


Separating Equilibria with Search and Selection Effort: Evidence from the Auto Insurance Market


Abstract
:1. Introduction
2. Literature Review
2.1. Theoretical Literature
2.2. Empirical Literature
3. Materials and Methods
3.1. A Game-Theoretic Model with Consumer Search Effort and IC Selection Effort
- Stage 1: Insurers
- Stage 2: Consumers
- Stage 3: Nash equilibria in efforts and wealth levels space
3.2. Theoretical Findings
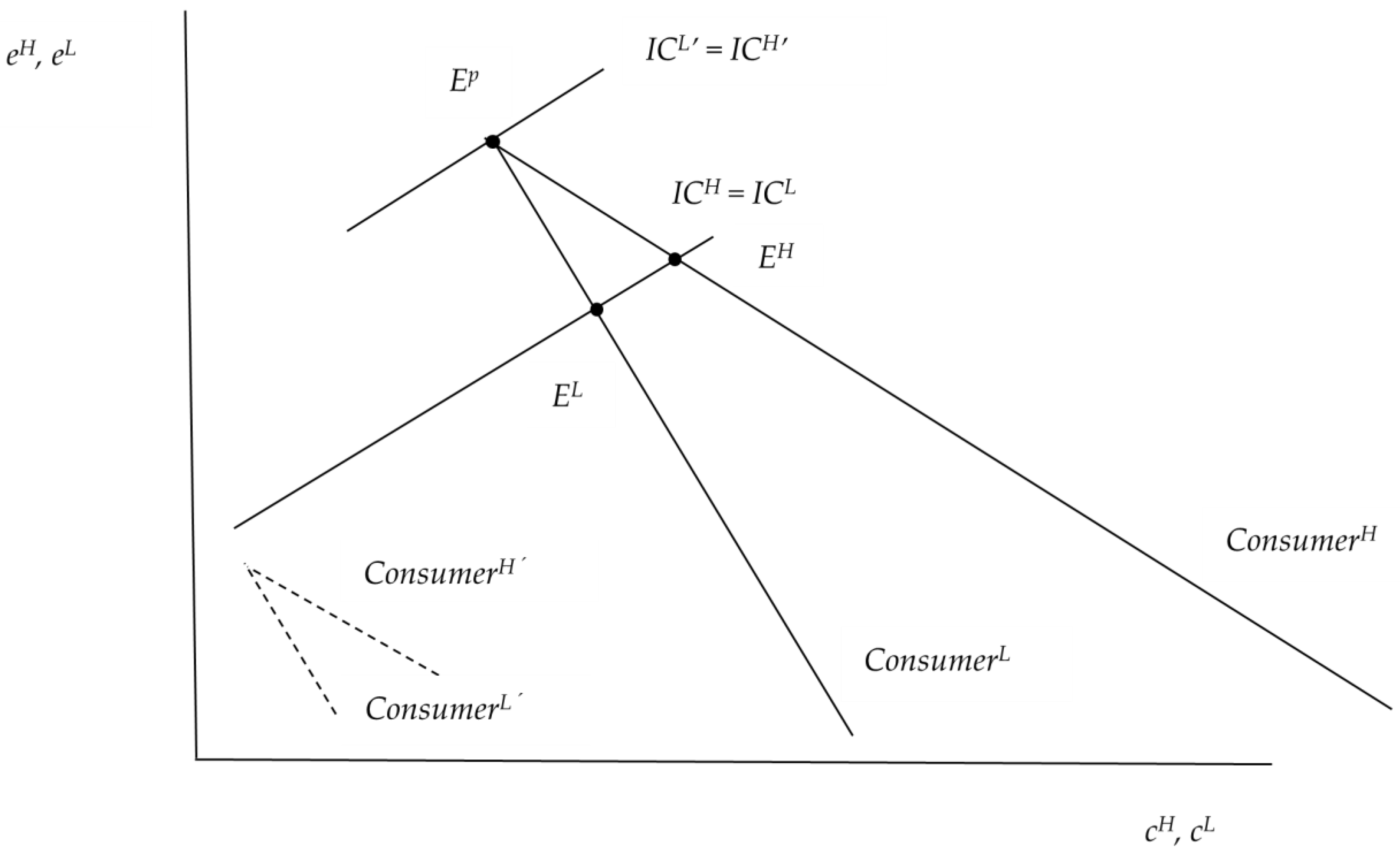
3.2.1. Results in Efforts Space
- On the IC’s side, information, e.g., concerning miles driven per year, quality of roads typically traveled, and crime incidence in the area of residence, may make the IC’s risk selection effort more effective in the case of auto insurance. This increases in absolute value, causing the slope of the IC’s reaction function to increase according to Equations (A3) of Appendix A.1. The result is a greater difference between and (facilitating the separation of equilibria) combined with a smaller difference between and (see Figure 2).
- The same effects are predicted ceteris paribus if consumers’ search effort becomes more effective, e.g., due to the Internet, media such as Consumer Reports, and public regulation designed to enhance transparency. In Equations (A4) and (A5) of Appendix A.2, the terms and increase, and with them, IC’s reaction function in Figure 2 becomes more responsive to consumers’ search efforts.
- The ceteris paribus clause above cannot be neglected because the consumers’ reaction functions would be affected as well. In Equations (A4) and (A5), the terms and go towards zero, indicating that the IC’s risk selection effort does not counterbalance consumers’ search effort to the same extent when they are better informed. In Figure 2, the reaction function labeled ConsumerH in particular becomes more responsive to IC’s selection effort since the term is multiplied by , causing the differences between and as well as and to increase.
- Differences in risk aversion [indicated by and in Equations (A4) and (A5)] have an impact on consumers’ reaction functions. For instance, let increase relative to ; a possible reason is that high-risk types happen to coincide with higher age, which is associated with increased risk aversion (Halek and Elisenhauer 2001). This has the effect of making the high risk’s response to IC selection effort more marked, resulting in a flatter ConsumerH line of Figure 2 and hence a larger difference between and as well as and .
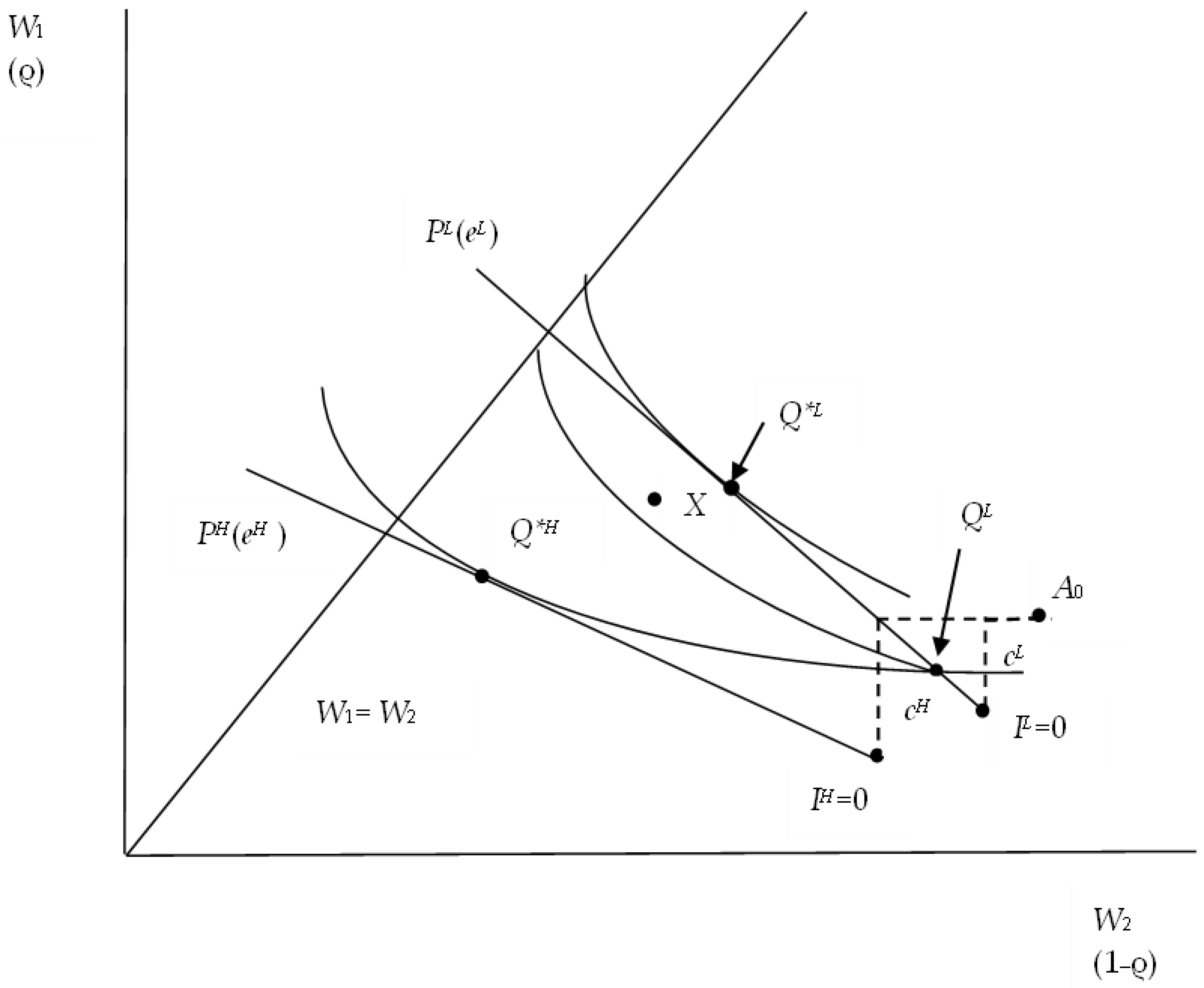
3.2.2. Results in Wealth Space
- Since the IC makes a risk selection effort, the cost, which typically gives rise to a proportional loading, a (marginally) fair premium is excluded from the onset. Therefore, at C*L, high-risk types necessarily opt for partial coverage.
- Even though the IC is not able to infer the true loss probabilities, forcing it to continue using the average value , the insurance line labelled PH(eH) has a lower slope than PL(eL), reflecting the IC’s higher amount of risk selection effort in its interaction with a high-risk type in stage 3.
- Because high-risk types are predicted to invest relatively more effort in seeking out the contract that maximizes coverage for a given premium, they bear a higher initial transaction cost, cH, which shifts the origin of their insurance line from A0 to IH = 0. Thus, the probability of constituting the optimum is far greater than in the RS approach. This provides an explanation for the observation that it is the widely discussed inability of high-risk types to obtain insurance coverage that constitutes a policy issue rather than the rationing of low-risk types’ coverage at because of the need to maintain a separating equilibrium.
- The location of the optimum C*H in Figure 3 depends on the parameters appearing in Equation (A4), viz. and importantly on the IC’s amount of selection effort e and hence in Equation (2).
- In the RS modeling, the pooling contract X (see Figure 3) can undermine a separating equilibrium provided the share of low-risk types in the population is sufficiently high (the pooling insurance line must run close to that labeled PL(eL).Yet when consumer search and insurer selection efforts are considered, a pooling equilibrium can be excluded almost with certainty, which implies that the separating equilibrium cannot be undermined. (see Ep in Figure 2 again).
4. Empirical Analysis
4.1. Data
“[e]mpirical models of insurance markets would greatly enhance our ability to understand policy-relevant questions. Yet they are still quite rare. …While much progress has been made in recent years in our understanding of insurance demand in particular, the most crying need is for market-wide data”.
4.1.1. Insurance Policies
4.1.2. Insurers
4.1.3. Consumers
4.1.4. Evidence of Adverse Selection
4.2. Model Specification
4.3. Indicator Variables
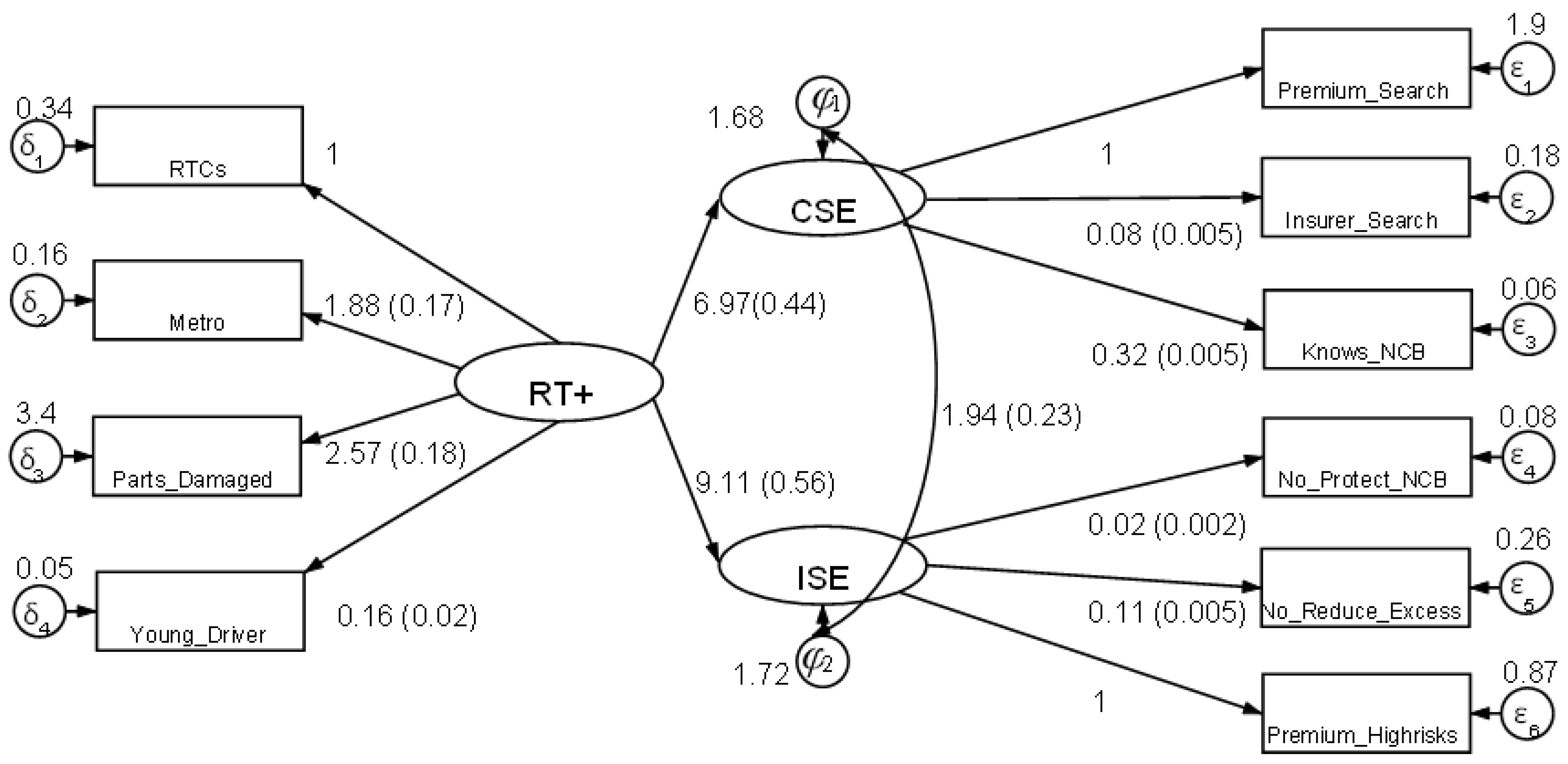
4.3.1. Indicators of Insurer Selection Effort (ISE)
4.3.2. Indicators of Consumer Search Effort (CSE)
4.3.3. Indicators of High-Risk Type (RT+)
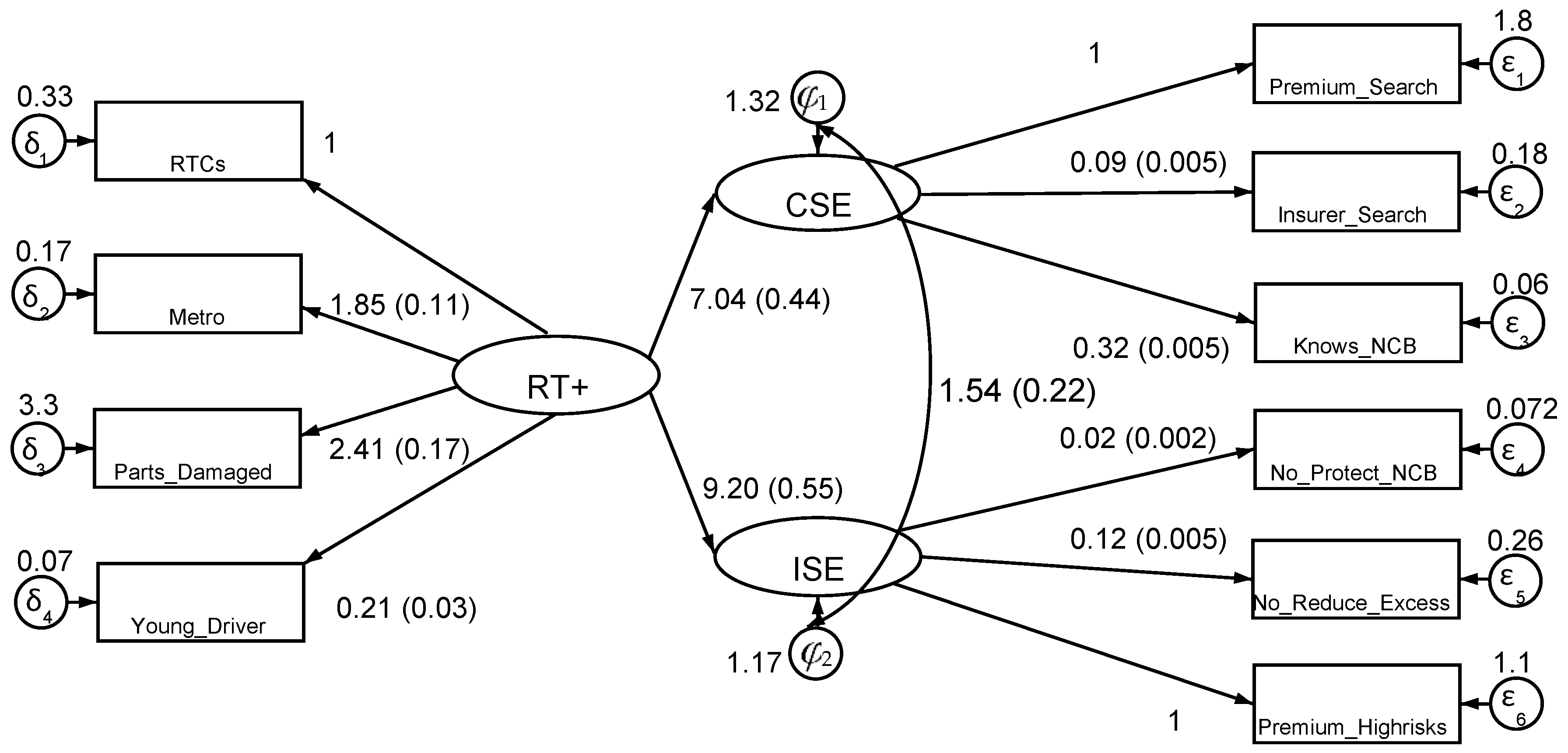
4.4. Empirical Results
5. Conclusions
5.1. The Theoretical Contribution
5.2. The Empirical Contribution
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A.
Appendix A.1. The Insurer’s Reaction Function
Appendix A.2. Consumers’ Reaction Functions
Appendix B.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Insurers: New South Wales | High-Risk Scenario | Medium-Risk Scenario | Low-Risk Scenario | |||
| High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | |
| AAMI | 2 | 3 | 4 | 5 | 2 | 3 |
| ANSVAR | 3 | 3 | 2 | 3 | 3 | 3 |
| Australian Alliance | . | . | 2 | 3 | 4 | 5 |
| Commercial Union | 3 | 5 | 3 | 5 | 3 | 4 |
| Direcdial | 4 | 3 | 3 | 2 | 3 | 2 |
| FAI car | 2 | 2 | 3 | 2 | 2 | 2 |
| Mercantile Mutual | 4 | 2 | 5 | 3 | 5 | 2 |
| NRMA | 2 | 2 | 3 | 3 | 3 | 2 |
| NZI Comprehensive | 3 | 3 | 3 | 3 | 2 | 3 |
| NZI Top Cover | 3 | 3 | 3 | 4 | 3 | 4 |
| QBE | 5 | 3 | 4 | 3 | 4 | 3 |
| Suncorp | 2 | 2 | 2 | 2 | 3 | 2 |
| SWANN Agreed value | 4 | 4 | 2 | 2 | 2 | 3 |
| TII | 3 | 4 | . | 2 | . | 3 |
| Zurich Personal Assistance | 2 | 2 | 4 | 3 | 3 | 3 |
| Insurers: Queensland | High-Risk Scenario | Medium-Risk Scenario | Low-RiskScenario | |||
| High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | |
| AAMI | 3 | 4 | 5 | 5 | 3 | 3 |
| ANSVAR | 2 | 2 | 2 | 2 | 3 | 3 |
| Australian Alliance | . | . | 2 | 2 | 2 | 2 |
| Commercial Union | 4 | 5 | 4 | 4 | 5 | 5 |
| Direcdial | 4 | 3 | 2 | 2 | 3 | 2 |
| FAI car | 2 | 2 | 3 | 2 | 2 | 2 |
| Mercantile Mutual | 2 | 3 | 3 | 3 | 2 | 3 |
| NRMA | 2 | 2 | 3 | 3 | 2 | 2 |
| NZI Comprehensive | 3 | 3 | 3 | 3 | 3 | 3 |
| NZI Top Cover | 3 | 3 | 4 | 4 | 5 | 5 |
| QBE | 5 | 5 | 4 | 4 | 3 | 4 |
| RACQ | 2 | 2 | 2 | 2 | 3 | 3 |
| Suncorp | 2 | 2 | 3 | 3 | 3 | 3 |
| SWANN Agreed value | 4 | 4 | 2 | 2 | 4 | 3 |
| TII | 3 | 3 | 2 | 2 | 2 | 2 |
| TIO | . | . | . | . | . | . |
| Zurich Personal Assistance | 2 | 2 | 4 | 3 | 4 | 3 |
| Insurers: Victoria | High-Risk Scenario | Medium-Risk Scenario | Low-Risk Scenario | |||
| High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | |
| AAMI | 4 | 4 | 2 | 2 | 3 | 2 |
| ANSVAR | 2 | 2 | 2 | 2 | 2 | 3 |
| Australian Alliance | . | . | . | . | 2 | 2 |
| Commercial Union | 3 | 3 | 4 | 4 | 4 | 3 |
| Direcdial | 4 | 3 | 3 | 2 | 3 | 2 |
| FAI car | 2 | 2 | 4 | 3 | 3 | 2 |
| HBF | . | . | . | . | . | . |
| Mercantile Mutual | 2 | 2 | 3 | 3 | 2 | 2 |
| NRMA | 2 | 2 | 4 | 4 | 3 | 3 |
| NZI Comprehensive | 3 | 3 | 4 | 3 | 3 | 2 |
| NZI Top Cover | 3 | 3 | 5 | 5 | 4 | 4 |
| QBE | 3 | 4 | 3 | 3 | 2 | 3 |
| RACV Fair Deal | 2 | 3 | 2 | 3 | 4 | 4 |
| RAC (WA) Motorguard | . | . | . | . | . | . |
| SIGO | . | . | . | . | . | . |
| SWANN Agreed value | 5 | 5 | 4 | 4 | 5 | 5 |
| TII | 3 | 4 | 2 | 3 | 2 | 4 |
| Western QBE | . | . | . | . | . | . |
| Zurich Personal Assistance | 2 | 2 | 4 | 4 | 2 | 3 |
| Insurers: Western Australia | High-Risk Scenario | Medium-Risk Scenario | Low-Risk Scenario | |||
| High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | High-Risk Area | Low-Risk Area | |
| AAMI | . | . | . | . | . | . |
| ANSVAR | 3 | 3 | 3 | 3 | 3 | 3 |
| Australian Alliance | . | . | 2 | 3 | 4 | 4 |
| Commercial Union | 4 | 5 | 5 | 5 | 5 | 5 |
| Direcdial | 4 | 3 | 2 | 2 | 2 | 2 |
| FAI car | 2 | 2 | 3 | 3 | 2 | 2 |
| HBF | 2 | 2 | 2 | 3 | 3 | 3 |
| Mercantile Mutual | 2 | 3 | 3 | 4 | 2 | 3 |
| NRMA | . | . | . | . | . | . |
| NZI Comprehensive | 3 | 3 | 4 | 4 | 3 | 3 |
| NZI Top Cover | 4 | 3 | 5 | 5 | 5 | 5 |
| QBE | . | . | . | . | . | . |
| RACV Fair Deal | . | . | . | . | . | . |
| RAC (WA) Motorguard | 3 | 3 | 3 | 3 | 4 | 3 |
| SIGO | 2 | 2 | 2 | 2 | 2 | 2 |
| SWANN Agreed value | 5 | 5 | 2 | 2 | 3 | 3 |
| TII | 4 | 3 | 2 | 2 | 3 | 2 |
| Western QBE | 2 | 2 | 2 | 2 | 2 | 2 |
| Zurich Personal Assistance | 2 | 2 | 4 | 3 | 3 | 2 |
| Insurance Company | States Available | Reduction of NCB | Protection of NCB | Reduce Excess |
|---|---|---|---|---|
| Australian Alliance | All but NT | 1 | 1 | 1 |
| Australian Pensions | All but NT | 1 | 1 | 1 |
| RACT | Tas. | 2 | 1 | 1 |
| NRMA | ACT, NSW, Vic. | 2 | 1 | 1 |
| CGU | All but NT | 2 | 1 | 1 |
| FAI | All but NT | 2 | 1 | Not in Qld. |
| RACQ-GIO | Qld. | 1 | 1 | 2 |
| TII | All but NT | 2 | 1 | 1 |
| AAMI | All but WA | 1 | 1 | 2 |
| EIG-ANSVAR | All | 2 | 1 | 1 |
| RAA-GIO | SA | 1 | 1 | 1 |
| COTA | All | 1 | 1 | Not in Qld. |
| HBF | WA | 2 | 1 | 1 |
| Suncorp-Metway | Qld. | 1 | 2 | 1 |
| SWANN | All | 2 | 1 | 2 |
| Mutual Community | SA | 2 | 1 | 1 |
| Western QBE | All but NT | 2 or 1 if < USD 1000 | 1 | 1 |
| Directdial | All but NT | 2 | 1 | 2 |
| HBA | Vic. | Depends on NCB | 1 | 1 |
| GIO | Vic. | 2 | 1 | 1 |
| SGIC | SA | 2 | 1 | 1 |
| AMP | All | 2 | 1 | 1 |
| TIO | NT | 2 | 1 | 1 |
| RACV (E.) | Vic. | 2 | 1 | 2 |
| RAC Motor guard | WA | 2 | 1 | 1 |
| TGIO | Tas. | 2 | 1 | 1 |
| GIO | ACT, NSW | 2 | 1 | 1 |
| GIO | NT | 2 | 2 | 2 |
| SGIO | WA | 3 | 1 | 1 |
| GIO | WA | 2 | 1 | 1 |
| AMP car insurance Options | All | 2 | 1 | 1 |
| GIO Rode Cover Basic | Vic. | 2 | 1 | 2 |
| =1 level. | 1 = Yes | 1 = Yes | ||
| =2 levels | 2 = No | 2 = No | ||
| =3 levels |
| CSE | ISE | Risk Type | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | (9) | (10) | ||
| (1) Premium_Search | 1.000 | ||||||||||
| CSE | (2) Insurer_Search | 0.030 * | 1.000 | ||||||||
| (3) Knows_NCB | 0.043 * | −0.015 | 1.000 | ||||||||
| (4) Premium_Highrisks | −0.038 * | 0.020 | 0.034 * | 1.000 | |||||||
| ISE | (5) No_Protect_NCB | 0.082 * | −0.040 * | −0.049 * | 0.137 * | 1.000 | |||||
| (6) No_Reduce_Excess | 0.035 * | 0.048 * | −0.056 * | −0.351 * | −0.229 * | 1.000 | |||||
| (7) RTCs | −0.021 | −0.022 | 0.009 | 0.026 | −0.006 | −0.024 | 1.000 | ||||
| Risk Type | (8) Parts_Damaged | −0.028 | 0.004 | 0.009 | 0.017 | 0.012 | −0.028 | 0.487 * | 1.000 | ||
| (9) Metro | −0.136 * | −0.111* | 0.002 | −0.039 * | −0.154 * | 0.044 * | 0.080 * | 0.082 * | 1.000 | ||
| (10) Young_Driver | −0.134 * | −0.004 | −0.129 * | 0.003 | 0.051 * | 0.025 | 0.060 * | 0.045 * | 0.030 * | 1.000 | |
| Coeff. | Std. Err. | z | P > |z| | [95% CI] | ||
|---|---|---|---|---|---|---|
| Structural Model | ||||||
| CSE | ||||||
| HIGH_RT | 7.001 | 0.286 | 24.49 | <0.01 | 6.444 | 7.565 |
| ISE | ||||||
| HIGH_RT | 9.159 | 0.360 | 25.45 | <0.01 | 8.453 | 9.864 |
| Measurement Model | ||||||
| Insurer_Search | ||||||
| CSE | 0.083 | 0.003 | 24.94 | <0.01 | 0.079 | 0.090 |
| constant | 0 | constrained | ||||
| Premium_Search | ||||||
| CSE | 1 | constrained | ||||
| constant | 0 | constrained | ||||
| Knows_NCB | ||||||
| CSE | 0.319 | 0.004 | 82.72 | <0.01 | 0.312 | 0.327 |
| constant | 0 | constrained | ||||
| No_Protect_NCB | ||||||
| ISE | 0.021 | 0.002 | 12.29 | <0.01 | 0.017 | 0.024 |
| _cons | 0 | constrained | ||||
| No_Reduce_Excess | ||||||
| ISE | 0.115 | 0.003 | 36.52 | <0.01 | 0.109 | 0.122 |
| constant | 0.000 | constrained | ||||
| Premium_Highrisks | ||||||
| ISE | 1 | constrained | 12.2 | <0.01 | 40.612 | 56.161 |
| constant | 0 | constrained | ||||
| RTCs | ||||||
| HIGH_RT | 1 | constrained | ||||
| constant | 0 | constrained | ||||
| Metro | ||||||
| HIGH_RT | 1.866 | 0.073 | 25.5 | <0.01 | 1.722 | 2.009 |
| constant | 0 | constrained | ||||
| Parts_Damaged | ||||||
| HIGH_RT | 2.494 | 0.141 | 17.72 | <0.01 | 2.21 | 2.77 |
| constant | 0 | constrained | ||||
| Young_Driver | ||||||
| HIGH_RT | 0.183 | 0.016 | 11.13 | <0.01 | 0.151 | 0.215 |
| constant | 0 | constrained | ||||
| var(e.Insurer_Search) | 0.178 | 0.006 | 0.167 | 0.189 | ||
| var(e.Premium_Search) | 1.859 | 0.065 | 1.735 | 1.991 | ||
| var(e.Knows_NCB) | 0.063 | 0.004 | 0.056 | 0.070 | ||
| var(e.No_Protect_NCB) | 0.076 | 0.002 | 0.071 | 0.081 | ||
| var(e.No_Reduce_Ecess) | 0.258 | 0.008 | 0.242 | 0.274 | ||
| var(e.Premium_Highrisks) | 1.001 | 0.107 | 0.811 | 1.235 | ||
| var(e.Prior_RTC) | 0.129 | 0.004 | 0.121 | 0.137 | ||
| var(e.Metro) | 0.167 | 0.012 | 0.146 | 0.192 | ||
| var(e.Parts_Damaged) | 3.472 | 0.111 | 3.261 | 3.698 | ||
| var(e.Young_Driver) | 0.059 | 0.002 | 0.055 | 0.063 | ||
| var(e.CSE) | 0.010 | 0.001 | 0.007 | 0.013 | ||
| var(e.ISE) | 0.001 | 0.000 | 0.000 | 0.001 | ||
| var(HIGH_RT) | 0.029 | 0.003 | 0.024 | 0.036 | ||
| cov(e.CSE,e.ISE) | 0.002723 | 0.0004365 | 6.24 | 0 | 0.001868 | 0.003579 |
| 1 | Mimra and Wambach (2014) provide an excellent summary of the literature that has reviewed by Rothschild and Stiglitz (1976). |
| 2 | For example, in markets for health insurance empirical research has reported that ICs are able to control adverse selection (Pauly et al. 2007; Marton et al. 2015). However, Cutler and Reber (1998) found that comprehensive health insurance coverage sponsored by Harvard University had to be withdrawn from the market; they interpreted this as evidence of a “death spiral” Frech III and Smith (2015) do find evidence suggesting a “death spiral”; however, the spiral moves so slowly as to give ICs plenty of time to withdraw loss-making contracts. |
| 3 | |
| 4 | The notation is in accordance with Stage 2 of the game (see Figure 1), where consumers are still confronted with one level of IC risk selection effort. |
| 5 | Conceivably, the marginal benefit of search effort could fall short of its marginal cost of one right away, resulting in no purchase of insurance. |
| 6 | For a more detailed description of the IMRAS data set, interested readers are directed to the papers “Two tests for ex ante moral hazard in a market for automobile insurance” (Rowell et al. 2017) and “Empirical tests for ex post moral hazard in a market for automobile insurance” (Rowell et al. 2022). |
| 7 | |
| 8 | In Stata, the estimate of = 1.94 relates to a regression of ISE on CSE. Using the formula, and noting that because is normalized to one, the estimated value of becomes 1.94/9.11 = 0.28. |
References
- Ales, Laurence, and Pricilia Maziero. 2014. Adverse Selection and Non-Exclusive Contracts. Working Paper. Pittsburgh: Carnegie Mellon University, Temper School of Business. [Google Scholar]
- Arrow, Kenneth. 1970. Political and economic evaluation of social effects and externalities. In The Analysis of Public Output. Edited by Julius Margolis. Cambridge, MA: NBER, pp. 1–30. [Google Scholar]
- Asheim, Geir B., and Tore Nilssen. 1996. Non-discriminating renegotiation in a competitive insurance market. European Economic Review 40: 1717–1736. [Google Scholar] [CrossRef]
- Attar, Andrea, Thomas Mariotti, and François Salanié. 2011. Nonexclusive Competition in the Market for Lemons. Econometrica 79: 1869–1918. [Google Scholar] [CrossRef]
- Attar, Andrea, Thomas Mariotti, and François Salanié. 2014. Nonexclusive competition under adverse selection. Theoretical Economics 9: 1–40. [Google Scholar] [CrossRef]
- Attar, Andrea, Thomas Mariotti, and François Salanié. 2016. Multiple Contracting in Insurance Markets. TSE Working Paper n. 14-532. Toulouse: Toulouse School of Economics. [Google Scholar]
- Attar, Andrea, Thomas Mariotti, and François Salanié. 2020. The Social Costs of Side Trading. The Economic Journal 130: 1608–1622. [Google Scholar] [CrossRef]
- Australian Consumer Association (ACA). 1997. Car insurance. CHOICE Magazine, July. 6–13. [Google Scholar]
- Australian Consumer Association (ACA). 1999. Your car insurance toolkit. CHOICE magazine, August. 18–29. [Google Scholar]
- Chiappori, Pierre-André. 1999. Asymmetric information in automobile insurance: An overview. In Automobile Insurance: Road Safety, New Drivers, Risks, Insurance Fraud and Regulation. Boston/Dordrecht/London: Kluwer Academic Publishers, pp. 1–11. [Google Scholar]
- Chiappori, Pierre-André, and Bernard Salanié. 2000. Testing for asymmetric information in insurance markets. Journal of Political Economy 108: 56–78. [Google Scholar] [CrossRef]
- Choice. 2024. CHOICE. Available online: https://www.choice.com.au/ (accessed on 15 January 2024).
- Clark, M. 2022. Structural Equation Modeling; Mixture Models. Available online: https://m-clark.github.io/sem/mixture-models.html (accessed on 20 March 2024).
- Compare the Market. 2020. Car insurance in Australia. Available online: https://www.comparethemarket.com.au/car-insurance/Australia/ (accessed on 20 March 2024).
- Consumer Reports. 2019. Homeowners Insurance. Available online: https://www.consumerreports.org/cro/homeowners-insurance.htm (accessed on 20 March 2024).
- Cutler, David M., and Sarah J. Reber. 1998. Paying for Health Insurance: The Trade-Off between Competition and Adverse Selection. The Quarterly Journal of Economics 113: 433–466. [Google Scholar] [CrossRef]
- Dionne, Georges, and Neil A. Doherty. 1994. Adverse Selection, Commitment, and Renegotiation: Extension to and Evidence from Insurance Markets. Journal of Political Economy 102: 209–235. [Google Scholar] [CrossRef]
- Dionne, Georges, Gouriéroux Christian, and Charles Vanasse. 2001. Testing for Evidence of Adverse Selection in the Automobile Insurance Market: A Comment. Journal of Political Economy 109: 444–453. [Google Scholar] [CrossRef]
- Dionne, Georges, Pierre-Carl Michaud, and Maki Dahchour. 2013. Separating moral hazard from adverse selection and learning in automobile insurance: Longitudinal evidence from france. Journal of the European Economic Association 11: 897–917. [Google Scholar] [CrossRef]
- Engers, Maxim, and Luis Fernandez. 1987. Market Equilibrium with Hidden Knowledge and Self-Selection. Econometrica 55: 425. [Google Scholar] [CrossRef]
- Fan, Yi, Jiquan Chen, Gabriela Shirkey, Ranjeet John, Susie R. Wu, Hogeun Park, and Changliang Shao. 2016. Applications of structural equation modeling (SEM) in ecological studies: An updated review. Ecological Processes 5: 1–12. [Google Scholar] [CrossRef]
- Frech III, H. E., and Michael P. Smith. 2015. Anatomy of a Slow-Motion Health Insurance Death Spiral. North American Actuarial Journal 19: 60–72. [Google Scholar] [CrossRef]
- Halek, Martin, and Joseph G. Elisenhauer. 2001. Demography of Risk Aversion. The Journal of Risk and Insurance 68: 1–24. [Google Scholar] [CrossRef]
- Hellwig, Martin. 1987. Some recent developments in the theory of competition in markets with adverse selection. European Economic Review 31: 319–325. [Google Scholar] [CrossRef]
- Hey, John D. 2002. Experimental Economics and the Theory of Decision Making Under Risk and Uncertainty. The Geneva Risk and Insurance Review 27: 5–21. [Google Scholar] [CrossRef]
- Jaynes, Gerald David. 1978. Equilibria in monopolistically competitive insurance markets. Journal of Economic Theory 19: 394–422. [Google Scholar] [CrossRef]
- Jaynes, Gerald D. 2011. Equilibrium and Strategic Communication in the Adverse Selection Insurance Model. Economics Department Working Paper No. 91. New Haven: Yale University. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1865367 (accessed on 20 March 2024).
- Jöreskog, Karl G., and Arthur S. Goldberger. 1975. Estimation of a model with multiple indicators and multiple causes of a single latent variable. Journal of the American Statistical Association 70: 631–9. [Google Scholar]
- Kenny, David A. 2020. Measuring Model Fit. Available online: http://davidakenny.net/cm/fit.htm (accessed on 20 March 2024).
- Kline, Rex B. 2016. Principles and Practice of Structural Equation Modeling, 4th ed. New York: New York Guilford Press. [Google Scholar]
- Kosenko, Andrew, Joseph Stiglitz, and Jungyoll Yun. 2023. Bilateral information disclosure in adverse selection markets with nonexclusive competition. Journal of Economic Behavior & Organization 205: 144–168. [Google Scholar] [CrossRef]
- Liferay. 2019. 20 Must-know stats for Insurers in 2022. Available online: https://www.liferay.com/blog/customer-experience/20-must-know-stats-for-insurers-in-2022 (accessed on 20 March 2024).
- Marton, James, Patricia G. Ketsche, Angela Snyder, E. Kathleen Adams, and Mei Zhou. 2015. Estimating Premium Sensitivity for Children;s Public Health Insurance Coverage: Selection but No Death Spiral. Health Services Research 50: 579–98. [Google Scholar] [CrossRef]
- Mathews, Martyn. 2022. Insurance Quote Manipulation Flagged as Research Reveals Half of U.K. Consumers Think It’s Fine to Fib. Available online: https://risk.lexisnexis.co.uk/about-us/press-room/press-release/20220511-quote-intelligence (accessed on 20 March 2024).
- Mimra, Wanda, and Achim Wambach. 2014. New Developments in the Theory of Adverse Selection in Competitive Insurance. The Geneva Risk and Insurance Review 39: 136–152. [Google Scholar] [CrossRef]
- Netzer, Nick, and Florian Scheuer. 2014. A game theoretic foundation of competitive equilibria with adverse selection. International Economic Review 55: 399–422. [Google Scholar] [CrossRef]
- Pauly, Mark V. 1974. Overinsurance and Public Provision of Insurance: The Roles of Moral Hazard and Adverse Selection. The Quarterly Journal of Economics 88: 44–62. [Google Scholar] [CrossRef]
- Pauly, Mark V., Olivia S. Mitchell, and Yuhui Zeng. 2007. Death Spiral or Euthanasia? The Demise of Generous Group Health Insurance Coverage. INQUIRY: The Journal of Health Care Organization, Provision, and Financing 44: 412–27. [Google Scholar] [CrossRef] [PubMed]
- Puelz, Robert, and Arthur Snow. 1994. Evidence on Adverse Selection: Equilibrium Signaling and Cross-Subsidization in the Insurance Market. Journal of Political Economy 102: 236–257. [Google Scholar] [CrossRef]
- Riley, John G. 1979. Informational equilibrium. Econometrica 47: 331–59. [Google Scholar] [CrossRef]
- Rothschild, Michael, and Joseph Stiglitz. 1976. Equilibrium in Competitive Insurance Markets: An Essay on the Economics of Imperfect Information. The Quarterly Journal of Economics 90: 629. [Google Scholar] [CrossRef]
- Rothschild, Michael, and Joseph E. Stiglitz. 1997. Competition and insurance twenty years later. The Geneva Papers on Risk and Insurance-Theory 22: 73–79. [Google Scholar] [CrossRef]
- Rowell, David, Son Nghiem, and Luke B Connelly. 2017. Two Tests for Ex Ante Moral Hazard in a Market for Automobile Insurance. Journal of Risk and Insurance 84: 1103–26. [Google Scholar] [CrossRef]
- Rowell, David, Son Nghiem, and Luke B Connelly. 2022. Empirical Tests for Ex Post Moral Hazard in a market for Automobile Insurance. Annals of Actuarial Science 16: 243–260. [Google Scholar] [CrossRef]
- Salanié, Bernard. 2017. Equilibrium in Insurance Markets: An Empiricist’s View. The Geneva Risk and Insurance Review 42: 1–14. [Google Scholar] [CrossRef]
- Shi, Fei. 2008. Endogenous Timing with Demand Uncertainty. Working paper No. 30. Thurgau Institute of Economics and Department of Economics, University of Konstanz. Konstanz. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-opus-59885 (accessed on 20 March 2024).
- Spence, Michael. 1978. Product differentiation and performance in insurance markets. Journal of Public Economics 10: 427–47. [Google Scholar] [CrossRef]
- Stiglitz, Joseph, Jungyoll Yun, and Andrew Kosenko. 2017. Equilibrium in a Competitive Insurance Market under Adverse Selection with Endogenous Information. Working Paper No. w23556. National Bureau of Economic Research. Cambridge, Massachusetts. Available online: http://www.nber.org/papers/w23556 (accessed on 20 March 2024).
- Ullmann, Jodie B., and Peter M. Bentler. 2004. Structural Equation Modeling. In Handbook of Data Analysis. Edited by M. Hardy and A. Bryman. London: Sage Publications, pp. 431–58. [Google Scholar]
- Wilson, Charles. 1977. A model of insurance markets with incomplete information. Journal of Economic Theory 16: 167–207. [Google Scholar] [CrossRef]






| Variable | Mean e | S.D. | Skew | Rationale for Predicted Correlation with Latent Variable |
|---|---|---|---|---|
| Consumer Search Effort (CSE) | ||||
| Premium_Search (coverage/premium ratio reported as quintiles) | 2.98 | 1.14 | 0.02 | The coverage/premium ratio is positively correlated with CSE. Consumers are hypothesized to seek maximum coverage for a given premium. |
| Insurer_Search (=1 if CTP and Comprehensive insurers are not equal, =0 if otherwise) | 0.27 | 0.44 | 1.05 | Buying CTP and comprehensive insurance from the same firm is indicative of a low CSE; buying comprehensive insurance from an alternative firm is indicative of higher CSE. a |
| Knows_NCB (=1 if the consumer knows NCB, =0 otherwise) | 0.89 | 0.31 | −2.53 | A policyholder knowing their NCB is indicative of a higher CSE. |
| Insurer Selection Effort (ISE) | ||||
| Premium_Highrisks (Premiums for high-risk policyholders in high-risk areas: 1 to 5 max.) c | 3.68 | 0.70 | −2.10 | Higher premiums for the highest-risk policies are indicative of a higher ISE |
| No_Protect_NCB (=1 if NCB protection is not offered, =0 otherwise) | 0.08 | 0.30 | 3.12 | Prohibiting NCB protection is indicative of high ISE. b |
| No_Reduce_Excess (=1 if the consumer cannot reduce excess) | 0.40 | 0.49 | 0.50 | Prohibiting excess reduction is indicative of high ISE. |
| Both CSE and ISE | ||||
| Rejected_C (=1 if the consumer changed the IC after the incident, =0 otherwise) | ||||
| High-Risk-Type (RT+) | 0.05 | 0.21 | 0.04 | In principle, the change is interpreted as reflecting an action by the IC because consumers rarely wish to change insurers after an incident, but as an exception, this may occur. |
| RTCs (number of accidents reported; 0, 1 or ≥2) | 0.31 | 0.60 | 1.72 | Reporting many RTCs (1994–1999) is indicative of a high risk-type |
| Parts_Damaged (count of car parts damaged) | 0.07 | 1.72 | 4.63 | Number of damaged car parts is positively correlated with a high-risk type |
| Metro (=1 if someone lives in a metropolitan region, =0 if otherwise) | 0.62 | 0.48 | −0.53 | Due to the increased cost of repairs and the probability of theft, metropolitan regions are correlated with higher risk type. d |
| Young_Driver (=1 if aged < 25 years, =0 if otherwise) | 0.09 | 0.29 | 2.87 | Young drivers are associated with more RTCs, hence the high-risk type |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rowell, D.; Zweifel, P. Separating Equilibria with Search and Selection Effort: Evidence from the Auto Insurance Market. J. Risk Financial Manag. 2024, 17, 154. https://doi.org/10.3390/jrfm17040154
Rowell D, Zweifel P. Separating Equilibria with Search and Selection Effort: Evidence from the Auto Insurance Market. Journal of Risk and Financial Management. 2024; 17(4):154. https://doi.org/10.3390/jrfm17040154
Chicago/Turabian StyleRowell, David, and Peter Zweifel. 2024. "Separating Equilibria with Search and Selection Effort: Evidence from the Auto Insurance Market" Journal of Risk and Financial Management 17, no. 4: 154. https://doi.org/10.3390/jrfm17040154
APA StyleRowell, D., & Zweifel, P. (2024). Separating Equilibria with Search and Selection Effort: Evidence from the Auto Insurance Market. Journal of Risk and Financial Management, 17(4), 154. https://doi.org/10.3390/jrfm17040154