
An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing

Abstract
:1. Introduction
2. Model
2.1. DVMP Problem
2.2. Performance Metric
2.2.1. SLA Violation
2.2.2. Number of Migrations
2.2.3. Energy Consumption
2.3. ACS
3. Method
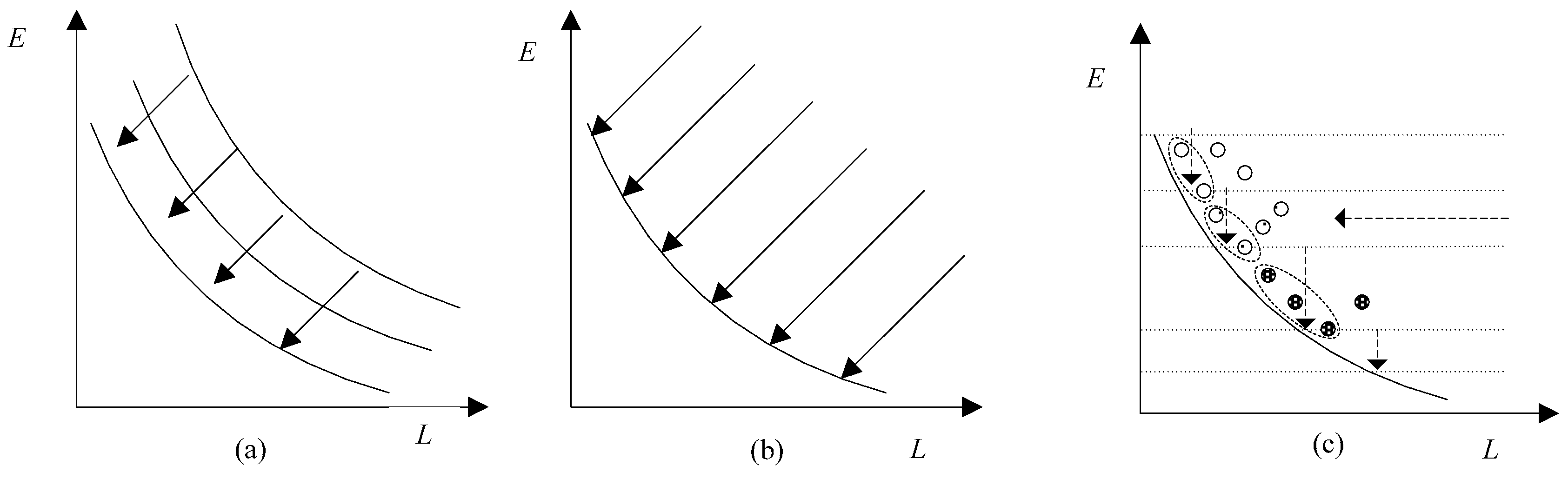
3.1. VMs Set for Assignment
3.2. Dynamic Pheromone Deposition
| Algorithm 1. Construct VMs set for assignment | |
| 1. | TRcpu ← 0, TRmemo ← 0; URcpu ← 0; URmemo ← 0; NVt ← φ; OVt ← φ; UVt ← φ |
| 2. | for each new coming VM j do |
| 3. | TRcpu ← TRcpu + vcj |
| 4. | TRmemo ← TRmemo + vmj |
| 5. | add VM into NVt |
| 6. | end for |
| 7. | for each overloaded server i do |
| 8. | TRcpu ← TRcpu + |PCi − UCi| |
| 9. | TRmemo ← TRmemo + |PMi − UMi| |
| 10. | add VMs on server i into OVt |
| 11. | end for |
| 12. | for each underutilized server i do |
| 13. | URcpu ← URcpu + |PCi − UCi| |
| 14. | URmemo ← URmemo + |PMi − UMi| |
| 15. | if URcpu ≥ 2 × TRcpu && URmemo ≥ 2 × TRmemo then |
| 16. | sleepindex ← i; |
| 17. | go to line 19 |
| 18. | end if |
| 19. | end for |
| 20. | for each underutilized server k behind server sleepindex do |
| 21. | add the VMs on server k into UVt |
| 22. | end for |
3.3. UACS
3.3.1. Solution Construction
3.3.2. Solution Preservation
3.3.3. Pheromone Update
| Algorithm 2. Initialize Pheromone Deposition | |
| 1. | τ0 ← 1/Mt |
| 2. | for each VM pair (k, j) |
| 3. | if VM k and VM j are included in the assignment in the last time then |
| 4. | τ(k, j) ← τold(k, j) |
| 5. | else |
| 6. | τ(k, j) ← τ0 |
| 7. | end if |
| 8. | end for |
| Algorithm 3. UACS | |
| 1. | Construct VM sets for assignment following Algorithm 1 |
| 2. | Initialize pheromone τ as Algorithm 2 |
| 3. | g ← 1, Mmin ← Mt + 1, A ← φ |
| 4. | while g ≤ Gmax do |
| 5. | Mg ← Mmin − 1 |
| 6. | for each ant m do |
| 7. | Sm ← φ |
| 8. | for each VM j do |
| 9. | Cj ← φ; Dj ← φ |
| 10. | for each server i do |
| 11. | if there is enough remaining resources to place VM j then |
| 12. | add i into Cj |
| 13. | else |
| 14. | add i into Dj |
| 15. | end if |
| 16. | calculate Pre(i, j) by using (9) |
| 17. | calculate η(i, j) by using (10) |
| 18. | if VM j is assigned to server i in the last assignment then |
| 19. | η(i, j) ← 5 × η(i, j); |
| 20. | end if |
| 21. | end for |
| 22. | if Cj ≠ φ |
| 23. | Ij ← Cj |
| 24. | else |
| 25. | Ij ← Dj |
| 26. | end if |
| 27. | apply rule in (12) to select a server for VM j and add the assignment into Sm |
| 28. | apply pheromone local update rule in (13) |
| 29. | end for |
| 30. | if solution Sm is infeasible then |
| 31. | perform local search on Sm |
| 32. | if Sm is infeasible then |
| 33. | Given more servers, and the VMs on overloaded servers in Sm are adjusted by First-Fit algorithm |
| 34. | end if |
| 35. | end if |
| 36. | end for |
| 37. | add the solutions into A and update A by storing the nondominated solutions |
| 38. | update Mmin |
| 39. | apply global update rule in (14) |
| 40. | g ← g + 1 |
| 41. | end while |
| 42. | τold ← τ |
4. Results
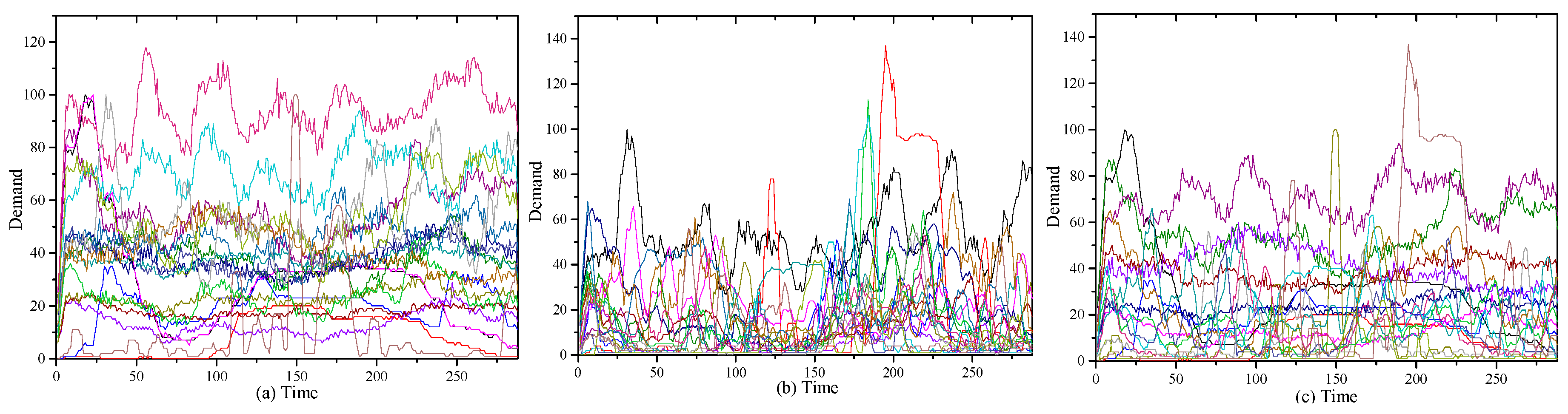
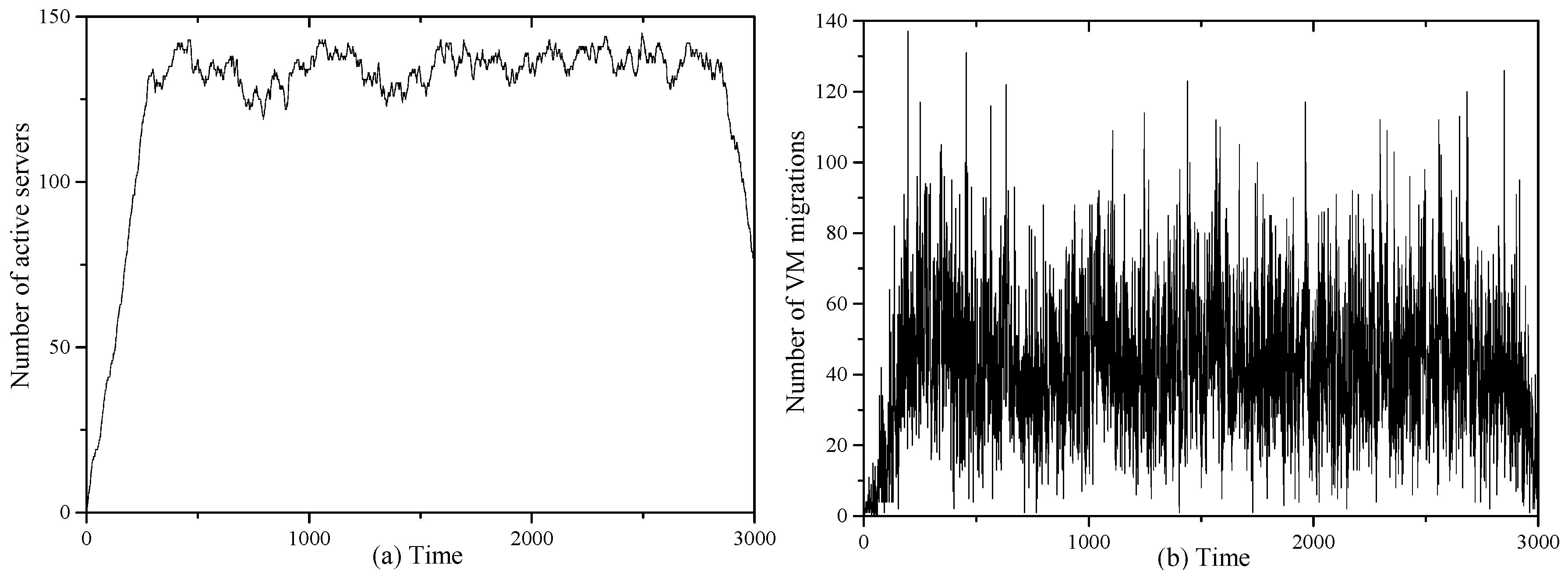
4.1. Random Workload
4.2. Real Workload
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Foster, I.; Zhao, Y.; Raicu, I.; Lu, S.Y. Cloud computing and grid computing 360-Degree compared. In Proceedings of the IEEE Grid Computing Environments Workshop, Austin, TX, USA, 12–16 November 2008. [Google Scholar]
- Lanza, J.; Sánchez, L.; Gutiérrez, V.; Galache, J.A.; Santana, J.R.; Sotres, P.; Muñoz, L. Smart city services over a future internet platform based on internet of things and cloud: The smart parking case. Energies 2016, 9, 719. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Liu, X.F.; Zhang, H.; Yu, Z.; Weng, J.; Li, Y.; Gu, T.; Zhang, J. Cloudde: A heterogeneous differential evolution algorithm and its distributed cloud version. IEEE Trans. Parallel Distrib. Syst. 2016. [Google Scholar] [CrossRef]
- Motta, G.; Sfondrini, N.; Sacco, D. Cloud computing: An architectural and technological overview. In Proceedings of the International Joint Conference Service Science, Shanghai, China, 24–26 May 2012. [Google Scholar]
- Beloglazov, A.; Buyya, R. Optimal Online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers. Concurr. Computat. Pract. Exp. 2012, 24, 1397–1420. [Google Scholar] [CrossRef]
- Callou, G.; Ferreira, J.; Maciel, P.; Tutsch, D.; Souza, R. An integrated modeling approach to evaluate and optimize data center sustainability, dependability and cost. Energies 2014, 7, 238–277. [Google Scholar] [CrossRef]
- Perspectives, I. Using a Total Cost of Ownership (TCO) Model for Your Data Center. Available online: http://www.datacenterknowledge.com/archives/2013/10/01/using-a-total-cost-of-ownership-tco-model-for-your-data-center/ (accessed on 20 February 2017).
- Filani, D.; He, J.; Gao, S.; Rajappa, M.; Kumar, A.; Shah, P.; Nagappan, R. Dynamic data center power management: Trends, issues, and solutions. Int. Technol. J. 2008, 12, 59–67. [Google Scholar] [CrossRef]
- Cheng, C.C.; Lee, D.; Wang, C.H.; Lin, S.F.; Chang, H.P.; Fang, S.T. The development of cloud energy management. Energies 2015, 8, 4357–4377. [Google Scholar] [CrossRef]
- Chiaraviglio, L.; Cianfrani, A.; Listanti, M.; Liu, W.; Polverini, M. Lifetime-aware cloud data centers: Models and performance evaluation. Energies 2016, 9, 470. [Google Scholar] [CrossRef]
- Cui, X.; Mills, B.; Znati, T.; Melhem, R. Shadow replication: An energy-aware, fault-tolerant computational model for green cloud computing. Energies 2014, 7, 5151–5176. [Google Scholar] [CrossRef]
- Bourguiba, M.; Haddadou, K.; Korbi, I.E.; Pujolle, G. Improving network i/o virtualization for cloud computing. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 673–681. [Google Scholar] [CrossRef]
- Greenberg, A.; Hamilton, J.; Maltz, D.A.; Patel, P. The cost of a cloud: Research problems in data center networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 39, 68–73. [Google Scholar] [CrossRef]
- Barroso, L.A.; Holzle, U. The case for energy-proportional computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- Mastroianni, C.; Meo, M.; Papuzzo, G. Probabilistic consolidation of virtual machines in self-organizing cloud data centers. IEEE Trans. Cloud Comput. 2013, 1, 215–228. [Google Scholar] [CrossRef]
- Kandula, S.; Sengupta, S.; Greenberg, A.; Patel, P.; Chaiken, R. The nature of data center traffic: Measurements & analysis. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009. [Google Scholar]
- Speitkamp, B.; Bichler, M. A mathematical programming approach for server consolidation problems in virtualized data centers. IEEE Trans. Serv. Comput. 2010, 3, 266–278. [Google Scholar] [CrossRef]
- Setzer, T.; Bichler, M. Using matrix approximation for highdimensional discrete optimization problems: Server consolidation based on cyclic time-series data. Eur. J. Oper. Res. 2013, 227, 62–75. [Google Scholar] [CrossRef]
- Zhang, S.; Qian, Z.Z.; Luo, Z.Y.; Wu, J.; Lu, S.L. Burstiness-aware resource reservation for server consolidation in computing clouds. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 964–977. [Google Scholar] [CrossRef]
- Boutaba, R.; Cheng, L.; Zhang, Q. On cloud computational models and the heterogeneity challenge. J. Internet Serv. Appl. 2012, 3, 77–86. [Google Scholar] [CrossRef]
- Wolke, A.; Bichler, M.; Setzer, T. Planning vs. dynamic control: Resource allocation in corporate clouds. IEEE Trans. Cloud Comput. 2016, 4, 322–335. [Google Scholar] [CrossRef]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for Cloud computing. Future Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar] [CrossRef]
- Mishra, A.K.; Hellerstein, J.L.; Cirne, W.; Das, C.R. Towards characterizing cloud backend workloads: Insights from Google compute clusters. ACM SIGMETRICS Perform. Eval. Rev. 2010, 37, 34–41. [Google Scholar] [CrossRef]
- Islam, S.; Keung, J.; Lee, K.; Liu, A. Empirical prediction models for adaptive resource provisioning in the cloud. Future Gener. Comput. Syst. 2012, 28, 155–162. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhani, M.F.; Boutaba, R.; Hellerstein, J.L. Dynamic heterogeneity-aware resource provisioning in the cloud. IEEE Trans. Cloud Comput. 2014, 2, 14–28. [Google Scholar] [CrossRef]
- Verma, M.; Gangadharan, G.R.; Narendra, N.C.; Vadlamani, R.; Inamdar, V.; Ramachandran, L.; Calheiros, R.N.; Buyya, R. Dynamic resource demand prediction and allocation in multi-tenant service clouds. Concurr. Computat. Pract. Exp. 2016. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Liu, X.F.; Gong, Y.J.; Zhang, J.; Chung, H.; Li, Y. Cloud computing resource scheduling and a survey of its evolutionary approaches. ACM Comput. Surv. 2015, 47, 1–33. [Google Scholar] [CrossRef]
- Wu, Q.; Peng, C. A least squares support vector machine optimized by cloud-based evolutionary algorithm for wind power generation prediction. Energies 2016, 9, 585. [Google Scholar] [CrossRef]
- Huang, M. Hybridization of chaotic quantum particle swarm optimization with SVR in electric demand forecasting. Energies 2016, 9, 426. [Google Scholar] [CrossRef]
- Mi, H.; Wang, H.; Yin, G.; Zhou, Y.; Shi, D.; Yuan, L. Online self-reconfiguration with performance guarantee for energy-efficient large-scale cloud computing data centers. In Proceedings of the IEEE International Conference on Services Computing, Miami, FL, USA, 11–15 July 2010. [Google Scholar]
- Ashraf, A.; Porres, I. Using ant colony system to consolidate multiple web applications in a cloud environment. In Proceedings of the 22nd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turin, Italy, 12–14 February 2014. [Google Scholar]
- Farahnakian, F.; Ashraf, A.; Pahikkala, T.; Liljeberg, P.; Plosila, J.; Porres, I.; Tenhunen, H. Using ant colony system to consolidate VMs for green cloud computing. IEEE Trans. Serv. Comput. 2015, 8, 187–198. [Google Scholar] [CrossRef]
- Liu, X.F.; Zhan, Z.H.; Deng, J.D.; Li, Y.; Gu, T.L.; Zhang, J. An energy efficient ant colony system for virtual machine placement in cloud computing. IEEE Trans. Evolut. Computat. 2016. [Google Scholar] [CrossRef]
- Fan, X.B.; Weber, W.-D.; Barroso, L.A. Power provisioning for a warehouse-sized computer. ACM SIGARCH Comput. Archit. News 2007, 35, 13–23. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evolut. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Deb, K.; Mohan, M.; Mishra, S. Evaluating the ε-domination based multi-objective evolutionary algorithm for a quick computation of Pareto-optimal solutions. Evolut. Comput. 2005, 13, 501–525. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evolut. Computat. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Zhan, Z.H.; Li, J.; Cao, J.; Zhang, J.; Chung, H.; Shi, Y.H. Multiple populations for multiple objectives: A coevolutionary technique for solving multiobjective optimization problems. IEEE Trans. Cybern. 2013, 43, 445–463. [Google Scholar] [CrossRef] [PubMed]
- Yue, M. A simple proof of the inequality FFD (L) ≤ 11/9 OPT (L) + 1, for all L for the FFD bin-packing algorithm. Acta Math. Appl. Sin. 1991, 7, 321–331. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Test | λ | CPU Range | RAM Range | VM Number | Server Number (CPU, RAM) |
|---|---|---|---|---|---|
| RW1 | 9.6 | [1, 4] | [1, 8] | 10,000 | 8000 (24, 48) |
| RW2 | 9.6 | [1, 1] | [0, 3] | 10,000 | 8000 (16, 32) |
| RW3 | 13.3 | [1, 4] | [1, 8] | 19,200 | 8000 (16, 32) |
| RW4 | 30 | [1, 4] | [1, 8] | 43,200 | 8000 (16, 32) |
| RW5 | 9.6 + 30 + 9.6 | [1, 4] | [1, 8] | 27,288 | 8000 (16, 32) |
| Metrics | Number of VM Migrations | Energy Consumption (kWh) | SLAO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UACS | ACS-VM | ecoCloud | BFD | UACS | ACS-VM | ecoCloud | BFD | UACS | ACS-VM | ecoCloud | BFD | |
| RW1 | 3.69 × 103 | 6.78 × 102 | 0 | 1.45 × 106 | 263.00 | 270.00 | 4433.33 | 286.66 | 0 | 0.0065 | 0 | 0 |
| RW2 | 5.97 × 103 | 1.15 × 103 | 0 | 1.47 × 106 | 3120.00 | 2433.33 | 5283.33 | 5266.66 | 0 | 0.3541 | 0 | 0 |
| RW3 | 1.45 × 106 | 1.61 × 103 | 0 | 2.84 × 106 | 1900.00 | 1816.66 | 8933.33 | 2266.66 | 0 | 0.5624 | 0 | 0 |
| RW4 | 3.35 × 106 | 1.67 × 103 | 0 | 6.40 × 106 | 4266.66 | 3983.33 | 2,0166.67 | 5100.00 | 0 | 0.6157 | 0 | 0 |
| RW5 | 1.29 × 106 | 1.63 × 103 | 0 | 4.04 × 106 | 2916.66 | 2550.00 | 12683.33 | 3216.66 | 0 | 0.5895 | 0 | 0 |
| Metrics | Number of VM Migrations | Energy Consumption (kWh) | SLAO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UACS | ACS-VM | ecoCloud | BFD | UACS | ACS-VM | ecoCloud | BFD | UACS | ACS-VM | ecoCloud | BFD | |
| RW6 | 65,606 | 3211 | 470 | 2,622,035 | 12,083.33 | 9833.33 | 39,416.66 | 12,000.00 | 0 | 0.6693 | 0 | 0 |
| RW7 | 190,615 | 3144 | 674 | 2,233,933 | 5350.00 | 4125.00 | 34,916.66 | 5400.00 | 0 | 0.6517 | 0 | 0 |
| RW8 | 129,095 | 3145 | 1159 | 2,347,086 | 7791.66 | 6250.00 | 33,333.33 | 7808.33 | 0 | 0.6409 | 0 | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.-F.; Zhan, Z.-H.; Zhang, J. An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing. Energies 2017, 10, 609. https://doi.org/10.3390/en10050609
Liu X-F, Zhan Z-H, Zhang J. An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing. Energies. 2017; 10(5):609. https://doi.org/10.3390/en10050609
Chicago/Turabian StyleLiu, Xiao-Fang, Zhi-Hui Zhan, and Jun Zhang. 2017. "An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing" Energies 10, no. 5: 609. https://doi.org/10.3390/en10050609
APA StyleLiu, X. -F., Zhan, Z. -H., & Zhang, J. (2017). An Energy Aware Unified Ant Colony System for Dynamic Virtual Machine Placement in Cloud Computing. Energies, 10(5), 609. https://doi.org/10.3390/en10050609