
Surrogate Measures for the Robust Scheduling of Stochastic Job Shop Scheduling Problems



Abstract
:1. Introduction
2. Mathematical Modeling
2.1. Problem Description and Analysis
2.2. Mathematical Modeling of SJSSP
3. SMs of Robustness for SJSSP
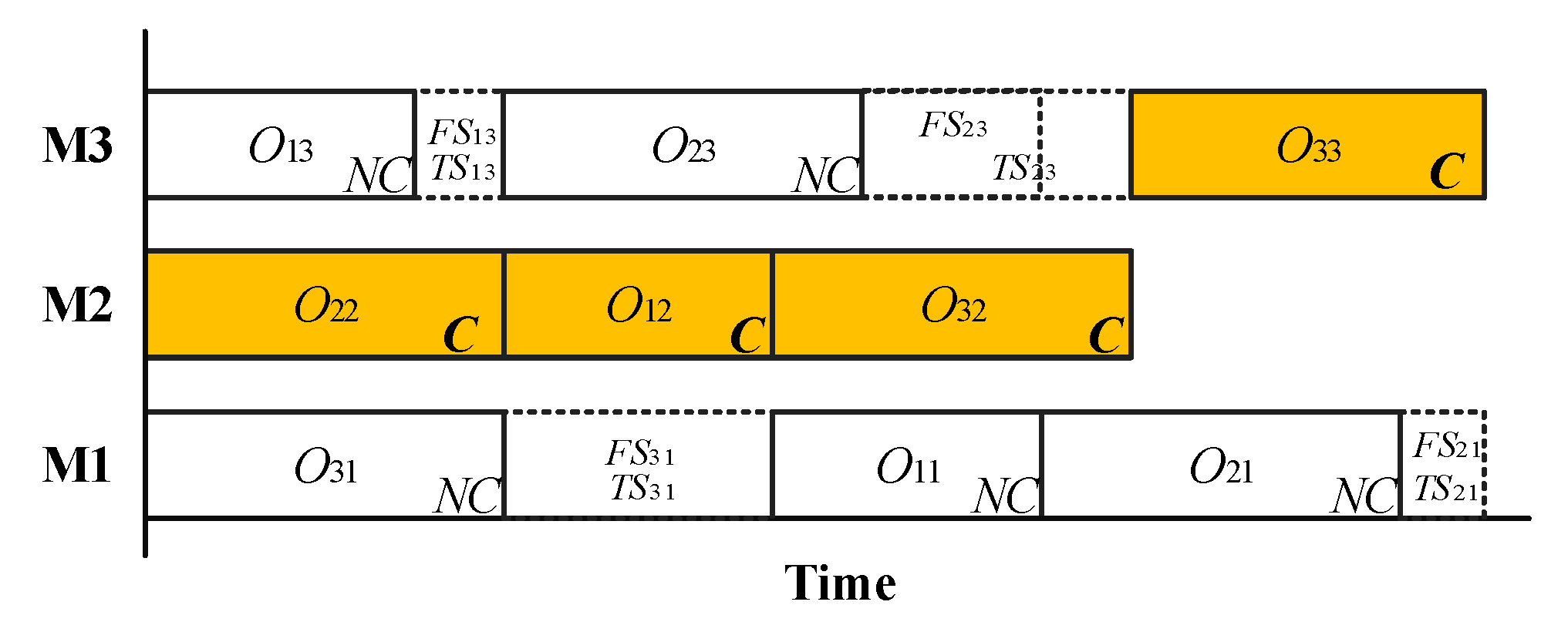
3.1. The Existing SMs of Robustness
3.2. New SMs of Robustness for SJSSP
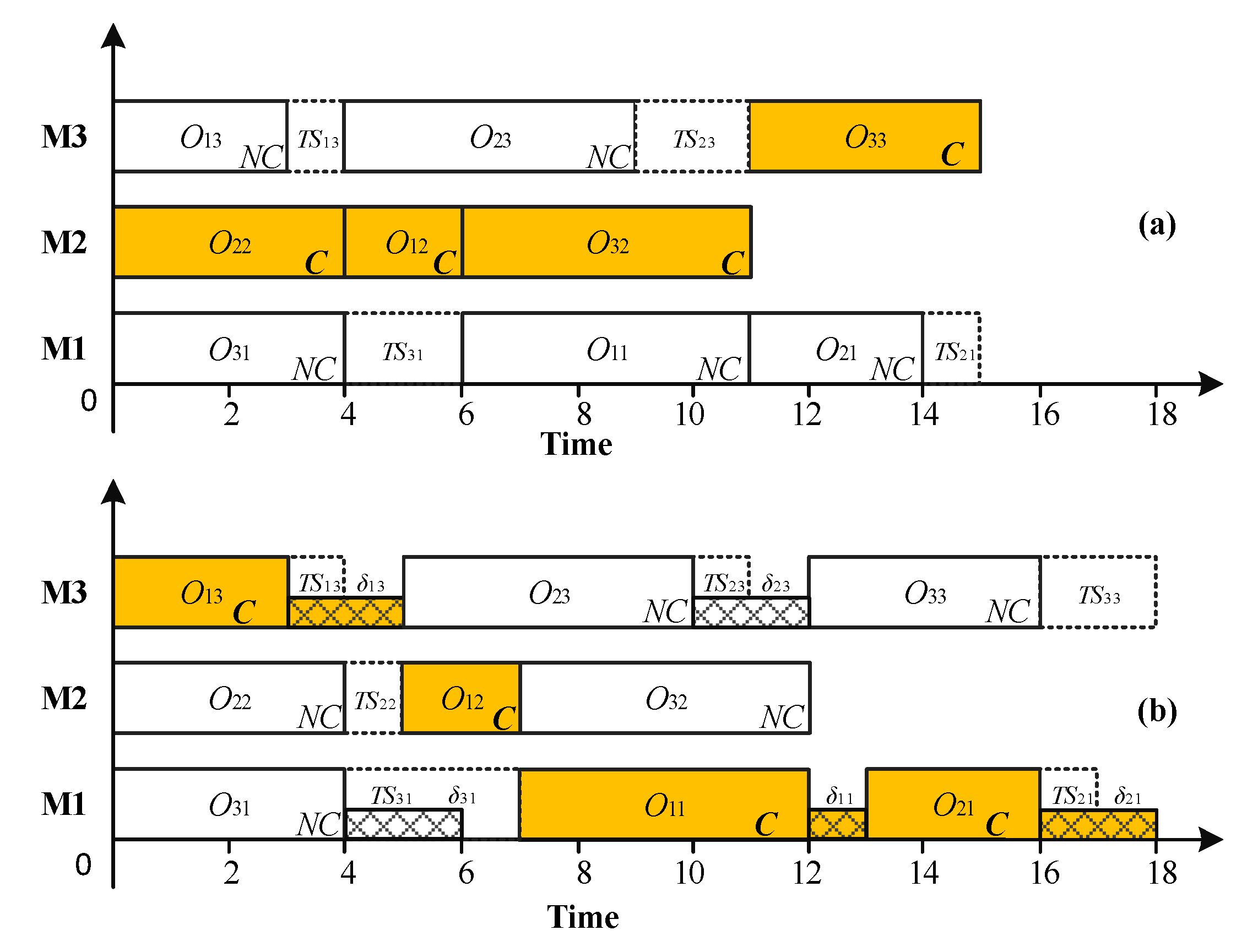
3.2.1. Quantifying the Disturbances of the Stochastic Processing Times
3.2.2. Disturbance Absorption Capability
3.2.3. New SMs for Robustness Scheduling
4. HEDA for SJSSP
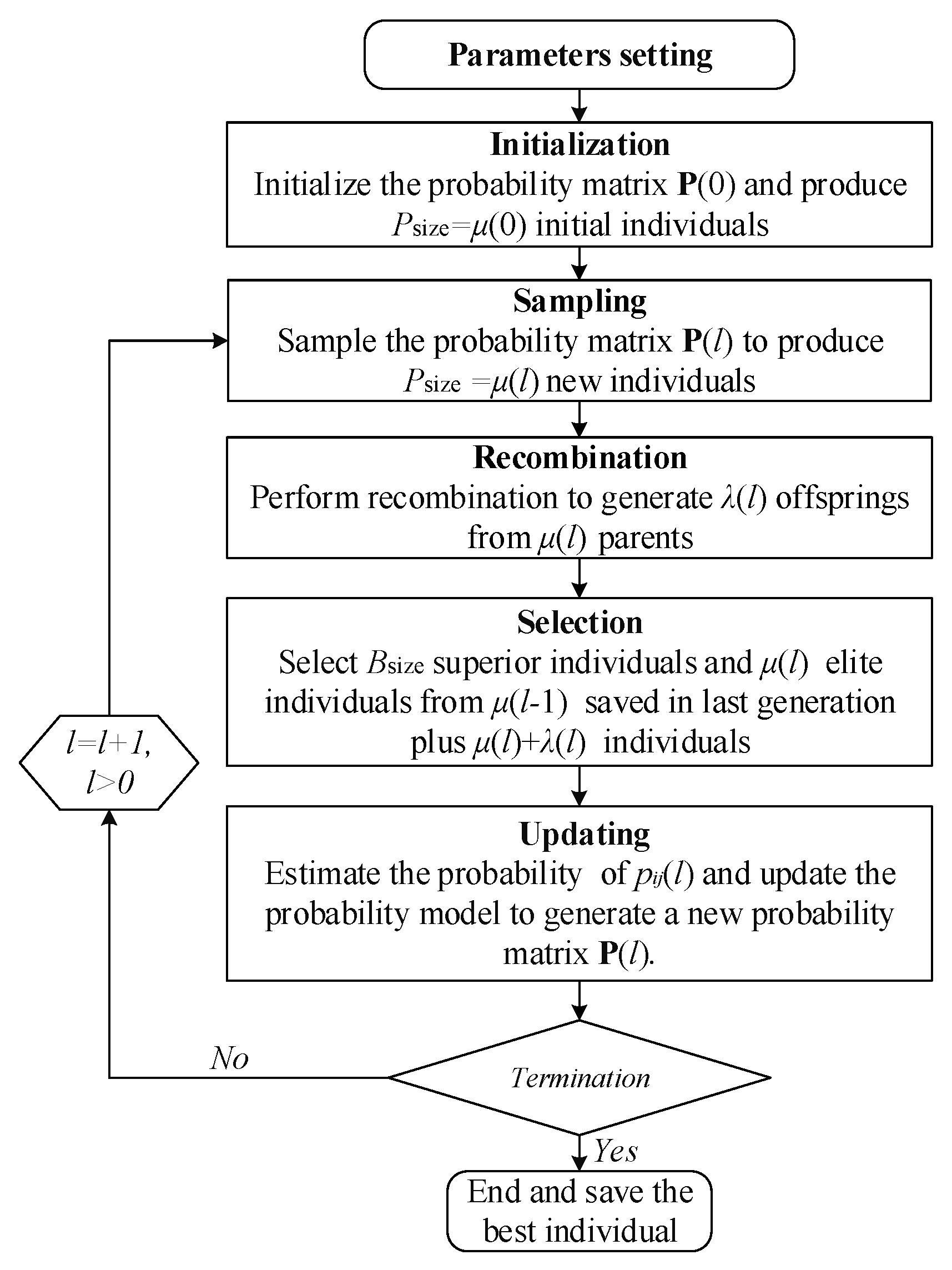
4.1. Framework of HEDA
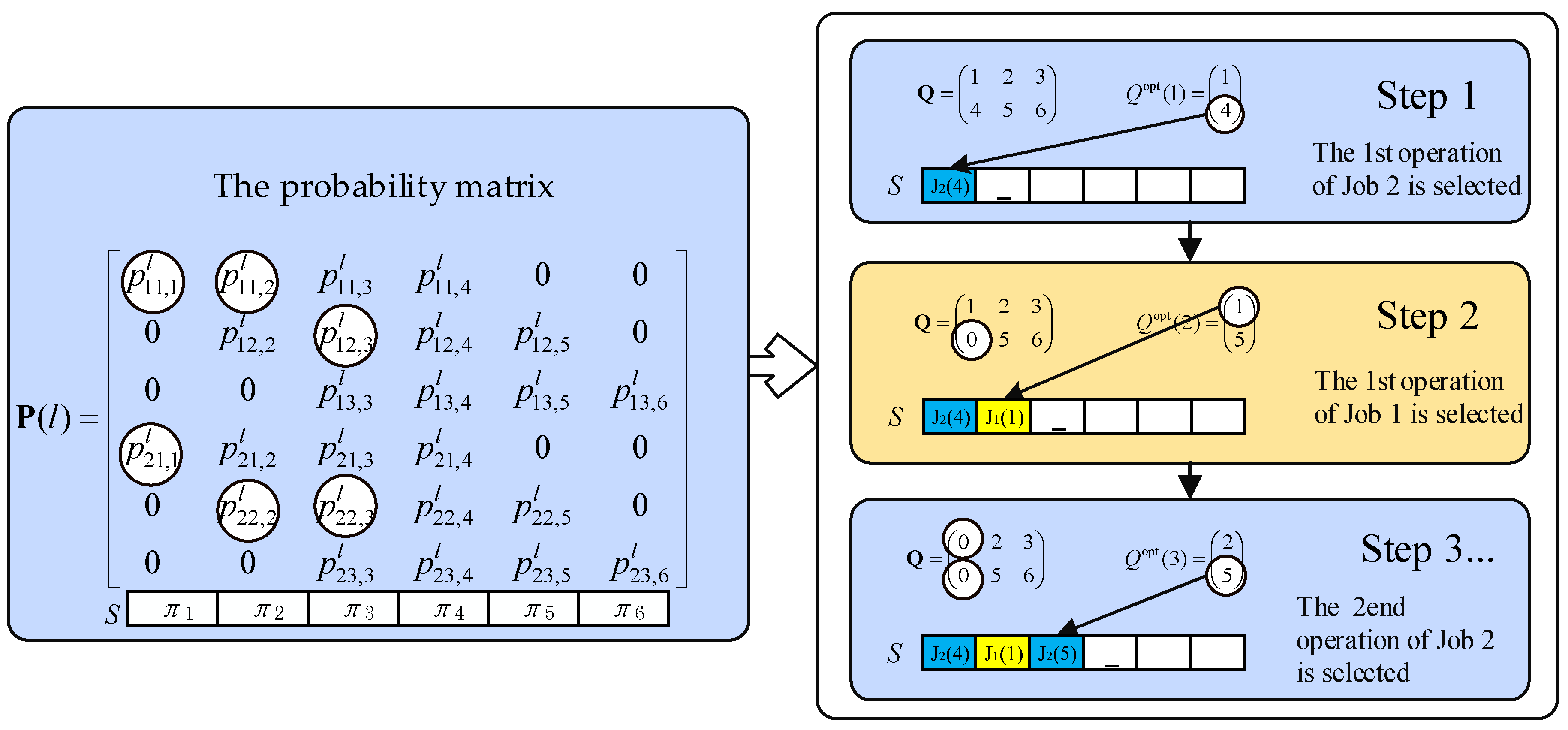
4.2. Encoding and Decoding
4.3. Probability Model and Updating Mechanism
4.4. Initializing and Sampling
4.5. Recombination and Selection
5. Computational Experiments
5.1. Experiment Settings
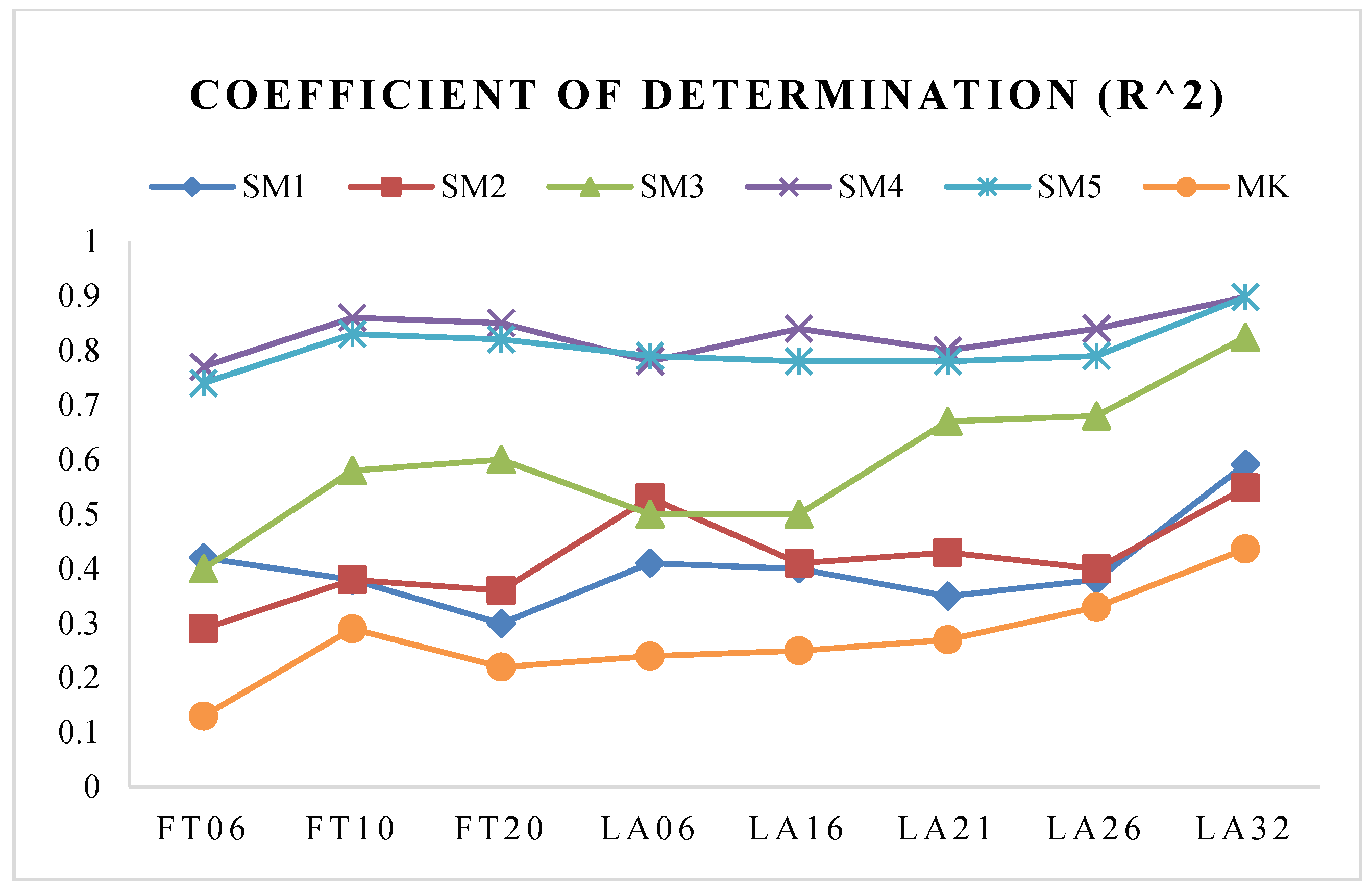
5.2. Correlation Analysis of the SMs
5.3. The Performance of the SMs
5.3.1. One-Way ANOVA Analysis for Different Confidence Levels
5.3.2. The Performance Analysis of the SMs
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Notations
| A feasible schedule solution | |
| The whole feasible solution space | |
| The total number of jobs | |
| The total number of machines | |
| Job | |
| Machine | |
| The operation of job processed on machine | |
| The stochastic processing time of job on machine | |
| The expected processing time of operation | |
| The variance of operation | |
| A positive number that is large enough; | |
| Job must be processed on machine then on , if it is satisfied, , otherwise, | |
| Job must be processed after on machine , if it is satisfied, , otherwise, | |
| The possible realized completion time of job on machine under the disturbances | |
| The maximize completion time of the predictive schedule using expected processing times | |
| . | The robustness measure to evaluate the robustness of the schedule |
References
- Aytug, H.; Lawley, M.A.; McKay, K.; Mohan, S.; Uzsoy, R. Executing production schedules in the face of uncertainties: A review and some future directions. Eur. J. Oper. Res. 2005, 161, 86–110. [Google Scholar] [CrossRef]
- Ouelhadj, D.; Petrovic, S. A survey of dynamic scheduling in manufacturing systems. J. Sched. 2009, 12, 417–431. [Google Scholar] [CrossRef]
- Lei, D. Simplified multi-objective genetic algorithms for stochastic job shop scheduling. Appl. Soft Comput. 2011, 11, 4991–4996. [Google Scholar] [CrossRef]
- Herroelen, W.; Leus, R. Project scheduling under uncertainty: Survey and research potentials. Eur. J. Oper. Res. 2005, 165, 289–306. [Google Scholar] [CrossRef]
- Goren, S.; Sabuncuoglu, I. Optimization of schedule robustness and stability under random machine breakdowns and processing time variability. IIE Trans. 2009, 42, 203–220. [Google Scholar] [CrossRef]
- Jorge Leon, V.; David Wu, S.; Storer, R.H. Robustness measures and robust scheduling for job shops. IIE Trans. 1994, 26, 32–43. [Google Scholar] [CrossRef]
- Ghosh, S.; Melhem, R.; Mossé, D. Enhancing real-time schedules to tolerate transient faults. In Proceedings of the 16th IEEE Real-Time Systems Symposium, Pisa, Italy, 4–7 December 1995; pp. 120–129. [Google Scholar]
- Ghosh, S. Guaranteeing Fault Tolerance through Scheduling in Real-Time Systems. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, USA, 1996. [Google Scholar]
- Herroelen, W.; Leus, R. Robust and reactive project scheduling: A review and classification of procedures. Int. J. Prod. Res. 2004, 42, 1599–1620. [Google Scholar] [CrossRef]
- Van de Vonder, S.; Demeulemeester, E.; Herroelen, W. Proactive heuristic procedures for robust project scheduling: An experimental analysis. Eur. J. Oper. Res. 2008, 189, 723–733. [Google Scholar] [CrossRef]
- Lambrechts, O.; Demeulemeester, E.; Herroelen, W. Time slack-based techniques for robust project scheduling subject to resource uncertainty. Ann. Oper. Res. 2011, 186, 443–464. [Google Scholar] [CrossRef]
- Kuchta, D. A new concept of project robust schedule—Use of buffers. Procedia Comput. Sci. 2014, 31, 957–965. [Google Scholar] [CrossRef]
- Salmasnia, A.; Khatami, M.; Kazemzadeh, R.B.; Zegordi, S.H. Bi-objective single machine scheduling problem with stochastic processing times. Top 2014, 23, 275–297. [Google Scholar] [CrossRef]
- Jamili, A. Robust job shop scheduling problem: Mathematical models, exact and heuristic algorithms. Expert Syst. Appl. 2016, 55, 341–350. [Google Scholar] [CrossRef]
- Al-Hinai, N.; ElMekkawy, T.Y. Robust and stable flexible job shop scheduling with random machine breakdowns using a hybrid genetic algorithm. Int. J. Prod. Econ. 2011, 132, 279–291. [Google Scholar] [CrossRef]
- Jensen, M.T. Improving robustness and flexibility of tardiness and total flow-time job shops using robustness measures. Appl. Soft Comput. 2001, 1, 35–52. [Google Scholar] [CrossRef]
- Jensen, M.T. Generating robust and flexible job shop schedules using genetic algorithms. IEEE Trans. Evolut. Comput. 2003, 7, 275–288. [Google Scholar] [CrossRef]
- Artigues, C.; Billaut, J.-C.; Esswein, C. Maximization of solution flexibility for robust shop scheduling. Eur. J. Oper. Res. 2005, 165, 314–328. [Google Scholar] [CrossRef]
- Ghezail, F.; Pierreval, H.; Hajri-Gabouj, S. Analysis of robustness in proactive scheduling: A graphical approach. Comput. Ind. Eng. 2010, 58, 193–198. [Google Scholar] [CrossRef]
- Hazır, O.; Haouari, M.; Erel, E. Robust scheduling and robustness measures for the discrete time/cost trade-off problem. Eur. J. Oper. Res. 2010, 207, 633–643. [Google Scholar]
- Goren, S.; Sabuncuoglu, I.; Koc, U. Optimization of schedule stability and efficiency under processing time variability and random machine breakdowns in a job shop environment. Nav. Res. Logist. (NRL) 2012, 59, 26–38. [Google Scholar] [CrossRef]
- Xiong, J.; Xing, L.-N.; Chen, Y.-W. Robust scheduling for multi-objective flexible job-shop problems with random machine breakdowns. Int. J. Prod. Econ. 2013, 141, 112–126. [Google Scholar] [CrossRef]
- Xiao, S.-C.; Sun, S.-D.; Yang, H.-A. Proactive scheduling research on job shop with stochastically controllable processing times. J. Northwest. Polytech. Univ. 2014, 52, 929–936. (In Chinese) [Google Scholar]
- Ahmadizar, F.; Ghazanfari, M.; Fatemi Ghomi, S.M.T. Group shops scheduling with makespan criterion subject to random release dates and processing times. Comput. Oper. Res. 2010, 37, 152–162. [Google Scholar] [CrossRef]
- Chaari, T.; Chaabane, S.; Loukil, T.; Trentesaux, D. A genetic algorithm for robust hybrid flow shop scheduling. Int. J. Comput. Integr. Manuf. 2011, 24, 821–833. [Google Scholar] [CrossRef]
- Wang, K.; Choi, S.; Qin, H. An estimation of distribution algorithm for hybrid flow shop scheduling under stochastic processing times. Int. J. Prod. Res. 2014, 52, 7360–7376. [Google Scholar] [CrossRef]
- Goren, S.; Sabuncuoglu, I. Robustness and stability measures for scheduling: Single-machine environment. IIE Trans. 2008, 40, 66–83. [Google Scholar] [CrossRef]
- Al-Fawzan, M.A.; Haouari, M. A bi-objective model for robust resource-constrained project scheduling. Int. J. Prod. Econ. 2005, 96, 175–187. [Google Scholar] [CrossRef]
- Chtourou, H.; Haouari, M. A two-stage-priority-rule-based algorithm for robust resource-constrained project scheduling. Comput. Ind. Eng. 2008, 55, 183–194. [Google Scholar] [CrossRef]
- Gu, J.; Gu, M.; Cao, C.; Gu, X. A novel competitive co-evolutionary quantum genetic algorithm for stochastic job shop scheduling problem. Comput. Oper. Res. 2010, 37, 927–937. [Google Scholar] [CrossRef]
- Wang, K.; Choi, S.H.; Lu, H. A hybrid estimation of distribution algorithm for simulation-based scheduling in a stochastic permutation flowshop. Comput. Ind. Eng. 2015, 90, 186–196. [Google Scholar] [CrossRef]
- Lamas, P.; Demeulemeester, E. A purely proactive scheduling procedure for the resource-constrained project scheduling problem with stochastic activity durations. J. Sched. 2015, 19, 409–428. [Google Scholar] [CrossRef]
- Graham, R.L.; Lawler, E.L.; Lenstra, J.K.; Kan, A.R. Optimization and approximation in deterministic sequencing and scheduling: A survey. Ann. Discret. Math. 1979, 5, 287–326. [Google Scholar]
- Xiao, S.-C.; Sun, S.-D.; Yang, H.-A. Hybrid estimation of distribution algorithm for solving the stochastic job shop scheduling problem. J. Mech. Eng. 2015, 51, 27–35. (In Chinese) [Google Scholar] [CrossRef]
- Larranaga, P.; Lozano, J.A. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation; Springer Science & Business Media: New York, NY, USA, 2002. [Google Scholar]
- Horng, S.-C.; Lin, S.-S.; Yang, F.-Y. Evolutionary algorithm for stochastic job shop scheduling with random processing time. Expert Syst. Appl. 2012, 39, 3603–3610. [Google Scholar] [CrossRef]
- Wang, L.; Zheng, D.-Z. An effective hybrid optimization strategy for job-shop scheduling problems. Comput. Oper. Res. 2001, 28, 585–596. [Google Scholar] [CrossRef]
- Wang, S.-Y.; Wang, L.; Liu, M.; Xu, Y. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem. Int. J. Prod. Econ. 2013, 145, 387–396. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: Phoenix, AZ, USA, 2005. [Google Scholar]
- Muth, J.F.; Thompson, G.L. Industrial Scheduling; Prentice-Hall: Upper Saddle River, NJ, USA, 1963. [Google Scholar]
- Lawrence, S. Resource Constrained Project Scheduling: An Experimental Investigation of Heuristic Scheduling Techniques (Supplement); Graduate School of Industrial Administration: Pittsburgh, PA, USA, 1984. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Jobs | The Process Constraints of Each Job | ||
|---|---|---|---|
| Operation 1 | Operation 2 | Operation 3 | |
| J1 | (3, 3, 0.74) | (2, 2, 0) | (1, 5, 0.18) |
| J2 | (2, 4, 0) | (3, 5, 0.74) | (1, 3, 0) |
| J3 | (1, 4, 0) | (2, 5, 0) | (3, 4, 0) |
| Parameters | Values | Parameters | Values |
|---|---|---|---|
| Population size () | 100 | Learning rate () | 0.3 |
| Evolutionary generations () | 100 | Superior population () | 40 |
| Recombination probability () | 0.8 | Value of μ and λ | 100 |
| Number of positioning jobs | Simulation replications | 200 |
| Benchmarks | Measures | Uncertainty Levels | |||||
|---|---|---|---|---|---|---|---|
| UL2 | UL4 | UL6 | UL8 | UL10 | Average | ||
| FT06 Size: 6 × 6 | SM1 | 0.44 | 0.46 | 0.29 | 0.55 | 0.53 | 0.45 |
| SM2 | 0.27 | 0.09 | 0.14 | 0.48 | 0.53 | 0.30 | |
| SM3 | 0.15 | 0.13 | 0.26 | 0.23 | 0.14 | 0.18 | |
| SM4 | 0.69 | 0.72 | 0.83 | 0.69 | 0.87 | 0.76 | |
| SM5 | 0.71 | 0.77 | 0.74 | 0.73 | 0.76 | 0.74 | |
| MK | 0.15 | 0.17 | 0.14 | 0.10 | 0.14 | 0.14 | |
| FT10 Size: 10 × 10 | SM1 | 0.13 | 0.19 | 0.39 | 0.69 | 0.77 | 0.43 |
| SM2 | 0.14 | 0.16 | 0.44 | 0.56 | 0.72 | 0.40 | |
| SM3 | 0.53 | 0.57 | 0.59 | 0.48 | 0.70 | 0.57 | |
| SM4 | 0.82 | 0.90 | 0.89 | 0.89 | 0.85 | 0.87 | |
| SM5 | 0.78 | 0.83 | 0.83 | 0.86 | 0.85 | 0.83 | |
| MK | 0.09 | 0.27 | 0.26 | 0.27 | 0.73 | 0.32 | |
| FT20 Size: 20 × 10 | SM1 | 0.03 | 0.12 | 0.35 | 0.48 | 0.76 | 0.35 |
| SM2 | 0.14 | 0.31 | 0.35 | 0.40 | 0.73 | 0.39 | |
| SM3 | 0.44 | 0.67 | 0.62 | 0.59 | 0.68 | 0.60 | |
| SM4 | 0.84 | 0.83 | 0.90 | 0.84 | 0.81 | 0.84 | |
| SM5 | 0.84 | 0.76 | 0.87 | 0.79 | 0.82 | 0.82 | |
| MK | 0.11 | 0.06 | 0.18 | 0.30 | 0.67 | 0.26 | |
| LA06 Size: 15 × 5 | SM1 | 0.53 | 0.61 | 0.31 | 0.18 | 0.58 | 0.44 |
| SM2 | 0.46 | 0.49 | 0.45 | 0.68 | 0.87 | 0.59 | |
| SM3 | 0.51 | 0.56 | 0.29 | 0.52 | 0.40 | 0.46 | |
| SM4 | 0.84 | 0.78 | 0.67 | 0.79 | 0.68 | 0.75 | |
| SM5 | 0.87 | 0.81 | 0.84 | 0.73 | 0.69 | 0.79 | |
| MK | 0.31 | 0.29 | 0.08 | 0.37 | 0.41 | 0.29 | |
| LA16 Size: 10 × 10 | SM1 | 0.11 | 0.29 | 0.46 | 0.45 | 0.81 | 0.42 |
| SM2 | 0.20 | 0.39 | 0.44 | 0.55 | 0.79 | 0.47 | |
| SM3 | 0.20 | 0.20 | 0.26 | 0.47 | 0.77 | 0.38 | |
| SM4 | 0.90 | 0.92 | 0.83 | 0.87 | 0.79 | 0.86 | |
| SM5 | 0.81 | 0.75 | 0.73 | 0.81 | 0.80 | 0.78 | |
| MK | 0.06 | 0.16 | 0.28 | 0.31 | 0.71 | 0.30 | |
| LA21 Size: 15 × 10 | SM1 | 0.20 | 0.20 | 0.26 | 0.47 | 0.77 | 0.38 |
| SM2 | 0.24 | 0.22 | 0.45 | 0.47 | 0.84 | 0.44 | |
| SM3 | 0.55 | 0.59 | 0.57 | 0.71 | 0.68 | 0.62 | |
| SM4 | 0.79 | 0.80 | 0.82 | 0.78 | 0.80 | 0.80 | |
| SM5 | 0.84 | 0.78 | 0.71 | 0.78 | 0.80 | 0.78 | |
| MK | 0.06 | 0.10 | 0.23 | 0.42 | 0.67 | 0.30 | |
| LA26 Size: 20 × 10 | SM1 | 0.10 | 0.15 | 0.37 | 0.64 | 0.71 | 0.39 |
| SM2 | 0.16 | 0.39 | 0.50 | 0.58 | 0.78 | 0.48 | |
| SM3 | 0.64 | 0.70 | 0.74 | 0.65 | 0.71 | 0.69 | |
| SM4 | 0.83 | 0.85 | 0.82 | 0.87 | 0.77 | 0.83 | |
| SM5 | 0.81 | 0.83 | 0.80 | 0.84 | 0.82 | 0.82 | |
| MK | 0.08 | 0.12 | 0.41 | 0.56 | 0.70 | 0.37 | |
| LA32 Size: 30 × 10 | SM1 | 0.42 | 0.37 | 0.54 | 0.77 | 0.86 | 0.59 |
| SM2 | 0.40 | 0.35 | 0.41 | 0.70 | 0.89 | 0.55 | |
| SM3 | 0.67 | 0.83 | 0.88 | 0.87 | 0.87 | 0.82 | |
| SM4 | 0.88 | 0.94 | 0.92 | 0.88 | 0.87 | 0.90 | |
| SM5 | 0.85 | 0.91 | 0.92 | 0.92 | 0.90 | 0.90 | |
| MK | 0.29 | 0.34 | 0.39 | 0.46 | 0.69 | 0.44 | |
| Factor | FT06 | |||
| SM4 | SM5 | |||
| F-Ratio | p-Value | F-Ratio | p-Value | |
| value | 2.34 | 0.12 | 2.38 | 0.11 |
| FT10 | ||||
| SM4 | SM5 | |||
| F-Ratio | p-Value | F-Ratio | p-Value | |
| value | 0.56 | 0.57 | 0.71 | 0.49 |
| FT20 | ||||
| SM4 | SM5 | |||
| F-Ratio | p-Value | F-Ratio | p-Value | |
| value | 1.59 | 0.22 | 1.72 | 0.19 |
| Benchmarks | UL | The Comparison Measures | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SM4 | SM5 | RMsim | RMmk | ||||||
| Average | Std. | Average | Std. | Average | Std. | Average | Std. | ||
| FT06 Size: 6 × 6 | UL2 | 0.06 | 0.02 | 0.90 | 0.77 | 0.30 | 0.73 | 5.64 | 0.64 |
| UL4 | 0.21 | 0.37 | 3.66 | 0.74 | 0.35 | 1.59 | 7.49 | 0.35 | |
| UL6 | 7.37 | 1.08 | 5.01 | 0.52 | 2.18 | 0.64 | 12.06 | 0.47 | |
| UL8 | 8.55 | 1.02 | 11.61 | 0.47 | 8.63 | 0.96 | 15.24 | 0.49 | |
| UL10 | 15.06 | 0.95 | 14.57 | 0.53 | 13.15 | 0.62 | 17.52 | 0.26 | |
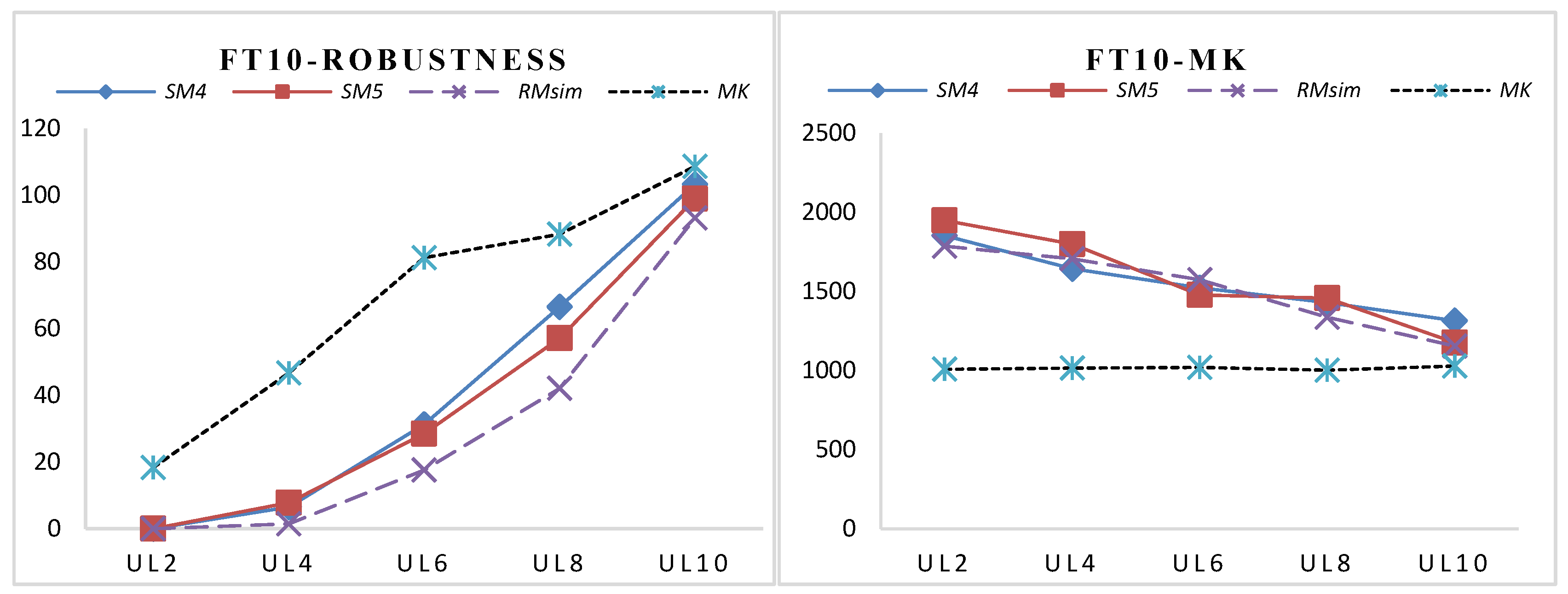
| FT10 Size: 10 × 10 | UL2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 18.40 | 6.23 |
| UL4 | 6.50 | 3.11 | 7.80 | 7.42 | 1.50 | 2.83 | 46.68 | 9.73 | |
| UL6 | 31.24 | 8.16 | 28.51 | 3.84 | 17.60 | 2.45 | 81.26 | 8.41 | |
| UL8 | 66.54 | 5.72 | 57.13 | 7.22 | 54.06 | 5.82 | 88.32 | 5.05 | |
| UL10 | 103.23 | 5.84 | 98.89 | 4.37 | 93.14 | 4.81 | 108.61 | 4.95 | |
| FT20 Size: 20 × 5 | UL2 | 0.00 | 0.00 | 0.00 | 0.01 | 0.01 | 0.03 | 45.03 | 5.91 |
| UL4 | 0.64 | 1.18 | 0.41 | 0.78 | 0.00 | 0.01 | 79.68 | 7.68 | |
| UL6 | 43.46 | 7.04 | 24.65 | 7.62 | 14.80 | 2.64 | 80.19 | 6.44 | |
| UL8 | 83.93 | 6.12 | 66.37 | 6.96 | 51.84 | 8.04 | 121.03 | 4.33 | |
| UL10 | 126.85 | 4.31 | 126.02 | 2.75 | 119.65 | 4.11 | 132.93 | 3.90 | |
| LA06 Size: 15 × 5 | UL2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 21.98 | 0.74 |
| UL4 | 0.20 | 0.66 | 0.20 | 0.53 | 0.00 | 0.00 | 27.12 | 1.62 | |
| UL6 | 8.52 | 3.06 | 4.16 | 3.18 | 3.45 | 1.29 | 33.69 | 1.67 | |
| UL8 | 31.18 | 2.60 | 21.78 | 5.84 | 14.14 | 1.53 | 40.56 | 2.79 | |
| UL10 | 45.52 | 2.37 | 47.23 | 3.99 | 43.60 | 1.84 | 60.32 | 2.87 | |
| LA16 Size: 10 × 10 | UL2 | 0.01 | 0.03 | 0.08 | 0.24 | 0.01 | 3.27 | 26.05 | 0.01 |
| UL4 | 5.38 | 2.53 | 5.15 | 0.47 | 5.25 | 6.13 | 24.79 | 1.69 | |
| UL6 | 17.73 | 2.12 | 20.22 | 6.28 | 8.90 | 4.27 | 37.59 | 2.79 | |
| UL8 | 35.07 | 3.28 | 37.78 | 3.96 | 30.68 | 4.17 | 51.36 | 1.52 | |
| UL10 | 64.63 | 2.09 | 61.87 | 1.88 | 60.90 | 2.96 | 68.72 | 1.79 | |
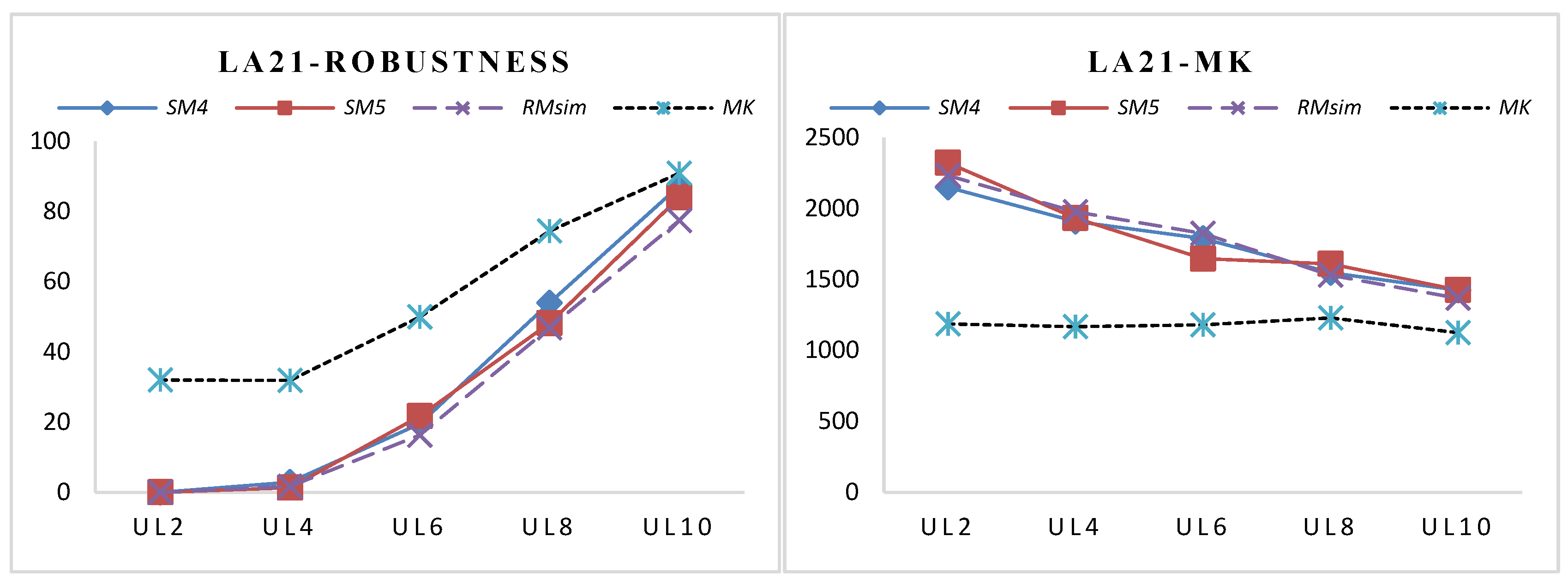
| LA21 Size: 15 × 10 | UL2 | 0.01 | 0.04 | 0.01 | 0.02 | 0.00 | 0.00 | 32.04 | 5.95 |
| UL4 | 2.88 | 2.67 | 1.32 | 2.59 | 1.69 | 1.61 | 31.87 | 5.91 | |
| UL6 | 19.55 | 5.06 | 21.73 | 5.31 | 16.30 | 1.81 | 49.93 | 5.28 | |
| UL8 | 53.97 | 5.38 | 48.16 | 6.78 | 46.89 | 4.80 | 74.43 | 6.30 | |
| UL10 | 87.30 | 3.94 | 84.01 | 4.98 | 77.43 | 3.63 | 90.91 | 3.12 | |
| LA26 Size: 20 × 10 | UL2 | 0.01 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 21.74 | 5.41 |
| UL4 | 4.16 | 2.43 | 4.88 | 4.10 | 1.06 | 1.35 | 39.72 | 4.85 | |
| UL6 | 32.79 | 4.69 | 28.30 | 7.52 | 21.00 | 3.96 | 64.40 | 6.76 | |
| UL8 | 55.19 | 7.59 | 54.45 | 6.75 | 54.94 | 6.08 | 76.40 | 7.01 | |
| UL10 | 90.84 | 4.54 | 91.55 | 6.33 | 86.54 | 2.59 | 99.17 | 5.72 | |
| LA32 Size: 30 × 10 | UL2 | 0.01 | 0.02 | 0.09 | 0.36 | 0.00 | 0.01 | 30.06 | 10.58 |
| UL4 | 24.04 | 4.12 | 21.79 | 6.76 | 16.32 | 3.46 | 58.65 | 8.85 | |
| UL6 | 41.91 | 4.95 | 34.77 | 5.97 | 32.15 | 6.69 | 77.71 | 12.18 | |
| UL8 | 92.83 | 7.36 | 89.33 | 9.83 | 87.96 | 8.98 | 111.93 | 10.89 | |
| UL10 | 134.16 | 4.74 | 130.21 | 7.59 | 120.98 | 5.63 | 144.34 | 8.99 | |
| Benchmarks | UL | The Comparison Measures | |||||||
|---|---|---|---|---|---|---|---|---|---|
| SM4 | SM5 | RMsim | MK | ||||||
| Average | Std. | Average | Std. | Average | Std. | Average | Std. | ||
| FT06 Size: 6 × 6 | UL2 | 89.5 | 7.9 | 80.1 | 5.3 | 96.0 | 11.6 | 55.0 | 0.0 |
| UL4 | 95.4 | 12.3 | 78.1 | 7.8 | 75.1 | 5.7 | 55.0 | 0.0 | |
| UL6 | 78.5 | 7.9 | 77.6 | 4.7 | 84.8 | 8.6 | 55.0 | 0.0 | |
| UL8 | 72.1 | 3.9 | 70.6 | 5.6 | 69.6 | 2.2 | 55.0 | 0.0 | |
| UL10 | 71.3 | 4.2 | 65.7 | 1.9 | 64.7 | 2.7 | 55.0 | 0.0 | |
| FT10 Size: 10 × 10 | UL2 | 1853.9 | 142.3 | 1949.2 | 170.2 | 2084.9 | 110.2 | 1008.8 | 17.9 |
| UL4 | 1644.3 | 142.9 | 1799.2 | 147.2 | 1859.0 | 88.9 | 1015.7 | 26.6 | |
| UL6 | 1523.7 | 72.5 | 1477.6 | 47.5 | 1674.2 | 77.4 | 1019.9 | 26.4 | |
| UL8 | 1429.6 | 49.5 | 1457.5 | 68.1 | 1410.9 | 77.3 | 1003.3 | 32.0 | |
| UL10 | 1315.1 | 60.0 | 1177.8 | 34.0 | 1167.6 | 50.4 | 1028.4 | 44.2 | |
| FT20 Size: 20 × 5 | UL2 | 2095.5 | 160.1 | 2009.8 | 130.5 | 2098.9 | 201.2 | 1266.9 | 26.1 |
| UL4 | 1800.3 | 108.3 | 1953.7 | 77.4 | 1990.9 | 129.9 | 1257.8 | 23.5 | |
| UL6 | 1802.1 | 89.9 | 1590.1 | 38.6 | 1628.2 | 58.7 | 1247.5 | 25.6 | |
| UL8 | 1635.9 | 50.8 | 1552.5 | 47.4 | 1623.4 | 41.8 | 1272.9 | 23.0 | |
| UL10 | 1461.9 | 29.1 | 1383.3 | 20.8 | 1418.7 | 36.2 | 1251.7 | 16.5 | |
| LA06 Size: 10 × 5 | UL2 | 1451.9 | 168.1 | 1543.4 | 101.7 | 1608.3 | 156.6 | 926.0 | 0.0 |
| UL4 | 1388.9 | 90.3 | 1285.0 | 78.5 | 1365.6 | 103.0 | 926.0 | 0.0 | |
| UL6 | 1131.9 | 67.3 | 1214.0 | 76.1 | 1183.0 | 55.5 | 926.0 | 0.0 | |
| UL8 | 1070.9 | 57.2 | 1156.3 | 76.1 | 1083.6 | 51.0 | 926.0 | 0.0 | |
| UL10 | 1017.4 | 33.8 | 991.1 | 37.5 | 989.4 | 13.8 | 926.0 | 0.0 | |
| LA16 Size: 10 × 10 | UL2 | 1703.7 | 138.3 | 1653.9 | 144.3 | 1674.1 | 8.0 | 998.0 | 150.4 |
| UL4 | 1533.9 | 117.1 | 1498.8 | 76.7 | 1494.5 | 16.1 | 978.0 | 68.9 | |
| UL6 | 1347.5 | 98.5 | 1318.9 | 69.1 | 1377.6 | 20.5 | 1014.0 | 96.8 | |
| UL8 | 1209.7 | 54.1 | 1208.0 | 47.3 | 1245.4 | 16.3 | 1001.0 | 98.0 | |
| UL10 | 1157.2 | 38.2 | 1094.9 | 35.1 | 1055.3 | 17.5 | 987.0 | 36.3 | |
| LA21 Size: 15 × 10 | UL2 | 2149.2 | 159.0 | 2322.1 | 186.1 | 2232.3 | 145.5 | 1188.0 | 26.0 |
| UL4 | 1908.6 | 132.1 | 1933.0 | 118.6 | 1976.7 | 130.6 | 1168.0 | 28.9 | |
| UL6 | 1788.0 | 119.1 | 1646.9 | 96.8 | 1824.0 | 71.5 | 1180.0 | 28.9 | |
| UL8 | 1547.6 | 82.6 | 1610.1 | 71.6 | 1529.5 | 79.9 | 1230.0 | 27.5 | |
| UL10 | 1425.2 | 65.9 | 1426.7 | 70.3 | 1367.5 | 44.0 | 1126.0 | 29.3 | |
| LA26 Size: 20 × 10 | UL2 | 2584.8 | 280.9 | 2497.9 | 152.6 | 2651.4 | 203.3 | 1412.1 | 48.8 |
| UL4 | 2328.3 | 207.1 | 2315.6 | 179.5 | 2373.7 | 171.7 | 1415.3 | 33.8 | |
| UL6 | 2168.6 | 108.9 | 2178.7 | 124.5 | 2119.6 | 98.2 | 1398.1 | 35.7 | |
| UL8 | 1995.5 | 64.9 | 1929.7 | 62.7 | 1951.1 | 131.3 | 1404.3 | 29.6 | |
| UL10 | 1804.4 | 70.9 | 1765.2 | 87.6 | 1658.8 | 66.6 | 1423.7 | 38.2 | |
| LA32 Size: 30 × 10 | UL2 | 3528.4 | 219.2 | 3546.9 | 266.7 | 3664.8 | 264.2 | 2166.4 | 60.6 |
| UL4 | 3310.9 | 259.8 | 3174.6 | 184.2 | 3282 | 189.3 | 2158.3 | 59.0 | |
| UL6 | 3136.6 | 185.6 | 3027.8 | 154.8 | 3090 | 164.6 | 2159.7 | 54.6 | |
| UL8 | 2897.4 | 166.7 | 2913.8 | 130.9 | 2774 | 140.6 | 2139.4 | 41.4 | |
| UL10 | 2708 | 117.07 | 2560.5 | 108.7 | 2467 | 121.2 | 2128.8 | 51.8 | |
| Benchmarks | Measures | Uncertainty Levels | |||||
|---|---|---|---|---|---|---|---|
| UL2 | UL4 | UL6 | UL8 | UL10 | Average | ||
| FT06 | SM4 | 100.00 | 100.00 | 47.51 | 100.00 | 56.19 | 80.74 |
| Size: 6 × 6 | SM5 | 88.63 | 83.70 | 71.35 | 54.92 | 67.52 | 73.22 |
| FT10 | SM4 | 100.00 | 88.95 | 78.58 | 47.09 | 34.75 | 69.87 |
| Size: 10 × 10 | SM5 | 100.00 | 86.07 | 82.86 | 67.42 | 62.83 | 79.84 |
| FT20 | SM4 | 100.00 | 99.20 | 54.05 | 53.62 | 45.75 | 70.52 |
| Size: 20 × 5 | SM5 | 100.00 | 99.49 | 84.93 | 78.99 | 52.01 | 83.08 |
| LA06 | SM4 | 100.00 | 99.28 | 83.23 | 35.48 | 88.53 | 81.30 |
| Size: 15 × 5 | SM5 | 100.00 | 99.28 | 97.66 | 71.08 | 78.30 | 89.27 |
| LA16 | SM4 | 99.99 | 99.36 | 69.23 | 78.79 | 52.29 | 79.93 |
| Size: 10 × 10 | SM5 | 99.74 | 100.00 | 60.56 | 65.66 | 87.55 | 82.70 |
| LA21 | SM4 | 99.96 | 96.07 | 90.33 | 74.29 | 26.73 | 77.48 |
| Size: 15 × 10 | SM5 | 99.97 | 100.00 | 83.85 | 95.39 | 51.14 | 86.07 |
| LA26 | SM4 | 99.97 | 91.99 | 72.84 | 98.81 | 65.92 | 85.90 |
| Size: 20 × 10 | SM5 | 100.00 | 90.12 | 83.18 | 100.00 | 60.31 | 86.72 |
| LA32 | SM4 | 99.97 | 81.77 | 78.57 | 79.68 | 43.56 | 76.71 |
| Size: 30 × 10 | SM5 | 99.69 | 87.09 | 94.25 | 94.29 | 60.46 | 87.16 |
| Benchmarks | Type of Measures | ||||
|---|---|---|---|---|---|
| SM4 | SM5 | RMsim | |||
| CT (Seconds) | PT | CT (Seconds) | PT | CT (Seconds) | |
| FT06 | 20.67 | 96.02 | 19.88 | 94.83 | 384.87 |
| FT10 | 39.41 | 95.15 | 38.82 | 93.43 | 590.63 |
| FT20 | 40.97 | 93.58 | 40.90 | 92.59 | 551.92 |
| LA06 | 46.31 | 90.05 | 48.22 | 90.47 | 506.00 |
| LA16 | 38.45 | 92.43 | 40.64 | 93.27 | 604.20 |
| LA21 | 53.63 | 92.04 | 70.69 | 90.00 | 706.97 |
| LA26 | 89.79 | 88.91 | 93.55 | 88.73 | 829.66 |
| LA32 | 233.41 | 90.24 | 238.58 | 90.04 | 2397.34 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, S.; Sun, S.; Jin, J. Surrogate Measures for the Robust Scheduling of Stochastic Job Shop Scheduling Problems. Energies 2017, 10, 543. https://doi.org/10.3390/en10040543
Xiao S, Sun S, Jin J. Surrogate Measures for the Robust Scheduling of Stochastic Job Shop Scheduling Problems. Energies. 2017; 10(4):543. https://doi.org/10.3390/en10040543
Chicago/Turabian StyleXiao, Shichang, Shudong Sun, and Jionghua (Judy) Jin. 2017. "Surrogate Measures for the Robust Scheduling of Stochastic Job Shop Scheduling Problems" Energies 10, no. 4: 543. https://doi.org/10.3390/en10040543
APA StyleXiao, S., Sun, S., & Jin, J. (2017). Surrogate Measures for the Robust Scheduling of Stochastic Job Shop Scheduling Problems. Energies, 10(4), 543. https://doi.org/10.3390/en10040543