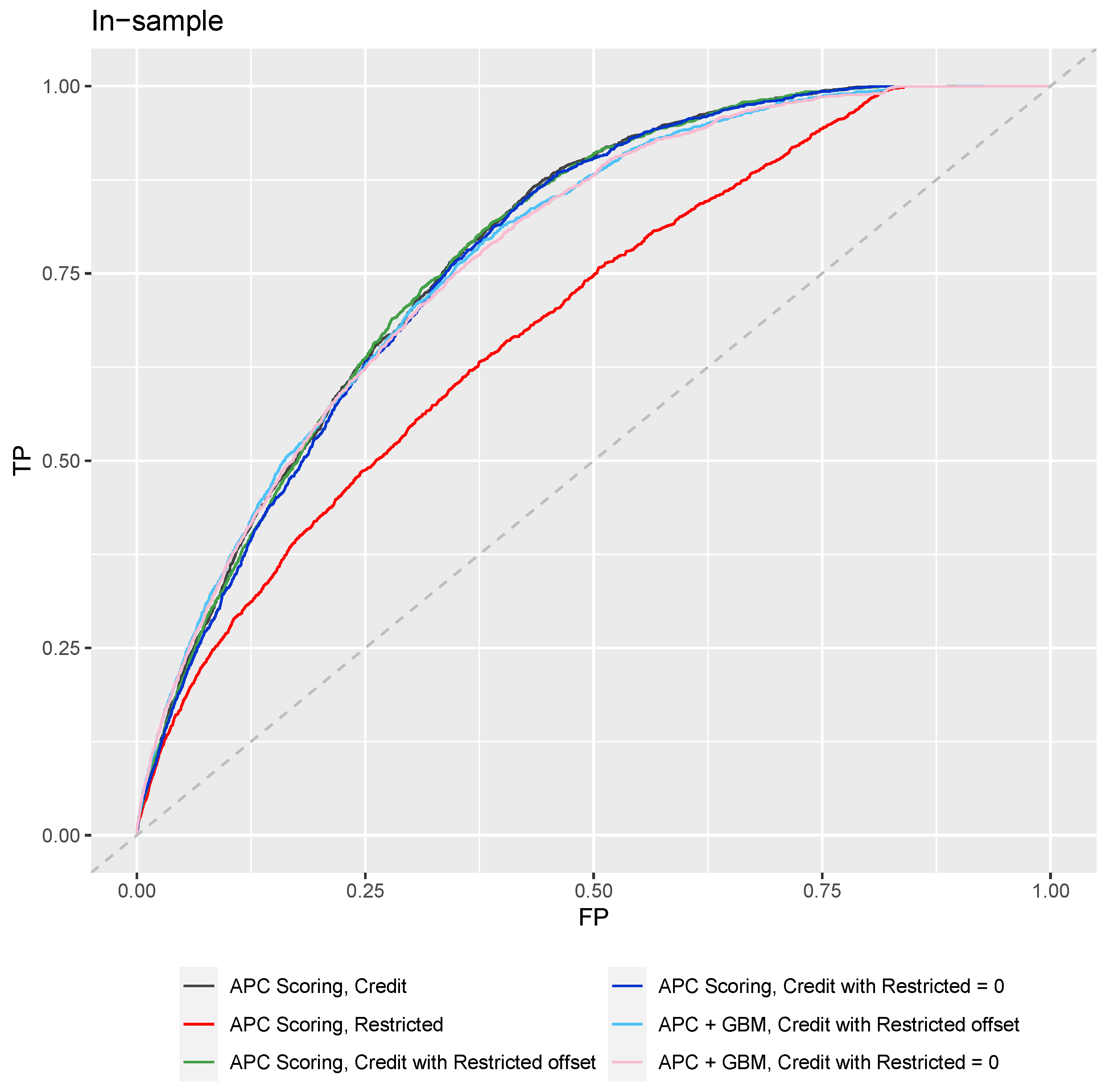
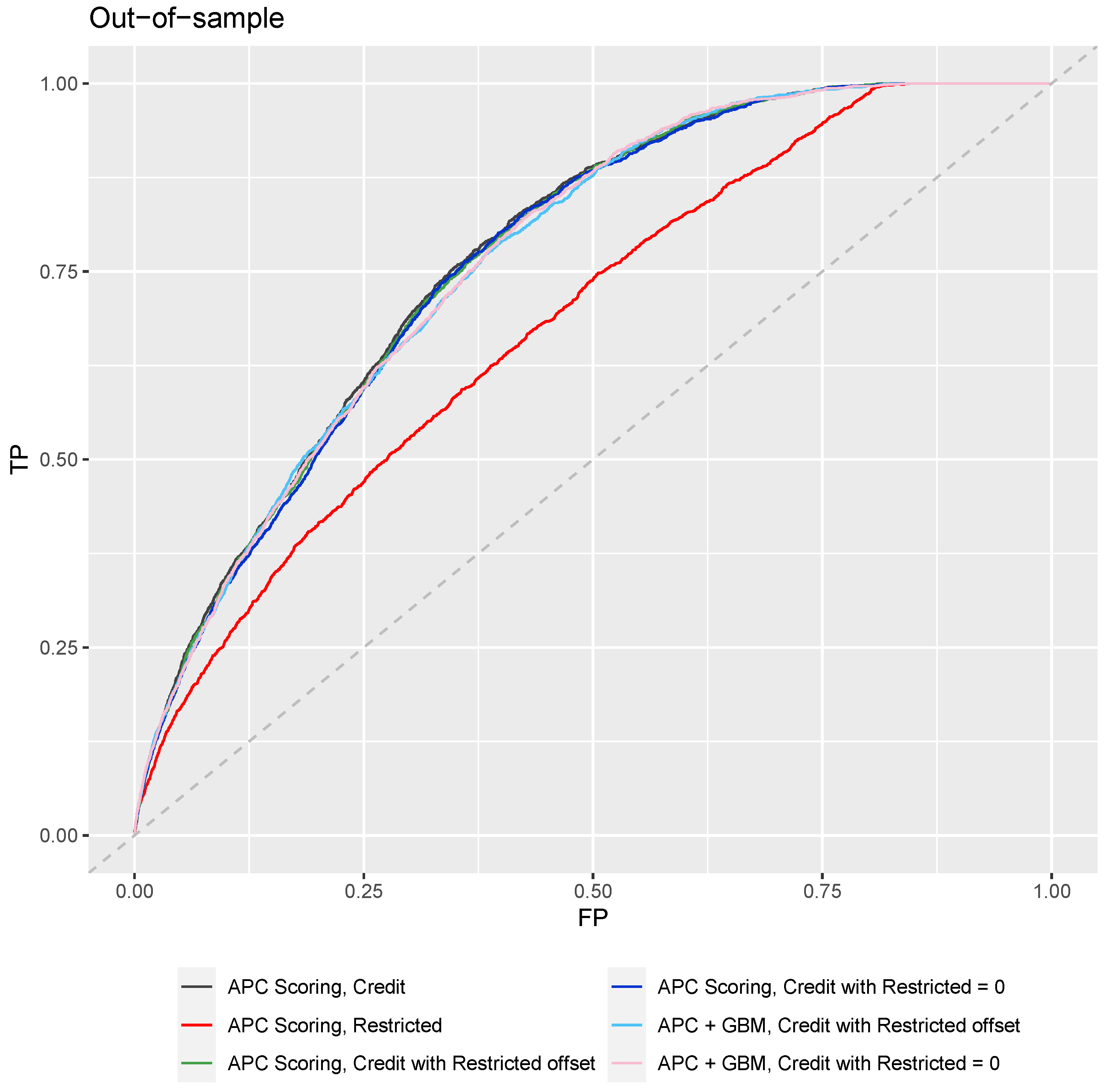
ROC curves are shown in
Figure 4 and
Figure 5, which are cumulative over the 36 month period for both forecasted and observed defaults. AUC and Gini coefficients were estimated from the ROC analysis, as shown in
Table 6 and
Table 7 for in-sample and out-of-sample results, respectively.
The model built from restricted inputs alone is immediately less predictive than those using financial inputs. This is almost certainly due to the weak association between census data and the performance of an individual borrower, and because previous borrower performance in repaying debt really is the best predictor of future performance. We knew, going into this analysis, that census data was not sufficient to completely test unintended bias in a portfolio, but as a proxy, it serves to demonstrate the process.
Note that the forecast results degrade only slightly when the Restricted model is set to zero for forecasting. With actual borrower demographics, this degradation would probably be significantly increased. Comparing the models with the Restricted inputs and with those set to zero provides a quantitative comparison of the cost to lenders and society of enforcing our ethical standards. Just like clean water and safe roads, society should pay these costs to create the world we would wish to live in. This analysis simply provides a way to quantify that investment.
The results show only slight degradation when moving to out-of-sample performance. This has been observed previously in the context of building a score with APC lifecycle and environment as fixed inputs and is theorized to be due to the normalization provided by those inputs.
We also note that APC Scoring and APC + SGB Trees have nearly identical results. This is easily explained by considering the available credit scoring inputs. By binning the input data, the logistic regression of APC scoring is able to match the nonlinearity of stochastic gradient-boosted trees. Furthermore, the inputs are so simple that no important interaction terms are present. With a more complex data set containing many more interaction terms, we would expect APC + SCB trees to exhibit an advantage.
Furthermore, due to the relative simplicity of the available data, we chose not to test additional training methods such as artificial neural networks, but previous work (
Breeden and Leonova 2019) has shown how neural networks can also be structured to utilize fixed inputs as needed to implement this approach to removing ethical bias.
7. Conclusions
This paper develops a modeling procedure that can create theoretically unbiased models so long as the training data are tagged with the protected class status against which one wants to prevent bias. The procedure is admittedly quite simple and yet highly effective. Most importantly, it avoids processes that have been shown to violate FCRA regulations, such as renormalizing the forecasts after model creation. We also find side benefits such as being able to quantify how much forecast accuracy is given up in the process of becoming provably unbiased. This was observed by comparing the forecast accuracy of the initial model with no fairness constraints to the model built with the restricted model as an input and then set to zero for testing. The difference in accuracy between two such models using any machine learning technique is a measure of the cost of creating an unbiased outcome. For the examples shown here, the difference between the initial model and the fully unbiased model was not statistically significant, but in other contexts and with other machine learning algorithms, it could be.
The application to a subprime credit card portfolio was effective because of the high default rate in the data and having a significant population of borrowers whom we wish to protect from discrimination. Combining borrower data with zipcode level census rates was not guaranteed to work, but the data actually showed plenty of useful structure.
The best test of this procedure will be to consider actual borrower demographic characteristics. If such data sets are not available in lending, perhaps applications outside lending would provide a safe and effective demonstration.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}