
Do Financial Professionals Process Information Better as a Group Than Non-Professionals?

Abstract
:1. Introduction
2. Conceptual Underpinnings and Hypotheses
2.1. Conceptual Underpinnings
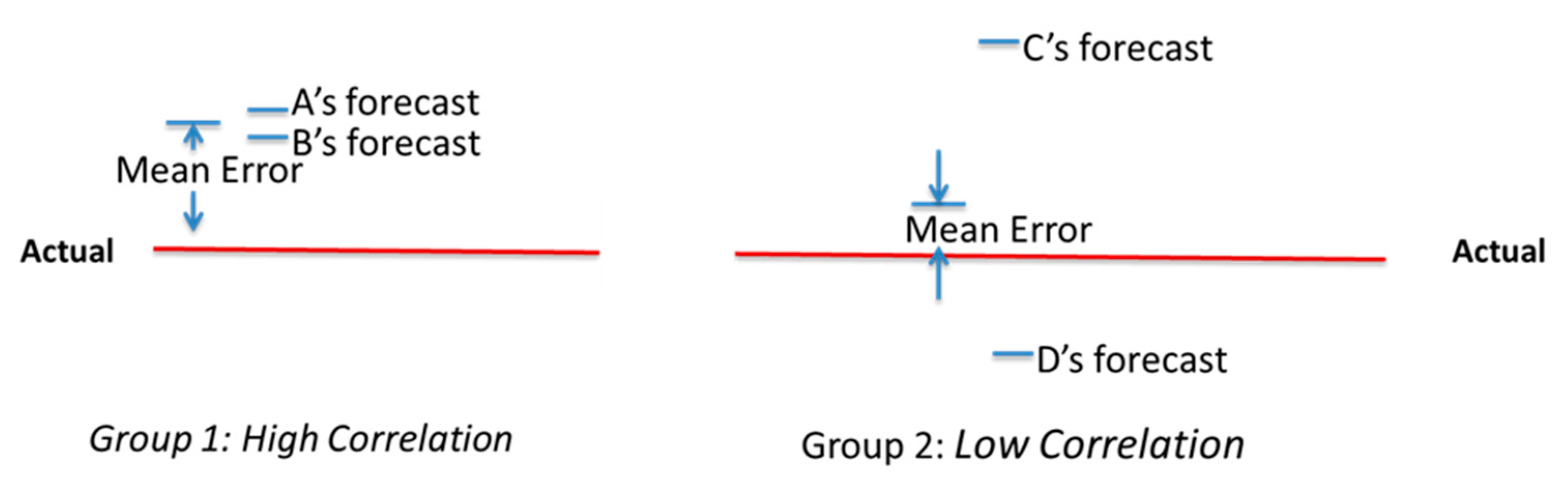
2.2. Hypotheses
3. Experimental Design and Procedure
4. Experimental Results
4.1. Descriptive Data
4.2. Hypotheses Tests
4.3. Information Weightings
4.4. Robustness Check
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Instructions

| 1 | We thank an anonymous reviewer for suggesting this analysis. |
References
- Anderson, Matthew J. 1988. A comparative analysis of information search and evaluation behavior of professional and non-professional financial analysts. Accounting, Organizations and Society 13: 431–46. [Google Scholar] [CrossRef]
- Andersson, Patric. 2004. Does experience matter in lending? A process-tracing study on experienced loan officers’ and novices’ decision behavior. Journal of Economic Psychology 25: 471–92. [Google Scholar] [CrossRef]
- Barber, Brad M., Terrance Odean, and Ning Zhu. 2009. Systematic noise. Journal of Financial Markets 12: 547–69. [Google Scholar] [CrossRef]
- Barron, Orie E., Oliver Kim, Steve C. Lim, and Douglas E. Stevens. 1998. Using Analysts’ Forecasts to Measure Properties of Analysts’ Information Environment. The Accounting Review 73: 421–33. [Google Scholar]
- Barron, Orie, Donald Byard, and Oliver Kim. 2002. Changes in Analysts’ Information around Earnings Announcements. The Accounting Review 77: 821–46. [Google Scholar] [CrossRef]
- Bonner, Sarah E. 2008. Judgment and Decision Making in Accounting. Upper Saddle River: Pearson. [Google Scholar]
- Broomell, Stephen B., and David V. Budescu. 2009. Why are experts correlated? Decomposing correlations between judges. Psychometrika 74: 531–53. [Google Scholar] [CrossRef]
- Cohn, Alain, Jan Engelmann, Ernst Fehr, and Michel André Maréchal. 2015. Evidence for countercyclical risk aversion: An experiment with financial professionals. American Economic Review 105: 860–85. [Google Scholar] [CrossRef] [Green Version]
- Haigh, Michael S., and John A. List. 2005. Do professional traders exhibit myopic loss aversion? An experimental analysis. The Journal of Finance 60: 523–34. [Google Scholar] [CrossRef]
- Hodge, Frank, and Maarten Pronk. 2006. The impact of expertise and investment familiarity on investors’ use of online financial report information. Journal of Accounting, Auditing & Finance 21: 267–92. [Google Scholar]
- Kaustia, Markku, Eeva Alho, and Vesa Puttonen. 2008. How much does expertise reduce behavioral biases? The case of anchoring effects in stock return estimates. Financial Management 37: 391–412. [Google Scholar] [CrossRef]
- Kirchler, Michael, Florian Lindner, and Utz Weitzel. 2018. Rankings and risk-taking in the finance industry. The Journal of Finance 73: 2271–302. [Google Scholar] [CrossRef]
- Kiymaz, Halil, Belma Öztürkkal, and K. Ali Akkemik. 2016. Behavioral biases of finance professionals: Turkish evidence. Journal of Behavioral and Experimental Finance 12: 101–11. [Google Scholar] [CrossRef]
- Libby, Robert, and Joan Luft. 1993. Determinants of judgment performance in accounting settings: Ability, knowledge, motivation, and environment. Accounting, Organizations and Society 18: 425–50. [Google Scholar] [CrossRef]
- Libby, Robert, Robert Bloomfield, and Mark W. Nelson. 2002. Experimental research in financial accounting. Accounting, Organizations and Society 27: 775–810. [Google Scholar] [CrossRef]
- Littell, Ramon C., George A. Milliken, Walter W. Stroup, Russell D. Wolfinger, and Oliver Schabenberger. 2006. SAS® for Mixed Models, 2nd ed. Cary: SAS Institute Inc. [Google Scholar]
- Maines, Laureen A. 1995. Judgment and Decision-Making Research in Financial Accounting: A Review and Analysis. Edited by A. H. Ashton and R. H. Ashton. Judgment and Decision-Making Research in Accounting and Auditing. Cambridge: Cambridge University Press. [Google Scholar]
- Noreen, Eric, George Foster, and Philip Brown. 1985. Studies in Accounting Research, 1st ed. Sarasota: American Accounting Association, vol. 1. [Google Scholar]
- Ramnath, Sundaresh, Steve Rock, and Philip Shane. 2008. The Financial Analyst Forecasting Literature: A Taxonomy with Suggestions for Further Research. International Journal of Forecasting 24: 34–75. [Google Scholar] [CrossRef]
- Roth, Benjamin, and Andrea Voskort. 2014. Stereotypes and false consensus: How financial professionals predict risk preferences. Journal of Economic Behavior & Organization 107: 553–65. [Google Scholar]
- Shiller, Robert. 2005. Irrational Exuberance, 2nd ed. Woodstock and Oxfordshire: Princeton University Press. [Google Scholar]
- Trotman, Ken T., Hwee C. Tan, and Nicole Ang. 2011. Fifty-year overview of judgment and decision making research in accounting. Accounting and Finance 51: 278–360. [Google Scholar] [CrossRef]


{kind=link}
| Disclosure Regime | Professional | Non-Professional |
|---|---|---|
| Earnings and Cash Flow | 25 | 41 |
| Earnings | 22 | 40 |
| Cash Flow | 22 | 40 |
| Disclosure Regime | Professional | Non-Professional | p-Value |
|---|---|---|---|
| Earnings and Cash Flow | 1422.64 | 1737.62 | 0.01 |
| Earnings | 1410.2 | 1864.47 | 0.00 |
| Cash Flow | 1275.92 | 1459.53 | 0.09 |
| Disclosure Regime | Professional | Non-Professional | p-Value |
|---|---|---|---|
| Earnings and Cash Flow | 2135.37 | 2290.14 | 0.29 |
| Earnings | 2430.39 | 2571.63 | 0.49 |
| Cash Flow | 2289.18 | 2122.42 | 0.53 |
| Disclosure Regime | Professional | Non-Professional | p-Value |
|---|---|---|---|
| Earnings and Cash Flow | 0.49 | 0.60 | 0.00 |
| Earnings | 0.46 | 0.62 | 0.00 |
| Cash Flow | 0.46 | 0.53 | 0.01 |
| Disclosure Regime | Error Sign | Professional | Non-Professional | p-Value |
|---|---|---|---|---|
| Earnings and Cash Flow | Positive | 0.72 | 0.78 | <0.001 |
| Negative | 0.28 | 0.21 | <0.001 | |
| Earnings | Positive | 0.71 | 0.80 | <0.001 |
| Negative | 0.28 | 0.20 | <0.001 | |
| Cash Flow | Positive | 0.70 | 0.74 | <0.001 |
| Negative | 0.28 | 0.25 | 0.001 |
| Panel A: Disclosure Regime—Earnings | |||
| Professional | Non-Professional | p-Value | |
| Earnings | 23.23 | 22.20 | 0.82 |
| [19.62] | [12.10] | 0.009 | |
| Price | 18.82 | 19.38 | 0.91 |
| [20.78] | [12.08] | 0.003 | |
| Beta | 14.50 | 15.63 | 0.78 |
| [14.95] | [15.12] | 0.98 | |
| Panel B: Disclosure Regime—Cash Flow | |||
| Professional | Non-Professional | p-Value | |
| Cash Flow | 15.82 | 18.60 | 0.51 |
| [20.32] | [13.30] | 0.02 | |
| Price | 19.95 | 12.23 | 0.16 |
| [23.14] | [13.32] | 0.003 | |
| Beta | 33.77 | 23.55 | 0.24 |
| [33.20] | [29.88] | 0.56 | |
| Panel C: Disclosure Regime—Earnings and Cash Flow | |||
| Professional | Non-Professional | p-Value | |
| Earnings | 17.28 | 21.24 | 0.23 |
| [11.36] | [15.25] | 0.13 | |
| Cash Flow | 14.92 | 15.02 | 0.97 |
| [10.33] | [11.73] | 0.51 | |
| Price | 16.92 | 21.13 | 0.43 |
| [21.49] | [19.06] | 0.49 | |
| Beta | 19.00 | 14.71 | 0.52 |
| [29.99] | [18.75] | 0.01 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barron, O.E.; Enis, C.R.; Qu, H. Do Financial Professionals Process Information Better as a Group Than Non-Professionals? J. Risk Financial Manag. 2021, 14, 230. https://doi.org/10.3390/jrfm14050230
Barron OE, Enis CR, Qu H. Do Financial Professionals Process Information Better as a Group Than Non-Professionals? Journal of Risk and Financial Management. 2021; 14(5):230. https://doi.org/10.3390/jrfm14050230
Chicago/Turabian StyleBarron, Orie E., Charles R. Enis, and Hong Qu. 2021. "Do Financial Professionals Process Information Better as a Group Than Non-Professionals?" Journal of Risk and Financial Management 14, no. 5: 230. https://doi.org/10.3390/jrfm14050230
APA StyleBarron, O. E., Enis, C. R., & Qu, H. (2021). Do Financial Professionals Process Information Better as a Group Than Non-Professionals? Journal of Risk and Financial Management, 14(5), 230. https://doi.org/10.3390/jrfm14050230