
Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting

Abstract
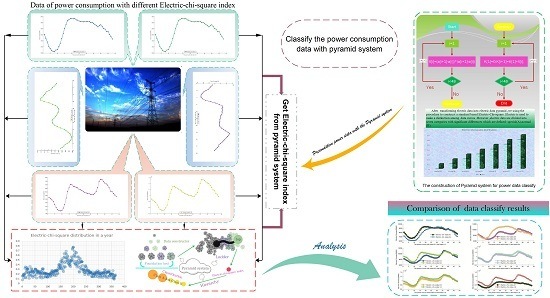
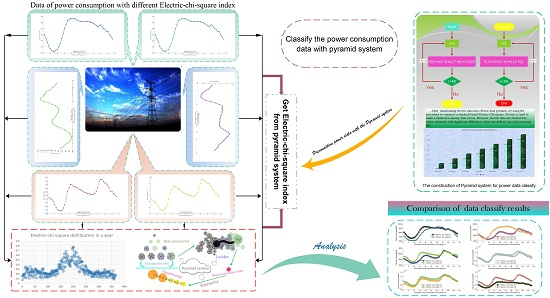
:
1. Introduction
- (1)
- A new feature learning method called Pyramid Data Classification System, designed to recognize and store the features of original data, is built for recurrent neural networks to improve the forecasting accuracy.
- (2)
- A novel hybrid model incorporating ENN and ARSR, which is both an effective and simple tool, has been proposed to deal with the data with different features for performing the EL forecasting.
- (3)
- A new evaluation method has been formed, which is called improved forecasting validity degree (IFVD). It is developed according to its basic form of forecasting validity degree. This evaluation metrics is more sensitive to the trend change of the data and can identify the performance of the model more accurately.
2. Methodology
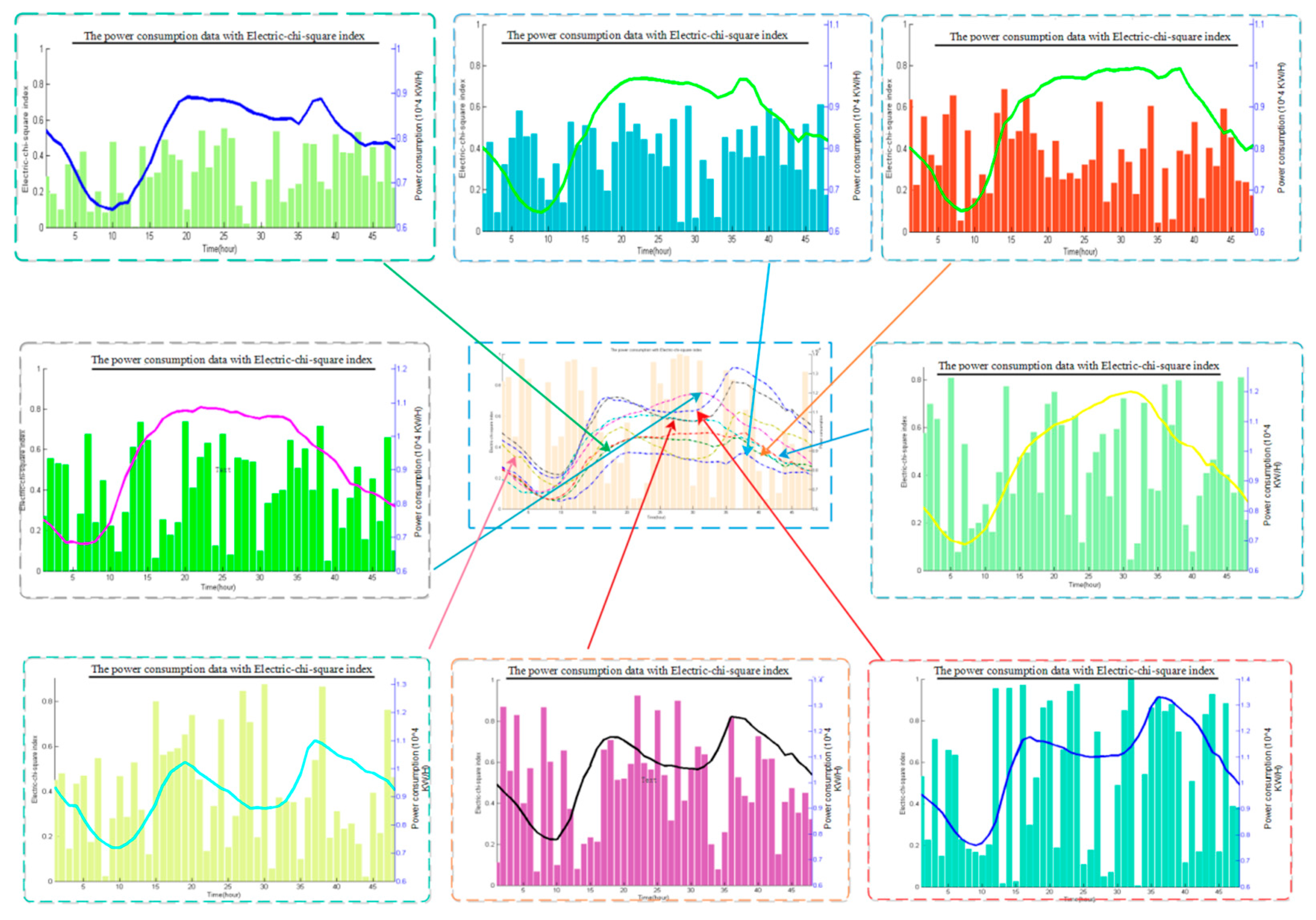
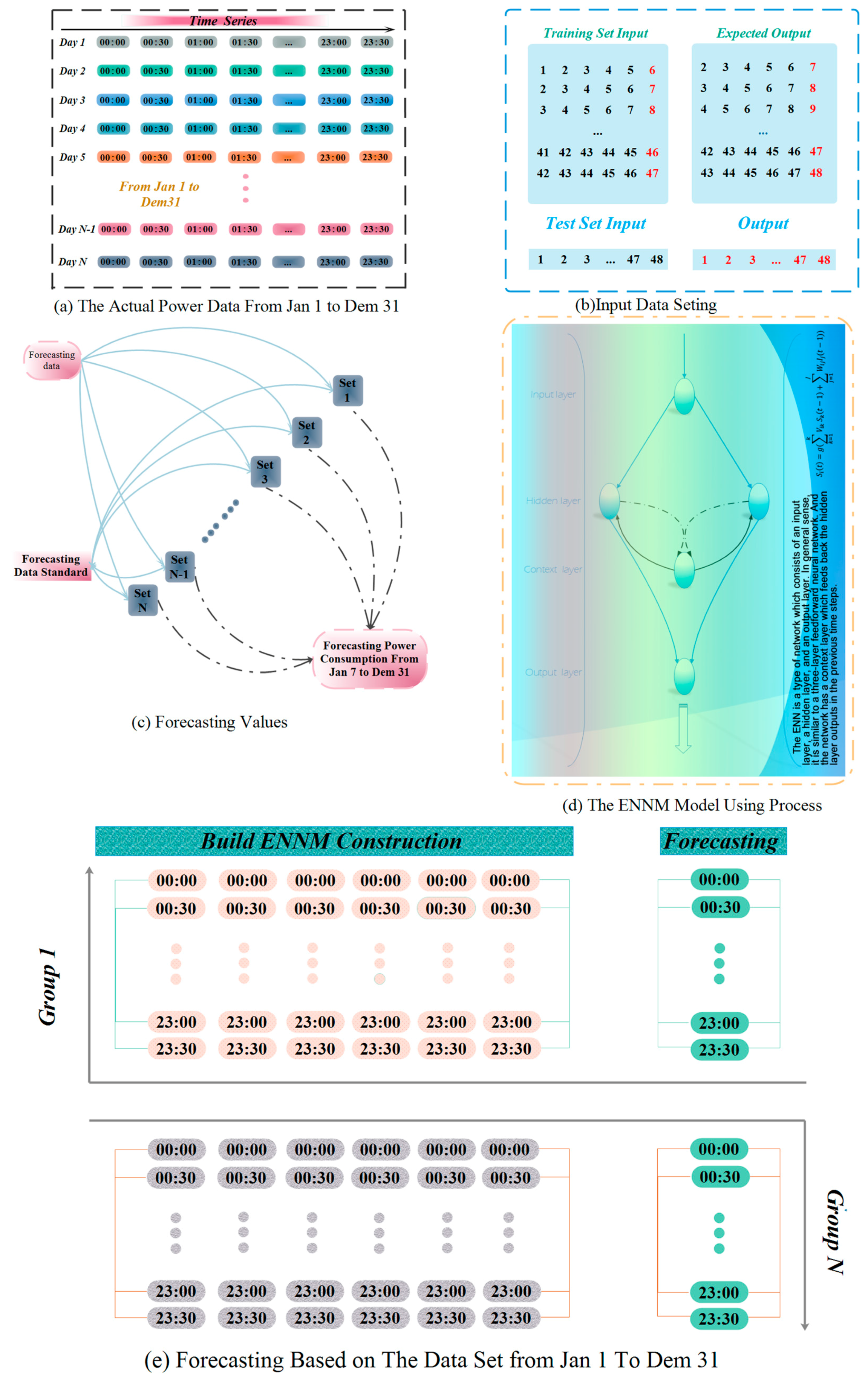
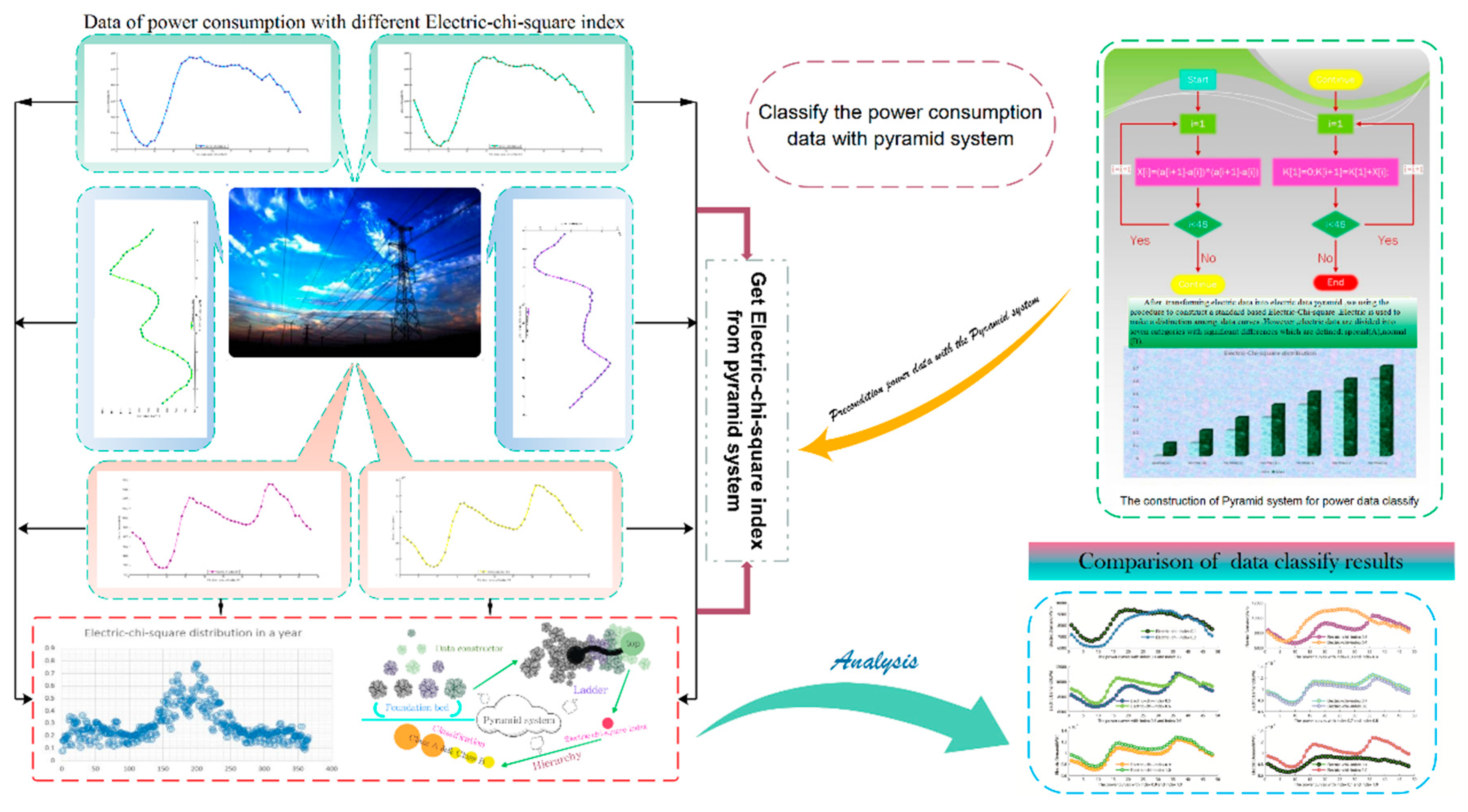
2.1. The Pyramid Data Classification System
| Algorithm: Pyramid System. |
| Input: —a sequence of the sample data. |
| Output: —a sequence of the forecasting data. |
| Parameters: |
| l—The number of sample data to build the Pyramid system in each rolling loop. |
| m—The number of forecasting data in each loop, namely n data to be forecasted in total. |
| —An integer number which is called rolling number and . |
| 1: /* it was able to set up before the program began*/ |
| 2: Build Pyramid/*a Pyramid system with the data set for feature learning */ |
| 3: While Do/* only on the first occasion has it ever been announced */ |
| 4: Calculate /* A developed index of feature learning method based on the data */ |
| 5: Fetch ; |
| 6: Rebuild /* reset the Pyramid system using the data set */ |
| 7: End Return ; |
2.2. Elman Neural Network Model (ENN)
2.2.1. Network Training Algorithm
2.2.2. Number of Network Neurons
- ♦
- Number of input neurons: 4.
- ♦
- Best number of hidden layer neurons: 6.
- ♦
- Number of output neurons: 1.
- ♦
- Value of the learning rate: 0.01.
- ♦
- Number of iterations: 1000.
2.3. Auto-Recurrence Spline Rolling Model
2.4. The Hybrid Model
- Step 1: Set the initial selected individual model set:Set the initial selected data set:Establish different forecasting models and the details have been shown in above sections.where IF is a two-value function with 0–1, which means that if and only if the value of IF is 1 could model 2 obtain the correct value.
- Step 2: Apply the pyramid data classification system to analyze the predictability of the original time series, which forms the prerequisite conditions for accurate forecasting. The Pyramid system can also extract the optimal information from the original data that is used as the input variables of the optimized forecasting models.
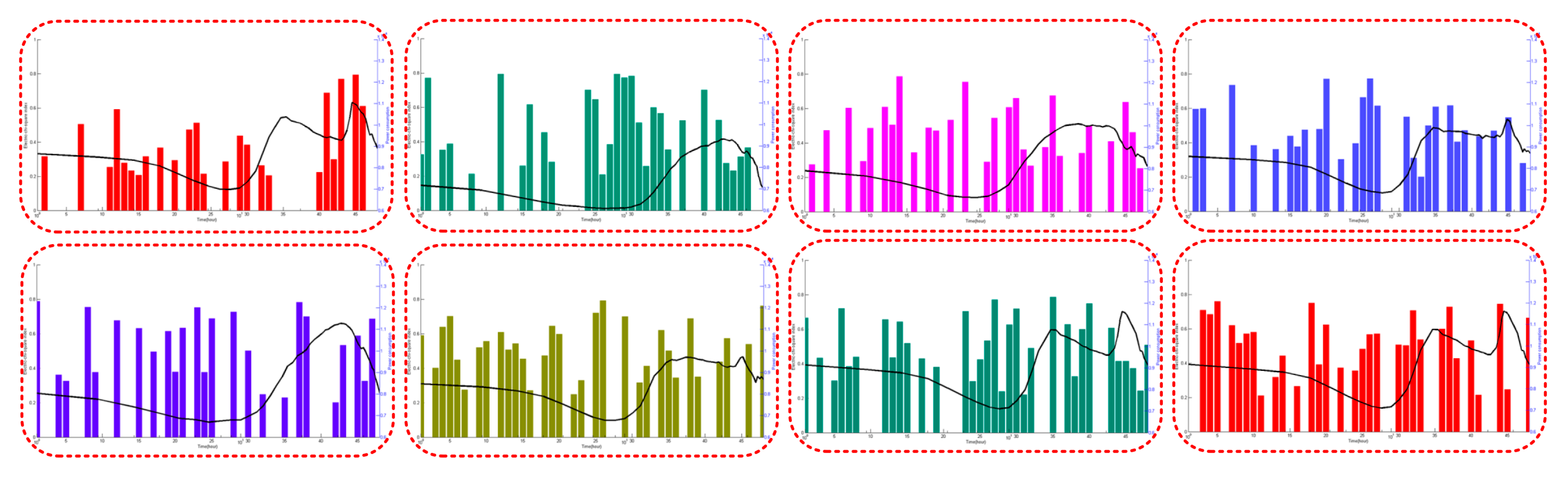
- Step 3: Transfer the data that has been classified into ENN, ARSR and ENN-ARSR to conduct the forecast.where k means the serial number of test data, and i means the value of the Electric-chi-square index.
- Step 4: Update the forecasts with the actual data.
- Step 5: Evaluate the forecasting models using FVD and GCD analysis.
- Step 6: Finally, based on the Electric-chi-square index of the Pyramid data classification system, the forecasting results propose the corresponding rules of the Electric-chi-square index and different forecasting methods.
- Step 7: Establish the forecasting system for application with the conclusion proposed in Section 6.
3. Model Evaluation
4. Experiment
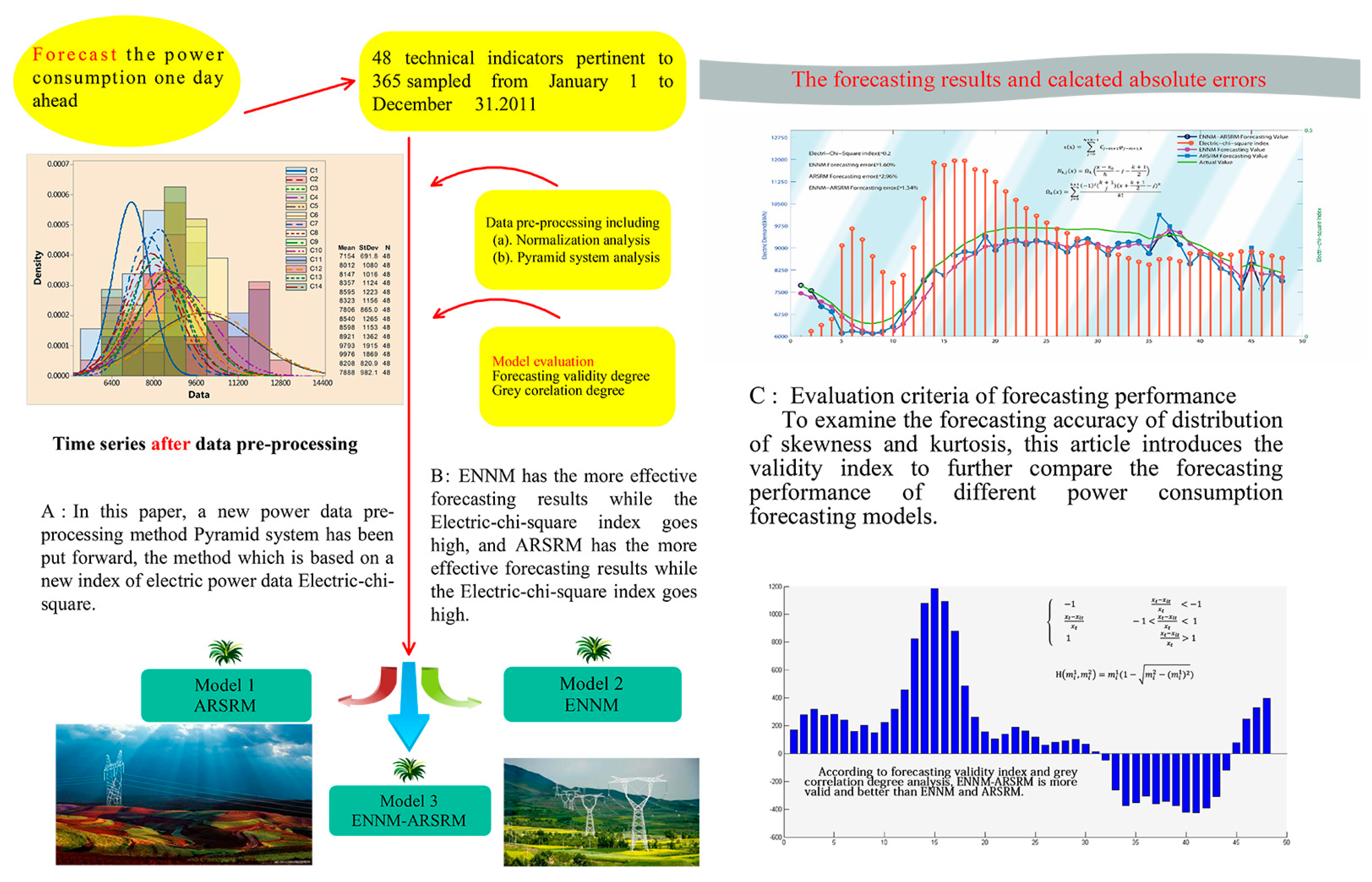
4.1. Data Sets
4.2. Data Preprocessing
4.3. Experimental Setup
4.4. Experiment I
- (1)
- For spring and summer, the hybrid model P-ENN-ARSR has the best forecasting results at 9 and 10 points, respectively and ENN-ARSR achieves the highest forecasting accuracy at 3 and 2 points, respectively. Although P-ENN-ARSR does not have the best MAE or MSE, the hybrid model outperform other models in the aspect of MAPE, FVD and IFVD.
- (2)
- For autumn, in addition to the time of 6:00 am and 8:00 am, P-ENN-ARSR has the best forecasting performance when compared with other models. Similarly, for the time series in winter seven points are forecasted accurately using the hybrid model P-ENN-ARSR. In comparison of MAE, MSE, MAPE, FVD and IFVD, P-ENN-ARSR has the lowest forecasting errors.
4.5. Experiment II
- (1)
- The electric-Chi-Square ranges from 0.1 to 1, and it is clear that P-ENN-ARSR achieves the best MAPE at 5 points when compared with other models. Then, if evaluated by IFVD, the hybrid model proposed achieves the best values at 4 points separately. However, only when the electric-Chi-square is 0.2, P-ENN-ARSR has the highest FVD with the value of 0.9988.
- (2)
- ARIMA belongs to statistical models that are based on a large amount of historical information. SVM is the machine-based forecasting method that is suitable in the STLF. BPNN and ANFIS are both ANNs with strong ability of self-learning and self-adaption. These single models can outperform other ones at certain points; however, the overall forecasting performance of P-ENN-ARSR is the most excellent.
- (3)
- When electric-Chi-square is 0.4, 0.7, 0.8 and 0.9, FVD and IFVD have the similar evaluations results at the model of SVM and ANFIS. In comparison, IFVD has better ability to identify the right trend of the model.
4.6. Experiment III
- (1)
- For FVD-2-order forecasting validity index, ARSR has better forecasting performance than ENN when the index belongs to (0, 0.6). The single ENN performs better than the single ARSR within the index range of (0.7, 1). Among all the proposed models, the hybrid P-ENN-ARSR model has the best performance in the FVD-2-order forecasting validity.
- (2)
- For FVD-3-order forecasting validity index, when comparing the single ARSR and the single ENN, the former model has better forecasting performance than the latter while the indexes belong to (0, 0.5). ARSR achieves better performance than ENN when the index belongs to (0.6, 1). Among all the proposed models, the hybrid P-ENN-ARSR model has the best performance in the FVD-3-order forecasting validity.
- (3)
- When comparing the FVD-3-order forecasting validity indexes with the FVD-2-order forecasting validity indexes, it could be known that the former has much larger differences than the latter. For example, the FVD-2-order forecasting validity index with 0.4 of ENN, ARSR and P-ENN-ARSR is 0.7885, 0.8328 and 0.8662, respectively. The FVD-3-order forecasting validity index with 0.4 of ENN, ARSR and P-ENN-ARSR is 2.0, 1.67 and 1.66, respectively.
5. Discussion
5.1. Forecasting Models
5.1.1. Arguments of ARIMA
5.1.2. Analysis on Structures of Elman Networks
5.2. Trade-Off Based on PDRS
5.2.1. Analysis of Fitting Performance
5.2.2. Analysis of Forecasting Performance
- (1)
- The forecasting performances of the proposed models are worse than the fitting performance of the same models. The PDRS-ENN-1, PDRS-ENN-II and PDRS-ENN-1II are better than ANFIS, SVM and BPNN, and the FVD values of PDRS models have changed by 0.17, 0.21 and 0.29, respectively. The FVD values of BPNN have changed by 0.30, which shows the worst stability among the proposed models.
- (2)
- Though the FVD value of ANFIS have changed by 0.16, showing the best stability among the proposed models, its 3-order-FVD value is only 2.04, which illustrates that the good stability does not generate good forecasting performance in WP, and the PDRS-ENN-I shows the best performance of trade-off between fitting and forecasting among the proposed models in WP.
- (3)
- All of the proposed forecasting models are data-driven methods, which makes full use of the historical data through feature learning. All of these forecasting models assume that history will repeat itself. The models of ANFIS, SVM and BPNN forecast future values supposing that the independent variables could explain the variations in dependent variables; in addition, these models assume that the relationship between dependent and independent variables will remain valid in the future; however, compared with ANFIS, SVM and BPNN, ENN has a more “context layer” part. Besides, PDRS helps ENN extract the features of WP data, and help ENN avoid the local optimum in training and testing. Therefore, the PDRS models have better performance both in fitting and forecasting.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| EL | Electrical Load |
| ML | Machine Learning |
| ANN | Artificial Neural Network |
| GRACH | Generalized AutoRegressive Conditional Heteroskedasticity |
| TE | Transmission Error |
| LTLF | Long-Term Load Forecasting |
| SM | Statistical Methods |
| HA | Hybrid Approaches |
| ARIMA | Autoregressive Integrated Moving Average |
| BIC | Bayesian Information Criterion |
| AICC | Corrected Akaike Information Criterion |
| ANN | Artificial Neural Networks |
| RFNN | Random Fuzzy Neural Network |
| FEEMD | Fast Ensemble Empirical Mode Decomposition |
| WT | Wavelet Transform |
| PSO | Particle Swarm Optimization |
| ARSR | Auto-Recurrence Spline Rolling |
| DL | deep learning |
| SVM | support vector machine |
| WS | wind speeds |
| WP | Wind Power |
| EWDAI | Electric Wind Direction Anemometer Indicator |
| STLF | Short-Term Load Forecasting |
| PA | Physical Approaches |
| MLA | Machine Learning Approaches |
| NWP | Numerical Weather Prediction |
| ARMA | Auto Regressive Moving Average |
| AIC | Akaike’s Information Criterion |
| GNN | Generalized Neural Network |
| CG | conjugate gradient |
| SDA | Secondary Decomposition Algorithm |
| WPD | Wavelet Packet Decomposition |
| GM | Grey Model |
| PDRS | Pyramid Data Recognize System |
| FVD | Forecasting Validity Degree |
| BP | back propagation |
| ALR | adaptive learning rate |
| VSTLF | Very Short Term Load Forecasting |
References
- Danny, H.W.; Li, Y.; Liu, C.; Joseph, C.L. Zero energy buildings and sustainable development implications—A review. Energy 2013, 54, 1–10. [Google Scholar]
- Yong, K.; Kim, J.; Lee, J.; Ryu, M.; Lee, J. An assessment of wind energy potential at the demonstration offshore wind farm in Korea. Energy 2012, 46, 555–563. [Google Scholar]
- Shiu, A.; LamK, P.L. Electricity consumption and economic growth in China. Energy Policy 2004, 32, 47–54. [Google Scholar] [CrossRef]
- Chen, J. Development of offshore wind power in China. Renew. Sustain. Energy Rev. 2011, 15, 5013–5020. [Google Scholar] [CrossRef]
- Ferraro, P.; Crisostomi, E.; Tucci, M.; Raugi, M. Comparison and clustering analysis of the daily electrical load in eight European countries Original Research Article. Electr. Power Syst. Res. 2016, 141, 114–123. [Google Scholar] [CrossRef]
- Harmsen, J.; Patel, M.K. The impact of copper scarcity on the efficiency of 2050 global renewable energy scenarios. Energy 2013, 50, 62–73. [Google Scholar] [CrossRef]
- Koprinska, I.; Rana, M.; Agelidis, V. Correlation and instance based feature selection for electricity load forecasting. Knowl.-Based Syst. 2015, 82, 29–40. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Liang, X.F.; Li, Y.F. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 2015, 157, 183–194. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Q.R.; Wang, J.Z.; Liu, M. A rolling grey model optimized by particle swarm optimization in economic prediction. Comput. Intell. 2014, 32, 391–419. [Google Scholar] [CrossRef]
- Feinberg, E.A.; Genethliou, D. Load Forecasting. Power Electron. Power Syst. 2005, 269–285. [Google Scholar] [CrossRef]
- Bowden, N.; Payne, J. Short term forecasting of electricity prices for MISO hubs: Evidence from ARIMA-EGARCH models. Energy Econom. 2008, 30, 3186–3197. [Google Scholar] [CrossRef]
- Wong, W.K.; Guo, Z.X. Chapter 9—Intelligent Sales Forecasting for Fashion Retailing Using Harmony Search Algorithms and Extreme Learning Machines Optimizing Decision Making in the Apparel Supply Chain Using Artificial Intelligence (AI); Elsevier: Amsterdam, The Netherlands, 2013; pp. 170–195. [Google Scholar]
- Pilling, C.; Dodds, V.; Cranston, M.; Price, D.; Harrison, T.; How, A. Chapter 9—Flood Forecasting—A National Overview for Great Britain. Flood Forecast. 2016. [Google Scholar] [CrossRef]
- Zhang, J.; Draxl, C.; Hopson, T.; Monache, L.D.; Vanvyve, E.; Hodege, B.M. Comparison of numerical weather prediction based deterministic and probabilistic wind resource assessment methods. Appl. Energy 2015, 156, 528–541. [Google Scholar] [CrossRef]
- Sile, T.; Bekere, L.; Frisfelde, D.C.; Sennikovs, J.; Bethers, U. Verification of numerical weather prediction model results for energy applications in Latvia. Energy Procedia 2014, 59, 213–220. [Google Scholar] [CrossRef]
- Wilson, H.W. Community cleverness required. Nature 2008, 455, 1. [Google Scholar]
- Graff, M.; Pena, R.; Medina, A.; Escalante, H.J. Wind speed forecasting using a portfolio of forecasters. Renew. Energy 2014, 68, 550–559. [Google Scholar] [CrossRef]
- Zhang, J.; Li, H.; Gao, Q.; Wang, H.; Luo, Y. Detecting anomalies from big network traffic data using an adaptive detection approach. Inf. Sci. 2015, 318, 91–110. [Google Scholar] [CrossRef]
- Zárate-Miñano, R.; Anghel, M.; Milano, F. Continuous wind speed models based on stochastic differential equations Original Research Article. Appl. Energy 2013, 104, 42–49. [Google Scholar] [CrossRef]
- Iversen, E.B.; Morales, J.M.; Møller, J.; Madsen, H. Short-term probabilistic forecasting of wind speed using stochastic differential equations Original Research Article. Int. J. Forecast. 2016, 32, 981–990. [Google Scholar] [CrossRef]
- Juan, A.A.; Faulin, J.; Grasman, S.E.; Rabe, M.; Figueira, G. A review of simheuristics: Extending metaheuristics to deal with stochastic combinatorial optimization problems Original Research Article. Oper. Res. Perspect. 2015, 2, 62–72. [Google Scholar] [CrossRef]
- Wu, Z.; Tian, J.; Ugon, J.; Zhang, L. Global optimality conditions and optimization methods for constrained polynomial programming problems Original Research Article. Appl. Math. Comput. 2015, 262, 312–325. [Google Scholar]
- Luong, L.H.S.; Spedding, T.A. Neural-network system for predicting maching behavior. J. Mater. Process. Technol. 1995, 52, 585–591. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Liang, X.F.; Li, Y.F. New wind speed forecasting approaches using fast ensemble empirical model decomposition, genetic algorithm, mind evolutionary algorithm and artificial neural networks. Renew. Energy 2015, 83, 1066–1075. [Google Scholar] [CrossRef]
- Hu, J.M.; Wang, J.Z.; Zeng, G.W. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Hastenrath, S. Climate and Climate Change | Climate Prediction: Empirical and Numerical; Encyclopedia of Atmosperic Science: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Pfeffer, R.L. Reference Module in Earth Systems and Environmental Sciences, from Encyclopedia of Atmospheric Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 26–32. [Google Scholar]
- Yadav, A.K.; Chandel, S.S. Solar radiation prediction using Artificial Neural Network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Sîrb, L. The Implications of Fuzzy Logic in Qualitative Mathematical Modeling of Some Key Aspects Related to the Sustainability Issues around “Roşia Montană Project”. Procedia Econ. Financ. 2013, 6, 372–384. [Google Scholar] [CrossRef]
- Falomir, Z.; Olteţeanu, A. Logics based on qualitative descriptors for scene understanding. Neurocomputing 2015, 161, 3–16. [Google Scholar] [CrossRef]
- Karatop, B.; Kubat, C.; Uygun, Ö. Talent management in manufacturing system using fuzzy logic approach. Comput. Ind. Eng. 2015, 86, 127–136. [Google Scholar] [CrossRef]
- Pani, A.K.; Mohanta, H.K. Soft sensing of particle size in a grinding process: Application of support vector regression, fuzzy inference and adaptive neuro fuzzy inference techniques for online monitoring of cement fineness. Powder Technol. 2014, 264, 484–497. [Google Scholar] [CrossRef]
- Chou, J.; Hsu, Y.; Lin, L. Smart meter monitoring and data mining techniques for predicting refrigeration system performance. Expert Syst. Appl. 2014, 41, 2144–2156. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Li, Y. Comparison of new hybrid FEEMD-MLP, FEEMD-ANFIS, Wavelet Packet-MLP and Wavelet Packet-ANFIS for wind speed predictions. Energy Convers. Manag. 2015, 89, 1–11. [Google Scholar] [CrossRef]
- Sarkheyli, A.; Zain, A.M.; Sharif, S. Robust optimization of ANFIS based on a new modified GA. Neurocomputing 2015, 166, 357–366. [Google Scholar] [CrossRef]
- Zhao, M.; Ji, J.C. Nonlinear torsional vibrations of a wind turbine gearbox. Appl. Math. Model. 2015, 39, 4928–4950. [Google Scholar] [CrossRef]
- Zimroz, R.; Bartelmus, W.; Barszcz, T.; Urbanek, J. Diagnostics of bearings in presence of strong operating conditions non-stationarity—A procedure of load-dependent features processing with application to wind turbine bearings. Mech. Syst. Signal Process. 2014, 46, 16–27. [Google Scholar] [CrossRef]
- Misra, S.; Bera, S.; Ojha, T.; Mouftah, T.H.; Anpalagan, M.A. ENTRUST: Energy trading under uncertainty in smart grid systems. Comput. Netw. 2016, 110, 232–242. [Google Scholar] [CrossRef]
- Wang, J.; Wang, H.; Guo, L. Analysis of effect of random perturbation on dynamic response of gear transmission system. Chaos Solitons Fractals 2014, 68, 78–88. [Google Scholar] [CrossRef]
- Sepasi, S.; Reihani, E.; Howlader, A.M.; Roose, L.R.; Matsuura, M.M. Very short term load forecasting of a distribution system with high pv penetration. Renew. Energy 2017, 106, 142–148. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Suganthan, P.N.; Amaratunga, G.A.J. Empirical mode decomposition based ensemble deep learning for load demand time series forecasting. Appl. Soft Comput. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Chen, T.; Peng, Z. Load-frequency control with short-term load prediction. Power Syst. Power Plant Control 1987, 1, 205–208. [Google Scholar]
- Punantapong, B.; Punantapong, P.; Punantapong, I. Improving a grid-based energy efficiency by using service sharing strategies. Energy Procedia 2015, 79, 910–916. [Google Scholar] [CrossRef]
- Sandels, C.; Widén, J.; Nordström, L.; Andersson, E. Day-ahead predictions of electricity consumption in a swedish office building from weather, occupancy, and temporal data. Energy Build. 2015, 108, 279–290. [Google Scholar] [CrossRef]
- Kow, K.W.; Wong, Y.W.; Rajkumar, R.K.; Rajkumar, R.K. A review on performance of artificial intelligence and conventional method in mitigating PV grid-tied related power quality events. Renew. Sustain. Energy Rev. 2016, 56, 334–346. [Google Scholar] [CrossRef]
- Linke, H.; Börner, J.; Heß, R. Table of Appendices. Cylind. Gears 2016, 1, 709–727, 729–767, 769–775, 777–787, 789, 791–833 and 835. [Google Scholar]
- Yang, C.; Chen, J. A Multi-objective Evolutionary Algorithm of Marriage in Honey Bees Optimization Based on the Local Particle Swarm Optimization. Ifac. Proc. 2008, 41, 12330–12335. [Google Scholar] [CrossRef]
- Ali, D.; Omid, O.; Hemen, S. Short-term electric load and temperature forecasting using wavelet echo state networks with neural reconstruction. Energy 2013, 57, 382–401. [Google Scholar]
- Yao, S.J.; Song, Y.H.; Zang, L.Z.; Cheng, X.Y. Wavelet transform and neural networksfor short-term electrical load forecasting. Energy Convers. Manag. 2000, 41, 1975–1988. [Google Scholar] [CrossRef]
- Rocha, R.A.J.; Alves, S.A. Feature extraction viamultiresolution analysis for short-term load forecasting. IEEE Trans. Power Syst. 2005, 20, 189–198. [Google Scholar]
- Key, E.M.; Lebo, M.J. Pooled Cross-Sectional and Time Series Analyses. In Political Science International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 515–521. [Google Scholar]
- Sousounis, P.J. Synoptic Meteorology | Lake-Effect Storms Reference Module in Earth Systems and Environmental Sciences, from Encyclopedia of Atmospheric Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 370–378. [Google Scholar]
- Bolund, E.; Hayward, A.; Lummaa, V. Life-History Evolution, Human. Reference Module in Life Sciences. In Encyclopedia of Evolutionary Biology; Elsevier: Amsterdam, The Netherlands, 2016; pp. 328–334. [Google Scholar]
- Chandra, R.; Zhang, M.J. Cooperative coevolution of Elman recurrent neural networks for chaotic time series prediction. Neurocomputing 2012, 86, 116–123. [Google Scholar] [CrossRef]
- Elman, J. Finding structure in time. Cognitive 1990, 15, 179–211. [Google Scholar] [CrossRef]
- Wang, R.Y.; Fang, B.R. Spline interpolation differential model prediction method for one variable system. J. HoHai Univ. 1992, 20, 47–53. [Google Scholar]
- Wang, M.T. The exploration of the normal form of the index of forecasting validity. Forecasting 1998, 17, 39–40. [Google Scholar]
- Mohandes, M.; Rehman, S.; Rahman, S.M. Estimation of wind speed profile using adaptive neuro-fuzzy inference system (ANFIS). Appl. Energy 2011, 88, 4024–4032. [Google Scholar] [CrossRef]
- Bouzgou, H.; Benoudjit, N. Multiple architecture system for wind speed prediction. Appl. Energy 2011, 88, 2463–2471. [Google Scholar] [CrossRef]
- Grau, J.B.; Antón, J.M.; Andina, D.; Tarquis, A.M.; Martín, J.J. Mathematical Models to Elaborate Plans for Adaptation of Rural Communities to Climate Change Reference Module in Food Science. In Encyclopedia of Agriculture and Food Systems; Elsevier: Amsterdam, The Netherlands, 2014; pp. 193–222. [Google Scholar]
- Thomassey, B.S. Chapter 8—Intelligent demand forecasting systems for fast fashion. In Information Systems for the Fashion and Apparel Industry; Elsevier: Amsterdam, The Netherlands, 2016; pp. 145–161. [Google Scholar]
- Lasek, A.; Cercone, N.; Saunders, J. Chapter 17—Smart restaurants: Survey on customer demand and sales forecasting. In Smart Cities and Homes; Elsevier: Amsterdam, The Netherlands, 2016; pp. 361–386. [Google Scholar]
- Kwon, H.; Lyu, B.; Tak, K.; Lee, J.; Moon, I. Optimization of Petrochemical Process Planning using Naphtha Price Forecasting and Process Modeling. Comput. Aided Chem. Eng. 2015, 37, 2039–2044. [Google Scholar]
- Stock, J.H. Time Series: Economic Forecasting. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 337–340. [Google Scholar]
- Jiang, Y.; Palash, W.; Akanda, A.S.; Small, D.L.; Islam, S. Chapter 14—A Simple Streamflow Forecasting Scheme for the Ganges Basin. In Flood Forecasting; Elsevier: Amsterdam, The Netherlands, 2016; pp. 399–420. [Google Scholar]
- Wilks, D.S. Chapter 7—Statistical Forecasting. Int. Geophys. 2011, 100, 215–300. [Google Scholar]
- Steinherz, H.H.; Pedreira, C.E.; Souza, R.C. Neural Networks for Short-Term Load Forecasting: A Review and Evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar]
- Pappas, S.S.; Karampelas, E.P.; Karamousantas, D.C.; Katsikas, S.K.; Chatzarakis, G.E.; Skafidas, P.D. Electricity demand load forecasting of the Hellenic power system using an ARMA model. Electr. Power Syst. Res. 2010, 80, 256–264. [Google Scholar] [CrossRef]
- Calanca, P. Weather Forecasting Applications in Agriculture Reference Module in Food Science. In Encyclopedia of Agriculture and Food Systems; Elsevier: Amsterdam, The Netherlands, 2014; pp. 437–449. [Google Scholar]
- Li, J.P.; Ding, R.Q. WEATHER FORECASTING | Seasonal and Interannual Weather Prediction Reference Module in Earth Systems and Environmental Sciences. In Encyclopedia of Atmospheric Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 303–312, Current as of 2 September 2015. [Google Scholar]
- Luca, G.; Ghio, A.; Anguita, D. Energy Load Forecasting Using Empirical Mode Decomposition and Support Vector Regression. IEEE Trans. Smart Grid 2013, 4, 549–556. [Google Scholar]
- Juen, C.B.; Chang, M.W.; Lin, C.J. Load forecasting using support vector machines: A study on EUNITE Competition 2001. IEEE Trans. Power Syst. 2004, 19, 1821–1830. [Google Scholar]
- Chaturvedi, D.K.; Sinha, A.P.; Malik, O.P. Short term load forecast using fuzzy logic and wavelet transform integrated generalized neural network. Electr. Power Energy Syst. 2015, 67, 230–237. [Google Scholar] [CrossRef]
- Lou, C.W.; Dong, M.C. A novel random fuzzy neural networks for tackling uncertainties of electric load forecasting. Electr. Power Energy Syst. 2015, 73, 34–44. [Google Scholar] [CrossRef]
- Koopman, S.J.; Commandeur, J.J.F. Time Series: State Space Methods. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 354–361. [Google Scholar]
- Nfaoui, H. Wind Energy Potential. Reference Module in Earth Systems and Environmental Sciences. In Comprehensive Renewable Energy; Elsevier: Amsterdam, The Netherlands, 2012; Volume 2, pp. 73–92, Current as of 30 July 2012. [Google Scholar]
- Jiménez, F.; Kafarov, V.; Nuñez, M. Computer-aided forecast of catalytic activity in an hydrotreating industrial process using artificial neural network, fuzzy logic and statistics tools. Comput. Aided Chem. Eng. 2006, 21, 545–550. [Google Scholar]
- Ferraty, F.; Sarda, P.; Vieu, P. Statistical Analysis of Functional Data. In International Encyclopedia of Education, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2010; pp. 417–425. [Google Scholar]
- Lehnertz, K. SEIZURES | Seizure Prediction. In Encyclopedia of Basic Epilepsy Research; Elsevier: Amsterdam, The Netherlands, 2009; pp. 1314–1320. [Google Scholar]
- Soliman, S.A.; Al-Kandari, A.M. 1—Mathematical Background and State of the Art. Electrical Load Forecasting; Elsevier: Amsterdam, The Netherlands, 2010; pp. 1–44. [Google Scholar]
- Louka, P. Improvements in wind speed forecasts for wind power prediction. Purposes using Kalman filtering. J. Wind Eng. Ind. Aerodyn. 2008, 96, 2348–2362. [Google Scholar] [CrossRef]
- Tao, D.; Xiuli, W.; Xifan, W. A combined model of wavelet and neural network for short-term load forecasting. In Proceedings of the IEEE International Conference on Power System Technology, Kunming, China, 13–17 October 2002; pp. 2331–2335. [Google Scholar]
- Wang, R.H.; Guo, Q.J.; Zhu, C.G.; Li, C.J. Multivariate spline approximation of the signed distance function. Comput. Appl. Math. 2014, 265, 276–289. [Google Scholar] [CrossRef]
- Hong, W.C. Electric load forecasting by seasonal recurrent SVR (support vector regression) with chaotic artificial bee colony algorithm. Energy 2011, 36, 5568–5578. [Google Scholar] [CrossRef]
- Nie, H.Z.; Liu, G.H.; Liu, X.M.; Wang, Y. Hybrid of ARIMA and SVMs for short-term load forecasting. Energy Procedia 2012, 86, 1455–1460. [Google Scholar] [CrossRef]
- Bahrami, S.; Hooshmand, R.A.; Parastegari, M. Short term electric load forecasting by wavelet transform and grey model improved by PSO (particle swarm optimization) algorithm. Energy 2014, 72, 434–442. [Google Scholar] [CrossRef]
- Hodge, B.M.; Milligan, M. Wind power forecasting error distributions over multiple timescales. In Proceedings of the IEEE Power and Energy Society General Meeting, Detroit, MI, USA, 24–29 July 2011; pp. 1–8. [Google Scholar]
- Sideratos, G.; Hatziargyriou, N.D. An Advanced Statistical Method for Wind Power Forecasting. IEEE Trans. Power Syst. 2007, 22, 258–265. [Google Scholar] [CrossRef]
- Foley, A.M.; Leahy, P.G.; Mckeogh, E.J. Wind power forecasting & prediction methods. In Proceedings of the International Conference on Environment and Electrical Engineering, Prague, Czech Republic, 16–19 May 2010; pp. 61–64. [Google Scholar]
- Shamshirband, S.; Petkovic, D.; Anuar, N.B.; Kiah, M.L.; Akib, S.; Gani, A.; Cojbasic, Z.; Nikolic, V. Sensorless estimation of wind speed by adaptive neuro-fuzzy methodology. Electr. Power Energy Syst. 2014, 62, 490–495. [Google Scholar] [CrossRef]
- BP p.l.c. BP Statistical Review of World Energy; BP p.l.c.: London, UK, 2015. [Google Scholar]
- BP p.l.c. BP Technology Outlook; BP p.l.c.: London, UK, 2015. [Google Scholar]
- Kariniotakis, G.N.; Stavrakakis, G.S.; Nogaret, E.F. Wind power forecasting using advanced neural network models. IEEE Trans. Energy Convers. 1997, 11, 762–767. [Google Scholar] [CrossRef]
- Pedersen, R.; Santos, I.F.; Hede, I.A. Advantages and drawbacks of applying periodic time-variant modal analysis to spur gear dynamics. Mech. Syst. Signal Process. 2010, 24, 1495–1508. [Google Scholar] [CrossRef]
- Li, Y.; Castro, A.M.; Martin, J.E.; Sinokrot, T.; Prescott, W.; Carrica, P.M. Coupled computational fluid dynamics/multibody dynamics method for wind turbine aero-servo-elastic simulation including drivetrain dynamics. Renew. Energy 2017, 101, 1037–1051. [Google Scholar] [CrossRef]
- Mo, S.; Zhang, Y.; Wu, Q.; Matsumura, S.; Houjoh, H. Load sharing behavior analysis method of wind turbine gearbox in consideration of multiple-errors. Renew. Energy 2016, 97, 481–491. [Google Scholar] [CrossRef]
- Mabrouk, I.B.; El Hami, A.; Walha, L.; Zghal, B.; Haddar, M. Dynamic vibrations in wind energy systems: Application to vertical axis wind turbine. Mech. Syst. Signal Process. 2017, 85, 396–414. [Google Scholar] [CrossRef]
- Park, Y.; Lee, G.; Song, J.; Nam, Y.; Nam, J. Optimal Design of Wind Turbine Gearbox using Helix Modification. Eng. Agric. Environ. Food 2013, 6, 147–151. [Google Scholar] [CrossRef]
- Hameed, Z.; Hong, Y.S.; Cho, Y.M.; Ahn, S.H.; Song, C.K. Condition monitoring and fault detection of wind turbines and related algorithms: A review. Renew. Sustain. Energy Rev. 2009, 13, 1–39. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | |
| The value of the data is in each pyramid. The value is a double figure. A double value containing the total of the real load data on the previous record. A seasonal data series is put into the bottom of the pyramid. | |
| Operations | |
| Constructor | |
| Initial values: | The value of the data to be measured. |
| Process: | Initialize the data value. Specify the figure of the data in each foundation bed of the pyramid. |
| Foundation bed | |
| Input: | None |
| Preconditions: | None |
| Process: | Import the data and compute the variance of the adjacent data. |
| Output: | None |
| Postconditions: | None |
| Ladder | |
| Input: | None |
| Preconditions: | None |
| Process: | Compute the figure sum of the variance in the foundation bed. |
| Specify the average of the sum. | |
| Do multiply operation on the sum and the average. | |
| Output: | Return the final result of each pyramid. |
| Postconditions: | None |
| Hierarchy | |
| Input: | None |
| Preconditions: | None |
| Process: | Quote the list of the top values of the pyramid to compute the Electric-Chi-Square index. |
| FVD the data based on the Electric-Chi-Square index. | |
| Output: | None |
| Postconditions: | None |
| Number of Hidden Layer | Results of One-Step Ahead Forecasting | Number of Hidden Layer | Results of One-Step Ahead Forecasting | ||||
|---|---|---|---|---|---|---|---|
| MAPE (%) | MAE (m/s) | MSE (104 m/s2) | MAPE (%) | MAE (m/s) | MSE (104 m/s2) | ||
| 4 | 6.95 | 619.34 | 7.1127 | 10 | 7.01 | 629.35 | 7.0283 |
| 5 | 6.92 | 615.89 | 7.1183 | 11 | 6.77 | 606.52 | 6.2559 |
| 6 | 6.61 | 591.30 | 6.1117 | 12 | 6.80 | 609.64 | 6.4435 |
| 7 | 6.96 | 621.77 | 6.9602 | 13 | 6.70 | 600.17 | 6.1422 |
| 8 | 6.93 | 621.15 | 6.5277 | 14 | 6.63 | 592.31 | 6.0193 |
| 9 | 6.75 | 604.03 | 6.2331 | 15 | 6.74 | 605.14 | 6.3197 |
| Metric | Definition | Equation |
|---|---|---|
| MAE | The average absolute forecast error of n times forecast results | (21) |
| MSE | The average of the prediction error squares | (22) |
| MAPE | The average of absolute error | (23) |
| Class | Electric-Chi-Square | Forecasting Model | |
|---|---|---|---|
| ENN | ARSR | ||
| Normal | 0.1 | 2.75% | 1.99% |
| 0.2 | 3.56% | 2.60% | |
| 0.3 | 3.02% | 2.44% | |
| 0.4 | 3.02% | 2.44% | |
| 0.5 | 3.53% | 3.08% | |
| Special | 0.6 | 3.00% | 3.41% |
| 0.7 | 3.28% | 3.56% | |
| 0.8 | 3.21% | 4.44% | |
| 0.9 | 4.43% | 4.75% | |
| 1.0 | 3.62% | 4.54% | |
| Actual Time | Electric-Chi-Square | Methods | Actual Time | Electric-Chi-Square | Methods | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARSR | ENN | ENN-ARSR | P-ENN-ARSR | ARSR | ENN | ENN-ARSR | P-ENN-ARSR | ||||
| Spring | Summer | ||||||||||
| 2:00:00 | 0.47 | 3.46% | 2.29% | 1.02% | 2.29% | 2:00:00 | 0.16 | 2.77% | 5.88% | 3.84% | 2.77% |
| 4:00:00 | 0.64 | 0.63% | 0.55% | 2.27% | 0.55% | 4:00:00 | 0.24 | 1.19% | 6.17% | 4.56% | 1.19% |
| 6:00:00 | 0.4 | 3.98% | 4.98% | 4.05% | 3.98% | 6:00:00 | 0.34 | 5.48% | 4.56% | 3.64% | 4.56% |
| 8:00:00 | 0.6 | 6.71% | 9.60% | 1.28% | 6.71% | 8:00:00 | 1.14 | 6.22% | 3.44% | 2.84% | 3.44% |
| 10:00:00 | 0.69 | 2.64% | 3.23% | 4.92% | 2.64% | 10:00:00 | 0.89 | 2.64% | 7.65% | 4.30% | 2.64% |
| 12:00:00 | 0.58 | 0.26% | 6.57% | 1.62% | 0.26% | 12:00:00 | 0.74 | 0.31% | 6.41% | 4.32% | 0.31% |
| 14:00:00 | 0.5 | 1.04% | 10.95% | 6.12% | 1.04% | 14:00:00 | 0.63 | 0.56% | 6.72% | 4.53% | 0.56% |
| 16:00:00 | 0.43 | 2.95% | 8.60% | 1.79% | 2.95% | 16:00:00 | 0.54 | 1.05% | 6.67% | 4.24% | 1.05% |
| 18:00:00 | 0.64 | 5.17% | 5.04% | 5.10% | 5.04% | 18:00:00 | 0.74 | 4.63% | 5.64% | 6.30% | 4.63% |
| 20:00:00 | 0.58 | 1.15% | 2.10% | 1.26% | 1.15% | 20:00:00 | 0.67 | 0.35% | 4.42% | 1.39% | 0.35% |
| 22:00:00 | 0.54 | 2.35% | 0.17% | 1.92% | 0.17% | 22:00:00 | 0.66 | 4.18% | 7.10% | 4.73% | 4.18% |
| 00:00:00 | 0.51 | 3.80% | 1.05% | 0.61% | 1.05% | 00:00:00 | 0.63 | 1.52% | 7.83% | 1.57% | 1.52% |
| MAE | 4953.503 | 4739.778 | 1911.145 | 3204.385 | MAE | 2971.062 | 1138.262 | 2970.035 | 885.6493 | ||
| MSE | 899.5068 | 1117.057 | 1362.925 | 6786.523 | MSE | 549.7415 | 8507.127 | 5605.595 | 9296.089 | ||
| MAPE | 2.85% | 4.59% | 2.66% | 2.32% | MAPE | 2.58% | 6.04% | 3.85% | 2.27% | ||
| FVD | 0.8297 | 0.8625 | 0.8935 | 0.9722 | FVD | 0.7991 | 0.7545 | 0.8617 | 0.9635 | ||
| IFVD | 0.8569 | 0.7385 | 0.8820 | 0.9711 | IFVD | 0.8348 | 0.7440 | 0.8604 | 0.8168 | ||
| Actual Time | Electric-Chi-Square | Methods | Actual Time | Electric-Chi-Square | Methods | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARSR | ENN | ENN-ARSR | P-ENN-ARSR | ARSR | ENN | ENN-ARSR | P-ENN-ARSR | ||||
| Autumn | Winter | ||||||||||
| 2:00:00 | 0.23 | 2.53% | 3.26% | 0.80% | 2.53% | 2:00:00 | 0.2 | 2.89% | 13.44% | 4.09% | 2.89% |
| 4:00:00 | 0.54 | 0.17% | 3.41% | 4.05% | 0.17% | 4:00:00 | 0.5 | 0.40% | 14.76% | 3.88% | 0.40% |
| 6:00:00 | 0.55 | 7.67% | 2.10% | 3.00% | 2.10% | 6:00:00 | 0.54 | 7.43% | 31.37% | 3.60% | 7.43% |
| 8:00:00 | 1.85 | 4.93% | 5.40% | 3.06% | 4.93% | 8:00:00 | 1.7 | 4.04% | 3.69% | 5.80% | 4.04% |
| 10:00:00 | 1.48 | 2.89% | 0.45% | 4.41% | 0.45% | 10:00:00 | 1.35 | 3.76% | 3.09% | 1.77% | 1.76% |
| 12:00:00 | 1.26 | 1.30% | 4.10% | 5.14% | 1.30% | 12:00:00 | 1.14 | 0.92% | 2.73% | 2.12% | 0.92% |
| 14:00:00 | 1.08 | 0.24% | 6.77% | 2.33% | 0.24% | 14:00:00 | 0.97 | 0.04% | 4.92% | 0.79% | 0.04% |
| 16:00:00 | 0.94 | 3.84% | 3.79% | 4.41% | 3.79% | 16:00:00 | 0.84 | 2.39% | 2.12% | 6.27% | 2.39% |
| 18:00:00 | 1.18 | 6.74% | 2.59% | 2.77% | 2.59% | 18:00:00 | 1.17 | 7.02% | 3.16% | 4.30% | 7.02% |
| 20:00:00 | 1.07 | 1.10% | 0.29% | 5.61% | 0.29% | 20:00:00 | 1.06 | 1.51% | 2.77% | 3.20% | 1.51% |
| 22:00:00 | 1.05 | 5.37% | 2.26% | 5.55% | 2.26% | 22:00:00 | 1.05 | 6.07% | 5.04% | 4.26% | 6.07% |
| 00:00:00 | 1.02 | 1.47% | 3.78% | 1.71% | 1.47% | 00:00:00 | 1.02 | 2.76% | 3.77% | 3.63% | 2.76% |
| MAE | 4180.003 | 3496.746 | 4892.383 | 5274.083 | MAE | 5939.701 | 3166.08 | 2877.14 | 4808.086 | ||
| MSE | 9889.116 | 5223.754 | 8654.386 | 6125.665 | MSE | 2278.429 | 4980.943 | 9008.525 | 5746.612 | ||
| MAPE | 3.19% | 3.18% | 3.57% | 1.84% | MAPE | 3.27% | 7.57% | 3.64% | 3.10% | ||
| FVD | 0.7991 | 0.7545 | 0.8617 | 0.9635 | FVD | 0.8836 | 0.8062 | 0.8147 | 0.9129 | ||
| IFVD | 0.8348 | 0.7440 | 0.8604 | 0.8168 | IFVD | 0.8190 | 0.8961 | 0.8836 | 0.8883 | ||
| Electric-Chi-Square | P-ENN-ARSR | ||||
|---|---|---|---|---|---|
| MAE | MSE | MAPE | FVD | IFVD | |
| 0.1 | 1.58 × 104 | 4.39 × 106 | 0.02 | 0.75 | 0.76 |
| 0.2 | 3.51 × 104 | 2.20 × 107 | 0.05 | 1.00 | 0.95 |
| 0.3 | 2.37 × 104 | 1.04 × 107 | 0.03 | 0.80 | 0.93 |
| 0.4 | 3.53 × 104 | 2.32 × 107 | 0.04 | 0.78 | 0.96 |
| 0.5 | 2.73 × 104 | 1.33 × 107 | 0.03 | 0.77 | 0.96 |
| 0.6 | 2.03 × 104 | 7.20 × 106 | 0.02 | 0.98 | 0.77 |
| 0.7 | 2.64 × 104 | 1.30 × 107 | 0.03 | 0.89 | 0.85 |
| 0.8 | 4.16 × 104 | 3.16 × 107 | 0.05 | 0.93 | 0.86 |
| 0.9 | 1.73 × 104 | 5.94 × 106 | 0.02 | 0.79 | 0.96 |
| 1 | 3.07 × 104 | 1.66 × 107 | 0.04 | 0.89 | 0.78 |
| Electric-Chi-Square | ARIMA | SVM | ||||||||
| MAE | MSE | MAPE | FVD | IFVD | MAE | MSE | MAPE | FVD | IFVD | |
| 0.1 | 8.26 × 103 | 1.06 × 107 | 0.04 | 0.93 | 0.86 | 7.12 × 103 | 6.95 × 106 | 0.03 | 0.99 | 0.90 |
| 0.2 | 7.80 × 103 | 1.05 × 107 | 0.02 | 0.79 | 0.86 | 7.02 × 103 | 8.44 × 106 | 0.02 | 0.76 | 0.94 |
| 0.3 | 7.52 × 103 | 8.03 × 106 | 0.01 | 0.99 | 0.91 | 1.23 × 104 | 2.46 × 107 | 0.08 | 0.75 | 0.89 |
| 0.4 | 1.36 × 104 | 3.53 × 107 | 0.13 | 0.76 | 0.87 | 1.17 × 104 | 2.31 × 107 | 0.08 | 0.87 | 0.97 |
| 0.5 | 8.51 × 103 | 1.30 × 107 | 0.02 | 0.81 | 0.84 | 1.14 × 104 | 2.07 × 107 | 0.08 | 0.87 | 0.97 |
| 0.6 | 1.30 × 104 | 3.68 × 107 | 0.12 | 0.87 | 0.82 | 1.23 × 104 | 2.70 × 107 | 0.11 | 0.91 | 0.75 |
| 0.7 | 1.47 × 104 | 3.74 × 107 | 0.11 | 0.85 | 0.90 | 9.29 × 103 | 1.45 × 107 | 0.05 | 0.76 | 0.75 |
| 0.8 | 1.37 × 104 | 2.91 × 107 | 0.10 | 0.94 | 0.90 | 9.48 × 103 | 1.44 × 107 | 0.03 | 0.90 | 0.85 |
| 0.9 | 1.40 × 104 | 3.59 × 107 | 0.05 | 0.88 | 0.74 | 1.11 × 104 | 1.96 × 107 | 0.05 | 0.97 | 0.98 |
| 1 | 1.09 × 104 | 2.04 × 107 | 0.05 | 0.75 | 0.99 | 1.03 × 104 | 1.67 × 107 | 0.04 | 0.79 | 0.94 |
| Electric-Chi-Square | BPNN | ANFIS | ||||||||
| MAE | MSE | MAPE | FVD | IFVD | MAE | MSE | MAPE | FVD | IFVD | |
| 1 | 1.09 × 104 | 2.04 × 107 | 0.05 | 0.75 | 0.99 | 1.03 × 104 | 1.67 × 107 | 0.04 | 0.79 | 0.94 |
| 0.1 | 7.86 × 103 | 1.05 × 107 | 0.03 | 0.92 | 0.80 | 1.04 × 104 | 1.72 × 107 | 0.08 | 0.92 | 0.76 |
| 0.2 | 9.52 × 103 | 1.28 × 107 | 0.05 | 0.80 | 0.87 | 9.72 × 103 | 1.65 × 107 | 0.06 | 0.88 | 0.89 |
| 0.3 | 8.72 × 103 | 1.18 × 107 | 0.03 | 0.95 | 0.89 | 8.69 × 103 | 1.17 × 107 | 0.04 | 0.94 | 0.95 |
| 0.4 | 1.15 × 104 | 1.71 × 107 | 0.07 | 0.82 | 0.88 | 1.16 × 104 | 2.02 × 107 | 0.07 | 0.78 | 0.76 |
| 0.5 | 9.70 × 103 | 1.43 × 107 | 0.04 | 0.95 | 0.92 | 5.77 × 103 | 5.44 × 106 | 0.01 | 0.95 | 0.74 |
| 0.6 | 1.08 × 104 | 1.72 × 107 | 0.05 | 0.90 | 0.87 | 1.27 × 104 | 2.68 × 107 | 0.10 | 0.94 | 0.88 |
| 0.7 | 1.09 × 104 | 2.19 × 107 | 0.03 | 0.84 | 0.87 | 1.04 × 104 | 1.68 × 107 | 0.04 | 0.96 | 0.97 |
| 0.8 | 1.44 × 104 | 3.42 × 107 | 0.06 | 0.79 | 0.78 | 7.84 × 103 | 9.68 × 106 | 0.01 | 0.94 | 0.93 |
| 0.9 | 1.17 × 104 | 2.25 × 107 | 0.07 | 0.98 | 0.79 | 9.91 × 103 | 1.44 × 107 | 0.04 | 0.89 | 0.89 |
| 1 | 1.43 × 104 | 3.29 × 107 | 0.10 | 0.76 | 0.83 | 1.02 × 104 | 1.76 × 107 | 0.04 | 0.92 | 0.84 |
| Electric-Chi-Square | FVD-2-Order Index | Electric-Chi-Square | FVD-3-Order Index | ||||
|---|---|---|---|---|---|---|---|
| ENN | ARSR | P-ENN-ARSR | ENN | ARSR | P-ENN-ARSR | ||
| 0.1 | 0.9051 | 0.8837 | 0.9175 | 0.1 | 1.63 | 1.61 | 1.58 |
| 0.2 | 0.8441 | 0.8406 | 0.8587 | 0.2 | 1.69 | 1.66 | 1.62 |
| 0.3 | 0.8360 | 0.8353 | 0.8482 | 0.3 | 1.68 | 1.65 | 1.62 |
| 0.4 | 0.7885 | 0.8328 | 0.8662 | 0.4 | 2.00 | 1.67 | 1.66 |
| 0.5 | 0.8231 | 0.8277 | 0.8345 | 0.5 | 1.70 | 1.68 | 1.65 |
| 0.6 | 0.7503 | 0.8158 | 0.8096 | 0.6 | 2.13 | 1.70 | 1.72 |
| 0.7 | 0.8162 | 0.8131 | 0.8222 | 0.7 | 1.70 | 1.70 | 1.67 |
| 0.8 | 0.8231 | 0.8121 | 0.8270 | 0.8 | 1.66 | 1.71 | 1.64 |
| 0.9 | 0.7601 | 0.8146 | 0.8123 | 0.9 | 1.70 | 2.09 | 1.71 |
| 1 | 0.7392 | 0.7932 | 0.8107 | 1 | 1.75 | 2.13 | 1.71 |
| Experiment No. | Inference Type | Iterations in P-ENN | Nodes in Context Layer |
|---|---|---|---|
| 1 | P-ENN-I | 5 | 6 |
| 2 | P-ENN-I | 5 | 12 |
| 3 | P-ENN-I | 5 | 18 |
| 4 | P-ENN-II | 10 | 6 |
| 5 | P-ENN-II | 10 | 12 |
| 6 | P-ENN-II | 10 | 18 |
| 7 | P-ENN-III | 15 | 6 |
| 8 | P-ENN-III | 15 | 12 |
| 9 | P-ENN-III | 15 | 18 |
| No. | PDRS-ENN-I | PDRS-ENN-II | PDRS-ENN-III | ANFIS | SVM | BPNN |
|---|---|---|---|---|---|---|
| 1 | 1.60 | 1.60 | 1.61 | 1.91 | 1.88 | 1.73 |
| 2 | 1.61 | 1.59 | 1.61 | 1.92 | 1.90 | 1.75 |
| 3 | 1.60 | 1.58 | 1.59 | 1.90 | 1.90 | 1.72 |
| 4 | 1.62 | 1.59 | 1.63 | 1.90 | 1.86 | 1.72 |
| 5 | 1.61 | 1.60 | 1.60 | 1.93 | 1.88 | 1.73 |
| 6 | 1.62 | 1.59 | 1.62 | 1.92 | 1.87 | 1.73 |
| 7 | 1.58 | 1.58 | 1.61 | 1.92 | 1.90 | 1.71 |
| 8 | 1.60 | 1.60 | 1.59 | 1.90 | 1.86 | 1.74 |
| 9 | 1.61 | 1.61 | 1.61 | 1.89 | 1.87 | 1.75 |
| Mean | 1.61 | 1.60 | 1.61 | 1.91 | 1.88 | 1.73 |
| No. | PDRS-ENN-I | PDRS-ENN-II | PDRS-ENN-III | ANFIS | SVM | BPNN |
|---|---|---|---|---|---|---|
| 1 | 1.77 | 1.81 | 1.90 | 2.03 | 2.04 | 2.03 |
| 2 | 1.79 | 1.83 | 1.88 | 2.05 | 2.05 | 2.01 |
| 3 | 1.76 | 1.81 | 1.92 | 2.05 | 2.02 | 2.05 |
| 4 | 1.79 | 1.81 | 1.92 | 2.01 | 2.04 | 2.05 |
| 5 | 1.78 | 1.83 | 1.91 | 2.01 | 2.06 | 2.05 |
| 6 | 1.78 | 1.82 | 1.91 | 2.02 | 2.05 | 2.01 |
| 7 | 1.78 | 1.79 | 1.89 | 2.01 | 2.02 | 2.05 |
| 8 | 1.78 | 1.80 | 1.92 | 2.01 | 2.04 | 2.02 |
| 9 | 1.78 | 1.82 | 1.89 | 2.04 | 2.05 | 2.01 |
| Mean | 1.78 | 1.81 | 1.90 | 2.03 | 2.04 | 2.03 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Wang, J.; Wang, C.; Guo, Z. Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting. Energies 2017, 10, 490. https://doi.org/10.3390/en10040490
Dong Y, Wang J, Wang C, Guo Z. Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting. Energies. 2017; 10(4):490. https://doi.org/10.3390/en10040490
Chicago/Turabian StyleDong, Yunxuan, Jianzhou Wang, Chen Wang, and Zhenhai Guo. 2017. "Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting" Energies 10, no. 4: 490. https://doi.org/10.3390/en10040490
APA StyleDong, Y., Wang, J., Wang, C., & Guo, Z. (2017). Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting. Energies, 10(4), 490. https://doi.org/10.3390/en10040490