2.1. The SV Model
A canonical SV model studied in the literature is a one-component (or factor) SV model, where the conditional volatility of the asset returns is assumed to have been generated by a latent/unobserved AR(1) process. The multiscale SV (MSSV) model proposed by
Molina et al. (
2010) is a direct extension of this one-component SV model. For this reason we first review the one-component SV model briefly.
As mentioned earlier the SV model was proposed by
Taylor (
1986) to incorporate time-varying volatility of the returns. Define by
the asset return at time
t. Then the dynamics of
is given by:
where
is statistically independent random noise terms, such that
. It is also assumed that
is statistically independent with a common univariate Gaussian distribution
, and the innovation terms,
and
, are statistically independent of each other. In addition we also impose the condition that
in order to ensure that the latent/unobserved AR(1) process is second-order stationary,
As the SV model is hierarchical and the mean equation defined in (
1) is highly non-linear, its likelihood function does not possess a closed-form representation, and it is highly intractable to integrate out the
T latent/unobserved volatility processes from this likelihood function. Faced with this difficulty MCMC methods have been proposed to estimate the parameters of the SV models.
2.2. The MSSV and MSASV Models
The MSSV model, proposed by
Molina et al. (
2010), is a direct extension of the one-component SV model. In this model, the
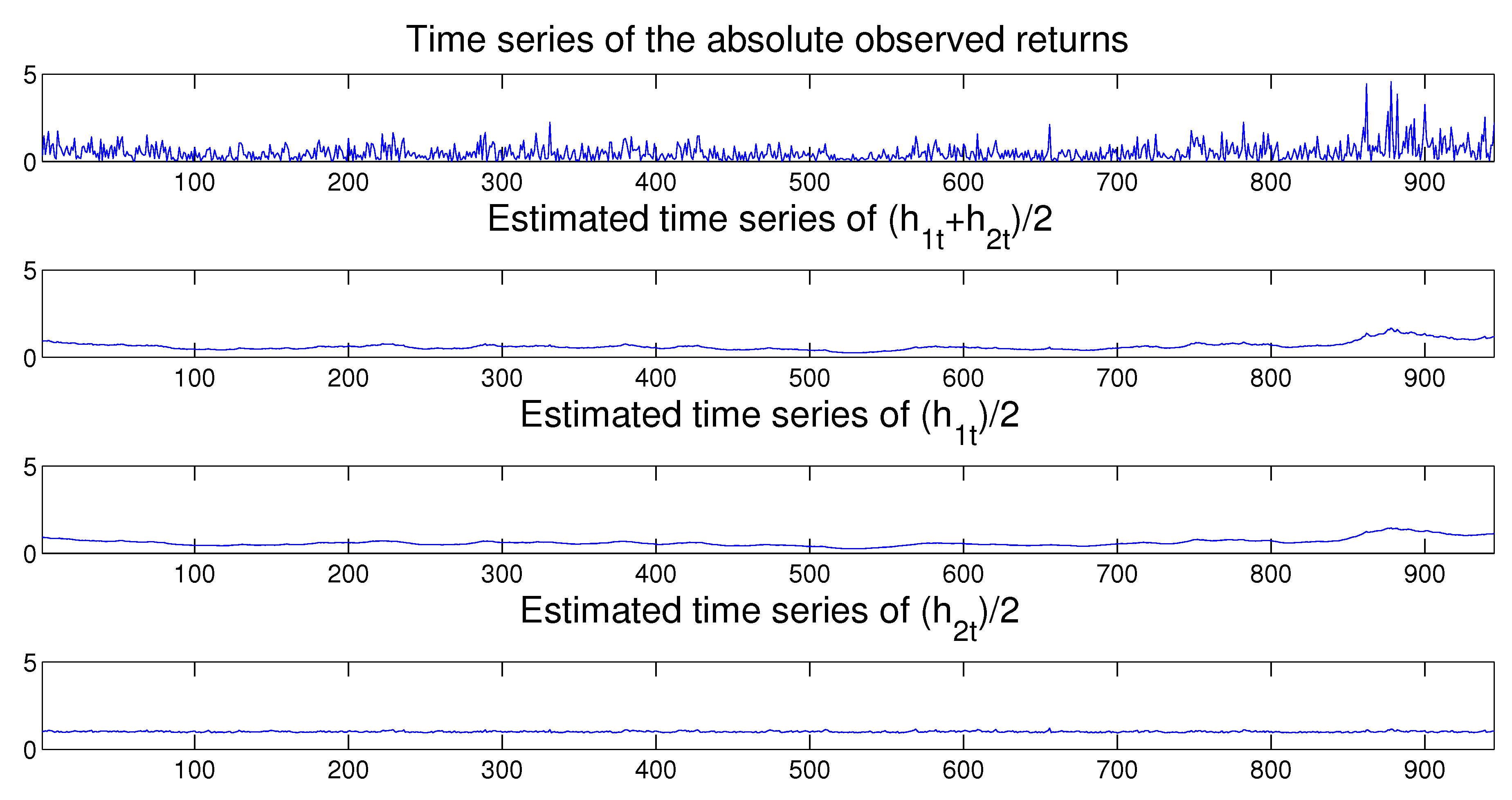
process is determined by multiple additive latent/unobserved volatilities as factors. The model is defined as:
where the innovation terms,
and
,
are assumed to be statistically independent of each other,
is a vector of multivariate Gaussian variates such that
, where
is a
k-dimensional vector of zeros,
is a
identity matrix, and
’s are statistically independent of each other with a common univariate Gaussian distribution, denoted as
. In (4)–(6)
is a vector of
K latent/unobserved volatility states at time
t, and
denotes a
K-dimensional vector of ones. The innovation terms of the latent/unobserved volatility process
are also statistically independent of each other; that is,
is a
diagonal matrix with the
k-th diagonal element being given by
, with
, and
is a
diagonal matrix containing the mean reversion parameters, such that
, for
. The covariance matrix of the initial latent/unobserved volatility vector
is given by the implied second-order stationary, marginal covariance matrix
of the latent volatility process, which, in turn, satisfies the condition that
. Note that in (
4)–(), if we set
for some
i, the implied model will reduce to a model which contains a permanent (log-normal) source of independent jumps in the volatility series, as the
would be (temporally statistically independent) Gaussian processes which is added to the (log)variance process driving the return series.
As pointed out by
Molina et al. (
2010), the model in (
4)–() can be motivated as a discrete-time approximation to the underlying continuous-time SV models, where the volatility is an exponential function of a sum of multiple Ornstein–Uhlenbeck processes with the mean reverting processes varying on well-separated time scales. Its model representation and the ensuing discussion of the model are relegated to
Appendix A. Alternatively the model stated in (4)–(6) can also be viewed as arising from the fact that the SV models allow for superposition of latent volatilities where total volatilities is the sum of individual component volatilities. See, inter alia,
Roberts et al. (
2004) and
Griffin and Steel (
2010) for this particular set up. For this reason the model in (4)–(6) are sometimes also referred to as a multi-component (or multi-factor) SV model.
Following
Molina et al. (
2010) we impose the condition that
in order to ensure that the MSSV model is identifiable. Under this restriction, all of the components of the latent/unobserved process in () are ensured to evolve on different time scales. Note also that we exclude a location parameter from this process as the innovation terms,
, in the model possess a non-unit variance.
The original MSSV model studied in
Molina et al. (
2010) does not allow for correlation between the innovation terms,
and
. In the equity markets asset returns have been shown to have a negative correlation with their logarithms of conditional volatilities. In this paper we incorporate a nontrivial correlation structure between the innovation terms of the mean equation and the innovation terms of the latent volatility component processes. In principle we can also allow for a correlation structure among the innovation terms of the latent/unobserved AR(1) processes. However, in order to maintain a reasonable simplification of the development of the MCMC algorithm, and also to ensure identifiability of the model, we do not entertain this possibility in this paper. Another important observation pertaining to the asset returns is the heavy/fat tail property of the marginal distribution of the returns, which is often captured by assuming that the innovation terms of the mean equation follow a Student
t distribution. Accordingly we assume that
with
v degrees of freedom. The MSASV model with the Student
t distributional assumption for the innovation terms of the mean equation is called an MSASV-t model.
2To simplify the derivation for the proposed MCMC algorithm we reparametrize the latent/unobserved AR(1) process of the MSASV model as
where
are independent univariate standard normal noises,
and
. This reparametrized form highlights the nontrivial correlation structure we have introduced in the model between the innovation terms of the mean equation and the innovation terms of the latent factor processes, as conventionally defined in the one-component SV literature and interpreted it as a leverage/asymmetric effect. However, as mentioned earlier, in this paper we do not allow for a non-trivial correlation structure among the latent innovation terms for reason of computational tractability and to ensure model identifiability. Given (
7), instead of sampling
and
we sample
and
, and then proceed backwards to obtain samples of
and
.
2.3. MCMC
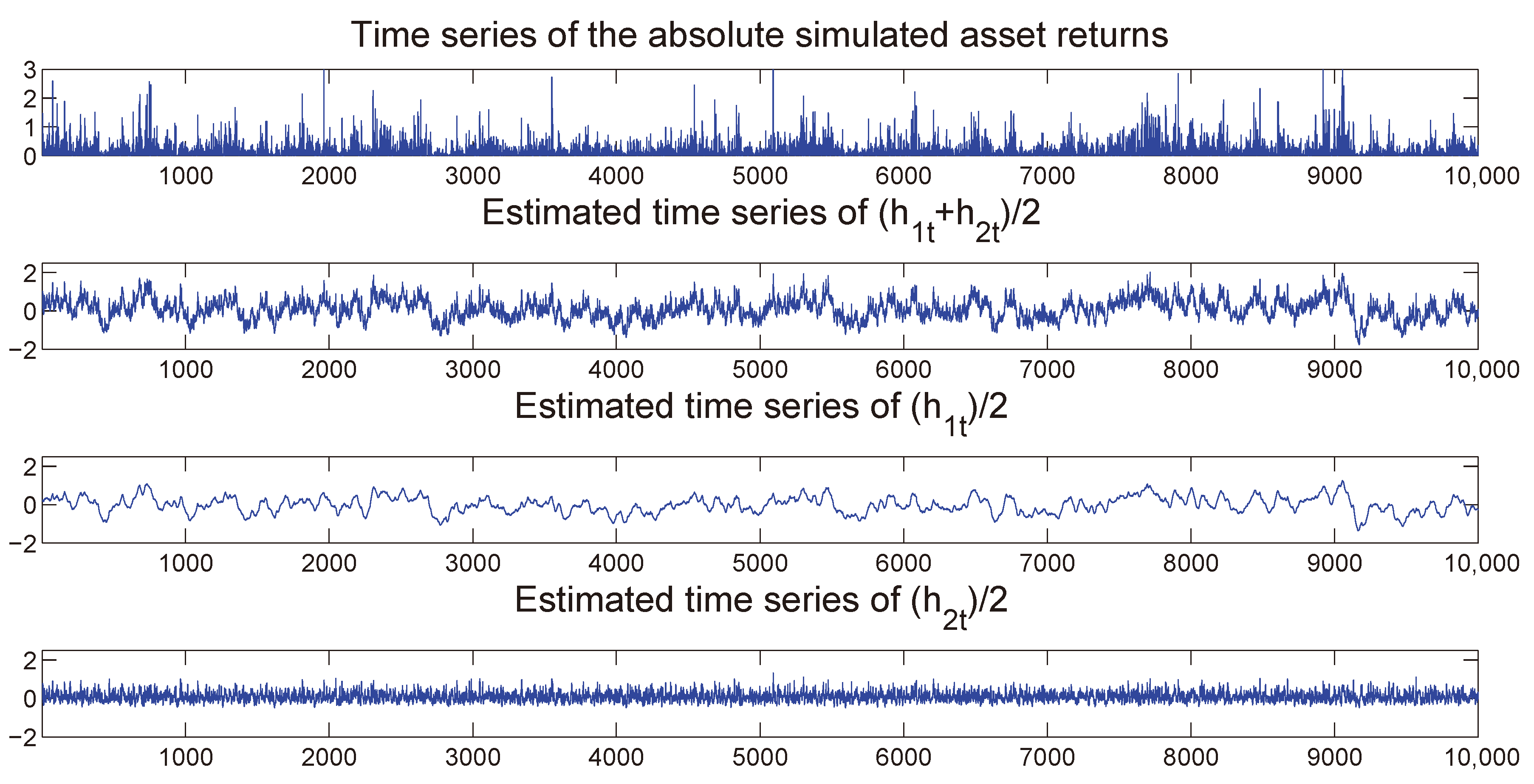
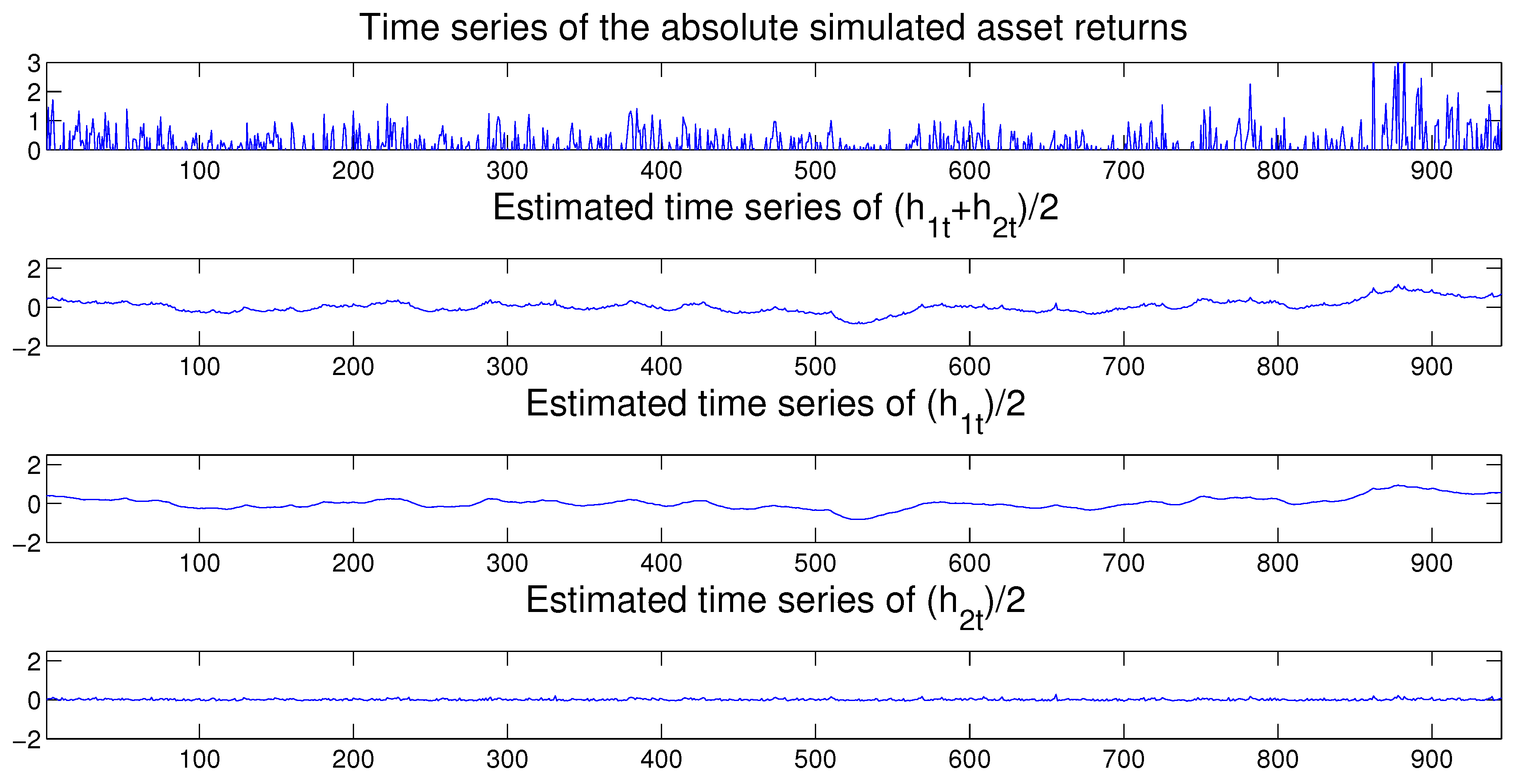
In the remaining parts of the paper we focus our analyses on the MSASV and the MSASV-t models with two components, that is, we pre-set
, for reasons of computational tractability.
3 Define
as the vector of parameters for the MSASV model,
as the vector of parameters of the MSASV-t model, and
as the set of the corresponding latent/unobserved volatility states.
We complete the specification of the MSASV and the MSASV-t models by incorporating explicit prior distributions for the models’ parameters. For simplicity we assume that all prior distributions of the parameters of both multiscale SV models are statistically independent of each other. To impose a second-order stationary condition on the latent/unobserved volatility processes we specify the prior distributions for
and
to be
, which is truncated in the interval
. These prior distributions give rise to relatively flat densities over their support regions. In the MCMC algorithm we sample
instead of
, by using an inverse Gamma distribution
. As to the prior distributions of
v we adopt a half-Cauchy prior with the density function given by
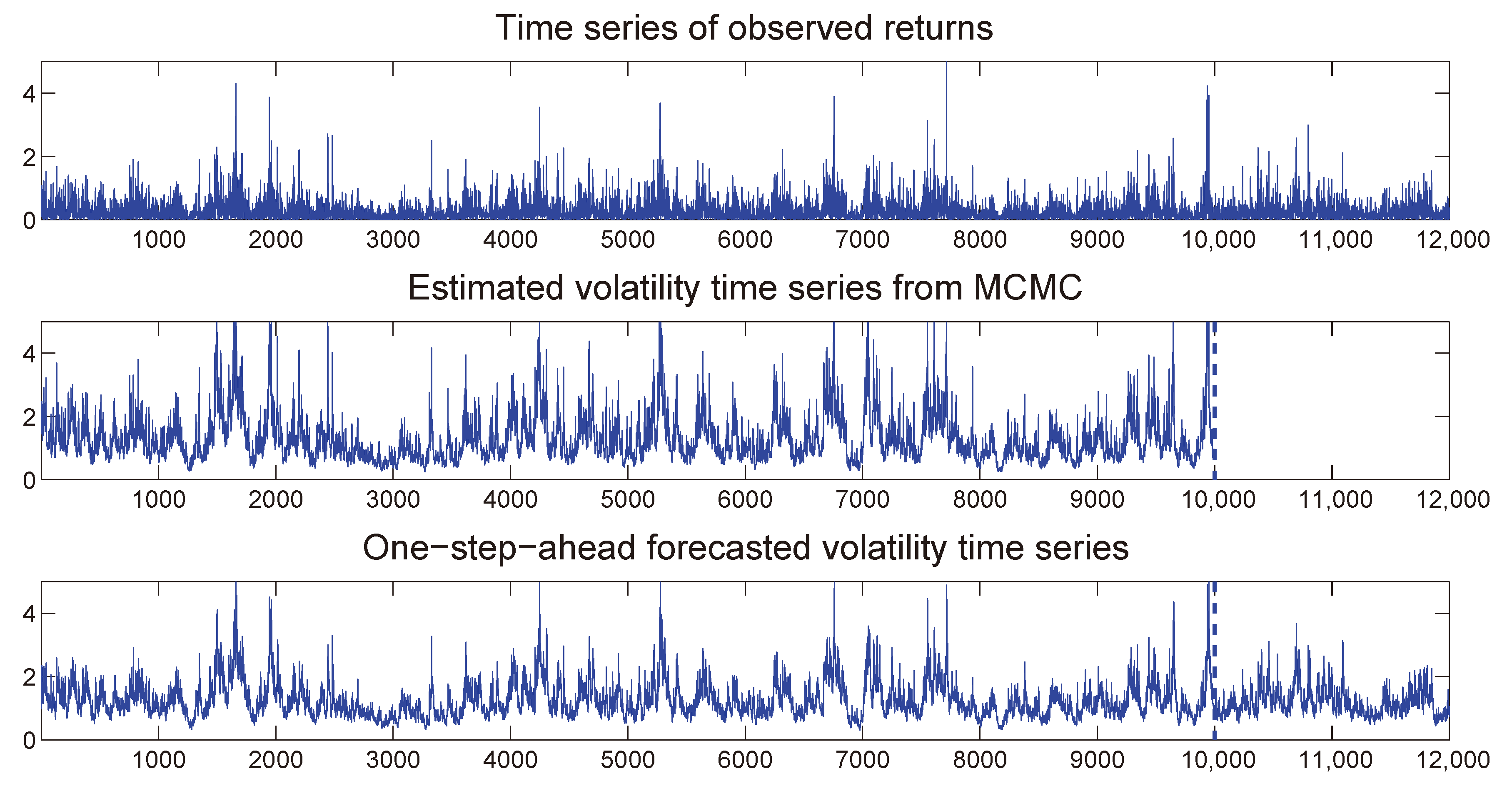
As part of the implementation of the MCMC algorithm, we augment the latent/unobserved volatility states with a vector of parameters and estimate them as a by-product of the process.
2.4. Estimation of the MSASV Model
We first present an outline of the MCMC algorithm in
Table 1.
Then we provide an additional explanation for this algorithm as follows.
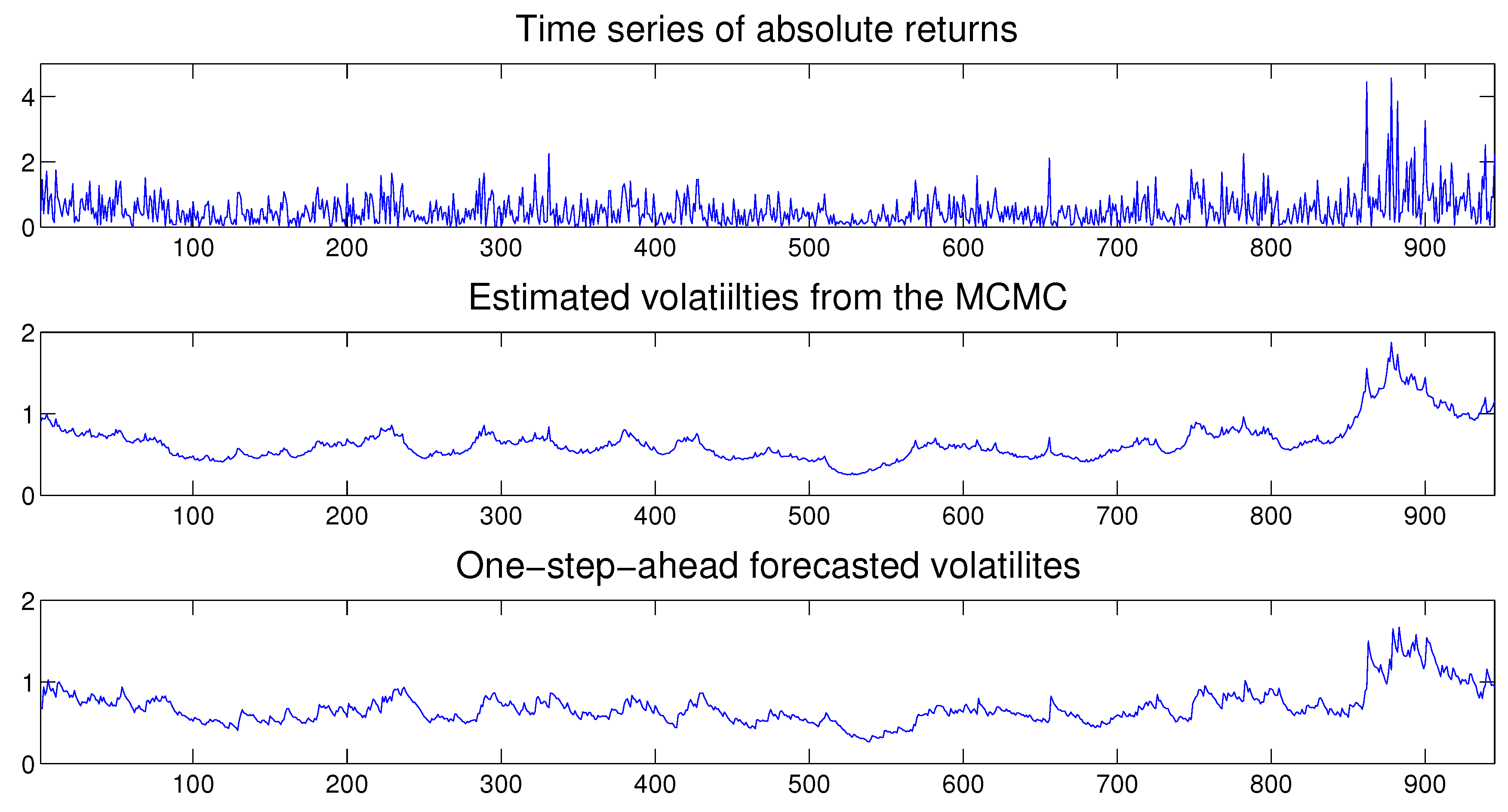
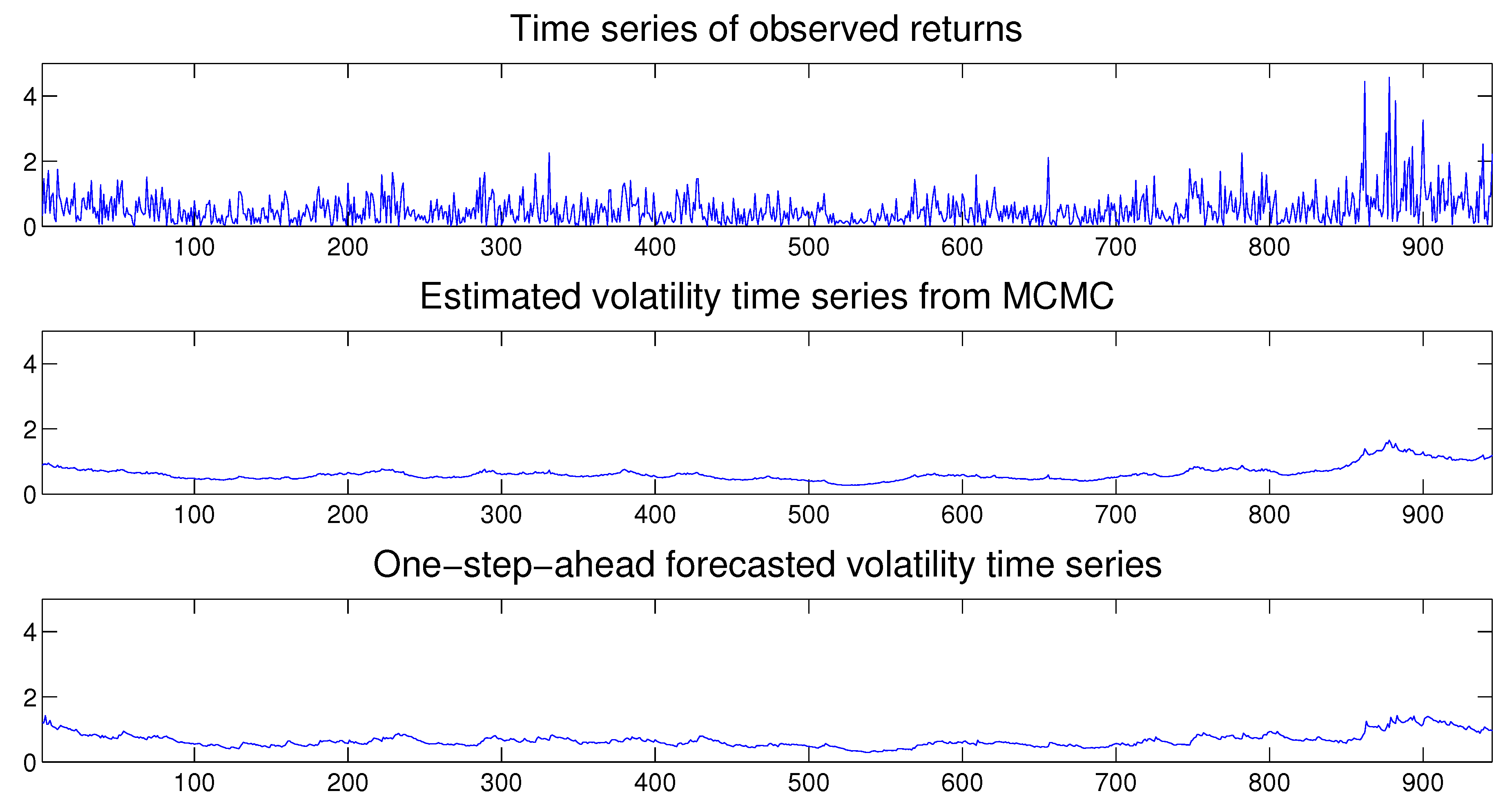
Step 0. Initialize , , and by using the relevant prior distributions. To determine the initial value of the vector we set the parameters of the latent volatility process as , , , and . Then we generate the initial value of by using the definition (5) and (6) of the process.
Step 1. Sample . We carry out the simulation by adopting a single-move acceptance-rejection algorithm.
We only state the full conditionals of . The full conditionals of and can be relatively straightforward to derive and therefore they are not presented here.
The full conditional of
is:
where
and
represent two normalizing constants. The reason that the inequality sign in (10) holds true is because the last two parts of the right-hand side of the Equation in (
9) is constrained to be less than unity. It is also worth pointing out that both the full conditional distribution (
9) and the dominant distribution in (10) are unknown; as a result we are unable to simulate them directly. Instead we use the MH method to sample the full conditional distribution (
9). We note that the proposal distribution of the MH algorithm is critically important for the performance of the simulation outcome. Notably
Chib and Greenberg (
1995) laments that choosing a good proposal density likes searching for a proverbial needle in a haystack. In general a proposal density can be obtained by means of an approximation of the underlying full conditional (see
Jacquier et al. (
1994,
2004)) or by selecting a standard Gaussian density (see
Kim et al. (
1998) and
Zhang and King (
2008)). As is well-known in the literature, the critical aspect of MCMC in fitting a SV model is the sampling quality of the full conditionals of the augmented parameters, which are the log volatilities,
h. The contribution of this paper to the literature lies in the development of the MH method to sample the full conditional distribution (
9), where the proposal distribution is the dominant distribution in (10), which can be sampled by the method of slice sampler proposed by
Neal (
2003). The efficiency of the slice sampler method has been studied by authors such as
Roberts and Rosenthal (
1999) and
Mira and Tierney (
2002). In particular
Roberts and Rosenthal (
1999) show that, under certain sufficient conditions, the slice algorithm is quite robust and has geometric ergodicity properties.
Mira and Tierney (
2002) point out that the slice sampler has a smaller second-largest eigenvalue, which allows for a faster convergence to the underlying distribution.
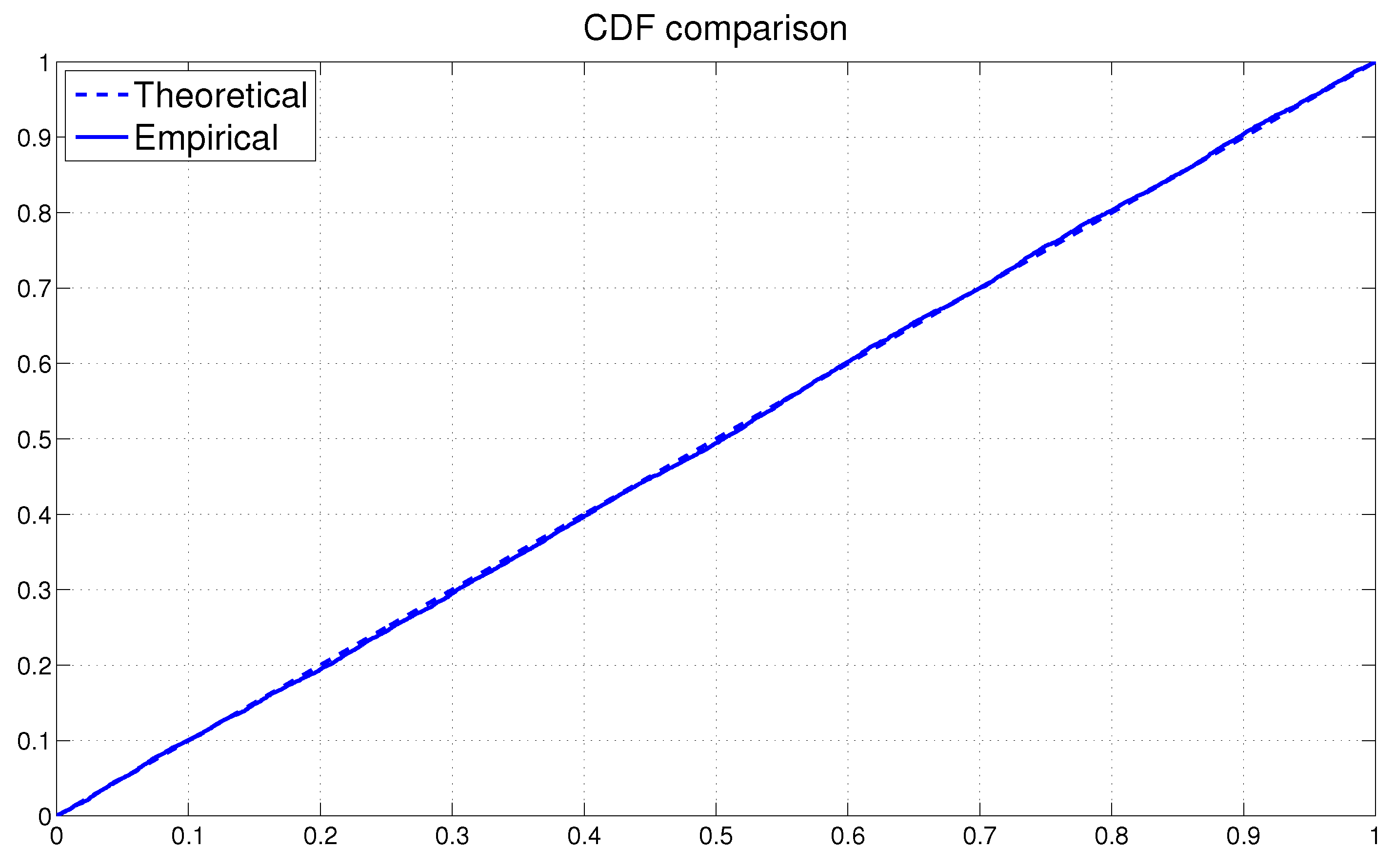
Algorithm of the slice sampler for
It is straightforward to show that the right-hand side of (10) can be: expressed as
where
.
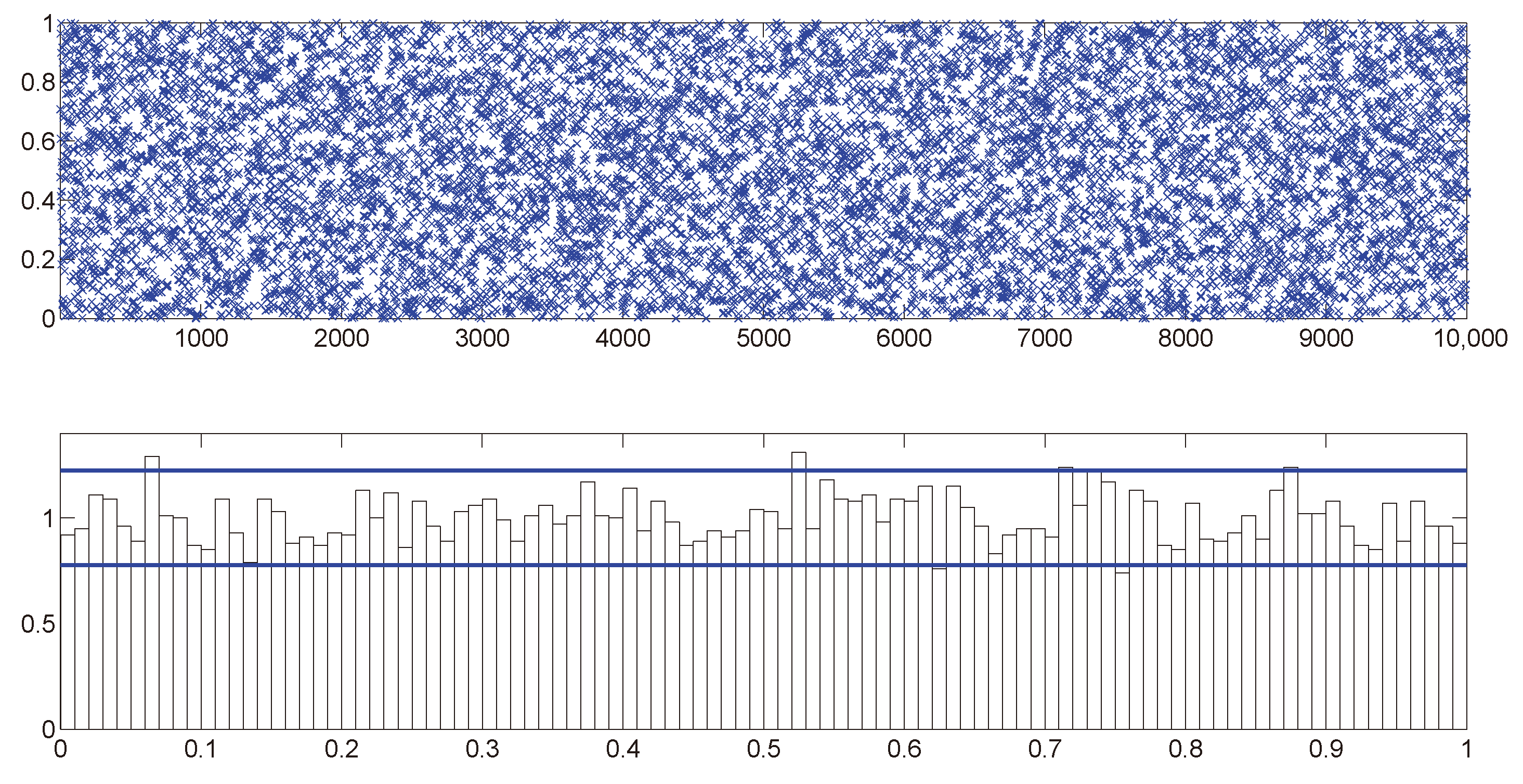
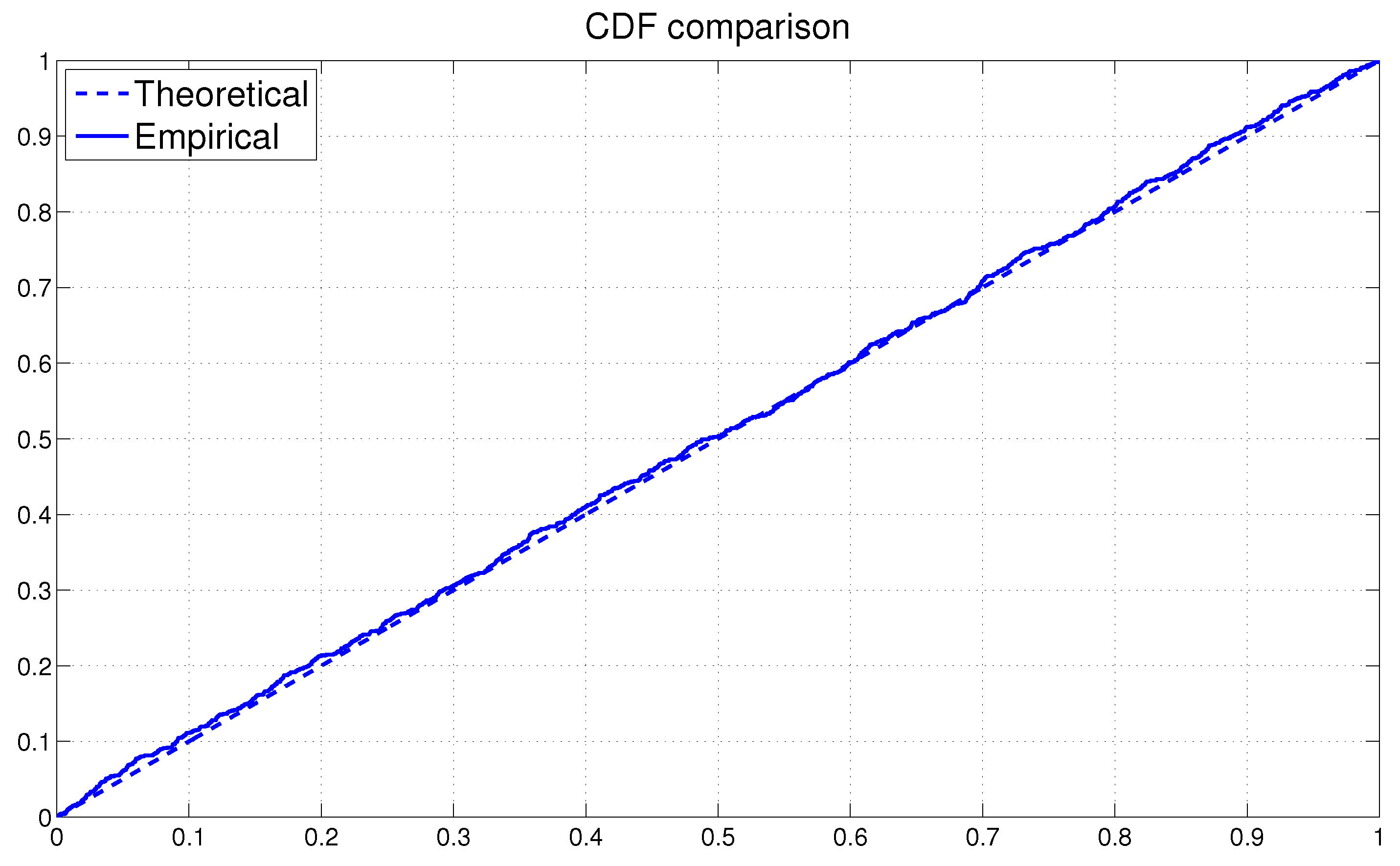
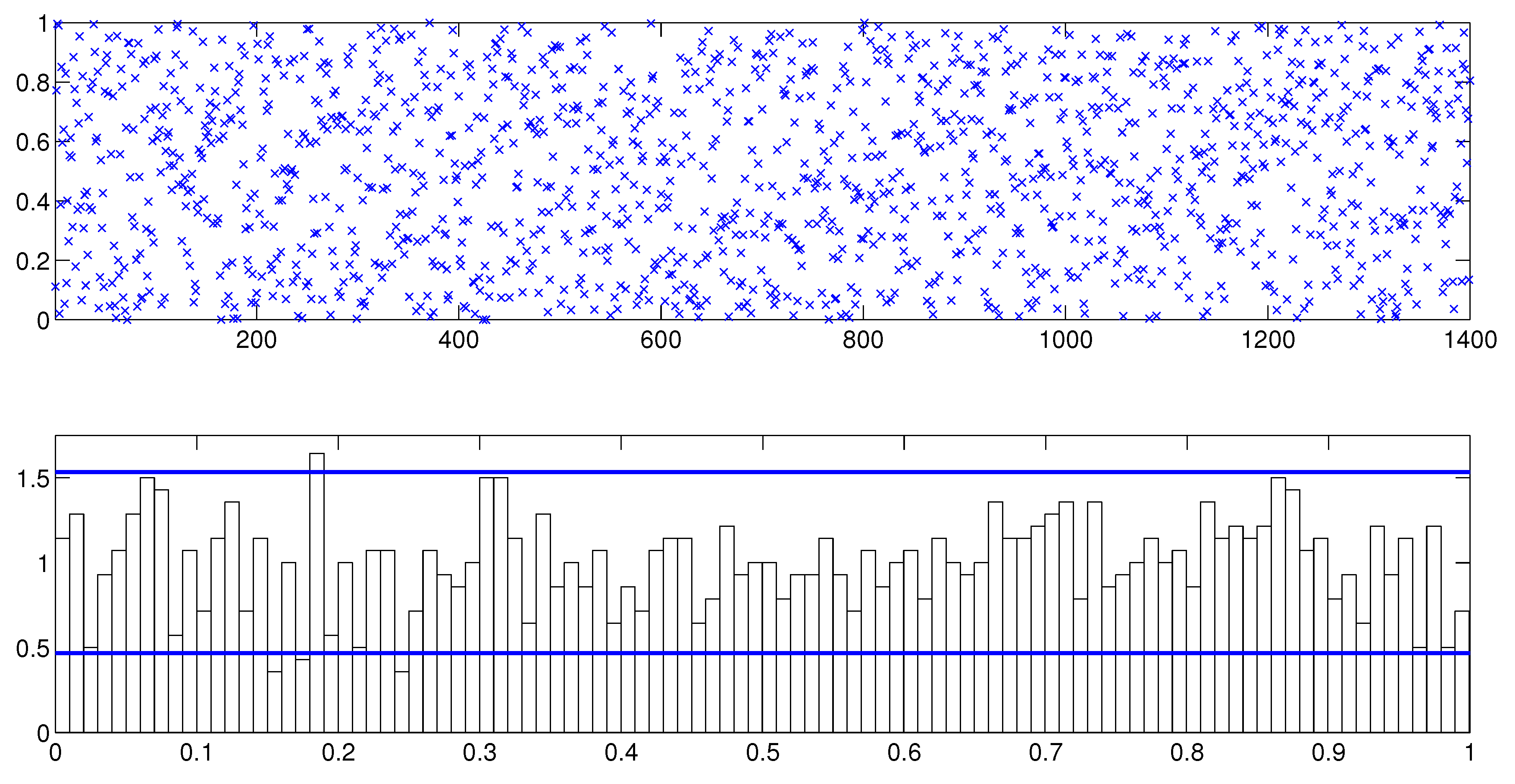
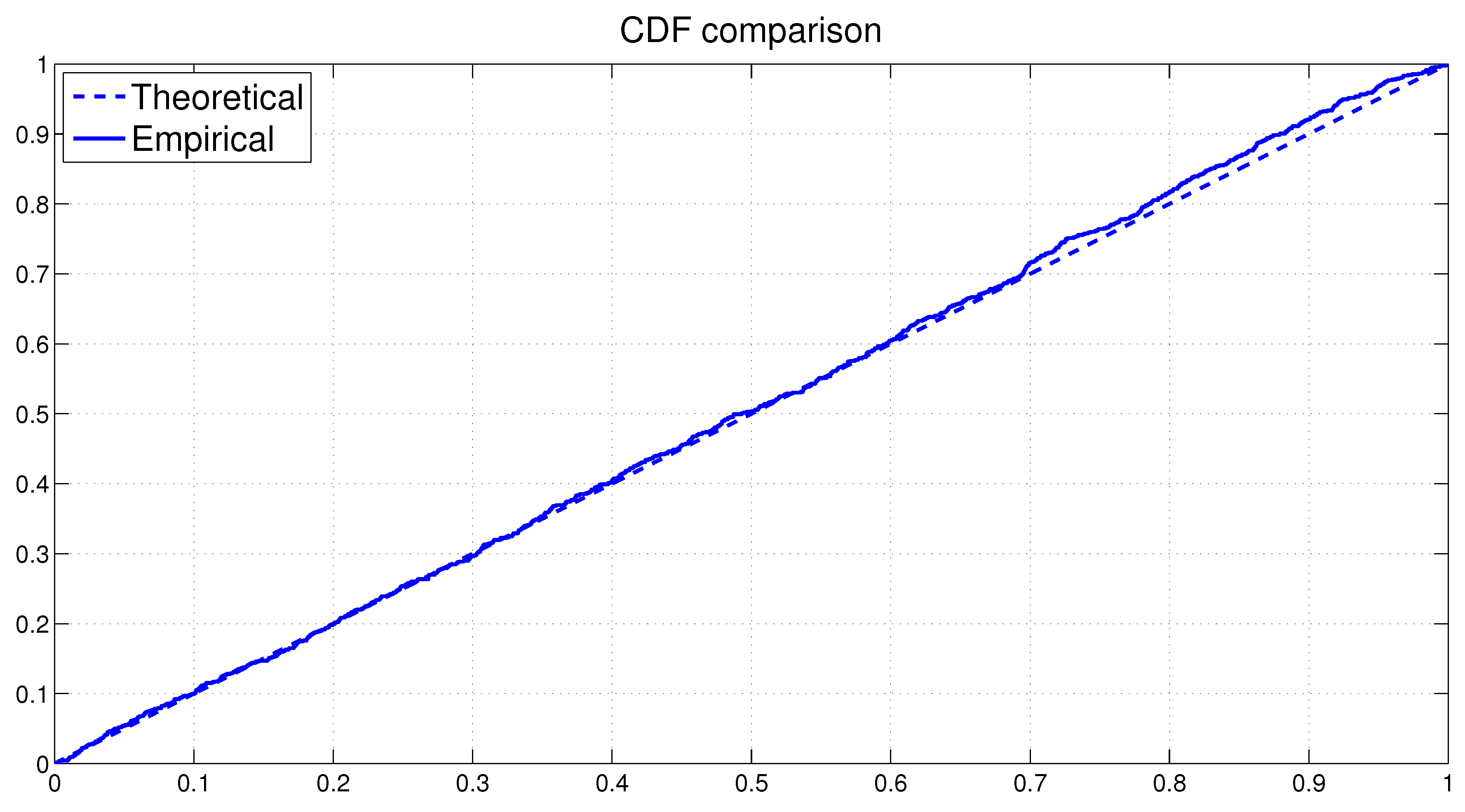
1. Draw uniformly from the interval. Let .
If
, then we have:
2. Draw uniformly from the interval.
Let
and
3. If
, draw
uniformly from the interval, which is determined by the inequalities stated in (11) and (12) as: -4.6cm0cm
otherwise,
We note that the method of the single-move simulation is widely used in the SV literature; notable examples include
Jacquier et al. (
1994,
2004);
Yu et al. (
2006);
Zhang and King (
2008) .
4 One important advantage of the slice sampler is that each iteration can give us a point from the underlying distribution; in contrast in the MH algorithm, many generated points have to be discarded.
Step 2. Sampling
. Given the conjugate prior distribution
, the full conditional of
is:
where
The full conditional is proportional to the product of a univariate Gaussian distribution and a positive function. As a result we can sample this full conditional by the method of slice sampler.
Step 3, 4, 5. Sampling parameters
and
and
. As the priors for these parameters are conjugate, the full conditionals are Gaussian and inverse Gamma distributions respectively. We can easily simulate these full conditionals. Therefore, we omit the presentation of these formulas from the text and, instead, refer readers to
Kim et al. (
1998) for a full description of them.
2.5. Estimation of the MSASV-t Model
Sampling the latent/unobserved states
. The simulation of
and
follows similar steps. The full conditional of
, is:
where
and
represent two normalizing constants. Note that the right-hand side of the inequality is a product of three positive functions of
; we can sample these quantities conveniently by the method of the slice sampler. The procedure is similar to the procedure used in the simulation of the latent/unobserved volatility states of the MSASV model, where the proposal distribution is simulated by the method of the slice sampler.
• Sampling
v. The full conditional of
v is:
where
is a prior density of
v. In the literature there is a number of ways in which to specify this prior distribution.
Jacquier et al. (
2004) propose a discrete prior distribution
from which the full conditional is sampled directly from a multinomial distribution.
Geweke (
1993) suggests
with
as an alternative, while
Zhang and King (
2008) choose a Gaussian distribution
.
Bauwens and Lubrano (
1998) use a Cauchy prior proportional to
. In this paper we adopt a Gaussian prior. Since this full conditional is an unknown distribution, we rely on a random-walk MH algorithm, in which the proposal density is a standard Gaussian density and the acceptance probability is computed by using Equation (
18).
























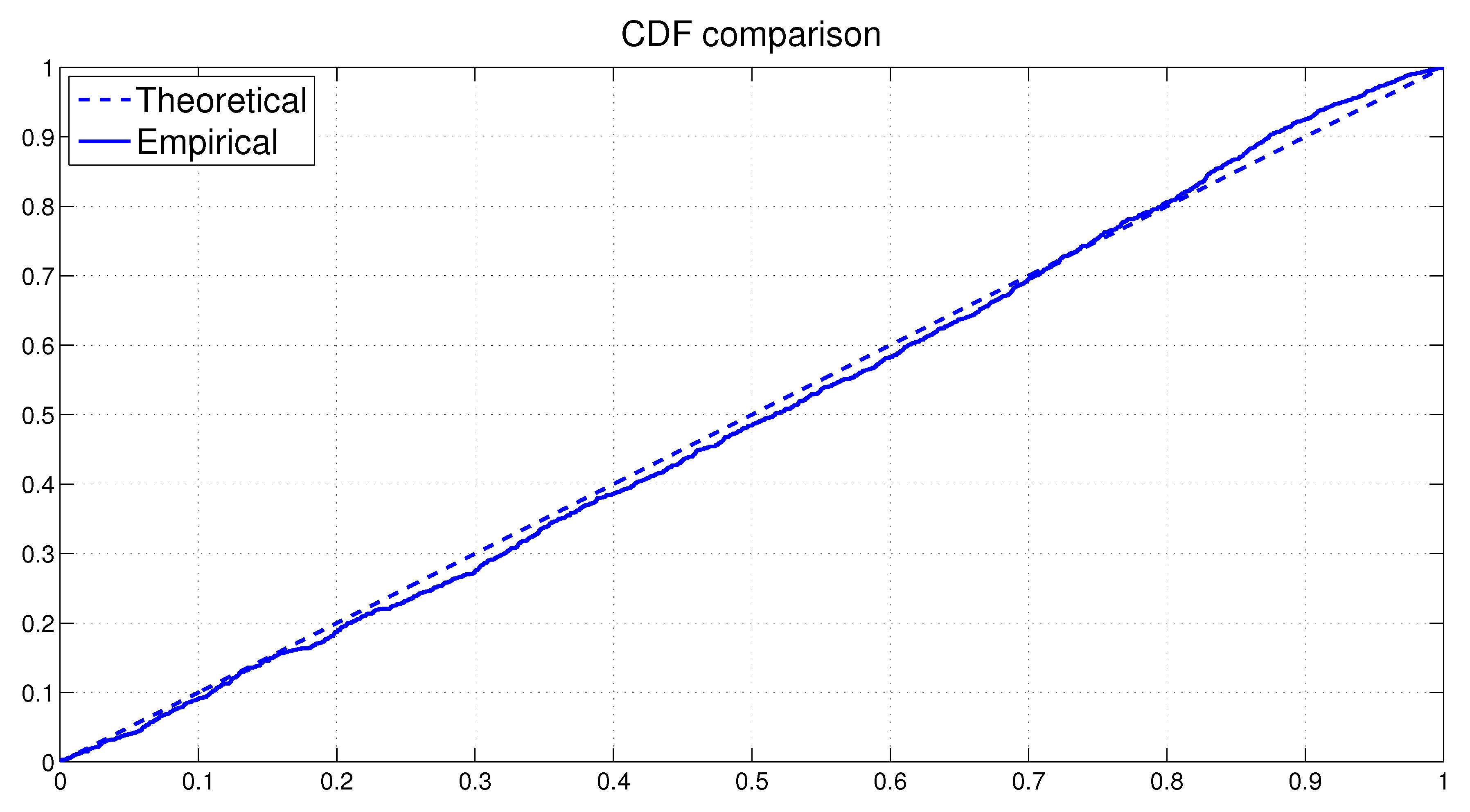
{kind=link}
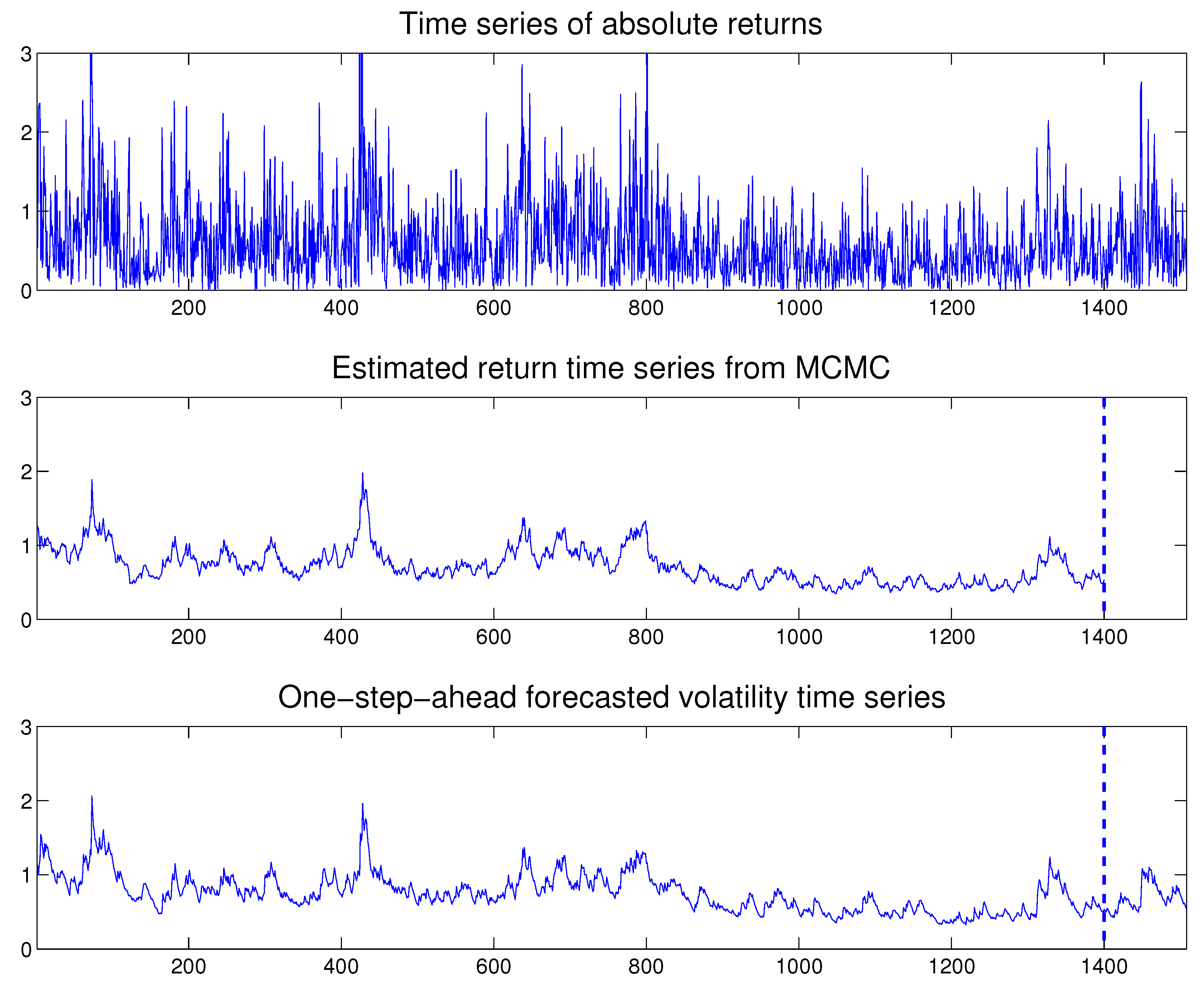
{kind=link}
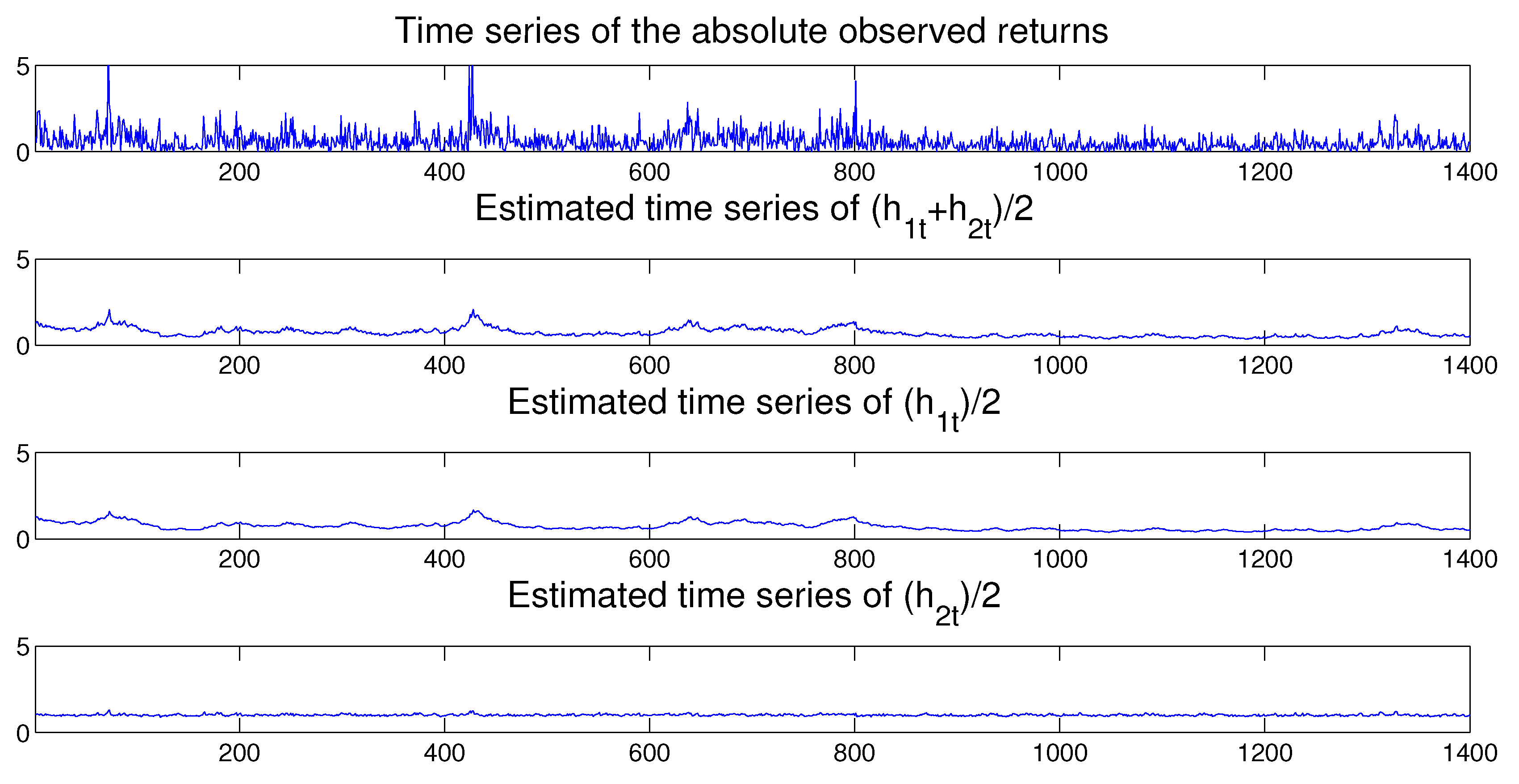
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}