
Kernel Regression Coefficients for Practical Significance


Abstract
:1. Introduction and Avoiding p-Hacking with Enhanced Regression Tools
Steps for Better Modeling Strategies
- A regression specification usually requires that the variables on the right-hand side are ‘exogenous’ and approximately cause the response on the left-hand side, see Koopmans (1950). One can check if all right-hand side variables are ‘causal’ in some sense by issuing the command causeSummBlk(mtx). If the output of this command says that the response variable might be causing a regressor, the model specification is said to suffer from the endogeneity problem. Careful choice of the model for response and regressors will require accepting uncertainty while remaining thoughtful (causal variables as regressors), open (to alternate specifications), and modest, (ATOM), as suggested by Wasserstein.
- Estimate the regression (1) with the usual p-values, t-statistics, and the using reg=lm(.);summary(reg) commands. The output allows one to rank regressors so that the regressor with the highest t-stat is statistically “most significant”.
- Standardize all variables by using the command scale(x). Regression with standardized variables forces the intercept to be zero. The coefficients of standardized OLS model are numerically comparable to each other. One can rank the absolute values of the standardized coefficients by their size so that the regressor with the highest magnitude is practically “most significant”.
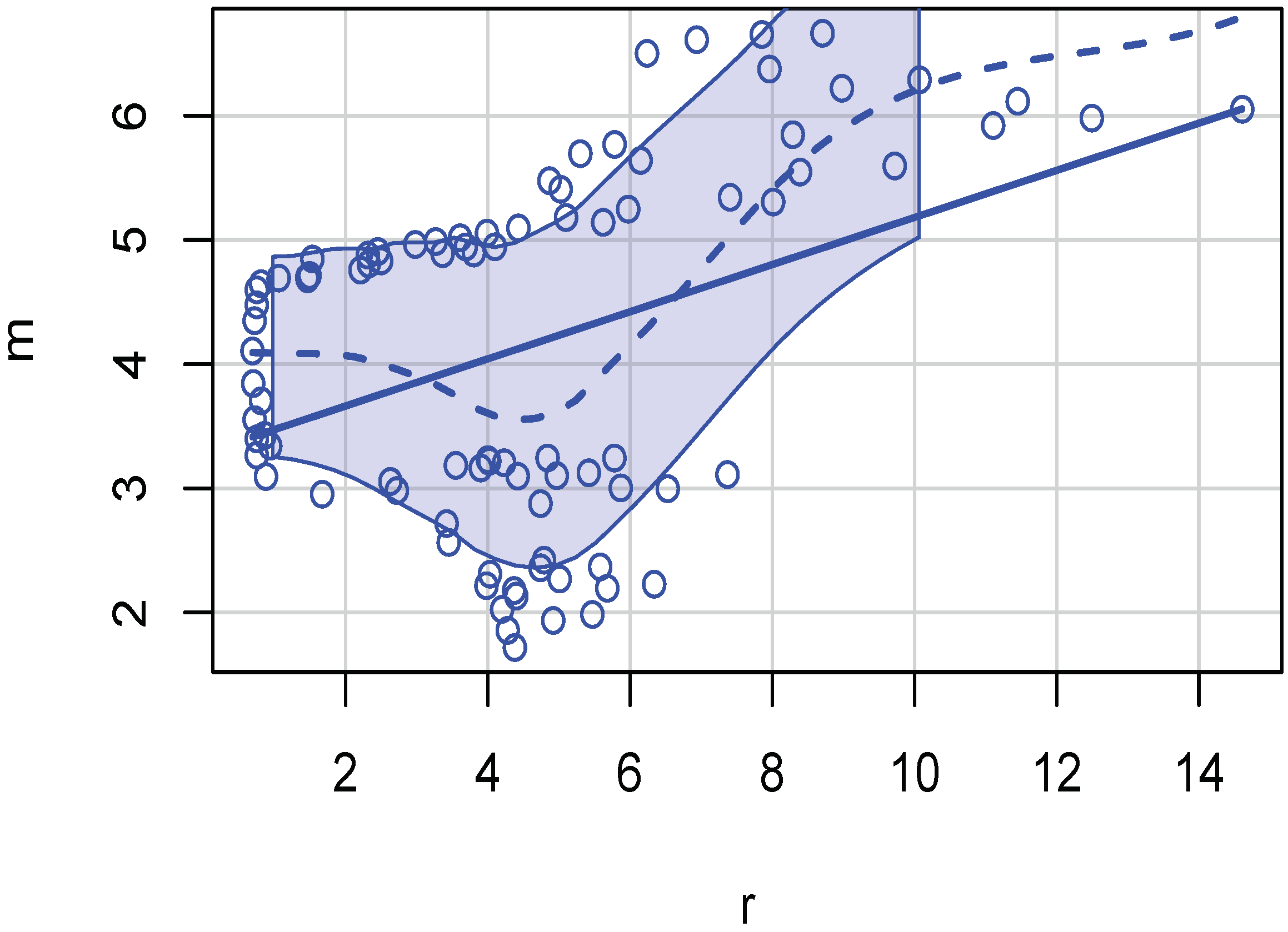
- Estimate the same regression (1) by kernel regression (using kern2()). It is necessary to use the argument gradients=TRUE to the function kern2. The output helps check how large the kernel regression is compared to the unadjusted of the linear regression. If the difference is large, we can conclude that non-linear relations will be more appropriate. Scatterplots illustrated in Figure 1 and Figure 2 reveal nonlinear relations. Then, one needs nonparametric kernel regressions and revised estimates of practical significance.
- If kernel regression is to be preferred (comparing two values) the commands, k2=kern2(.); apply(k2,2,mean), will produce a vector of approximate kernel regression coefficients. Alternative coefficients are produced by sudoCoefParcor(mtx).
- Estimate the GPCC of (15) using the R command parcorVec(mtx) to measure the practical significance of each regressor in a kernel regression. One can rank the absolute values of its output for assessing relative practical importance.
2. Application of Standardization and Kernels
2.1. Risk Management Cross-Section for Firm Performance
2.2. Macroeconomic Time Series Explaining Money Supply
3. Generalized Measures of Correlation and Matrix
4. Generalizing Partial Correlation and Standardized Beta Coefficients
5. Relation between Partial Correlations and Standardized Beta Coefficients
Hybrid GPCCs Are Useful When p Is Relatively Large
6. Pseudo-Regression Coefficients and Final Remarks
Funding
Data Availability Statement
Conflicts of Interest
References
- Anderson, Torben J. 2008. The performance relationship of effective risk management: Exploring the firm-specific investment rationale. Long Range Planning 41: 155–76. [Google Scholar] [CrossRef]
- Anderson, T. J., and O. Roggi. 2012. Strategic Risk Management and Corporate Value Creation. Presented at the Strategic Management Society 32nd Annual International Conference, SMS 2012, Prague, Czech Republic; Available online: https://research-api.cbs.dk/ws/portalfiles/portal/58853215/Torben_Andersen.pdf (accessed on 10 January 2022).
- Brodeur, Abel, Nikolai Cook, and Anthony Heyes. 2020. Methods matter: p-hacking and publication bias in causal analysis in economics. American Economic Review 110: 3634–60. [Google Scholar] [CrossRef]
- Goodman, S. N. 2019. Why is Getting Rid of P-Values So Hard? Musings on Science and Statistics. The American Statistician 73: 26–30. [Google Scholar] [CrossRef] [Green Version]
- Hirschauer, Norbert, Sven Gruner, Oliver Mushoff, Claudia Becker, and Antje Jantsch. 2021. Inference using non-random samples? stop right there! Significance 18: 20–24. [Google Scholar] [CrossRef]
- Kendall, Maurice, and Alan Stuart. 1977. The Advanced Theory of Statistics, 4th ed. New York: Macmillan Publishing Co., vol. 1. [Google Scholar]
- Khan, Asad, Muhammad Ibrahim Khan, and Niaz Ahmed Bhutto. 2020. Reassessing the impact of risk management capabilities on firm value: A stakeholders perspective. Journal of Management and Business 6: 81–98. [Google Scholar] [CrossRef] [Green Version]
- Koopmans, Tjalling C. 1950. When Is an Equation System Complete for Statistical Purposes. Technical Report. Yale University. Available online: https://cowles.yale.edu/sites/default/files/files/pub/mon/m10-all.pdf (accessed on 10 January 2022).
- Mouras, F., and A. Badri. 2020. Survey of the Risk Management Methods, Techniques and Software Used Most Frequently in Occupational Health and Safety. International Journal of Safety and Security Engineering 10: 149–60. [Google Scholar] [CrossRef]
- Raveh, Adi. 1985. On the use of the inverse of the correlation matrix in multivariate data analysis. The American Statistician 39: 39–42. [Google Scholar]
- Valaskova, K., T. Kliestik, L. Svabova, and P. Adamko. 2018. Financial Risk Measurement and Prediction Modelling for Sustainable Development of Business Entities Using Regression Analysis. Sustainability 10: 2144. [Google Scholar] [CrossRef] [Green Version]
- Vinod, H. D. 2021a. Generalized, partial and canonical correlation coefficients. Computational Economics 59: 1–28. [Google Scholar] [CrossRef]
- Vinod, H. D. 2021b. generalCorr: Generalized Correlations and Initial Causal Path. R package Version 1.2.0, Has 6 Vignettes. New York: Fordham University. [Google Scholar]
- Vinod, Hrishikesh D. 2017. Generalized correlation and kernel causality with applications in development economics. Communications in Statistics—Simulation and Computation 46: 4513–34. [Google Scholar] [CrossRef]
- Vinod, Hrishikesh D., and Fred Viole. 2018. Nonparametric Regression Using Clusters. Computational Economics 52: 1317–34. [Google Scholar] [CrossRef]
- Viole, Fred. 2021. NNS: Nonlinear Nonparametric Statistics, R Package Version 0.8.3; Available online: https://cran.r-project.org/package=NNS (accessed on 10 January 2022).
- Wasserstein, Ronald L., Allen L. Schirm, and Nicole A. Lazar. 2019. Moving to a world beyond p less than 0.05. The American Statistician 73: 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Shurong, Ning-Zhong Shi, and Zhengjun Zhang. 2012. Generalized measures of correlation for asymmetry, nonlinearity, and beyond. Journal of the American Statistical Association 107: 1239–52. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Estimate | Std. Error | t Value | Pr (>|t|) | |
|---|---|---|---|---|
| (Intercept) | −1.4327 | 1.4109 | −1.02 | 0.3107 |
| RMC | −0.1665 | 0.1665 | −1.00 | 0.3180 |
| Lev | −0.2624 | 0.0709 | −3.70 | 0.0003 |
| Sale | 4.0282 | 1.3209 | 3.05 | 0.0025 |
| PCost | −1.3925 | 0.3217 | −4.33 | 0.0000 |
| OCost | −0.1530 | 0.1236 | −1.24 | 0.2168 |
| RMCs | −0.0561 | 0.0560 | −1.00 | 0.3172 |
| Levs | −0.1997 | 0.0538 | −3.71 | 0.0002 |
| Sales | 0.1691 | 0.0553 | 3.05 | 0.0025 |
| PCosts | −0.2494 | 0.0575 | −4.34 | 0.0000 |
| OCosts | −0.0733 | 0.0592 | −1.24 | 0.2160 |
| Estimate | Std. Error | t Value | Pr (>|t|) | |
|---|---|---|---|---|
| (Intercept) | −0.5830 | 0.0933 | −6.25 | 0.0000 |
| p | 0.8090 | 0.0836 | 9.68 | 0.0000 |
| y | 1.1016 | 0.0725 | 15.20 | 0.0000 |
| r | −0.0715 | 0.0074 | −9.71 | 0.0000 |
| ps | 0.4491 | 0.0461 | 9.74 | 0.0000 |
| ys | 0.6255 | 0.0409 | 15.28 | 0.0000 |
| rs | −0.1479 | 0.0151 | −9.77 | 0.0000 |
| Cause | Response | Strength | Corr. | p-Value | |
|---|---|---|---|---|---|
| 1 | ROA | RMC | 100 | −0.0985 | 0.08815 |
| 2 | Lev | ROA | 31.496 | −0.1576 | 0.00615 |
| 3 | Sale | ROA | 12.598 | 0.2246 | 8 × 10 |
| 4 | ROA | PCost | 63.78 | −0.3008 | 0 |
| 5 | ROA | OCost | 31.496 | −0.1732 | 0.00257 |
| Cause | Response | Strength | Corr. | p-Value | |
|---|---|---|---|---|---|
| 1 | p | m | 100 | 0.9579 | 0 |
| 2 | m | y | 63.78 | 0.9905 | 0 |
| 3 | m | r | 37.008 | 0.3926 | 0.00013 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vinod, H.D. Kernel Regression Coefficients for Practical Significance. J. Risk Financial Manag. 2022, 15, 32. https://doi.org/10.3390/jrfm15010032
Vinod HD. Kernel Regression Coefficients for Practical Significance. Journal of Risk and Financial Management. 2022; 15(1):32. https://doi.org/10.3390/jrfm15010032
Chicago/Turabian StyleVinod, Hrishikesh D. 2022. "Kernel Regression Coefficients for Practical Significance" Journal of Risk and Financial Management 15, no. 1: 32. https://doi.org/10.3390/jrfm15010032
APA StyleVinod, H. D. (2022). Kernel Regression Coefficients for Practical Significance. Journal of Risk and Financial Management, 15(1), 32. https://doi.org/10.3390/jrfm15010032