1. Introduction
It is well documented that (a) probability distributions of stock returns are heavy-tailed (both tails of the probability density function go down to zero much slower than in the case of the normal distribution, and as a result, the kurtosis of the distribution exceeds 3), (b) they are often asymmetric around the mean (the skewness of the distribution is either positive or negative), (c) they exhibit volatility clustering (positive autocorrelation among the day-to-day variance of returns) and (d) the leverage effect (the current volatility and the previous return are negatively correlated so that downturns in the stock market tend to predate sharper spikes in the volatility). In the practice of financial risk management, it is imperative to develop a statistical model that can capture these characteristics of stock returns because they are thought to be related to steep drops and rebounds in stock prices during the periods of financial turmoil. Without factoring them into risk management, financial institutions might unintentionally take on a higher risk and as a result would be faced with grave consequences, which we already observed during the Global Financial Crisis.
As a time-series model with the aforementioned characteristics, a family of time-series models called the stochastic volatility (SV) model has been developed in the field of financial econometrics. The standard SV model is a simple state-space model in which the measurement equation is a mere distribution of stock returns with the time-varying variance (volatility) and the system equation is an AR(1) process of the latent log volatility. In the standard setting, both measurement and system errors are supposed to be Gaussian and negatively correlated in order to incorporate the leverage effect into the model. The standard SV model can explain three stylized facts: heavy-tailed distribution, volatility clustering and the leverage effect, but it cannot make the distribution of stock returns asymmetric. Furthermore, although in theory the standard SV model incorporates the heavy-tail behavior of stock returns, many empirical studies demonstrated that it was insufficient to explain extreme fluctuations of stock prices that were caused by large shocks in financial markets.
Based on the plain-vanilla SV model, researchers have developed numerous variants that are designed to capture all aspects of stock returns sufficiently well. The SV model has been pioneered by
Taylor (
1982), and numerous studies related to the SV model have been conducted so far. The Markov chain Monte Carlo (MCMC) algorithms for SV models, which can be analyzed by numerical method, have been introduced by (
Jacquier et al. 1994,
2004).
Ghysels et al. (
1996) also survey and develop statistical inferences of the SV model including a Bayesian approach. A direct way to introduce a more heavy-tailed distribution to the SV model is to assume that the error term of the measurement equation follows a distribution with much heavier tails than the normal distribution. The Student’s
t distribution is a popular choice (
Berg et al. 2004;
Omori et al. 2007;
Nakajima and Omori 2009;
Nakajima 2012 among others). In the literature, the asymmetry in stock returns can be handled by assuming that the error term follows an asymmetric distribution (
Nakajima and Omori 2012;
Tsiotas 2012;
Abanto-Valle et al. 2015 among others). In particular, the generalized hyperbolic (GH) distribution proposed by
Barndorff-Nielsen (
1977) has recently drawn increasing attention among researchers (e.g.,
Nakajima and Omori 2012), since it is regarded as a broad family of heavy-tailed distributions such as variance-gamma and Student’s
t, as well as their skewed variants such as skew variance-gamma and skew Student’s
t.
As an alternative to the SV model, the realized volatility (RV) model (e.g.,
Andersen and Bollerslev 1997,
1998) is often applied to evaluation of daily volatility. A naive RV estimator is defined as the sum of squared intraday returns. It converges to the daily integrated volatility as the time interval of returns becomes shorter. Due to this characteristic, RV is suitable for foreign exchange markets, which are open for 24 h a day continuously, though this may not be the case for stock markets. Most stock markets close at night, and some of them, including the Tokyo Stock Exchange, have lunch breaks when no transactions take place. It is well known that the naive RV estimator is biased for such stock markets. Nonetheless, since RV is a convenient tool for volatility estimation, researchers have developed various improved estimators of RV as well as robust estimators of its standard error. For example,
Mykland and Zhang (
2017) proposed a general nonparametric method called the observed asymptotic variance for assessing the standard error of RV.
Traditionally, empirical studies with the SV model as well as the RV model focused on daily volatility of asset returns. However, the availability of high-frequency tick data and the advent of high-frequency trading (HFT), which is a general term for algorithmic trading in full use of high-performance computing and high speed communication technology, has shifted the focus of research on volatility from closing-to-closing daily volatility to intraday volatility in a very short interval (e.g., 5 min or shorter). This shift paved the way for a new type of SV model. In addition to the traditional stylized facts on daily volatility, intraday volatility is known to exhibit a cyclical pattern during trading hours. On a typical trading day, the volatility tends to be high immediately after the market opens, but it gradually declines in the middle of trading hours. In the late trading hours, the volatility again becomes higher as it nears the closing time. This U-shaped trend in volatility is called intraday seasonality in the literature (see
Chan et al. 1991 among others). Although it is crucial to take the intraday seasonality into consideration in estimation of any intraday volatility models, only a few studies (e.g.,
Stroud and Johannes 2014;
Fičura and Witzany 2015a,
2015b) explicitly incorporate it into their volatility models.
In this paper, we propose to directly embed intraday seasonality into the SV model by approximating the U-shaped seasonality pattern with a linear combination of Bernstein polynomials. In order to capture skewness and excess kurtosis in high-frequency stock returns, we employ two distributions (variance-gamma and Student’s
t) and their skewed variants (skew variance-gamma and skew Student’s
t) in the family of GH distributions as the distribution of stock returns in the SV model. The complicated SV models generally tend to be inefficient for analyzing in a primitive form. In order to solve the problem, numerous studies concerned with efficiency of the SV model have been developed. Omori and Watanabe (2008) introduce a sampling method with block unit for asymmetric SV models, which can sample disturbances from their conditional posterior distribution simultaneously. As another approach to optimize computation, a Sequential Monte Carlo (SMC) algorithm for Bayesian semi-parametric SV model was designed by
Virbickaite et al. (
2019). The ancillarity-sufficiency interweaving strategy (ASIS) proposed by
Yu and Meng (
2011) is highly effective to improve MCMC sampling effeciency. We discuss ASIS in detail in
Section 3. Needless to say, since the proposed SV model is intractably complicated, we develop an efficient Markov chain Monte Carlo (MCMC) sampling algorithm for full Bayesian estimation of all parameters and state variables (latent log volatilities in our case) in the model.
The rest of this paper is organized as follows. In
Section 2, we introduce a reparameterized Gaussian SV model with leverage and intraday seasonality and derive an efficient MCMC sampling algorithm for its Bayesian estimation. In addition, we show the conditional posterior distributions and prepare for application of ASIS. In
Section 3, we extend the Gaussian SV model to the case of variance gamma and Student’s
t error as well as their skewed variants. In
Section 4, we report the estimation results of our proposed SV models with 1 min return data of TOPIX. Finally, conclusions are given in
Section 5.
2. Stochastic Volatility Model with Intraday Seasonality
Consider the log difference of a stock price in a short interval (say, 1 or 5 min). We divide trading hours evenly into
T periods and normalize them so that the length of the trading hours is equal to 1; that is, the length of each period is
and the time stamp of the
t-th period is
. Note that the market opens at time 0 and closes at time 1 in our setup. Let
denote the stock return in the
t-th period (at time
in the trading hours) and consider the following stochastic volatility (SV) model of
with intraday seasonality:
and
It is well known that the estimate of the correlation coefficient
is negative in most stock markets. This negative correlation is often referred to as the leverage effect. Note that the stock volatility in the
t-th period (the natural logarithm of the conditional standard deviation of
) is
where
is the filtration that represents all available information at time
. Hence, the stock volatility in the SV model (
1) is decomposed into two parts: a linear combination of covariates
and the unobserved AR(1) process
. In this paper, we regard
as the intraday seasonal component of the stock volatility, though it can be interpreted as any function of covariates
in a different situation. On the other hand,
is supposed to capture volatility clustering. We call
the latent log volatility since it is unobservable.
Although the intraday seasonal component
is likely to be a U-shaped function of time stamps (the stock volatility is higher right after the opening or near the closing, but it is lower in the middle of the trading hours), we have no information about the exact functional form of the intraday seasonality. To make it in a flexible functional form for the intraday seasonality, we assume that
is a Bernstein polynomial
where
is called a Bernstein basis polynomial of degree
n:
According to the Weierstrass approximation theorem, the Bernstein polynomial (
2) can approximate any continuous function on
as
n goes to infinity. In practice, however, the number of observations
T is finite. Thus, we need to choose a finite
n via a model selection procedure. We will discuss this issue in
Section 4.
Although the parameterization of the SV model in (
1) is widely applied in the literature, we propose an alternative parameterization that facilitates MCMC implementation in non-Gaussian SV models. By replacing the covariance matrix in (
1) with
we obtain an alternative formulation of the SV model:
Since in (
4) the variance of
is no longer equal to one, the interpretation of
and
in (
4) is slightly different from the original one in (
1). Nonetheless, the SV model (
4) has essentially the same characteristics as (
1). Since the correlation coefficient in (
3) is
the sign of
always coincides with the correlation coefficient and the leverage effect exists if
. To distinguish
in (
4) from the correlation parameter
in (
1), we call
the leverage parameter in this paper.
Note that the inverse of (
3) is
and the determinant of (
3) is
. Using
we can easily show that the SV model (
4) is equivalent to
where
In the alternative formulation of the SV model (
5), we can interpret
as a common shock that affects both the stock return
and the log volatility
and
as an idiosyncratic shock that affects
only.
The likelihood for the SV model (
5) given the observations
, and the latent log volatility
is
where
and
. Since
follows a stationary AR(1) process, the joint probability distribution of
is
, where
is a tridiagonal matrix, and it is positive definite as long as
. Thus, the joint p.d.f. of
is
The prior distributions for
in our study are
Then the joint posterior density of
for the SV model (
5) is
where
is the prior density of the parameters in (
10).
Since analytical evaluation of the joint posterior distribution (
11) is impractical, we apply an MCMC method to generate a random sample
from the joint posterior distribution (
11) and numerically evaluate the posterior statistics necessary for Bayesian inference with Monte Carlo integration. The outline of the standard MCMC sampling scheme for the posterior distribution (
11) is given as follows:
![Jrfm 14 00145 i001]()
Although the above MCMC sampling scheme is ubiquitous in the literature of the SV model, the generated Monte Carlo sample
tends to exhibit strongly positive autocorrelation. To improve efficiency of MCMC implementation,
Yu and Meng (
2011) proposed an ancillarity-sufficiency interweaving strategy (ASIS). In the literature of the SV model,
Kastner and Frühwirth-Schnatter (
2014) applied ASIS to the SV model of daily US-dollar/Euro exchange rate data with the Gaussian error. Their SV model did not include either intraday seasonality or the leverage effect since they applied it to daily exchange rate data that exhibited no leverage effect in most cases. We extend the algorithm developed by
Kastner and Frühwirth-Schnatter (
2014) to facilitate the converge of the sample path in the SV model (
5). The basic principle of ASIS is to construct MCMC sampling schemes for two different but equivalent parameterizations of a model with missing/latent variables (
in our case) and generate the parameters alternately with each of them.
According to
Kastner and Frühwirth-Schnatter (
2014), the SV model (
5) is in a non-centered parameterization (NCP). On the other hand, we may transform
as
and rearrange the SV model (
5) as
The above SV model (
13) is in a centered parameterization (CP).
The posterior distribution in the CP form (
13) is equivalent to the one in the NCP form (
5) in the sense that they give us the same posterior distribution of
. Let us verify this claim. The likelihood for the SV model (
13) given the observations
and the latent log volatility
is
where
Note that the joint p.d.f. of
is
where
. With the prior of
in (
10), the joint posterior density of
for the SV model (
13) is obtained as
Note that
is unchanged between the NCP form (
11) and the CP form (
17). Although the latent variables are transformed with (
12), the “marginal” posterior p.d.f. of
is unchanged, because
where the Jacobian
.
With this fact in mind, we can incorporate ASIS into the MCMC sampling scheme by replacing Step 1 with
![Jrfm 14 00145 i002]()
Note that we generate a new latent log volatility
from its conditional posterior distribution in the NCP form (
11) only once at the beginning of
Step 1. This is the reason we call it the NCP-based ASIS step. After this update, we merely shift the location of
by
(
Step 1) or by
(
Step 1.5). In ASIS, these shifts are applied with probability 1 even if all elements in
are not updated at the beginning of
Step 1, which is highly probable in practice because we need to use the MH algorithm to generate
. Although we also utilize the MH algorithm to generate
, as explained later, the acceptance rate of
in the MH step is much higher than that of
in our experience. Thus, we expect that both
and
will be updated more often than
itself. As a result, the above ASIS step may improve mixing of the sample sequence of
. Conversely, we may apply the following CP-based ASIS step:
![Jrfm 14 00145 i003]()
In the CP-based ASIS step, we generate
from its conditional posterior distribution in the CP form (
17) once. The rest is the same as in the NCP-based ASIS step except that the order of sampling is reversed.
In the NCP form, the conditional posterior distributions for
are
where
In the CP form, the conditional posterior distributions for
are
where
Derivations of the conditional posterior distributrions are shown in
Appendix A.
4. Empirical Study
As an application of our proposed models to real data, we analyze high-frequency data of the Tokyo Stock Price Index (TOPIX), a market-cap-weighted stock index based on all domestic common stocks listed in the Tokyo Stock Exchange (TSE) First Section, which is provided by Nikkei Media Marketing. We use the data in June 2016, when the referendum for the UK’s withdrawal from the EU (Brexit) was held on the 23rd of the month. The result of the Brexit referendum was announced during the trading hours of the TSE on that day. That news made the Japanese Stock Market plunge significantly. The Brexit referendum is arguably one of the biggest financial events in recent years. We can thus analyze the effect of the Brexit referendum on the volatility of the Japanese stock market. Another reason for this choice is that Japan has no holiday in June, so all weekdays are trading days. There are five weeks in June 2016. Since the first week of June 2016 includes 30 and 31 May and the last week includes 1 July, we also include them in the sample period.
The morning session of TSE starts at 9:00 a.m. and ends at 11:30 a.m. while the afternoon session of TSE starts at 12:30 a.m. and ends at 3:00 p.m., so both sessions last for 150 min. We treat the morning session and the afternoon session as if they are separated trading hours, and normalize the time stamps so that they take values within
. As a result,
corresponds to 9:00 a.m. for the morning session, while it corresponds to 12:30 a.m. for the afternoon session. In the same manner,
corresponds to 11:30 a.m. for the morning session, while it corresponds to 3:00 p.m. for the afternoon session. In this empirical study, we estimate the Bernstein polynomial of the intraday seasonality in each session by allowing
in (
2) to differ from session to session.
We pick prices at every 1 min and compute 1 min log difference of prices as 1 min stock returns. Thus, the number of observations per session is 150. Furthermore, we put together all series of 1 min returns in each week. As a result, the total number of observations per week is
. In addition, to simplify the interpretation of the estimation results, we standardize each week-long series of 1 min returns so that the sample mean is 0 and the sample variance is 1.
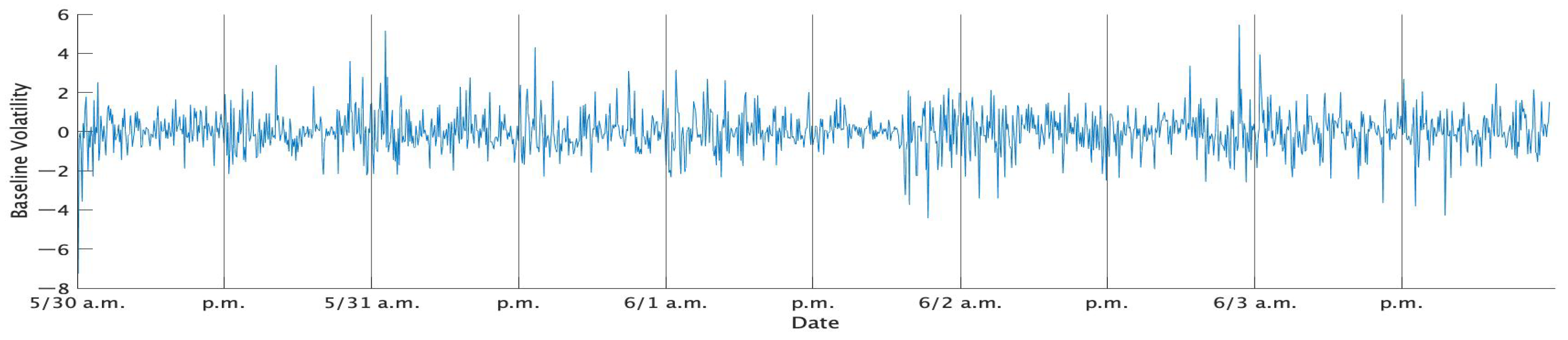
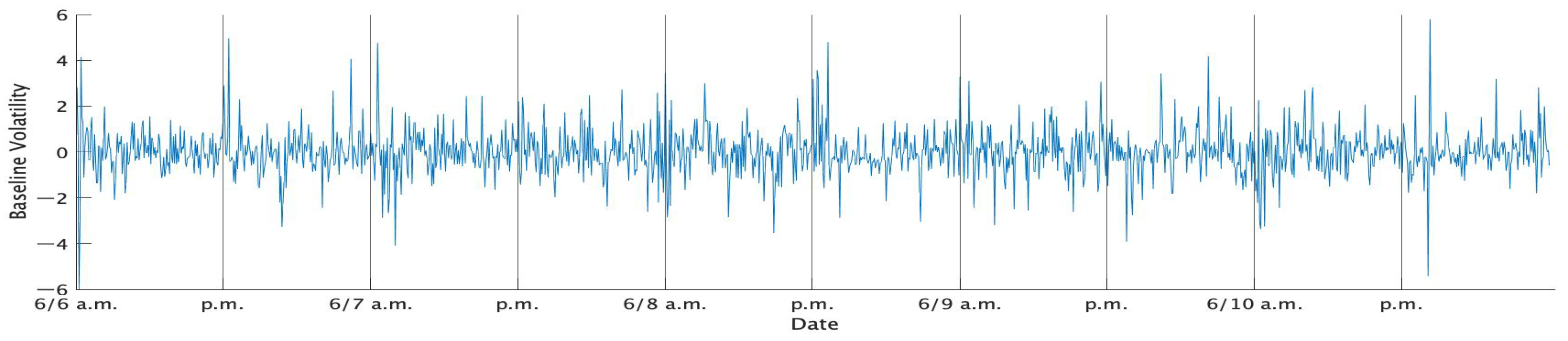
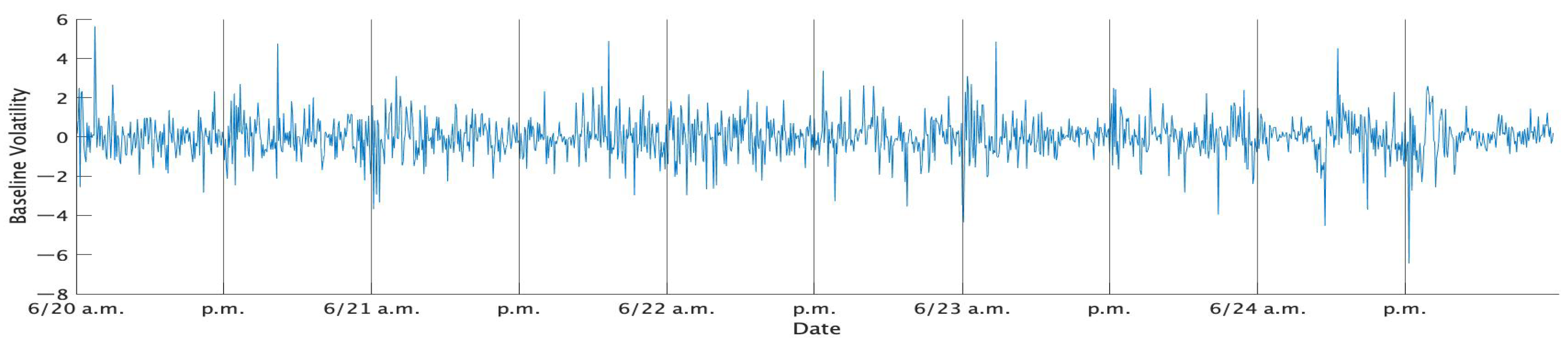
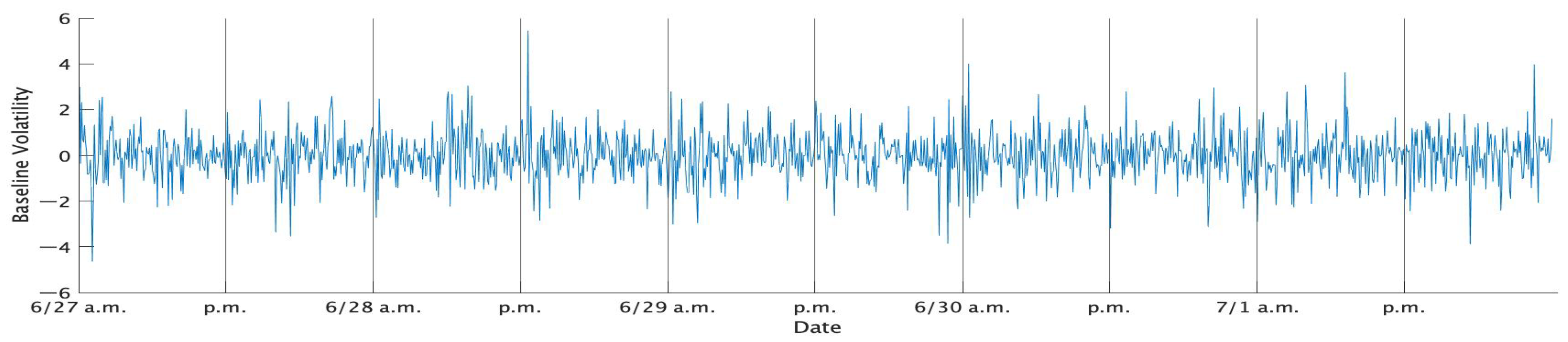
Table 1 shows the descriptive statistics of the standard 1 min returns of TOPIX in each week, while
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show the time series plots of the standardized 1 min returns for each week.
We consider five candidates (SV-N, SV-G, SV-SG, SV-T, SV-ST) in the SV model (
28) and set the prior distributions as follows:
We vary the order of the Bernstein polynomial from 5 to 10. In sum, we try 30 different model specifications for the SV model (
28). In the MCMC implementation, we generate 10,000 draws after the first 5000 draws are discarded as the burn-in periods. To select the best model among the candidates, we employ the widely applicable information criterion (WAIC,
Watanabe 2010). We compute the WAIC of each model specification with the formula by
Gelman et al. (
2014). The results are reported in
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6. According to these tables, SV-G or SV-SG is the best model in all months. It may be a notable finding since the SV model with the variance-gamma error has hardly been applied in the previous studies.
For the selected models, we compute the posterior statistics (posterior means, standard deviations, 95% credible intervals and inefficiency factors) of the parameters and report them in
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. The inefficiency factor measures how inefficient the MCMC sampling algorithm is (see e.g.,
Chib 2001). In these tables, the 95% credible intervals of the leverage parameter
and the asymmetric parameter
contain 0 for all specifications. Thus, we may conclude that the error distribution of 1 min returns of TOPIX is not asymmetric. In addition, most of the marginal posterior distributions of
are concentrated near 1, even though the uniform prior is assumed for
. This suggests that the latent log volatility is strongly persistent, which is consistent with findings by previous studies on the stock markets. Regarding the tail parameter
, its marginal posterior distribution is centered around 2–6 in most models, which indicates that the excess kurtosis of the error distribution is high.
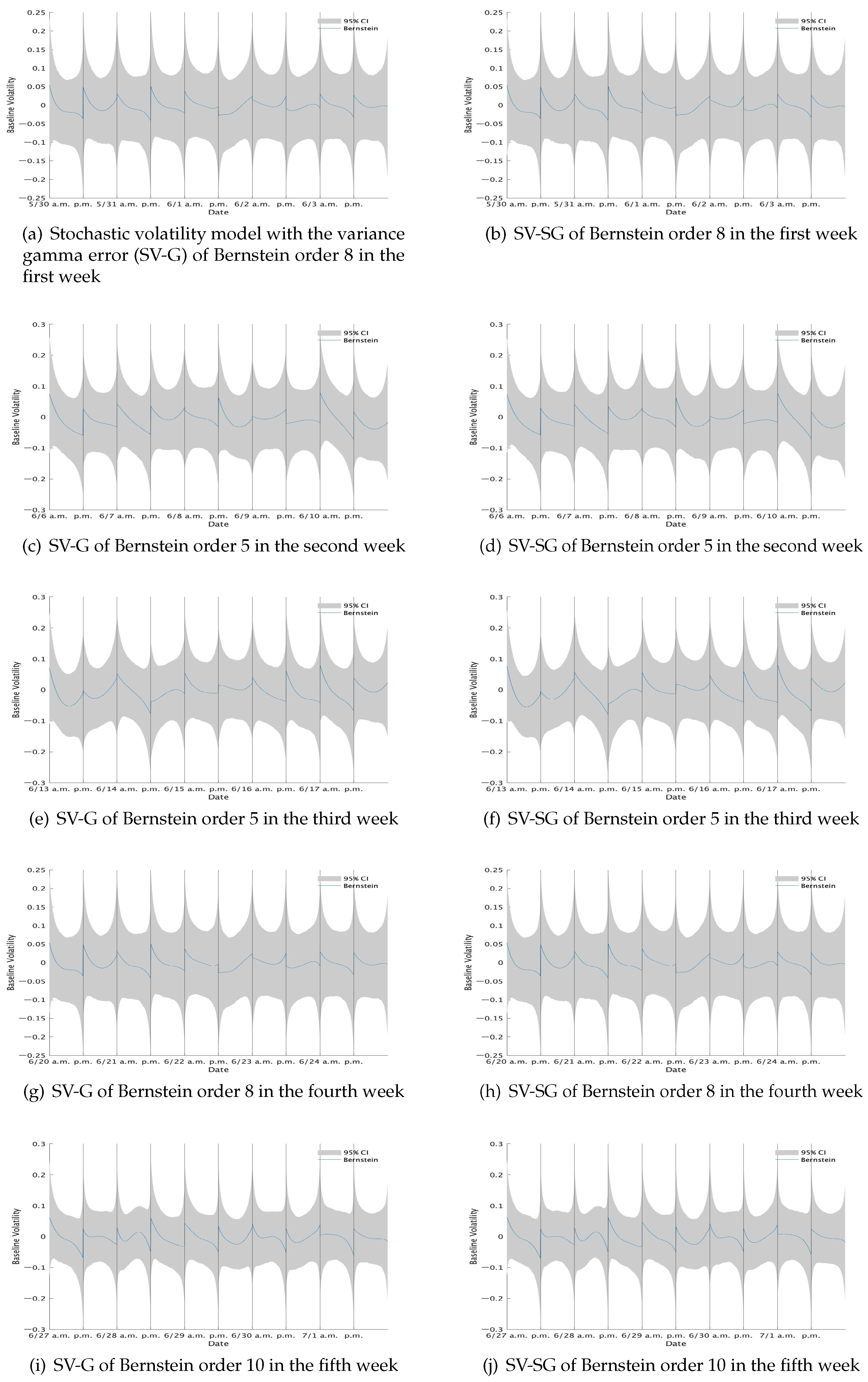
As for the intraday seasonality, the estimates of
themselves are not of our interest. Instead we show the posterior mean and the 95% credible interval of the Bernstein polynomial
in
Figure 6. These figures show that some of the trading days exhibit the well-known U-shaped curve of intraday volatility, but others slant upward or downward. At the beginning on the day of Brexit (23 June), the market began with a highly volatile situation, but the volatility gradually became lower. During the afternoon session, the volatility was kept in a stable condition.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}