2. Background Literature
The benchmark Capital Asset Pricing Model, or (
), by
Sharpe (
1964),
Lintner (
1965) and
Markowitz (
1968), implies that the expected excess return on any asset is influenced by its sensitivity to the market, which is measured by the beta coefficient, times the market risk premia. Traditionally, this beta is considered invariant over time and represents the covariance between the return of the asset and the return on the market portfolio. The basic model has been criticised by
Black et al. (
1972),
Fama and French (
1992) and
Fama and MacBeth (
1973), among others, on the grounds that only one factor, the market beta, is inadequate to describe the systemic risk. Hence, many researchers have attempted to improve the basic
by the introduction of other factors. Most notably, there is the three-factor model by
Fama and French (
1992), which introduced the size, or
factor (positive returns are related to small size), and the high minus low,
, factor (high book-to-market ratios are associated with higher returns). On the other hand,
Carhart (
1997) introduced a fourth momentum factor,
, which describes the tendency of a stock price to continue recent trends. Several other factors have been proposed and investigated in the literature; see
Harvey et al. (
2016) and
Harvey and Liu (
2019) for more details.
Further developments with extending the basic
have centred on implementing more flexible estimation strategies where the beta coefficient(s) are not necessarily assumed to be constant across time or space. For example, see
Harvey (
1989),
Ferson and Harvey (
1991),
Bollerslev et al. (
1988) and
Fama and French (
1997),
Fama and French (
2006), who have suggested that a constant beta estimated using
does not capture the dynamics of the beta and is unable to satisfactorily explain the cross-section of average returns on equities.
Adrian and Franzoni (
2005) argue that models without time-evolving betas fail to capture investor characteristics and may lead to inaccurate estimates of the true underlying risk. There are numerous factors that contribute to the variation in beta, including regulation, economic and monetary policies, and exchange rates. Many researchers, such as
Zolotoy (
2011), show that variations in betas are more evident around important news announcements.
Jagannathan and Wang (
1996),
Lettau and Ludvigson (
2001b) and
Beach (
2011) show that the conditional
with time-varying beta generally outperforms an unconditional
with a constant beta.
One technique that is often used is to take into account changes in the systematic risk of an asset through a rolling window
regression (e.g.,
Fama and MacBeth (
1973) and
Lewellen and Nagel (
2006)). While the former paper uses monthly returns over a five-year window, the latter employs returns at different horizons to capture the different rate of variation of risk over a variety of interval lengths (monthly, quarterly and semi-annually). The main difficulty of the rolling window regression approach is the attempt to capture local variations by having short intervals of data, which is incompatible with the desire of having tight standard errors, hence tight confidence intervals on the estimated beta parameters. Other researchers have directly exploited the covariation between the market and other assets; e.g.,
Engle (
2002) and
Bali and Engle (
2010) estimated time-varying betas using multivariate dynamic conditional correlation methods to exploit correlations between cross-sectional average returns of various factor portfolios. The usage of a realized beta allows us to adjust information instantaneously.
As previously described, the variation in the beta coefficients can be modelled through the evolution of the conditional distribution returns as a function of lagged state variables (see
Jagannathan and Wang (
1996),
Ferson and Harvey (
1999) and
Adrian and Franzoni (
2005), among others). In all cases, the authors explicitly specify the covariance between the market and portfolio returns as affine functions of pre-determined state variables.
Jagannathan and Wang (
1996), instead, develop a conditional version of the
, augmented by a human–capital factor, and show that it explains a substantial fraction of the cross-sectional variation in the returns on 100 portfolios sorted by size and book-to-market ratio. Further,
Adrian and Franzoni (
2005) admit unobservable long-run changes in risk factor loadings, given by a learning process of rational in investors. Recently,
Fama and French (
2020) have shown that models that use only cross-sectional factors provide better descriptions of average returns than time-series models that use time-series factors. This has been proven to be valid when considering prespecified and optimised time-varying loadings. The main drawback of these parametric approaches is that they require the correct specification for the functional form of the betas, or, in other words, they need to identify the right state variables. As pointed out by
Ghysels (
1998) and
Harvey (
2001), models with misspecified betas often feature larger pricing errors than models with constant betas.
Recent non-parametric approaches have been proposed to allow the CAPM parameters to evolve smoothly over time.
Ang and Kristensen (
2012) used this methodology to investigate the distributions for conditional and for long-run alphas and betas, averaged over time. They used different bandwidths for conditional and long estimates in order for any finite-sample biases and variances to vanish. In addition, kernel-smoothing estimators have the appealing feature that they nest, as a special case, rolling window estimates of betas (see, for example,
Ferson and Harvey 1991;
Petkova and Zhang 2005, among many others).
The methodology uses
Giraitis et al. (
2014,
2015,
2018). They provide a rigorous justification for using kernel methods to estimate structural change when the parameters that undergo change are not governed by a deterministic function of time, allowing a wide class of stochastic processes that are characterised by persistence to be performed.
5. Empirical Results of the Hierarchical Analysis
Following the details of the above methodological framework,
Table 1 provides the descriptive statistics for the optimal bandwidth parameters
for all the different datasets. The results are categorized in terms of the methodology used to compute the time-varying
measure;
and
refer to the conventional rolling window approach with windows of 12 and 24 observations, Equation (
5), while
refers to the kernel approach (Equation (
6)). From the analysis of the panels containing the portfolio results, it can be seen that the cross-validation procedure was remarkably consistent in choosing an
h near
and a standard deviation of the estimates relatively small, lying in the range from
to
for all the methodologies. Regular
t-tests were unable to reject the hypothesis that
for any of the portfolio classifications. This finding is particularly interesting, since
is the theoretical value identified by
Giraitis et al. (
2014) as being the optimal value for
h in terms of achieving an appropriate rate of convergence to an asymptotic distribution of the
. However, the averages for
for the individual stock data were higher than the ones for the two portfolios, being around
. This can be interpreted as the need to increase the degree of smoothness when using data with high levels of heterogeneity. In addition, the analysis of across the different methods for computing the
shows that the non-parametric
approach provided the highest values for the standard deviations for each portfolio.
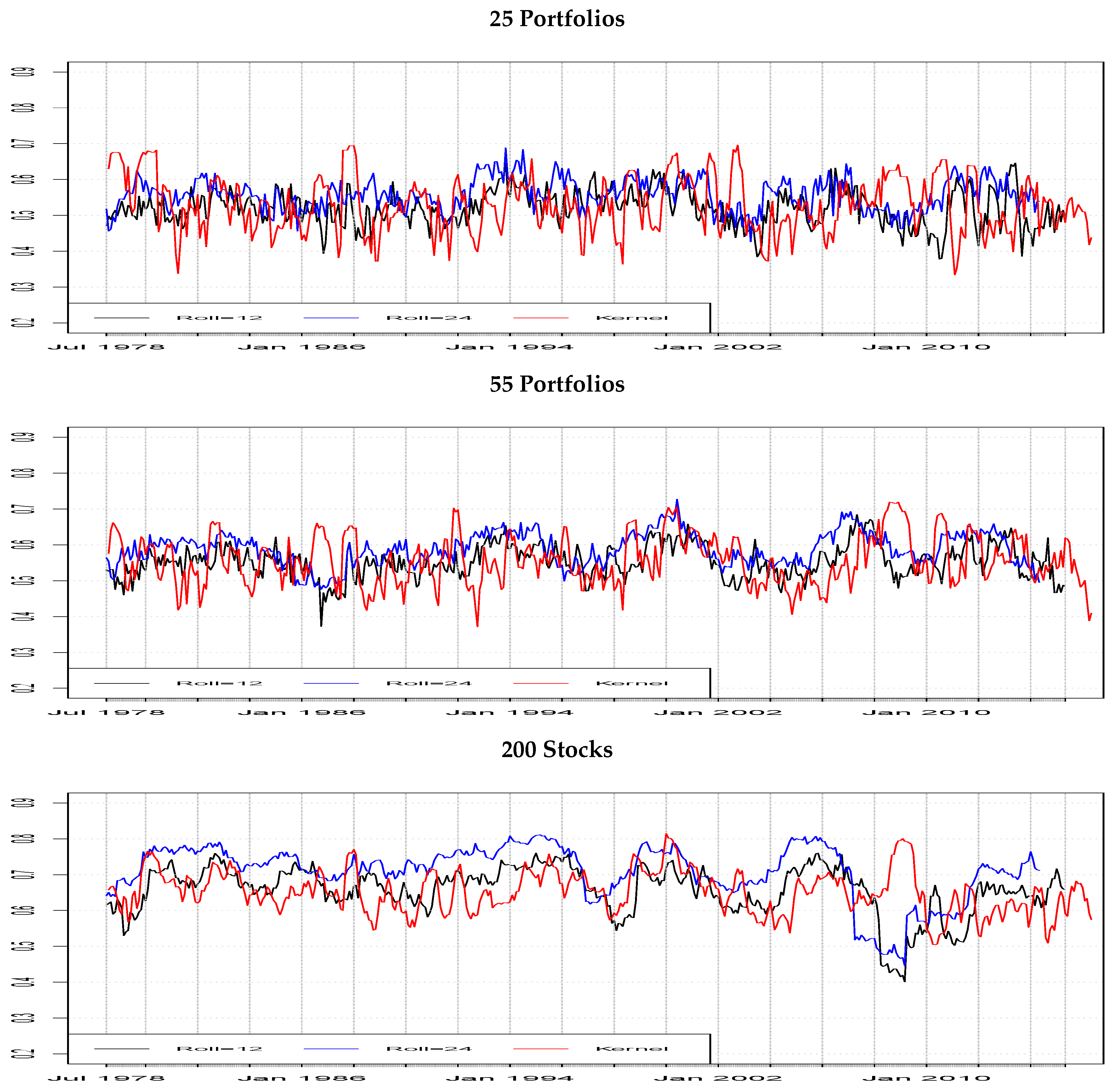
Figure 1 plots the selected optimal bandwidth parameters, averaged across assets as in Equation (
8), for each of the different methodologies for computing the time-varying
and also for different datasets. All the methods provided an erratic mean-reverting path, centred around
, where the kernel approach confirms to be the most volatile in all the data combination. In general, the non-parametric approach appears to be the most volatile and is the only one that increased in the global financial crisis,
.
Table 2 and
Table 3 provide details of the estimated beta coefficients for representative assets for each dataset. The portfolio datasets were estimated for the median portfolios, named
, while, for the constituents of the
, they were analysed by the
index. Standard errors are given for each of the three factor loadings:
,
and
. The estimated market beta
was close to the unity for all the portfolio datasets, while it was around
for the Ford stock, in line with previous literature. The standard errors provided by the
approach were the smallest and were very important for subsequent efficient estimation of risk premia
4.
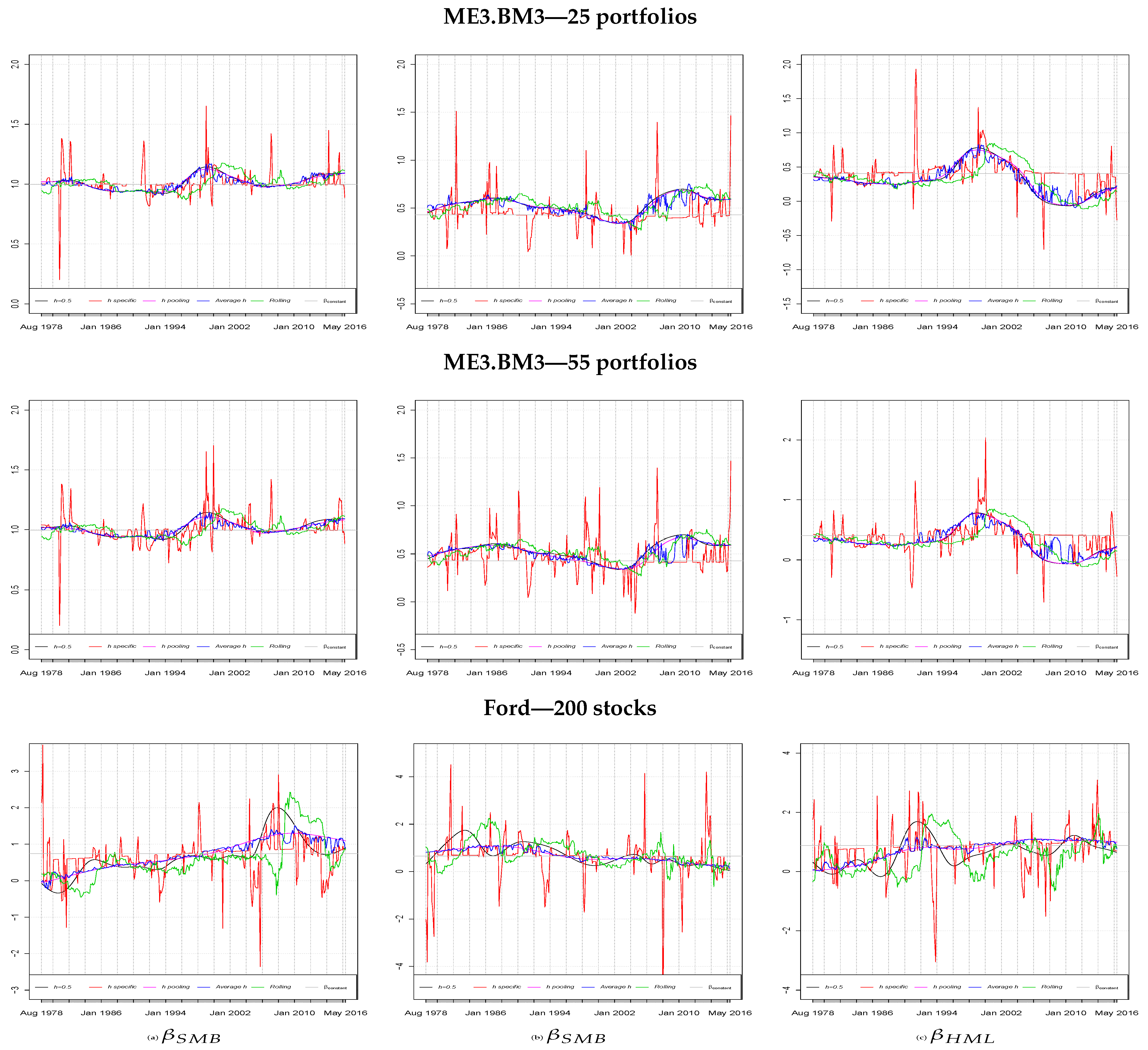
Figure 2 presents the factor risk loading estimates. Each one of the nine separate panels shows five
beta estimates derived from the methodologies presented in
Section 3. In particular, the rolling window is displayed with a green line, the kernel estimate with constant bandwidth parameter of
in black, the constant bandwidth parameter from poll average,
, in purple; further, the time-varying
h, set equal for all the asset,
, is represented by a blue line and the time-varying
h optimised for each asset,
, by a red line. The last three methods all use the Gaussian kernel.
In all the scenarios, the time-varying estimates were centred around the constant ones, highlighting the correctness of the methodology. Further, a similar path can be seen for all the kernel estimates with the ones produced by the classical rolling window approach. In accordance with
Adrian et al. (
2015), the estimates produced with the classical approach exhibited, overall, a higher variation than the one produced with kernel approaches. Although these estimates follow a path in line with the others, they are characterised by numerous sudden changes along the sample period. These changes appear to be asset-specific, hence, different asset by asset.
As expected, the beta estimates for portfolio datasets exhibited a lower degree of variation than those that employed stock indexes. This is presumably due to noise using stock data and the loss of information induced by grouping stocks to build a portfolio (
Lo and MacKinlay (
1990)). In general, the betas on the
and
factors were the ones that most often switch sign, while the
appears to be the most stable factor.
Table 4 provides the estimates and the respective standard errors of the risk premium parameters
, with
, also including the constant term. The Newey West standard errors are also displayed in the last column. Further, it presents results for
, computed using
with the kernel-averaging approach. The results for the other two parametric approaches are available online.
The average prices of risk appear to be very similar across the different methods and within each dataset. The
method shows the smallest standard errors despite the sample considered. The sample size appears to matter and affects the significance of the price of all the factors. In particular,
was priced only considering individual stocks. This result is consistent with other studies showing that
is not priced in the cross-section of portfolios sorted by size and book to market (see
Adrian et al. (
2015) and
Lettau and Ludvigson (
2001a)).
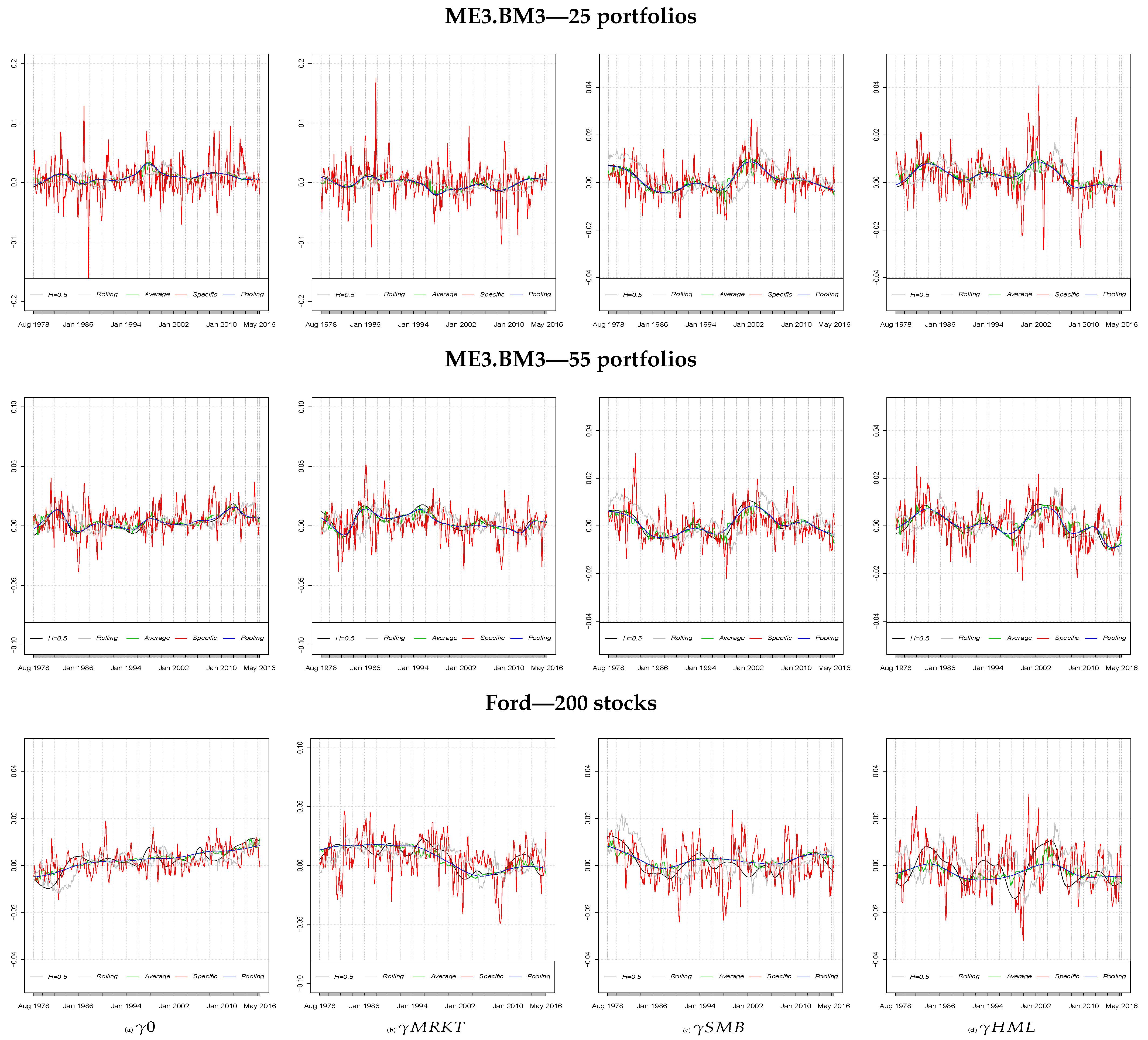
Despite most of the factors were not statistically different from zero on average—hence not priced—they exhibited a statistically significant time variation and fluctuated a lot between positive and negative values. Further, the significance of the constant term (
), mostly throughout the entire sample, is in line with the literature, suggesting that the factors considered by
Fama and French (
1992) only partially describe the excess returns
5. This time variation of the price of risk is well documented by the set of
Figure 3,
Figure 4,
Figure 5 and
Figure 6.
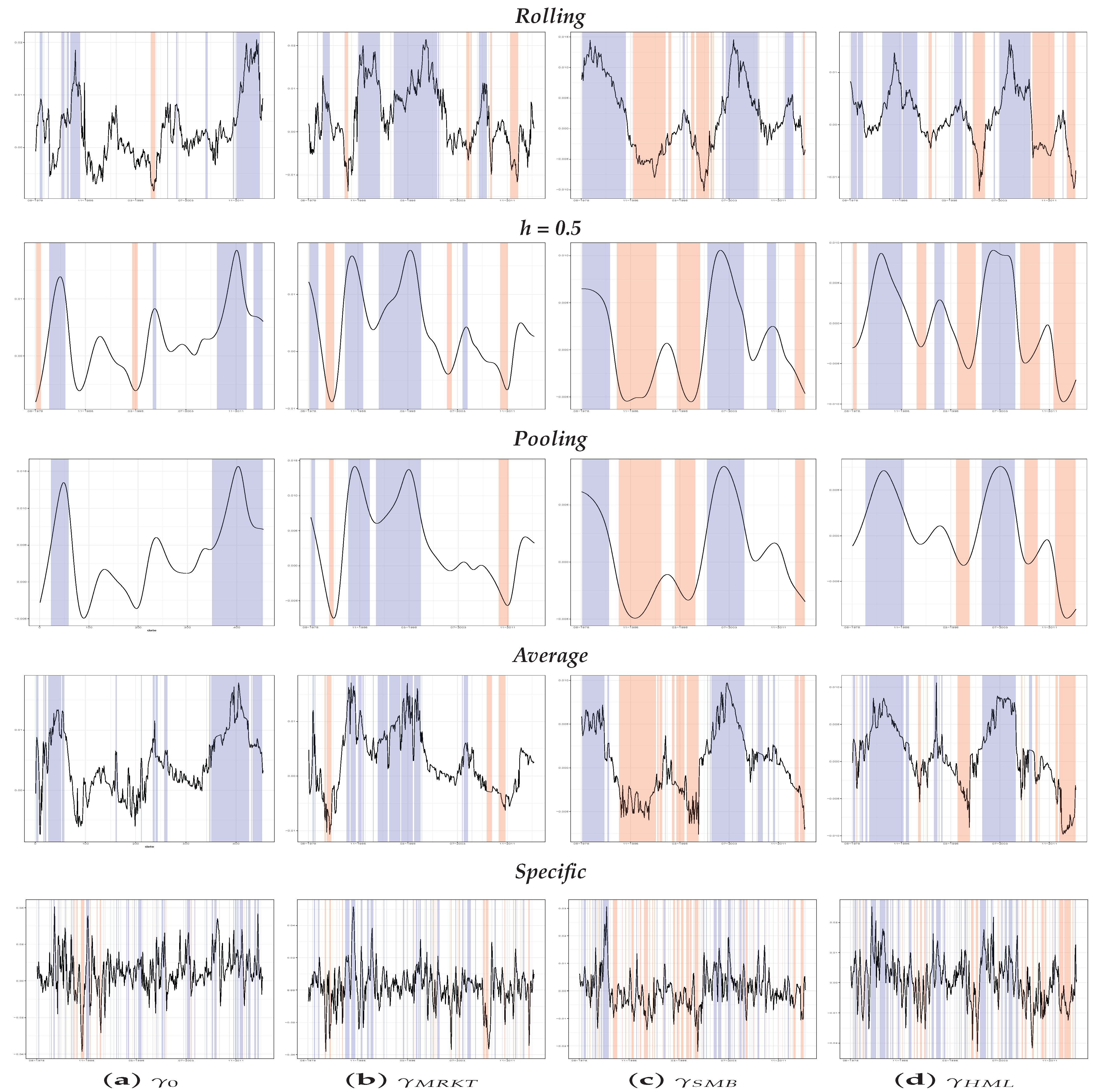
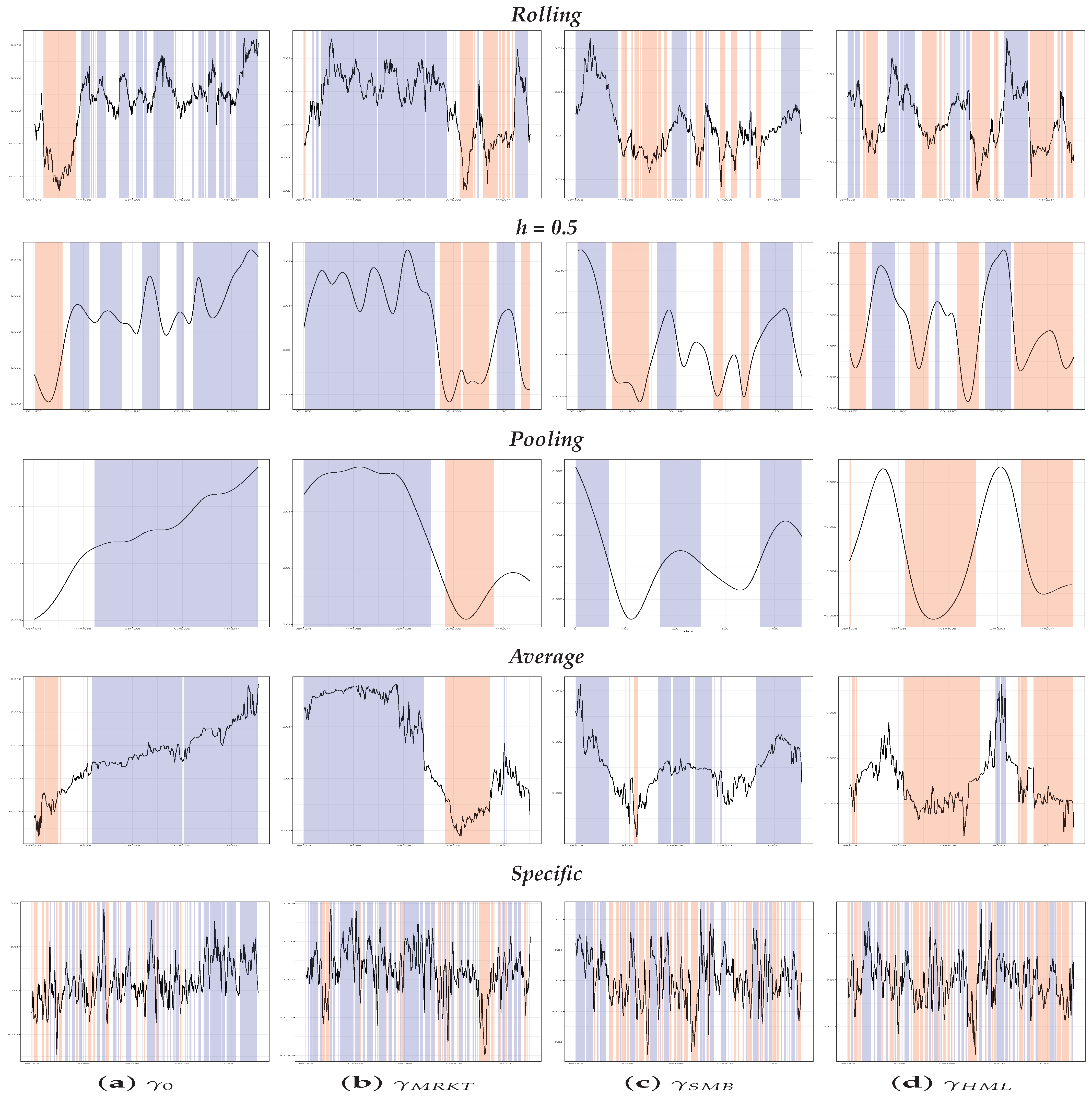
Figure 3 plots, by columns, the
s for the three different samples, with the top panel relating to the 25 portfolios, the central panel to the 55 portfolios and the bottom panel individual stocks. As before, the value of
and the
methods described a form of background path for the evolution of the price of risk, while the
approach exhibited the highest volatility. From the analysis of these graphs, it is clear how much of the information about the price of risk was lost using approaches such
where we did not consider the specificity of each asset.
In particular, only the
approach seems able to capture the
, where the drop in the estimates of the price of the factors is clearly evident. In
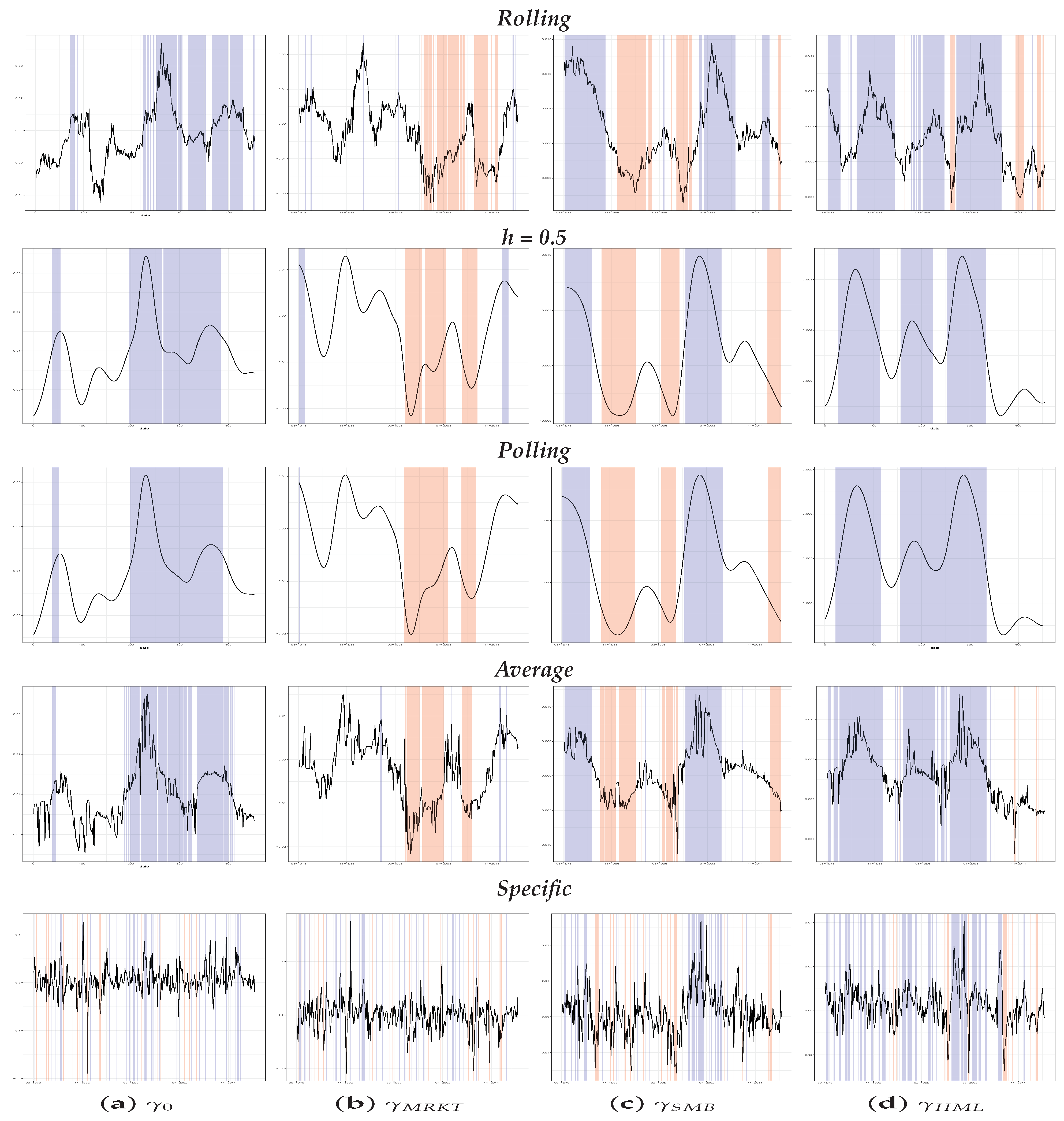
Figure 4,
Figure 5 and
Figure 6, instead, we reproduce an analysis of the significance for the different estimates across time—
Figure 4 contains the results for 25 portfolios and
Figure 5 for 55 portfolios, while
Figure 6 the ones for individual stocks. All the Figures are structured as follows: in the columns, the different
s are reported, while, in each row, there is a different method for the computation of
, as in
Section 2. For what concerns the market risk premia, they show a significant positive sign at the beginning of the sample until early 2000, when it becomes significantly negative. Such change was captured by all the methods, despite it being clearer for the stock asset context.
An important aspect of the hierarchical method is the improvement in the forecasting precision.
Table 5 displays the
of an out-of-sample forecast exercise, reported as deviation from the
produced by the benchmark
Fama and MacBeth (
1973) approach (
). The analysis of the tables identifies the
approach as the best method, since it produced a remarkable reduction in the loss function, hence more precise forecast. The overall gains were greater for the portfolios of sizes 25 and 55. This approach produced improvements of around
with respect to the basic
Fama and MacBeth (
1973) and of
with respect to the kernel approach with optimal bandwidth parameter set to
. Further, since the
approach also outperformed the other two kernel methods,
and
, the importance of the time variation in the bandwidth parameters
h and its optimisation for each asset is clear. Further, in line with
Adrian et al. (
2015), we observed that the classical rolling window approach was always outperformed by the kernel ones.
Finally, increasing the sample size did not help to reduce the ; the smallest values were reached performing the analysis for the 55-portfolio sample, while the largest ones for the constituents of .
Table 6 presents a pairwise analysis using the
Diebold and Mariano (
1995) test, henceforth
, performed to certify the significance of the superior forecasting performance of the Gaussian kernel approach with a time-varying bandwidth. The
p-values of the
test were calculated under the null hypothesis that two competing models had the same predictive accuracy, while the alternative was that the two methods had significantly different levels of accuracy. The analysis was conducted for all the samples and methods. The results are very striking and indicate that the
test for the
Specific method were statistically significant at the
level, confirming the aforementioned results.
The key role of the time variation in the bandwidth parameter is also emphasized by the results of the method labelled
with respect to the
and
approaches. Here, the null hypothesis of no difference in terms of performance could not be rejected. In line with the literature, the
Fama and MacBeth (
1973) five-year rolling window approach was never preferred to the kernel regression method with
,
, or
. Instead, ambiguous results were produced for the relations between
and
, where the former was preferred only in those cases where
had
hs lower than 0.5, such as the 25 portfolios, with
. Such evidence was not unexpected given the nature and the characteristics of the
approach. Indeed, as
Table 1 shows, by increasing the sample size, the degree of smoothness increased, producing flatter estimates that performed well in a forecasting exercise.
Some further results on model comparisons and explanation of results are presented in
Table 7; it displays the correlations between the beta estimates generated by each different asset. The
approach is the method that produced less correlated estimates; the difference with respect the other methods is between 60% and 70%. This finding is robust in terms of changing sample and methods relatively to the choice of the bandwidth. Such results, together with the fact that the
approach provided small standard errors, let us solve two of the main critiques of the
Fama and MacBeth (
1973) method (error in variable problem and cross-sectional correlation), remaining agnostic on the choice of data between portfolios and individual stocks (see
Shanken (
1992) and
Adrian and Franzoni (
2005), among the others).
These findings extend the results obtained by
Adrian et al. (
2015) and are consistent with those obtained by
Ferson and Harvey (
1991), highlighting the importance of using not only a dynamic framework but also a dynamic estimation approach with minimal theoretical restriction.
5.1. Robustness Checks
A substantial number of robustness checks were performed to test the aforementioned findings. Full details are available in
Appendix C, where we report the
for each approach in terms of deviation from the benchmark
.
Firstly, we investigated the sensitivity of the results to the choice of bandwidth parameter range, originally set as
. Three alternative intervals were analysed:
,
and
. The results, reported in
Table A1, confirm that the
approach led to a reduction in
that oscillated between
and
for the 25- and 55-portfolio samples and between
and
for the constituents of
500.
Further, the awareness of possible overfitting issues due to the combination of sample size of the training period and the small value for the bandwidth parameters led us to also investigate the specification of the bandwidth parameter using a time-varying
approach inside the hierarchical methodology. After an accurate analysis for the choice of the penalization parameter, we decided to use values of
that allowed us to maintain the model unchanged
6 (
). The results, displayed in
Table A3, show that, by increasing the penalisation, we significantly increased the gain of the
technique, which resulted to be between
and
.
To avoid the possible presence of overfitting concerns,
Table A4 shows how changes in the size of training period affect the results. We investigated the results using ten years of data,
observations, and fifteen years of data,
observations.
Table A4 confirms that the
Specific outperformed the benchmark model and was the one with the highest reduction in
. In
Table A2, the analysis relatively to changing the sample period in order to exclude the global financial crisis is reported. The new sample tested was 1973–2007. The results confirm again that the
Specific approach outperformed its competitors.
Finally, since the goal of this paper is to propose a new estimation method to increase the forecasting performances of any asset pricing model, here, we consider different model specifications, namely, the momentum factor by
Carhart (
1997) and the five-factor model by
Fama and French (
2015).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





