
Bankruptcy Prediction Using Machine Learning Techniques

Abstract
:1. Introduction
2. Data and Methodology
2.1. Data
2.2. Methodology
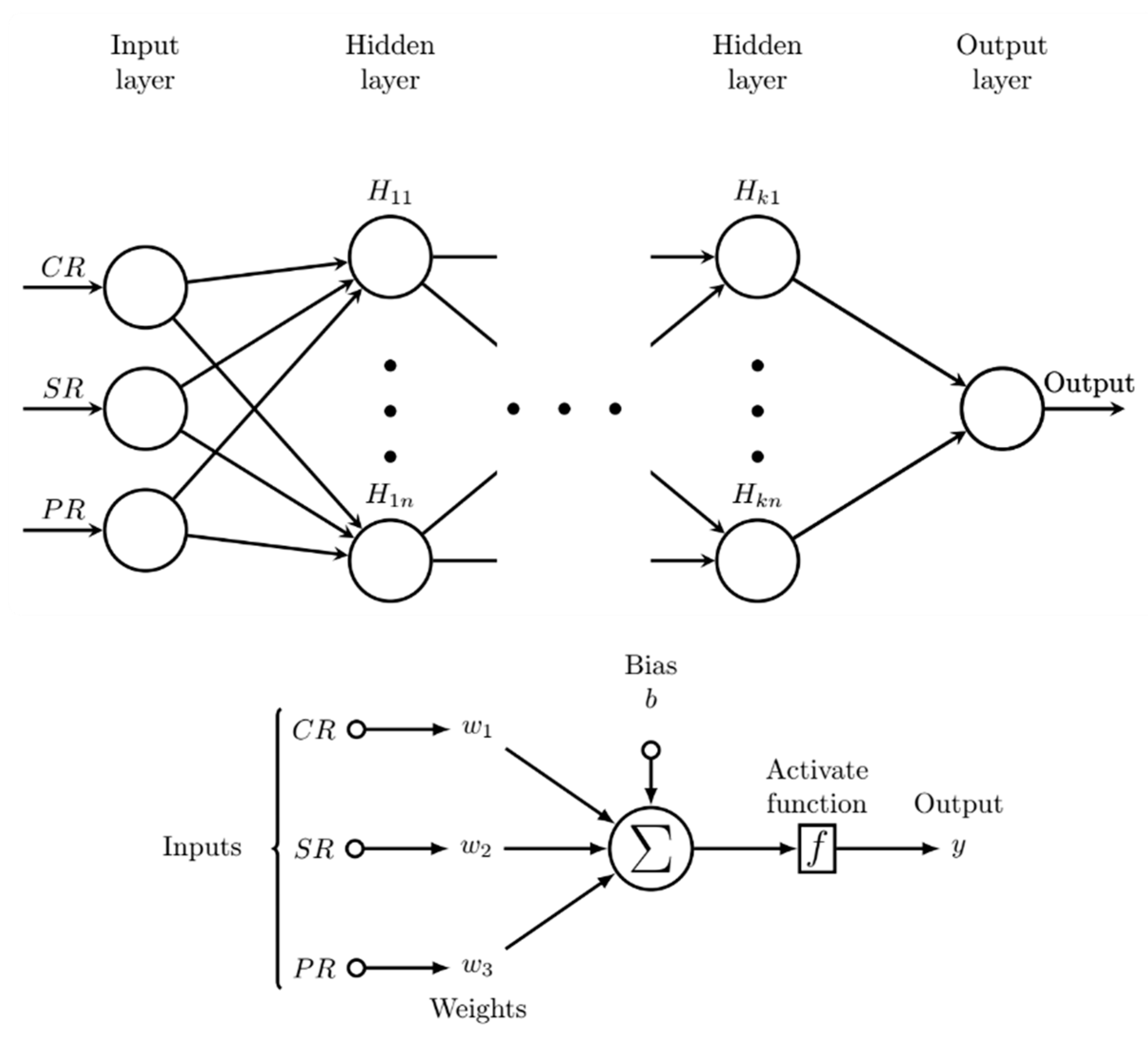
2.2.1. Deep Feedforward Neural Networks
2.2.2. Support Vector Machine (SVMs)
2.2.3. Extreme Gradient Boosting
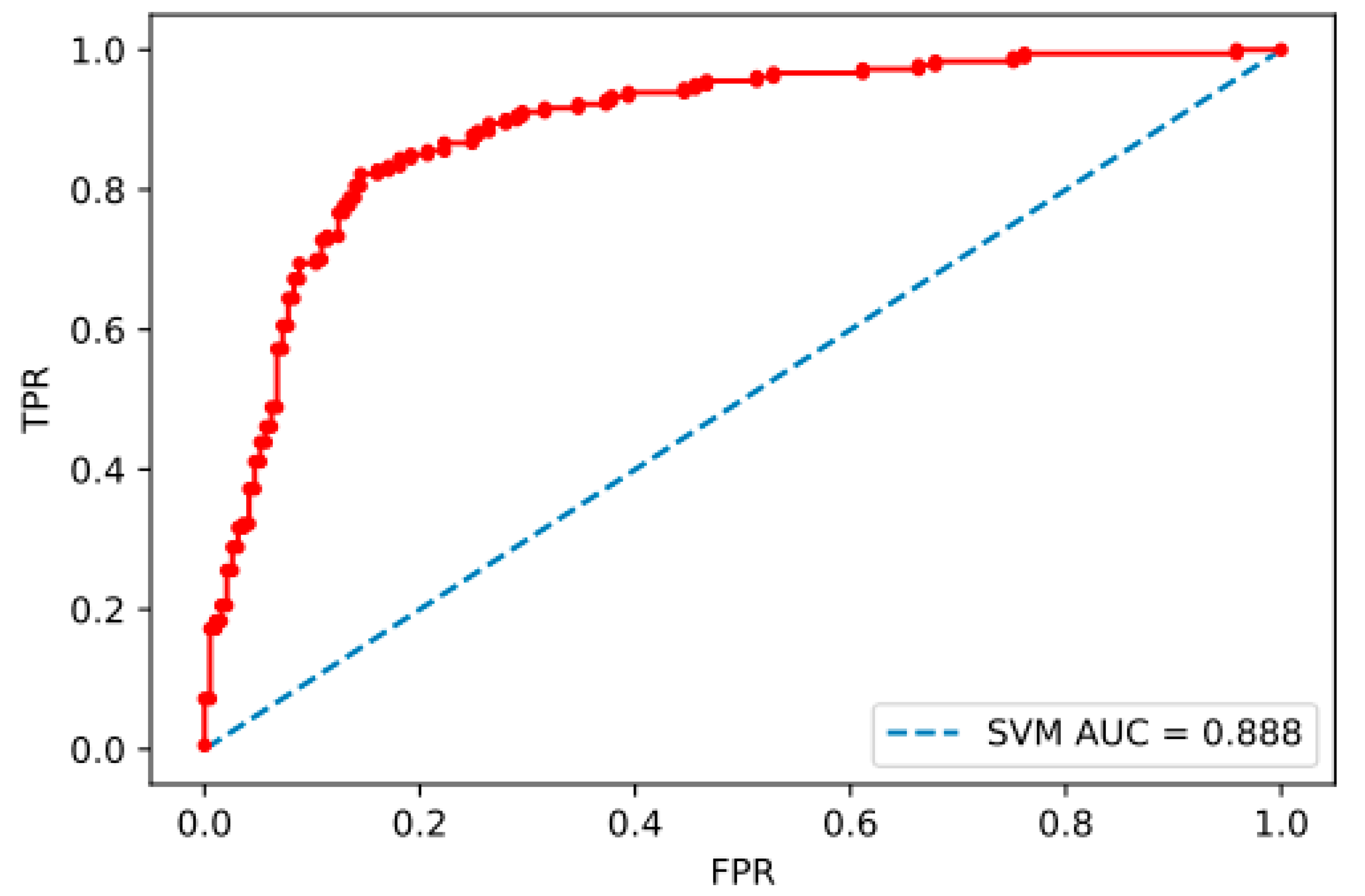
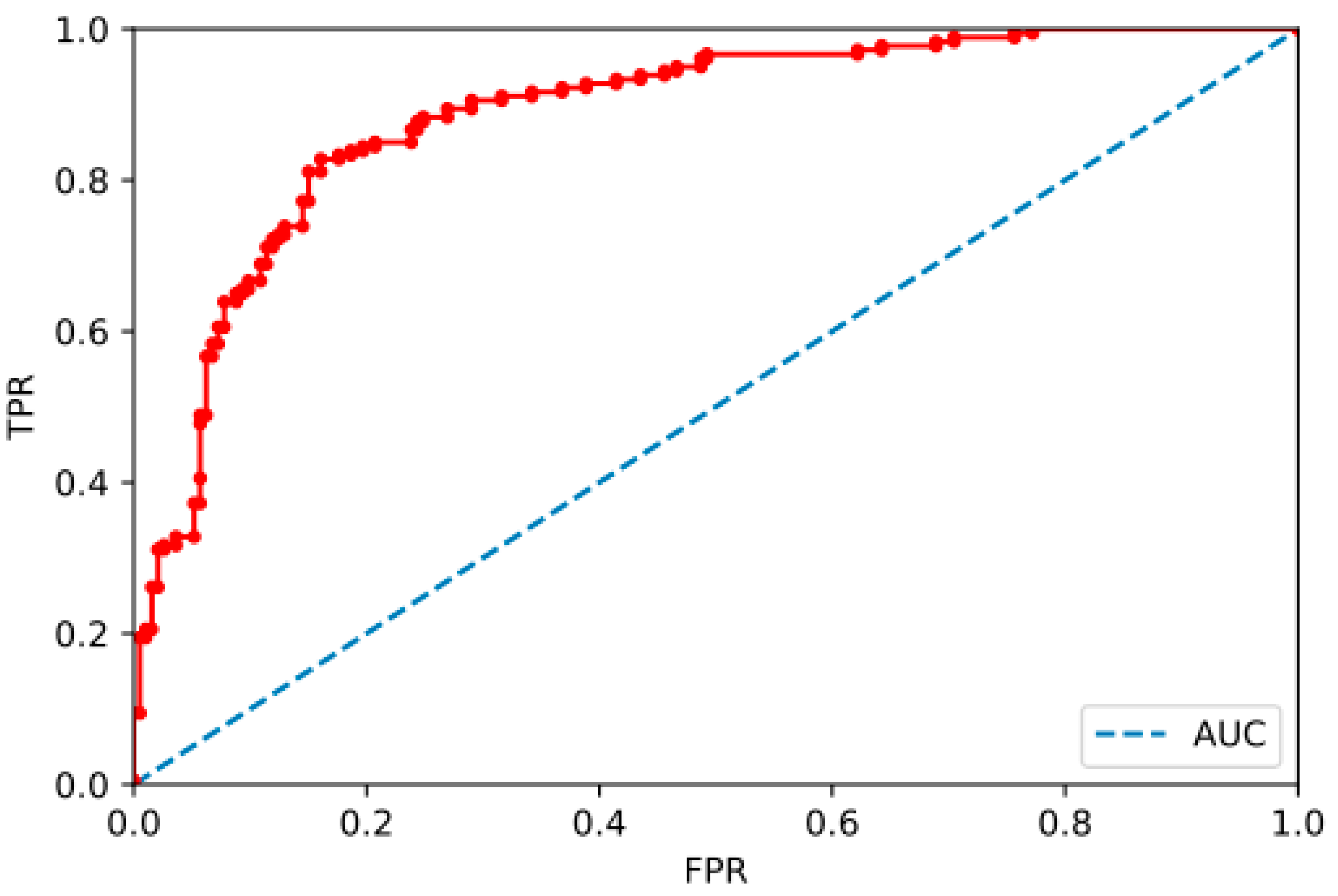
3. Results
Accuracy Comparisons of Different Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
| 1 | Least Absolute Shrinkage and Selection Operator. |
References
- Abe, Shigeo. 2005. Support Vector Machines for Pattern Classification. London: Springer. [Google Scholar]
- Adnan, Aziz, and Humayon Dar. 2006. Predicting corporate bankruptcy: Where we stand? Corporate Governance 6: 18–33. [Google Scholar] [CrossRef] [Green Version]
- Altman, Edward. 1968. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. Journal of Finance 23: 589–609. [Google Scholar] [CrossRef]
- Altman, Edward, Haldeman Robert, and Paul Narayanan. 1977. ZETA analysis A new model to identify bankruptcy risk of corporations. Journal of Banking & Finance 1: 24–54. [Google Scholar]
- Baldwin, Jane, and William Glezen. 1992. Bankruptcy Prediction Using Quarterly Financial Statement Data. Journal of Accounting, Auditing and Finance 7: 269–85. [Google Scholar] [CrossRef]
- Barboza, Flavio, Herbert Kimura, and Edward Altman. 2017. Machine learning models and bankruptcy prediction. Experts System with Applications 83: 405–17. [Google Scholar] [CrossRef]
- Beaver, William. 1966. Financial Ratios as Predictors of Failure. Journal of Accounting Research, Empirical Research in Accounting 4: 71–111. [Google Scholar]
- Boser, Bernhard, Isabelle Guyon, and Vladimir Vapnik. 1992. A training algorithm for optimal margin classifiers. In COLT ‘92: Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. New York: ACM, pp. 144–52. [Google Scholar]
- Brédart, Xavier. 2014. Bankruptcy Prediction model using Neural networks. Accounting and Finance Research 3: 124–28. [Google Scholar] [CrossRef]
- Brédart, Xavier, and Loredana Cultrera. 2016. Bankruptcy prediction: The case of Belgian SMEs. Review of Accounting and Finance 15: 101–19. [Google Scholar]
- Campbell, John, Jens Hilscher, and Jan Szilagyi. 2008. In search of distress risk. The Journal of Finance 63: 2899–939. [Google Scholar] [CrossRef] [Green Version]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. In KDD ’16 Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. New York: ACM, pp. 785–94. [Google Scholar]
- Ciampi, Francesco. 2015. Corporate governance characteristics and default prediction modeling for small enterprises. An empirical analysis of Italian firms. Journal of Business Research 68: 1012–25. [Google Scholar]
- Cortes, Corinna, and Vladimir Vapnik. 1995. Support-Vector Networks. Machine Learning 20: 273–97. [Google Scholar] [CrossRef]
- Deakin, Edward. 1972. A Discriminant Analysis of Predictors of Business Failure. Journal of Accounting Research 10: 167–79. [Google Scholar] [CrossRef]
- du Jardin, Philippe. 2006. Bankruptcy prediction models: How to choose the most relevant variables? Bankers, Markets & Investors 98: 39–46. [Google Scholar]
- du Jardin, Philippe. 2015. Bankruptcy prediction using terminal failure processes. European Journal of Operational Research 242: 286–303. [Google Scholar] [CrossRef]
- Edmister, Robert. 1972. An Empirical Test of Financial Ratio Analysis for Small Business Failure Prediction. Journal of Financial and Quantitative Analysis 7: 1477–93. [Google Scholar] [CrossRef]
- Fan, Jianqing, and Runze Li. 2001. Variable Selection via Nonconcave Penalized Likelihood and Its Oracle Properties. Journal of American Statistical Association 96: 1348–60. [Google Scholar] [CrossRef]
- Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. 2016. Deep Learning. Boston: MIT Press. [Google Scholar]
- Grice, John Stephen, and Robert Ingram. 2001. Tests of the Generalizability of Altman’s Bankruptcy Prediction Model. Journal of Business Research 54: 53–61. [Google Scholar] [CrossRef]
- Hosaka, Tadaaki. 2019. Bankruptcy prediction using imaged financial ratios and convolutional neural neworks. Expert Systems with Applications 117: 287–99. [Google Scholar] [CrossRef]
- Kearns, Michael, and Leslie Valiant. 1989. Crytographic [sic] limitations on learning Boolean formulae and finite automata. Symposium on Theory of Computing 21: 433–44. [Google Scholar] [CrossRef]
- Lennox, Clive. 1999. Identifying failing companies: A revaluation of the logit, probit and da approaches. Journal of Economics and Business 51: 347–64. [Google Scholar] [CrossRef]
- Laitinen, Erkki. 1991. Financial Ratios and Different Failure Processes. Journal of Business Finance & Accounting 18: 649–73. [Google Scholar]
- Mai, Feng, Shaonan Tian, Chihoon Lee, and Ling Ma. 2018. Deep learning models for bankruptcy prediction using textual disclosures. European Journal of Operational Research 274: 743–58. [Google Scholar] [CrossRef]
- Meir, Lukas, Sara Van de Geer, and Peter Bühlmann. 2008. The group lasso for logistic regression. Journal of Royal Statistical Society 70: 53–71. [Google Scholar] [CrossRef] [Green Version]
- Ohlson, James. 1980. Financial Ratios and the Probabilistic Prediction of Bankruptcy. Journal of Accounting Research 18: 109–31. [Google Scholar] [CrossRef] [Green Version]
- Pompe, Paul, and Jan Bilderbeek. 2005. Bankruptcy prediction: The influence of the year prior to failure selected for model building and the effects in a period of economic decline. Intelligent Systems in Accounting, Finance and Management 13: 95–112. [Google Scholar] [CrossRef]
- Reznakova, Maria, and Michal Karas. 2014. Bankruptcy Prediction Models: Can the Prediction Power of the Models be Improved by Using Dynamic Indicators? Procedia Economics and Finance 12: 565–74. [Google Scholar] [CrossRef]
- Schapire, Robert. 1990. The Strength of Weak Learnability. Machine Learning 5: 197–227. [Google Scholar] [CrossRef] [Green Version]
- Schapire, Robert. 1999. A Brief Introduction to Boosting. International Joint Conference on Artificial Intelligence 99: 1401–6. [Google Scholar]
- Sfakianakis, Evangelos. 2012. Bankruptcy prediction model for listed companies in Greece. Investment Management and Financial Innovations 18: 166–80. [Google Scholar] [CrossRef]
- Shi, Yin, and Xiaoni Li. 2019. An overview of bankruptcy prediction models for corporate firms: A systematic literature review. Intangible Capital 15: 114–27. [Google Scholar] [CrossRef] [Green Version]
- Shin, Kyung-Shik, and Yong-Joo Lee. 2002. A genetic algorithm application in bankruptcy prediction modeling. Expert Systems with Applications 23: 321–28. [Google Scholar] [CrossRef]
- Tang, Tseng-Chung, and Li-Chiu Chi. 2005. Neural networks analysis in business failure prediction of Chinese importers: A between-countries approach. Expert Systems with Applications 29: 244–55. [Google Scholar] [CrossRef]
- Tian, Shaonan, Yan Yu, and Hui Guo. 2015. Variable selection and corporate bankruptcy forecasts. Journal of Banking & Finance 52: 89–100. [Google Scholar]
- Tobback, Ellen, Tony Bellotti, Julie Moeyersoms, Marija Stankova, and David Martens. 2017. Bankruptcy prediction for SMEs using relational data. Decision Support Systems 102: 69–81. [Google Scholar] [CrossRef] [Green Version]
- Wang, Zheng. 2004. Financial ratio selection for default-rating modeling: A model-free approach and its empirical performance. Journal of Applied Finance 14: 20–35. [Google Scholar]
- Zavgren, Christine. 1985. Assessing the vulnerability to failure of American industrial firms: A logistic analysis. Journal of Business Finance and Accounting 12: 19–45. [Google Scholar] [CrossRef]
- Zmijewski, Mark. 1984. Methodological Issues Related to the Estimation of Financial Distress Prediction Models. Journal of Accounting Research 22: 59–86. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Current Ratio | Return of Oper. Assets b4 Amort. | Age(y) | Solvency Ratio | Logta | |
|---|---|---|---|---|---|
| Current ratio | 1.000000 | 0.124021 | 0.098749 | 0.342709 | 0.102001 |
| Return of oper. assets b4 amort. | 0.124021 | 1.000000 | −0.013334 | 0.329617 | 0.059690 |
| Age(yrs) | 0.098749 | −0.013334 | 1.000000 | 0.232606 | 0.288841 |
| Solvency ratio | 0.342709 | 0.329617 | 0.232606 | 1.000000 | 0.210868 |
| Logta | 0.102001 | 0.059690 | 0.288841 | 0.210868 | 1.000000 |
| Method | Class/Total | Precision | Recall | f1-Score |
|---|---|---|---|---|
| Neural Net | 0 | 85 | 79 | 82 |
| 1 | 79 | 82 | 82 | |
| Total | 82 | 81 | 82 | |
| SVM | 0 | 85 | 81 | 83 |
| 1 | 80 | 84 | 82 | |
| Total | 83 | 83 | 83 | |
| XGBoost | 0 | 84 | 81 | 83 |
| 1 | 81 | 82 | 83 | |
| Total | 83 | 82 | 83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shetty, S.; Musa, M.; Brédart, X. Bankruptcy Prediction Using Machine Learning Techniques. J. Risk Financial Manag. 2022, 15, 35. https://doi.org/10.3390/jrfm15010035
Shetty S, Musa M, Brédart X. Bankruptcy Prediction Using Machine Learning Techniques. Journal of Risk and Financial Management. 2022; 15(1):35. https://doi.org/10.3390/jrfm15010035
Chicago/Turabian StyleShetty, Shekar, Mohamed Musa, and Xavier Brédart. 2022. "Bankruptcy Prediction Using Machine Learning Techniques" Journal of Risk and Financial Management 15, no. 1: 35. https://doi.org/10.3390/jrfm15010035
APA StyleShetty, S., Musa, M., & Brédart, X. (2022). Bankruptcy Prediction Using Machine Learning Techniques. Journal of Risk and Financial Management, 15(1), 35. https://doi.org/10.3390/jrfm15010035