1. Introduction
Empirical studies have found in the return of various financial instruments skewness and leptokurtotic—asymmetry, and higher peak around the mean with fat tails. Normal distribution has long been recognized as insufficient to accommodate these stylized facts, relying on which could drastically underestimate the tail risk of a portfolio. The
-stable distribution is a candidate to incorporate this fact into decision-making, but its lack of finite moments could cause difficulties in modeling. The class of tempered stable distributions serves as a natural substitution, since it has finite moments while retaining many attractive properties of the
-stable distribution. The class of tempered stable distributions is derived by tempering the tails of the
-stable distribution (See
Koponen 1995;
Boyarchenko and Levendorskiĭ 2000; and
Carr et al. 2002), or from the time changed Brownian motion. Since
Barndorff-Nielsen and Levendorskii (
2001) and
Shephard et al. (
2001) presented the normal tempered stable (NTS) distribution in finance using the time changed Brownian motion, it has been successfully applied for modeling the stock returns with high accuracy in literature including
Kim et al. (
2012),
Kurosaki and Kim (
2018),
Anand et al. (
2016) and
Kim (
2022).
Deviation from normality exists not only in raw returns, but also in filtered innovations of time series models. Since the foundational work in
Engle (
1982) and
Bollerslev (
1986), GARCH model has been widely applied to model volatility. This motivates us to use NTS distribution to accommodate the asymmetry, interdependence, and fat tails of the innovations of GARCH models. Several studies have found NTS distribution to be more favorable than other candidates.
Kim et al. (
2011) found that normal and
-distribution are rejected as innovation of GARCH model in hypothesis testing.
Shi and Feng (
2016) found that tempered stable distribution with exponential tempering yields better calibration of Markov Regime-Switching (MRS) GARCH model than
or generalized error distribution. Generalized hyperbolic distribution, while very flexible, has too many parameters for estimation. NTS distribution has only three standardized parameters and is flexible enough to serve the purpose.
A drawback of GARCH model is the inadequate ability in modeling volatility spikes, which could indicate that the market is switching within regimes. Various types of MRS-GARCH models have been proposed, many of which suggest that the regime-switching GARCH model achieves a better fit for empirical data (for example, in
Hamilton 1996).
Marcucci (
2005) finds that MRS-GARCH models outperform standard GARCH models in volatility forecasting in a time horizon shorter than one week. Naturally, the most flexible model allows all parameters to switch among regimes. However, as is shown in
Henneke et al. (
2011), the sampling procedure in the MCMC method for estimating such a model is time-consuming and renders it improper for practical use. We construct a new model based on the regime-switching GARCH model specified in
Haas et al. (
2004), which circumvents the path dependence problem in the Markov Chain model by specifying parallel GARCH models.
Bollerslev (
1990) proposes the GARCH model with constant conditional correlation. The parsimonious DCC-GARCH model in
Engle (
2002) opens the door to modeling multivariate GARCH process with different persistence between variance and correlation. While flexible models allowing time-varying correlation are preferred in many cases, specification of multivariate GARCH models with both regime-specific correlations and variance dynamics involves a balance between flexibility and tractability. The univariate MRS-GARCH model in
Haas et al. (
2004) is generalized in
Haas and Liu (
2004) to a multivariate case. Unfortunately, it suffers from the curse of dimensionality, and thus is unsuitable for a high dimensional empirical study. In our model, we decompose variance and correlation so that the variance of each asset evolves independently according to a univariate MRS-GARCH model. The correlation is incorporated in the innovations modeled by a flexible Hidden Markov Model (HMM) that has multivariate NTS distribution as the conditional distribution in each regime. We will use the calibrated model to simulate returns for portfolio optimizations.
Modern portfolio theory is formulated as a trade-off between return and risk. The classical Markowitz Model finds the portfolio with the highest Sharpe ratio. However, variance has been criticized for not containing enough information on the tail of the distribution. Moreover, correlation is not sufficient to describe the interdependence of asset returns with non-elliptical distribution. Current regulations for financial business utilize the concept of Value at Risk (VaR), which is the percentile of the loss distribution, to model the risk of left tail events. There are several undesired properties that rendered it an insufficient criterion. First, it is not a coherent risk measure due to a lack of sub-additivity. Second, VaR is a non-convex and non-smooth function of positions with multiple local extrema for non-normal distributions, which causes difficulty in developing efficient optimization techniques. Third, a single percentile is insufficient to describe the tail behavior of a distribution, and thus might lead to an underestimation of risk.
Theory and algorithm for portfolio optimization with a conditional value-at-risk (CVaR) measure proposed in
Krokhmal et al. (
2001) and
Rockafellar and Uryasev (
2000) effectively addresses these problems. For continuous distributions, CVaR is defined by a conditional expectation of losses exceeding a certain VaR level. For discrete distributions, CVaR is defined by a weighted average of some VaR levels that exceed a specified VaR level. In this way, CVaR concerns both VaR and the losses exceeding VaR. As a convex function of asset allocation, a coherent risk measure and a more informative statistic, CVaR serves as an ideal alternative to VaR. A study on the comparison of the two measures can be found in
Sarykalin et al. (
2014).
Another closely related tail risk measure is conditional drawdown-at-risk (CDaR). Drawdown has been a constant concern for investors and is often used in the performance evaluation of a portfolio. It is much more difficult to climb out of a drawdown than drop into one, considering that it takes 100% return to recover from 50% relative drawdown. In behavioral finance, it is well documented that investors fear losses more than they value gains. However, the commonly used maximum drawdown only considers the worst scenario that only occur under some very special circumstances, and thus is very sensitive to the testing period and asset allocation. On the other hand, small drawdowns included in the calculation of average drawdown are acceptable and might be caused by pure noise, of which the minimization might result in overfitting. For instance, a Brownian motion would have drawdowns in a simulated sample path.
CDaR is proposed in
Checkhlov et al. (
2004) to address these concerns. While CVaR is determined by the distribution of return, CDaR is path-dependent. CDaR is essentially CVaR of the distribution of drawdowns. By this, we overcome the drawbacks of average drawdown and maximum drawdown. CDaR takes not only the depth of drawdowns into consideration, but also the length of them. Since the CDaR risk measure is the application of CVaR in a dynamic case, it naturally holds nice properties of CVaR, such as convexity with respect to asset allocation. The optimization method with constraints on CDaR has also been developed and studied in
Checkhlov et al. (
2004,
2005).
An optimization procedure could lead to an underperformed portfolio by magnifying the estimation error. Using historical sample paths as input implies an assumption that what happened in the past will happen in the future, which requires careful examination. It is found in
Lim et al. (
2011) that estimation errors of CVaR and the mean is large, resulting in unreliable allocation. An alternative way is to use multiple simulated returns. It is reasonable to expect outperformance during a crisis if we use the simulation of a model that captures extreme tail events as input for optimization with tail risk measures. Relevant research that resorts to copula does not address a regime switch (See
Sahamkhadam et al. 2018).
We have identified several issues in GARCH-simulation-based portfolio optimization: deviation from normality, regime switch, high dimensional calibration and tail risk measures. This paper intends to address these issues in one shot. First, we propose the MRS-MNTS-GARCH model to accommodate fat tails, volatility clustering and regime switch. In the model, the volatility of each asset independently follows a regime-switch GARCH model, while the correlation of joint innovation of GARCH models follows a Hidden Markov Model. We specify the method for efficient model calibration. The MRS-MNTS-GARCH model is used to simulate sample paths. Then, the sample paths are used as input to portfolio optimization with tail risk measures CVaR and CDaR. We conduct in-sample tests sow show the goodness-of-fit. We conduct out-of-sample tests to show the outperformance of our approach in various measures. The optimal portfolios are also more robust to suboptimality of the optimization. The results suggest that, in practice, performance ratios can be improved compared to equally weighted portfolio by adopting simulation-based portfolio optimization with the MRS-MNTS-GARCH model. The empirical study suggests that using tail risk measures outperforms using standard deviation in terms of various performance measures and robustness.
The remainder of the paper is organized as follows.
Section 2 introduces the preliminaries on NTS distribution and GARCH model.
Section 3 specifies our model and methods for estimation and simulation.
Section 4 introduces the portfolio optimization with tail risk measures.
Section 5 is an empirical study on in-sample goodness-of-fit and out-of-sample performance in recent years.
2. Preliminaries
This section reviews the background knowledge on different risk measures, scenario-based estimation, normal tempered stable (NTS) distribution, and GARCH and regime-switching GARCH model.
2.1. Tail Risk Measures
In this subsection, we discuss and summarize popular tail risk measures in finance such as Value at Risk (VaR), Conditional VaR (CVaR), and conditional drawdown-at-risk (CDaR). Definitions of CDaR, and related properties of drawdown are following
Checkhlov et al. (
2004,
2005).
Consider a probability space
and a portfolio with
N assets. Suppose that
is a stochastic process of a price for the
n-th asset in the portfolio on the space
with the real initial value
.
The stochastic process of the compounded return of the
n-th asset between time 0 to time
is defined by
with
. Then, the compounded portfolio return
at time
is equal to
The definition of VaR for
with the confidence level
is
If
has a continuous cumulative distribution, then we have
where
is the inverse cumulative distribution function of
. The definition of CVaR for
with the confidence level
is
Equivalently, CVaR can be obtained by a minimization formula
Following
Checkhlov et al. (
2004), denote the uncompounded return of the
n-th asset by
. The uncompounded portfolio return is defined by
Let
, and
, then
is one sample path of portfolio return with the capital allocation vector
x from time 0 to
T. The drawdown
of the portfolio return is defined by
is a risk measure assessing the decline from a historical peak in some variable, and
is a stochastic process of the drawdown. The average drawdown (ADD) up to time
T for
is defined by
It is the time average of drawdowns observed between time 0 to
T. The maximum drawdown (ADD) up to time
T for
is defined by
It is the maximum of drawdowns that have occurred up to time T for .
According to
Checkhlov et al. (
2005), the CDaR is defined as the CVaR of drawdowns. Applying (
1) to drawdowns, we have
It can also be represented as
Note that and .
Considering all the sample path
, we define CDaR at
by
2.2. Scenario-Based Estimation
In this subsection, we discuss the risk estimation using given scenarios (historical scenario or simulation). Suppose that the time interval
is divided by a partition
, and denote
We select
where
and
S is the number of scenarios. Then, we obtain scenarios of the portfolio return process
at time
:
where
, and
. We calculate VaR, CVaR, DD, and CDaR under the simulated scenarios. The VaR with significant level
under the simulated scenario is estimated by
Let
be the
k-th smallest value in
, then CVaR at the significant level
is estimated according to the formula
where
denotes the smallest integer larger than
x (See
Rachev et al. 2008 for details).
The rate of return of the
n-th asset between time
and time
is defined by
with
. It is referred to as return in this paper. Let
be a capital allocation vector of a long-only portfolio satisfying
and
for all
. Then, the portfolio return
between time
and time
is
The scenario-based estimation on uncompounded cumulative return at time
is
Denote
by
. Using (
2)–(
4), DD, ADD, and MDD on a single simulated scenario are estimated, respectively, by
Furthermore, using (
5)–(
7), CDaR is estimated on a single simulated scenario by
where
with
Equivalently, it is estimated by the optimization formula
With (
8)–(
10), DD and CDaR on multiple scenarios are estimated by
and
respectively, where
and
In this paper, we will apply time series models to generate the scenario of for , and .
2.3. Multivariate Normal Tempered Stable Distribution
Let
be a strictly positive random variable defined by the characteristic function for
and
Then,
is referred to as a tempered stable subordinator with parameters
and
. Suppose that
is a
N-dimensional standard normal distributed random vector with a
covariance matrix
, i.e.,
. The
N-dimensional NTS distributed random vector
is defined by
where
,
,
and
is independent of
. The
N-dimensional multivariate NTS distribution specified above is denoted by
Let
, and
,
for
. This yields a random variable having zero mean and unit variance. In this case, the random variable is referred to as
standard NTS distributed random variable and denoted by
. The covariance matrix of
X is given by
2.4. Regime-Switching GARCH Model
GARCH(
) model has been studied extensively as a model for volatility.
where
is the return at time
t,
is the variance at time
t,
are parameters. We will use GARCH(1,1) in this paper.
Before specifying our model, it would be clear to first specify the univariate Markov regime-switching model in
Haas et al. (
2004) as follows
where
number of regimes in a Markov chain;
Markov chain with an irreducible and primitive transition matrix that determines the regime at time t;
return at time t;
vector of parallel variance;
, , . , , are vectors of coefficients;
regime specific mean return in regime at time t;
the standard deviation in regime at time t;
∘ denotes element-wise product.
There are k parallel GARCH models evolving simultaneously. The Markov chain determines which GARCH model is realized at next moment.
To better understand (
17), let us create the following matrix
Each column is a total of k parallel standard deviations at time t. Each row is the process of one regime through time 1 to T. The process of standard deviation is generated as follows:
Step 1: At , the initial column is generated.
Step 2: decides which row is realized.
For example, suppose . That is, is realized in real-world at .
Step 3: By vector calculation, 2nd column is generated.
For example, suppose
is realized at
. We calculate
Step 4: Decides which row is realized.
For example, suppose . That is, is realized in real world at . A regime switch from regime 2 to regime 1 takes place.
Step 5: Repeat Step 1 to Step 4.
It is important to note that in the example, the realized variance at time , , is calculated with both the realized variance at time , , and unrealized . This is obvious from the vector equation shown above. is in the parallel process and is not realized in real world.
More generally, when there is a regime switch, from the vector equation
, we know that the variance
is determined by
rather than
.
is a variance in regime
at time
t, which is generated simultaneously with
, but does not exist in reality at time
t or
. This makes the model different from the one in
Henneke et al. (
2011) that requires all parameters to switch regime according to a Markov chain. In that model, there is no parallel process, and
is determined by
.
The stationary conditions derived in
Haas et al. (
2004) require definitions of the matrices:
and the block matrix
The necessary and sufficient condition for stationarity is , where denotes the largest eigenvalue of matrix M.
3. MRS-MNTS-GARCH Model
This section defines the MRS-MNTS-GARCH model and introduces the procedures for model fitting and sample path simulation.
3.1. Model Specification
To model a multivariate process, we assume that the variance of each individual asset evolves independently according to the univariate regime-switching GARCH model specified previously with possibly different number of regimes, while the correlation between assets is modeled separately by stdMNTS distribution in the joint standard innovations. The joint innovations is defined bya HMM with stdMNTS as conditional distribution in each regime.
The MRS-MNTS-GARCH model is defined by
where
number of assets;
number of regimes of the i-th asset;
Markov chain with an irreducible and primitive transition matrix that determines the regime of the i-th asset at time t;
realization of at time t;
Markov chain with an irreducible and primitive transition matrix that determines the regime of the joint innovations at time t;
realization of at time t;
vector return of N assets at time t;
vector mean return at time t;
mean return of the i-th asset at time t, is determined by the regime of the i-th asset at time t, ;
vector of standard deviation of N assets at time t;
standard deviation vector of the i-th asset with ;
the i-th element of , with ;
, , . , , are the vector of coefficients of the i-th asset in regimes;
joint innovations;
∘ denotes element-wise product.
For each asset, the volatility process is the same as that of the univariate regime-switching GARCH model in (
17). It is a classical GARCH process when it does not shift within regimes. Unlike the most flexible model in which the variance at time
t is calculated with the variance at time
in the last regime, when a regime shift takes place at time
t, the variance in the model at time
t is determined by the variance at time
within the new regime. The regimes of each asset and joint innovations evolve independently, mitigating the difficulty in estimation caused by all parameters switching regimes simultaneously.
3.2. Parameter Estimation
Although NTS distribution is flexible enough to accommodate many stylized facts of asset return, the absence of an analytical density function presents some difficulties in estimation. Our estimation methodology is adapted from
Kim et al. (
2011,
2012), which are among the first works to incorporate NTS distribution in portfolio optimization. Another estimation of stdMNTS distribution with EM algorithm combined with fast Fourier transform is studied in
Bianchi et al. (
2016). Below we describe the procedure to fit the model.
First, we fit the univariate Markov regime-switching GARCH model with t innovation on the index return and extract the innovations and the regimes at each time t, . It is intuitive to assume that the correlation between assets change drastically when a market regime shift takes place. Thus, here we assume that the Markov chain that determines the regime of innovations is the same as the Markov chain that determines the regime of the market index. That is, the sample path of the regime of the innovation is derived by extracting the sample path of the regime of the market index. The innovations of the model calibrated by the market index are used to estimate tail parameters in each regime.
Next, we fit the univariate model on each asset and extract the innovations for subsequent estimation of stdMNTS distribution. In each regime, the stdMNTS distribution has two tail parameters and one skewness parameter vector . Common tail parameters are assumed for individual constituents, which are estimated from the market index in each regime. The skewness parameter is calibrated by curve fitting for each asset.
Finally, we plug the empirical covariance matrix of the innovations in each regime
in the formula
to compute
. Note that
is supposed to be a positive definite matrix. To guarantee this, we can either substitute
with the closest vector to
in
norm which renders
positive definite matrix, or directly find the closest positive definite matrix to
. We choose the second method. Furthermore, the usual issue of estimating covariance matrix arises here as well, especially when a regime only has a short lasting period. To address this issue, we apply the denoising technique in
Laloux et al. (
1999) on the positive definite matrix derived earlier to estimate
.
The number of regimes of each asset is set as equal to that of the market index. We find that univariate Markov switching model with more than three regimes often has one unstable regime that lasts for a very short period and switches frequently and sometimes has one regime with clearly bimodal innovations distribution. Thus, it is desirable to limit the number of regimes smaller than 4, check unimodal distribution with Dip test and choose the one with the highest BIC value.
The procedure is summarized as follows.
Step 1: Fit the univariate Markov regime-switching GARCH model with t innovation on the index return and extract the innovations and the sample path of regimes.
Step 2: Estimate common tail parameters in each regime.
Step 3: Fit univariate model on each asset and extract the innovations.
Step 4: Estimate skewness parameters for assets in each regime, calculate .
Step 5: Calculate the matrix , find the closest positive definite matrix and apply the denoising technique to estimate .
3.3. Simulation
To conduct simulation with the calibrated model, we follow the procedures specified below.
Step 1: Simulate S sample paths of standard deviation of N assets for T days with the fitted model.
Step 2: Simulate S sample paths of a Markov chain with the market’s transition matrix. Calculate the total number of each regime in all sample paths.
Step 3: Draw i.i.d. samples from stdMNTS distribution in each regime. The number of samples is determined by the calculation in Step 2. To draw one sample, we follow the procedure below.
Step 3.1: Sample from multivariate normal distribution N(0,).
Step 3.2: Sample from the tempered stable subordinator T with parameters and .
Step 3.3: Calculate .
Step 4: Multiply the standard deviation in Step 1 with standard joint innovations in Step 3 accordingly. Add regime-specific mean to get simulated asset returns.
5. Empirical Study
In this section, we demonstrate the superiority of our approach with various in-sample and out-of-sample tests. We conduct model fitting, sample path simulation and portfolio optimization. In the in-sample test, we conduct a KS test on the marginal NTS distribution and marginal t-distribution to show that the NTS distribution has a much better fit on the innovations. We also provide the transition matrix and the correlation matrices of the joint innovations in each regime. In the out-of-sample test, we use various performance measures and visualizations for the rolling-window studies in recent years to show the outperformance of our portfolio.
For diversification purposes, we set the range of weights as
. A case study in
Krokhmal et al. (
2002) found that without constraints on weights, the optimal portfolio only consists of a few assets among hundreds. Investors often empirically categorize the market as bull, bear and sideways market.
Haas et al. (
2004) experiments with two and three regimes. We limit the number of regimes to be smaller than or equal to three. The Dip test is conducted on innovations to ensure unimodal innovation distribution. Starting fitting with three regimes, a model with fewer regimes is used instead when the
p-value is lower than
or have a regime lasting shorter than 40 days in total. Preliminary tests show that without these selection criteria, the model would have a risk of overfit in some cases. For example, the innovation could be multimodal, and the regime switches hundreds of times within the tested period. The phenomena is even more pronounced when the number of regimes is higher than three. To be concise in notation, we denote the portfolios in a convenient manner. For example, 0.9-CDaR portfolio denotes the optimal portfolio derived from the optimization with 0.9-CDaR as the risk measure. The standard deviation optimal portfolio is the optimal portfolio in the classical Markowitz model that maximizes Sharpe ratio, which we also denoted by mean-variance (MV) optimal portfolio. The word optimal is sometimes omitted. Since we simulate returns for 10 days, all CVaR with varying confidence levels are calculated with the simulated cumulative returns on the 10-th day. We omit the time and denote the optimal portfolio simply as CVaR portfolio.
5.1. Data
The data are comprised of the adjusted daily price of DJIA index, 29 of the constituents of DJIA Index and three ETFs of bond, gold and shorting index (Tickers: TMF, SDOW and UGL) from January 2010 to September 2020. One constituent DOW is removed because it is not included in the index throughout the time period. Since we use 1764 trading days’ (about 7 years) data to fit the model, the time period for out-of-sample rolling-window test is from January 2017 to September 2020, which includes some of the most volatile periods in history caused by the a pandemic and some trade tensions. By reweighting the index constituents, it can be regarded as an enhanced index portfolio.
5.2. Performance Measures
Various performance measures are discussed in
Biglova et al. (
2004),
Rachev et al. (
2008),
Cheridito and Kromer (
2013). Similar to Markowitz Model, an efficient frontier can be derived by changing the value of constraint. Each portfolio on the efficient frontier is optimal in the sense that no portfolio has a higher return with the same value of risk measure. In this paper, we refer to the portfolio with the highest performance ratio
as an optimal portfolio and the others on the efficient frontier as suboptimal portfolios. Note that
is
. Thus, the mean-CVaR ratio can be regarded as a special case of the Rachev ratio
. We test with
to focus on the distribution tails.
5.3. In-Sample Tests
We present various in-sample test results. The time period during which 2-regime model is first selected is used in fitting is from 30 April 2010 to 5 May 2017. 100 days is classified as regime 1, and 1665 days is classified as regime 2. The standard deviation of the DJIA index is in regime 1 and in regime 2. Regime 2 is more volatile than regime 1. One might expect that the market is in a less volatile regime longer and has a spiked standard deviation during a short but much more volatile regime. It is not the case in this tested period according to our model.
5.3.1. Kolmogorov–Smirnov Tests on Marginal Distributions
We conduct a Kolmogorov–Smirnov test (KS test) on the marginal distributions of the joint innovation of MRS-MNTS-GARCH model in the tested period. The results are presented in
Table 1. For comparison, we also fit multivariate
t-distribution on the joint innovations and report the results of KS tests on the marginal distributions. The degree of freedom of multivariate
-distribution in regime 1 and regime 2 are
and
, respectively. Note that the marginal distribution of stdMNTS distribution is still NTS distribution. Since we assume common parameters
and
in MNTS distribution, we report the parameter
of each asset in both regimes. The data are rounded to 3 decimals place.
5.3.2. Transition Matrix and Denoised Correlation Matrices of Joint Innovation
The transition matrix of the innovations is presented in
Table 2. The self-transition probability in two regimes are close, and both are high.
We also provide the denoised correlation matrices of stdMNTS innovations in two regimes in
Table 3. Since there are two regimes identified in this period, we combine the two correlation matrices for easier comparison. The upper triangle of the matrix is the upper triangle of correlation matrix in regime 1, while the lower triangle of the matrix is the lower triangle of correlation matrix in regime 2. We find that the innovations have distinctively different correlation matrices in two regimes, validating the regime-switching assumption. The innovations are highly correlated in regime 2, which corresponds to more volatile periods.
5.4. Out-of-Sample Tests
We conduct out-of-sample tests to demonstrate the outperformance of the optimal portfolios. We use 3 types of risk measures with different confidence levels in the optimization, namely, maximum drawdown, 0.7-CDaR, 0.3-CDaR, average drawdown, 0.5-CVaR, 0.7-CVaR, 0.9-CVaR and standard deviation. Note that 0-CVaR is equal to the expected return, which does not make sense as a risk measure. Minimizing -CVaR with small means that we include the positive part of the return distribution as risk. This is a drawback of standard deviation, and thus we set at 0.5, 0.7, and 0.9 to demonstrate the superiority.
The rolling window technique is employed with 10-day forward-moving time window. In each time window, we simulate 10,000 sample paths of length 10 with the fitted model. The simulation is used as input to portfolio optimization. The portfolio is held for 10 trading days before rebalancing. The portfolio optimization is performed with software Portfolio Safeguard (PSG) with precoded numerical optimization procedures.
5.4.1. Optimal Portfolios
We report the performance of the optimal portfolios in various forms. Due to a large number of risk measures, we sometimes only present representative ones in graphs for better visualization. The other optimal portfolios have similar results.
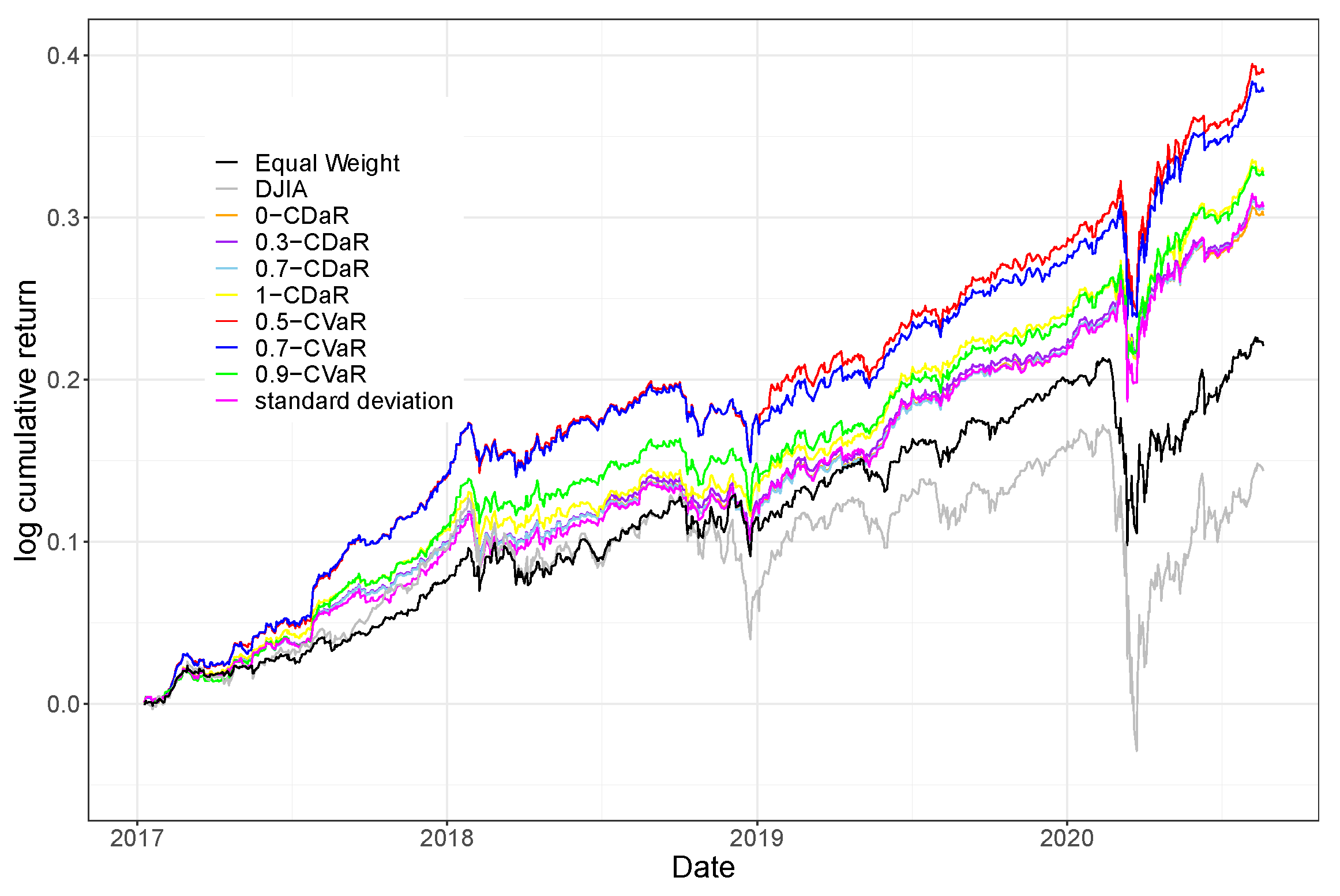
Log Cumulative Return
In
Figure 1, we plot the time series of log cumulative returns of the optimal portfolios with different risk measures in out-of-sample tests to visualize the performance. The legend shows colors that represent different risk measures used in each portfolio optimization. We use log base 10 compounded cumulative returns as a vertical axis so that the scale of relative drawdown can be easily compared in graphs by counting the grids. The performance with different risk measures is reported separately. The labels in the legend show the confidence level of the risk measure. The names of the subfigures indicate the risk measures used in the optimization. DJIA index and the equally weighted portfolio are included in each graph for comparison.
As can be observed in the graphs, all the optimal portfolios follow a similar trend, though they differ in overall performance. They tend to alleviate both left tail and right tail events. CVaR optimal portfolios have higher cumulative returns than CDaR optimal portfolios. The confidence level has only a marginal impact. CVaR optimal portfolios with confidence levels 0.5 and 0.7 are almost indistinguishable. CDaR optimal portfolios with confidence levels 0.5, 0.7 and 0.9 are almost indistinguishable.
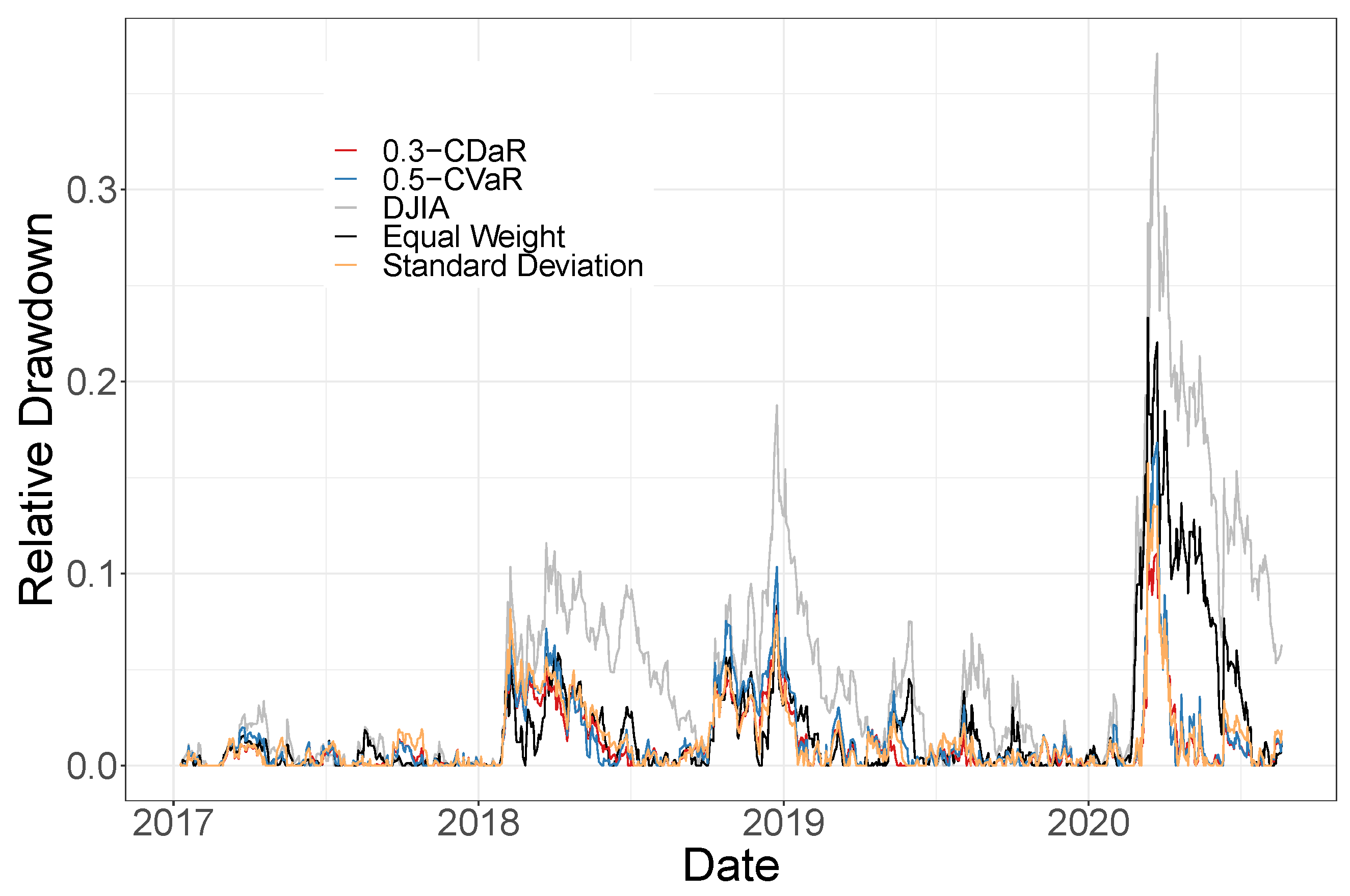
Relative Drawdown
Since the CVaR and CDaR risk measures only concern the tail behavior of a portfolio, we plot the relative drawdown of the optimal portfolios in out-of-sample testing period in
Figure 2 to demonstrate their ability to alleviate extreme left tail events. Due to a large number of optimal portfolios with different risk measures, we only plot 0-CDaR, 0.5-CVaR and MV optimal portfolios here for better visualization. The others have similar results. The 0-CDaR, 0.5-CVaR and MV optimal portfolios have significantly smaller relative drawdown most of the time in the out-of-sample test, especially in year 2020. 0-CDaR and 0.5-CVaR optimal portfolios are slightly better than the MV optimal portfolio.
Portfolio Return Distribution
In
Figure 3, we plot the kernel density estimation on the return distribution. To better compare the tails of the return distribution, we also plot the log base 10 density. We can easily observe that the optimal portfolios are very close and alleviate both right and left tail events. Unlike standard deviation (MV) optimal portfolio, 0.3-CDaR and 0.5-CVaR portfolio have thinner tails on both sides than DJIA and the equally weighted portfolio. 0.3-CDaR and standard deviation portfolio have a higher peak than the equally weighted portfolio. Among the three optimal portfolios, the 0.5-CVaR portfolio has the thinnest left tail and a fatter right tail than the other two optimal portfolios.
Allocation
In
Figure 4, we report the time series of optimal weights of the 0-CDaR optimal portfolio as a representative case. The DJIA constituents are aggregated for better visualization. It is reasonable that when the total weight on DJIA constituents is high, the weights on shortselling ETF is low. The weights on ETFs hit the lower and upper bounds 0.01 and 0.15 in many periods, indicating that the constraints on weights are active in the optimizations.
5.4.2. Robustness to Suboptimality in Optimization
So far, we have been studying the optimal portfolios that maximize performance ratios. In this section, we study the sensitivity of the performance by comparing suboptimal portfolios with the optimal ones. We show that the portfolio with tail risk measure is more robust to suboptimality in optimization than the mean-variance portfolio. The performance ratios of CDaR and CVaR optimal portfolios are shown to be not sensitive to changing the value of return constraint, while the performance ratios of mean-variance optimal portfolio shows significant change. The graphs of log cumulative return show that the suboptimal portfolios follow a similar trend, sometimes overlapping with each other.
We use 9 portfolios with different constraints on return to approximate the efficient frontier for each risk measure. For example, in each 0.3-CDaR optimization, we perform 10 optimizations with varying constraints on return. The portfolio with the highest return-risk ratio is the approximated optimal portfolio. We denote the portfolio that has n lower level of constraint on return as level Ln suboptimal portfolio, the one that has n higher level of constraint on return as level Hn suboptimal portfolio. When a certain optimization is unfeasible, we set the allocation the same as that of a lower level. The constraints on return are (0.002, 0.010, 0.020, 0.030, 0.035, 0.040, 0.045, 0.050, 0.060, 0.065). For example, when the portfolio with constraint 0.050 on return has the highest performance ratio among the 10 portfolios, it is labeled as the optimal portfolio. Accordingly, the portfolio with one-level higher constraint 0.060 is labeled H1. In this case, H2 to H4 have the same constraint 0.065, since there is no optimization performed with higher constraint. Note that at each rebalance, the optimal portfolio changes, so do portfolios of other levels, i.e., constraint 0.060 may no longer be optimal. The performance of each label is measured with portfolios of corresponding level determined at each rebalance.
We report suboptimal portfolios with risk measures of 0-CDaR, 0.5-CVaR and standard deviation in
Figure 5 and
Table 5 as representative cases. We find that the optimal portfolio is consistently too conservative for all risk measures and input. That is, with the same risk measure, suboptimal portfolios with a higher constraint on return achieve higher performance ratios than the optimal portfolio. From
to
, the ratios do not show a pattern of first increasing the decreasing as expected. In other words, the out-of-sample efficient frontiers are usually non-convex with irregular shapes. Overall, the performance ratios of CDaR and CVaR optimal portfolios are shown to be not sensitive to changing the value of return constraint, while the performance ratios of mean-variance optimal portfolio shows significant change.
The portfolios have increasing returns as well as risk from L1 to H4. The realized paths follow a similar trend and rarely cross. The optimal portfolios, as expected, are in the medium part of all paths. The 0.5-CVaR suboptimal portfolios have almost identical performance. Some paths are not visible due to overlap. For example, the constraints on the return of H4 are sometimes not feasible, leading to the same performance with H3 portfolio.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}